
Dans les tris de distribution, les éléments sont distribués et redistribués en classes jusqu'à ce que le tableau soit trié.
Dans le cas le plus général, cela se produit à peu près de la même manière. Les éléments sont dispersés par classes selon certains critères. Si cela ne conduit pas à l'ordre du tableau, les attributs de la classe sont affinés et les éléments sont à nouveau dispersés dans les classes affinées. Et cela se produit jusqu'à ce que le tableau soit ordonné.
Dans les triages par répartition, il n'y a presque toujours pas de comparaison d'éléments entre eux et leurs échanges. L'essentiel est de savoir si l'élément appartient à une certaine classe ou non, sa comparaison avec d'autres éléments joue rarement un rôle.
En règle générale, ces types ont une complexité temporelle linéaire (plutôt que logarithmique, comme pour les types efficaces d'échanges, de fusions, de choix ou d'insertions). De plus, les algorithmes de cette classe nécessitent presque toujours beaucoup de mémoire supplémentaire, car les éléments regroupés par classes doivent être stockés quelque part.
Les tris de distribution sont bons pour trier les entiers et les chaînes. Il n'est généralement pas pratique de trier les nombres réels avec eux. De plus, la distribution trie parfaitement les tableaux composés de nombres répétitifs - plus il y a de répétitions, moins il faut de classes différentes.

Cet article a été écrit avec le soutien d'EDISON.
Avis client: 10 avantages des programmeurs d'EDISON
C'est intéressant et utile à savoir: Programmeur de petit - déjeuner
Prenons un algorithme qui illustre le plus convexement les propriétés ci-dessus.
Tri par seau :: Tri par seau
Les autres noms sont le tri par panier, le tri par bloc, le tri par poche.
Nous dispersons des nombres dans des paniers, puis dans chaque panier nous nous dispersons dans des paniers plus petits, et ainsi de suite, jusqu'à ce qu'à un certain niveau dans le panier il n'y ait que les mêmes éléments. Ensuite, à partir de ces paniers du niveau le plus bas, il est facile de restaurer la baie dans un état ordonné.
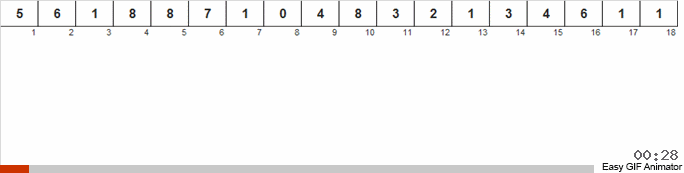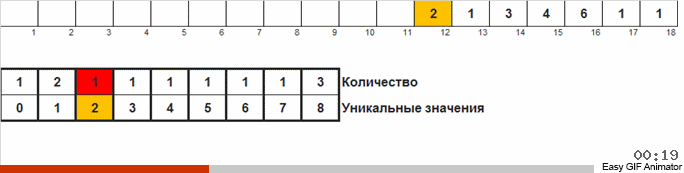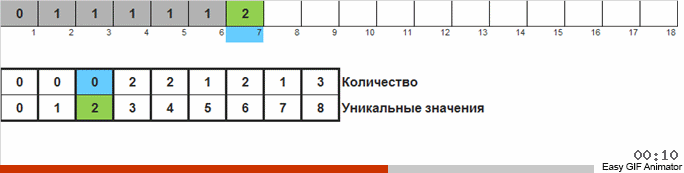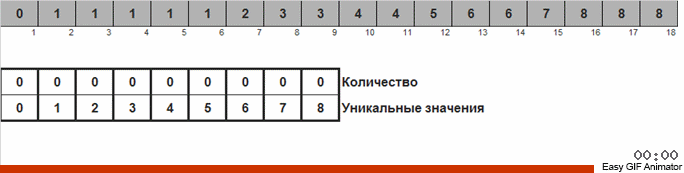
Expliquons-nous avec un exemple précis. Disons que nous avons un tableau non ordonné. Il est connu que ce tableau contient des nombres de 1 à 8.
