Nous sommes en train de préparer la prochaine version majeure de Tokio, un environnement d'exécution asynchrone pour Rust. Le 13 octobre, une
demande de pool avec un planificateur de tâches complètement réécrit a été émise pour la fusion dans une branche. Le résultat sera d'énormes améliorations de performances et une latence réduite. Certains tests ont enregistré une accélération décuplée! Comme d'habitude, les tests synthétiques ne reflètent pas les avantages réels dans la réalité. Par conséquent, nous avons également vérifié comment les modifications du planificateur affectaient les tâches réelles, telles que
Hyper et
Tonic (spoiler: le résultat est merveilleux).
En me préparant à travailler sur un nouveau planificateur, j'ai passé du temps à chercher des ressources thématiques. Hormis les implémentations réelles, rien de spécial n'a été trouvé. J'ai également constaté que le code source des implémentations existantes est difficile à parcourir. Pour résoudre ce problème, nous avons essayé d'écrire le sheduler Tokio aussi proprement que possible. J'espère que cet article détaillé sur la mise en œuvre du planificateur aidera ceux qui sont dans la même position et qui cherchent sans succès des informations sur ce sujet.
L'article commence par un examen de haut niveau de la conception, y compris des politiques de capture des emplois. Plongez ensuite dans les détails des optimisations spécifiques dans le nouveau planificateur Tokio.
Optimisations envisagées:
Comme vous pouvez le voir, le thème principal est la «réduction». Après tout, le code le plus rapide est son manque!
Nous parlerons également du
test du nouveau planificateur . Il est très difficile d'écrire le code parallèle correct sans verrou. Il vaut mieux travailler lentement, mais correctement, que rapidement, mais avec des problèmes, surtout si les bogues concernent la sécurité de la mémoire. Cependant, la meilleure option devrait fonctionner rapidement et sans erreurs, nous avons donc écrit
loom , un outil de test de concurrence.
Avant de plonger dans le sujet, je tiens à remercier:
- @withoutboats et d'autres personnes qui ont travaillé sur la fonction
async / await à Rust. Tu as fait du bon travail. Ceci est une fonctionnalité qui tue.
- @cramertj et d'autres qui ont développé
std::task . Il s'agit d'une énorme amélioration par rapport à ce qu'elle était auparavant. Et un excellent code.
- Flottant , le créateur de Linkerd, et plus important encore, mon employeur. Merci de m'avoir permis de consacrer autant de temps à ce travail. Si quelqu'un s'intéresse au maillage de service, jetez un œil à Linkerd. Bientôt, il inclura tous les avantages discutés dans cet article.
- Optez pour une telle bonne mise en œuvre du planificateur.
Prenez une tasse de café et asseyez-vous. Ce sera un long article.
Comment fonctionnent les planificateurs?
La tâche du sheduler est de planifier le travail. L'application est divisée en unités de travail, que nous appellerons
tâches . Une tâche est considérée comme exécutable lorsqu'elle peut avancer dans son exécution, mais n'est plus exécutée ou en mode inactif, lorsqu'elle est verrouillée sur une ressource externe. Les tâches sont indépendantes dans le sens où un nombre illimité de tâches peuvent être effectuées simultanément. Le planificateur est responsable de l'exécution des tâches dans un état en cours d'exécution jusqu'à ce qu'elles reviennent en mode veille. L'exécution de la tâche implique d'affecter du temps processeur à la tâche - une ressource globale.
L'article décrit les planificateurs d'espace utilisateur, c'est-à-dire qu'ils fonctionnent au-dessus des threads du système d'exploitation (qui, à leur tour, sont contrôlés par un sheduler au niveau du noyau). Le planificateur Tokio exécute les futurs Rust, qui peuvent être considérés comme des «fils verts asynchrones». Il s'agit d'un modèle de
streaming mixte M: N dans lequel de nombreuses tâches d'interface utilisateur sont multiplexées sur plusieurs threads du système d'exploitation.
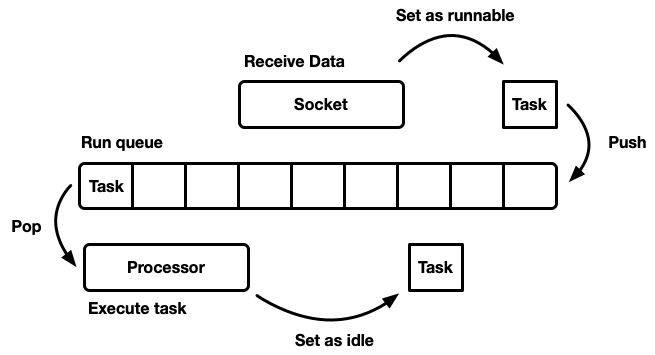
Il existe de nombreuses façons de simuler un sheduler, chacune avec ses avantages et ses inconvénients. Au niveau le plus élémentaire, le planificateur peut être modélisé comme une
file d'attente d'exécution et un
processeur qui le sépare. Un processeur est un morceau de code qui s'exécute dans un thread. En pseudo code, il fait ce qui suit:
while let Some(task) = self.queue.pop() { task.run(); }
Lorsqu'une tâche devient réalisable, elle est insérée dans la file d'attente d'exécution.
