
La tolérance aux pannes et la haute disponibilité sont des sujets importants, donc RabbitMQ et Kafka consacreront des articles distincts. Cet article concerne RabbitMQ, et le suivant concerne Kafka, par rapport à RabbitMQ. L'article est long, alors installez-vous confortablement.
Tenez compte des stratégies de tolérance aux pannes, de cohérence et de haute disponibilité (HA), ainsi que des compromis que chaque stratégie doit faire. RabbitMQ peut fonctionner sur un cluster de nœuds - puis il est classé comme un système distribué. Lorsqu'il s'agit de systèmes distribués, nous parlons souvent de cohérence et d'accessibilité.
Ces concepts décrivent le comportement du système en cas de panne. Échec de la connexion réseau, défaillance du serveur, défaillance du disque dur, indisponibilité temporaire du serveur en raison de la récupération de place, de la perte de paquets ou du ralentissement de la connexion réseau. Tout cela peut entraîner des pertes de données ou des conflits. Il s'avère qu'il est presque impossible de développer un système à la fois complètement cohérent (sans perte de données, sans anomalies de données) et accessible (il acceptera les opérations de lecture et d'écriture) pour tous les types de défaillance.
Nous verrons que la cohérence et l'accessibilité se situent à différentes extrémités du spectre, et vous devez choisir la voie à optimiser. La bonne nouvelle est qu'avec RabbitMQ un tel choix est possible. Vous avez une sorte de levier "Nerd" pour déplacer l'équilibre vers une plus grande cohérence ou une plus grande accessibilité.
Nous porterons une attention particulière aux configurations entraînant une perte de données en raison des enregistrements confirmés. Il existe une chaîne de responsabilité entre les éditeurs, les courtiers et les consommateurs. Une fois le message transmis au courtier, il lui appartient de ne pas perdre le message. Lorsque le courtier confirme à l'éditeur la réception du message, nous ne nous attendons pas à ce qu'il soit perdu. Mais nous verrons que cela peut vraiment se produire en fonction de la configuration de votre courtier et éditeur.
Les primitives de stabilité d'un nœud
Files d'attente / routage soutenus
Il existe deux types de files d'attente dans RabbitMQ: durable / non durable. Toutes les files d'attente sont stockées dans la base de données Mnesia. Les files d'attente persistantes sont re-déclarées au démarrage du nœud et survivent ainsi à un redémarrage, à un plantage du système ou à un plantage du serveur (tant que les données sont enregistrées). Cela signifie que pendant que vous déclarez le routage (échange) et la file d'attente résiliente, l'infrastructure des files d'attente / routage reviendra au mode en ligne.
Les files d'attente volatiles et le routage sont supprimés au redémarrage de l'hôte.
Messages persistants
Ce n'est pas parce que la file d'attente est longue que tous ses messages survivront au redémarrage d'un nœud. Seuls les messages définis par l'éditeur comme persistants seront restaurés. Les messages persistants créent une charge supplémentaire pour le courtier, mais si la perte de messages est inacceptable, il n'y a pas d'autre moyen.
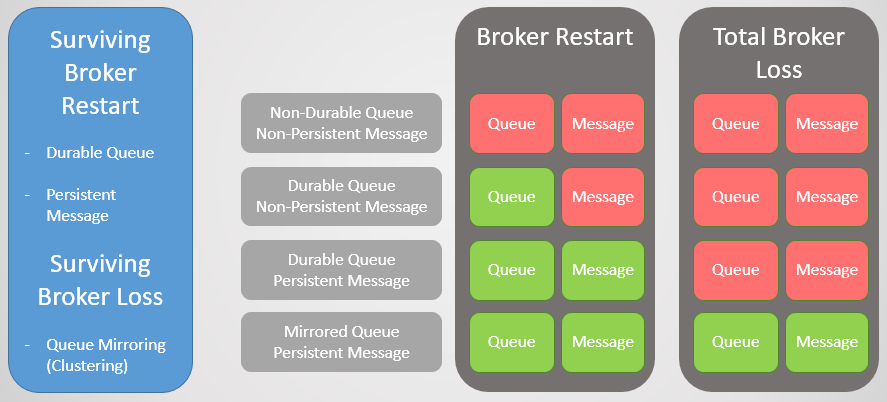 Fig. 1. Matrice de stabilité
Fig. 1. Matrice de stabilitéMise en miroir de la file d'attente
Pour survivre à la perte d'un courtier, nous avons besoin de redondance. Nous pouvons combiner plusieurs nœuds RabbitMQ dans un cluster, puis ajouter une redondance supplémentaire en répliquant les files d'attente entre plusieurs nœuds. Ainsi, si un nœud tombe, nous ne perdons pas de données et restons disponibles.
