
Bonjour, Habr! Nous continuons à publier des critiques d'articles scientifiques de membres de la communauté Open Data Science sur la chaîne #article_essense. Si vous souhaitez les recevoir avant tout le monde - rejoignez la communauté !
Articles pour aujourd'hui:
- La rotation des couches: un indicateur étonnamment puissant de généralisation dans les réseaux profonds? (Université catholique de Louvain, Belgique, 2018)
- Apprentissage par transfert à paramètres efficaces pour la PNL (Google Research, Jagiellonian University, 2019)
- RoBERTa: A Robustly Optimized BERT Pretraining Approach (Université de Washington, Facebook AI, 2019)
- EfficientNet: repenser la mise à l'échelle du modèle pour les réseaux de neurones convolutifs (Google Research, 2019)
- Comment le cerveau passe de la perception consciente à la perception subliminale (États-Unis, Argentine, Espagne, 2019)
- Grandes couches de mémoire avec clés de produit (Facebook AI Research, 2019)
- Faisons-nous vraiment beaucoup de progrès? Une analyse inquiétante des approches récentes de recommandation neuronale (Politecnico di Milano, Université de Klagenfurt, 2019)
- Apprentissage des fonctionnalités omnidimensionnelles pour la ré-identification des personnes (Université de Surrey, Université Queen Mary, Samsung AI, 2019)
- La reparamétrie neuronale améliore l'optimisation structurelle (Google Research, 2019)
Liens vers les anciennes collections de la série: 1. La rotation des couches: un indicateur étonnamment puissant de généralisation dans les réseaux profonds?
Auteurs: Simon Carbonnelle, Christophe De Vleeschouwer (Université catholique de Louvain, Belgique, 2018)
→ Article original
Auteur de la revue: Svyatoslav Skoblov (in slack error_derivative)

Dans cet article, les auteurs ont attiré l'attention sur une observation assez simple: la distance cosinus entre les poids des couches lors de l'initialisation et après la formation (le processus d'augmentation de la distance pendant la formation est appelé rotation des couches). Les messieurs disent que dans la plupart des expériences, les réseaux qui ont atteint une distance de 1 dans toutes les couches sont constamment supérieurs en précision aux autres configurations. L'article présente également l'algorithme Layca (Layer-level Controlled Amount of weight rotation), qui permet d'utiliser ce taux d'apprentissage par couche pour contrôler cette même rotation de couche. En fait, il diffère de l'algorithme SGD habituel par la présence d'une projection orthogonale et d'une normalisation. Une liste détaillée de l'algorithme avec le programme de formation peut être trouvée dans l'article.
L'idée principale que les auteurs en déduisent est la suivante: plus les rotations de couches sont importantes, meilleures sont les performances de généralisation . La plupart de l'article est un enregistrement d'expériences où divers scénarios de formation ont été étudiés: MNIST, CIFAR-10 / CIFAR-100, de minuscules ImageNet avec différentes architectures ont été utilisés, d'un réseau monocouche à la famille ResNet.
Une série d'expériences s'est déroulée en plusieurs étapes:
- Vanilla SGD Il s'est avéré que, dans l'ensemble, le comportement des échelles coïncide avec l'hypothèse (de grands changements de distance correspondaient aux meilleures valeurs métriques), mais des problèmes ont également été constatés: la rotation des couches s'est arrêtée bien avant les valeurs souhaitées; une instabilité dans le changement de distance a également été notée.
- SGD + décroissance du poids La diminution de la norme de poids a considérablement amélioré l'image de la formation: la plupart des couches ont atteint la distance maximale et les performances du test sont similaires à celles du Layca proposé. L’avantage incontestable de la méthode de l’auteur est l’absence d’un hyperparamètre supplémentaire.
- Échauffements LR Il s'est avéré que l'échauffement aide SGD à surmonter le problème de la rotation des couches instable, cependant, cela n'a aucun effet sur Layca.
