Conférence Habr - l'histoire n'est pas une première. Nous avions l'habitude de tenir des événements assez grands Toaster pour 300-400 personnes, mais maintenant nous avons décidé que les petites réunions thématiques seront pertinentes, dont vous pouvez également définir la direction - par exemple, dans les commentaires. La première conférence de ce format s'est tenue en juillet et était dédiée au développement backend. Les participants ont écouté les rapports sur les caractéristiques de la transition du backend au ML et sur la conception du service Quadrupel sur le portail des services d'État, et ont également participé à une table ronde consacrée à Serverless. Pour ceux qui n'ont pas pu assister à l'événement personnellement, dans ce post, nous racontons les plus intéressants.

Du développement backend au machine learning
Que font les ingénieurs de données ML? Quelles sont les similitudes et les différences entre les tâches du développeur backend et de l'ingénieur ML? Quel chemin faut-il emprunter pour changer le premier métier en deuxième? Cela a été dit par Alexander Parinov, qui est entré dans l'apprentissage automatique après 10 ans de backend.
 Alexander Parinov
Alexander ParinovAujourd'hui, Alexander travaille comme architecte de systèmes de vision par ordinateur au sein du X5 Retail Group et contribue à des projets open source liés à la vision par ordinateur et au deep learning (github.com/creafz). Ses compétences sont confirmées par sa participation dans le top 100 du classement mondial Kaggle Master (kaggle.com/creafz) - la plateforme la plus populaire qui accueille des compétitions de machine learning.
Pourquoi passer à l'apprentissage automatique
Il y a un an et demi, Jeff Dean, chef de Google Brain, le projet de recherche en intelligence artificielle de Google, a expliqué à Google comment un demi-million de lignes de code dans Google Translate ont été remplacées par un réseau neuronal avec Tensor Flow, qui ne comprend que 500 lignes. Après la formation du réseau, la qualité des données a augmenté et l'infrastructure a été simplifiée. Il semblerait que voici notre brillant avenir: ne plus avoir à écrire du code, juste faire des neurones et les jeter avec des données. Mais en pratique, tout est beaucoup plus compliqué.
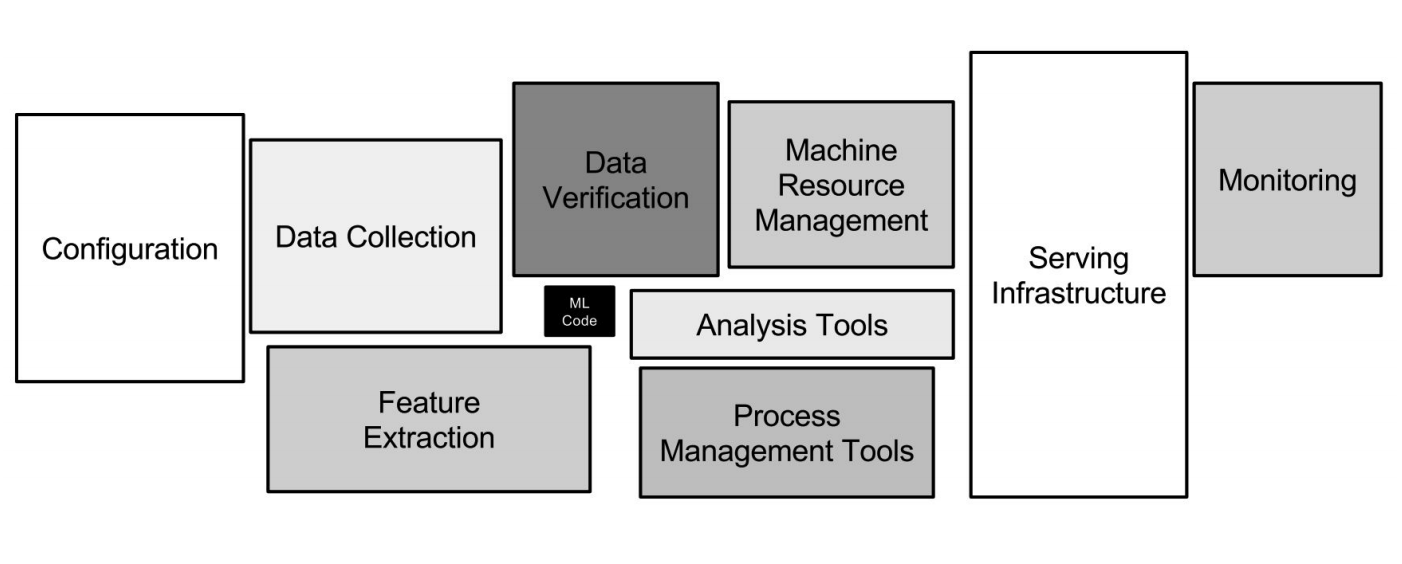 Infrastructure Google ML
Infrastructure Google MLLes réseaux de neurones ne sont qu'une petite partie de l'infrastructure (une petite boîte noire dans l'image ci-dessus). De nombreux autres systèmes auxiliaires sont nécessaires pour recevoir des données, les traiter, les stocker, vérifier la qualité, etc., nous avons besoin de l'infrastructure pour la formation, déployer du code d'apprentissage automatique en production, tester ce code. Toutes ces tâches sont exactement comme ce que font les développeurs backend.
