Alexey Lizunov, chef du centre de compétence des canaux de service à distance de la Direction des technologies de l'information de l'ICD
Comme alternative à la pile ELK (ElasticSearch, Logstash, Kibana), nous menons des recherches sur l'utilisation de la base de données ClickHouse comme entrepôt de données pour les journaux.
Dans cet article, nous aimerions parler de notre expérience d'utilisation de la base de données ClickHouse et des résultats préliminaires de l'opération pilote. Il convient de noter tout de suite que les résultats ont été impressionnants.
Ensuite, nous décrirons plus en détail la configuration de notre système et les composants qui le composent. Mais maintenant, je voudrais parler un peu de cette base de données dans son ensemble, et pourquoi vous devriez y prêter attention. La base de données ClickHouse est une base de données de colonnes analytiques hautes performances de Yandex. Il est utilisé dans les services Yandex, au départ c'est le principal entrepôt de données pour Yandex.Metrica. Le système open-source est gratuit. Du point de vue du développeur, j'ai toujours été intéressé par la façon dont ils l'ont implémenté, car il y a des données incroyablement volumineuses. Et l'interface utilisateur métrique elle-même est très flexible et rapide. A la première connaissance de cette base de données, l'impression: «Enfin, enfin! Conçu "pour les gens"! À partir du processus d'installation et se terminant par l'envoi de demandes. "
Cette base de données a un seuil d'entrée très bas. Même un développeur qualifié moyen peut installer cette base de données en quelques minutes et commencer à l'utiliser. Tout fonctionne clairement. Même les débutants de Linux peuvent rapidement passer à travers l'installation et effectuer des opérations simples. Auparavant, lorsque le mot Big Data, Hadoop, Google BigTable, HDFS, le développeur habituel avait l'idée qu'ils parlaient de certains téraoctets, pétaoctets, que certains surhumains étaient impliqués dans les paramètres et le développement de ces systèmes, puis avec l'avènement de la base de données ClickHouse, nous avons obtenu Un outil simple et compréhensible avec lequel vous pouvez résoudre la gamme de tâches auparavant inaccessible. Une seule voiture assez moyenne et cinq minutes à installer. Autrement dit, nous avons une telle base de données comme, par exemple, MySql, mais uniquement pour stocker des milliards d'enregistrements! Une sorte de superviseur SQL. C'est comme si les gens recevaient des armes d'extraterrestres.
À propos de notre système de collecte de journaux
Pour collecter des informations, des fichiers journaux IIS d'applications Web d'un format standard sont utilisés (nous sommes également engagés dans l'analyse des journaux d'applications, mais l'objectif principal au stade de l'opération pilote avec nous est de collecter les journaux IIS).
Pour diverses raisons, nous n'avons pas complètement abandonné la pile ELK et nous continuons à utiliser les composants LogStash et Filebeat, qui ont fait leurs preuves et fonctionnent de manière assez fiable et prévisible.
Le schéma de journalisation général est présenté dans la figure ci-dessous:
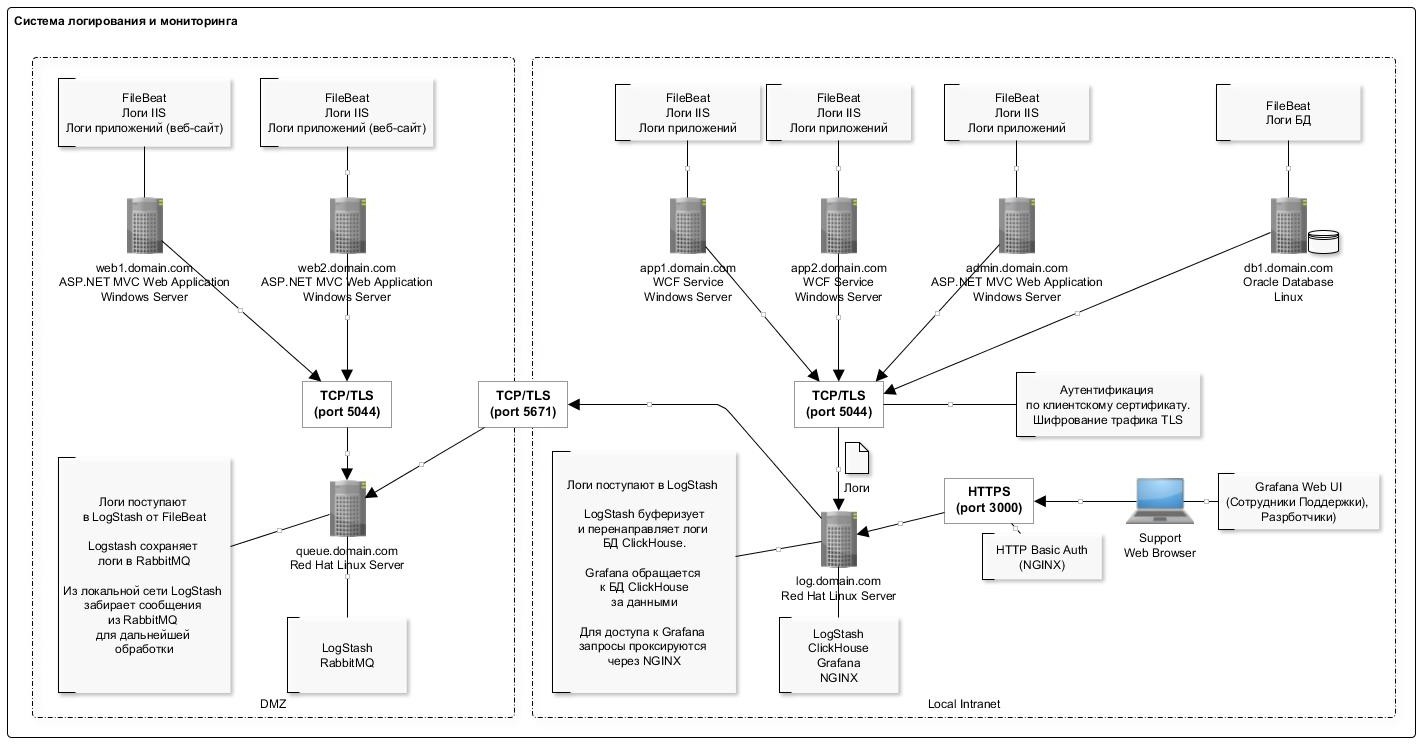
L'une des caractéristiques de l'écriture de données dans la base de données ClickHouse est l'insertion peu fréquente (une fois par seconde) d'enregistrements en lots importants. Apparemment, c'est la partie la plus «problématique» que vous rencontrez lorsque vous rencontrez pour la première fois la base de données ClickHouse: le schéma est un peu compliqué.
Le plugin LogStash a beaucoup aidé ici, qui insère directement des données dans ClickHouse. Ce composant est déployé sur le même serveur que la base de données elle-même. Donc, d'une manière générale, il n'est pas recommandé de le faire, mais d'un point de vue pratique, afin de ne pas produire de serveurs séparés pendant qu'il est déployé sur le même serveur. Nous n'avons pas observé d'échecs ou de conflits de ressources avec la base de données. De plus, il est à noter que le plugin dispose d'un mécanisme de retray en cas d'erreur. Et en cas d'erreur, le plugin écrit sur le disque un paquet de données qui n'a pas pu être inséré (le format de fichier est pratique: après l'édition, vous pouvez facilement insérer le paquet corrigé en utilisant clickhouse-client).
La liste complète des logiciels utilisés dans le schéma est présentée dans le tableau:
Liste des logiciels utilisés La configuration du serveur avec la base de données ClickHouse est présentée dans le tableau suivant:
Comme vous pouvez le voir, il s'agit d'un poste de travail normal.
