Chariot volant, Afu ChanJe travaille chez
Mail.ru Cloud Solutons en tant qu'architecte et développeur, y compris mon cloud. Il est connu qu'une infrastructure cloud distribuée a besoin d'un stockage en bloc productif, dont dépend le fonctionnement des services PaaS et des solutions construites à partir de ceux-ci.
Initialement, lors du déploiement d'une telle infrastructure, nous n'utilisions que Ceph, mais progressivement le stockage en bloc a évolué. Nous voulions que
nos bases de données , le stockage de fichiers et divers services fonctionnent à des performances maximales, nous avons donc ajouté des stockages localisés et mis en place une surveillance Ceph avancée.
Je vais vous dire comment c'était - peut-être cette histoire, les problèmes que nous avons rencontrés et nos solutions seront utiles à ceux qui utilisent également Ceph. Soit dit en passant,
voici une version vidéo de ce rapport.
Des processus DevOps à votre propre cloud
Les pratiques DevOps visent à déployer le produit le plus rapidement possible:
- Automatisation des processus - tout le cycle de vie: assemblage, test, livraison au test et productif. Automatisez progressivement les processus, en commençant par de petites étapes.
- L'infrastructure en tant que code est un modèle lorsque le processus de configuration de l'infrastructure est similaire au processus de programmation logicielle. D'abord, ils testent le produit, le produit a certaines exigences pour l'infrastructure et l'infrastructure doit être testée. A ce stade, souhaite qu'elle apparaisse, je souhaite «peaufiner» l'infrastructure - d'abord dans l'environnement de test, puis dans l'épicerie. À la première étape, cela peut être fait manuellement, mais ils passent ensuite à l'automatisation - au modèle «infrastructure en tant que code».
- Virtualisation et conteneurs - apparaissent dans l'entreprise lorsqu'il est clair que vous devez mettre les processus sur une voie industrielle, déployer de nouvelles fonctionnalités plus rapidement avec une intervention manuelle minimale.
 L'architecture de tous les environnements virtuels est similaire: machines invitées avec conteneurs, applications, réseaux publics et privés, stockage.
L'architecture de tous les environnements virtuels est similaire: machines invitées avec conteneurs, applications, réseaux publics et privés, stockage.Progressivement, de plus en plus de services sont déployés dans l'infrastructure virtuelle intégrée dans et autour des processus DevOps, et l'environnement virtuel devient non seulement un test (utilisé pour le développement et les tests), mais aussi productif.
En règle générale, aux premiers stades, ils sont contournés par les outils d'automatisation de base les plus simples. Mais à mesure que de nouveaux outils sont attirés, tôt ou tard, il est nécessaire de déployer une plate-forme cloud à part entière afin d'utiliser les outils les plus avancés comme Terraform.
À ce stade, l'infrastructure virtuelle des «hyperviseurs, réseaux et stockage» se transforme en une infrastructure cloud à part entière avec des outils et des composants développés pour orchestrer les processus. Ensuite, leur propre cloud apparaît, dans lequel les processus de test et de livraison automatisée des mises à jour aux services existants et le déploiement de nouveaux services ont lieu.
La deuxième façon d'accéder à votre propre cloud est de ne pas dépendre de ressources externes et de prestataires de services externes, c'est-à-dire de fournir une certaine indépendance technique à vos propres services.
 Le premier cloud ressemble presque à une infrastructure virtuelle - un hyperviseur (un ou plusieurs), des machines virtuelles avec des conteneurs, un stockage partagé: si vous ne construisez pas le cloud sur des solutions propriétaires, il s'agit généralement de Ceph ou DRBD.
Le premier cloud ressemble presque à une infrastructure virtuelle - un hyperviseur (un ou plusieurs), des machines virtuelles avec des conteneurs, un stockage partagé: si vous ne construisez pas le cloud sur des solutions propriétaires, il s'agit généralement de Ceph ou DRBD.Résilience et performances du cloud privé
Le cloud se développe, l'entreprise en dépend de plus en plus, l'entreprise commence à exiger une plus grande fiabilité.
Ici, la distribution est ajoutée au cloud privé, une infrastructure de cloud distribué apparaît: des points supplémentaires où se trouve l'équipement. Le cloud gère deux, trois ou plusieurs installations conçues pour fournir une solution tolérante aux pannes.
