
Bonjour, je veux partager avec vous mon expérience dans la configuration et l'utilisation du service AWS EKS (Elastic Kubernetes Service) pour les conteneurs Windows, ou plutôt sur l'impossibilité de l'utiliser, et le bogue trouvé dans le conteneur système AWS, pour ceux qui sont intéressés par ce service pour les conteneurs Windows, veuillez sous chat.
Je sais que les conteneurs Windows ne sont pas un sujet populaire, et peu de gens les utilisent, mais ont néanmoins décidé d'écrire cet article, car il y avait quelques articles sur Kubernetes et Windows sur Habré et il y a encore de telles personnes.
Commencer
Tout a commencé avec le fait que les services de notre entreprise, il a été décidé de migrer vers kubernetes, c'est 70% windows et 30% linux. Pour cela, le service cloud AWS EKS a été considéré comme l'une des options possibles. Jusqu'au 8 octobre 2019, AWS EKS Windows était dans l'aperçu public, j'ai commencé avec, la version de kubernetes utilisait l'ancien 1.11, mais j'ai décidé de le vérifier quand même et de voir à quel stade ce service cloud fonctionne, s'il s'avérait fonctionner du tout, ce n'était pas le cas un bug avec l'ajout de la suppression des foyers, tandis que les anciens ont cessé de répondre via l'IP interne du même sous-réseau que le nœud de travail Windows.
Par conséquent, il a été décidé d'abandonner l'utilisation d'AWS EKS au profit de leur propre cluster sur kubernetes sur le même EC2, seuls tous les équilibrages et HA devraient être décrits par moi-même via CloudFormation.
La prise en charge des conteneurs Windows Amazon EKS est désormais généralement disponible
par Martin Beeby | le 08 OCT 2019Je n'ai pas eu le temps d'ajouter un modèle à CloudFormation pour mon propre cluster, car j'ai vu cette nouvelle
prise en charge des conteneurs Windows Amazon EKS maintenant généralement disponibleBien sûr, j'ai reporté tous mes développements et j'ai commencé à étudier ce qu'ils ont fait pour GA et comment tout a changé par rapport à Public Preview. Oui, les boursiers AWS ont mis à jour les images du nœud de travail Windows vers la version 1.14 ainsi que la version de cluster 1.14 dans EKS maintenant avec la prise en charge des nœuds Windows. Ils ont fermé le projet Public Preview sur le
github et ont dit maintenant utiliser la documentation officielle ici:
EKS Windows SupportIntégration d'un cluster EKS dans le VPC et les sous-réseaux actuels
Dans toutes les sources, dans le lien au-dessus de l'annonce et également dans la documentation, il a été proposé de déployer le cluster via l'utilitaire propriétaire eksctl ou via CloudFormation + kubectl après, en utilisant uniquement des sous-réseaux publics dans Amazon, ainsi que la création d'un VPC distinct pour un nouveau cluster.
Cette option ne convient pas à beaucoup, tout d'abord, un VPC distinct est le coût supplémentaire de son trafic coût + peering vers votre VPC actuel. Que faire pour ceux qui ont déjà une infrastructure prête à l'emploi dans AWS avec leurs multiples comptes AWS, VPC, sous-réseaux, tables de routage, passerelle de transit, etc.? Bien sûr, je ne veux pas le décomposer ou tout refaire, et je dois intégrer le nouveau cluster EKS dans l'infrastructure réseau actuelle en utilisant le VPC existant et, pour diviser le maximum, créer de nouveaux sous-réseaux pour le cluster.
Dans mon cas, ce chemin a été choisi, j'ai utilisé le VPC existant, ajouté seulement 2 sous-réseaux publics et 2 sous-réseaux privés pour un nouveau cluster, bien sûr, toutes les règles ont été prises en compte selon la documentation
Créer votre VPC de cluster Amazon EKS .
Il y avait également une condition pour qu'aucun nœud de travail dans les sous-réseaux publics utilisant EIP.eksctl vs CloudFormation
Je vais faire une réservation tout de suite que j'ai essayé les deux méthodes de déploiement de cluster, dans les deux cas, l'image était la même.