- Méthodes adaptatives de gradient En plus de la vérité bien connue (en utilisant ces méthodes, il est plus difficile d'atteindre le niveau de généralisation que SGD + la décroissance de poids peut donner), il s'est avéré que les effets de la rotation des couches sont très différents: la première augmente la rotation dans les dernières couches, tandis que la SGD dans les couches initiales . Les auteurs suggèrent que cela peut être la méchanceté des méthodes adaptatives. Et ils suggèrent d'utiliser Layca en conjonction avec eux (améliorant la capacité de généraliser dans les méthodes adaptatives et accélérant l'apprentissage dans SGD).
L'article se termine par une tentative d'interprétation du phénomène. Pour ce faire, les auteurs ont formé un réseau avec 1 couche cachée sur une version dépouillée de MNIST, après quoi ils ont visualisé des neurones aléatoires, aboutissant à une conclusion tout à fait logique: un plus grand degré de rotation des couches correspond à un moindre effet d'initialisation et à une meilleure étude des caractéristiques, ce qui contribue à une meilleure généralisation.
Le code de l'algorithme implémenté (tf / keras) et le code de reproduction des expériences sont téléchargés .
2. Apprentissage de transfert à paramètres efficaces pour la PNL
Auteurs de l'article: Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly (Google Research, Jagiellonian University, 2019)
→ Article original
Auteur de la revue: Alexey Karnachev (in slack zhirzemli)
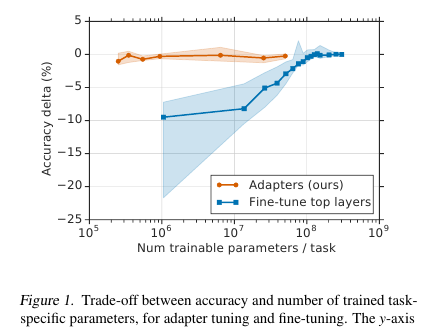
Ici, les messieurs offrent une technique de réglage fin simple mais efficace pour les modèles NLP (dans ce cas, BERT). L'idée est d'incorporer des couches d'apprentissage (adaptateurs) directement dans le réseau. Chacune de ces couches est un réseau avec un goulot d'étranglement, qui adapte les états latents du modèle d'origine à une tâche en aval spécifique. Les poids du modèle d'origine, quant à eux, restent figés.
La motivation
Dans les conditions de la formation en streaming (ou de la formation quasi en ligne), où il y a beaucoup de tâches en aval, je n'ai pas vraiment envie de classer l'intégralité du modèle. Premièrement, pendant longtemps, et deuxièmement, c'est difficile, et troisièmement, même s'il est serré, le modèle doit être en quelque sorte stocké: pour vider ou pour garder en mémoire. Et nous ne serons pas en mesure de réutiliser ce modèle pour la tâche suivante: chaque fois que nous devons régler une nouvelle manière. En conséquence, nous pouvons essayer d'adapter les états de réseau cachés au problème actuel. De plus, le modèle d'origine reste intact et les adaptateurs eux-mêmes sont beaucoup plus volumineux que le modèle principal (~ 4% du nombre total de paramètres)
Implémentation
Le problème est résolu d'une manière incroyablement simple: nous ajoutons 2 adaptateurs à chaque couche du modèle. Avant la normalisation des couches dans les modèles à transformateur, une connexion par saut se produit: l'entrée transformée (état masqué actuel) est ajoutée à l'entrée d'origine.
Il y a 2 sections de ce type dans chaque couche de transformateur: une après une attention multi-têtes, la seconde après une alimentation directe. Ainsi, les états cachés de ces sections sont également transmis via l'adaptateur: un réseau peu profond avec une couche cachée à 1 goulot d'étranglement et avec une sortie de la même dimension que l'entrée. La non-linéarité est appliquée à l'état de goulot d'étranglement et l'entrée (saut de connexion) est ajoutée à la sortie. Il s'avère que le nombre total de paramètres entraînés est: 2md + m + d, où d est la dimension de l'état caché du modèle d'origine, m est la taille de la couche d'adaptateur de goulot d'étranglement. Il s'avère que pour le modèle de base BERT (12 couches, paramètres 110M) et pour la taille de l'adaptateur bottlneck'a 128, nous obtenons 4,3% du nombre total de paramètres
Résultats
La comparaison a été faite avec le réglage complet du modèle. Pour toutes les tâches, cette approche a montré une perte mineure de métriques (en moyenne moins de 1 point), avec le nombre de poids formés - 3% du total. Je n'énumérerai pas les tâches elles-mêmes, il y en a beaucoup, il y a une tablette dans l'article.