Mise en miroir de la file d'attente:
- une file d'attente principale (maître), qui reçoit toutes les commandes d'écriture et de lecture
- un ou plusieurs miroirs qui reçoivent tous les messages et métadonnées de la file d'attente principale. Ces miroirs n'existent pas pour la mise à l'échelle, mais uniquement pour la redondance.
 Fig. 2. Mise en miroir de la file d'attente
Fig. 2. Mise en miroir de la file d'attenteLa mise en miroir est définie par la stratégie appropriée. Dans celui-ci, vous pouvez choisir le taux de réplication et même les nœuds sur lesquels la file d'attente doit être placée. Exemples:
ha-mode: all
ha-mode: exactly, ha-params: 2 (un maître et un miroir)
ha-mode: nodes, ha-params: rabbit@node1, rabbit@node2
Confirmation à l'éditeur
Pour obtenir un enregistrement séquentiel, les confirmations de l'éditeur doivent être confirmées. Sans eux, il y a une chance de perdre des messages. Une confirmation est envoyée à l'éditeur après avoir écrit le message sur le disque. RabbitMQ écrit des messages sur le disque non pas à la réception, mais sur une base périodique, dans la région de plusieurs centaines de millisecondes. Lorsque la file d'attente est mise en miroir, la confirmation n'est envoyée qu'après que tous les miroirs ont également écrit leur copie du message sur le disque. Cela signifie que l'utilisation d'accusés de réception augmente le délai, mais si la sécurité des données est importante, elles sont nécessaires.
File d'attente de basculement
Lorsque le courtier s'arrête ou se bloque, toutes les files d'attente principales (maîtres) sur ce nœud tombent avec lui. Le cluster sélectionne ensuite le miroir le plus ancien de chaque maître et le promeut en tant que nouveau maître.
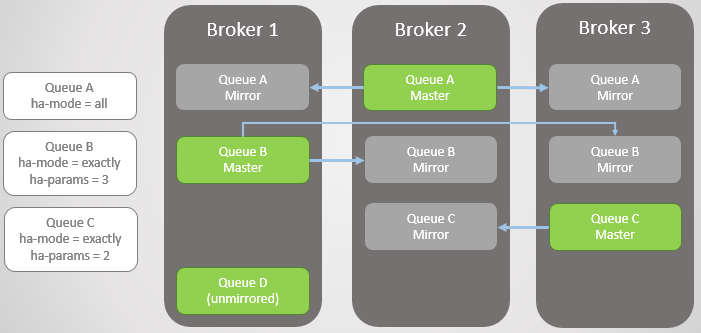 Fig. 3. Plusieurs files d'attente en miroir et leurs politiques
Fig. 3. Plusieurs files d'attente en miroir et leurs politiquesCourtier 3 gouttes. Notez que le miroir de la file d'attente C sur Broker 2 est mis à niveau vers un maître. Notez également qu'un nouveau miroir a été créé pour la file d'attente C sur le courtier 1. RabbitMQ essaie toujours de maintenir le taux de réplication spécifié dans vos stratégies.
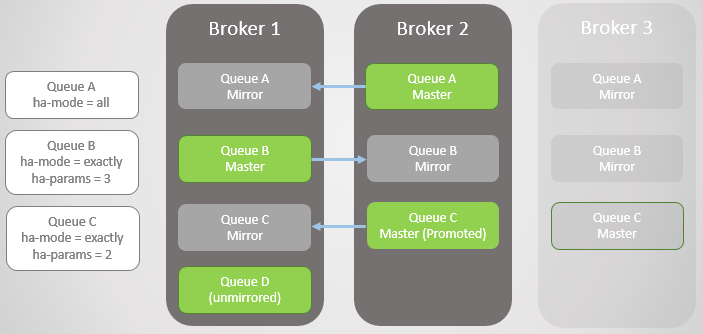 Fig. 4. Le courtier 3 tombe, entraînant l'échec de la file d'attente C
Fig. 4. Le courtier 3 tombe, entraînant l'échec de la file d'attente CLe prochain courtier 1 tombe! Il ne nous reste qu'un courtier. Le miroir de la file d'attente B monte vers le maître.
