Dès le début, quand j'ai commencé la programmation, la question s'est posée de ce qu'il fallait utiliser pour améliorer les performances: structure ou classe; quels tableaux sont les meilleurs à utiliser et comment. En ce qui concerne les structures, Apple se félicite de leur utilisation, expliquant qu'elles sont meilleures en optimisation, et toute l'essence du langage Swift est les structures. Mais il y a ceux qui ne sont pas d'accord avec cela, car vous pouvez magnifiquement simplifier le code en héritant d'une classe d'une autre et en travaillant avec une telle classe. Pour accélérer le travail avec les classes, nous avons créé différents modificateurs et objets qui ont été optimisés spécifiquement pour les classes, et il est déjà difficile de dire ce qui sera plus rapide et dans quel cas.
Pour organiser tous les points sur le «e», j'ai écrit plusieurs tests qui utilisent les approches habituelles du traitement des données: passer à une méthode, copier, travailler avec des tableaux, etc. J'ai décidé de ne pas tirer de grandes conclusions, tout le monde décidera par lui-même s'il vaut la peine de croire les tests, pourra télécharger le projet et voir comment cela fonctionnera pour vous, et essayera d'optimiser le fonctionnement d'un test particulier. Peut-être même de nouvelles puces sortiront que je n'ai pas mentionnées, ou elles sont si rarement utilisées que je n'en ai tout simplement pas entendu parler.
PS J'ai commencé à travailler sur un article sur Xcode 10.3 et j'ai pensé à comparer sa vitesse avec Xcode 11, mais l'article ne porte pas sur la comparaison de deux applications, mais sur la vitesse de nos applications. Je ne doute pas que le temps d'exécution des fonctions diminuera, et celui qui a été mal optimisé deviendra plus rapide. En conséquence, j'ai attendu le nouveau Swift 5.1 et j'ai décidé de tester les hypothèses dans la pratique. Bonne lecture.
Test 1: comparer des tableaux sur des structures et des classes
Supposons que nous ayons une classe et que nous voulions placer les objets de cette classe dans un tableau, l'action habituelle sur un tableau consiste à la parcourir.
Dans un tableau, lorsque vous utilisez des classes et que vous essayez de le parcourir, le nombre de liens augmente, une fois terminé, le nombre de liens vers l'objet diminuera.
Si nous parcourons la structure, au moment où l'objet est appelé par index, une copie de l'objet sera créée, en regardant la même zone mémoire, mais marquée immuable. Il est difficile de dire ce qui est plus rapide: augmenter le nombre de liens vers un objet ou créer un lien vers une zone en mémoire sans avoir la possibilité de le changer. Vérifions cela en pratique:
 Fig. 1: Comparaison de l'obtention d'une variable à partir de tableaux basés sur des structures et des classes
Fig. 1: Comparaison de l'obtention d'une variable à partir de tableaux basés sur des structures et des classesTest 2. Comparez ContiguousArray vs Array
Ce qui est plus intéressant, c'est de comparer les performances d'un tableau (Array) avec un tableau de référence (ContiguousArray), qui est nécessaire spécifiquement pour travailler avec des classes stockées dans le tableau.
Vérifions les performances dans les cas suivants:
ContiguousArray stockant une structure avec un type de valeur
ContiguousArray stockant struct avec String
ContiguousArray stockant la classe avec le type de valeur
ContiguousArray stockant la classe avec String
Tableau stockant une structure avec un type de valeur
Tableau stockant la structure avec String
Tableau stockant une classe avec un type de valeur
Tableau stockant la classe avec String
Étant donné que les résultats des tests (tests: passage à une fonction avec optimisation en ligne désactivée, passage à une fonction avec optimisation en ligne activée, suppression d'éléments, ajout d'éléments, accès séquentiel à un élément dans une boucle) comprendront un grand nombre de tests (pour 8 tableaux de 5 tests chacun) , Je donnerai les résultats les plus significatifs:
- Si vous appelez une fonction et lui passez un tableau en désactivant inline, un tel appel sera très coûteux (pour les classes basées sur la chaîne de référence, il est 20 000 fois plus lent, pour les classes basées sur Value, le type est 60 000 fois pire avec l'optimiseur en ligne désactivé) .
- Si l'optimisation (en ligne) fonctionne pour vous, alors la dégradation ne devrait être attendue que 2 fois, selon le type de données ajouté à quelle baie. La seule exception était le type de valeur, enveloppé dans une structure située dans le ContiguousArray - sans dégradation de temps.
- Suppression - l'écart entre la matrice de référence et la matrice habituelle était d'environ 20% (en faveur de la matrice habituelle).