Réglage fin
Dans ce modèle, seule la partie adaptateur est réglée (+ le classificateur de sortie lui-même). Pour les échelles d'adaptateurs, ils proposent de faire une initialisation proche de l'identité. Ainsi, un modèle non formé ne changera en rien les états de réseau cachés, ce qui permettra déjà au processus de formation du modèle de décider quels états s'adapter à la tâche et lesquels rester inchangés.
Le taux d'apprentissage recommande de prendre plus qu'avec le réglage fin BERT standard. Personnellement, sur ma tâche, 1e-04 lr a bien fonctionné. De plus, (déjà personnellement mon observation) pendant le processus de réglage, le modèle explose presque toujours les gradients, vous devez donc vous rappeler de faire un écrêtage. Optimiseur - Adam avec échauffement 10%
Code
Le code de leur article est joint. Implémentation sur Tensorflow .
Pour Torch, l'auteur de la revue fork-pytorch-transformers et a ajouté une couche Adaptateur (au début du fichier README.md il y a un petit manuel de lancement)
3. RoBERTa: une approche de pré-formation BERT robuste et optimisée
Auteurs de l'article: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov (University of Washington, Facebook AI, 2019)
→ Article original
Auteur de la revue: Artem Rodichev (in slack fuckai)
Améliore considérablement la qualité des modèles BERT, première place sur le classement GLUE et SOTA sur de nombreuses tâches PNL. Ils ont suggéré un certain nombre de façons de former le modèle BERT le mieux possible sans aucune modification de l'architecture du modèle lui-même.
Différences clés avec le BERT d'origine:
- Augmentation de la construction des trains 10 fois, de 16 Go de texte brut à 160 Go
- Masquage dynamique fait pour chaque échantillon
- Suppression de l'utilisation de la prédiction de la peine suivante de la perte
- Augmentation de la taille du mini-lot de 256 échantillons à 8k
- Amélioration du codage BPE en convertissant la base de données d'Unicode en octets.
Le meilleur modèle final a été formé sur 1024 cartes Nvidia V100 (128 serveurs DGX-1) pendant 5 jours.
L'essence de l'approche:
Données. En plus des coquilles Wiki et BookCorpus (16 Go au total), qui enseignaient le BERT original, ils ont ajouté 3 autres coquilles plus grandes, toutes en anglais:
- SS-News 63 millions de nouvelles en 2,5 ans sur 76 Go
- OpenWebText est le cadre sur lequel OpenAI a appris le modèle GPT2. Ce sont des articles analysés auxquels des liens ont été fournis dans des publications sur un reddit avec au moins trois mises à jour. 38 Go de données
- Histoires - 31GB CommonCrawl Story Case
Masquage dynamique. Dans le BERT d'origine, 15% des jetons sont masqués dans chaque échantillon et ces jetons sont prédits à l'aide de la partie non masquée de la séquence. Un masque est généré une fois pour chaque échantillon pendant le prétraitement et ne change pas. Dans le même temps, le même échantillon dans le train peut se produire plusieurs fois, selon le nombre d'époques dans le corps. L'idée du masquage dynamique est de créer un nouveau masque pour la séquence à chaque fois, plutôt que d'utiliser un masque fixe en prétraitement.
Objectif de prédiction de la phrase suivante. Disons simplement couper cet objektiv et voir si cela a empiré? Est-il devenu meilleur ou est-il également resté - sur les tâches SQuAD, MNLI, SST et RACE.
Augmentez la taille du mini-lot. Dans de nombreux endroits, en particulier dans la traduction automatique, il a été démontré que plus le mini-lot est grand, meilleurs sont les résultats finaux du train. Ils ont montré que si vous augmentez le minibatch de 256 échantillons, comme dans le BERT d'origine, à 2k, puis à 8k, alors la perplexité sur les baisses de validation et les métriques sur MNLI et SST-2 augmentent.
BPE Le BPE de l'implémentation BERT d'origine utilise des caractères Unicode comme base pour les unités de sous-mots. Cela conduit au fait que dans des cas importants et divers, une partie importante du dictionnaire sera occupée par des caractères Unicode individuels. OpenAI de retour dans GPT2 a suggéré d'utiliser non pas des caractères Unicode, mais des octets comme base pour les sous-mots. Si nous utilisons un dictionnaire BPE de 50k, nous n'aurons pas de tokens inconnus. Par rapport au BERT d'origine, la taille du modèle a augmenté de 15 M paramètres pour le modèle de base et de 20 M pour les grands, soit 5 à 10% de plus.
Résultats:
BERT-large et XLNet-large sont utilisés comme modèles de comparaison. RoBERTa lui-même est le même en termes de paramètres que BERT-large, ce qui lui a valu la première place sur le benchmark GLUE. Nous avons utilisé l'optimisation de fichiers à tâche unique, contrairement à de nombreuses autres approches du référentiel GLUE qui effectuent l'optimisation de fichiers à tâches multiples. Sur les filles dans GLUE, les résultats d'un modèle unique sont comparés, ils ont obtenu SOTA sur les 9 tâches. Sur l'ensemble de test, l'ensemble des modèles est comparé, SOTA pour 4 des 9 tâches et la vitesse de colle finale. Sur deux versions de SQuAD sur le réseau de développement SOTA, sur l'ensemble de test au niveau XLNet. De plus, contrairement à XLNet, ils ne se font pas prendre par des packages QA supplémentaires avant de résoudre SQuAD.

SOTA sur la tâche RACE dans laquelle un morceau de texte est donné, une question sur ce texte et 4 options de réponse où vous devez choisir la bonne. Pour résoudre cette tâche, ils concaténent le texte, la question et la réponse, parcourent BERT, obtiennent une représentation du jeton CLF, s'appliquent à une couche entièrement connectée et prédisent si la réponse est correcte. Cette opération est effectuée 4 fois - pour chacune des options de réponse.
Nous avons affiché le code et la pré-formation du modèle RoBERTa dans navet fairseq . Vous pouvez l'utiliser, tout semble net et simple.
4. EfficientNet: repenser la mise à l'échelle du modèle pour les réseaux de neurones convolutifs
Auteurs: Mingxing Tan, Quoc V. Le (Google Research, 2019)
→ Article original
Auteur de la revue: Alexander Denisenko (en mou Alexander Denisenko)

Ils étudient la mise à l'échelle (mise à l'échelle) des modèles et l'équilibre entre eux-mêmes la profondeur et la largeur (nombre de canaux) du réseau, ainsi que la résolution des images dans la grille. Ils offrent une nouvelle méthode de mise à l'échelle qui met uniformément à l'échelle la profondeur / largeur / résolution. Montrez son efficacité sur MobileNet et ResNet.
Ils utilisent également Neural Architecture Search pour créer un nouveau maillage et le mettre à l'échelle, obtenant ainsi une classe de nouveaux modèles - EfficientNets. Ils sont meilleurs et beaucoup plus économiques que les grilles précédentes. Sur ImageNet, EfficientNet-B7 atteint une précision de pointe de 84,4% dans le top 1 et 97,1% dans le top 5, soit 8,4 fois moins et 6,1 fois plus rapidement en inférence que le ConvNet, le meilleur de sa catégorie. Il se transfère bien à d'autres ensembles de données - ils ont obtenu SOTA sur 5 des 8 ensembles de données les plus populaires.
Mise à l'échelle du modèle composé
La mise à l'échelle est lorsque les opérations effectuées à l'intérieur de la grille sont fixes et que la profondeur (nombre de répétitions des mêmes modules) d, la largeur (nombre de canaux en convolution) w et la résolution r sont modifiées. Dans le pageur, la mise à l'échelle est formulée comme un problème d'optimisation - nous voulons la précision maximale (Net (d, w, r)) malgré le fait que nous n'explorions pas de mémoire et FLOPS.
Nous avons mené des expériences et nous avons veillé à ce que cela aide également à l'échelle en profondeur et en résolution lors de l'échelle en largeur. Avec les mêmes FLOPS, nous obtenons un résultat nettement meilleur sur ImageNet (voir l'image ci-dessus). En général, cela est raisonnable, car il semble qu'avec une augmentation de la résolution de l'image du réseau, plus de couches sont nécessaires en profondeur pour augmenter le champ récepteur et plus de canaux afin de capturer tous les motifs de l'image avec une résolution plus élevée.
L'essence de la mise à l'échelle composée: nous prenons le coefficient composé phi, qui met uniformément à l'échelle d, w et r avec ce coefficient: où - constantes obtenues à partir d'une petite vue de grille sur la grille source. - coefficient caractérisant la quantité de ressources informatiques disponibles.
Filet efficace
Pour créer la grille, nous avons utilisé la recherche d'architecture neuronale multi-objectifs, la précision optimisée et les FLOPS avec le paramètre responsable du compromis entre eux. Une telle recherche a donné EfficientNet-B0. En bref - Conv suivi de plusieurs MBConv, à la fin de Conv1x1, Pool, FC.
Effectuez ensuite la mise à l'échelle en deux étapes:
- Pour commencer, nous réparons , faire une recherche dans la grille pour rechercher .
- Mettez la grille à l'échelle en utilisant les formules pour d, w et r. Vous avez EffiientNet-B1. De même, l'augmentation , obtenez EfficientNet-B2, ... B7.
Mis à l'échelle pour différents ResNet et MobileNet, partout a reçu des améliorations significatives sur ImageNet, la mise à l'échelle composée a donné une augmentation significative par rapport à la mise à l'échelle dans une seule dimension. Nous avons également mené des expériences avec EfficientNet sur huit ensembles de données plus populaires, partout où nous avons obtenu SOTA ou un résultat proche avec un nombre de paramètres considérablement plus petit.
Code
5. Comment le cerveau passe de la perception consciente à la perception subliminale
Auteurs de l'article: Francesca Arese Lucini, Gino Del Ferraro, Mariano Sigman, Hernan A. Makse (États-Unis, Argentine, Espagne, 2019)
→ Article original
Auteur de la revue: Svyatoslav Skoblov (in slack error_derivative)
Cet article est une continuation et une refonte du travail de Dehaene, S, Naccache, L, Cohen, L, Le Bihan, D, Mangin, JF, Poline, JB, & Rivie`re, D.Mécanismes cérébraux de masquage de mots et d'amorçage de répétition inconsciente , dans que les auteurs ont essayé de considérer les modes de fonctionnement cérébral conscient et inconscient.
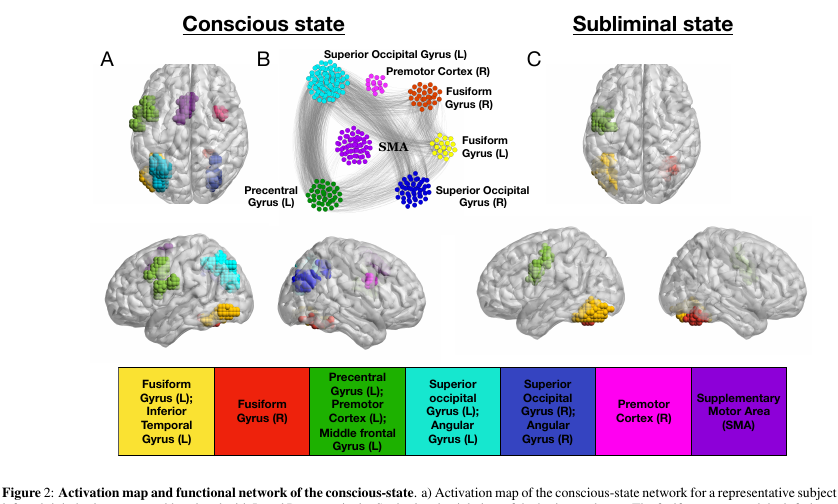
Expérience:
On montre aux volontaires des images (mots de 4 lettres, ou un écran vierge, ou des gribouillis). Chacun d'eux est affiché pendant 30 ms, en général, l'action entière dure 5 minutes.