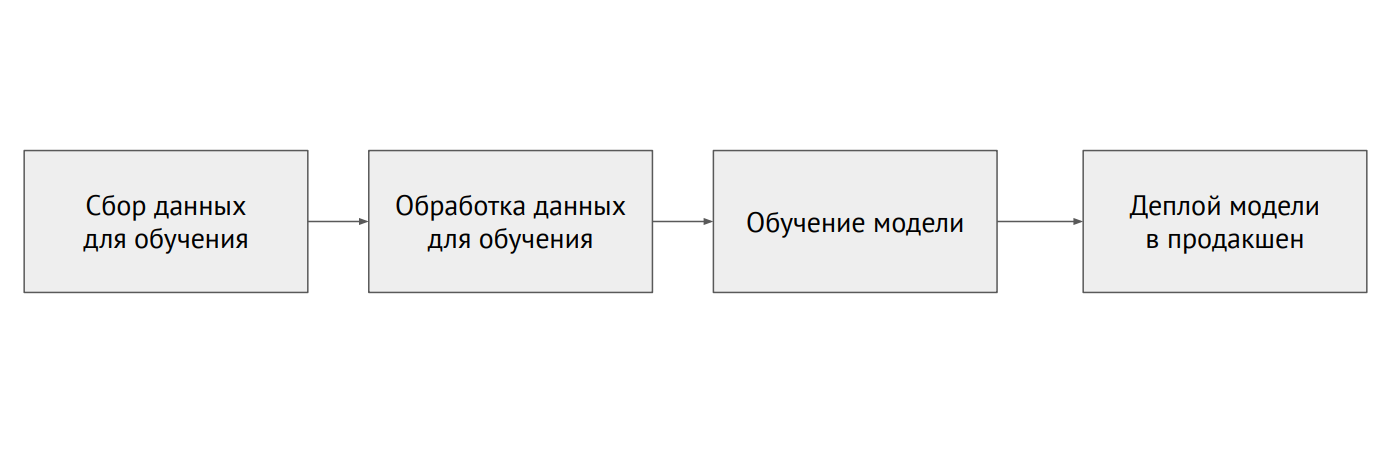 Processus d'apprentissage automatique
Processus d'apprentissage automatiqueQuelle est la différence entre ML et backend
En programmation classique, nous écrivons du code, ce qui dicte le comportement du programme. En ML, nous avons un petit code de modèle et beaucoup de données avec lesquelles nous déposons le modèle. Les données en ML sont très importantes: le même modèle, formé avec des données différentes, peut montrer des résultats complètement différents. Le problème est que presque toujours les données sont fragmentées et se trouvent dans différents systèmes (bases de données relationnelles, bases de données NoSQL, journaux, fichiers).
 Versionnage des données
Versionnage des donnéesML nécessite non seulement le versioning du code, comme dans le développement classique, mais aussi des données: il est nécessaire de bien comprendre sur quoi le modèle a été formé. Pour cela, vous pouvez utiliser la bibliothèque populaire Data Science Version Control (dvc.org).
 Balisage des données
Balisage des donnéesLa tâche suivante est le balisage des données. Par exemple, marquez tous les objets de l'image ou dites à quelle classe il appartient. Cela se fait par des services spéciaux comme Yandex.Tolki, le travail avec lequel simplifie considérablement la disponibilité de l'API. Des difficultés surviennent du fait du «facteur humain»: il est possible d'améliorer la qualité des données et de minimiser les erreurs en confiant la même tâche à plusieurs interprètes.
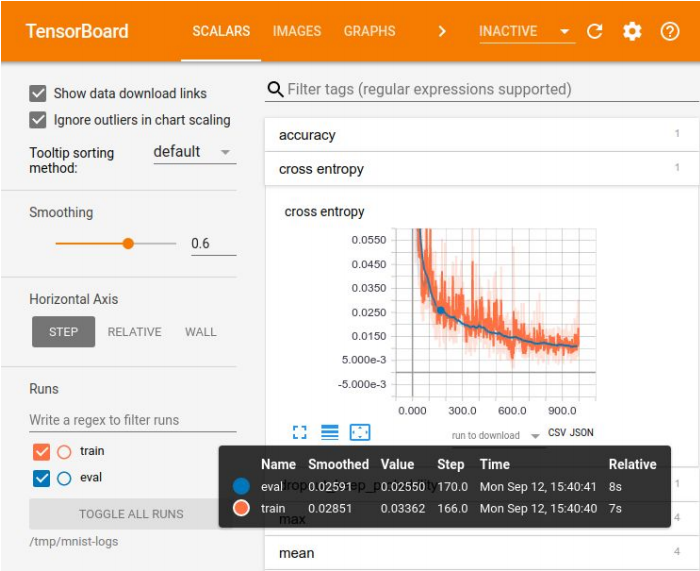 Visualisation dans Tensor Board
Visualisation dans Tensor BoardL'enregistrement des expériences est nécessaire pour comparer les résultats et choisir le meilleur modèle pour certaines mesures. Pour la visualisation, il existe un large éventail d'outils - par exemple, Tensor Board. Mais il n'y a pas de méthode idéale pour stocker les expériences. Dans les petites entreprises, ils se débrouillent souvent avec une plaque Excel, dans les grandes entreprises, ils utilisent des plates-formes spéciales pour stocker les résultats dans la base de données.
