
L'infrastructure Web moderne se compose de nombreux composants à des fins diverses, évidents et peu interconnectés. Cela devient particulièrement évident lors de l'exploitation d'applications qui utilisent différentes piles de logiciels, ce qui, avec l'avènement des microservices, a commencé à se produire littéralement à chaque étape. Des facteurs externes (API tierces, services, etc.) s'ajoutent au «plaisir» général, ce qui complique une image déjà difficile.
En général, même si ces applications seront unies par des idées et des solutions architecturales communes, pour éliminer les problèmes inhabituels, elles doivent souvent se frayer un chemin dans les prochains espaces sauvages inconnus. Que de tels problèmes surviennent n'est qu'une question de temps. Ce sont les exemples de notre dernière pratique auxquels cet article est consacré. Distribution: Golang, Sentry, RabbitMQ, nginx, PostgreSQL et autres.
Histoire n ° 1. Golang et HTTP / 2
L'exécution d'un benchmark qui exécute de nombreuses requêtes HTTP vers une application Web a conduit à des résultats inattendus. Une simple application Go dans le processus de référence va à une autre application Go située derrière l'entrée / openresty. Lorsque HTTP / 2 est activé, nous obtenons des erreurs avec le code 400 pour certaines demandes. Pour comprendre la raison de ce comportement, nous avons supprimé l'application Go à l'extrémité de la chaîne et créé un emplacement simple dans Ingress, qui renvoie toujours 200. Le comportement n'a pas changé!
Il a ensuite été décidé de reproduire le script en dehors de l'environnement Kubernetes - sur un autre matériel. Le résultat a été un Makefile, à l'aide duquel deux conteneurs sont lancés: dans l'un - les benchmarks qui vont à nginx, dans l'autre - dans Apache. Les deux écoutent HTTP / 2 avec un certificat auto-signé. Le temps de fonctionnement final voir dans
ce référentiel .
Exécutez les benchmarks avec
concurrency=200 :
1.1. Nginx:
Completed 0 requests Completed 1000 requests Completed 2000 requests Completed 3000 requests Completed 4000 requests Completed 5000 requests Completed 6000 requests Completed 7000 requests Completed 8000 requests Completed 9000 requests ----- Bench results begin ----- Requests per second: 10336.09 Failed requests: 1623 ----- Bench results end -----
1.2. Apache:
… ----- Bench results begin ----- Requests per second: 11427.60 Failed requests: 0 ----- Bench results end -----
Nous supposons que le point ici est une implémentation moins stricte de HTTP / 2 dans Apache.
Essayons avec
concurrency=1000 :
2.1. Nginx:
… ----- Bench results begin ----- Requests per second: 11274.92 Failed requests: 4205 ----- Bench results end -----
2.2. Apache:
… ----- Bench results begin ----- Requests per second: 11211.48 Failed requests: 5 ----- Bench results end -----
En même temps, on constate que les résultats
ne sont
pas reproduits à chaque fois : certains lancements passent sans problème.
Une recherche de problèmes sur le github du projet Golang a conduit à
# 25009 et
# 32441 . Grâce à eux, nous sommes passés au
PR 903 : désactiver HTTP / 2 dans Go par défaut!
L'interprétation des résultats de référence sans plonger profondément dans l'architecture des serveurs Web ci-dessus est assez difficile. Dans un cas spécifique, il suffisait de désactiver HTTP / 2 pour le service spécifié.
Histoire n ° 2. Vieux symfony et sentinelle
Dans l'un des projets, une très ancienne version du framework PHP symfony (v2.3) fonctionne toujours. Un ancien client Raven et une classe auto-écrite en PHP lui sont attachés «dans le kit», ce qui complique un peu le débogage.
Après le transfert de l'un des services de Kubernetes à Sentry, utilisé pour suivre les erreurs dans l'application de ce projet, les événements ont soudainement cessé de se produire. Pour reproduire ce comportement, nous avons utilisé des exemples du site Web Sentry, en prenant deux options et en copiant le DSN à partir des paramètres Sentry. Visuellement, tout fonctionnait: des messages d'erreur (prétendument) étaient envoyés les uns après les autres.