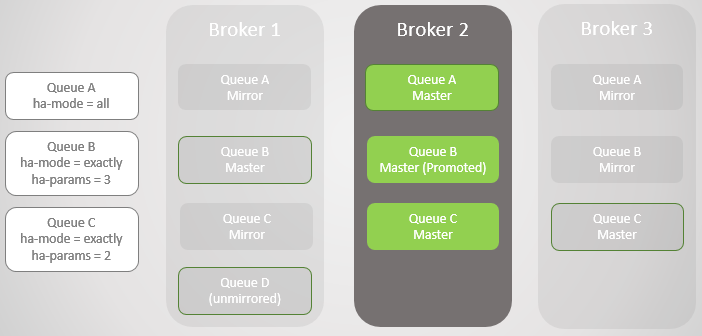 Fig. 5
Fig. 5Nous avons renvoyé le courtier 1. Quel que soit le succès avec lequel les données ont survécu à la perte et à la récupération du courtier, tous les messages de file d'attente en miroir sont ignorés au redémarrage. Ceci est important à noter, car il y aura des conséquences. Nous examinerons bientôt ces conséquences. Ainsi, Broker 1 est à nouveau membre du cluster, et le cluster tente de se conformer aux stratégies et crée donc des miroirs sur Broker 1.
Dans ce cas, la perte du courtier 1 était terminée, ainsi que les données, de sorte que la file d'attente D sans miroir était complètement perdue.
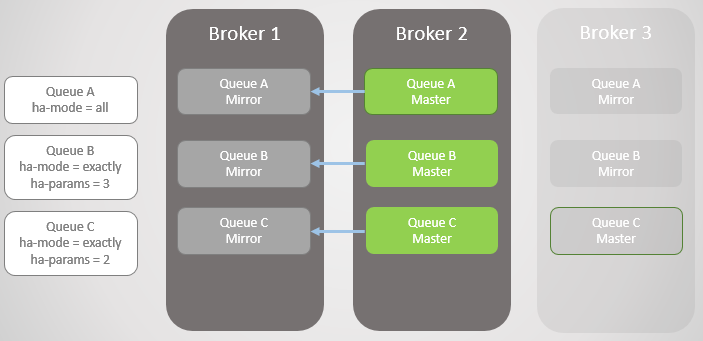 Fig. 6. Le courtier 1 est de retour en service
Fig. 6. Le courtier 1 est de retour en serviceLe courtier 3 est de retour en ligne, donc les lignes A et B obtiennent des miroirs créés en fonction de leurs politiques HA. Mais maintenant, toutes les lignes principales sont sur un seul nœud! Ce n'est pas idéal; une distribution uniforme entre les nœuds est meilleure. Malheureusement, il n'y a pas d'options spéciales pour rééquilibrer les maîtres. Nous reviendrons sur ce problème plus tard, car nous devons d'abord considérer la synchronisation des files d'attente.
 Fig. 7. Le courtier 3 est de retour en service. Toutes les files d'attente principales sur un nœud!
Fig. 7. Le courtier 3 est de retour en service. Toutes les files d'attente principales sur un nœud!Ainsi, vous devriez maintenant avoir une idée de la façon dont les miroirs offrent une redondance et une tolérance aux pannes. Cela garantit la disponibilité en cas de défaillance d'un nœud unique et protège contre la perte de données. Mais nous n'avons pas encore fini, car en réalité tout est beaucoup plus compliqué.
Sync
Lors de la création d'un nouveau miroir, tous les nouveaux messages seront toujours répliqués sur ce miroir et tous les autres. Quant aux données existantes dans la file d'attente principale, nous pouvons les répliquer dans un nouveau miroir, qui devient une copie complète du maître. Nous ne pouvons pas non plus répliquer les messages existants et permettre à la file d'attente principale et au nouveau miroir de converger à temps lorsque de nouveaux messages arrivent en queue et que les messages existants quittent la tête de la file d'attente principale.
Cette synchronisation est effectuée automatiquement ou manuellement et est contrôlée à l'aide d'une politique de file d'attente. Prenons un exemple.
Nous avons deux lignes en miroir. La file d'attente A se synchronise automatiquement et la file d'attente B manuellement. Les deux lignes ont chacune dix messages.
 Fig. 8. Deux files d'attente avec différents modes de synchronisation
Fig. 8. Deux files d'attente avec différents modes de synchronisationMaintenant, nous perdons Broker 3.
 Fig. 9. Le courtier 3 est tombé
Fig. 9. Le courtier 3 est tombéLe courtier 3 est de retour en service. Le cluster crée un miroir pour chaque file d'attente sur le nouveau nœud et synchronise automatiquement la nouvelle file d'attente A avec le maître. Cependant, le miroir du nouveau Turn B reste vide. Ainsi, nous avons une redondance complète de la file d'attente A et un seul miroir pour les messages existants de la file d'attente B.
