Pavel Selivanov, Southbridge Solution Architect et Slurm Lecturer, a fait une présentation à DevOpsConf 2019. Ce rapport fait partie du cours approfondi de Kubernetes Slur Mega.
Slurm Basic: une introduction à Kubernetes a lieu à Moscou du 18 au 20 novembre.
Slurm Mega: Nous regardons sous le capot de Kubernetes - Moscou, 22-24 novembre.
Slurm Online: les deux cours Kubernetes sont toujours disponibles.
Sous la coupe - transcription du rapport.
Bonjour, collègues et sympathisants. Aujourd'hui, je vais parler de sécurité.
Je vois qu'il y a beaucoup de gardes de sécurité dans le hall aujourd'hui. Je m'excuse à l'avance si je n'utilise pas les termes du monde de la sécurité de la manière que vous avez acceptée.
Il se trouve qu'il y a environ six mois, je suis tombé entre les mains d'un groupe public de Kubernetes. Public - signifie qu'il existe un nième nombre d'espaces de noms, dans ces espaces de noms, il y a des utilisateurs isolés dans leur espace de noms. Tous ces utilisateurs appartiennent à différentes sociétés. Eh bien, il était supposé que ce cluster devait être utilisé comme CDN. Autrement dit, ils vous donnent un cluster, ils donnent l'utilisateur là-bas, vous allez là-bas dans votre espace de noms, déployez vos fronts.
Ils ont essayé de vendre un tel service à ma précédente entreprise. Et on m'a demandé de pousser un cluster sur le sujet - cette solution est-elle appropriée ou non?
Je suis venu dans ce cluster. On m'a donné des droits limités, un espace de noms limité. Là, les gars ont compris ce qu'était la sécurité. Ils ont lu ce que Kubernetes avait le contrôle d'accès basé sur les rôles (RBAC) - et ils l'ont tordu pour que je ne puisse pas exécuter les pods séparément du déploiement. Je ne me souviens pas de la tâche que j'essayais de résoudre en exécutant sous sans déploiement, mais je voulais vraiment exécuter juste en dessous. J’ai décidé pour la bonne chance de voir quels droits j’ai dans le cluster, ce que je peux, ce que je ne peux pas, ce qu’ils ont raté. Dans le même temps, je vais vous dire ce qu'ils ont configuré de manière incorrecte dans le RBAC.
Il se trouve que deux minutes plus tard, j'ai trouvé un administrateur dans leur cluster, j'ai regardé tous les espaces de noms voisins, j'ai vu les fronts de production des entreprises qui avaient déjà acheté le service et je suis resté bloqué. Je me suis à peine arrêté, pour ne pas venir voir quelqu'un en avant et ne mettre aucun mot obscène sur la page principale.
Je vais vous dire avec des exemples comment j'ai fait cela et comment m'en protéger.
Mais d'abord, je me présente. Je m'appelle Pavel Selivanov. Je suis architecte à Southbridge. Je comprends Kubernetes, DevOps et toutes sortes de choses fantaisistes. Les ingénieurs de Southbridge et moi construisons tout cela, et je vous conseille.
En plus de notre cœur de métier, nous avons récemment lancé des projets appelés Slory. Nous essayons d'apporter notre capacité à travailler avec Kubernetes aux masses, à enseigner aux autres comment travailler avec les K8 aussi.
De quoi je vais parler aujourd'hui. Le sujet du rapport est évident - sur la sécurité du cluster Kubernetes. Mais je veux dire tout de suite que ce sujet est très vaste - et je veux donc préciser immédiatement ce que je ne dirai pas avec certitude. Je ne parlerai pas de termes farfelus qui sont déjà cent fois trop broyés sur Internet. Tout RBAC et certificats.
Je vais parler de la façon dont mes collègues et moi en avons marre de la sécurité dans le cluster Kubernetes. Nous voyons ces problèmes à la fois avec les fournisseurs qui fournissent des clusters Kubernetes et avec les clients qui viennent chez nous. Et même avec des clients qui nous viennent d'autres sociétés de conseil en administration. Autrement dit, l'ampleur de la tragédie est très grande en fait.
Littéralement trois points, dont je parlerai aujourd'hui:
- Droits utilisateur vs droits pod. Les droits d'utilisateur et les droits de foyer ne sont pas la même chose.
- Collecte d'informations sur les clusters. Je montrerai qu'à partir du cluster, vous pouvez collecter toutes les informations dont vous avez besoin sans avoir de droits spéciaux sur ce cluster.
- Attaque DoS sur le cluster. Si nous ne pouvons pas collecter d'informations, nous pouvons dans tous les cas mettre le cluster. Je vais parler des attaques DoS sur les contrôles de cluster.
Une autre chose courante que je mentionnerai est l'endroit où j'ai tout testé, ce que je peux dire avec certitude que tout fonctionne.
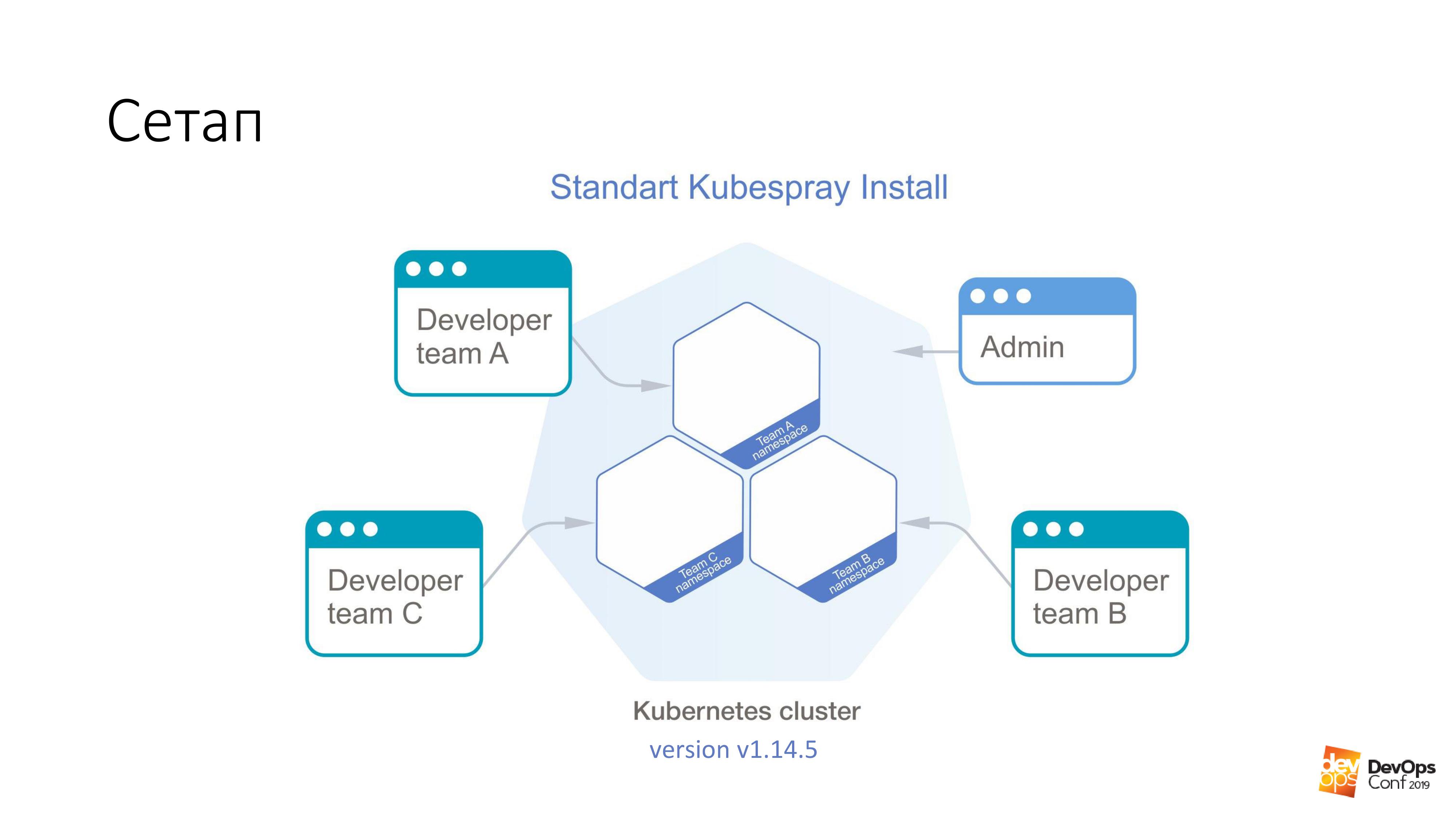
Comme base, nous prenons l'installation d'un cluster Kubernetes à l'aide de Kubespray. Si quelqu'un ne le sait pas, il s'agit en fait d'un ensemble de rôles pour Ansible. Nous l'utilisons constamment dans notre travail. La bonne chose est que vous pouvez rouler n'importe où - vous pouvez rouler sur les glandes et quelque part dans le nuage. Une méthode d'installation convient en principe à tout.