Option de vérification JavaScript:
<!DOCTYPE html> <html> <body> <script src="https://browser.sentry-cdn.com/5.6.3/bundle.min.js" integrity="sha384-/Cqa/8kaWn7emdqIBLk3AkFMAHBk0LObErtMhO+hr52CntkaurEnihPmqYj3uJho" crossorigin="anonymous"> </script> <h2>JavaScript in Body</h2> <p id="demo">A Paragraph.</p> <button type="button" onclick="myFunction()">Try it</button> <script> Sentry.init({ dsn: 'http://33dddd76e9f0c4ddcdb51@sentry.kube-dev.test//12' }); try { throw new Error('Caught'); } catch (err) { Sentry.captureException(err); } </script> </body> </html>
De même en Python:
from sentry_sdk import init, capture_message init("http://33dddd76e9f0c4ddcdb51@sentry.kube-dev.test//12") capture_message("Hello World")
Cependant, ils ne sont pas entrés dans Sentry. Lors de l'envoi d'un message, l'illusion est créée que le message a été envoyé, car les clients génèrent immédiatement un hachage pour le problème.
En conséquence, le problème a été résolu très simplement: l'envoi d'événements est allé à HTTP et le service Sentry n'a écouté que HTTPS. Une redirection de HTTP vers HTTPS a été fournie, mais l'ancien client (le code du côté symfony) n'a pas pu suivre les redirections, ce qui n'est pas prévu par défaut de nos jours.
Histoire n ° 3. RabbitMQ et proxy tiers
Dans un projet, le cloud Evotor est utilisé pour connecter les caisses enregistreuses. En fait, cela fonctionne comme un proxy: les requêtes POST d'Evotor vont directement à RabbitMQ - via le
plugin STOMP implémenté via les connexions WebSocket.
L'un des développeurs a fait des demandes de test à l'aide de Postman et a reçu les réponses attendues de
200 OK , cependant, les demandes via le cloud ont conduit à une
405 Method Not Allowed inattendue
405 Method Not Allowed .
200 OK source: kubernetes namespace: kube-nginx-ingress host: kube-node-2 pod_name: nginx-2bpt7 container_name: nginx stream: stdout app: nginx controller-revision-hash: 5bdbfd564 pod-template-generation: 25 time: 2019-09-10T09:42:50+00:00 request_id: 1271dba228f0943ab2df0196ff0d7f67 user: client address: 100.200.300.400 protocol: HTTP/1.1 scheme: http method: POST host: rmq-review.kube-dev.client.domain path: /api/queues/vhost/queue.gen.eeeeffff111:1.onlinecassa:55556666/get request_query: referrer: user_agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 content_kind: cacheable namespace: review ingress: stomp-ws service: rabbitmq service_port: stats vhost: rmq-review.kube-dev.client.domain location: / nginx_upstream_addr: 10.127.1.1:15672 nginx_upstream_bytes_received: 2538 nginx_upstream_response_time: 0.008 nginx_upstream_status: 200 bytes_received: 757 bytes_sent: 1254 request_time: 0 status: 200 upstream_response_time: 0 upstream_retries: 0
405 Méthode non autorisée source: kubernetes namespace: kube-nginx-ingress host: kube-node-1 pod_name: nginx-4xx6h container_name: nginx stream: stdout app: nginx controller-revision-hash: 5bdbfd564 pod-template-generation: 25 time: 2019-09-10T09:46:26+00:00 request_id: b8dd789604864c95b4af499ed6805630 user: client address: 200.100.300.400 protocol: HTTP/1.1 scheme: http method: POST host: rmq-review.kube-dev.client.domain path: /api/queues/vhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get request_query: referrer: user_agent: ru.evotor.proxy/37 content_kind: cache-headers-not-present namespace: review ingress: stomp-ws service: rabbitmq service_port: stats vhost: rmq-review.kube-dev.client.domain location: / nginx_upstream_addr: 10.127.1.1:15672 nginx_upstream_bytes_received: 134 nginx_upstream_response_time: 0.004 nginx_upstream_status: 405 bytes_received: 878 bytes_sent: 137 request_time: 0 status: 405 upstream_response_time: 0 upstream_retries: 0