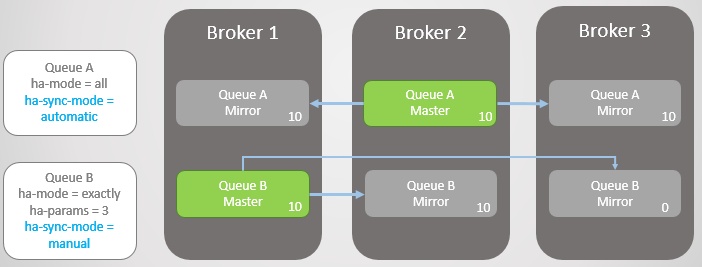 Fig. 10. Le nouveau miroir de la file d'attente A reçoit tous les messages existants, mais le nouveau miroir de la file d'attente B ne
Fig. 10. Le nouveau miroir de la file d'attente A reçoit tous les messages existants, mais le nouveau miroir de la file d'attente B neLes deux lignes reçoivent dix messages supplémentaires. Ensuite, le courtier 2 tombe et la file d'attente A revient au miroir le plus ancien, qui se trouve sur le courtier 1. En cas de défaillance, il n'y a pas de perte de données. Il y a vingt messages dans la file d'attente B dans l'assistant et seulement dix dans le miroir, car cette file d'attente n'a jamais répliqué les dix messages d'origine.
 Fig. 11. La ligne A est restaurée vers le courtier 1 sans perdre de messages
Fig. 11. La ligne A est restaurée vers le courtier 1 sans perdre de messagesLes deux lignes reçoivent dix messages supplémentaires. Le courtier 1 se bloque maintenant. La file d'attente A passe au miroir sans aucun problème sans perdre de messages. Cependant, la file d'attente B a des problèmes. À ce stade, nous pouvons optimiser l'accessibilité ou la cohérence.
Si nous voulons optimiser l'accessibilité, la politique
ha-promotion-on-fail doit être définie sur
toujours . Il s'agit de la valeur par défaut, vous pouvez donc tout simplement omettre la stratégie. Dans ce cas, en fait, nous autorisons les échecs dans les miroirs non synchronisés. Cela entraînera une perte de message, mais la file d'attente reste lisible et inscriptible.
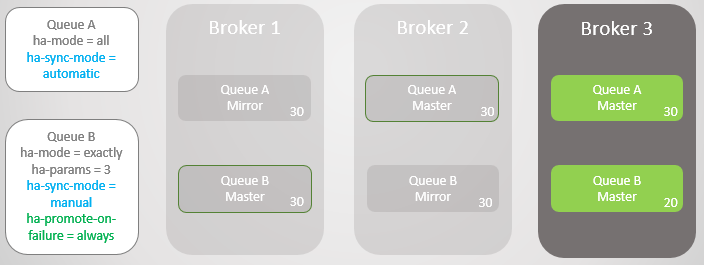 Fig. 12. La ligne A est restaurée vers le courtier 3 sans perdre de messages. La ligne B revient au courtier 3 avec la perte de dix messages
Fig. 12. La ligne A est restaurée vers le courtier 3 sans perdre de messages. La ligne B revient au courtier 3 avec la perte de dix messagesNous pouvons également définir
ha-promote-on-failure sur une
when-synced . Dans ce cas, au lieu de revenir au miroir, la file d'attente attendra que le courtier 1 avec ses données revienne en mode en ligne. Après son retour, la file d'attente principale apparaît à nouveau sur le courtier 1 sans perte de données. L'accessibilité est sacrifiée pour la sécurité des données. Mais c'est un mode risqué, qui peut même conduire à une perte complète de données, que nous envisagerons dans un avenir proche.
 Fig. 13. La ligne B reste indisponible après avoir perdu le courtier 1
Fig. 13. La ligne B reste indisponible après avoir perdu le courtier 1Vous pouvez poser une question: «Peut-être est-il préférable de ne jamais utiliser la synchronisation automatique?». La réponse est que la synchronisation est une opération de blocage. Pendant la synchronisation, la file d'attente principale ne peut effectuer aucune opération de lecture ou d'écriture!
Prenons un exemple. Nous avons maintenant de très longues files d'attente. Comment peuvent-ils atteindre cette taille? Pour plusieurs raisons:
- Les files d'attente ne sont pas activement utilisées.
- Ce sont des lignes à grande vitesse, et en ce moment, les consommateurs sont lents
- Ce sont des files d'attente à grande vitesse, une défaillance s'est produite et les consommateurs rattrapent leur retard
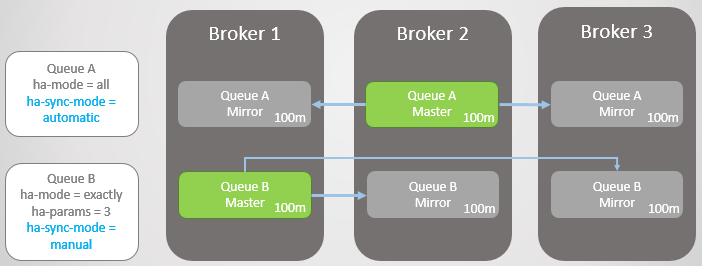 Fig. 14. Deux grandes files d'attente avec différents modes de synchronisation
Fig. 14. Deux grandes files d'attente avec différents modes de synchronisationMaintenant, Broker 3 plante.