Je vais montrer un exemple uniquement avec l'utilisation de eksctl car le code est plus court ici. L'utilisation du cluster eksctl se déploie en 3 étapes:
1.Créez le cluster lui-même + le nœud de travail Linux sur lequel les conteneurs système et le malheureux contrôleur vpc seront placés plus tard.
eksctl create cluster \ --name yyy \ --region www \ --version 1.14 \ --vpc-private-subnets=subnet-xxxxx,subnet-xxxxx \ --vpc-public-subnets=subnet-xxxxx,subnet-xxxxx \ --asg-access \ --nodegroup-name linux-workers \ --node-type t3.small \ --node-volume-size 20 \ --ssh-public-key wwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami auto \ --node-private-networking
Afin de déployer sur un VPC existant, spécifiez simplement l'ID de vos sous-réseaux, et eksctl déterminera le VPC lui-même.
Pour que votre nœud de travail se déploie uniquement sur le sous-réseau privé, vous devez spécifier --node-private-networking pour le groupe de nœuds.
2. Installez vpc-controller dans notre cluster, qui traitera ensuite nos nœuds de travail en comptant le nombre d'adresses IP libres, ainsi que le nombre d'ENI sur l'instance, en les ajoutant et en les supprimant.
eksctl utils install-vpc-controllers --name yyy --approve
3.Après le démarrage réussi de vos conteneurs système sur votre nœud de travail Linux, y compris vpc-controller, il ne reste plus qu'à créer un autre groupe de nœuds avec des travailleurs Windows.
eksctl create nodegroup \ --region www \ --cluster yyy \ --version 1.14 \ --name windows-workers \ --node-type t3.small \ --ssh-public-key wwwwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami-family WindowsServer2019CoreContainer \ --node-ami ami-0573336fc96252d05 \ --node-private-networking
Une fois que votre nœud s'est correctement connecté à votre cluster et que tout semble bien se passer, il est à l'état Prêt, mais non.
Erreur dans vpc-controller
Si nous essayons d'exécuter des pods sur le nœud de travail Windows, nous obtenons une erreur:
NetworkPlugin cni failed to teardown pod "windows-server-iis-7dcfc7c79b-4z4v7_default" network: failed to parse Kubernetes args: pod does not have label vpc.amazonaws.com/PrivateIPv4Address]
En regardant plus loin, nous voyons que notre instance AWS ressemble à ceci:

Et ça devrait être comme ça:

De cela, il est clair que vpc-controller n'a pas fonctionné pour une raison quelconque et n'a pas pu ajouter de nouvelles adresses IP à l'instance afin que les pods puissent les utiliser.
Nous grimpons pour regarder les journaux de pod vpc-controller et voici ce que nous voyons:
kubectl log <vpc-controller-deployment> -n kube-system I1011 06:32:03.910140 1 watcher.go:178] Node watcher processing node ip-10-xxx.ap-xxx.compute.internal. I1011 06:32:03.910162 1 manager.go:109] Node manager adding node ip-10-xxx.ap-xxx.compute.internal with instanceID i-088xxxxx. I1011 06:32:03.915238 1 watcher.go:238] Node watcher processing update on node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.200423 1 manager.go:126] Node manager failed to get resource vpc.amazonaws.com/CIDRBlock pool on node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxxx E1011 06:32:08.201211 1 watcher.go:183] Node watcher failed to add node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxx I1011 06:32:08.201229 1 watcher.go:259] Node watcher adding key ip-10-xxx.ap-xxx.compute.internal (0): failed to find the route table for subnet subnet-0xxxx I1011 06:32:08.201302 1 manager.go:173] Node manager updating node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.201313 1 watcher.go:242] Node watcher failed to update node ip-10-xxx.ap-xxx.compute.internal: node manager: failed to find node ip-10-xxx.ap-xxx.compute.internal.