Bien que vous puissiez concevoir un système dans lequel des ressources, des tâches et un processeur existent sur le même thread, Tokio préfère utiliser plusieurs threads. Nous vivons dans un monde où un ordinateur possède de nombreux processeurs. Le développement d'un ordonnanceur à un seul fil conduira à une charge insuffisante de fer. Nous voulons utiliser tous les CPU. Il existe plusieurs façons de procéder:
- Une file d'attente d'exécution globale, de nombreux processeurs.
- De nombreux processeurs, chacun avec sa propre file d'attente d'exécution.
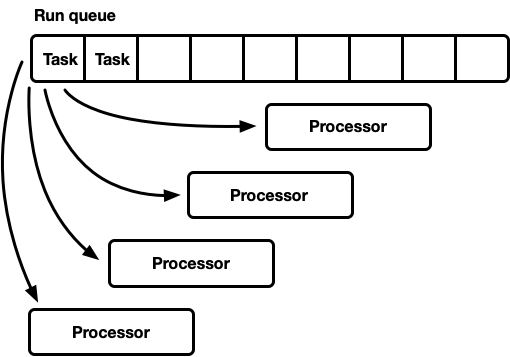
Un tour, plusieurs processeurs
Ce modèle possède une file d'attente d'exécution globale. Lorsque les tâches sont terminées, elles sont placées à la fin de la file d'attente. Il existe plusieurs processeurs, chacun dans un thread distinct. Chaque processeur prend une tâche de la tête de la file d'attente ou bloque le thread s'il n'y a pas de tâches disponibles.
La ligne d'exécution doit être prise en charge par de nombreux fabricants et consommateurs. Habituellement, une liste
intrusive est utilisée, dans laquelle la structure de chaque tâche comprend un pointeur vers la tâche suivante dans la file d'attente (au lieu d'envelopper les tâches dans une liste liée). Ainsi, l'allocation de mémoire pour les opérations push et pop peut être évitée. Vous pouvez utiliser
l'opération push sans verrouillage , mais pour coordonner les consommateurs, le mutex est requis pour l'opération pop (il est techniquement possible d'implémenter une file d'attente multi-utilisateurs sans verrouillage).
Cependant, dans la pratique, la surcharge pour une protection adéquate contre les verrous est plus que l'utilisation d'un mutex.
Cette approche est souvent utilisée pour un pool de threads à usage général, car elle présente plusieurs avantages:
- Les tâches sont assez planifiées.
- Implémentation relativement simple. Une file d'attente plus ou moins standard est interfacée avec le cycle du processeur décrit ci-dessus.
Une brève note sur une planification juste (équitable). Cela signifie que les tâches sont exécutées honnêtement: celui qui est venu plus tôt est celui qui est parti plus tôt. Les planificateurs à usage général essaient d'être justes, mais il existe des exceptions, telles que la parallélisation via la jointure en fourche, où la vitesse de calcul du résultat, plutôt que la justice pour chaque sous-tâche individuelle, est un facteur important.
Ce modèle a un inconvénient. Tous les processeurs postulent pour des tâches depuis le début de la file d'attente. Pour les threads à usage général, ce n'est généralement pas un problème. Le temps pour terminer une tâche dépasse de loin le temps pour la récupérer de la file d'attente. Lorsque les tâches sont effectuées sur une longue période de temps, la concurrence dans la file d'attente est réduite. Toutefois, les tâches Rust asynchrones devraient se terminer très rapidement. Dans ce cas, les frais généraux pour le combat dans la file d'attente augmentent considérablement.
Concurrence et sympathie mécanique
Pour atteindre des performances maximales, nous devons tirer le meilleur parti des fonctionnalités matérielles. Le terme «sympathie mécanique» pour les logiciels a été utilisé pour la première fois par
Martin Thompson (dont le blog n'est plus mis à jour, mais toujours très informatif).
Une discussion détaillée de la mise en œuvre du parallélisme dans les équipements modernes dépasse le cadre de cet article. De manière générale, le fer augmente la productivité non pas en raison de l'accélération, mais en raison de l'introduction d'un plus grand nombre de cœurs de processeur (même mon ordinateur portable en a six!) Chaque cœur peut effectuer de grandes quantités de calcul dans des intervalles de temps minuscules. Des actions telles que l'accès au cache et à la mémoire prennent
beaucoup plus de temps par rapport au temps d'exécution sur le CPU. Par conséquent, pour accélérer les applications, vous devez maximiser le nombre d'instructions du processeur pour chaque accès à la mémoire. Bien que le compilateur aide beaucoup, nous devons encore penser à des choses comme l'alignement et les modèles d'accès à la mémoire.
Les threads séparés fonctionnent de manière très similaire à un seul thread isolé,
jusqu'à ce que plusieurs threads modifient simultanément la même ligne de cache (mutations simultanées) ou qu'une
cohérence cohérente soit requise. Dans ce cas, le
protocole de cohérence du cache CPU est activé. Il garantit la pertinence du cache de chaque CPU.
La conclusion est évidente: dans la mesure du possible, évitez la synchronisation entre les threads, car elle est lente.