Dans le même temps, des données sont nécessaires sur tous les sites, et il y a un problème: au sein d'un site, il n'y a pas de gros retards dans le transfert de données, mais entre les sites, les données sont transmises plus lentement.
 Sites d'installation et stockage commun. Les rectangles rouges sont des goulots d'étranglement au niveau du réseau.
Sites d'installation et stockage commun. Les rectangles rouges sont des goulots d'étranglement au niveau du réseau.La partie externe de l'infrastructure du point de vue du réseau de gestion ou du réseau public n'est pas très occupée, mais sur le réseau interne les volumes de données transférés sont beaucoup plus importants. Et dans les systèmes distribués, les problèmes commencent, exprimés en une longue durée de service. Si le client arrive à un groupe de nœuds de stockage, les données doivent être répliquées instantanément vers le deuxième groupe afin que les modifications ne soient pas perdues.
Pour certains processus, la latence de réplication des données est acceptable, mais dans des cas tels que le traitement des transactions, les transactions ne peuvent pas être perdues. Si la réplication asynchrone est utilisée, un décalage temporel peut entraîner la perte d'une partie des données en cas de défaillance de l'une des «queues» du système de stockage (système de stockage de données). Si la réplication synchrone est utilisée, le temps de service augmente.
Il est également tout à fait naturel que lorsque le temps de traitement (latence) du stockage augmente, les bases de données commencent à ralentir et des effets négatifs doivent être combattus.
Dans notre cloud, nous recherchons des solutions équilibrées pour maintenir la fiabilité et les performances. La technique la plus simple consiste à localiser les données - puis nous avons ajouté des clusters Ceph localisés supplémentaires.
 La couleur verte indique des clusters Ceph localisés supplémentaires.
La couleur verte indique des clusters Ceph localisés supplémentaires.L'avantage d'une telle architecture complexe est que ceux qui ont besoin d'une entrée / sortie rapide de données peuvent utiliser des stockages localisés. Les données pour lesquelles la pleine disponibilité est critique sur deux sites se trouvent dans un cluster distribué. Cela fonctionne plus lentement, mais les données qu'il contient sont répliquées sur les deux sites. Si ses performances ne sont pas suffisantes, vous pouvez utiliser des clusters Ceph localisés.
La plupart des clouds publics et privés finissent par avoir approximativement le même schéma de travail, lorsque, selon les besoins, la charge est déployée dans différents types de stockages (différents types de disques).
Diagnostics Ceph: comment construire la surveillance
Lorsque nous avons déployé et lancé l'infrastructure, il était temps d'assurer son fonctionnement, de minimiser le temps et le nombre de pannes. Par conséquent, la prochaine étape dans le développement des infrastructures a été la construction de diagnostics et de surveillance.
Considérez la tâche de surveillance tout au long - nous avons une pile d'applications dans un environnement de cloud virtuel: une application, un système d'exploitation invité, un périphérique de bloc, les pilotes de ce périphérique de bloc sur un hyperviseur, un réseau de stockage et le système de stockage réel (système de stockage). Et tout cela n'a pas encore été couvert par le suivi.
 Éléments non couverts par le suivi.
Éléments non couverts par le suivi.La surveillance est implémentée en plusieurs étapes, nous commençons par les disques. Nous obtenons le nombre d'opérations de lecture / écriture, avec une certaine précision, le temps de service (mégaoctets par seconde), la profondeur de la file d'attente, d'autres caractéristiques, et nous collectons également SMART sur l'état des disques.