Demande Tcpdump d'Evotor 200.100.300.400.21519 > 100.200.400.300: Flags [P.], cksum 0x8e29 (correct), seq 1:879, ack 1, win 221, options [nop,nop,TS val 2313007107 ecr 79097074], length 878: HTTP, length: 878 POST /api/queues//vhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get HTTP/1.1 device-model: ST-5 device-os: android Accept-Encoding: gzip content-type: application/json; charset=utf-8 connection: close accept: application/json x-original-forwarded-for: 10.11.12.13 originhost: rmq-review.kube-dev.client.domain x-original-uri: /api/v2/apps/e114-aaef-bbbb-beee-abadada44ae/requests x-scheme: https accept-encoding: gzip user-agent: ru.evotor.proxy/37 Authorization: Basic X-Evotor-Store-Uuid: 20180417-73DC-40C9-80B7-00E990B77D2D X-Evotor-Device-Uuid: 20190909-A47B-40EA-806A-F7BC33833270 X-Evotor-User-Id: 01-000000000147888 Content-Length: 58 Host: rmq-review.kube-dev.client.domain {"count":1,"encoding":"auto","ackmode":"ack_requeue_true"}[!http] 12:53:30.095385 IP (tos 0x0, ttl 64, id 5512, offset 0, flags [DF], proto TCP (6), length 52) 100.200.400.300:80 > 200.100.300.400.21519: Flags [.], cksum 0xfa81 (incorrect -> 0x3c87), seq 1, ack 879, win 60, options [nop,nop,TS val 79097122 ecr 2313007107], length 0 12:53:30.096876 IP (tos 0x0, ttl 64, id 5513, offset 0, flags [DF], proto TCP (6), length 189) 100.200.400.300:80 > 200.100.300.400.21519: Flags [P.], cksum 0xfb0a (incorrect -> 0x03b9), seq 1:138, ack 879, win 60, options [nop,nop,TS val 79097123 ecr 2313007107], length 137: HTTP, length: 137 HTTP/1.1 405 Method Not Allowed Date: Tue, 10 Sep 2019 10:53:30 GMT Content-Length: 0 Connection: close allow: HEAD, GET, OPTIONS
Tcpdump demande faite par curl 777.10.74.11.61211 > 100.200.400.300:80: Flags [P.], cksum 0x32a8 (correct), seq 1:397, ack 1, win 2052, options [nop,nop,TS val 734012594 ecr 4012360530], length 396: HTTP, length: 396 POST /api/queues/%2Fvhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get HTTP/1.1 Host: rmq-review.kube-dev.client.domain User-Agent: curl/7.54.0 Authorization: Basic = Content-Type: application/json Accept: application/json Content-Length: 58 {"count":1,"ackmode":"ack_requeue_true","encoding":"auto"}[!http] 12:40:11.001442 IP (tos 0x0, ttl 64, id 50844, offset 0, flags [DF], proto TCP (6), length 52) 100.200.400.300:80 > 777.10.74.11.61211: Flags [.], cksum 0x2d01 (incorrect -> 0xfa25), seq 1, ack 397, win 59, options [nop,nop,TS val 4012360590 ecr 734012594], length 0 12:40:11.017065 IP (tos 0x0, ttl 64, id 50845, offset 0, flags [DF], proto TCP (6), length 2621) 100.200.400.300:80 > 777.10.74.11.61211: Flags [P.], cksum 0x370a (incorrect -> 0x6872), seq 1:2570, ack 397, win 59, options [nop,nop,TS val 4012360605 ecr 734012594], length 2569: HTTP, length: 2569 HTTP/1.1 200 OK Date: Tue, 10 Sep 2019 10:40:11 GMT Content-Type: application/json Content-Length: 2348 Connection: keep-alive Vary: Accept-Encoding cache-control: no-cache vary: accept, accept-encoding, origin
L'œil exercé d'un ingénieur voit immédiatement la différence:
- curl:
POST /api/queues/%2Fclient… - Evotor:
POST /api/queues//client…
Le fait est que dans un cas, un
//vhost incompréhensible (pour RabbitMQ)
//vhost , et dans l'autre -
%2Fvhost , ce qui est le comportement attendu lorsque:
# rabbitmqctl list_vhosts Listing vhosts ... /vhost
Dans le
numéro du projet RabbitMQ sur ce sujet, le développeur explique:
Nous ne remplacerons pas% -encoding. C'est un moyen standard de codage de chemin URL et cela depuis des siècles. Supposer que% -encoding dans les outils HTTP disparaîtra en raison même du cadre le plus populaire en supposant que ces chemins URL sont "malveillants" est à courte vue et naïf. Le nom d'hôte virtuel par défaut peut être modifié en n'importe quelle valeur (telle que celle qui n'utilise pas de barres obliques ou tout autre caractère nécessitant un codage%) et au moins avec la version Pivotal BOSH de RabbitMQ, l'hôte virtuel par défaut est supprimé de toute façon au moment du déploiement .