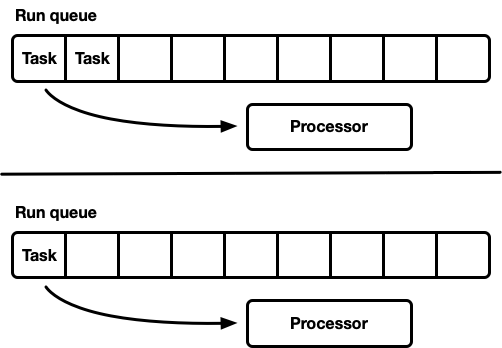
De nombreux processeurs, chacun avec sa propre file d'attente d'exécution
Un autre modèle est plusieurs planificateurs monothread. Chaque processeur reçoit sa propre file d'attente d'exécution et les tâches sont fixées sur un processeur spécifique. Cela évite complètement le problème de synchronisation. Étant donné que le modèle de tâche Rust nécessite la possibilité de mettre une tâche en file d'attente à partir de n'importe quel thread, il devrait toujours y avoir un moyen sûr pour les threads d'entrer des tâches dans le planificateur. Soit la file d'attente d'exécution de chaque processeur prend en charge le fonctionnement push-thread-safe (MPSC), soit chaque processeur possède
deux files d'attente d'exécution: non synchronisées et thread-safe.
Cette stratégie utilise
Seastar . Comme nous évitons presque complètement la synchronisation, cette stratégie donne une très bonne vitesse. Mais elle ne résout pas tous les problèmes. Si la charge de travail n'est pas complètement homogène, alors certains processeurs sont sous charge, tandis que d'autres sont inactifs, ce qui conduit à une utilisation non optimale des ressources. Cela se produit car les tâches sont fixées sur un processeur spécifique. Lorsqu'un groupe de tâches est planifié dans un package sur un processeur, il remplit à lui seul la charge de pointe, même si d'autres sont inactives.
La plupart des charges de travail «réelles» ne sont pas homogènes. Par conséquent, les planificateurs à usage général évitent généralement ce modèle.
Planificateur de capture des travaux
Le planificateur avec des planificateurs de vol de travail est basé sur le modèle de planificateur fragmenté et résout le problème du chargement incomplet des ressources matérielles. Chaque processeur prend en charge sa propre file d'attente d'exécution. Les tâches qui sont exécutées sont placées dans la file d'attente d'exécution du processeur actuel, et cela fonctionne dessus. Mais lorsque le processeur est inactif, il vérifie les files d'attente du processeur frère et essaie de récupérer quelque chose à partir de là. Le processeur ne passe en mode veille qu'après avoir été incapable de trouver du travail dans les files d'attente d'exécution d'égal à égal.

Au niveau du modèle, c'est l'approche du «meilleur des deux mondes». Sous charge, les processeurs fonctionnent indépendamment, évitant la synchronisation des frais généraux. Dans les cas où la charge entre les processeurs est répartie de manière inégale, le planificateur peut la redistribuer. C'est pourquoi ces ordonnanceurs sont utilisés dans
Go ,
Erlang ,
Java et d'autres langages.
L'inconvénient est que cette approche est beaucoup plus compliquée. L'algorithme de file d'attente doit prendre en charge la capture des travaux et, pour une exécution fluide,
une synchronisation entre les processeurs est requise. S'il n'est pas correctement implémenté, la surcharge pour la capture peut être supérieure au gain.
Considérez cette situation: le processeur A exécute actuellement une tâche et il a une file d'attente d'exécution vide. Le processeur B est inactif; il essaie de capturer une tâche, mais échoue, alors il passe en mode veille. Ensuite, 20 tâches sont générées à partir de la tâche du processeur A. Idéalement, le processeur B devrait se réveiller et en récupérer quelques-uns. Pour cela, il est nécessaire d'implémenter certaines heuristiques dans le planificateur, où les processeurs signalent aux processeurs homologues endormis l'apparition de nouvelles tâches dans leur file d'attente. Bien sûr, cela nécessite une synchronisation supplémentaire, de sorte que de telles opérations sont mieux minimisées.
En résumé:
- Moins il y a de synchronisation, mieux c'est.
- La capture des travaux est l'algorithme optimal pour les planificateurs à usage général.
- Chaque processeur fonctionne indépendamment des autres, mais une synchronisation est nécessaire pour capturer le travail.
Planificateur Tokio 0.1
Le premier planificateur fonctionnel pour Tokio a été publié en mars 2018. Il s'agissait de la première tentative, basée sur certaines hypothèses qui se sont révélées fausses.
Premièrement, le planificateur Tokio 0.1 a suggéré que les threads du processeur soient fermés s'ils étaient inactifs pendant un certain temps. Le planificateur a été créé à l'origine comme un système "à usage général" pour le pool de threads Rust. A cette époque, le runtime Tokio était encore à un stade précoce de développement. Ensuite, le modèle a supposé que les tâches d'E / S seraient effectuées sur le même thread que le sélecteur d'E / S (epoll, kqueue, iocp ...). Plus de tâches de calcul pourraient être dirigées vers le pool de threads. Dans ce contexte, une configuration flexible du nombre de threads actifs est supposée, il est donc plus logique de désactiver les threads inactifs. Cependant, dans le planificateur avec capture de travail, le modèle est passé à l'exécution de
toutes les tâches asynchrones et, dans ce cas, il est logique de toujours conserver un petit nombre de threads à l'état actif.
Deuxièmement, une ligne de
croisement bidirectionnelle y a été mise en place. Cette implémentation est basée sur la ligne
bidirectionnelle Chase-Lev et ne convient pas à la planification de tâches asynchrones indépendantes pour les raisons décrites ci-dessous.
Troisièmement, la mise en œuvre s'est avérée trop compliquée. Cela est dû en partie au fait qu'il s'agissait de mon premier planificateur de tâches. De plus, j'étais trop impatient lorsque j'utilisais l'atomique dans les branches, où le mutex aurait fait l'affaire. Une leçon importante est que, très souvent, ce sont les mutex qui fonctionnent le mieux.
