Je semble avoir l'habitude d'écrire sur
des machines puissantes , où de nombreux cœurs sont
inactifs en raison de verrous incorrects. Alors ... oui. Encore une fois à ce sujet.
Cette histoire est particulièrement impressionnante. En fait, à quelle fréquence avez-vous un spin de fil pendant quelques secondes dans un cycle de sept commandes, tenant un verrou qui arrête le travail de 63 autres processeurs? C'est tout simplement incroyable, dans un sens terrible.
Contrairement à la croyance populaire, je n'ai en fait pas de machine avec 64 processeurs logiques et je n'ai jamais vu ce problème particulier. Mais mon ami est tombé dessus,
ce nerd m'a accroché, il a demandé de l'aide et j'ai décidé que le problème était assez intéressant. Il a envoyé une
trace ETW avec suffisamment d'informations pour que l'esprit collectif sur Twitter ait rapidement résolu le problème.
La plainte de l'ami était assez simple: il a récupéré la construction en utilisant un
ninja . En règle générale, ninja fait un excellent travail en augmentant la charge, en prenant constamment en charge n + 2 processus pour éviter les temps d'arrêt. Mais ici, l'utilisation du CPU dans les 17 premières secondes de l'assemblage ressemblait à ceci:

Si vous regardez de plus près (une blague), vous pouvez voir une ligne mince où la charge totale du processeur passe de 100% à 0% en quelques secondes. En seulement une demi-seconde, la charge est réduite de 64 à deux ou trois fils. Voici un fragment agrandi de l'une de ces chutes - les secondes sont marquées le long de l'axe horizontal:
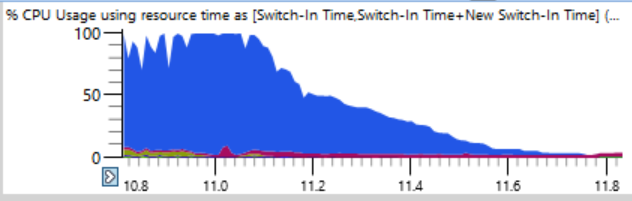
La première pensée était que le ninja ne peut pas créer rapidement des processus. Je l'ai vu plusieurs fois, généralement en raison de l'intervention d'un logiciel antivirus. Mais quand j'ai trié les graphiques à la fin, j'ai constaté que lors de tels plantages, aucun processus n'était terminé, donc ninja n'est pas à blâmer.
Le tableau d'
utilisation du processeur (précis) est idéal pour identifier la cause des temps d'arrêt. Les journaux de tous les changements de contexte y sont stockés, y compris des enregistrements précis de chaque début de flux, y compris le lieu et le délai d'expiration.
L'astuce est qu'il n'y a rien de mal avec les temps d'arrêt. Le problème se pose lorsque nous voulons vraiment que le thread fasse le travail, mais à la place, il est inactif. Par conséquent, vous devez sélectionner certains moments d'arrêt.
Lors de l'analyse, il est important de comprendre que le changement de contexte se produit lorsqu'un thread reprend l'opération. Si nous regardons ces endroits où la charge du processeur commence à tomber, nous ne trouverons rien. Au lieu de cela, concentrez-vous sur le moment où le système a recommencé à fonctionner. Cette phase de trace est encore plus dramatique. Alors que la baisse de charge du processeur prend une demi-seconde, le processus inverse d'un thread utilisé à une charge complète ne prend que douze millisecondes! Le graphique ci-dessous est assez fortement agrandi, et pourtant la transition du ralenti au chargement est presque une ligne verticale:

J'ai zoomé sur douze millisecondes et trouvé 500 changements de contexte, une analyse minutieuse est requise ici.
La table de changement de contexte a de nombreuses colonnes que j'ai
documentées ici . Lorsqu'un processus se bloque, pour en trouver la raison, je fais un regroupement par nouveaux processus, nouveaux threads, nouvelles piles de threads, etc. (
discuté ici ), mais cela ne fonctionne pas sur des centaines de processus arrêtés. Si j'ai étudié un mauvais processus, il est clair qu'il a été préparé par le processus précédent, qui a été préparé par le précédent, et je balayerais une longue chaîne pour trouver le premier maillon qui (vraisemblablement) détient un verrou important pendant longtemps.