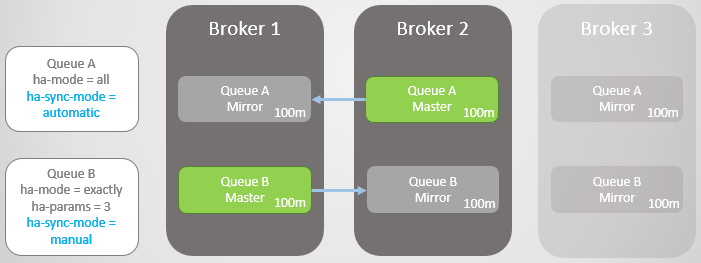 Fig. 15. Le courtier 3 tombe, laissant un maître et un miroir dans chaque file d'attente
Fig. 15. Le courtier 3 tombe, laissant un maître et un miroir dans chaque file d'attenteBroker 3 revient et de nouveaux miroirs sont créés. La file d'attente principale A commence à répliquer les messages existants vers un nouveau miroir et pendant ce temps, la file d'attente A n'est pas disponible. La réplication des données nécessite deux heures, ce qui entraîne deux heures d'indisponibilité pour cette file d'attente!
Cependant, la ligne B reste disponible pendant toute la période. Elle a sacrifié une certaine redondance pour des raisons d'accessibilité.
 Fig. 16. La file d'attente reste indisponible pendant la synchronisation
Fig. 16. La file d'attente reste indisponible pendant la synchronisationAprès deux heures, la file d'attente A devient également disponible et peut recommencer à accepter les opérations de lecture et d'écriture.
Mises à jour
Ce comportement de blocage lors de la synchronisation rend difficile la mise à niveau des clusters avec de très grandes files d'attente. À un moment donné, le nœud avec l'assistant doit être redémarré, ce qui signifie soit basculer vers le miroir soit désactiver la file d'attente lors de la mise à jour du serveur. Si nous choisissons une transition, nous perdrons des messages si les miroirs ne sont pas synchronisés. Par défaut, lors de la déconnexion du courtier, la transition vers un miroir non synchronisé n'est pas effectuée. Cela signifie que dès que le courtier revient, nous ne perdons aucun message, le seul dommage était seulement une simple file d'attente. La désactivation des courtiers est régie par la politique
ha-promote-on-shutdown . Vous pouvez définir l'une des deux valeurs:
always = basculement activé vers des miroirs non synchronisés
when-synced = basculer uniquement vers le miroir synchronisé, sinon la file d'attente devient inaccessible pour la lecture et l'écriture. La file d'attente revient dès que le courtier revient
D'une manière ou d'une autre, avec de grandes files d'attente, vous devez choisir entre la perte de données et l'inaccessibilité.
Quand la disponibilité améliore la sécurité des données
Avant de prendre une décision, une complication supplémentaire doit être prise en compte. Bien que la synchronisation automatique soit meilleure pour la redondance, comment affecte-t-elle la sécurité des données? Bien sûr, grâce à une meilleure redondance, RabbitMQ est moins susceptible de perdre des messages existants, mais qu'en est-il des nouveaux messages des éditeurs?
Ici, vous devez prendre en compte les éléments suivants:
- Un éditeur peut-il simplement renvoyer une erreur et un service ou un utilisateur supérieur réessaiera plus tard?
- Un éditeur peut-il enregistrer un message localement ou dans une base de données pour réessayer plus tard?
Si l'éditeur ne peut que supprimer le message, alors, en fait, l'amélioration de l'accessibilité augmente également la sécurité des données.
Ainsi, vous devez rechercher un équilibre et la décision dépend de la situation spécifique.
Problèmes avec ha-promo-on-failure = lors de la synchronisation
L'idée de
ha-promo-on-failure =
lors de la synchronisation est que nous empêchons de basculer vers un miroir non synchronisé et évitons ainsi la perte de données. La file d'attente reste inaccessible pour la lecture ou l'écriture. Au lieu de cela, nous essayons de renvoyer un courtier tombé en panne avec des données intactes afin qu'il reprenne le travail en tant que maître sans perte de données.