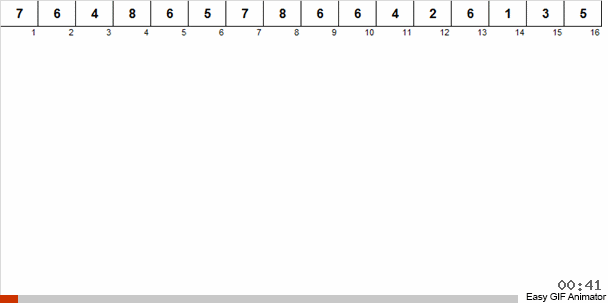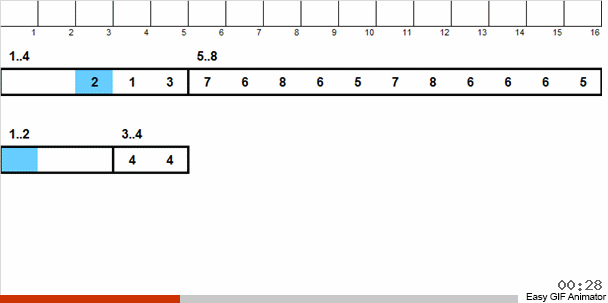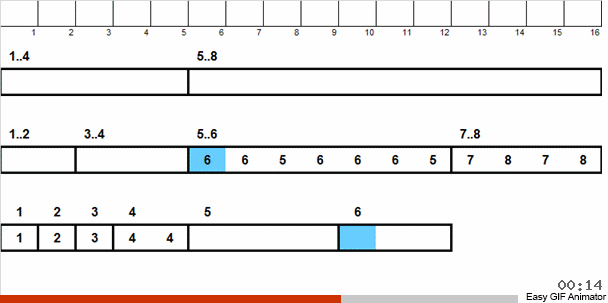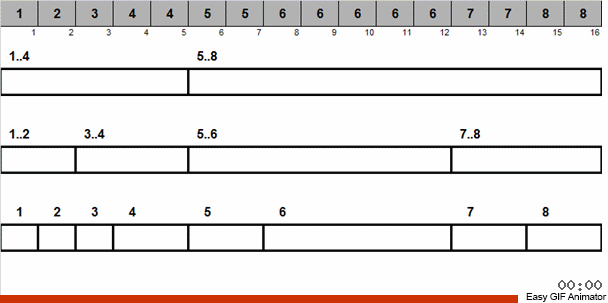
Nous jetons ces nombres en 2 groupes: les nombres de 1 à 4 tombent dans un groupe, de 5 à 8 dans le second. Ensuite, nous répartissons les nombres dans le premier panier en deux paniers: dans un numéro 1 et 2 et dans les autres 3 et 4. Nous distribuons également ces paniers dans des paniers libériens, qui contiennent déjà des numéros de la même taille. À ce grand panier contenant des nombres de 5 à 8, nous appliquons une récursivité similaire.
Ensuite, à partir de petits paniers, dont chacun contient les mêmes numéros, nous renvoyons les éléments au tableau principal par ordre de priorité.
Le tri nucléaire sous cette forme n'est pas particulièrement applicable dans la pratique, mais il montre de manière standard le fonctionnement de tous les tri par distribution en général.
Tri Thanos :: Tri Thanos
Parfois, des tris d'auteur me sont envoyés et c'est exactement le cas. L'auteur Andrei Danilin l'a appelé «tri russe en deux», mais je l'ai appelé le tri de Thanos. Ou, si nous procédons formellement à partir des méthodes utilisées, nous pouvons appeler son tri de moyenne arithmétique.
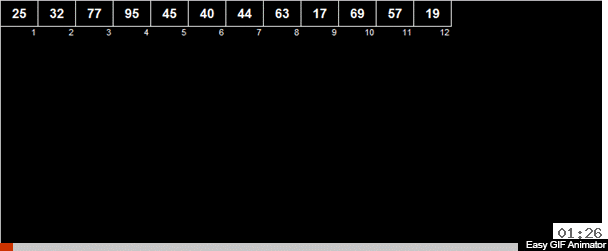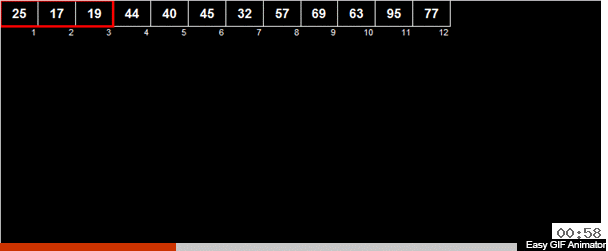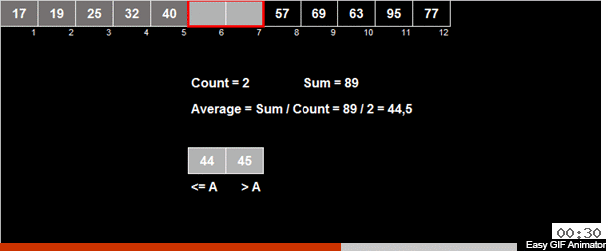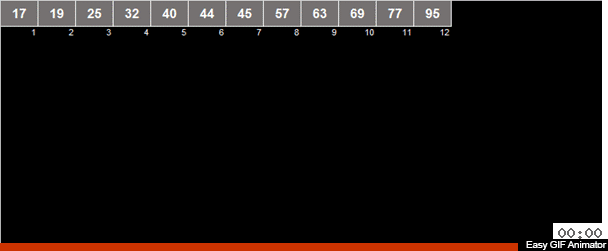
La moyenne arithmétique des éléments est calculée dans le tableau puis tous les éléments sont répartis en 2 groupes. Les éléments plus petits (ou égaux à) la moyenne arithmétique vont à un groupe, plus grands que la moyenne arithmétique au deuxième groupe. Ensuite, les mêmes actions sont appliquées récursivement aux deux groupes - et ainsi de suite jusqu'à la fin amère.