Le problème a été résolu sans implication supplémentaire de nos ingénieurs (côté Evotor après les avoir contactés).
Histoire n ° 4. Gène dans PostgreSQL
PostgreSQL a un index très utile, qui est souvent oublié. Cette histoire a commencé par des plaintes concernant les freins de l'application. Dans un
article récent, nous avons déjà donné un exemple de flux de travail approximatif lors de l'analyse de telles situations. Et ici, notre APM -
Atatus - a montré l'image suivante:

À 10 heures du matin, le temps que l'application passe à travailler avec la base de données augmente. Comme prévu, la raison réside dans les réponses lentes du SGBD. Pour nous, analyser les requêtes, identifier les zones problématiques et «suspendre» les index est une routine compréhensible. L'
okmètre que nous utilisons y contribue
beaucoup : il existe à la fois des panneaux standard pour surveiller l'état des serveurs et la possibilité de créer
rapidement le nôtre - avec la sortie de mesures problématiques:

Les graphiques de charge du processeur indiquent que l'une des bases de données est chargée à 100%. Pourquoi? Les nouveaux panneaux PostgreSQL vous demanderont:

La cause des problèmes est immédiatement apparente - le principal consommateur du CPU:
SELECT u.* FROM users u WHERE u.id = ? & u.field_1 = ? AND u.field_2 LIKE '%somestring%' ORDER BY u.id DESC LIMIT ?
Compte tenu du plan de travail de la requête problème, nous avons constaté que le filtrage par champs indexés de la table donne une sélection trop grande: la base de données reçoit plus de 70 000 lignes par
id et
field_1 , puis recherche une sous-chaîne parmi elles. Il s'avère que
LIKE sur une sous-chaîne itère sur une grande quantité de données texte, ce qui conduit à un sérieux ralentissement de l'exécution des requêtes et à une augmentation de la charge du processeur.
Ici, vous pouvez à juste titre remarquer qu'un problème architectural n'est pas exclu (une correction de la logique d'application ou même un moteur de texte intégral est requis ...), mais il n'y a pas de temps pour le retravailler, mais il aurait dû fonctionner rapidement il y a 15 minutes. En même temps, le mot recherché est en fait un identifiant (et pourquoi pas dans un champ séparé? ..), qui produit des unités de lignes. En fait, si nous pouvions composer un index sur ce champ de texte, tous les autres deviendraient inutiles.La dernière solution actuelle consiste à ajouter un index GIN pour
field_2 . C’est le héros du jour - ce même «génie». En bref, GIN est une sorte d'index qui fonctionne très bien dans la recherche en texte intégral, l'accélérant qualitativement. Vous pouvez en savoir plus à ce sujet, par exemple, dans
ce merveilleux matériel .

Comme vous pouvez le voir, cette opération simple a permis de supprimer la charge supplémentaire, et avec elle - et d'économiser de l'argent pour le client.
Histoire n ° 5. Mise en cache S3 dans Nginx
Le stockage cloud compatible S3 figure depuis longtemps sur la liste des technologies utilisées par de nombreux projets. Si vous avez besoin d'un stockage d'images fiable pour votre site ou pour des données de réseau neuronal, Amazon S3 est un excellent choix. La fiabilité du stockage et la haute disponibilité des données (et l'absence de la nécessité de «clôturer le jardin») sont captivantes.