La structure du tableau de stockage des journaux est la suivante:
log_web.sqlCREATE TABLE log_web ( logdate Date, logdatetime DateTime CODEC(Delta, LZ4HC), fld_log_file_name LowCardinality( String ), fld_server_name LowCardinality( String ), fld_app_name LowCardinality( String ), fld_app_module LowCardinality( String ), fld_website_name LowCardinality( String ), serverIP LowCardinality( String ), method LowCardinality( String ), uriStem String, uriQuery String, port UInt32, username LowCardinality( String ), clientIP String, clientRealIP String, userAgent String, referer String, response String, subresponse String, win32response String, timetaken UInt64 , uriQuery__utm_medium String , uriQuery__utm_source String , uriQuery__utm_campaign String , uriQuery__utm_term String , uriQuery__utm_content String , uriQuery__yclid String , uriQuery__region String ) Engine = MergeTree() PARTITION BY toYYYYMM(logdate) ORDER BY (fld_app_name, fld_app_module, logdatetime) SETTINGS index_granularity = 8192;
Nous utilisons des valeurs par défaut pour le partitionnement (par mois) et la granularité de l'index. Tous les champs correspondent pratiquement aux entrées du journal IIS pour l'enregistrement des requêtes http. Séparément, des champs séparés pour stocker les balises utm (ils sont analysés au stade de l'insertion dans la table à partir du champ de chaîne de requête).
Dans le tableau, plusieurs champs système sont également ajoutés pour stocker des informations sur les systèmes, les composants et les serveurs. Voir le tableau ci-dessous pour une description de ces champs. Dans une même table, nous stockons les journaux de plusieurs systèmes.