 Il existe de nombreuses plates-formes d'apprentissage automatique, mais aucune d'entre elles ne couvre même 70% des besoins
Il existe de nombreuses plates-formes d'apprentissage automatique, mais aucune d'entre elles ne couvre même 70% des besoinsLe premier problème auquel vous devez faire face lorsque vous amenez un modèle formé à la production est lié à votre outil de data scientist préféré - Jupyter Notebook. Il n'y a aucune modularité, c'est-à-dire que la sortie est une telle «chute de code» qui n'est pas divisée en éléments logiques - modules. Tout est mélangé: classes, fonctions, configurations, etc. Ce code est difficile à versionner et à tester.
Comment y faire face? Vous pouvez supporter Netflix et créer votre propre plateforme qui vous permet d'exécuter ces ordinateurs portables directement en production, de leur transférer des données et d'obtenir le résultat. Vous pouvez forcer les développeurs qui lancent le modèle en production à réécrire le code normalement, à le diviser en modules. Mais avec cette approche, il est facile de se tromper et le modèle ne fonctionnera pas comme prévu. Par conséquent, l'option idéale est d'interdire l'utilisation de Jupyter Notebook pour le code du modèle. Si, bien sûr, les Data Scientists acceptent cela.
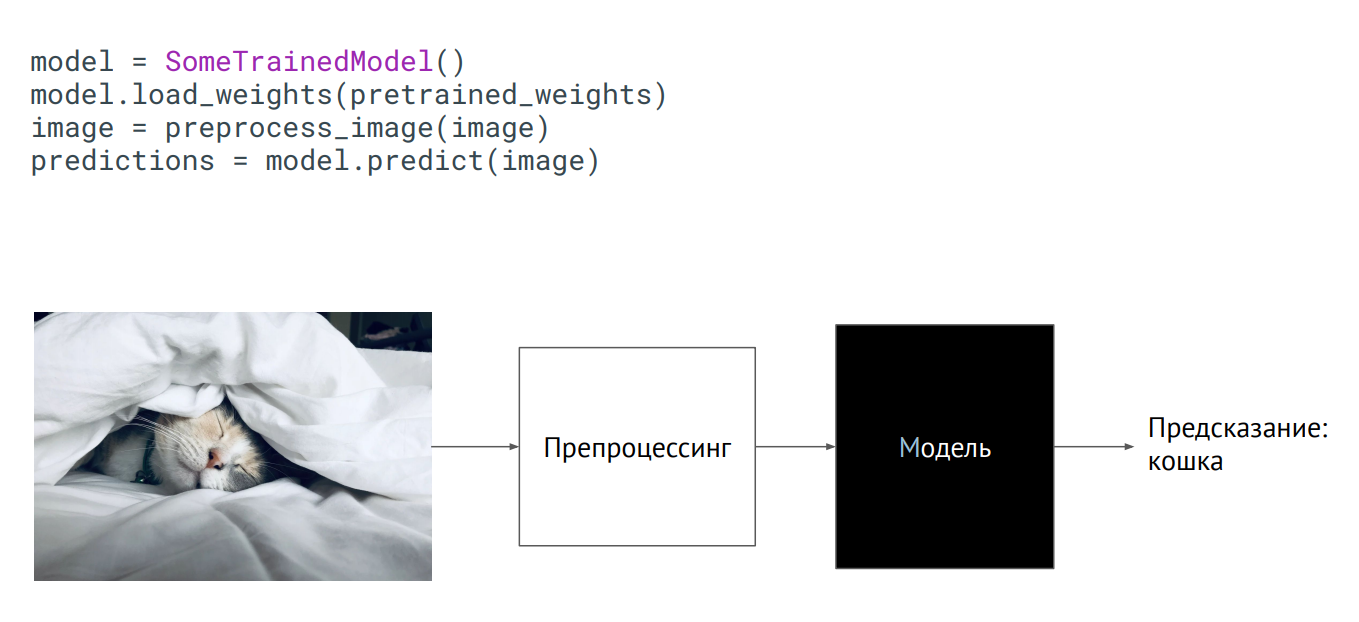 Modèle en boîte noire
Modèle en boîte noireLa façon la plus simple d'amener un modèle en production est de l'utiliser comme boîte noire. Vous avez une classe du modèle, les poids du modèle (paramètres des neurones du réseau formé) vous ont été transmis, et si vous initialisez cette classe (appelez la méthode de prédiction, mettez une image dessus), la sortie obtiendra une sorte de prédiction. Ce qui se passe à l'intérieur n'a pas d'importance.