Cependant, parfois pour économiser de l'argent - car généralement le paiement pour S3 va pour les demandes et pour le trafic - une bonne solution consiste à installer un serveur proxy de mise en cache devant le stockage. Cette méthode réduira les coûts en ce qui concerne, par exemple, les avatars des utilisateurs, qui sont nombreux sur chaque page.
Il semblerait que c'est plus facile que de prendre nginx et de configurer des proxys avec mise en cache, revalidation, mise à jour en arrière-plan et autres blackjack? Cependant, comme ailleurs, il y a quelques nuances ...
La configuration approximative d'un tel proxy avec mise en cache ressemblait à ceci:
proxy_cache_key $uri; proxy_cache_methods GET HEAD; proxy_cache_lock on; proxy_cache_revalidate on; proxy_cache_background_update on; proxy_cache_use_stale updating error timeout invalid_header http_500 http_502 http_503 http_504; proxy_cache_valid 200 1h; location ~ ^/(?<bucket>avatars|images)/(?<filename>.+)$ { set $upstream $bucket.s3.amazonaws.com; proxy_pass http://$upstream/$filename; proxy_set_header Host $upstream; proxy_cache aws; proxy_cache_valid 200 1h; proxy_cache_valid 404 60s; }
Et en général, cela a fonctionné: les images étaient affichées, tout allait bien avec le cache ... cependant, des problèmes avec les clients AWS S3 sont apparus. En particulier, le client de
aws-sdk-php a cessé de fonctionner. L'analyse des journaux nginx a montré que le code en amont renvoyait 403 pour les requêtes HEAD, et la réponse contenait une erreur spécifique:
SignatureDoesNotMatch . Lorsque nous avons vu que nginx fait une demande GET en amont, tout s'est mis en place.
Le fait est que le client S3 signe chaque demande et que le serveur vérifie cette signature. Dans le cas d'un proxy simple, tout fonctionne bien: la requête parvient au serveur sans changement. Cependant, lorsque la mise en cache est activée, nginx commence à optimiser le travail avec le backend et remplace les requêtes HEAD par GET. La logique est simple: il est préférable de récupérer et d'enregistrer l'intégralité de l'objet, puis toutes les requêtes HEAD du cache également. Cependant, dans notre cas, la demande ne peut pas être modifiée - elle est signée.
Il existe essentiellement deux solutions:
- Ne conduisez pas les clients S3 via des proxys;
- s'il est "nécessaire", désactivez l'option
proxy_cache_convert_head et ajoutez $request_method à la clé de mise en cache. Dans ce cas, nginx envoie les demandes HEAD «en l'état» et met en cache les réponses séparément.
Histoire n ° 6. DDoS et contenu utilisateur Google
Le dimanche soir n'a laissé présager de problèmes que - du coup! - La file d'attente d'invalidation du cache sur les serveurs de périphérie n'a pas augmenté, ce qui donne du trafic aux utilisateurs réels. C'est un symptôme très étrange: après tout, le cache est implémenté en mémoire et n'est pas lié aux disques durs. Vider le cache dans l'architecture utilisée est une opération bon marché, donc cette erreur ne peut apparaître que dans le cas d'une charge vraiment élevée. Cela a été confirmé par le fait que les mêmes serveurs ont commencé à signaler l'apparition de 500 erreurs
(pointes de ligne rouges dans le graphique ci-dessous) .