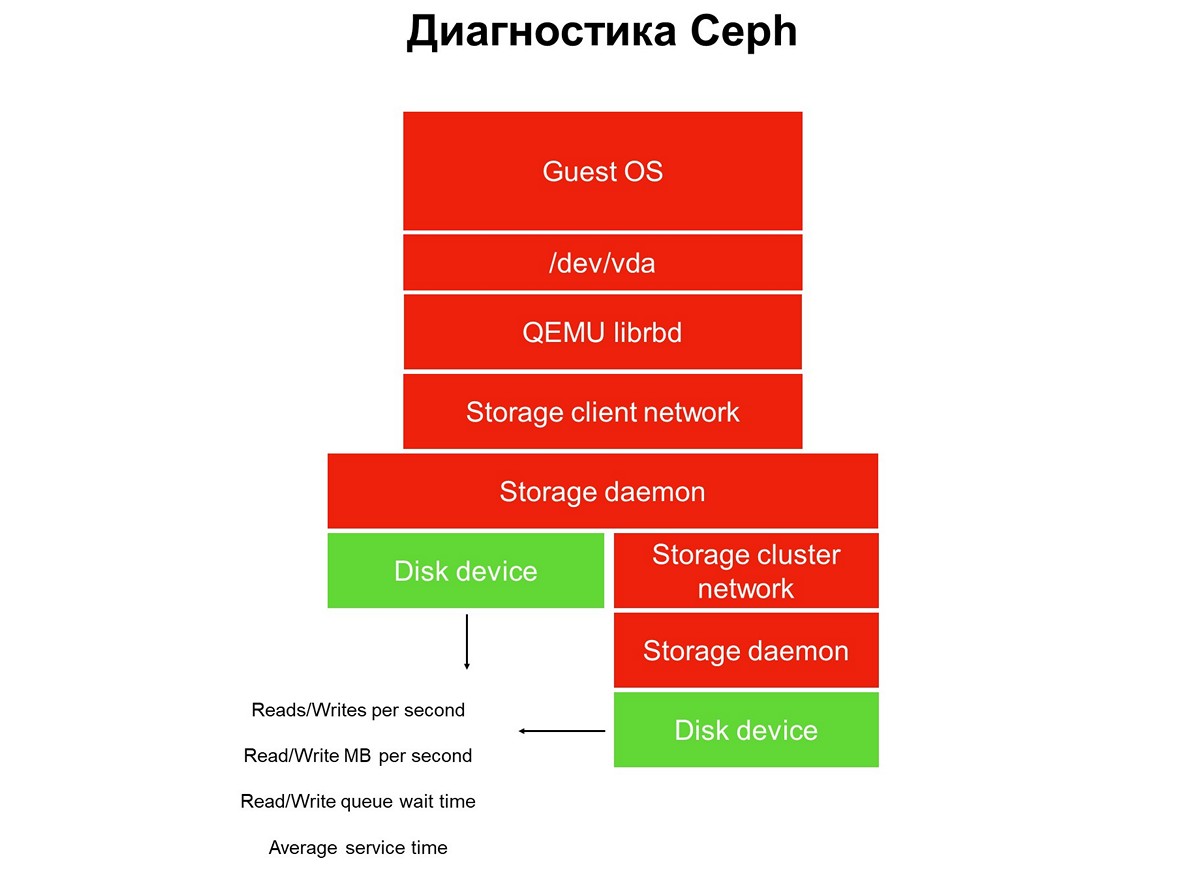 Première étape: nous couvrons les disques de surveillance.
Première étape: nous couvrons les disques de surveillance.La surveillance du disque ne suffit pas pour obtenir une image complète de ce qui se passe dans le système. Par conséquent, nous passons à la surveillance d'un élément essentiel de l'infrastructure - le réseau du système de stockage. Il y en a en fait deux: le cluster interne et le client, qui connecte les clusters de stockage aux hyperviseurs. Ici, nous obtenons les taux de transfert de paquets de données (mégaoctets par seconde, paquets par seconde), la taille des files d'attente réseau, des tampons et éventuellement des chemins de données.
 Deuxième étape: surveillance du réseau.
Deuxième étape: surveillance du réseau.Ils s'arrêtent souvent à cela, mais cela ne peut pas être fait, car la plupart des infrastructures n'ont pas encore été fermées par la surveillance.
Tout le stockage distribué utilisé dans les clouds publics et privés est SDS, stockage défini par logiciel. Ils peuvent être mis en œuvre sur les solutions d'un fournisseur particulier, des solutions open source, vous pouvez faire quelque chose vous-même en utilisant une pile de technologies familières. Mais c'est toujours SDS, et le travail de ces composants logiciels doit être surveillé.
 Troisième étape: surveiller le démon de stockage.