Enfin, il y avait de nombreux défauts mineurs dans la mise en œuvre initiale. Au cours des premières années, les détails de mise en œuvre du modèle asynchrone de Rust ont considérablement évolué, mais les bibliothèques ont maintenu l'API stable à tout moment. Cela a conduit à l'accumulation d'une partie de la dette technique.
Tokio approche maintenant de la première version majeure - et nous pouvons payer toute cette dette, ainsi que tirer parti de l'expérience acquise au cours des années de développement. C'est une période passionnante!
Planificateur Tokio de nouvelle génération
Il est maintenant temps de regarder de plus près ce qui a changé dans le nouveau planificateur.
Nouveau système de tâches
Premièrement, il est important de souligner ce qui
ne fait
pas partie de Tokio, mais qui est crucial en termes d'amélioration de l'efficacité: il s'agit d'un
nouveau système de tâches en
std , développé à l'origine par
Taylor Kramer . Ce système fournit les crochets que le planificateur doit implémenter pour effectuer des tâches Rust asynchrones, et le système est vraiment superbement conçu et implémenté. Il est beaucoup plus léger et plus flexible que l'itération précédente.
La structure
Waker partir des ressources signale qu'une tâche
réalisable doit être placée dans la file d'attente du planificateur. Dans le nouveau système de tâches, il s'agit d'une structure à deux points, alors qu'auparavant elle était beaucoup plus grande. La réduction de la taille est importante pour minimiser la surcharge de copie de la valeur
Waker à différents endroits, et elle prend moins de place dans les structures, ce qui vous permet de compresser des données plus importantes dans la ligne de cache. La conception de
vtable a fait un certain nombre d'optimisations, dont nous discuterons plus tard.
Choisir le meilleur algorithme de file d'attente
La file d'attente d'exécution se trouve au centre du planificateur. Par conséquent, c'est le composant le plus important à corriger. L'ordonnanceur Tokio d'origine utilisait une
file d'attente à double
faisceau croisé : une implémentation à source unique (producteur) et de nombreux consommateurs. Une tâche est placée à une extrémité et les valeurs sont récupérées de l'autre. La plupart du temps, le thread «pousse» les valeurs depuis la fin de la file d'attente, mais parfois d'autres threads interceptent le travail, effectuant la même opération. La file d'attente bidirectionnelle est prise en charge par un tableau et un ensemble d'index qui suivent la tête et la queue. Lorsque la file d'attente est pleine, son introduction entraînera une augmentation de l'espace de stockage. Un nouveau tableau plus grand est alloué et les valeurs sont déplacées vers le nouveau stockage.
La capacité de croissance est obtenue grâce à la complexité et aux frais généraux. Les opérations push / pop devraient tenir compte de cette croissance. De plus, la libération de la baie d'origine est source de difficultés supplémentaires. Dans un langage de récupération de place (GC), l'ancien tableau sera hors de portée et, éventuellement, le GC l'effacera. Cependant, Rust est livré sans GC. Cela signifie que nous sommes nous-mêmes responsables de la libération du tableau, mais les threads peuvent essayer d'accéder à la mémoire en même temps. Pour résoudre ce problème, la traverse utilise une stratégie de récupération basée sur l'époque. Bien qu'il ne nécessite pas beaucoup de ressources, il ajoute une surcharge non triviale au chemin principal (hot path). Chaque opération doit maintenant effectuer des opérations atomiques RMW (lecture-modification-écriture) à l'entrée et à la sortie des sections critiques pour signaler aux autres threads que la mémoire est en cours d'utilisation et ne peut pas être effacée.
En raison des frais généraux liés à la croissance de la file d'attente d'exécution, il est logique de penser: le support de cette croissance est-il vraiment nécessaire? Cette question m'a finalement incité à réécrire le planificateur. La nouvelle stratégie consiste à avoir une taille de file d'attente fixe pour chaque processus. Lorsque la file d'attente est pleine, au lieu d'augmenter la file d'attente locale, la tâche se déplace vers la file d'attente globale avec plusieurs consommateurs et plusieurs producteurs. Les processeurs vérifieront périodiquement cette file d'attente globale, mais à une fréquence bien inférieure à celle locale.
Dans le cadre de l'une des premières expériences, nous avons remplacé la traverse par du
mpmc . Cela n'a pas conduit à une amélioration significative en raison de la quantité de synchronisation pour le push et le pop. La clé pour capturer le travail est qu'il n'y a presque pas de concurrence dans les files d'attente sous charge, car chaque processeur n'a accès qu'à sa propre file d'attente.
À ce stade, j'ai décidé d'étudier attentivement les sources Go - et j'ai constaté qu'elles utilisent une taille de file d'attente fixe avec un fabricant et plusieurs consommateurs, avec une synchronisation minimale, ce qui est très impressionnant. Pour adapter l'algorithme au planificateur Tokio, j'ai apporté quelques modifications. Il est à noter que l'implémentation Go utilise des opérations atomiques séquentielles (si je comprends bien). La version Tokio réduit également le nombre de certaines opérations de copie dans des branches de code plus rares.