Les recherches sur Google n'ont abouti à rien, car apparemment personne n'avait encore détecté un tel bug, eh bien, ou publié un problème dessus, je devais d'abord penser aux options moi-même. La première chose qui m'est venue à l'esprit est que peut-être vpc-controller ne peut pas dégriser ip-10-xxx.ap-xxx.compute.internal et y arriver et donc les erreurs tombent.
Oui, en effet, nous utilisons des serveurs DNS personnalisés dans VPC et nous n'utilisons pas de serveurs Amazon en principe, donc même le transfert n'a pas été configuré sur ce domaine ap-xxx.compute.internal. J'ai vérifié cette option, et elle n'a donné aucun résultat, peut-être que le test n'était pas propre, et donc, en communiquant avec le support technique, j'ai succombé à leur idée.
Comme il n'y avait pas d'idées, tous les groupes de sécurité ont été créés par eksctl lui-même, donc il n'y avait aucun doute qu'ils fonctionnaient, les tables de routage étaient également correctes, nat, dns, il y avait aussi un accès Internet avec des nœuds de travail.
Dans le même temps, si vous déployez un nœud de travail sur un sous-réseau public sans utiliser --node-private-networking, ce nœud a été immédiatement mis à jour par vpc-controller et tout fonctionnait comme une horloge.
Il y avait deux options:
- Martelez et attendez que quelqu'un décrive ce bogue dans AWS et le corrige, puis vous pouvez utiliser AWS EKS Windows en toute sécurité, car il vient d'entrer dans GA (cela a pris 8 jours au moment de la rédaction), très probablement beaucoup suivront le même chemin que moi .
- Écrivez au support AWS et expliquez-leur l'essence du problème avec tout le tas de journaux de partout et prouvez-leur que leur service ne fonctionne pas lors de l'utilisation de leur VPC et de leurs sous-réseaux, ce n'est pas en vain que nous avons eu le support commercial, nous devons l'utiliser au moins une fois :-)
Communication avec les ingénieurs AWS
Ayant créé un ticket sur le portail, j'ai choisi par erreur de me répondre via le Web - e-mail ou centre de support, grâce à cette option, ils peuvent vous répondre après quelques jours, malgré le fait que mon ticket avait une gravité - Système altéré, ce qui impliquait une réponse dans un délai <12 heures, et puisque le plan de support aux entreprises a un support 24/7, j'espérais pour le mieux, mais il s'est avéré comme toujours.
Mon ticket a atterri dans Non assigné du vendredi au lundi, puis j'ai décidé de l'écrire à nouveau et j'ai choisi l'option de réponse Chat. Après une courte attente, Harshad Madhav m'a été nommé, puis ça a commencé ...
Nous avons débattu avec lui en ligne pendant 3 heures d'affilée, transférant des journaux, déployant le même cluster dans le laboratoire AWS pour émuler le problème, recréant le cluster de ma part, et ainsi de suite, la seule chose à laquelle nous sommes arrivés était que les journaux montraient que la résolution ne fonctionnait pas Les noms de domaine internes AWS comme je l'ai écrit ci-dessus, et Harshad Madhav m'a demandé de créer un transfert, soi-disant nous utilisons des DNS personnalisés et cela peut être un problème.
Transfert
ap-xxx.compute.internal -> 10.xx2 (VPC CIDRBlock) amazonaws.com -> 10.xx2 (VPC CIDRBlock)
Ce qui a été fait, la journée était finie. Harshad Madhav s'est désabonné de ce chèque et ça devrait marcher, mais non, la résolution n'a pas aidé.
Puis il y a eu une conversation avec 2 autres ingénieurs, l'un vient de tomber du chat, apparemment effrayé par un cas difficile, le second a passé ma journée à nouveau sur un cycle de débogage complet, envoyant des journaux, créant des clusters des deux côtés, au final il vient de bien le dire, ça marche pour moi, je suis ici documentation officielle Je fais tout étape par étape et vous et vous réussirez.
A laquelle je lui ai poliment demandé de partir, et d'en assigner un autre à mon ticket si vous ne savez pas où chercher le problème.