Troisième étape: surveiller le démon de stockage.La plupart des opérateurs Ceph utilisent des données collectées à partir des démons de surveillance et de contrôle Ceph (moniteur et gestionnaire, alias mgr). Au départ, nous avons suivi le même chemin, mais nous nous sommes très vite rendu compte que ces informations n'étaient pas suffisantes - les avertissements concernant les demandes suspendues apparaissent tardivement: la demande a été suspendue pendant 30 secondes, seulement alors nous l'avons vue. Tant qu'il s'agit de surveillance, alors que la surveillance déclenche l'alarme, au moins trois minutes s'écoulent. Dans le meilleur des cas, cela signifie qu'une partie du stockage et des applications sera inactive pendant trois minutes.
Naturellement, nous avons décidé d'étendre la surveillance et sommes descendus à l'élément principal de Ceph - le démon OSD. De la surveillance du démon de stockage d'objets, nous obtenons le temps de fonctionnement approximatif tel que l'OSD le voit, ainsi que des statistiques sur les demandes bloquées - qui, quand, dans quelle PG, pendant combien de temps.
Pourquoi seul Ceph ne suffit pas et que faire à ce sujet
Ceph à lui seul ne suffit pas pour plusieurs raisons. Par exemple, nous avons un client avec un profil de base de données. Il a déployé toutes les bases de données dans le cluster 100% flash, la latence des opérations qui y ont été émises lui convenait, cependant, il y avait des plaintes de temps d'arrêt.
Le système de surveillance ne vous permet pas de voir ce qui se passe à l'intérieur des clients d'environnement virtuel. Par conséquent, pour identifier le problème, nous avons utilisé l'analyse avancée, qui a été demandée à l'aide de l'utilitaire blktrace de sa machine virtuelle.
 Le résultat d'une analyse approfondie.
Le résultat d'une analyse approfondie.Les résultats d'analyse contiennent des opérations marquées des drapeaux W et WS. Le drapeau W est un enregistrement, le drapeau WS est un enregistrement synchrone, attendant que le périphérique termine l'opération. Lorsque nous travaillons avec des bases de données, presque toutes les bases de données SQL ont un goulot d'étranglement - WAL (journal d'écriture anticipée).
La base de données écrit toujours d'abord les données dans le journal, reçoit une confirmation du disque avec des tampons de vidage, puis elle écrit les données dans la base de données elle-même. Si elle n'a pas reçu la confirmation d'une réinitialisation du tampon, elle pense qu'une réinitialisation de l'alimentation peut effacer une transaction confirmée par le client. Ceci est inacceptable pour la base de données, elle affiche donc «write SYNC / FLUSH», puis écrit les données. Lorsque les journaux sont pleins, leur commutation se produit et tout ce qui est entré dans le cache de pages est également flashé de force.
Ajouté: il n'y a pas de réinitialisation dans l'image elle-même - c'est-à-dire, les opérations avec le drapeau de pré-rinçage. Ils ressemblent à FWS - pré-rinçage + écriture + synchronisation ou FWSF - pré-rinçage + écriture + synchronisation + FUALorsqu'un client effectue de nombreuses petites transactions, pratiquement toutes ses E / S se transforment en une chaîne séquentielle: écriture - vidage - écriture - vidage. Comme vous ne pouvez pas faire quelque chose avec la base de données, nous commençons à travailler avec le système de stockage. En ce moment, nous comprenons que les capacités de Ceph ne sont pas suffisantes.
Pour nous, à ce stade, la meilleure solution était d'ajouter de petits référentiels locaux rapides qui n'étaient pas implémentés à l'aide des outils Ceph (nous avons essentiellement épuisé ses capacités). Et nous transformons le stockage cloud en quelque chose de plus que Ceph. Dans notre cas, nous avons ajouté de nombreuses histoires locales (locales en termes de centre de données, pas d'hyperviseur).
 Référentiels localisés supplémentaires Cibles A et B.
Référentiels localisés supplémentaires Cibles A et B.La durée de service d'un tel stockage local est d'environ 0,3 ms par flux. S'il se trouve dans un autre centre de données, il fonctionne plus lentement - avec une performance d'environ 0,7 ms. Il s'agit d'une augmentation significative par rapport à Ceph, qui produit 1,2 ms, et distribué sur les centres de données - 2 ms. Les performances de ces petites usines, dont nous avons plus d'une douzaine, sont d'environ 100 000 par module, 100 000 IOPS par enregistrement.