Une implémentation de file d'attente est un tampon circulaire qui stocke des valeurs dans un tableau. La tête et la queue de la file d'attente sont suivies par des opérations atomiques avec des valeurs entières.
struct Queue {
La mise en file d'attente est effectuée par un seul thread:
loop { let head = self.head.load(Acquire);
Notez que dans cette fonction
push , les seules opérations atomiques sont le chargement avec la commande
Acquire et l'enregistrement avec la commande
Release . Il n'y a pas d'opérations RMW (
compare_and_swap ,
fetch_and ...) ni ordre séquentiel, comme précédemment. Ceci est important car sur les puces x86, tous les téléchargements / sauvegardes sont déjà «atomiques». Ainsi, au niveau CPU,
cette fonction ne sera pas synchronisée . Les opérations atomiques empêcheront certaines optimisations dans le compilateur, mais c'est tout. Très probablement, la première opération de
load pourrait être effectuée en toute sécurité avec une commande
Relaxed , mais le remplacement ne comporte pas de frais généraux notables.
Lorsque la file d'attente est pleine,
push_overflow est
push_overflow .
Cette fonction déplace la moitié des tâches de la file d'attente locale vers la file globale. La file d'attente globale est une liste intrusive protégée par un mutex. Lors du déplacement vers la file d'attente globale, les tâches sont d'abord liées entre elles, puis un mutex est créé et toutes les tâches sont insérées en mettant à jour le pointeur sur la queue de la file d'attente globale. Cela permet d'économiser une petite taille de section critique.Si vous connaissez les détails de la commande de la mémoire atomique, vous pouvez remarquer un «problème» potentiel avec la fonction indiquée ci-dessus push. L'opération de loadcommande atomique est Acquireplutôt faible. Il peut renvoyer des valeurs obsolètes, c'est-à-dire qu'une opération de capture parallèle peut déjà augmenter la valeur self.head, mais dans le cache de fluxpushl'ancienne valeur restera, elle ne remarquera donc pas l'opération de capture. Ce n'est pas un problème avec l'exactitude de l'algorithme. De manière principale (rapide), pushnous nous soucions uniquement de savoir si la file d'attente locale est pleine ou non. Étant donné que seul le thread actuel peut pousser la file d'attente, une opération obsolète loadrendra simplement la file d'attente plus pleine qu'elle ne l'est réellement. Il peut déterminer de manière incorrecte que la file d'attente est pleine et provoquer push_overflow, mais cette fonction inclut une opération atomique plus puissante. S'il push_overflowdétermine que la file d'attente n'est pas réellement pleine, renvoie ensuite w / Erret l'opération pushrecommence. C’est une autre raison pour laquellepush_overflowdéplace la moitié de la file d'attente d'exécution vers la file d'attente globale. Après ce mouvement, ces faux positifs se produisent beaucoup moins fréquemment.Local pop(à partir du processeur auquel appartient la file d'attente) est également implémenté simplement: loop { let head = self.head.load(Acquire);
Dans cette fonction, un atomique loadet un compare_and_swaps Release. Les frais généraux principaux proviennent de compare_and_swap.La fonction stealest similaire à pop, mais la self.tailcharge atomique doit être transférée de . De plus, de la même manière push_overflow, l'opération stealtente de faire semblant d'être la moitié de la file d'attente au lieu d'une seule tâche. Cela a un bon effet sur les performances, dont nous discuterons plus tard.La dernière partie manquante est l'analyse de la file d'attente globale, qui reçoit les tâches qui dépassent les files d'attente locales, ainsi que le transfert des tâches vers le planificateur à partir de threads non processeur. Si le processeur est sous charge, c'est-à-dire qu'il y a des tâches dans la file d'attente locale, le processeur essaiera de retirer des tâches de la file d'attente globale après environ 60 tâches dans la file d'attente locale. Il vérifie également la file d'attente globale lorsqu'elle est dans l'état de «recherche» décrit ci-dessous.Modèles de message rationalisés
Les applications Tokio se composent généralement de nombreuses petites tâches indépendantes. Ils interagissent entre eux à travers des messages. Un tel modèle est similaire à d'autres langues telles que Go et Erlang. Étant donné la fréquence à laquelle le modèle est courant, il est logique que le planificateur l'optimise.Supposons que les tâches A et B soient données. La tâche A est en cours d'exécution et envoie un message à la tâche B sur le canal de transmission. Un canal est une ressource sur laquelle la tâche B est actuellement verrouillée, donc l'action d'envoyer un message entraînera la transition de la tâche B vers un état exécutable - et elle sera placée dans la file d'attente d'exécution du processeur actuel. Ensuite, le processeur déduira la tâche suivante de la file d'attente d'exécution, l'exécutera et répétera ce cycle jusqu'à ce qu'il atteigne la tâche B.Le problème est qu'il peut y avoir un délai important entre l'envoi d'un message et la fin de la tâche B. En outre, les données chaudes, comme un message, sont stockées dans le cache du processeur, mais au moment où la tâche est terminée, il est probable que les caches correspondants seront effacés.Pour résoudre ce problème, le nouveau planificateur Tokio implémente l'optimisation (comme dans les planificateurs Go et Kotlin). Lorsqu'une tâche passe dans un état exécutable, elle n'est pas placée à la fin de la file d'attente, mais est stockée dans un emplacement spécial «tâche suivante». Le processeur vérifie toujours cet emplacement avant de vérifier la file d'attente. S'il existe déjà une ancienne tâche lors de l'insertion dans l'emplacement, elle est supprimée de l'emplacement et se déplace à la fin de la file d'attente. Ainsi, la tâche de transmission d'un message sera achevée pratiquement sans délai.