Finale
Le troisième jour, un nouvel ingénieur Arun B. m'a été nommé, et dès le début de la communication avec lui, il était immédiatement clair qu'il ne s'agissait pas de 3 ingénieurs précédents. Il a lu toute l'histoire et a immédiatement demandé de collecter les journaux avec son propre script sur ps1 qui se trouvait sur son github. Ensuite, toutes les itérations de création de clusters, de sortie des résultats des équipes, de collecte des journaux ont suivi à nouveau, mais Arun B. allait dans la bonne direction à en juger par les questions qui m'étaient posées.
Quand nous sommes arrivés à inclure -stderrthreshold = debug dans leur contrôleur vpc, et que s'est-il passé ensuite? cela ne fonctionne certainement pas) pod ne démarre tout simplement pas avec cette option, seul -stderrthreshold = info fonctionne.
C'est là que nous avons fini et Arun B. a dit qu'il essaierait de reproduire mes étapes pour obtenir la même erreur. Le lendemain, je reçois une réponse d'Arun B.Il n'a pas abandonné cette affaire, mais a pris le code de révision de leur contrôleur vpc et a trouvé le même endroit où il le fait et pourquoi ne fonctionne pas:
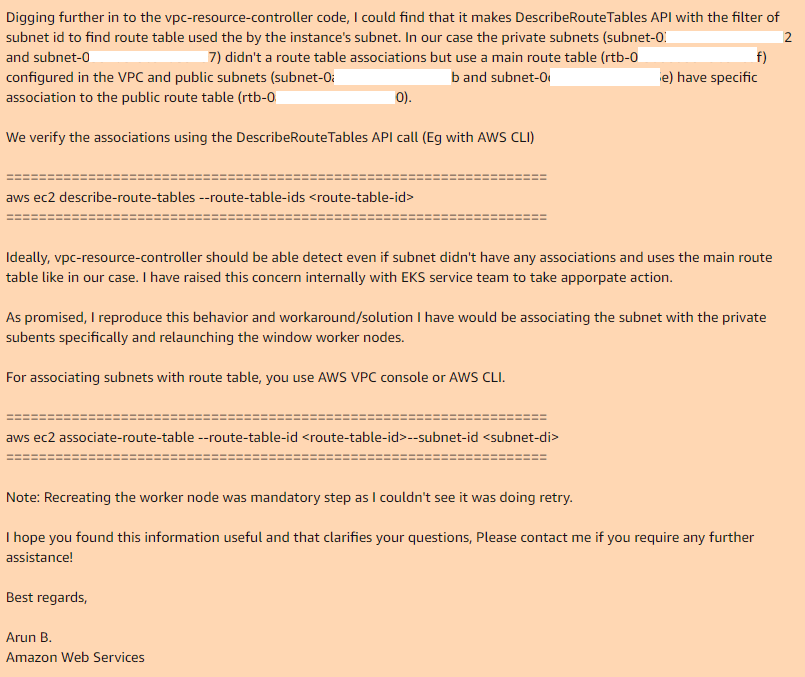
Ainsi, si vous utilisez la table de routage principale dans votre VPC, par défaut, il n'a pas d'association avec les sous-réseaux nécessaires, donc le contrôleur vpc nécessaire, dans le cas du sous-réseau public, il a une table de routage personnalisée qui a une association.
En ajoutant manuellement des associations pour la table de routage principale avec les sous-réseaux souhaités et en recréant le groupe de nœuds, tout fonctionne parfaitement.
J'espère que Arun B. signalera effectivement ce bogue aux développeurs EKS et nous verrons une nouvelle version de vpc-controller, et où tout fonctionnera hors de la boîte. Actuellement la dernière version: 602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/vpc-resource-controllerPoint.2.1
a ce problème.
Merci à tous ceux qui ont lu jusqu'au bout, testez tout ce que vous allez utiliser en production, avant l'implémentation.