- Ajouter: lors de l'utilisation d'objets enveloppés dans des classes, ContiguousArray avait une vitesse environ 20% plus rapide que Array avec les mêmes objets, tandis qu'Array était plus rapide lors du travail avec des structures que ContiguousArray avec des structures.
- L'accès aux éléments du tableau lors de l'utilisation de wrappers à partir de structures s'est avéré être plus rapide que n'importe quel wrapper sur des classes, y compris ContiguousArray (environ 500 fois plus rapide).
Dans la plupart des cas, l'utilisation de tableaux réguliers pour travailler avec des objets est plus efficace. Utilisé avant, nous utilisons plus loin.
L'optimisation de boucle pour les tableaux est servie par l'initialiseur de collection paresseux, qui vous permet de parcourir une seule fois l'ensemble du tableau, même si plusieurs filtres ou cartes sont utilisés sur les éléments du tableau.
L'utilisation de structures comme outil d'optimisation présente des pièges, tels que l'utilisation de types référencés en interne dans la nature: chaînes, dictionnaires, tableaux de référence. Ensuite, lorsqu'une variable qui stocke un type de référence en soi est entrée dans une fonction, une référence supplémentaire est créée pour chaque élément qui est une classe. Cela a un autre côté, un peu plus loin. Vous pouvez essayer d'utiliser une classe wrapper sur une variable. Ensuite, le nombre de liens lors du passage à la fonction augmentera uniquement pour elle, et le nombre de liens vers les valeurs à l'intérieur de la structure restera le même. En général, je veux voir combien de variables d'un type de référence doivent être dans la structure pour que ses performances diminuent plus bas que les performances des classes avec les mêmes paramètres. Il existe un article sur le Web intitulé «Arrêtez d'utiliser les structures!» Qui pose la même question et y répond. J'ai téléchargé le projet et j'ai décidé de comprendre ce qui se passe où et dans quels cas nous obtenons des structures lentes. L'auteur montre la faible performance des structures par rapport aux classes, faisant valoir que la création d'un nouvel objet est beaucoup plus lente que l'augmentation de la référence à l'objet est absurde (j'ai donc supprimé la ligne où un nouvel objet est créé dans la boucle à chaque fois). Mais si nous ne créons pas de lien vers l'objet, mais le passons simplement dans une fonction pour travailler avec lui, alors la différence de performance sera très insignifiante. Chaque fois que nous mettons en
ligne (jamais) une fonction, notre application doit l'exécuter et ne pas créer de code dans une chaîne. À en juger par les tests, Apple a fait en sorte que l'objet transmis à la fonction soit légèrement modifié, pour les structures, le compilateur change de mutabilité et rend paresseux les propriétés non mutables de l'objet. Quelque chose de similaire se produit dans la classe, mais augmente en même temps le nombre de références à l'objet. Et maintenant, nous avons un objet paresseux, tous ses champs sont également paresseux, et chaque fois que nous appelons une variable objet, il l'initialise. En cela, les structures n'ont pas d'égal: lorsqu'une fonction appelle deux variables, la structure de l'objet n'est que légèrement inférieure à la classe de vitesse; lorsque vous en appelez trois ou plus, la structure sera toujours plus rapide.
Test 3: comparer les performances des structures et des classes stockant de grandes classes
J'ai également légèrement modifié la méthode elle-même, qui a été appelée lorsqu'une autre variable a été ajoutée (de cette manière, trois variables ont été initialisées dans la méthode, et non deux, comme dans l'article), et afin qu'il n'y ait pas de débordement Int, j'ai remplacé les opérations sur les variables par la somme et la soustraction. Ajout de métriques de temps plus compréhensibles (dans la capture d'écran, il s'agit de secondes, mais ce n'est pas si important pour nous, il est important de comprendre les proportions résultantes), en supprimant le cadre Darwin (je n'utilise pas dans les projets, peut-être en vain, il n'y a pas de différences dans les tests avant / après l'ajout du cadre dans mon test), l'inclusion d'une optimisation maximale et de construire sur la version de la version (il semble que ce sera plus honnête), et voici le résultat:
 Fig. 2: Performances des structures et des classes de l'article «Arrêtez d'utiliser des structures»
Fig. 2: Performances des structures et des classes de l'article «Arrêtez d'utiliser des structures»Les différences dans les résultats des tests sont négligeables.
Test 4: Fonction acceptant générique, protocole et fonction sans générique
Si nous prenons une fonction générique et y passons deux valeurs, unies uniquement par la possibilité de comparer ces valeurs (func min), alors le code de trois lignes se transformera en code de huit (comme le dit Apple). Mais cela ne se produit pas toujours, Xcode a des méthodes d'optimisation dans lesquelles s'il voit deux valeurs structurelles lui être transmises lorsqu'il appelle la fonction, il génère automatiquement une fonction qui prend deux structures et ne copie plus les valeurs.