Après un tel changement d'infrastructure, notre cloud passe sous un million d'IOPS pour l'écriture, soit environ deux à trois millions d'IOPS pour la lecture au total pour tous les clients:

Il est important de noter que ce type de stockage n'est pas la principale méthode d'expansion, nous plaçons le pari principal sur Ceph, et la présence d'un stockage rapide n'est importante que pour les services qui nécessitent un temps de réponse du disque.
Nouvelles itérations: améliorations du code et de l'infrastructure
Toutes nos histoires sont des ressources partagées. Une telle infrastructure nous oblige à
mettre en
œuvre une politique de niveau de service : nous devons fournir un certain niveau de service et ne pas permettre à un client d'interférer avec un autre par accident ou exprès, en désactivant le stockage.
Pour ce faire, nous avons dû procéder à la finalisation et au déploiement non trivial - livraison itérative au producteur.
Ce déploiement était différent des pratiques DevOps habituelles, lorsque tous les processus: assemblage, test, déploiement de code, redémarrage du service, si nécessaire, commencent par un clic sur un bouton, puis tout fonctionne. Si vous déployez des pratiques DevOps dans l'infrastructure, elles perdurent jusqu'à la première erreur.
C'est pourquoi «l'automatisation complète» n'a pas particulièrement pris racine dans l'équipe infrastructure. Bien sûr, il existe une certaine approche de l'automatisation des tests et de la livraison - mais elle est toujours contrôlée et la livraison est initiée par les ingénieurs SRE de l'équipe cloud.
Nous avons déployé des changements dans plusieurs services: dans le backend Cinder, le frontend Cinder (client Cinder) et dans le service Nova. Les modifications ont été appliquées en plusieurs itérations - une itération à la fois. Après la troisième itération, les modifications correspondantes ont été appliquées aux machines invitées des clients: quelqu'un a migré, quelqu'un a redémarré lui-même la machine virtuelle (redémarrage matériel) ou a planifié la migration pour desservir les hyperviseurs.
Le problème suivant qui se pose est celui des
sauts de vitesse d'écriture . Lorsque nous travaillons avec un stockage connecté au réseau, l'hyperviseur par défaut considère que le réseau est lent et met donc en cache toutes les données. Il écrit rapidement, jusqu'à plusieurs dizaines de mégaoctets, puis commence à vider le cache. Il y a eu beaucoup de moments désagréables à cause de ces sauts.
Nous avons constaté que si vous activez le cache, les performances du SSD s'affaissent de 15% et si vous désactivez le cache, les performances du HDD s'affaissent de 35%. Il a fallu un autre développement, déployé la gestion du cache géré, lorsque la mise en cache est explicitement attribuée à chaque type de disque. Cela nous a permis de conduire des SSD sans cache et des disques durs - avec un cache, en conséquence, nous avons cessé de perdre les performances.
La pratique consistant à offrir un développement à un producteur est similaire - itérations. Nous avons déployé le code, redémarré le démon, puis, si nécessaire, redémarrez ou migrez les machines virtuelles invitées, qui devraient être sujettes à modification. La machine virtuelle cliente a migré du disque dur, son cache activé - tout fonctionne, ou, au contraire, le client a migré avec SSD, son cache désactivé - tout fonctionne.
Le troisième problème est le
mauvais fonctionnement des machines virtuelles déployées à partir d'images GOLD sur le disque dur .
Il existe de nombreux clients de ce type, et la particularité de la situation est que le travail de la machine virtuelle a été ajusté par lui-même: le problème était garanti de se produire pendant le déploiement, mais a été résolu pendant que le client atteignait le support technique. Dans un premier temps, nous avons demandé aux clients d'attendre une demi-heure jusqu'à la stabilisation de la VM, puis nous avons commencé à travailler sur la qualité du service.
Au cours de la recherche, nous avons réalisé que les capacités de notre infrastructure de surveillance ne sont toujours pas suffisantes.