Une telle forte augmentation a entraîné des dépassements de CPU:
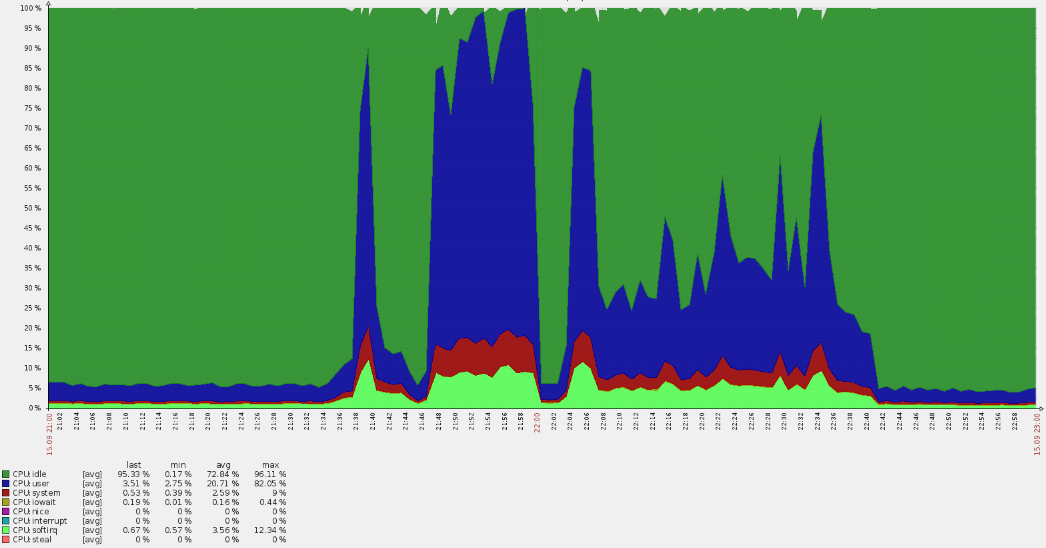
Une analyse rapide a montré que les demandes ne provenaient pas des domaines principaux, mais à partir des journaux, il est devenu clair qu'elles étaient en vhost par défaut. En cours de route, il s'est avéré que de nombreux utilisateurs américains sont venus à la ressource russe. De telles circonstances soulèvent toujours immédiatement des questions.
Après avoir collecté des données à partir des journaux nginx, nous avons révélé que nous avons affaire à un certain botnet:
35.222.30.127 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?ITPDH=XHJI" HTTP/1.1 301 178 "http://example.ru/ORQHYGJES" "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?ITPDH=XHJI" "redirect=http://www.example.ru/?ITPDH=XHJI" ancient=1 cipher=- "LM=-;EXP=-;CC=-" 107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?REVQSD=VQPYFLAJZ" HTTP/1.1 301 178 "http://www.usatoday.com/search/results?q=MLAJSBZAK" "Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0; en-US)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?REVQSD=VQPYFLAJZ" "redirect=http://www.example.ru/?REVQSD=VQPYFLAJZ" ancient=1 cipher=- "LM=-;EXP=-;CC=-" 107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?MPYGEXB=OMJ" HTTP/1.1 301 178 "http://engadget.search.aol.com/search?q=MIWTYEDX" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?MPYGEXB=OMJ" "redirect=http://www.example.ru/?MPYGEXB=OMJ" ancient=1 cipher=- "LM=-;EXP=-;CC=-"
Un modèle compréhensible est tracé dans les journaux:
- véritable user-agent;
- une requête à l'URL racine avec un argument GET aléatoire pour éviter d'entrer dans le cache;
- référent indique que la demande provient d'un moteur de recherche.
Nous collectons les adresses et vérifions leur affiliation - elles appartiennent toutes à
googleusercontent.com , avec deux sous-réseaux (107.178.192.0/18 et 34.64.0.0/10). Ces sous-réseaux contiennent des machines virtuelles GCE et divers services, tels que la traduction de pages.
Heureusement, l'attaque n'a pas duré si longtemps (environ une heure) et a progressivement diminué. Il semble que les algorithmes de protection à l'intérieur de Google aient fonctionné, donc le problème a été résolu "par lui-même".
Cette attaque n'a pas été destructrice, mais a soulevé des questions utiles pour l'avenir:
- Pourquoi les anti-ddos n'ont-ils pas fonctionné? Un service externe est utilisé, auquel nous avons envoyé une demande correspondante. Cependant, il y avait beaucoup d'adresses ...
- Comment vous en protéger à l'avenir? Dans notre cas, même des options de fermeture d'accès sur une base géographique sont possibles.
PS
Lisez aussi dans notre blog: