Fiabilité du flash: attendue et inattendue. Partie 1. XIV conférence de l'association USENIX. Technologies de stockage de fichiersFiabilité du flash: attendue et inattendue. Partie 2. XIV conférence de l'association USENIX. Technologies de stockage de fichiers5.5. Erreurs irrécupérables et lithographie
Fait intéressant, l'effet de la lithographie sur les erreurs non corrigibles est moins clair que dans le cas du RBER, où une lithographie plus petite, comme prévu, conduit à un RBER plus élevé. Par exemple, la figure 6 montre que le modèle SLC-B a un taux de correction d'erreur plus rapide que le modèle SLC-A, bien que le SLC-B ait une lithographie plus grande (50 nm par rapport à 34 nm pour le modèle SLC-A). De plus, les modèles de la série MLC avec une taille de travail plus petite (modèle MLC-B) n'ont généralement pas de taux d'erreur fatale plus élevé que les autres modèles.
En effet, pendant le premier tiers de sa vie (le nombre de cycles PE de 0 à 1000) et dans le dernier tiers de sa vie (> 2200 cycles PE), ce modèle a une fréquence UE plus faible que, par exemple, le modèle MLC-D. Rappelez-vous que tous les lecteurs MLC et SLC utilisent le même mécanisme ECC, de sorte que ces conséquences ne peuvent pas être attribuées à des différences dans ECC.
En général, nous constatons que la lithographie a un effet moindre que prévu et un effet moindre sur les erreurs non corrigeables par rapport à ce que nous avons observé lors de l'étude de l'effet du RBER.
5.6. L'impact d'autres types d'erreurs par rapport aux erreurs non corrigibles
Déterminez si la présence d'autres erreurs augmente la probabilité d'erreurs non corrigibles.
La figure 7 montre la probabilité qu'une erreur fatale se produise au cours d'un mois donné de fonctionnement du disque, selon que différents types d'erreurs se sont produits sur le disque à un moment donné de la période de fonctionnement précédente (couleur jaune des rayures) ou du mois précédent (couleur verte des rayures), et comparaison cette probabilité avec la probabilité d'occurrence d'une erreur non corrigible (barres rouges) au cours du mois suivant.
Nous constatons que tous les types d'erreurs augmentent la probabilité d'erreurs non corrigibles. Dans ce cas, l'augmentation maximale se produit lorsque l'erreur précédente a été remarquée relativement récemment (c'est-à-dire au cours du mois précédent - les barres vertes sur le graphique sont plus élevées que le jaune) ou si l'erreur précédente était également une erreur non corrigeable. Par exemple, la probabilité qu'une erreur non corrigible se produise un mois après une autre erreur non corrigeable est de près de 30% par rapport à la probabilité de 2% de voir une erreur non corrigible au cours d'un autre mois. Mais les erreurs d'écriture finales, les méta-erreurs et les erreurs d'effacement augmentent également la probabilité des UE de plus de 5 fois.
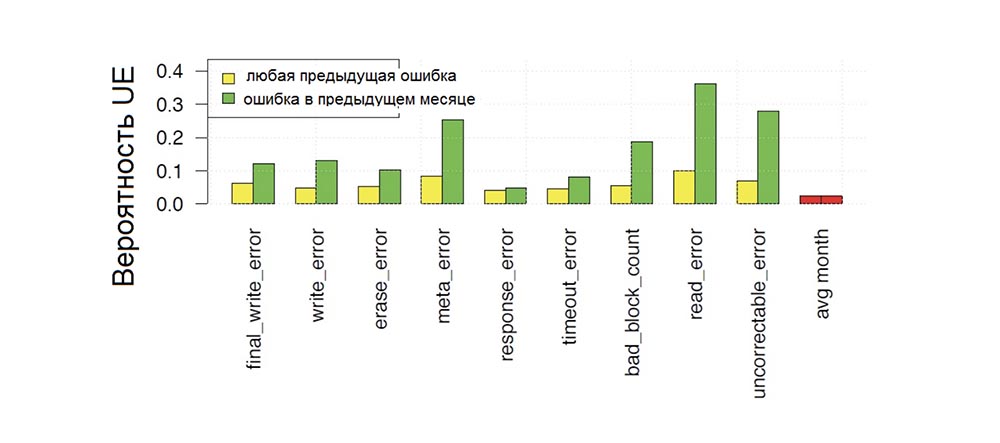 Fig. 7. La probabilité mensuelle d'apparition d'erreurs de lecteur non corrigibles en fonction de la dépendance à la présence d'erreurs antérieures de divers types.
Fig. 7. La probabilité mensuelle d'apparition d'erreurs de lecteur non corrigibles en fonction de la dépendance à la présence d'erreurs antérieures de divers types.Ainsi, les erreurs précédentes, en particulier les erreurs non corrigibles précédentes, augmentent le risque de survenue ultérieure d'erreurs non corrigibles de plus d'un ordre de grandeur.
6. Défaillances matérielles
6.1. Blocs endommagés
Un bloc est une section de mémoire dans laquelle des opérations d'effacement sont effectuées. Dans notre étude, nous faisons la distinction entre les unités qui ont été endommagées sur le terrain et celles qui avaient déjà subi des dommages en usine lorsque les disques ont été livrés aux utilisateurs.
Dans notre étude, les lecteurs ont déclaré le bloc endommagé après l'erreur finale de lecture, d'écriture ou d'effacement, et l'ont donc réaffecté (c'est-à-dire que le bloc a été exclu de toute utilisation ultérieure et toutes les données qui ont été placées dans ce bloc et qui pourraient être restaurées ont été redirigées vers un autre bloc) .
 Tab. 4. Statistiques sur la présence de blocs endommagés survenant dans les conditions de fonctionnement sur le terrain et sur la présence de blocs endommagés survenant dans le processus de fabrication d'un disque dans une usine.
Tab. 4. Statistiques sur la présence de blocs endommagés survenant dans les conditions de fonctionnement sur le terrain et sur la présence de blocs endommagés survenant dans le processus de fabrication d'un disque dans une usine.La moitié supérieure du tableau 4 donne des statistiques sur les unités endommagées dans les disques testés sur le terrain. La ligne du haut montre la proportion de disques avec des blocs endommagés pour chacun des 10 modèles de disques, la moyenne montre le nombre moyen de blocs endommagés pour les disques qui contiennent des blocs endommagés, la ligne du bas montre le nombre moyen de blocs endommagés parmi les disques avec des blocs endommagés.
Nous avons considéré uniquement les variateurs mis en production il y a au moins quatre ans, et uniquement les blocs endommagés apparus au cours des 4 premières années des tests sur le terrain. La moitié inférieure du tableau donne des statistiques sur les disques dans lesquels des blocs endommagés sont apparus lors de la fabrication en usine.
6.1.1. La présence d'unités endommagées sur le terrain
Nous sommes arrivés à la conclusion que les blocs endommagés sont fréquents: sur le terrain, selon le modèle, ils se retrouvent dans 30 à 80% des disques. L'étude de la fonction de distribution cumulative (CDF) pour le nombre de blocs de disques endommagés a montré que la plupart des disques avec des blocs endommagés n'en ont qu'un petit nombre: le nombre médian de mauvais blocs pour les disques avec des blocs endommagés varie de 2 à 4. Selon le modèle, cependant blocs du lecteur est plus que le nombre médian, alors généralement c'est beaucoup plus. Ce phénomène est illustré à la figure 8.
 Fig. 8. Figure montrant une augmentation du nombre de blocs endommagés en fonction du nombre de blocs initialement endommagés.
Fig. 8. Figure montrant une augmentation du nombre de blocs endommagés en fonction du nombre de blocs initialement endommagés.La figure 8 montre comment le nombre médian de blocs d'entraînement endommagés se développe avec une augmentation du nombre de blocs déjà endommagés. La ligne bleue correspond aux modèles MLC, les lignes rouges en pointillés correspondent aux modèles SLC. En particulier, pour les lecteurs MLC, nous observons une forte augmentation du nombre de blocs endommagés après le deuxième bloc endommagé détecté, tandis que le nombre médian passe à 200, c'est-à-dire que 50% des disques qui ont 2 blocs endommagés sont détectés, au fil du temps, 200 blocs endommagés ou plus apparaissent.