J'ai donc essayé une disposition de colonne différente dans le programme:
- Heure d'entrée (lorsque le changement de contexte s'est produit)
- Processus de préparation (qui a libéré le verrou après avoir attendu)
- Nouveau processus (qui a commencé à travailler)
- Temps depuis la dernière (depuis combien de temps le nouveau processus attend)
Cela donne une liste chronologique de changements de contexte avec une note de qui a préparé qui et combien de temps les processus étaient prêts à fonctionner.
Il s'est avéré que cela suffisait. Le tableau ci-dessous parle de lui-même si vous savez le lire. Les premiers changements de contexte ne sont pas intéressants, car le temps d'attente pour un nouveau processus (Time Since Last) est assez petit, mais sur la ligne en surbrillance (# 4) une chose intéressante commence:
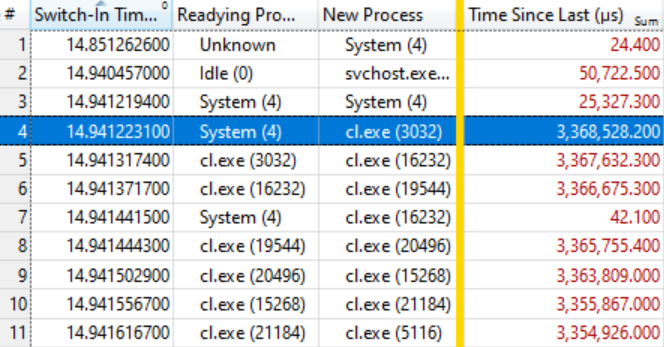
Cette ligne indique que
System (4) a préparé le
cl Exe (3032) , qui a attendu 3,386 secondes. La ligne suivante indique qu'en moins de 0,1 ms,
cl. Exe (3032) a préparé
cl.exe (16232) , qui a attendu 3,367 secondes. Et ainsi de suite.
Plusieurs commutateurs de contexte, comme dans la ligne # 7, ne sont pas inclus dans la chaîne d'attente, mais reflètent simplement d'autres travaux dans le système, mais en général, la chaîne est étendue à plusieurs dizaines d'éléments.
Cela signifie que tous ces processus attendent la libération du même verrou. Lorsque le processus
System (4) libère le verrou (après l'avoir maintenu pendant 3.368 secondes!), Les processus en attente, à leur tour, le capturent, font leur petit travail et transmettent le verrou. La file d'attente comporte une centaine de processus, ce qui montre le degré d'influence d'un seul verrou.
Une petite étude de
Ready Thread Stacks a montré que la plupart des attentes proviennent de
KernelBase.dllWriteFile . J'ai demandé à WPA d'afficher les appelants de cette fonction, avec regroupement. Là, vous pouvez voir qu'en 12 millisecondes de cette catharsis 174 threads sortent de
WriteFile en attente, et ils ont attendu en moyenne 1184 secondes:
 174 threads en attente de WriteFile, temps d'attente moyen de 1 184 secondes
174 threads en attente de WriteFile, temps d'attente moyen de 1 184 secondesIl s'agit d'un décalage étonnant, et en fait, même pas toute l'étendue du problème, car de nombreux threads d'autres fonctions, telles que
KernelBase.dll! GetQueuedCompletionStatus, attendent la libération du même verrou.
Que fait le système (4)
À ce stade, je savais que la progression de la construction s'arrêtait car tous les processus du compilateur et d'autres attendaient
WriteFile , car
System (4) détenait le verrou. Une autre colonne
Ready Thread Id a montré que le thread 3276 a déverrouillé le processus système.
Pendant tous les «blocages» de l'assemblage, le thread 3276 était chargé à 100%, il est donc clair qu'il a fait un peu de travail sur le CPU tout en maintenant le verrou. Pour savoir où le temps processeur est dépensé, regardons le
graphique d'
utilisation du
processeur (échantillonné) pour le thread 3276. Les données d'utilisation du processeur étaient étonnamment claires. Presque tout le temps nécessaire au travail d'une fonction
ntoskrnl.exe! RtlFindNextForwardRunClear (le nombre d'échantillons est indiqué dans la colonne avec des nombres):
 La pile d'appels mène à ntoskrnl.exe! RtlFindNextForwardRunClear
La pile d'appels mène à ntoskrnl.exe! RtlFindNextForwardRunClearLa visualisation de la pile de
threads Readying Thread Id a confirmé que
NtfsCheckpointVolume a libéré le verrou après 3,368 s:
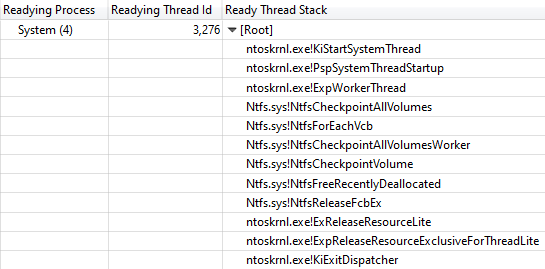 Pile d'appels de NtfsCheckpointVolume à ExReleaseResourceLite
Pile d'appels de NtfsCheckpointVolume à ExReleaseResourceLiteEn ce moment, il m'a semblé qu'il était temps d'utiliser la riche connaissance de mes followers sur Twitter, j'ai donc posté
cette question et montré une pile complète d'appels. Les tweets contenant de telles questions peuvent être très efficaces si vous fournissez suffisamment d'informations.
Dans ce cas, la
bonne réponse de
Caitlin Gadd est arrivée très rapidement, ainsi que de nombreuses autres excellentes suggestions. Elle a désactivé la fonction de récupération du système - et soudain, la construction est allée deux à trois fois plus vite!
Mais attendez, plus c'est encore mieux
Bloquer l'exécution dans tout le système pendant plus de 3 secondes est assez impressionnant, mais la situation est encore plus impressionnante si vous ajoutez la colonne
Adresse à la table
Utilisation du
processeur (échantillonnée) et triez-la. Il montre où exactement les échantillons
RtlFindNextForwardRunClear obtiennent - et 99% d'entre eux tombent sur une instruction!

J'ai pris les
fichiers ntoskrnl.exe et
ntkrnlmp.pdb (la même version que mon ami) et
dumpbin /disasm exécuté
dumpbin /disasm pour afficher la fonction d'intérêt dans l'assembleur. Les premiers chiffres des adresses sont différents car le code se déplace au démarrage, mais les quatre dernières valeurs hexadécimales sont les mêmes (elles ne changent pas après ASLR):
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx
140064652: 73 0F jae 0000000140064663
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663
140064659: 49 83 C0 04 add r8.4
14006465D: 41 83 C1 20 add r9d, 20h
140064661: EB EC jmp 000000014006464F
...
Nous voyons que l'instruction sur ... 4657 est incluse dans un cycle de sept instructions, qui se trouvent dans d'autres exemples. Le nombre de ces échantillons est indiqué à droite:
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx 4
140064652: 73 0F jae 0000000140064663 41
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663 7498
140064659: 49 83 C0 04 add r8.4 2
14006465D: 41 83 C1 20 add r9d, 20h 1
140064661: EB EC jmp 000000014006464F 1
...
En tant qu'exercice pour le lecteur, laissons l'interprétation du nombre d'échantillons sur un processeur superscalaire avec une exécution extraordinaire des instructions, bien que quelques bonnes idées puissent être trouvées dans
cet article . Dans ce cas, nous avons un AMD Ryzen Threadripper à 32 cœurs 2990WX. Apparemment, la fonction de processeur de Micro-Up Fusion avec l'exécution de cinq instructions à la fois permet en fait de terminer chaque cycle sur jne, car l'instruction après l'instruction la plus chère tombe dans la majorité des interruptions de la sélection.
Il s'avère donc qu'une machine avec 64 processeurs logiques s'arrête dans un cycle de sept commandes dans le processus système, tout en maintenant un verrou NTFS vital, qui est corrigé en désactivant la récupération du système.
Coda
Il n'est pas clair pourquoi ce code s'est mal comporté sur cette machine particulière. Je suppose que cela est en quelque sorte lié à la distribution des données sur un disque de 2 To presque vide. Lorsque la récupération du système a été réactivée, le problème est également revenu, mais pas si grave. Peut-être existe-t-il une sorte de pathologie pour les disques avec d'énormes fragments d'espace vide?
Un autre abonné sur Twitter a mentionné le bogue Volume Shadow Copy de Windows 7, qui permet l'
exécution pendant O (n ^ 2) . Cette erreur aurait été corrigée dans Windows 8, mais elle aurait pu être conservée sous une forme ou une autre. Mes traces de pile montrent clairement que
VspUpperFindNextForwardRunClearLimited (recherche d'un bit utilisé dans cette zone de 16 mégaoctets) appelle
VspUpperFindNextForwardRunClear (recherche le prochain bit utilisé n'importe où, mais ne le renvoie pas s'il se trouve en dehors de la zone spécifiée). Bien sûr, cela provoque un certain sentiment de déjà-vu. Comme je l'ai
dit récemment , O (n ^ 2) est un point faible d'algorithmes peu évolutifs. Deux facteurs coïncident ici: un tel code est assez rapide pour entrer en production, mais assez lent pour abandonner cette production.
Il y a eu des rapports qu'un problème similaire se produit avec une
suppression massive de fichiers , mais notre trace ne montre pas beaucoup de suppressions, donc le problème, apparemment, n'est pas celui-là.
En conclusion, je vais dupliquer le calendrier de charge du processeur à l'échelle du système depuis le début de l'article, mais cette fois en indiquant l'utilisation du processeur par le processus de problème
système (en vert ci-dessous). Dans une telle image, le problème est complètement évident. Le processus du système est techniquement visible sur le graphique du haut, mais à cette échelle, il est facile de le manquer.
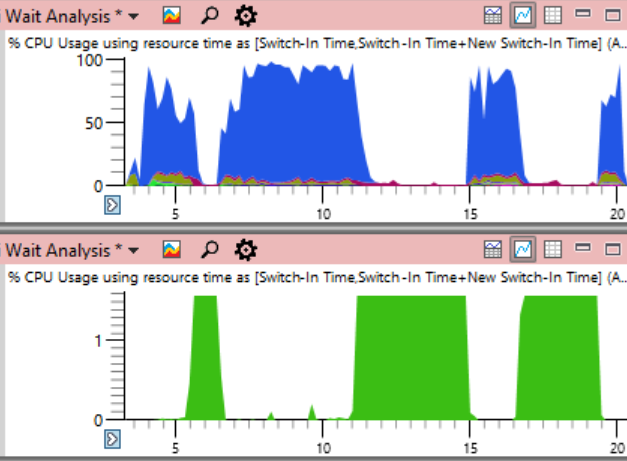
Bien que le problème soit clairement visible sur le graphique, il ne prouve en fait rien.
Comme on dit , la corrélation n'est pas une relation causale. Seule une analyse des événements de changement de contexte montre que c'est ce flux qui détient le verrou critique - et alors vous pouvez être sûr que nous avons trouvé la cause réelle, et pas seulement une corrélation aléatoire.
Demandes
Comme d'habitude, je termine cette enquête par un
appel à mieux nommer les threads . Le processus système a des dizaines de threads, dont beaucoup ont un but spécial, et aucun n'a de nom. Le thread système le plus occupé dans cette trace était
MiZeroPageThread . J'ai plongé à plusieurs reprises dans sa pile, et à chaque fois je me suis rappelé que ça ne m'intéressait pas. Le compilateur VC ++ ne nomme pas non plus ses threads. Il ne faut pas beaucoup de temps pour renommer les flux, et c'est vraiment utile. Donnez simplement le nom.
C'est simple . Chromium inclut même un outil pour
répertorier les noms de flux dans un processus .
Si quelqu'un de l'équipe NTFS de Microsoft souhaite parler de ce sujet, faites-le moi savoir et je pourrai vous mettre en relation avec l'auteur du rapport d'origine et fournir une trace ETW.
Les références