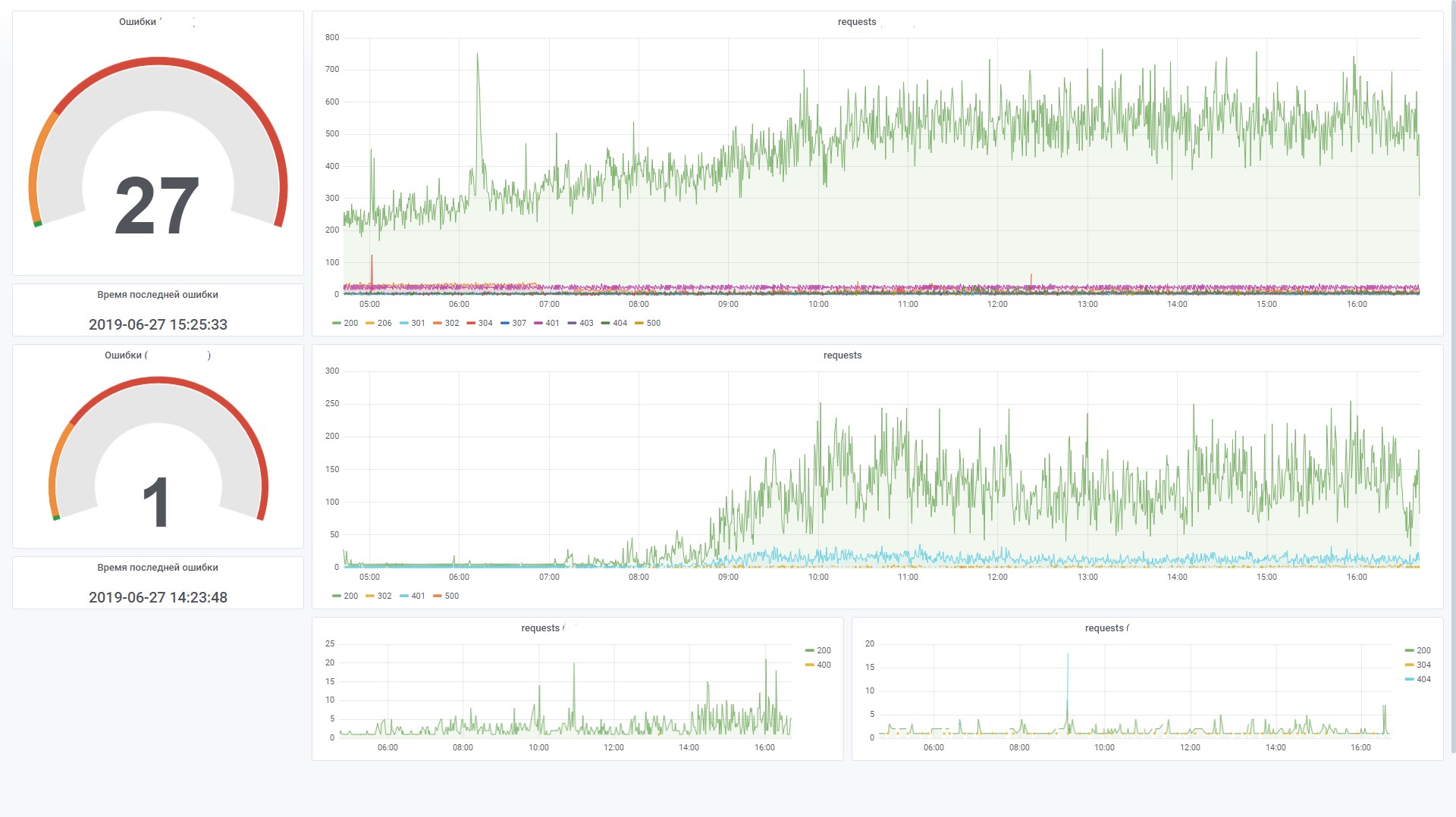
Cela vous permet de créer efficacement des graphiques dans Grafana. Par exemple, affichez les demandes du frontend d'un système spécifique. Ceci est similaire au compteur de site dans Yandex.Metrica.
Voici quelques statistiques sur l'utilisation de la base de données pendant deux mois.
Nombre d'enregistrements par système et composant SELECT fld_app_name, fld_app_module, count(fld_app_name) AS rows_count FROM log_web GROUP BY fld_app_name, fld_app_module WITH TOTALS ORDER BY fld_app_name ASC, rows_count DESC ┌─fld_app_name─────┬─fld_app_module─┬─rows_count─┐ │ site1.domain.ru │ web │ 131441 │ │ site2.domain.ru │ web │ 1751081 │ │ site3.domain.ru │ web │ 106887543 │ │ site3.domain.ru │ svc │ 44908603 │ │ site3.domain.ru │ intgr │ 9813911 │ │ site4.domain.ru │ web │ 772095 │ │ site5.domain.ru │ web │ 17037221 │ │ site5.domain.ru │ intgr │ 838559 │ │ site5.domain.ru │ bo │ 7404 │ │ site6.domain.ru │ web │ 595877 │ │ site7.domain.ru │ web │ 27778858 │ └──────────────────┴────────────────┴────────────┘ Totals: ┌─fld_app_name─┬─fld_app_module─┬─rows_count─┐ │ │ │ 210522593 │ └──────────────┴────────────────┴────────────┘ 11 rows in set. Elapsed: 4.874 sec. Processed 210.52 million rows, 421.67 MB (43.19 million rows/s., 86.51 MB/s.)
La quantité de données sur le disque SELECT formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed, formatReadableSize(sum(data_compressed_bytes)) AS compressed, sum(rows) AS total_rows FROM system.parts WHERE table = 'log_web' ┌─uncompressed─┬─compressed─┬─total_rows─┐ │ 54.50 GiB │ 4.86 GiB │ 211427094 │ └──────────────┴────────────┴────────────┘ 1 rows in set. Elapsed: 0.035 sec.