Tant que nous n'avons pas accès au comptage des erreurs au niveau de la puce, les blocs endommagés sont considérés comme des centaines, probablement en raison de défaillances de la puce elle-même, donc la figure 8 indique qu'après l'apparition de plusieurs blocs endommagés, il y a de fortes chances qu'une puce entière échoue. Ce résultat peut constituer une opportunité potentielle pour prédire les pannes de puce si vous vous basez sur les calculs précédents de blocs défectueux et prenez en compte d'autres facteurs tels que l'âge, la charge de travail et les cycles PE.
En plus de déterminer la fréquence d'apparition des blocs défectueux, nous souhaitons également savoir comment les blocs endommagés sont détectés - lors des opérations d'écriture ou d'effacement, lorsqu'une défaillance de bloc est invisible pour l'utilisateur ou lorsqu'une erreur de lecture finale est visible pour l'utilisateur et crée un risque de perte de données. Bien que nous ne disposions pas de données sur les défaillances de bloc individuelles et sur la façon dont elles ont été détectées, nous pouvons nous référer aux fréquences observées de divers types d'erreurs, qui indiquent une défaillance de bloc. En revenant au tableau 2, nous constatons que pour tous les modèles, la fréquence des erreurs d'effacement et des erreurs d'écriture est inférieure à celle des erreurs de lecture finales, c'est-à-dire que la plupart des blocs endommagés sont détectés à la suite de l'apparition d'erreurs opaques, notamment lors des opérations de lecture.
6.1.2. Unités endommagées dans l'usine
Ci-dessus, nous avons examiné la dynamique de l'apparition de blocs défectueux sur le terrain. Ici, nous notons que presque tous les disques (> 99% pour la plupart des modèles) contenaient des défauts d'usine sous la forme de blocs endommagés, et leur nombre varie considérablement entre les modèles, à partir du nombre médian inférieur à 100 pour 2 modèles SLC, et se terminant par une valeur plus typique de plus de 800 pour les autres modèles. La distribution des blocs endommagés en usine correspond à la distribution normale, tandis que les valeurs moyennes et médianes sont proches. Fait intéressant, le nombre d'unités endommagées en usine prédit dans une certaine mesure l'apparition d'autres problèmes d'entraînement sur le terrain. Par exemple, nous avons remarqué que pour tous les modèles de lecteurs sauf un, 95% des lecteurs avec des blocs défectueux d'usine ont une proportion plus élevée de nouveaux blocs endommagés sur le terrain et une proportion plus élevée d'erreurs d'écriture finale que le disque moyen du même modèles. Ils ont également une part plus élevée du développement de certains types d'erreurs de lecture (finales ou non finales). Les disques dans le percentile de 5% ont une part d'erreurs de délai d'attente inférieure à la moyenne. Ainsi, nous sommes arrivés aux conclusions suivantes concernant les blocs défectueux: les dommages aux blocs sont une occurrence assez courante observée dans 30 à 80% des disques qui ont au moins un tel bloc. Dans le même temps, il existe une forte dépendance: si le disque contient au moins 2 à 4 blocs endommagés, il y a 50% de chances que des centaines de blocs endommagés suivent. Presque tous les disques sont livrés avec des blocs endommagés en usine, ce qui permet de prédire leur développement sur le terrain, ainsi que le développement de certains autres types d'erreurs.
6.2. Puces de mémoire endommagées
Dans notre étude, on pense que la puce de disque a échoué si plus de 5% des blocs ont échoué, ou si le nombre d'erreurs de disque au cours du dernier intervalle de temps a dépassé la valeur limite. Certains lecteurs flash d'usine contiennent une puce de rechange, donc si une puce tombe en panne, le lecteur utilise la seconde. Dans notre étude, les variateurs avaient la même fonction. Au lieu de travailler sur une puce de rechange, les puces de mémoire endommagées ont été exclues de toute utilisation ultérieure, et le lecteur a continué de fonctionner avec des performances réduites sur les puces restantes.