 Fig. 3: Fonction générique typique
Fig. 3: Fonction générique typiqueJ'ai décidé de tester deux fonctions: dans la première, le type de données générique est déclaré, la seconde accepte uniquement le protocole. Dans la nouvelle version de Swift 5.1 Protocol, il est même un peu plus rapide que Generic (avant Swift 5.1, les protocoles étaient 2 fois plus lents), bien que selon Apple, cela devrait être l'inverse, mais quand il s'agit de passer par un tableau, nous devons déjà taper, ce qui ralentit Générique (mais ils sont toujours super, car ils sont plus rapides que les protocoles):
 Fig. 4: Comparaison des fonctions hôtes génériques et protocolaires.
Fig. 4: Comparaison des fonctions hôtes génériques et protocolaires.Test 5: Comparez l'appel de la méthode parent à celui de la méthode native, et vérifiez en même temps la classe finale pour un tel appel
Ce qui m'a toujours intéressé, c'est la lenteur des cours avec un grand nombre de parents, la rapidité avec laquelle une classe appelle ses fonctions et celle d'un parent. Dans les cas où nous essayons d'appeler une méthode qui prend une classe, la répartition dynamique entre en jeu. Qu'est ce que c'est Chaque fois qu'une méthode ou variable est appelée à l'intérieur de notre fonction, un message est généré demandant à l'objet cette variable ou méthode. L'objet, recevant une telle demande, commence à rechercher la méthode dans la table de répartition de sa classe, et si un remplacement de la méthode ou de la variable a été appelé, la prend et la renvoie, ou il atteint récursivement la classe de base.
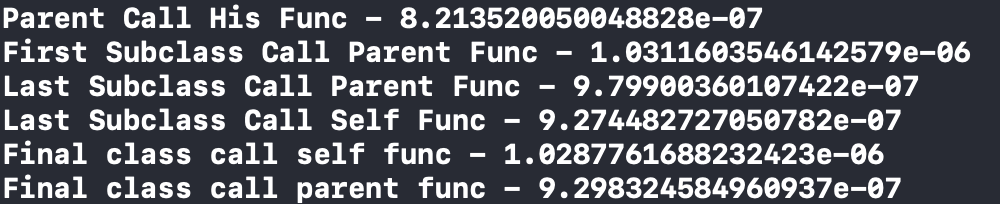 Fig. 5: Appels de méthode de classe, pour les tests de répartition
Fig. 5: Appels de méthode de classe, pour les tests de répartitionPlusieurs conclusions peuvent être tirées du test ci-dessus: plus la classe de classes parent est grande, plus elle fonctionnera lentement et que la différence de vitesse est si petite qu'elle peut être négligée en toute sécurité, très probablement l'optimisation du code fera en sorte qu'il n'y aura pas de différence de vitesse. Dans cet exemple, le modificateur de classe final n'a pas d'avantage, au contraire, le travail de la classe est encore plus lent, peut-être du fait qu'il ne devient pas une fonction vraiment rapide.
Test 6: Appel d'une variable avec le dernier modificateur contre une variable de classe régulière
Également des résultats très intéressants avec l'attribution du modificateur final à une variable, vous pouvez l'utiliser lorsque vous savez avec certitude que la variable ne sera réécrite nulle part dans les héritiers de la classe. Essayons de mettre le dernier modificateur à une variable. Si dans notre test, nous avons créé une seule variable et appelé une propriété dessus, alors elle serait initialisée une fois (le résultat est d'en bas). Si nous créons honnêtement à chaque fois un nouvel objet et demandons sa variable, la vitesse ralentira sensiblement (le résultat est au dessus):
 Fig. 6: Appel de la dernière variable
Fig. 6: Appel de la dernière variableDe toute évidence, le modificateur n'est pas allé au profit de la variable, et il est toujours plus lent que son concurrent.
Test 7: Problème de polymorphisme et protocoles pour les structures. Ou les performances d'un conteneur Existential
Problème: si nous prenons un protocole qui prend en charge une certaine méthode et plusieurs structures héritées de ce protocole, que pensera notre compilateur lorsque nous mettrons des structures avec différents volumes de valeurs stockées dans un tableau, unies par le protocole d'origine?
Pour résoudre le problème de l'appel d'une méthode prédéfinie chez les héritiers, le mécanisme Protocol Witness Table est utilisé. Il crée des structures shell qui référencent les méthodes nécessaires.