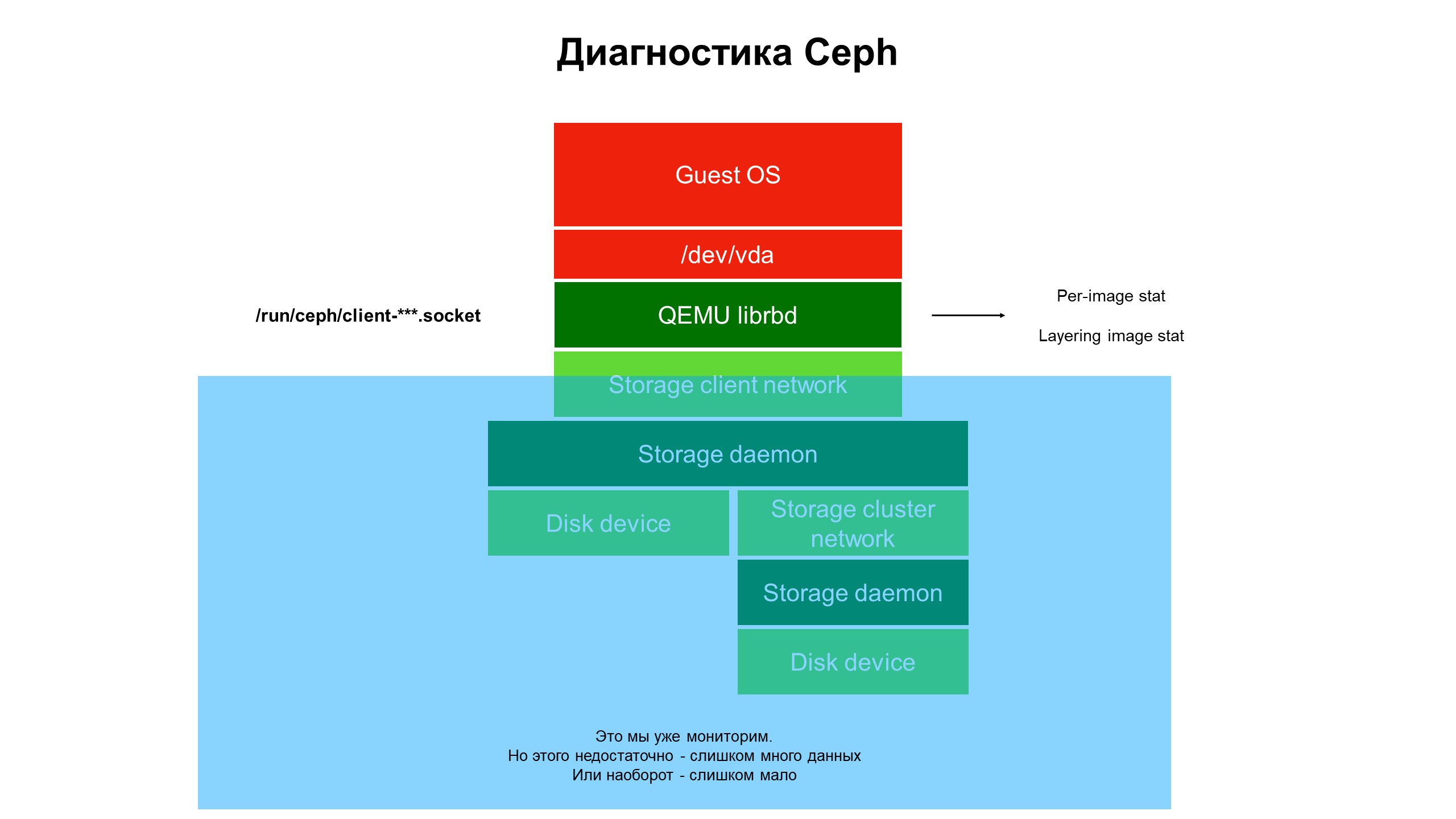 La surveillance a fermé la partie bleue et le problème était au sommet de l'infrastructure, non couvert par la surveillance.