La première ligne du tableau 5 montre la prévalence des puces endommagées. Nous constatons que 2 à 7% des disques présentent des dysfonctionnements de puce au cours des quatre premières années de fonctionnement. Les disques qui n'ont pas de mécanisme de mappage des puces endommagées nécessitent une réparation et sont renvoyés au fabricant.
 Tab. 5. La part des différents modèles de disques avec puces défectueuses nécessitant une réparation et remplacés au cours des 4 premières années d'essais sur le terrain.
Tab. 5. La part des différents modèles de disques avec puces défectueuses nécessitant une réparation et remplacés au cours des 4 premières années d'essais sur le terrain.Nous avons également examiné les symptômes qui provoquent le marquage de la puce comme défectueux: dans tous les modèles, environ les deux tiers des puces sont marquées comme endommagées après que 5% des blocs endommagés sont formés, et un tiers des puces sont marquées comme ayant échoué après avoir atteint la limite de jours avec des erreurs.
Nous avons remarqué que les fournisseurs de toutes les puces de mémoire flash pour ces disques garantissaient que le nombre de blocs endommagés par puce ne dépasserait pas 2% jusqu'à ce que la limite de cycles PE soit atteinte. Par conséquent, les deux tiers des puces défectueuses, dans lesquelles plus de 5% des blocs ont échoué, ne répondent pas à la garantie du fabricant.
6.3. Réparation et remplacement de disques
Le variateur doit être remplacé ou réparé en cas de problème nécessitant l'intervention du personnel technique. La deuxième ligne du tableau 5 indique le pourcentage de disques qui ont dû être réparés à un moment donné au cours des 4 premières années de fonctionnement. Nous observons des différences importantes dans les besoins de réparation des disques de différents modèles. Alors que pour la plupart des modèles, seuls 6 à 9% doivent être réparés à un moment donné, certains modèles de variateurs, tels que SLC-B et SLC-C, nécessitent une réparation dans 30% et 26% des cas, respectivement. En examinant la fréquence relative des réparations, c'est-à-dire le rapport entre les jours de fonctionnement du variateur et le nombre de cas de réparation, troisième rangée du tableau 5), nous observons une plage allant de quelques milliers de jours entre les événements de réparation pour les pires modèles à 15000 jours entre les réparations pour les meilleurs modèles.
Nous avons également examiné la fréquence des réparations répétées: pendant toute la période de fonctionnement, 96% des disques ne subissent qu'une seule réparation. Une étude du parc de disques d'exploitation a montré qu'environ 5% des disques étaient constamment remplacés dans les 4 ans suivant la date de mise en service (quatrième rangée du tableau 5), alors que parmi les pires modèles (MLC - B et SLC-B), environ 10% des disques. Parmi les disques remplacés, environ la moitié ont été réparés, et il était entendu qu'au moins la moitié de toutes les réparations seraient réussies.
7. Comparaison des lecteurs MLC, eMLC et SLC
Les actionneurs comme eMLC et SLC attirent le marché des consommateurs à un prix plus élevé. Outre le fait qu'ils se caractérisent par leur endurance la plus élevée, c'est-à-dire un nombre élevé de cycles de réécriture, les clients considèrent que ces produits du segment le plus élevé du SSD se caractérisent par leur fiabilité et leur durabilité générales. Dans cette section de l'article, nous avons essayé d'évaluer l'équité de cette opinion.
En retournant au tableau 3, nous voyons que cette opinion est vraie en ce qui concerne les disques SLC par rapport à RBER, car ce coefficient est d'un ordre de grandeur inférieur à celui des lecteurs MLC et eMLC. Cependant, les tableaux 2 et 5 montrent que les disques SLC n'ont pas la meilleure fiabilité: la fréquence de leur remplacement et de leur réparation, ainsi que la fréquence des erreurs opaques ne sont pas inférieures à des indicateurs similaires de disques fabriqués à l'aide d'autres technologies.