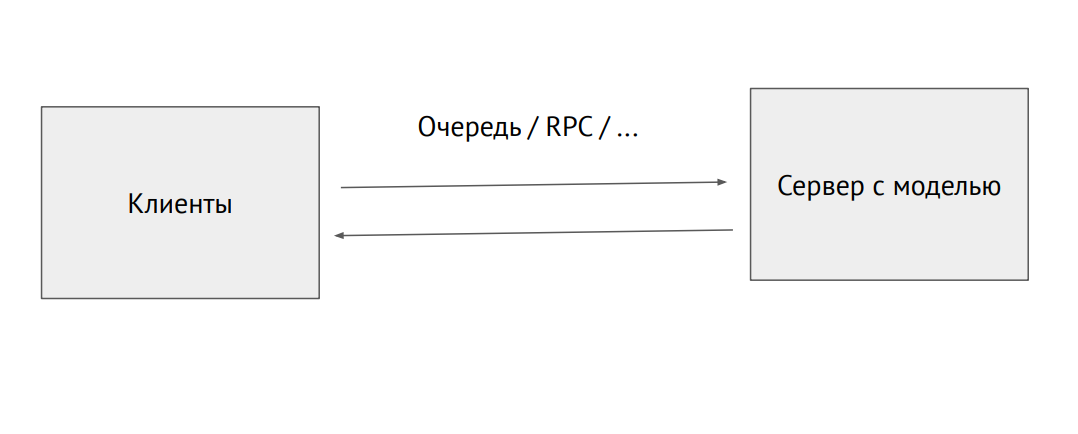 Processus de serveur séparé avec un modèle
Processus de serveur séparé avec un modèleVous pouvez également choisir un processus distinct et l'envoyer via la file d'attente RPC (avec des images ou d'autres données sources. À la sortie, nous recevrons des prédictions.
Un exemple d'utilisation du modèle dans Flask:
@app.route("/predict", methods=["POST"]) def predict(): image = flask.request.files["image"].read() image = preprocess_image(image) predictions = model.predict(image) return jsonify_prediction(predictions)
Le problème avec cette approche est la limitation des performances. Supposons que nous ayons un code Phyton écrit par des scientifiques des données qui ralentisse et que nous voulons réduire les performances maximales. Pour ce faire, vous pouvez utiliser des outils qui convertissent le code en natif ou le convertissent en un autre framework, affiné pour la production. Il existe de tels outils pour chaque framework, mais il n'y a pas d'outils idéaux, vous devrez le finir vous-même.
L'infrastructure en ML est la même que dans un backend régulier. Il existe Docker et Kubernetes, uniquement pour Docker, vous devez définir le runtime NVIDIA, qui permet aux processus à l'intérieur du conteneur d'accéder aux cartes vidéo de l'hôte. Kubernetes a besoin d'un plugin pour gérer les serveurs avec des cartes vidéo.
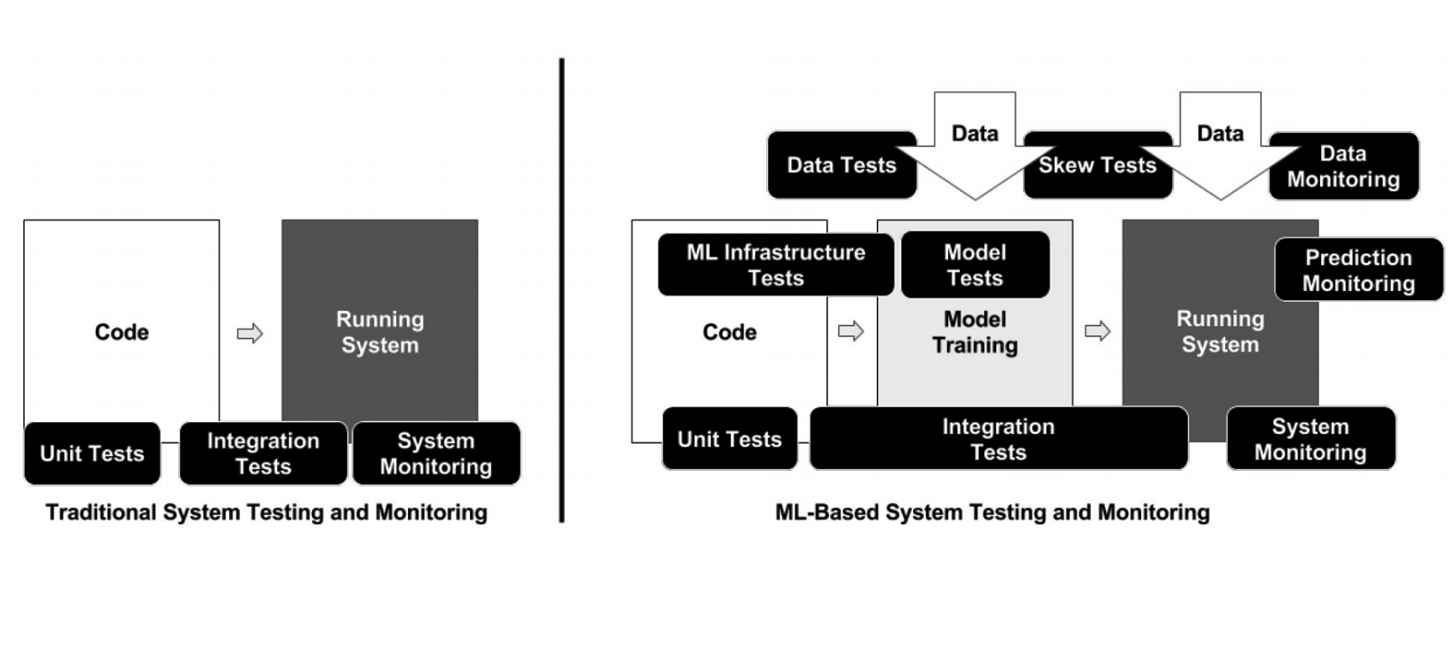
Contrairement à la programmation classique, dans le cas du ML, l'infrastructure comporte de nombreux éléments mobiles différents qui doivent être vérifiés et testés - par exemple, le code de traitement des données, le pipeline de formation des modèles et la production (voir le diagramme ci-dessus). Il est important de tester le code qui relie différents morceaux de pipelines: il y en a beaucoup, et des problèmes surviennent très souvent aux frontières des modules.
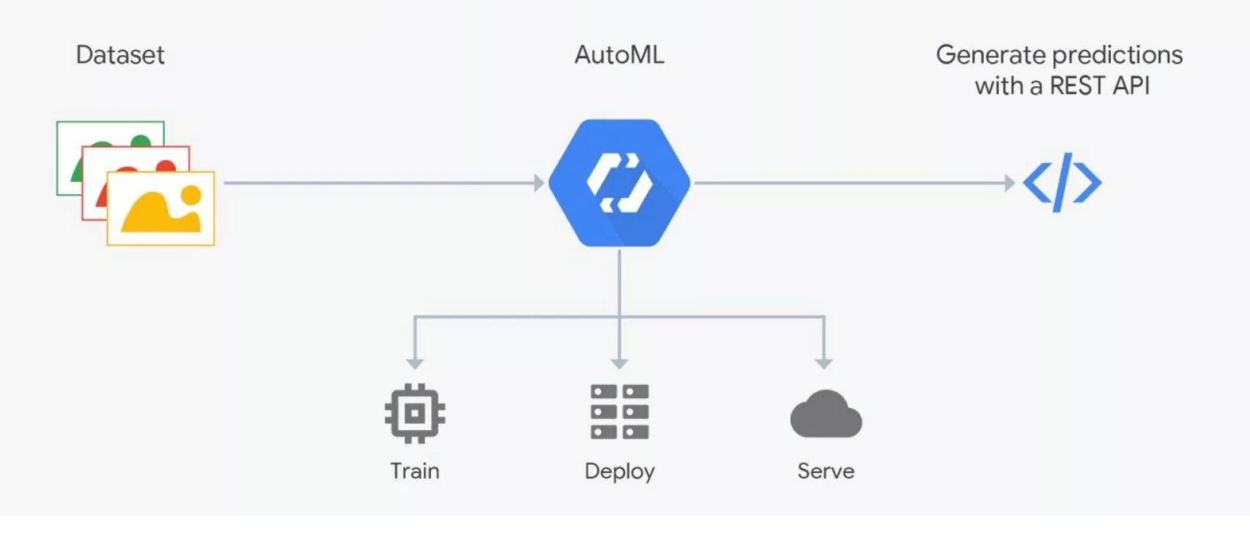 Fonctionnement d'AutoML
Fonctionnement d'AutoMLLes services AutoML promettent de sélectionner le meilleur modèle pour vos objectifs et de le former. Mais vous devez comprendre: en ML, les données sont très importantes, le résultat dépend de leur préparation. Les gens balisent, ce qui est lourd d'erreurs. Sans contrôle rigoureux, les ordures peuvent se révéler, mais l'automatisation ne fonctionne pas encore; vérification par des experts - des scientifiques des données sont nécessaires. C'est là que AutoML «casse». Mais cela peut être utile pour la sélection de l'architecture - lorsque vous avez déjà préparé les données et que vous souhaitez mener une série d'expériences pour trouver le meilleur modèle.
