But et objectif
Dans une série d'articles, nous considérons les classificateurs des appels vocaux, pourquoi ils sont nécessaires, comment les amener rapidement à la productivité. Je vais vous parler d'approches qui réduiront le temps écoulé entre la définition d'une tâche, le lancement d'un modèle et l'obtention d'un résultat commercial.
Pour cet article, vous pouvez voir le rapport sur le lien
Comment Méthode est devenue Anna. Série n ° 1
Commençons!
Je m'appelle Julia, je suis ingénieur dans le département d'apprentissage automatique d'un grand fournisseur. Environ 3 000 appels de clients arrivent chaque jour dans notre centre d'appels. Chaque opérateur reçoit en moyenne 100 appels par jour. Et alors? Il semblerait que cela accepte 100 appels. Mais il y a beaucoup de sujets d'appels à l'entreprise, l'opérateur doit comprendre tous les produits, services et processus de l'entreprise. Si nous prenons les demandes des clients les plus typiques, elles peuvent être regroupées en 40 (!) Sujets, et il existe encore des applications atypiques qui doivent également pouvoir être traitées.

En raison de la variété des sujets, la formation des opérateurs a duré trois mois. Vous devez d'abord étudier toutes les instructions et ensuite seulement il est autorisé à recevoir des appels. Une quantité énorme de ressources est dépensée pour créer un nouvel opérateur compétent. L'idée est donc venue de mettre progressivement l'opérateur en ligne. Autrement dit, il ne recevra des appels que sur les sujets qu'il a maîtrisés, augmentant au fil du temps ses compétences, étudiant d'autres sujets.
Bonne idée, pourquoi ne pas faire ... un simple RVI? (un système de messages vocaux préenregistrés qui achemine les appels à l'intérieur du centre d'appels à l'aide des informations saisies par le client sur le clavier du téléphone à l'aide de la numérotation par tonalité. wiki )
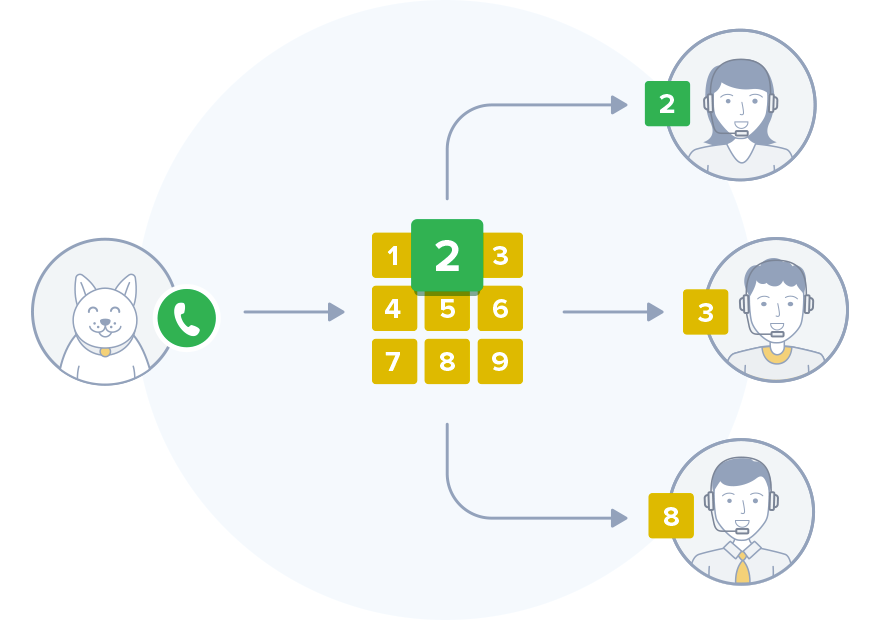
Mais peu de gens aiment écouter une voix enregistrée pendant longtemps, attendre, quel chiffre doit être pressé, mais à la fin ils n’obtiennent toujours pas les informations nécessaires.
Nous ne voulions pas tourmenter nos clients avec l'IVR et nous avons fixé la tâche - classer la demande de l'abonné selon la première phrase. Ainsi, selon la demande exprimée, le routage entre les opérateurs aura lieu.
Les données
Les opérateurs de support technique sur le résultat de chaque appel exposent le sujet de l'appel depuis environ 10 ans. Nous avons identifié les 16 groupes les plus nombreux, et un balisage est apparu à partir de ces sujets. Ensuite, nous avons téléchargé des enregistrements de 120 000 conversations sur divers sujets, reconnu l'enregistrement de la conversation du client à l'aide de Yandex.SpeechKit et les divisé en phrases par silence. Nous avons donc obtenu des morceaux audio avec des phrases distinctes.