Mais (et c'est gros mais) si le courtier a perdu ses données, alors nous avons un gros problème: la file d'attente est perdue! Toutes les données ont disparu! Même si vous disposez de miroirs qui rattrapent essentiellement la file d'attente principale, ces miroirs sont également supprimés.
Pour rajouter un nœud avec le même nom, nous demandons au cluster d'oublier le nœud perdu (avec la
commande rabbitmqctl oublie_cluster_node ) et démarre un nouveau courtier avec le même nom d'hôte. Tant que le cluster se souvient du nœud perdu, il se souvient de l'ancienne file d'attente et des miroirs non synchronisés. Lorsqu'un cluster est invité à oublier un nœud perdu, cette file d'attente est également oubliée. Vous devez maintenant le déclarer à nouveau. Nous avons perdu toutes les données, bien que nous disposions de miroirs avec un ensemble de données partiel. Il serait préférable de passer à un miroir non synchronisé!
Par conséquent, à mon avis, la synchronisation manuelle (et l'échec de la synchronisation) en combinaison avec
ha-promote-on-failure=when-synced est assez risquée. Les documents disent que cette option existe pour la sécurité des données, mais c'est un couteau à double tranchant.
Rééquilibrer les Masters
Comme promis, nous revenons au problème de l'accumulation de tous les maîtres sur un ou plusieurs nœuds. Cela peut se produire même à la suite de mises à jour continues de cluster. Dans un cluster à trois nœuds, toutes les files d'attente principales s'accumuleront sur un ou deux nœuds.
Le rééquilibrage des maîtres peut être problématique pour deux raisons:
- Pas de bons outils de rééquilibrage
- Synchronisation de file d'attente
Pour le rééquilibrage, il existe un
plugin tiers qui n'est pas officiellement pris en charge. Concernant les plug-ins tiers, le manuel RabbitMQ
dit : «Le plug-in fournit des outils de configuration et de reporting supplémentaires, mais il n'est pas pris en charge et non testé par l'équipe RabbitMQ. Utilisez à vos risques et périls. "
Il existe une autre astuce pour déplacer la file d'attente principale via des stratégies HA. Le manuel mentionne un
script pour cela. Cela fonctionne comme suit:
- Supprime tous les miroirs utilisant une stratégie temporaire avec une priorité plus élevée que la stratégie HA existante.
- Modifie la stratégie temporaire HA pour utiliser le mode nœuds avec le nœud vers lequel la file d'attente principale doit être déplacée.
- Synchronise la file d'attente pour la migration forcée.
- Une fois la migration terminée, supprime la stratégie temporaire. La stratégie initiale HA entre en vigueur et le nombre de miroirs requis est créé.
L'inconvénient est que cette approche peut ne pas fonctionner si vous avez de grandes files d'attente ou des exigences de redondance strictes.
Voyons maintenant comment les clusters RabbitMQ fonctionnent avec les partitions réseau.
Perturbation de la connectivité
Les nœuds d'un système distribué sont connectés par des liaisons réseau, et les liaisons réseau peuvent et seront déconnectées. La fréquence des pannes dépend de l'infrastructure locale ou de la fiabilité du cloud sélectionné. Dans tous les cas, les systèmes distribués devraient pouvoir les gérer. Encore une fois, nous avons le choix entre l'accessibilité et la cohérence, et encore une fois, la bonne nouvelle est que RabbitMQ fournit les deux (mais pas en même temps).
Avec RabbitMQ, nous avons deux options principales:
- Autoriser la séparation logique (split-brain). Cela fournit l'accessibilité, mais peut entraîner une perte de données.
- Interdisez la séparation logique. Peut entraîner une perte de disponibilité à court terme selon la façon dont les clients se connectent au cluster. Cela peut également conduire à une inaccessibilité complète dans un cluster de deux nœuds.
Mais qu'est-ce que la séparation logique? C'est lorsqu'un cluster est divisé en deux en raison de la perte de connexions réseau. De chaque côté, les rétroviseurs montent vers le maître, donc au final, il y a plusieurs maîtres à chaque tour.
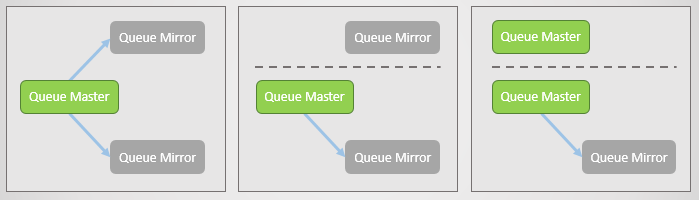 Fig. 17. La ligne principale et deux miroirs, chacun sur un nœud distinct. Ensuite, une panne de réseau se produit et un miroir se sépare. Le nœud détaché voit que les deux autres sont tombés et avance ses miroirs au maître. Nous avons maintenant deux lignes principales, et les deux permettent l'écriture et la lecture.