Capture de l'accélérateur
Dans un planificateur de capture de travaux, si la file d'attente d'exécution du processeur est vide, le processeur tente de capturer des tâches à partir de CPU homologues. Tout d'abord, un processeur homologue aléatoire est sélectionné, si aucune tâche n'est trouvée pour lui, la suivante est recherchée, et ainsi de suite, jusqu'à ce que des tâches soient trouvées.En pratique, plusieurs processeurs terminent souvent le traitement de la file d'attente d'exécution à peu près en même temps. Cela se produit lorsqu'un package de tâches arrive (par exemple, lorsqueepollinterrogé pour savoir si le socket est prêt). Les processeurs se réveillent, reçoivent des tâches, les démarrent et terminent. Cela conduit au fait que tous les processeurs tentent simultanément de capturer les tâches d'autres personnes, c'est-à-dire que de nombreux threads tentent d'accéder aux mêmes files d'attente. Il y a un conflit. Un choix aléatoire du point de départ permet de réduire la concurrence, mais la situation n'est toujours pas très bonne.Pour contourner ce problème, le nouveau planificateur limite le nombre de processeurs parallèles qui effectuent des opérations de capture. Nous appelons l'état du processeur dans lequel il essaie de capturer les tâches des autres «recherche d'emploi» ou «recherche» pour faire court (plus de détails plus loin). Une telle optimisation est effectuée en utilisant la valeur atomiqueint, que le processeur augmente avant de lancer la recherche et diminue à la sortie de l'état de recherche. Un maximum de la moitié du nombre total de processeurs peut être en état de recherche. Autrement dit, la limite approximative est définie, ce qui est normal. Nous n'avons pas besoin d'une limite stricte sur le nombre de processeurs dans la recherche, juste la limitation. Nous sacrifions la précision pour l'efficacité de l'algorithme.Après être entré dans l'état de recherche, le processeur tente de capturer le travail à partir des CPU homologues et vérifie la file d'attente globale.Diminue la synchronisation entre les threads
Une autre partie importante du planificateur consiste à notifier les processeurs homologues de nouvelles tâches. Si le "frère" dort, il se réveille et capture les tâches. Les notifications jouent un autre rôle important. Rappelons que l'algorithme de file d'attente utilise un ordre atomique faible ( Acquire/ Release). En raison de l'allocation atomique de la mémoire, rien ne garantit qu'un processeur homologue verra jamais les tâches dans la file d'attente sans synchronisation supplémentaire. Par conséquent, les notifications en sont également responsables. Pour cette raison, les notifications deviennent chères. Le but est de minimiser leur nombre afin de ne pas utiliser les ressources CPU, c'est-à-dire que le processeur a des tâches et que le frère ne peut pas les voler. Un nombre excessif de notifications conduit à un problème de troupeau de tonnerre .Le planificateur original de Tokio a adopté une approche naïve des notifications. Chaque fois qu'une nouvelle tâche était placée dans la file d'attente d'exécution, le processeur recevait une notification. Chaque fois que le CPU a été averti et a vu la tâche après s'être réveillé, il a notifié un autre CPU. Cette logique a très rapidement conduit tous les processeurs à se réveiller et à chercher du travail (provoquant un conflit). Souvent, la plupart des transformateurs ne trouvaient pas de travail et se rendormaient.Le nouveau planificateur a considérablement amélioré ce modèle, similaire au planificateur Go. Les notifications sont envoyées comme précédemment, mais uniquement s'il n'y a pas de CPU dans l'état de recherche (voir la section précédente). Lorsque le processeur reçoit une notification, il entre immédiatement dans l'état de recherche. Lorsque le processeur dans l'état de recherche trouve de nouvelles tâches, il quitte d'abord l'état de recherche, puis avertit l'autre processeur.Cette logique limite la vitesse à laquelle les processeurs se réveillent. Si un ensemble de tâches est planifié immédiatement (par exemple, lorsqueepollinterrogé pour savoir si le socket est prêt), la première tâche entraînera une notification au processeur. Il est maintenant en état de recherche. Les tâches planifiées restantes dans le package n'informeront pas le processeur, car il y a au moins un processeur à l'état de recherche. Ce processeur notifié capturera la moitié des tâches du lot et, à son tour, notifiera l'autre processeur. Un troisième processeur se réveille, trouve les tâches de l'un des deux premiers processeurs et en capture la moitié. Cela conduit à une augmentation en douceur du nombre de processeurs de travail, ainsi qu'à un équilibrage de charge rapide.Réduisez l'allocation de mémoire
Le nouveau planificateur Tokio ne nécessite qu'une seule allocation de mémoire pour chaque tâche générée, tandis que l'ancienne en demandait deux. Auparavant, la structure des tâches ressemblait à ceci: struct Task {
La structure Tasksera également mise en évidence dans Box. Pendant très longtemps, j'ai voulu réparer ce joint (j'ai essayé pour la première fois en 2014). Deux choses ont changé depuis l'ancien planificateur Tokio. Tout d'abord, stabilisé std::alloc. Deuxièmement, le futur système de tâches est passé à une stratégie explicite de table . Ce sont ces deux choses qui manquaient, enfin, pour se débarrasser de l'allocation de mémoire double inefficace pour chaque tâche.Maintenant, la structure Taskest présentée sous la forme suivante: struct Task<T> { header: Header, future: T, trailer: Trailer, }
Header ,
Trailer , «» () «» (), . . , , , . «» . , ( 64 128 ). , .