Permettez-moi de vous rappeler que mon objectif était de classer la demande initiale du client, de sorte que seule la première phrase a été sélectionnée pour chaque appel. Au total, les données étaient de 120 000 phrases client au format texte avec balisage des opérateurs. Prétraitement de texte standard: suppression des mots vides, normalisation du texte (astuces: attacher une particule «non» au mot suivant) et les données sont prêtes. Je vais vous en dire plus sur notre pipeline de prétraitement dans un autre article.
Classification
Ensuite, après avoir reçu le texte traité, nous avons mené de nombreuses expériences, triées à travers différentes configurations de modèles et plongements.
Tableau avec comparaison des résultats expérimentaux Le meilleur résultat a été donné par l'ensemble standard de TF-IDF et la régression logistique. Le tableau montre la métrique f-score. Dans certaines expériences, en plus du texte, 11 signes supplémentaires concernant le client (contexte) ont été ajoutés au moment de l'appel. Dans l'espoir que cela améliorera la qualité. Contexte - ce sont des signes booléens, si le client a maintenant un solde négatif, si la réparation est affectée à l'adresse et à d'autres qui caractérisent le client en ce moment. Mais même avec le contexte, la qualité est mauvaise, seulement 72% ont été atteints.
Analyse des erreurs
Sans analyse d'erreur, la qualité de la classification ne pourrait pas être améliorée. Après avoir examiné les cas où les modèles se trompent, nous avons identifié les problèmes typiques suivants:
- mauvais balisage
- déséquilibre de classe
- il est difficile pour les gens de formuler une pensée
- reconnaissance vocale
Marquage
Le balisage était souvent incorrect en raison du fait que la conversation pouvait commencer par un sujet et se terminer par un autre, et l'opérateur définissait le sujet de l'appel, ce qui était dit à la toute fin du dialogue. Redistribué manuellement ces cas et le problème a disparu.
Solde de classe
Il existe plusieurs approches pour équilibrer les classes.
Plus de détails- Sous-échantillonnage. Suppression aléatoire d'exemples de grandes classes.
- Suréchantillonnage. Ajout aléatoire d'exemples de classes mineures.
- Suréchantillonnage des minorités synthétiques. Ajout aléatoire d'exemples des plus petites classes, mais en les modifiant légèrement.
L'approche à choisir dépend de la tâche et de la quantité de données. Dans le cadre de cette tâche, il a été possible d'équilibrer l'ensemble de données en supprimant les exemples des classes de fréquences les plus nombreuses à la valeur médiane du nombre d'exemples, mais les classes mineures sont restées inchangées.
Après avoir lu les premières phrases, nous avons remarqué que 36% des demandes contenaient du texte non informatif, par exemple: «Bonjour, bonjour» ou «Bonjour, j'ai une question». Ce n'est qu'après que l'opérateur a demandé: «quelle est votre question?», Le client a formulé le problème.
Ainsi, il était faux de ne retenir que la première phrase du client de la conversation; quelqu'un n'était tout simplement pas en mesure de formuler une demande tout de suite. Par conséquent, pour chaque première phrase, le «caractère informatif» a été calculé. Si le modèle n'a attribué la demande avec une confiance élevée à aucune des classes, c'est-à-dire que toutes les classes ont reçu une valeur de probabilité égale, le message n'est pas informatif et vous devez prendre la deuxième phrase. Et si la classe est déjà déterminée avec une forte probabilité, la première phrase suffit.
Ici, la bonne question peut apparaître, mais que faire sur le produit, car il y aura les mêmes requêtes non informatives. J'en parlerai plus tard dans le prochain article.
Reconnaissance vocale
Lors de l'analyse des erreurs, nous avons remarqué des inexactitudes dans la reconnaissance de texte, à cause desquelles la classe était mal définie. Par exemple, le mot «équilibre» a parfois été remplacé par «banane». Nous avons décidé de comparer la reconnaissance de Yandex et de Google. Google s'est montré mieux sur nos données, mais pas au point de payer trop cher, le prix est presque deux fois plus élevé.
Comparaison de la reconnaissance vocale entre deux systèmes. Résumé de l'analyse des erreurs
Après avoir analysé et corrigé les erreurs, nous avons pu améliorer la qualité à un score f moyen de 84%; la meilleure qualité était toujours le résultat d'une régression logistique.
Gain de qualité pour chaque classe Conclusions
Résumant la première étape de développement, nous pouvons tirer la conclusion suivante.
Tout d'abord, vous devez gérer les données et le balisage. Vous ne devez pas entraîner immédiatement les réseaux de neurones, sur des données incorrectes, cela ne sera pas très bénéfique. Pour éviter de perdre du temps et de l'énergie, il suffit d'analyser les erreurs sur des modèles «simples».
Rendez-vous dans la deuxième série , où nous parlerons de la façon d'exécuter un modèle formé dans un environnement productif. Nous écouterons des exemples de la façon dont Methodius reçoit le robot et nous comprendrons pourquoi il est devenu Anna.