- Dans le mode «conscient» de l'expérience, un écran vierge alterne avec des mots, ce qui permet à une personne de percevoir consciemment le texte.
- Dans le mode «inconscient», les mots alternent avec les gribouillis, ce qui interfère assez efficacement avec la perception du texte à un niveau conscient.
Données:
Au cours de cette présentation, les cerveaux de nos primates ont été scannés à l'aide de l'IRMf. Au total, les chercheurs avaient 15 volontaires, chacun répété l'expérience 5 fois, un total de 75 flux d'IRMf. Il est à noter que le scan du voxel s'est avéré être assez grand (très simplifié: le voxel est un cube 3D contenant un nombre assez important de cellules) - 4x4x4mm.
Magie:
Appelons le nœud voxel actif de notre flux. Le cerveau étant un gant de toilette modulaire, nous y introduisons deux types de connexions: externe et interne (correspondant à la disposition spatiale des nœuds). Les connexions sont assemblées de manière intéressante: nous construisons une matrice de corrélation croisée entre les nœuds et connectons les nœuds avec une connexion si la corrélation est supérieure à certains paramètres adaptatifs lambda. Ce paramètre affecte la décharge de notre réseau.
Le réglage des paramètres s'effectue à l'aide de la procédure de "filtrage". Si nous balançons un peu notre lambda, des transitions nettes entre les dimensions finales du réseau deviennent perceptibles (c'est-à-dire qu'un changement de paramètre suffisamment petit correspond à un grand incrément de taille).
Donc: les connexions internes sont activées par la valeur lambda-1, qui correspond à la valeur lambda juste avant une transition brusque. Externe - valeur lambda-2 correspondant à la valeur lambda immédiatement après une transition brusque.
Magic 2:
filtrage k-core. Le concept k-core décrit la connectivité réseau et est formulé simplement: le sous-réseau maximum, dont tous les nœuds ont au moins k voisins. Un tel sous-réseau peut être obtenu par suppression itérative de nœuds avec moins de k voisins. Étant donné que les nœuds restants perdront des voisins, le processus se poursuit jusqu'à ce qu'il n'y ait rien à supprimer. Reste le réseau k-core.
Résultats:
En appliquant cette artillerie à notre cerveau, vous pouvez voir un certain nombre de caractéristiques très intéressantes.
- Le nombre de nœuds dans k-core avec k petit / très grand est extrêmement grand. Mais pour k moyen, au contraire, ce n'est pas suffisant. Dans l'image, il ressemble à une forme en U, à savoir, une telle configuration de réseau donne la plus grande stabilité du système (résistance aux erreurs locales et globales).
- et les nœuds les plus importants appartenant au k-core avec un petit k peuvent être vus dans presque tous les états du réseau. Mais un k-core avec un k très grand n'est caractéristique que pour les parties du cerveau qui sont actives à l'état inconscient de gyrus fusiforme et de gyrus précentral gauche . Les mêmes parties du cortex sont les plus actives et dans un état conscient.
, rewiring, ( , ). k. , U shape , , .
Conclusions:
, , , . , , , - ( , , , ).
, , , , , , , - . , , qualia.
6. Large Memory Layers with Product Keys
: Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou (Facebook AI Research, 2019)
→
: ( belerafon)

, key-value , .
- attention. q, k v. q, k, , value . , . , . , , . - q (, -10). . .
— q k . , "Product Keys". , q , . -10 , , O(N) "" , (sqrt(N)).
key-value . , ( , ). , BERT 28 . , , . : 12- 2 , 24- , perplexity .
( self-attention). , - . , multy-head attention. C'est-à-dire query , value, . -.
, , , , BERT . .
7. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
: Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach (Politecnico di Milano, University of Klagenfurt, 2019)
→
: ( netcitizen)

DL , , .
DL top-n. DL KDD, SIGIR, TheWebConf (WWW) RecSys :
- -
- 7/18 (39%)
- “” train/test, ., , , .
- (Variational Autoencoders for Collaborative Filtering (Mult-VAE) ± ) KNN, SVD, PR.
DL, CV, NLP , .