Et qu'en est-il du titane fou? S'il s'agit d'un tableau aléatoire, alors dans l'ensemble, l'élément, comparé à la moyenne arithmétique, a 50/50 de chances qu'il ira à l'un des deux groupes.
Soit dit en passant, sur Internet, je suis tombé sur un autre algorithme comique du même nom. Si le tableau n'est pas trié, cliquez sur le gant Infinity et envoyez la moitié des éléments du tableau sélectionnés au hasard à la non-existence. Si les survivants forment un tableau ordonné, alors leur grande mission peut être considérée comme remplie. Si ce n'est pas déjà fait, vous pouvez effectuer quelques clics supplémentaires.

Mais revenons à nos tris de distribution. Tous peuvent être divisés en seulement deux groupes -
comptage des tris et
tri au niveau du bit . Eh bien, si vous le souhaitez, vous pouvez également mettre en évidence
les tri de comptage de bits , c'est-à-dire ceux qui peuvent être attribués aux deux.
Il existe également des algorithmes hybrides (ce sont ceux qui utilisent des méthodes de différentes classes, par exemple, le tri de Tim est un mélange de tri par fusion et de tri par insertion, le tri introspectif est un tri rapide qui va dans un tri en grappe, etc.), y compris les tri de distribution Cependant, les hybrides sont une section distincte. À leur sujet plus tard.
Le tri par milliers et le tri par moyenne arithmétique sont liés au comptage des tris.
Compter les tris
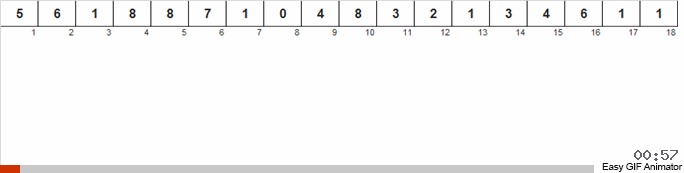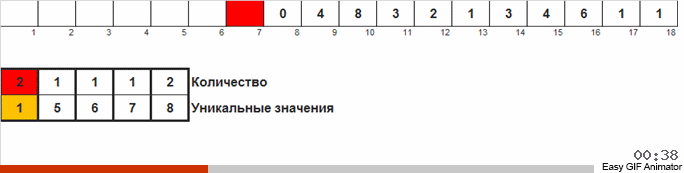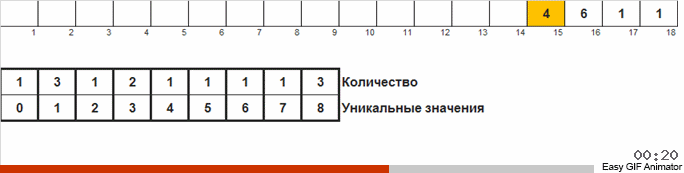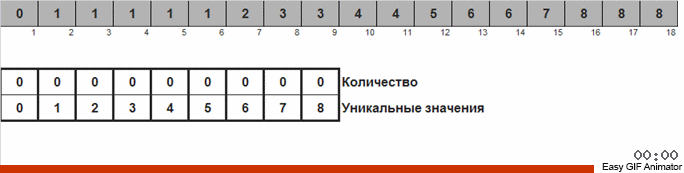
L'idée de base est que nous comptons le nombre de nombres dans chaque classe.
Tri par comptage :: Tri par comptage
Nous comptons le nombre de fois où l'un ou l'autre nombre apparaît dans le tableau. Connaissant ces quantités, nous formons rapidement un tableau déjà commandé.
Pour ce tri, vous devez connaître le minimum et le maximum dans le tableau. Ensuite, les clés sont générées pour le tableau auxiliaire, dans lequel nous fixons quoi et combien de fois il s'est rencontré.
Code Python:
def CountingSort(array, mn, mx): count = defaultdict(int) for i in array: count[i] += 1 result = [] for j in range(mn,mx+1): result += [j]* count[j] return result
Tri des pigeons :: Tri des trous de pigeon
Nous parcourons le tableau, si un nouveau numéro est trouvé, alors nous démarrons le compteur (comme clé de la liste auxiliaire) de ce numéro. Si le nombre n'est pas rencontré pour la première fois, l'incrément pour ce compteur est simplement déclenché.