La dernière optimisation dont nous discutons dans cet article est de réduire le nombre de liens atomiques. Il existe de nombreuses références à la structure de la tâche, y compris du planificateur et de chaque waker. La stratégie générale de gestion de cette mémoire est le comptage de liens atomiques . Cette stratégie nécessite une opération atomique chaque fois qu'un lien est cloné et chaque fois qu'un lien est supprimé. Lorsque le dernier lien sort du domaine, la mémoire est libérée.Dans l'ancien planificateur Tokio, le planificateur et tous les wakers contenaient un lien vers un descripteur de tâche, approximativement: struct Waker { task: Arc<Task>, } impl Waker { fn wake(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Lorsque la tâche se réveille, le lien est cloné (un incrément atomique se produit). Ensuite, le lien est placé dans la file d'attente d'exécution. Lorsque le processeur reçoit la tâche et termine son exécution, il supprime le lien, ce qui entraîne une réduction atomique. Ces opérations atomiques (incrémentation et diminution) s'additionnent.Ce problème a été identifié précédemment par les développeurs du système de tâches std::future. Ils ont remarqué que lors de l'appel, le Waker::wakelien d'origine vers n'est wakersouvent plus nécessaire. Cela vous permet de réutiliser le compteur de liens atomiques lors du déplacement d'une tâche vers la file d'attente d'exécution. Le système de tâches std::futurecomprend désormais deux appels d'API pour se "réveiller":Une telle construction API nous oblige à l'utiliser lors de l'appel wake, en évitant l'incrément atomique. L'implémentation devient comme ceci: impl Waker { fn wake(self) { task.scheduler.schedule(self.task); } fn wake_by_ref(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Cela évite la surcharge de comptes de liens supplémentaires uniquement si vous pouvez prendre la responsabilité de vous réveiller. D'après mon expérience, au lieu de cela, il est presque toujours conseillé de se réveiller avec &self. L'éveil selfempêche la réutilisation de waker (utile dans les cas où la ressource envoie beaucoup de valeurs, c'est-à-dire des canaux, des sockets, ...). Dans le cas également, il est selfplus difficile d'implémenter un réveil sans fil (nous laisserons les détails pour un autre article).Le nouveau planificateur résout le problème du "réveil self" en évitant l'incrément atomique dans wake_by_ref, ce qui le rend aussi efficace quewake(self). Pour ce faire, le planificateur conserve une liste de toutes les tâches actuellement actives (pas encore terminées). La liste représente le compteur de référence nécessaire pour soumettre la tâche à la file d'attente d'exécution.La complexité de cette optimisation réside dans le fait que le planificateur ne supprimera pas les tâches de sa liste jusqu'à ce qu'il reçoive la garantie que la tâche sera replacée dans la file d'attente d'exécution. Les détails de la mise en œuvre de ce schéma dépassent le cadre de cet article, mais je vous recommande vivement de consulter la source.Concurrence audacieuse (non sécurisée) avec Loom
Il est très difficile d'écrire le code parallèle correct sans verrou. Il vaut mieux travailler lentement, mais correctement, que rapidement, mais avec des problèmes, surtout si les bogues concernent la sécurité de la mémoire. Cependant, la meilleure option devrait fonctionner rapidement et sans erreur. Le nouveau planificateur a fait quelques optimisations plutôt agressives et il évite la plupart des types stdpar souci de spécialisation. En général, il contient beaucoup de code dangereux unsafe.Il existe plusieurs façons de tester du code parallèle. L'un d'eux est pour les utilisateurs de tester et de déboguer à la place de vous (une option intéressante, c'est sûr). Une autre consiste à écrire des tests unitaires qui s'exécutent en boucle et peuvent détecter une erreur. Peut-être même utiliser TSAN. Bien sûr, s'il trouve une erreur, elle ne peut pas être facilement reproduite sans redémarrer le cycle de test. De plus, combien de temps dure ce cycle? Dix secondes? Dix minutes? Dix jours? Auparavant, vous deviez tester du code parallèle dans Rust.Nous avons trouvé cette situation inacceptable. Lorsque nous publions le code, nous voulons nous sentir en confiance (autant que possible), en particulier dans le cas d'un code parallèle sans verrouillage. Les utilisateurs de Tokio ont besoin de fiabilité.Par conséquent, nous avons développé Loom : un outil de test de permutation de code parallèle. Les tests sont écrits comme d'habitude, maisloomIl les exécutera plusieurs fois, réorganisant toutes les options possibles d'exécution et de comportement que le test peut rencontrer dans un environnement de streaming. Il vérifie également l'accès correct à la mémoire, la libération de mémoire, etc.À titre d'exemple, voici le test du métier à tisser pour le nouveau planificateur: #[test] fn multi_spawn() { loom::model(|| { let pool = ThreadPool::new(); let c1 = Arc::new(AtomicUsize::new(0)); let (tx, rx) = oneshot::channel(); let tx1 = Arc::new(Mutex::new(Some(tx)));