Comment entrer dans l'apprentissage automatique
Entrer dans ML est plus facile si vous développez en Python, qui est utilisé dans tous les cadres d'apprentissage profond (et les cadres réguliers). Cette langue est pratiquement requise pour ce domaine d'activité. Le C ++ est utilisé pour certaines tâches avec vision par ordinateur - par exemple, dans les systèmes de contrôle de véhicules sans pilote. JavaScript et Shell - pour la visualisation et des choses étranges telles que le lancement d'un neurone dans un navigateur. Java et Scala sont utilisés lorsque vous travaillez avec le Big Data et pour l'apprentissage automatique. R et Julia sont aimées des gens qui font des statistiques.
Obtenir une expérience pratique pour commencer est plus pratique chez Kaggle, la participation à l'un des concours de la plate-forme donne plus d'un an d'étude de la théorie. Sur cette plate-forme, vous pouvez prendre le code mis en page et commenté de quelqu'un et essayer de l'améliorer, d'optimiser vos objectifs. Le rang de bonus sur Kaggle affecte votre salaire.
Une autre option est d'aller en tant que développeur backend à l'équipe ML. Maintenant, il y a beaucoup de startups impliquées dans l'apprentissage automatique, dans lesquelles vous acquérez de l'expérience en aidant vos collègues à résoudre leurs problèmes. Enfin, vous pouvez rejoindre l'une des communautés de scientifiques des données - Open Data Science (ods.ai) et d'autres.
L'orateur a placé des informations supplémentaires sur le sujet à l' adresse https://bit.ly/backend-to-ml
«Quadrupel» - le service de notifications ciblées du portail «State Services»

Evgeny Smirnov
L'orateur suivant était Yevgeny Smirnov, chef du département de développement des infrastructures d'e-gouvernement, qui a parlé du Quadrupel. Il s'agit d'un service de notification ciblé du portail Gosuslugi (gosuslugi.ru), la ressource d'État la plus visitée sur Internet russe. L'audience quotidienne est de 2,6 millions, au total, 90 millions d'utilisateurs sont inscrits sur le site, dont 60 millions confirmés. La charge sur l'API du portail est de 30 000 RPS.
 Technologies utilisées dans le backend Gosuslug
Technologies utilisées dans le backend Gosuslug«Quadruple» est un service de notification d'adresse, à l'aide duquel l'utilisateur reçoit une offre de service au moment qui lui convient le mieux en mettant en place des règles spéciales d'information. Les principales exigences dans le développement du service étaient des paramètres flexibles et un temps suffisant pour l'envoi.
Comment fonctionne le Quadruple?

Le schéma ci-dessus montre une des règles du "Quadruple" sur l'exemple d'une situation avec la nécessité de remplacer un permis de conduire. Tout d'abord, le service recherche les utilisateurs dont la date d'expiration expire dans un mois. Ils ont mis en place une bannière avec une offre pour recevoir le service correspondant et envoyer un message électronique. Pour les utilisateurs qui ont déjà expiré, la bannière et l'e-mail changent. Après un échange de droits réussi, l'utilisateur reçoit d'autres notifications - avec une proposition de mise à jour des données du certificat.
D'un point de vue technique, ce sont des scripts groovy dans lesquels le code est écrit. À l'entrée - données, à la sortie - vrai / faux, apparié / non apparié. Au total, plus de 50 règles - de la détermination de l'anniversaire de l'utilisateur (la date actuelle est égale à l'anniversaire de l'utilisateur) aux situations difficiles. Chaque jour, selon ces règles, environ un million de correspondances sont déterminées - des personnes qui doivent être informées.
 Quadruple canaux de notification
Quadruple canaux de notificationSous le capot du Quadrupel se trouve une base de données dans laquelle sont stockées les données des utilisateurs, et trois applications:
- Worker est conçu pour mettre à jour les données.
- L'API Rest reprend et donne les bannières elles-mêmes au portail et à l'application mobile.
- Le planificateur lance des recomptages de bannières ou des envois groupés.
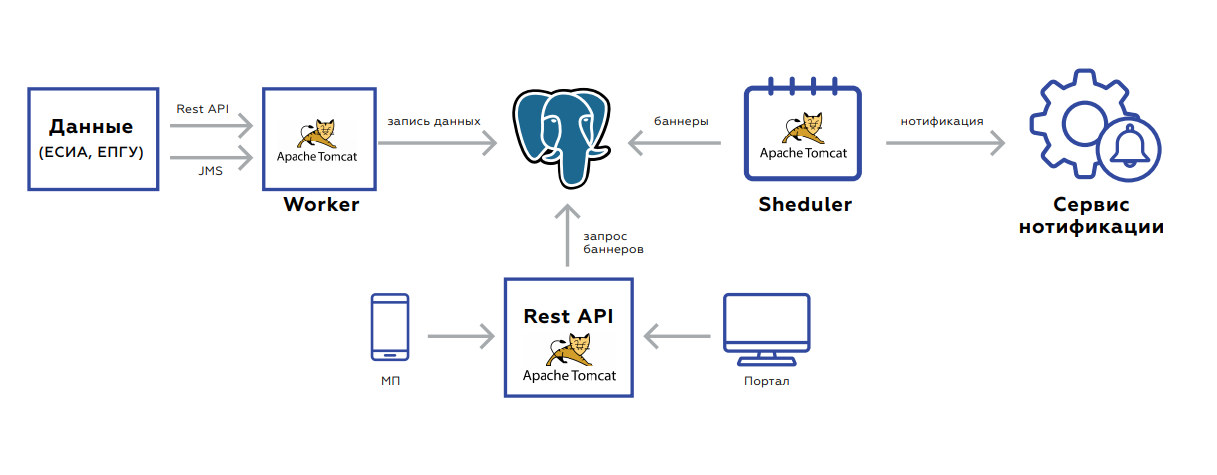
Le backend est orienté événement pour la mise à jour des données. Deux interfaces - repos ou JMS. Il existe de nombreux événements, avant qu'ils ne soient enregistrés et traités, ils sont agrégés afin de ne pas faire de demandes inutiles. La base de données elle-même, la plaque dans laquelle les données sont stockées, ressemble à un stockage de valeur clé - la clé de l'utilisateur et la valeur elle-même: des drapeaux indiquant la présence ou l'absence de documents pertinents, leur période de validité, des statistiques agrégées sur l'ordre des services par cet utilisateur, etc.