La différence avec la méthode précédente est qu'en triant par comptage, nous démarrons immédiatement des compteurs pour tous les nombres possibles qui peuvent se produire dans le tableau (nous pouvons nous le permettre si le maximum et le minimum dans le tableau sont connus). Certains chiffres n'apparaissent jamais et leurs compteurs affichent zéro. Dans le tri des pigeons, nous démarrons les compteurs uniquement pour les nombres qui se produisent réellement dans le tableau. Un tableau est utilisé pour compter le tri des compteurs, et une liste doublement liée est utilisée pour le tri des pigeons, ce qui vous permet d'ajouter de nouveaux compteurs lors de vos déplacements.
Cette méthode est parfois appelée alternativement le
tri de Dirichlet , car l'algorithme lui-même est une illustration des diverses conséquences du principe de Dirichlet.
Si N objets sont répartis sur M conteneurs et N> M, alors au moins un conteneur contient plus d'un élément.
Code Python:
def PigeOnHoleSort(a): mi = min(a) size = max(a) - mi + 1 holes = [0] * size for x in a: holes[x - mi] += 1 i = 0 for count in range(size): while holes[count] > 0: holes[count] -= 1 a[i] = count + mi i += 1
Tri des bits
Nous distribuons les numéros en fonction du chiffre qui se trouve dans une catégorie particulière du numéro. Si nous le faisons plusieurs fois pour différents chiffres, nous obtenons soudainement un tableau trié.
Tri au niveau des bits de faible poids :: Tri radix LSD

Nous passons des chiffres inférieurs aux plus anciens et à chaque itération, nous distribuons les éléments du tableau en fonction du chiffre qui se trouve dans le chiffre.
Après la distribution suivante, nous renvoyons les éléments au tableau principal dans l'ordre dans lequel les éléments sont tombés dans les classes lors de la prochaine redistribution.
Pour les tris au niveau du bit, il est important que les éléments soient considérés comme ayant le même nombre de chiffres. Si le nombre réel de chiffres est différent, le problème est résolu en ajoutant des zéros supplémentaires en tant que chiffres supérieurs.
Tri au niveau des bits de haut niveau :: MSD Radix Sort

Premièrement, nous nous répartissons entre les rangs supérieurs, à partir desquels nous passons aux plus jeunes.
Cette option est plus difficile à implémenter, car la transition vers les chiffres inférieurs est effectuée de manière récursive à l'intérieur des classes, et non parmi tous les éléments du tableau.
Mais cette complexité est récompensée par le fait que le MSD est plus rapide que le LSD. Lorsque vous passez des chiffres les plus bas aux plus anciens, vous devez traiter tous les chiffres de tous les nombres afin de les trier correctement. Si vous passez de senior à junior, alors en fait vous n'avez pas à traiter tous les chiffres de tous les nombres, l'état trié, en règle générale, vient plus tôt.
La plupart des tris au niveau du bit sont une variante du MSD plus efficace. Ceci est particulièrement utile pour trier les chaînes; pour cela, un arbre de suffixes est généralement utilisé. Nous analyserons dans l'un des articles suivants.
Compter les tri au niveau du bit
Parfois, le tri de la distribution est simultanément dénombrable et au niveau du bit.
Tri des perles :: Tri des perles

Autres noms de l'algorithme: tri des bouliers, tri par gravité.
J'ai déjà écrit plusieurs fois sur ce tri (
1 ,
2 ), donc je serai bref, seulement l'essentiel.
Supposons que chaque nombre dans un tableau soit un ensemble de boules, le nombre de boules est la valeur d'un nombre. Si nous organisons les nombres les uns sur les autres sous forme de rangées horizontales de ces boules, puis les poussons verticalement, nous obtenons un tableau ordonné.
L'astuce ici est que nous représentons chaque nombre à l'aide de boules dans un système numérique unaire. Et en fait, nous comptons simplement combien de fois tous les nombres ont chaque chiffre.
BeadSort en Python sur une seule ligne:
Après un certain temps, nous analyserons des tri plus complexes au niveau du comptage, parmi lesquels le tri par
drapeau américain occupe une place de choix.
Les références
 Seau
Seau /
Seaux ,
Comptage /
Pigeonhole /
Dirichlet ,
Radix /
Discharges ,
BeadArticles de série:
L'application AlgoLab Excel a été considérablement mise à jour. Certains algorithmes de l'article d'aujourd'hui y sont apparus pour la première fois. Mettez à jour qui utilise.