Le degré de compression des données dans les colonnes SELECT name, formatReadableSize(data_uncompressed_bytes) AS uncompressed, formatReadableSize(data_compressed_bytes) AS compressed, data_uncompressed_bytes / data_compressed_bytes AS compress_ratio FROM system.columns WHERE table = 'log_web' ┌─name───────────────────┬─uncompressed─┬─compressed─┬─────compress_ratio─┐ │ logdate │ 401.53 MiB │ 1.80 MiB │ 223.16665968777315 │ │ logdatetime │ 803.06 MiB │ 35.91 MiB │ 22.363966401202305 │ │ fld_log_file_name │ 220.66 MiB │ 2.60 MiB │ 84.99905736932571 │ │ fld_server_name │ 201.54 MiB │ 50.63 MiB │ 3.980924816977078 │ │ fld_app_name │ 201.17 MiB │ 969.17 KiB │ 212.55518183686877 │ │ fld_app_module │ 201.17 MiB │ 968.60 KiB │ 212.67805817411906 │ │ fld_website_name │ 201.54 MiB │ 1.24 MiB │ 162.7204926761546 │ │ serverIP │ 201.54 MiB │ 50.25 MiB │ 4.010824061219731 │ │ method │ 201.53 MiB │ 43.64 MiB │ 4.617721053304486 │ │ uriStem │ 5.13 GiB │ 832.51 MiB │ 6.311522291936919 │ │ uriQuery │ 2.58 GiB │ 501.06 MiB │ 5.269731450124478 │ │ port │ 803.06 MiB │ 3.98 MiB │ 201.91673864241824 │ │ username │ 318.08 MiB │ 26.93 MiB │ 11.812513794583598 │ │ clientIP │ 2.35 GiB │ 82.59 MiB │ 29.132328640073343 │ │ clientRealIP │ 2.49 GiB │ 465.05 MiB │ 5.478382297052563 │ │ userAgent │ 18.34 GiB │ 764.08 MiB │ 24.57905114484208 │ │ referer │ 14.71 GiB │ 1.37 GiB │ 10.736792723669906 │ │ response │ 803.06 MiB │ 83.81 MiB │ 9.582334090987247 │ │ subresponse │ 399.87 MiB │ 1.83 MiB │ 218.4831068635027 │ │ win32response │ 407.86 MiB │ 7.41 MiB │ 55.050315514606815 │ │ timetaken │ 1.57 GiB │ 402.06 MiB │ 3.9947395692010637 │ │ uriQuery__utm_medium │ 208.17 MiB │ 12.29 MiB │ 16.936148912472955 │ │ uriQuery__utm_source │ 215.18 MiB │ 13.00 MiB │ 16.548367623199912 │ │ uriQuery__utm_campaign │ 381.46 MiB │ 37.94 MiB │ 10.055156353418509 │ │ uriQuery__utm_term │ 231.82 MiB │ 10.78 MiB │ 21.502540454070672 │ │ uriQuery__utm_content │ 441.34 MiB │ 87.60 MiB │ 5.038260760449327 │ │ uriQuery__yclid │ 216.88 MiB │ 16.58 MiB │ 13.07721335008116 │ │ uriQuery__region │ 204.35 MiB │ 9.49 MiB │ 21.52661903446796 │ └────────────────────────┴──────────────┴────────────┴────────────────────┘ 28 rows in set. Elapsed: 0.005 sec.
Description des composants utilisés
FileBeat. Transfert du journal des fichiers
Ce composant surveille les modifications des fichiers journaux sur le disque et transfère les informations à LogStash. Il est installé sur tous les serveurs sur lesquels les fichiers journaux sont écrits (généralement IIS). Il fonctionne en mode queue (c'est-à-dire qu'il transfère uniquement les enregistrements ajoutés dans un fichier). Mais séparément, vous pouvez configurer l'intégralité du transfert de fichiers. Ceci est utile lorsque vous devez télécharger des données des mois précédents. Mettez simplement le fichier journal dans un dossier et il le lira dans son intégralité.
Lorsque le service s'arrête, les données cessent d'être transférées vers le stockage.
Un exemple de configuration est le suivant:
filebeat.yml filebeat.inputs: - type: log enabled: true paths: - C:/inetpub/logs/LogFiles/W3SVC1
LogStash Collecteur de journaux
Ce composant est destiné à recevoir des entrées de journal de FileBeat (ou via la file d'attente RabbitMQ), à analyser et à insérer des bundles dans la base de données ClickHouse.
Pour insérer dans ClickHouse, le plug-in Logstash-output-clickhouse est utilisé. Le plugin Logstash a un mécanisme pour récupérer les requêtes, mais avec un arrêt régulier, il est préférable d'arrêter le service lui-même. Lorsque vous vous arrêtez, les messages s'accumulent dans la file d'attente RabbitMQ, donc si vous vous arrêtez pendant longtemps, il est préférable d'arrêter Filebeats sur les serveurs. Dans un schéma où RabbitMQ n'est pas utilisé (sur un réseau local, Filebeat envoie des journaux directement à Logstash), Filebeats fonctionne de manière assez raisonnable et sûre, donc pour eux l'inaccessibilité de la sortie est sans conséquence.
Un exemple de configuration est le suivant:
log_web__filebeat_clickhouse.conf input { beats { port => 5044 type => 'iis' ssl => true ssl_certificate_authorities => ["/etc/logstash/certs/ca.cer", "/etc/logstash/certs/ca-issuing.cer"] ssl_certificate => "/etc/logstash/certs/server.cer" ssl_key => "/etc/logstash/certs/server-pkcs8.key" ssl_verify_mode => "peer" add_field => { "fld_server_name" => "%{[fields][fld_server_name]}" "fld_app_name" => "%{[fields][fld_app_name]}" "fld_app_module" => "%{[fields][fld_app_module]}" "fld_website_name" => "%{[fields][fld_website_name]}" "fld_log_file_name" => "%{source}" "fld_logformat" => "%{[fields][fld_logformat]}" } } rabbitmq { host => "queue.domain.com" port => 5671 user => "q-reader" password => "password" queue => "web_log" heartbeat => 30 durable => true ssl => true
ClickHouse. Stockage des journaux
Les journaux de tous les systèmes sont enregistrés dans une seule table (voir le début de l'article). Il est destiné à stocker des informations sur les demandes: tous les paramètres sont similaires pour différents formats, par exemple, les journaux IIS, les journaux apache et nginx. Pour les journaux d'application dans lesquels, par exemple, des erreurs, des messages d'information, des avertissements sont enregistrés, un tableau séparé sera fourni avec la structure correspondante (maintenant au stade de la conception).
Lors de la conception d'une table, il est très important de déterminer la clé primaire (selon laquelle les données seront triées pendant le stockage). Le degré de compression des données et la vitesse de requête en dépendent. Dans notre exemple, la clé est
ORDER BY (fld_app_name, fld_app_module, logdatetime)
C'est-à-dire par le nom du système, le nom du composant système et la date de l'événement. La date d'origine de l'événement était en premier lieu. Après l'avoir déplacé au dernier endroit, les requêtes ont commencé à fonctionner environ deux fois plus rapidement. La modification de la clé primaire nécessitera de recréer la table et de recharger les données pour que ClickHouse trie à nouveau les données sur le disque. Il s'agit d'une opération difficile, il est donc conseillé de penser à l'avance ce qui doit être inclus dans la clé de tri.
Il convient également de noter que relativement dans les versions récentes, le type de données LowCardinality est apparu. Lors de son utilisation, la taille des données compressées est fortement réduite pour les champs qui ont une faible cardinalité (peu d'options).
Maintenant, la version 19.6 est utilisée et nous prévoyons d'essayer de mettre à jour la version au plus tard. Ils comprenaient des fonctionnalités merveilleuses telles que la granularité adaptative, les indices de saut et le codec DoubleDelta, par exemple.
Par défaut, lors de l'installation, le niveau du journal de configuration est défini sur trace. Les journaux sont tournés et archivés, mais s'étendent à un gigaoctet. S'il n'y a pas besoin, vous pouvez définir le niveau d'avertissement, puis la taille du journal diminue fortement. Les paramètres de journalisation sont définis dans le fichier config.xml:
<level>warning</level>
Quelques commandes utiles Debian, Linux Altinity. : https://www.altinity.com/blog/2017/12/18/logstash-with-clickhouse sudo yum search clickhouse-server sudo yum install clickhouse-server.noarch 1. sudo systemctl status clickhouse-server 2. sudo systemctl stop clickhouse-server 3. sudo systemctl start clickhouse-server ( ";") clickhouse-client
LogStash Routeur de journaux FileBeat vers la file d'attente RabbitMQ
Ce composant est utilisé pour router les journaux provenant de FileBeat vers la file d'attente RabbitMQ. Il y a deux points:
- Malheureusement, FileBeat n'a pas de plugin de sortie pour écrire directement sur RabbitMQ. Et une telle fonctionnalité, à en juger par l'ish sur leur github, n'est pas prévue pour la mise en œuvre. Il existe un plugin pour Kafka, mais pour une raison quelconque, nous ne pouvons pas l'utiliser à la maison.
- Il existe des exigences pour la collecte des journaux dans la DMZ. Sur cette base, les journaux doivent d'abord être ajoutés à la file d'attente, puis LogStash de l'extérieur lit les entrées de la file d'attente.
Par conséquent, c'est précisément pour le cas de l'emplacement du serveur dans la DMZ que vous devez utiliser un schéma aussi légèrement compliqué. Un exemple de configuration est le suivant:
iis_w3c_logs__filebeat_rabbitmq.conf input { beats { port => 5044 type => 'iis' ssl => true ssl_certificate_authorities => ["/etc/pki/tls/certs/app/ca.pem", "/etc/pki/tls/certs/app/ca-issuing.pem"] ssl_certificate => "/etc/pki/tls/certs/app/queue.domain.com.cer" ssl_key => "/etc/pki/tls/certs/app/queue.domain.com-pkcs8.key" ssl_verify_mode => "peer" } } output {
RabbitMQ. File d'attente des messages
Ce composant est utilisé pour mettre en mémoire tampon les entrées de journal dans la DMZ. L'enregistrement se fait via le lien Filebeat → LogStash La lecture se fait depuis l'extérieur de la DMZ via LogStash. Lorsque vous utilisez RabboitMQ, environ 4 000 messages sont traités par seconde.
Le routage des messages est configuré en fonction du nom du système, c'est-à-dire en fonction des données de configuration de FileBeat. Tous les messages tombent dans une file d'attente. Si, pour une raison quelconque, le service de file d'attente est arrêté, cela n'entraînera pas de perte de messages: FileBeats recevra des erreurs de connexion et suspendra l'envoi temporaire. Et LogStash, qui lit à partir de la file d'attente, recevra également des erreurs réseau et attendra que la connexion reprenne. Les données dans ce cas, bien sûr, ne seront plus écrites dans la base de données.
Les instructions suivantes sont utilisées pour créer et configurer des files d'attente:
sudo /usr/local/bin/rabbitmqadmin/rabbitmqadmin declare exchange
Grafana Tableaux de bord
Ce composant est utilisé pour visualiser les données de surveillance. Dans ce cas, vous devez installer la source de données ClickHouse pour le plug-in Grafana 4.6+. Nous avons dû le modifier un peu pour augmenter l'efficacité du traitement des filtres SQL sur un tableau de bord.
Par exemple, nous utilisons des variables, et si elles ne sont pas définies dans le champ de filtre, nous aimerions qu'il ne génère pas de condition sous la forme WHERE (uriStem = `` AND uriStem! = ''). Dans ce cas, ClickHouse lira la colonne uriStem. En général, nous avons essayé différentes options et finalement corrigé le plugin (macro $ valueIfEmpty) de sorte qu'en cas de valeur vide, il retournerait 1, sans mentionner la colonne elle-même.