Après avoir enregistré les données, la tâche est définie dans JMS afin que les bannières soient immédiatement recomptées - cela doit être immédiatement affiché sur le Web. Le système démarre la nuit: dans JMS, les tâches sont lancées à des intervalles utilisateur, selon lesquels vous devez recompter les règles. Ceci est repris par les recompteurs. En outre, les résultats du traitement tombent dans la file d'attente suivante, qui enregistre les bannières dans la base de données ou envoie des tâches à l'utilisateur pour avertir l'utilisateur. Le processus prend 5 à 7 heures, il est facilement évolutif car vous pouvez toujours supprimer des processeurs ou augmenter les instances avec de nouveaux processeurs.

Le service fonctionne plutôt bien. Mais la quantité de données augmente à mesure que le nombre d'utilisateurs augmente. Cela conduit à une augmentation de la charge sur la base de données - même en tenant compte du fait que l'API Rest examine la réplique. Le deuxième point est JMS, qui, en fin de compte, n'est pas très approprié en raison de la grande consommation de mémoire. Il y a un risque élevé de dépassement de file d'attente avec un crash JMS et un arrêt du traitement. Il est impossible de relever le JMS après cela sans nettoyer les journaux.
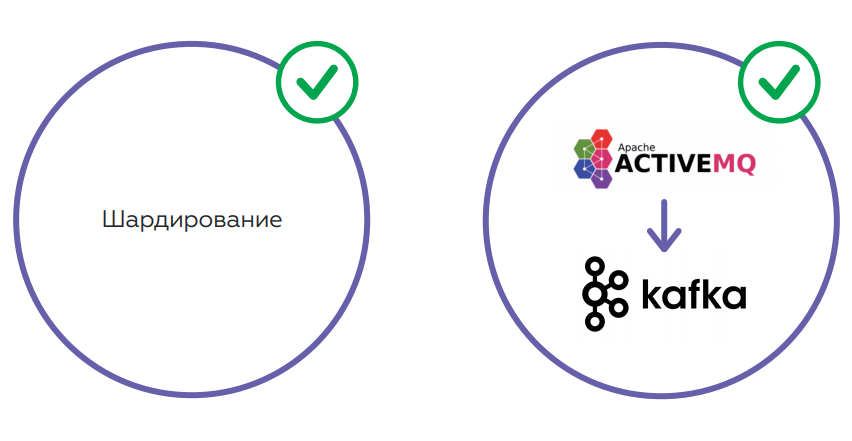
Il est prévu de résoudre les problèmes en utilisant le sharding, ce qui permettra d'équilibrer la charge sur la base. Il est également prévu de changer le schéma de stockage des données et de changer le JMS en Kafka - une solution plus tolérante aux pannes qui résoudra les problèmes de mémoire.
Vs de back-end en tant que service Sans serveur
 De gauche à droite: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara Israelyan
De gauche à droite: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara IsraelyanBackend en tant que service ou solution sans serveur? Les personnes suivantes ont participé à la discussion de cette question urgente à la table ronde:
- Ara Israelyan, CTO CTO et fondateur de Scorocode.
- Nikolay Markov, ingénieur principal des données chez Aligned Research Group.
- Andrey Tomilenko, chef du département de développement RUVDS.
La conversation a été animée par le développeur senior Alexander Borgart. Nous présentons le débat, auquel le public a participé, dans une version abrégée.
- Qu'est-ce que Serverless dans votre compréhension?
Andrei : Il s'agit d'un modèle de calcul - une fonction Lambda qui devrait traiter les données afin que le résultat ne dépende que des données. Le terme vient de Google ou d'Amazon et de son service AWS Lambda. Il est plus facile pour le fournisseur de traiter une telle fonction en lui allouant un pool de capacité. Différents utilisateurs peuvent être considérés indépendamment sur les mêmes serveurs.