Dans ce cluster, j'aurai Kubernetes v1.14.5. L'ensemble du cluster de Cuba, que nous examinerons, est divisé en espaces de noms, chaque espace de noms appartient à une équipe distincte, les membres de cette équipe ont accès à chaque espace de noms. Ils ne peuvent pas accéder à des espaces de noms différents, mais uniquement aux leurs. Mais il existe un compte administrateur qui a des droits sur l'ensemble du cluster.
J'ai promis que la première chose que nous aurons serait d'obtenir des droits d'administrateur sur le cluster. Nous avons besoin d'un pod spécialement préparé qui cassera le cluster Kubernetes. Il nous suffit de l'appliquer au cluster Kubernetes.
kubectl apply -f pod.yaml
Ce pod arrivera chez l'un des maîtres du cluster Kubernetes. Et après cela, le cluster nous retournera avec plaisir un fichier appelé admin.conf. À Cuba, tous les certificats d'administrateur sont stockés dans ce fichier, et en même temps, l'API de cluster est configurée. C'est juste comment vous pouvez obtenir un accès administrateur, je pense, à 98% des clusters Kubernetes.
Je répète, ce pod a été créé par un développeur de votre cluster qui a accès pour déployer ses propositions dans un petit espace de noms, il est tout serré par RBAC. Il n'avait aucun droit. Néanmoins, le certificat est revenu.
Et maintenant sur le foyer spécialement préparé. Exécutez sur n'importe quelle image. Par exemple, prenez debian: jessie.
Nous avons une telle chose:
tolerations: - effect: NoSchedule operator: Exists nodeSelector: node-role.kubernetes.io/master: ""
Qu'est-ce que la tolérance? Les maîtres du cluster Kubernetes sont généralement marqués d'une chose appelée taint ("infection" en anglais). Et l'essence de cette "infection" - elle dit que les pods ne peuvent pas être assignés aux nœuds maîtres. Mais personne ne se soucie d'indiquer en aucune façon qu'il est tolérant à "l'infection". La section Tolérance dit simplement que si NoSchedule est sur un nœud, alors notre sous-infection est tolérante - et aucun problème.
De plus, nous disons que notre sous n'est pas seulement tolérant, mais veut aussi tomber spécifiquement sur le maître. Parce que les maîtres sont les plus délicieux dont nous avons besoin - tous les certificats. Par conséquent, nous disons nodeSelector - et nous avons une étiquette standard sur les assistants, ce qui nous permet de sélectionner exactement les nœuds qui sont des assistants de tous les nœuds du cluster.
Avec ces deux sections, il viendra définitivement au maître. Et il sera autorisé à y vivre.
Mais venir au maître ne nous suffit pas. Cela ne nous donnera rien. Par conséquent, nous avons en outre ces deux choses:
hostNetwork: true hostPID: true
Nous indiquons que notre sous, que nous lançons, vivra dans l'espace de noms du noyau, dans l'espace de noms du réseau et dans l'espace de noms PID. Dès qu'il démarre sur l'assistant, il pourra voir toutes les interfaces réelles et en direct de ce nœud, écouter tout le trafic et voir le PID de tous les processus.
Ensuite, c'est petit. Prenez etcd et lisez ce que vous voulez.
La plus intéressante est cette fonctionnalité Kubernetes, qui y est présente par défaut.
volumeMounts: - mountPath: /host name: host volumes: - hostPath: path: / type: Directory name: host
Et son essence est que nous pouvons dire que nous voulons créer un volume de type hostPath dans le pod que nous exécutons, même sans les droits sur ce cluster. Cela signifie prendre le chemin de l'hôte sur lequel nous allons commencer - et le prendre comme volume. Et puis appelez-le nom: hôte. Tout ce hostPath que nous montons à l'intérieur du foyer. Dans cet exemple, dans le répertoire / host.
Je répète encore une fois. Nous avons dit au pod de venir vers le maître, d'y obtenir hostNetwork et hostPID - et de monter la racine entière du maître à l'intérieur de ce pod.
Vous comprenez que dans debian, nous avons bash en cours d'exécution, et ce bash fonctionne sous notre racine. Autrement dit, nous venons d'obtenir la racine du maître, sans avoir de droits sur le cluster Kubernetes.
De plus, toute la tâche consiste à aller dans le sous-répertoire / host / etc / kubernetes / pki, si je ne me trompe pas, récupérez tous les certificats maîtres du cluster là-bas et, en conséquence, devenez l'administrateur du cluster.
Si vous regardez de cette façon, ce sont certains des droits les plus dangereux dans les pods - malgré les droits de l'utilisateur:

Si j'ai des droits d'exécution dans un espace de noms de cluster, ce sous-marin a ces droits par défaut. Je peux exécuter des pods privilégiés, et ce sont généralement tous les droits, pratiquement root sur le nœud.
Mon préféré est l'utilisateur root. Et Kubernetes a une telle option Run As Non-Root. Il s'agit d'un type de protection contre les pirates. Savez-vous ce qu'est le «virus moldave»? Si vous êtes un pirate informatique et que vous venez sur mon cluster Kubernetes, alors nous, pauvres administrateurs, demandons: «Veuillez indiquer dans vos pods avec lesquels vous allez pirater mon cluster, exécuté en tant que non root. Et il se trouve que vous démarrez le processus dans votre foyer sous la racine, et il vous sera très facile de me pirater. Veuillez vous protéger de vous-même. »
Volume du chemin de l'hôte - à mon avis, le moyen le plus rapide d'obtenir le résultat souhaité à partir du cluster Kubernetes.
Mais que faire de tout ça?
Réflexions qui devraient venir à tout administrateur normal qui rencontre Kubernetes: «Oui, je vous l'ai dit, Kubernetes ne fonctionne pas. Il y a des trous dedans. Et le cube entier est des conneries. " En fait, la documentation existe, et si vous y regardez, il y a une section Politique de sécurité des pods .
Il s'agit d'un tel objet yaml - nous pouvons le créer dans le cluster Kubernetes - qui contrôle les aspects de sécurité dans la description des foyers. Autrement dit, il contrôle ces droits pour utiliser toutes sortes de hostNetwork, hostPID, certains types de volume, qui sont dans les pods au démarrage. Avec la politique de sécurité des pods, tout cela peut être décrit.
La chose la plus intéressante dans la politique de sécurité des pods est que dans le cluster Kubernetes, tous les installateurs PSP ne sont tout simplement pas décrits en aucune façon, ils sont simplement désactivés par défaut. La politique de sécurité des pods est activée à l'aide du plug-in d'admission.
D'accord, finissons dans une politique de sécurité des pods de cluster, disons que nous avons une sorte de pods de service dans l'espace de noms, auxquels seuls les administrateurs ont accès. Disons que dans tous les autres pods, ils ont des droits limités. Parce que très probablement, les développeurs n'ont pas besoin d'exécuter des modules privilégiés dans votre cluster.
Et tout semble aller bien avec nous. Et notre cluster Kubernetes ne peut pas être piraté en deux minutes.
Il y a un problème. Très probablement, si vous avez un cluster Kubernetes, la surveillance est installée dans votre cluster. Je présume même de prédire que s'il y a une surveillance dans votre cluster, alors cela s'appelle Prométhée.
Ce que je vais vous dire maintenant sera valable à la fois pour l'opérateur Prometheus et pour le Prometheus livré sous sa forme pure. La question est que si je ne parviens pas à obtenir l’administrateur aussi rapidement dans le cluster, cela signifie que j’ai besoin de chercher plus. Et je peux rechercher en utilisant votre surveillance.
Probablement, tout le monde a lu les mêmes articles sur Habré, et la surveillance est en surveillance. Le diagramme de barre est appelé approximativement le même pour tout le monde. Je suppose que si vous installez helm stable / prometheus, vous obtiendrez approximativement les mêmes noms. Et même très probablement, je n'aurai pas à deviner le nom DNS de votre cluster. Parce que c'est standard.
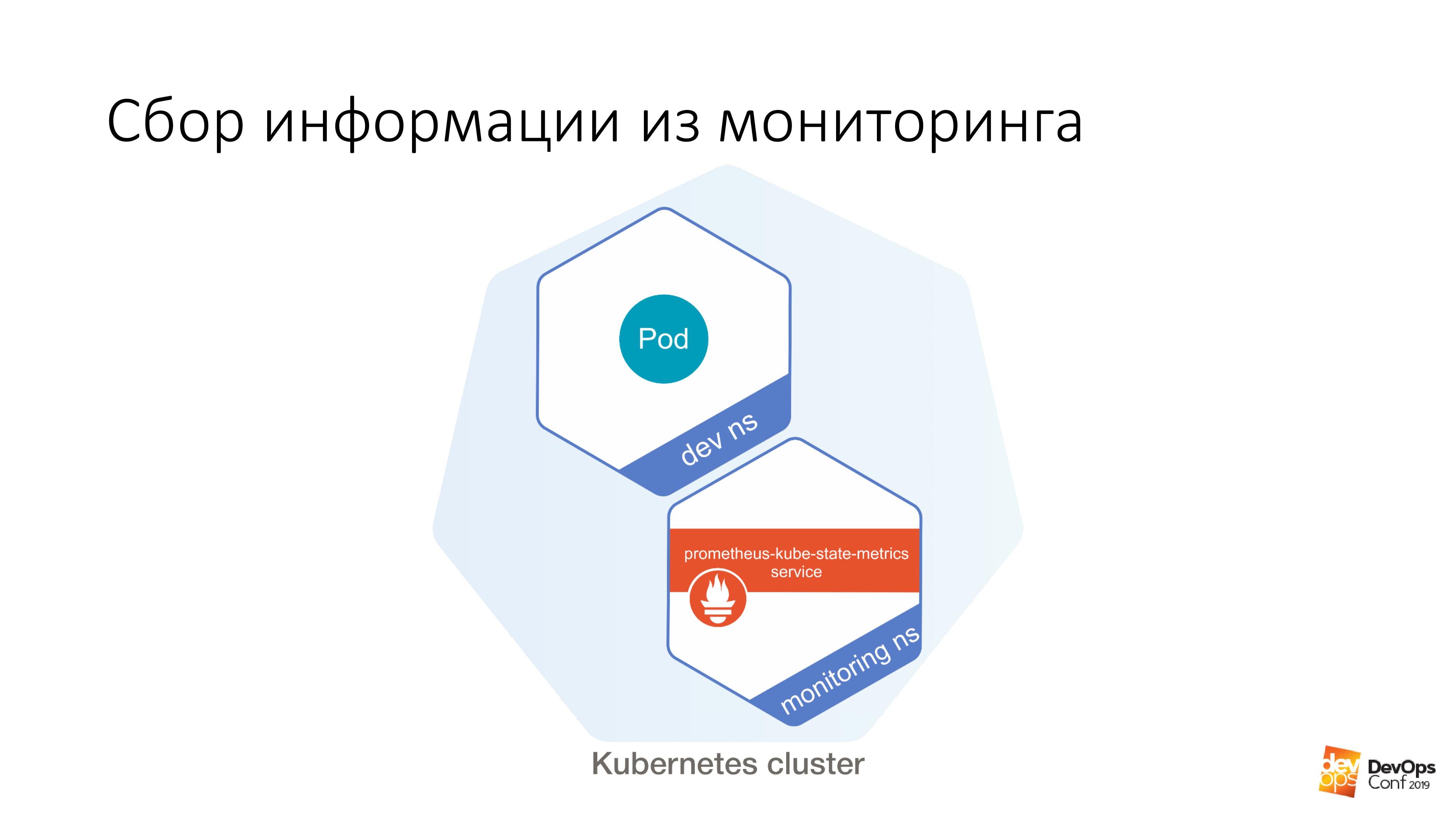
En outre, nous avons un certain dev ns, il est possible de lancer un certain sous. Et plus loin de ce foyer, il est très facile de faire comme ça:
$ curl http://prometheus-kube-state-metrics.monitoring
prometheus-kube-state-metrics est l'un des exportateurs prometheus qui collecte des métriques à partir de l'API Kubernetes. Il y a beaucoup de données qui s'exécutent dans votre cluster, ce que c'est, quels problèmes vous avez avec.
Comme exemple simple:
kube_pod_container_info {namespace = "kube-system", pod = "kube-apiserver-k8s-1", container = "kube-apiserver", image =
"gcr.io/google-containers/kube-apiserver:v1.14.5"
, Image_id = "docker-pullable: //gcr.io/google-containers/kube- apiserver @ SHA256: e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989", container_id = "docker: // 7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b"} 1
Après avoir fait une simple demande de boucle à partir d'un fichier non privilégié, vous pouvez obtenir ces informations. Si vous ne savez pas dans quelle version de Kubernetes vous utilisez, il vous le dira facilement.
Et le plus intéressant est que, outre le fait que vous vous tourniez vers les métriques d'état du kube, vous pouvez tout aussi bien appliquer directement à Prométhée lui-même. Vous pouvez collecter des métriques à partir de là. Vous pouvez même créer des métriques à partir de là. Même théoriquement, vous pouvez créer une telle demande à partir d'un cluster dans Prometheus, ce qui la désactive simplement. Et votre surveillance cesse généralement de fonctionner à partir du cluster.
Et ici, la question se pose déjà de savoir si une surveillance externe surveille votre surveillance. Je viens d'avoir l'opportunité d'agir dans le cluster Kubernetes sans aucune conséquence pour moi. Vous ne saurez même pas que j'agis là-bas, car il n'y a plus de surveillance.
Tout comme avec PSP, le problème est que toutes ces technologies à la mode - Kubernetes, Prometheus - ne fonctionnent tout simplement pas et sont pleines de trous. Pas vraiment.
Il y a une telle chose - la politique de réseau .
Si vous êtes un administrateur normal, alors très probablement à propos de la stratégie réseau, vous savez qu'il s'agit d'un autre yaml, qui dans le cluster est déjà dofig. Et certaines politiques réseau ne sont absolument pas nécessaires. Et même si vous lisez ce qu'est la stratégie réseau, qu'est-ce que le pare-feu Kubernetes yaml, il vous permet de restreindre les droits d'accès entre les espaces de noms, entre les pods, puis vous avez certainement décidé que le pare-feu de type yaml dans Kubernetes est sur les abstractions suivantes ... Non, non . Ce n'est certainement pas nécessaire.
Même si vos spécialistes de la sécurité n’ont pas été informés qu’en utilisant votre Kubernetes, vous pouvez créer un pare-feu très facilement et simplement, et il est très granulaire. S'ils ne le savent toujours pas et ne vous tirent pas: «Eh bien, donnez, donnez ...» Dans tous les cas, vous avez besoin d'une stratégie réseau pour bloquer l'accès à certains emplacements de service que vous pouvez retirer de votre cluster sans aucune autorisation.
Comme dans l'exemple que j'ai cité, vous pouvez extraire les métriques d'état du kube depuis n'importe quel espace de noms du cluster Kubernetes sans y avoir de droits. Les stratégies réseau ont fermé l'accès de tous les autres espaces de noms à la surveillance des espaces de noms et, pour ainsi dire, à tout: aucun accès, aucun problème. Dans tous les graphiques qui existent, à la fois le prometeus standard et ce prometeus qui est dans l'opérateur, il y a simplement dans les valeurs de la barre il y a une option pour simplement activer les politiques de réseau pour eux. Il vous suffit de l'activer et ils fonctionneront.
Il y a vraiment un problème ici. En tant qu'administrateur barbu normal, vous avez probablement décidé que les stratégies réseau ne sont pas nécessaires. Et après avoir lu toutes sortes d'articles sur des ressources telles que Habr, vous avez décidé que la flanelle, en particulier avec le mode passerelle hôte, était la meilleure chose que vous puissiez choisir.
Que faire
Vous pouvez essayer de redéployer la solution réseau qui se trouve dans votre cluster Kubernetes, essayez de la remplacer par quelque chose de plus fonctionnel. Sur le même Calico, par exemple. Mais immédiatement, je veux dire que la tâche de changer la solution réseau dans le cluster de travail de Kubernetes n'est pas anodine. Je l'ai résolu deux fois (les deux fois, cependant, théoriquement), mais nous avons même montré comment faire cela sur les Slurms. Pour nos étudiants, nous avons montré comment changer la solution réseau dans le cluster Kubernetes. En principe, vous pouvez essayer de vous assurer qu'il n'y a pas de temps d'arrêt sur le cluster de production. Mais vous ne réussirez probablement pas.
Et le problème est en fait résolu très simplement. Il y a des certificats dans le cluster et vous savez que vos certificats vont mal tourner dans un an. Eh bien, et généralement une solution normale avec des certificats dans le cluster - pourquoi allons-nous créer un nouveau cluster à côté de lui, le laisser pourrir dans l'ancien, et nous allons tout refaire. Certes, quand ça va mal, tout se couchera de nos jours, mais alors un nouveau cluster.
Lorsque vous soulevez un nouveau cluster, insérez en même temps Calico au lieu de flanelle.
Que faire si vous avez des certificats délivrés depuis cent ans et que vous n'allez pas recluster le cluster? Il y a une telle chose Kube-RBAC-Proxy. C'est un développement très cool, il vous permet de vous intégrer comme conteneur de sidecar à n'importe quel foyer du cluster Kubernetes. Et elle ajoute en fait une autorisation via Kubernetes RBAC à ce pod.
Il y a un problème. Auparavant, Kube-RBAC-Proxy était intégré au prometheus de l'opérateur. Mais il était parti. Désormais, les versions modernes reposent sur le fait que vous avez une stratégie réseau et que vous les fermez. Et donc vous devez réécrire un peu le graphique. En fait, si vous accédez à ce référentiel , il existe des exemples de la façon de l'utiliser comme side-cars, et vous devrez réécrire les graphiques de manière minimale.
Il y a un autre petit problème. Non seulement Prometheus donne ses métriques à toute personne qui les obtient. Nous avons également tous les composants du cluster Kubernetes, ils peuvent donner leurs métriques.
Mais comme je l'ai dit, si vous ne pouvez pas accéder au cluster et collecter des informations, vous pouvez au moins faire du mal.
Je vais donc vous montrer rapidement deux façons de gâcher votre cluster Kubernetes.
Vous allez rire quand je vous le dis, ce sont deux cas de la vraie vie.
La première façon. Manque de ressources.
Nous lançons un autre sous spécial. Il aura une telle section.
resources: requests: cpu: 4 memory: 4Gi
Comme vous le savez, les requêtes sont la quantité de CPU et de mémoire réservée sur l'hôte pour des pods spécifiques avec des requêtes. Si nous avons un hôte à quatre cœurs dans le cluster Kubernetes et que quatre CPU y arrivent avec des demandes, cela signifie qu'aucun pod supplémentaire avec des demandes à cet hôte ne peut arriver.
Si je lance ceci sous, alors je ferai une commande:
$ kubectl scale special-pod --replicas=...
Personne d'autre ne pourra alors se déployer sur le cluster Kubernetes. Parce que dans tous les nœuds, les demandes se termineront. Et donc j'arrête votre cluster Kubernetes. Si je le fais le soir, je peux arrêter le déploiement pendant un certain temps.
Si nous regardons à nouveau la documentation de Kubernetes, nous verrons une chose appelée Limit Range. Il définit des ressources pour les objets de cluster. Vous pouvez écrire un objet Limit Range dans yaml, l'appliquer à certains espaces de noms - et plus loin dans cet espace de noms, vous pouvez dire que vous avez des ressources pour les pods par défaut, maximum et minimum.
Avec l'aide d'une telle chose, nous pouvons limiter les utilisateurs dans des espaces de noms de produits spécifiques d'équipes dans la capacité d'indiquer des choses désagréables sur leurs pods. Mais malheureusement, même si vous dites à l'utilisateur qu'il est impossible d'exécuter des pods avec des demandes de plusieurs processeurs, il existe une merveilleuse commande de mise à l'échelle, ou via le tableau de bord, ils peuvent faire de la mise à l'échelle.
Et d'ici vient la méthode numéro deux. Nous lançons 11 111 111 111 111 111 foyers. C'est onze milliards. Ce n'est pas parce que j'ai trouvé un tel numéro, mais parce que je l'ai vu moi-même.
La vraie histoire. Tard dans la soirée, j'allais quitter le bureau. Je regarde, un groupe de développeurs est assis dans le coin et fait quelque chose frénétiquement avec les ordinateurs portables. Je vais voir les gars et je leur demande: "Qu'est-ce qui vous est arrivé?"
Un peu plus tôt, à neuf heures du soir, l'un des développeurs rentrait chez lui. Et il a décidé: "Je vais sauter ma candidature jusqu'à maintenant." J'ai cliqué un peu et Internet un peu terne. Il a de nouveau cliqué sur l'unité, il a appuyé sur l'unité, a cliqué sur Entrée. Poussé sur tout ce qu'il pouvait. Puis Internet a pris vie - et tout a commencé à évoluer jusqu'à cette date.
Certes, cette histoire n'a pas eu lieu sur Kubernetes, à l'époque c'était Nomad. Cela s'est terminé par le fait qu'après une heure de nos tentatives pour empêcher Nomad de tenter de rester ensemble, Nomad a répondu qu'il n'arrêterait pas de coller et ne ferait rien d'autre. "Je suis fatigué, je pars." Et recroquevillé.
J'ai naturellement essayé de faire de même sur Kubernetes. Les onze milliards de pods de Kubernetes n'étaient pas satisfaits, a-t-il déclaré: «Je ne peux pas. Dépasse les protège-dents internes. " Mais 1 000 000 000 de foyers le pouvaient.