Cela semble assez normal, mais un morceau de code dans un bloc loom::models'exécute plusieurs milliers de fois (peut-être des millions), à chaque fois avec un léger changement de comportement. Chaque exécution modifie l'ordre exact des threads. De plus, pour chaque opération atomique, loom essaie tous les différents comportements autorisés dans le modèle de mémoire C ++ 11. Rappelons que la charge atomique avec Acquireétait plutôt faible et pouvait renvoyer des valeurs obsolètes. Le test loomva essayer toutes les valeurs possibles qui peuvent être chargées.loomest devenu un outil précieux pour développer un nouveau planificateur. Il a détecté plus de dix bogues qui ont réussi tous les tests unitaires, les tests manuels et les tests de charge.Un lecteur averti peut douter que le métier à tisser vérifie «toutes les permutations possibles» et il aura raison. Les permutations naïves entraîneront une explosion combinatoire. Tout test non trivial ne se terminera jamais. Ce problème est étudié depuis de nombreuses années et un certain nombre d'algorithmes ont été développés pour empêcher une explosion combinatoire. Métier à tisser de base algorithme basé sur la réduction dynamique de commande partielle (dynamique de réduction d'ordre partiel). Cet algorithme élimine les permutations conduisant au même résultat. Mais l'espace d'état peut toujours atteindre une taille telle qu'il ne sera pas traité dans un délai raisonnable (plusieurs minutes). Loom vous permet de le limiter davantage en utilisant la réduction dynamique avec une commande partielle.En général, grâce à des tests approfondis avec Loom, je suis maintenant beaucoup plus confiant dans l'exactitude du planificateur.Résultats
Nous avons donc examiné ce que sont les ordonnanceurs et comment le nouvel ordonnanceur Tokio a réussi à augmenter considérablement les performances ... mais quel type de croissance? Étant donné que le nouvel ordonnanceur n'a été développé que dans le monde réel, il n'a pas encore été testé dans son intégralité. Voici ce que nous savons.Premièrement, le nouveau planificateur est beaucoup plus rapide dans les micro-benchmarks:Ancien planificateur
test chained_spawn ... banc: 2,019,796 ns / iter (+/- 302,168)
test ping_pong ... banc: 1,279,948 ns / iter (+/- 154,365)
test spawn_many ... banc: 10,283,608 ns / iter (+/- 1,284,275)
test yield_many ... banc: 21,450,748 ns / iter (+/- 1,201,337)
Nouveau planificateur
test chained_spawn ... banc: 168 854 ns / iter (+/- 8 339)
test ping_pong ... banc: 562,659 ns / iter (+/- 34,410)
test spawn_many ... banc: 7,320,737 ns / iter (+/- 264,620)
test yield_many ... banc: 14,638,563 ns / iter (+/- 1,573,678)
Cette référence comprend les éléments suivants:chained_spawn générer récursivement de nouvelles tâches, c'est-à-dire générer une tâche qui génère une autre tâche, qui génère également une tâche, etc.
ping_pongsélectionne un canal oneshotet génère une tâche qui envoie un message sur ce canal. La tâche d'origine attend un message. C'est le test le plus proche du «monde réel».
spawn_many Vérifie l'implémentation des tâches dans le planificateur, c'est-à-dire génère des tâches en dehors de son contexte.
yield_many vérifie l'éveil indépendant des tâches.
La différence de benchmarks est très impressionnante. Mais comment cela se reflétera-t-il dans le "monde réel"? C'est difficile à dire avec certitude, mais j'ai essayé d'exécuter les tests Hyper .Voici le serveur Hyper le plus simple, dont les performances sont mesurées en utilisant wrk -t1 -c50 -d10:Ancien planificateur
Exécution du test 10s @ http://127.0.0.1 {000
1 fils et 50 connexions
Stats des sujets Moy Stdev Max +/- Stdev
Latence 371.53us 99.05us 1.97ms 60.53%
Requête / Sec 114,61k 8,45k 133,85k 67,00%
1139307 requêtes en 10.00s, 95.61MB lus
Demandes / sec: 113923.19
Transfert / s: 9,56 Mo Nouveau planificateur
Exécution du test 10s @ http://127.0.0.1 {000
1 fils et 50 connexions
Stats des sujets Moy Stdev Max +/- Stdev
Latence 275.05us 69.81us 1.09ms 73.57%
Requête / sec 153.17k 10.68k 171.51k 71.00%
1522671 requêtes en 10.00s, 127.79MB lus
Demandes / sec: 152258.70
Transfert / s: 12,78 Mo Nous constatons une augmentation de 34% des requêtes par seconde juste après le changement d'ordonnanceur! La première fois que j'ai vu cela, j'étais très heureux, car je m'attendais à une augmentation d'un maximum de 5-10%. Mais je me suis senti triste, car ce résultat a également montré que l'ancien ordonnanceur Tokio n'est pas si bon. Ensuite, je me suis souvenu que Hyper est déjà un leader dans les classements TechEmpower . Il est intéressant de voir comment le nouveau planificateur affectera les notes.Tonic , le client et serveur gRPC, avec le nouveau planificateur a accéléré d'environ 10%, ce qui est assez impressionnant étant donné que Tonic n'est pas encore entièrement optimisé.Conclusion
Je suis vraiment très heureux de pouvoir enfin terminer ce projet après plusieurs mois de travail. Il s'agit d'une amélioration majeure des E / S asynchrones de Rust. Je suis très satisfait des améliorations apportées. Il y a encore beaucoup de place pour l'optimisation dans le code Tokio, nous n'avons donc pas encore terminé l'amélioration des performances.J'espère que le contenu de l'article sera utile pour les collègues qui essaient d'écrire leur planificateur de tâches.