La surveillance a fermé la partie bleue et le problème était au sommet de l'infrastructure, non couvert par la surveillance.Nous avons commencé à faire face à ce qui se passe dans la partie de l'infrastructure qui n'était pas couverte par la surveillance. Pour ce faire, nous avons utilisé les diagnostics avancés Ceph (ou plutôt, l'une des variétés du client Ceph - librbd). À l'aide d'outils d'automatisation, nous avons apporté des modifications à la configuration du client Ceph pour accéder aux structures de données internes via le socket de domaine Unix et avons commencé à prendre des statistiques des clients Ceph sur l'hyperviseur.
Qu'avons-nous vu? Nous n'avons pas vu de statistiques sur le cluster Ceph / OSD / cluster, mais des statistiques sur chaque disque de la machine virtuelle cliente dont les disques se trouvaient dans Ceph - c'est-à-dire les statistiques associées au périphérique.
 Résultats avancés des statistiques de surveillance.
Résultats avancés des statistiques de surveillance.Ce sont les statistiques étendues qui ont montré clairement que le problème se produit uniquement sur les disques clonés à partir d'autres disques.
Ensuite, nous avons examiné les statistiques sur les opérations, en particulier les opérations de lecture-écriture. Il s'est avéré que la charge sur les images de niveau supérieur est relativement faible, et sur les images initiales, d'où le clone provient, elle est grande mais sans équilibre: une grande quantité de lecture sans aucun enregistrement.
Le problème est localisé, maintenant une solution est nécessaire - code ou infrastructure?
Rien ne peut être fait avec le code Ceph, c'est «dur». De plus, la sécurité des données clients en dépend. Mais il y a un problème, il doit être résolu, et nous avons changé l'architecture du référentiel. Le cluster HDD s'est transformé en cluster hybride - une certaine quantité de SSD a été ajoutée au HDD, puis les priorités des démons OSD ont été modifiées afin que le SSD soit toujours prioritaire et devienne l'OSD principal dans le groupe de placement (PG).
Désormais, lorsque le client déploie la machine virtuelle à partir du disque cloné, ses opérations de lecture vont au SSD. En conséquence, la récupération à partir du disque est devenue rapide et seules les données client autres que l'image d'origine sont écrites sur le disque dur. Nous avons reçu une multiplication par trois de la productivité presque gratuitement (par rapport au coût initial de l'infrastructure).
Pourquoi la surveillance des infrastructures est importante
- L'infrastructure de surveillance doit être incluse au maximum dans toute la pile, en commençant par la machine virtuelle et en terminant par le disque. Après tout, alors qu'un client utilisant un cloud privé ou public arrive dans son infrastructure et fournit les informations nécessaires, le problème va changer ou se déplacer vers un autre endroit.
- La surveillance de l'intégralité de l'hyperviseur, de la machine virtuelle ou du conteneur «dans son intégralité» ne rapporte presque rien. Nous avons essayé de comprendre à partir du trafic réseau ce qui se passe avec Ceph - c'est inutile, les données volent à grande vitesse (à partir de 500 mégaoctets par seconde), il est extrêmement difficile de sélectionner celles qui sont nécessaires. Il faudra un volume monstrueux de disques pour stocker de telles statistiques et beaucoup de temps pour les analyser.
- Il est nécessaire de collecter autant de données de surveillance que possible, sinon il y a un risque de manquer quelque chose d'important. Et le revers: si vous avez collecté beaucoup de données, mais que vous ne pouvez pas les analyser et trouver ce dont vous avez besoin, cela rend les statistiques accumulées inutiles, les données collectées gaspilleront simplement votre espace disque sans but.
- Le but de la surveillance n'est pas seulement de déterminer la défaillance d'une infrastructure. Échec, vous verrez quand cela se produira. L'objectif principal est de prévoir les défaillances et de voir les tendances, de collecter des statistiques pour améliorer la qualité de service. Pour ce faire, nous avons besoin de flux de données bien organisés dans la surveillance, liés à l'infrastructure. Idéalement, d'un disque de machine virtuelle spécifique au niveau le plus bas - aux disques de stockage où se trouvent les données accessibles par la machine virtuelle cliente.
- Cloud MCS Cloud Solutions est une infrastructure dont les décisions d'évolution sont prises en grande partie sur la base des données accumulées par la surveillance. Nous améliorons la surveillance et utilisons ses données pour améliorer le niveau de service pour les clients.