En réponse à un milliard, le Cube n'est pas entré à l'intérieur. Il a vraiment commencé à évoluer. Plus le processus avançait, plus il lui fallait de temps pour créer de nouveaux foyers. Mais le processus continuait. Le seul problème est que si je peux exécuter des pods indéfiniment dans mon espace de noms, même sans demandes et limites, je peux démarrer un tel nombre de pods avec certaines tâches qu'avec ces tâches, les nœuds commenceront à s'additionner à partir de la mémoire, à partir du CPU. Lorsque j'exécute autant de foyers, les informations qu'ils contiennent doivent aller dans le référentiel, c'est-à-dire, etcd. Et quand trop d'informations arrivent là-bas, l'entrepôt commence à trahir trop lentement - et à Kubernetes les choses ternes commencent.
Et encore un problème ... Comme vous le savez, les éléments de contrôle de Kubernetes ne sont pas seulement une chose centrale, mais plusieurs composants. Là, en particulier, il y a un gestionnaire de contrôleur, un planificateur, etc. Tous ces gars-là commenceront à faire un travail stupide inutile en même temps, ce qui avec le temps commencera à prendre de plus en plus de temps. Le gestionnaire de contrôleur va créer de nouveaux pods. Le planificateur va essayer de leur trouver un nouveau nœud. Les nouveaux nœuds de votre cluster prendront probablement fin bientôt. Le cluster Kubernetes commencera à fonctionner plus lentement et plus lentement.
Mais j'ai décidé d'aller encore plus loin. Comme vous le savez, à Kubernetes, il existe une chose appelée service. Eh bien, et par défaut dans vos clusters, le service fonctionne probablement à l'aide de tables IP.
Si vous exécutez un milliard de foyers, par exemple, puis utilisez un script pour forcer Kubernetis à créer de nouveaux services:
for i in {1..1111111}; do kubectl expose deployment test --port 80 \ --overrides="{\"apiVersion\": \"v1\", \"metadata\": {\"name\": \"nginx$i\"}}"; done
Sur tous les nœuds du cluster, approximativement de nouvelles règles iptables seront générées approximativement simultanément. De plus, pour chaque service, un milliard de règles iptables seront générées.
J'ai vérifié tout cela sur plusieurs milliers, jusqu'à une douzaine. Et le problème est que déjà à ce seuil ssh sur le nœud est assez problématique à faire. Parce que les paquets, passant un tel nombre de chaînes, commencent à ne pas se sentir très bien.
Et tout cela est également résolu avec l'aide de Kubernetes. Il existe un tel objet quota de ressources. Définit le nombre de ressources et d'objets disponibles pour un espace de noms dans un cluster. Nous pouvons créer un objet yaml dans chaque espace de noms du cluster Kubernetes. En utilisant cet objet, nous pouvons dire que nous avons alloué un certain nombre de demandes, des limites pour cet espace de noms, puis nous pouvons dire que dans cet espace de noms, il est possible de créer 10 services et 10 pods. Et un seul développeur peut au moins se faufiler le soir. Kubernetes lui dira: "Vous ne pouvez pas tenir vos pods à un tel montant car il dépasse le quota de ressources." Tout, le problème est résolu. La documentation est ici .
Un point problématique se pose à cet égard. Vous sentez à quel point il devient difficile de créer un espace de noms dans Kubernetes. Pour le créer, nous devons considérer un tas de choses.
Quota de ressources + plage limite + RBAC
• Créer un espace de noms
• Créer une plage limite intérieure
• Créer un quota de ressources interne
• Créer un compte de service pour CI
• Créer une liaison de rôles pour CI et les utilisateurs
• Exécutez éventuellement les modules de service nécessaires
Par conséquent, saisissant cette occasion, je voudrais partager mes développements. Il existe une telle chose, appelée l'opérateur SDK. C'est un moyen dans le cluster Kubernetes d'écrire des opérateurs pour lui. Vous pouvez écrire des instructions à l'aide d'Ansible.
Tout d'abord, il a été écrit en Ansible, puis j'ai regardé qu'il y avait un opérateur SDK et j'ai réécrit le rôle Ansible dans l'opérateur. Cet opérateur vous permet de créer un objet dans le cluster Kubernetes appelé une équipe. yaml . , - .
.
. ?
. Pod Security Policy — . , , - .
Network Policy — - . , .
LimitRange/ResourceQuota — . , , . , .
, , , . .
. , warlocks , .
, , . , ResourceQuota, Pod Security Policy . .
.