Fig. 17. La ligne principale et deux miroirs, chacun sur un nœud distinct. Ensuite, une panne de réseau se produit et un miroir se sépare. Le nœud détaché voit que les deux autres sont tombés et avance ses miroirs au maître. Nous avons maintenant deux lignes principales, et les deux permettent l'écriture et la lecture.Si les éditeurs envoient des données aux deux maîtres, nous obtenons deux copies divergentes de la file d'attente.
Les différents modes RabbitMQ offrent soit l'accessibilité soit la cohérence.
Ignorer le mode (par défaut)
Ce mode fournit l'accessibilité. Après la perte de connectivité, une séparation logique se produit. Après la reconnexion, l'administrateur doit décider quelle partition préférer. Le côté perdant sera redémarré et toutes les données accumulées de ce côté seront perdues.
 Fig. 18. Trois éditeurs sont associés à trois courtiers. En interne, le cluster transfère toutes les demandes à la file d'attente principale sur Broker 2.
Fig. 18. Trois éditeurs sont associés à trois courtiers. En interne, le cluster transfère toutes les demandes à la file d'attente principale sur Broker 2.Maintenant, nous perdons le courtier 3. Il voit que d'autres courtiers sont tombés et déplace son miroir vers le maître. C'est la séparation logique.
 Fig. 19. Séparation logique (split-brain). Les enregistrements vont sur deux lignes principales et deux copies divergent.
Fig. 19. Séparation logique (split-brain). Les enregistrements vont sur deux lignes principales et deux copies divergent.La connectivité est restaurée, mais la séparation logique demeure. L'administrateur doit sélectionner manuellement le côté perdant. Dans le cas suivant, l'administrateur redémarre Broker 3. Tous les messages qu'il n'a pas réussi à transmettre sont perdus.
 Fig. 20. L'administrateur désactive Broker 3.
Fig. 20. L'administrateur désactive Broker 3. Fig. 21. L'administrateur démarre Broker 3 et il rejoint le cluster, perdant tous les messages qui y sont restés.
Fig. 21. L'administrateur démarre Broker 3 et il rejoint le cluster, perdant tous les messages qui y sont restés.Pendant la perte de connectivité et après sa restauration, le cluster et cette file d'attente étaient disponibles pour la lecture et l'écriture.
Mode Autoheal
Il fonctionne de manière similaire au mode Ignorer, sauf que le cluster lui-même sélectionne automatiquement le côté perdant après la division et la restauration de la connectivité. Le côté perdant revient au cluster vide et la file d'attente perd tous les messages qui ont été envoyés uniquement à ce côté.
Pause du mode minoritaire
Si nous ne voulons pas autoriser la séparation logique, alors notre seule option est de refuser de lire et d'écrire sur le petit côté après la partition du cluster. Quand un courtier voit qu'il est du côté inférieur, il fait une pause, c'est-à-dire, ferme toutes les connexions existantes et refuse toutes les nouvelles. Une fois par seconde, il vérifie la reconnexion. Une fois la connectivité restaurée, elle reprend son travail et rejoint le cluster.
 Fig. 22. Trois éditeurs sont associés à trois courtiers. En interne, le cluster transfère toutes les demandes à la file d'attente principale sur Broker 2.
Fig. 22. Trois éditeurs sont associés à trois courtiers. En interne, le cluster transfère toutes les demandes à la file d'attente principale sur Broker 2.Les courtiers 1 et 2 sont ensuite séparés du courtier 3. Au lieu de mettre à niveau leur miroir en maître, le courtier 3 s'arrête et devient inaccessible.
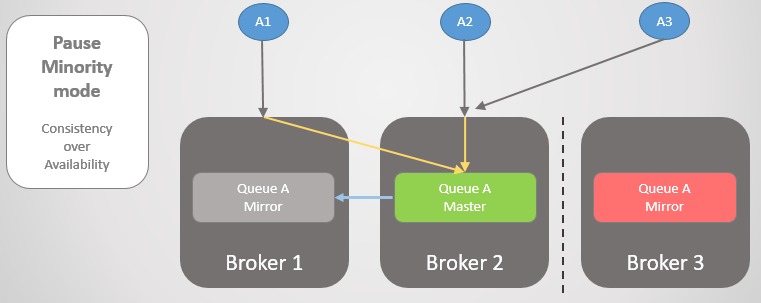 Fig. 23. Le courtier 3 interrompt, déconnecte tous les clients et rejette les demandes de connexion.
Fig. 23. Le courtier 3 interrompt, déconnecte tous les clients et rejette les demandes de connexion.Une fois la connectivité restaurée, elle revient au cluster.
Regardons un autre exemple, où la ligne principale se trouve sur Broker 3.
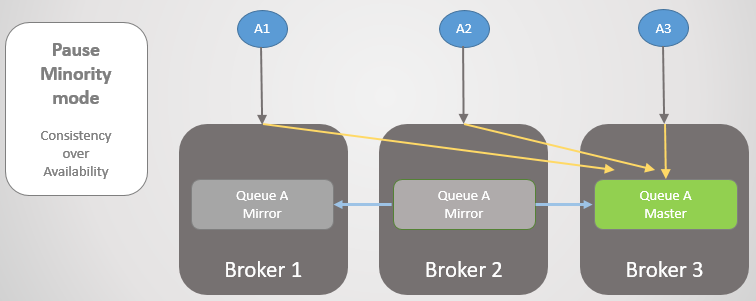 Fig. 24. La ligne principale au courtier 3.
Fig. 24. La ligne principale au courtier 3.Ensuite, la même perte de connectivité se produit. Le courtier 3 fait une pause car il est plus petit. De l'autre côté, les nœuds voient que le courtier 3 est tombé, de sorte que l'ancien miroir des courtiers 1 et 2 monte vers le maître.
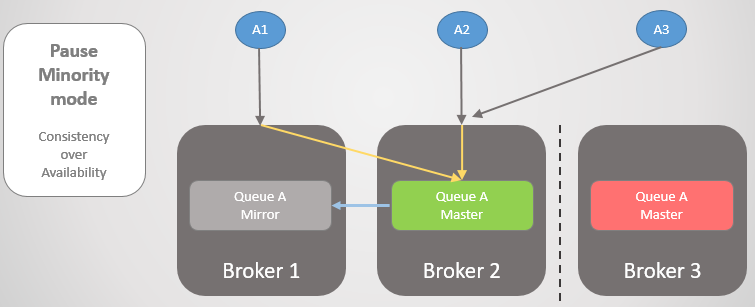 Fig. 25. Transition vers le courtier 2 si le courtier 3 n'est pas disponible.
Fig. 25. Transition vers le courtier 2 si le courtier 3 n'est pas disponible.Une fois la connectivité restaurée, Broker 3 se joindra au cluster.
 Fig. 26. Le cluster est revenu à un fonctionnement normal.
Fig. 26. Le cluster est revenu à un fonctionnement normal.Il est important de comprendre que nous obtenons de la cohérence, mais nous pouvons également obtenir l'accessibilité
si nous réussissons à transférer des clients vers la majeure partie de la section. Pour la plupart des situations, je choisirais personnellement le mode Pause minoritaire, mais cela dépend vraiment du cas particulier.
Pour garantir la disponibilité, il est important de s'assurer que les clients se connectent avec succès au site. Considérez nos options.
Connectivité client
Nous avons plusieurs options pour savoir comment, après avoir perdu la connectivité, envoyer des clients vers la partie principale du cluster ou vers des nœuds de travail (après une défaillance d'un nœud). Tout d'abord, rappelons qu'une file d'attente particulière est hébergée sur un hôte particulier, mais le routage et les politiques sont répliqués sur tous les hôtes. Les clients peuvent se connecter à n'importe quel nœud et le routage interne les dirigera si nécessaire. Mais lorsqu'un nœud est suspendu, il rejette la connexion, les clients doivent donc se connecter à un autre nœud. Si un nœud tombe, il ne peut rien faire du tout.
Nos options:
- Le cluster est accessible à l'aide d'un équilibreur de charge, qui parcourt simplement les nœuds et les clients tentent à plusieurs reprises de se connecter jusqu'à ce qu'ils soient terminés avec succès. , , ( ). , .
- / , . , , .
- , . , , .
- / DNS. TTL.
Conclusions
RabbitMQ . , :
. RabbitMQ , . , . RabbitMQ . RabbitMQ :
, :
ha-promote-on-failure=always
ha-sync-mode=manual
cluster_partition_handling=ignore ( autoheal )
- , , -
( ) :
- Publisher Confirms Manual Acknowledgements
ha-promote-on-failure=when-synced , ! =always .
ha-sync-mode=automatic ( ; , , )
- Pause Minority
; , (, ). Shovel.
- , , .
.
, RabbitMQ Docker Blockade, , .
:
№1 —
habr.com/ru/company/itsumma/blog/416629№2 —
habr.com/ru/company/itsumma/blog/418389№3 —
habr.com/ru/company/itsumma/blog/437446