Les disques EMLC affichent des RBER plus élevés que les MLC, même si l'on considère que les limites inférieures de RBER pour les disques MLC peuvent être jusqu'à 16 fois plus élevées dans le pire des cas. Cependant, il est possible que ces différences se produisent en raison de moins de lithographie que d'autres différences technologiques. Sur la base des observations ci-dessus, nous concluons que les lecteurs SLC ne sont généralement pas plus fiables que les lecteurs MLC.
8. Comparaison avec le disque dur
La question évidente est de savoir comment la fiabilité des lecteurs flash se compare à la fiabilité de leurs principaux concurrents - les disques durs.
Nous constatons qu'en ce qui concerne la fréquence de remplacement des disques, les lecteurs flash gagnent. Selon des études antérieures menées en 2007, environ 2 à 9% du nombre total de disques durs sont remplacés chaque année, ce qui représente nettement plus de 4 à 10% des disques SSD remplacés 4 ans après le début de l'opération. Cependant, les lecteurs flash sont moins attrayants en ce qui concerne les taux d'erreur. Plus de 20% des lecteurs flash développent des erreurs irrécupérables dans les 4 ans de fonctionnement, 30 à 80% d'entre eux ont des blocs endommagés et 2 à 7% des puces échouent. Les données de l'un des articles de recherche de 2007 indiquent l'émergence de secteurs endommagés dans seulement 3,5% des disques durs sur 32 mois. C'est un nombre assez faible, mais étant donné que le nombre total de secteurs de disque dur est d'un ordre de grandeur supérieur au nombre de blocs ou de puces de SSD, et que ces secteurs sont plus petits que les blocs, les pires caractéristiques des SSD ne semblent pas si graves.
En général, nous sommes arrivés à la conclusion que les lecteurs flash doivent être remplacés beaucoup moins fréquemment au cours de la durée de vie normale que les disques durs. En revanche, par rapport aux disques durs, les SSD ont plus d'erreurs non corrigibles.
9. Autres études dans ce domaine
Il existe de nombreuses recherches sur la fiabilité des puces flash basées sur des expériences contrôlées en laboratoire avec un petit nombre de puces, axées sur l'identification des tendances des erreurs et de leurs sources. Par exemple, certains des premiers travaux de 2002-2006 ont étudié la conservation, la programmation et la violation des opérations de lecture des puces flash, et dans certains travaux récents, les tendances de l'apparition d'erreurs dans les dernières puces MLC sont étudiées. Nous nous sommes intéressés au comportement des lecteurs flash sur le terrain, de sorte que les résultats de nos observations diffèrent parfois des résultats d'études publiées précédemment. Par exemple, nous pensons que le RBER n'est pas un indicateur fiable de la probabilité d'occurrence d'erreurs non corrigibles et que le RBER croît de façon linéaire, plutôt qu'exponentielle, avec les cycles d'EP.
Il n'y a qu'une seule étude de terrain récemment publiée sur les erreurs de mémoire flash basée sur les données collectées sur Facebook - «Étude à grande échelle des défaillances de la mémoire flash sur le terrain» (MEZA, J., WU, Q., KUMAR, S., MUTLU, O. «Une étude à grande échelle des défaillances de mémoire flash sur le terrain». ) Ceci et nos recherches se complètent, car ils se chevauchent très peu.
Les données de l'étude Facebook consistent en un coup d'œil rapide sur le parc de supports flash, composé de très jeunes disques (en termes d'utilisation par rapport à la limite des valeurs du cycle PE), et ils contiennent uniquement des informations sur les erreurs fatales, tandis que notre étude est basée sur , , , , (MLC, eMLC, SLC). , .
, Facebook (, , DRAM), .
, :
- Facebook , . « » , « » « », . , « », , Facebook ( PE , PE ). ;
- Facebook , . , , , RBER .
10.
, - . , . , .
- 20 — 63% , – 6 1000 .
- , , . . , , .
- , RBER , . , RBER .
- , UBER , UE . - .
- RBER, PE, , , , , PE, .
- , , , , , , , .
- SLC, , , MLC, SSD-.
- , RBER, , , .
- , SSD , HDD, , , , .
- . , .
- : , 30-80% 2-7% . () , .
- , , , , , (, , ). , , .
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un serveur d'entrée de gamme analogique unique que nous avons inventé pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?