Pour résoudre le problème de stockage des données, un conteneur Existential est utilisé. Il stocke en lui-même 5 cellules d'informations, chacune de 8 octets. Dans les trois premiers, un espace est alloué pour les données stockées dans la structure (si elles ne correspondent pas, cela crée un lien vers le tas dans lequel les données sont stockées), le quatrième stocke des informations sur les types de données utilisées dans la structure et nous indique comment gérer ces données , le cinquième contient des références aux méthodes de l'objet.
 Figure 7. Comparaison des performances d'un tableau qui crée un lien vers un objet et qui le contient
Figure 7. Comparaison des performances d'un tableau qui crée un lien vers un objet et qui le contientEntre les premier et deuxième résultats, le nombre de variables a triplé. En théorie, ils doivent être placés dans un conteneur, ils sont stockés dans ce conteneur, et la différence de vitesse est due au volume de la structure. Fait intéressant, si vous réduisez le nombre de variables dans la deuxième structure, le temps de fonctionnement ne changera pas, c'est-à-dire que le conteneur stocke en fait 3 ou 2 variables, mais il semble qu'il existe des conditions spéciales pour une variable qui augmentent considérablement la vitesse. La deuxième structure s'intègre parfaitement dans le conteneur et diffère en volume du troisième de moitié, ce qui donne une forte dégradation à l'exécution, par rapport aux autres structures.
Un peu de théorie pour optimiser vos projets
Les facteurs suivants peuvent influencer les performances des structures:
- où ses variables sont stockées (tas / pile);
- la nécessité de compter les références pour les propriétés;
- méthodes de planification (statique / dynamique);
- Copy-On-Write est utilisé uniquement par les structures de données qui sont des types de référence se faisant passer pour des structures (String, Array, Set, Dictionary) sous le capot.
Il convient de préciser tout de suite que les objets qui stockent les propriétés dans la pile sont les plus rapides, n'utilisez pas le comptage de références avec la méthode statique de l'examen médical.
Que les classes sont mauvaises et dangereuses par rapport aux structures
Nous ne contrôlons pas toujours la copie de nos objets, et si nous le faisons, nous pouvons obtenir trop de copies qui seront difficiles à gérer (nous avons créé des objets dans le projet qui sont responsables de la formation de la vue, par exemple).
Ils ne sont pas aussi rapides que les structures.
Si nous avons un lien vers un objet et que nous essayons de contrôler notre application dans un style multi-thread, nous pouvons obtenir la condition de concurrence lorsque notre objet est utilisé à partir de deux endroits différents (et ce n'est pas si difficile, car un projet construit avec Xcode est toujours un peu plus lent, que la version Store).
Si nous essayons d'éviter la condition de course, nous dépensons beaucoup de ressources sur Lock et nos données, ce qui commence à consommer des ressources et à perdre du temps au lieu d'un traitement rapide et nous obtenons des objets encore plus lents que les mêmes construits sur des structures.
Si nous faisons toutes les actions ci-dessus sur nos objets (liens), alors la probabilité de blocages imprévus est élevée.
La complexité du code augmente à cause de cela.
Plus de code = plus de bugs, toujours!
Conclusions
Je pensais que les conclusions de cet article étaient simplement nécessaires, parce que je ne veux pas lire l'article de temps en temps, et une liste consolidée de points est simplement nécessaire. Résumant les lignes sous les tests, je veux souligner les points suivants:
- Les tableaux sont mieux placés dans un tableau.
- Si vous souhaitez créer un tableau à partir de classes, il est préférable de choisir un tableau régulier, car ContiguousArray fournit rarement des avantages et ils ne sont pas très élevés.
- L'optimisation en ligne accélère le travail, ne le désactivez pas.
- L'accès aux éléments du tableau est toujours plus rapide que l'accès aux éléments du ContiguousArray.
- Les structures sont toujours plus rapides que les classes (à moins bien sûr que vous n'activiez l'optimisation de module entier ou une optimisation similaire).
- Lorsque vous passez un objet dans une fonction et appelez ses propriétés, à partir de la troisième, la structure est plus rapide que les classes.
- Lorsque vous transmettez une valeur à une fonction écrite pour Generic et Protocol, Generic sera plus rapide.
- Avec l'héritage de plusieurs classes, la vitesse de l'appel de fonction se dégrade.
- Les variables ont marqué le travail final plus lentement que les poivrons ordinaires.
- Si une fonction accepte un objet qui combine plusieurs objets avec le protocole, elle fonctionnera rapidement si une seule propriété y est stockée et se dégradera considérablement lors de l'ajout de propriétés.
Références:
medium.com/@vhart/protocols-generics-and-existential-containers-wait-what-e2e698262ab1developer.apple.com/videos/play/wwdc2016/416developer.apple.com/videos/play/wwdc2015/409developer.apple.com/videos/play/wwdc2016/419medium.com/commencis/stop-using-structs-e1be9a86376fTester le code source