Mise à jour: nouveau bogue n ° 2
Après avoir trouvé une solution au premier problème, nous avons continué à préparer ce service à nos besoins, et maintenant à la dernière étape, nous avons trouvé un autre bug incompatible avec la vie.
Problème:Déployez l'application sur Kubernetes, définissez votre déploiement, des répliques> 1 et voyez l'image suivante. Le nouveau pod démarre normalement et fonctionne, tandis que l'ancien pod perd son interface réseau. Oui, oui, l'ancien pod complètement sans réseau, bien qu'il continue de se bloquer dans l'état Running. Réduisez ou augmentez les répliques, supprimez les pods afin que vous ne fassiez pas toujours uniquement le pod que le dernier est entré dans l'état Running, tout le reste ne le fera pas. Quoi qu'il en soit, les pods ou les différents démarrent sur le même nœud.
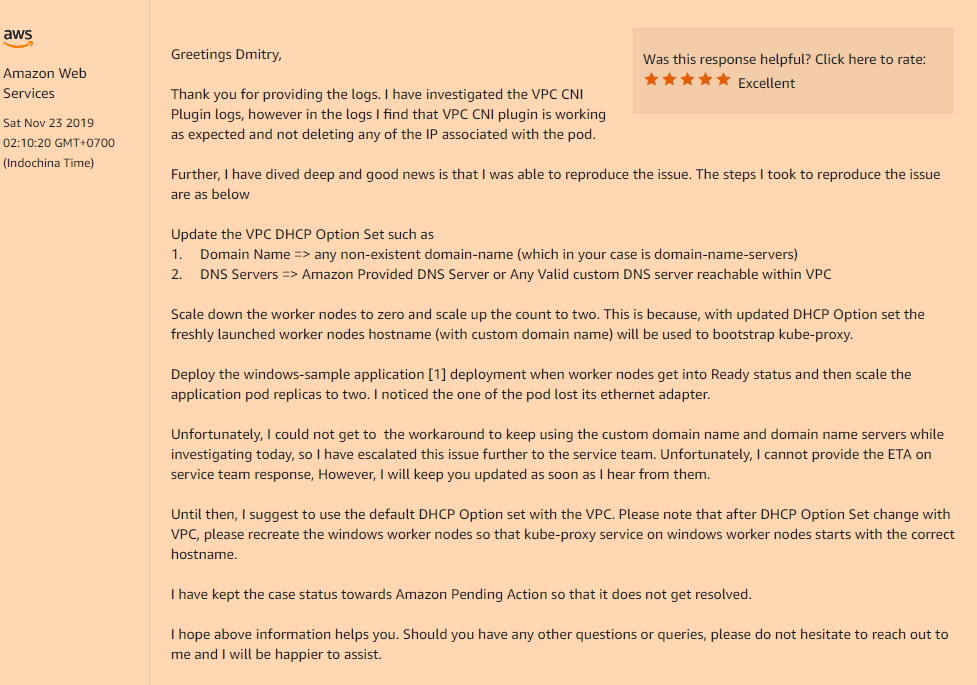
Solution:Oui, le problème s'est à nouveau avéré être dans la configuration personnalisée de notre VPC, à savoir si vous utilisez votre ensemble d'options DHCP qui indique la valeur personnalisée du champ de nom de domaine, ou est complètement vide (comme dans mon cas, j'ai changé uniquement les serveurs de nom de domaine, Je n'avais pas besoin du reste) vous obtiendrez un tel problème incompréhensible avec la disparition des interfaces réseau à l'intérieur de vos pods après le lancement.
Vous devez l'enregistrer dans votre ensemble d'options DHCP:
domain-name = <aws-region-name>.compute.internal;
Et après cela, il s'agit de réinstaller tous vos nœuds de travail afin que lors du bootstrap tous les composants enregistrent les paramètres corrects.
Voici les détails de la façon dont cette option de nom de domaine affecte vos nœuds de travail:
Cette fois, je leur ai demandé d'ajouter au moins de la documentation à AWS EKS pour Windows, ces «fonctionnalités» de leur service.