Bonjour, Habr!
Dans le cadre de l'exploration du sujet de C # 8, nous vous suggérons de discuter de l'article suivant sur les nouvelles règles d'implémentation des interfaces.
 En examinant attentivement la façon dont les
En examinant attentivement la façon dont les interfaces sont structurées
en C # 8 , vous devez considérer que lors de la mise en œuvre des interfaces, vous pouvez casser le bois de chauffage par défaut.
Les hypothèses liées à l'implémentation par défaut peuvent entraîner une corruption du code, des exceptions d'exécution et de mauvaises performances.L'une des fonctionnalités activement annoncées des interfaces C # 8 est que vous pouvez ajouter des membres à une interface sans casser les implémenteurs existants. Mais l'inattention dans ce cas est lourde de gros problèmes. Considérez le code dans lequel les fausses hypothèses sont faites - cela rendra plus clair à quel point il est important d'éviter de tels problèmes.
Tout le code de cet article est publié sur GitHub: jeremybytes / interfaces-in-csharp-8 , en particulier dans le projet DangerousAssumptions .
Remarque: Cet article décrit les fonctionnalités de C # 8, actuellement implémentées uniquement dans .NET Core 3.0. Dans les exemples que j'ai utilisés, Visual Studio 16.3.0 et .NET Core 3.0.100 .
Hypothèses sur les détails de mise en œuvreLa principale raison pour laquelle j'articule ce problème est la suivante: j'ai trouvé un article sur Internet où l'auteur propose un code avec de très mauvaises hypothèses sur la mise en œuvre (je n'indiquerai pas l'article parce que je ne veux pas que l'auteur soit récapitulé avec des commentaires; je le contacterai personnellement) .
L'article parle de la qualité de l'implémentation par défaut, car il nous permet de compléter les interfaces même après que le code a déjà des implémenteurs. Cependant, un certain nombre de mauvaises hypothèses sont faites dans ce code (le code se trouve dans le dossier
BadInterface de mon projet GitHub)
Voici l'interface d'origine:
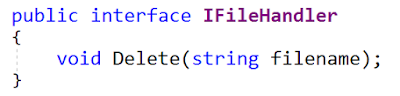
Le reste de l'article montre l'implémentation de l'interface MyFile (pour moi, dans le fichier
MyFile.cs ):
L'article montre ensuite comment vous pouvez ajouter la méthode
Rename avec l'implémentation par défaut, et il ne cassera pas la classe
MyFile existante.
Voici l'interface mise à jour (à partir
du fichier
IFileHandler.cs ):

MyFile fonctionne toujours, donc tout va bien. Alors? Pas vraiment.
Mauvaises hypothèsesLe principal problème avec la méthode Rename est ce qu'une hypothèse ÉNORME lui est associée: les implémentations utilisent un fichier physique situé dans le système de fichiers.
Considérez l'implémentation que j'ai créée pour une utilisation dans un système de fichiers situé dans la RAM. (Remarque: ceci est mon code. Ce n'est pas un article que je critique. Vous trouverez l'implémentation complète dans le fichier
MemoryStringFileHandler.cs .)

Cette classe implémente un système de fichiers formel qui utilise un dictionnaire situé dans la RAM, qui contient des fichiers texte. Il n'y a rien ici qui pourrait affecter le système de fichiers physique; il n'y a généralement aucune référence à
System.IO .
Implémenteur défectueuxAprès la mise à jour de l'interface, cette classe est endommagée.
Si le code client appelle la méthode Rename, il générera une erreur d'exécution (ou pire, renommera le fichier stocké dans le système de fichiers).
Même si notre implémentation fonctionne avec des fichiers physiques, elle peut accéder aux fichiers situés dans le stockage cloud et ces fichiers ne sont pas accessibles via System.IO.File.
Il existe également un problème potentiel en ce qui concerne les tests unitaires. Si l'objet simulé ou faux n'est pas mis à jour et que le code testé est mis à jour, il essaiera d'accéder au système de fichiers lors des tests unitaires.
Étant donné que la mauvaise hypothèse concerne l'interface, les implémenteurs de cette interface sont corrompus.
Des craintes déraisonnables?Il est inutile de considérer ces craintes comme non fondées. Quand je parle d'abus dans le code, ils me répondent: "Eh bien, c'est juste qu'une personne ne sait pas programmer." Je ne peux pas être en désaccord avec cela.
Habituellement, je fais cela: j'attends et regarde comment cela fonctionnera. Par exemple, j'avais peur que la possibilité d'une "utilisation statique" soit abusée. Jusqu'à présent, cela n'a pas dû être convaincu.
Il ne faut pas oublier que de telles idées sont dans l'air, il est donc en notre pouvoir d'aider les autres à emprunter une voie plus pratique, qui ne sera pas si pénible à suivre.
Problèmes de performancesJ'ai commencé à réfléchir à ce que d'autres problèmes pourraient nous attendre si nous faisions des hypothèses incorrectes sur les implémenteurs d'interface.
Dans l'exemple précédent, un code est appelé en dehors de l'interface elle-même (dans ce cas, en dehors de System.IO). Vous conviendrez probablement que de telles actions sont une cloche dangereuse. Mais, si nous utilisons les choses qui font déjà partie de l'interface, tout devrait bien se passer, non?
Pas toujours.
À titre d'exemple, j'ai créé l'interface IReader.
L'interface source et sa mise en œuvreVoici l'interface IReader d'origine (à partir du fichier
IReader.cs - bien qu'il existe déjà des mises à jour dans ce fichier):

Il s'agit d'une interface de méthode générique qui vous permet d'obtenir une collection d'éléments en lecture seule.
L'une des implémentations de cette interface génère une séquence de nombres de Fibonacci (oui, j'ai un intérêt malsain à générer des séquences de Fibonacci). Voici l'interface
FibonacciReader (du fichier
FibonacciReader.cs - elle est également mise à jour sur mon github):
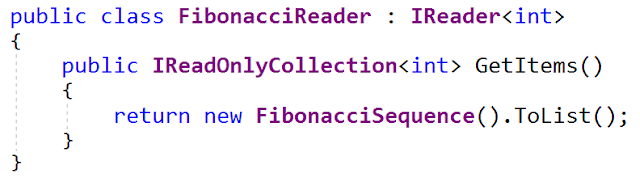
La classe
FibonacciSequence est une implémentation de
IEnumerable <int> (à partir du fichier FibonacciSequence.cs). Il utilise un entier 32 bits comme type de données, donc le débordement se produit assez rapidement.

Si vous êtes intéressé par cette implémentation, jetez un œil à mon
TDDing dans une séquence de Fibonacci en article
C # .
Le projet DangerousAssumptions est une application console qui affiche les résultats de FibonacciReader (à partir du fichier
Program.cs ):

Et voici la conclusion:
 Interface mise à jour
Interface mise à jourAlors maintenant, nous avons le code de travail. Mais, tôt ou tard, nous devrons peut-être obtenir un élément distinct d'IReader, et non la collection entière à la fois. Puisque nous utilisons un type générique avec l'interface, et pourtant nous n'avons pas la propriété «natural ID» dans l'objet, nous allons étendre l'élément situé à un index spécifique.
Voici notre interface à laquelle la méthode
GetItemAt est
GetItemAt (à partir de la version finale du fichier
IReader.cs ):

GetItemAt suppose ici une implémentation par défaut. À première vue - pas si mal. Il utilise un membre d'interface existant (
GetItems ), par conséquent, aucune hypothèse "externe" n'est faite ici. Avec les résultats, il utilise la méthode LINQ. Je suis un grand fan de LINQ, et ce code, à mon avis, est construit de manière raisonnable.
Différences de performancesÉtant donné que l'implémentation par défaut appelle
GetItems , elle nécessite que la collection entière soit renvoyée avant qu'un élément spécifique ne soit sélectionné.
Dans le cas de
FibonacciReader cela implique que toutes les valeurs seront générées. Dans un formulaire mis à jour, le fichier
Program.cs contiendra le code suivant:

Nous appelons donc
GetItemAt . Voici la conclusion:

Si nous mettons un point de contrôle à l'intérieur du fichier FibonacciSequence.cs, nous verrons que la séquence entière est générée pour cela.
Après avoir démarré le programme, nous tomberons sur ce point de contrôle deux fois: d'abord lors de l'appel à
GetItems , puis lors de l'appel à
GetItemAt .
Hypothèse nuisible aux performancesLe problème le plus grave de cette méthode est qu'elle nécessite de récupérer l'intégralité de la collection d'éléments. Si cet
IReader va le retirer de la base de données, alors beaucoup d'éléments devront en être retirés, puis un seul d'entre eux sera sélectionné. Il serait préférable que cette sélection finale soit traitée dans une base de données.
En travaillant avec notre
FibonacciReader , nous calculons chaque nouvel élément. Ainsi, la liste entière doit être entièrement calculée pour obtenir un seul élément dont nous avons besoin. Le calcul de la séquence de Fibonacci est une opération qui ne charge pas trop le processeur, mais que faire si nous traitons quelque chose de plus compliqué, par exemple, nous calculerons des nombres premiers?
Vous pourriez dire: «Eh bien, nous avons une méthode
GetItems qui renvoie tout. Si cela fonctionne trop longtemps, alors il ne devrait probablement pas être là. Et ceci est une déclaration honnête.
Cependant, le code appelant n'en sait rien. Si j'appelle
GetItems , je sais que (probablement) mes informations devront passer par le réseau, et ce processus prendra beaucoup de temps. Si je demande un seul article, pourquoi devrais-je m'attendre à de tels frais?
Optimisation des performances spécifiquesDans le cas de
FibonacciReader nous pouvons ajouter notre propre implémentation pour améliorer considérablement les performances (dans la version finale du fichier
FibonacciReader.cs ):

La méthode
GetItemAt remplace l'implémentation par défaut fournie dans l'interface.
Ici, j'utilise la même méthode LINQ
ElementAt que dans l'implémentation par défaut. Cependant, je n'utilise pas cette méthode avec la collection en lecture seule que GetItems renvoie, mais avec FibonacciSequence, qui est
IEnumerable .
Puisque
FibonacciSequence est
IEnumerable , l'appel à
ElementAt terminera dès que le programme atteindra l'élément que nous avons sélectionné. Ainsi, nous ne générerons pas la collection entière, mais uniquement les éléments situés jusqu'à la position spécifiée dans l'index.
Pour essayer cela, laissez le point de contrôle que nous avons fait ci-dessus dans l'application et exécutez à nouveau l'application. Cette fois, nous tombons sur un point d'arrêt une seule fois (lors de l'appel à
GetItems ). Lorsque vous appelez
GetItemAt cela ne se produira pas.
Un exemple un peu artificielCet exemple est un peu tiré par les cheveux, car, en règle générale, vous n'avez pas à sélectionner les éléments de l'ensemble de données par index. Cependant, vous pouvez imaginer quelque chose de similaire qui pourrait se produire si nous travaillions avec la propriété d'identification naturelle.
Si nous avons extrait des éléments par ID, et non par index, nous aurions pu rencontrer les mêmes problèmes de performances avec l'implémentation par défaut. L'implémentation par défaut nécessite le retour de tous les éléments, après quoi un seul est sélectionné parmi eux. Si vous autorisez la base de données ou un autre «lecteur» à extraire un élément spécifique par son ID, une telle opération serait beaucoup plus efficace.
Pensez à vos hypothèsesLes hypothèses sont indispensables. Si nous essayions de prendre en compte dans le code tous les cas d'utilisation possibles de nos bibliothèques, alors aucune tâche ne serait jamais terminée. Mais vous devez toujours examiner attentivement les hypothèses du code.
Cela ne signifie pas que l'implémentation
GetElementAt est nécessairement mauvaise. Oui, il peut y avoir des problèmes de performances. Cependant, si les ensembles de données sont petits ou que les éléments calculés sont «bon marché», l'implémentation par défaut peut être un compromis raisonnable.
Néanmoins, je n'accueille pas les modifications de l'interface après qu'elle ait déjà des implémenteurs. Mais je comprends qu'il existe également de tels scénarios dans lesquels des options alternatives sont préférées. La programmation est la solution des problèmes, et lors de la résolution des problèmes, il est nécessaire de peser les avantages et les inconvénients inhérents à chaque outil et approche que nous utilisons.
L'implémentation par défaut peut potentiellement endommager les implémenteurs d'interface (et éventuellement le code qui invoquera ces implémentations). Par conséquent, vous devez faire particulièrement attention aux hypothèses liées aux implémentations par défaut.
Bonne chance dans votre travail!