8. Omni-Scale Feature Learning for Person Re-Identification
: Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, Tao Xiang (University of Surrey, Queen Mary University, Samsung AI, 2019)
→
: ( graviton)
Person Re-Identification, Face Recognition, , . (Kaiyang Zhou) deep-person-reid , (OSNet), Person Re-Identification. .
Person Re-Identification:

:
- conv1x1 deepwise conv3x3 conv3x3 (figure 3).
- , . ResNeXt , Inception (figure 4).
- “aggregation gate” . , Inception .

OSNet , .. , : ( , ) .
Les résultats des tests ReID pour OSNet (environ 2 millions de paramètres) indiquent l'avantage de cette architecture par rapport aux autres modèles d'éclairage (marché: R1 93,6%, mAP 81,0% pour OSNet et R1 87,0%, mAP 69,5% pour MobileNetV2) et l'absence de différence significative de précision avec modèles lourds de ResNet et DenseNet (marché: R1 94,8%, mAP 84,9% pour OSNet et R1 94,8%, mAP 86,0% pour ResNet).
Un autre défi est l' adaptation du domaine : les modèles formés sur un ensemble de données sont de mauvaise qualité sur un autre. OSNet montre également de bons résultats dans ce segment sans l'utilisation d'une «adaptation de domaine non supervisée» (en utilisant les données de test sous une forme non allouée pour uniformiser la distribution des données).
L'architecture a également été testée sur ImageNet, où elle a atteint une précision similaire avec MobileNetV2 avec moins de paramètres, mais plus d'opérations.
9. La reparamétrie neuronale améliore l'optimisation structurelle
Auteurs: Stephan Hoyer, Jascha Sohl-Dickstein, Sam Greydanus (Google Research, 2019)
→ Article original
Auteur de la revue: Alexey (in Arech slack)
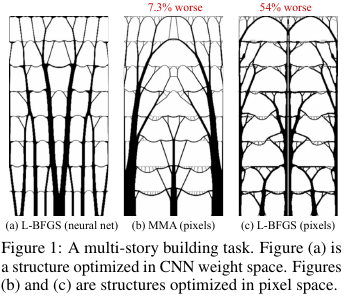
Dans la construction et d'autres technologies, il y a des tâches d'optimisation de la structure / topologie d'une solution. En gros, il s'agit d'une réponse informatique à une question comme, par exemple, comment concevoir un pont / bâtiment / aile d'avion / aube de turbine / blablabla, de sorte que certaines restrictions soient respectées et que la structure soit suffisamment solide. Il existe un ensemble de méthodes de solution «standard» - cela fonctionne, mais tout n'est pas toujours fluide.
Qu'est-ce que ces gars de Google ont trouvé? Ils ont dit: générons une solution par un réseau de neurones (la partie de suréchantillonnage de UNet), puis en utilisant un modèle physique différenciable, qui calculera le comportement d'une solution sous l'influence de toutes les forces et de la gravité, calculera la fonction objective - force (plus précisément, l'inverse - conformité) ) dessins. Puis, comme tout est automatiquement différenciable, nous obtenons le gradient de la fonction objectif, qui est repoussé à travers toute la structure vers les poids et l'entrée du réseau neuronal. Nous modifions les poids et l'entrée et continuons le cycle jusqu'à la convergence vers une solution stable.
Les résultats se sont révélés concerner de petits problèmes (en termes de taille de l'espace des solutions possibles) comparables aux méthodes traditionnelles d'optimisation des topologies, et pour les gros problèmes, ils sont nettement meilleurs que les problèmes traditionnels (surpoids dans 99 contre 66 sur 116 problèmes). De plus, les solutions qui en résultent sont souvent beaucoup plus technologiques et optimales que les décisions de référence.
C'est-à-dire en fait, ils ont utilisé le NS comme un moyen délicat de paramétrer le modèle physique de la structure, qui implicitement (grâce à l'architecture du NS) est capable d'imposer des restrictions utiles sur les valeurs des paramètres (contrôlées en supprimant le NS de la méthode et en optimisant directement les valeurs des pixels).
Code source.
Un aperçu plus détaillé de cet article sur habr.