Et maintenant, vous pouvez utiliser cette requête pour le graphique
$columns(response, count(*) c) from $table where $adhoc and $valueIfEmpty($fld_app_name, 1, fld_app_name = '$fld_app_name') and $valueIfEmpty($fld_app_module, 1, fld_app_module = '$fld_app_module') and $valueIfEmpty($fld_server_name, 1, fld_server_name = '$fld_server_name') and $valueIfEmpty($uriStem, 1, uriStem like '%$uriStem%') and $valueIfEmpty($clientRealIP, 1, clientRealIP = '$clientRealIP')
qui est converti en SQL (notez que les champs uriStem vides ont été convertis en seulement 1)
SELECT t, groupArray((response, c)) AS groupArr FROM ( SELECT (intDiv(toUInt32(logdatetime), 60) * 60) * 1000 AS t, response, count(*) AS c FROM default.log_web WHERE (logdate >= toDate(1565061982)) AND (logdatetime >= toDateTime(1565061982)) AND 1 AND (fld_app_name = 'site1.domain.ru') AND (fld_app_module = 'web') AND 1 AND 1 AND 1 GROUP BY t, response ORDER BY t ASC, response ASC ) GROUP BY t ORDER BY t ASC
Conclusion
L'apparition de la base de données ClickHouse est devenue un événement marquant sur le marché. Il était difficile d'imaginer que gratuitement en un instant, nous étions armés d'un outil puissant et pratique pour travailler avec les mégadonnées. Bien sûr, avec des besoins croissants (par exemple, partitionnement et réplication sur plusieurs serveurs), le schéma deviendra plus complexe. Mais à première vue, travailler avec cette base de données est très agréable. On peut voir que le produit est fait "pour les gens".
Par rapport à ElasticSearch, le coût de stockage et de traitement des journaux, selon les estimations préliminaires, est réduit de cinq à dix fois. En d'autres termes, si pour la quantité actuelle de données, nous devons configurer un cluster de plusieurs machines, alors lorsque vous utilisez ClickHouse, nous n'avons besoin que d'une seule machine à faible puissance. Oui, bien sûr, ElasticSearch dispose également de mécanismes de compression des données sur disque et d'autres fonctionnalités qui peuvent réduire considérablement la consommation de ressources, mais par rapport à ClickHouse, cela sera coûteux.
Sans aucune optimisation particulière de sa part, sur les paramètres par défaut, le chargement des données et la récupération des données de la base de données fonctionnent à une vitesse incroyable. Jusqu'à présent, nous avons un peu de données (environ 200 millions d'enregistrements), mais le serveur lui-même est faible. À l'avenir, nous pouvons utiliser cet outil à d'autres fins non liées au stockage des journaux. Par exemple, pour l'analyse de bout en bout, dans le domaine de la sécurité, du machine learning.
En fin de compte, un peu sur les avantages et les inconvénients.
Inconvénients
- Téléchargement d'enregistrements en gros lots. Ceci, d'une part, est une fonctionnalité, mais vous devez toujours utiliser des composants supplémentaires pour tamponner les enregistrements. Cette tâche n'est pas toujours simple, mais toujours résoluble. Et je voudrais simplifier le schéma.
- Certaines fonctionnalités exotiques ou nouvelles fonctionnalités font souvent leur apparition dans de nouvelles versions. Cela soulève des préoccupations, réduisant le désir de passer à une nouvelle version. Par exemple, le moteur de table Kafka est une fonctionnalité très utile qui vous permet de lire directement les événements de Kafka, sans implémentation de consommateurs. Mais à en juger par le nombre de problèmes sur le github, nous sommes toujours réticents à utiliser ce moteur en production. Cependant, si vous ne faites pas de mouvements brusques sur le côté et utilisez les fonctionnalités de base, cela fonctionne de manière stable.
Avantages
- Cela ne ralentit pas.
- Seuil d'entrée bas.
- Open source
- C'est gratuit.
- S'adapte bien (partitionnement / réplication prêts à l'emploi)
- Il est inclus dans le registre des logiciels russes recommandé par le ministère des Communications.
- La présence du soutien officiel de Yandex.