Nikolay : Si c'est simple, nous transférons une partie de notre infrastructure informatique, la logique métier vers le cloud, pour l'externaliser.
Ara : De la part des développeurs - une bonne tentative d'économiser des ressources, de la part des spécialistes du marketing - pour gagner plus d'argent.
- Sans serveur - la même chose que les microservices?
Nikolai : Non, Serverless est plus une organisation d'architecture. Le microservice est une unité atomique d'une certaine logique. Sans serveur est une approche, pas une «entité distincte».
Ara : La fonction Serverless peut être empaquetée dans un microservice, mais à partir de là, elle cessera d'être Serverless, cessera d'être une fonction Lambda. Dans Serverless, une fonction ne démarre que lorsqu'elle est demandée.
Andrew : Ils diffèrent dans la durée de vie. Nous avons lancé et oublié la fonction Lambda. Cela a fonctionné pendant quelques secondes et le client suivant peut traiter sa demande sur une autre machine physique.
- Quelle échelle mieux?
Ara : Avec la mise à l'échelle horizontale, les fonctions Lambda se comportent exactement de la même manière que les microservices.
Nikolai : Combien de répliques vous demandez - il y en aura tellement, il n'y a aucun problème avec la mise à l'échelle sans serveur. Kubernetes a créé un jeu de répliques, lancé 20 instances «quelque part» et 20 liens anonymes vous sont retournés. Allez-y!
- Est-il possible d'écrire un backend sur Serverless?
Andrew : Théoriquement, mais cela ne sert à rien. Les fonctions Lambda reposeront sur un référentiel unique - nous devons fournir une garantie. Par exemple, si l'utilisateur a effectué une certaine transaction, la prochaine fois qu'il devrait voir: la transaction a été effectuée, les fonds ont été crédités. Toutes les fonctions Lambda seront bloquées lors de cet appel. En fait, un tas de fonctions sans serveur se transformeront en un service unique avec un point d'accès étroit à la base de données.
- Dans quelles situations est-il judicieux d'utiliser une architecture sans serveur?
Andrew : Tâches dans lesquelles un stockage commun n'est pas nécessaire - la même exploitation minière, blockchain. Où vous devez compter beaucoup. Si vous avez beaucoup de puissance de calcul, vous pouvez définir une fonction telle que "calculer le hachage de quelque chose là-bas ..." Mais vous pouvez résoudre le problème du stockage de données en prenant, par exemple, les fonctions Amazon et Lambda, et leur stockage distribué. Et il s'avère que vous écrivez un service régulier. Les fonctions Lambda accéderont au référentiel et donneront une sorte de réponse à l'utilisateur.
Nikolai : les conteneurs qui s'exécutent sans serveur sont extrêmement limités en ressources. Il y a peu de mémoire et tout le reste. Mais si vous avez déployé toute l'infrastructure sur un cloud - Google, Amazon - et que vous avez un contrat permanent avec eux, il y a un budget pour tout cela, alors pour certaines tâches, vous pouvez utiliser des conteneurs sans serveur. Il est nécessaire d'être situé exactement à l'intérieur de cette infrastructure, car tout est conçu pour être utilisé dans un environnement spécifique. Autrement dit, si vous êtes prêt à tout lier à l'infrastructure cloud, vous pouvez expérimenter. Le plus, c'est que vous n'avez pas à gérer cette infrastructure.
Ara : Le fait que Serverless ne vous oblige pas à gérer Kubernetes, Docker, installer Kafka, etc., est une auto-tromperie. Le même Amazon et Google sont le gestionnaire et ils l'ont dit. Une autre chose est que vous avez un SLA. Avec le même succès, vous pouvez tout externaliser et ne pas le programmer vous-même.
Andrew : Serverless lui-même est peu coûteux, mais vous devez payer beaucoup pour le reste des services Amazon - par exemple, une base de données. Les gens les ont déjà poursuivis pour le fait qu'ils déchiraient de l'argent fou pour la porte API.
Ara : Si nous parlons d'argent, alors vous devez considérer ce point: vous devrez déployer à 180 degrés toute la méthodologie de développement dans l'entreprise afin de transférer tout le code vers Serverless. Cela prendra beaucoup de temps et d'argent.
- Existe-t-il des alternatives décentes à Amazon sans serveur et à Google?
Nikolay : Dans Kubernetes, vous commencez une sorte de travail, il remplit et meurt - c'est assez sans serveur du point de vue de l'architecture. Si vous voulez créer une logique métier vraiment intéressante avec des files d'attente, avec des bases, alors vous devez y réfléchir un peu plus. Tout cela est résolu sans quitter Kubernetes. Je ne commencerais pas à faire glisser une implémentation supplémentaire.
- Dans quelle mesure est-il important de surveiller ce qui se passe dans Serverless?
Ara : dépend de l'architecture du système et des besoins de l'entreprise. En fait, le fournisseur doit fournir des rapports qui aideront le développeur à identifier les problèmes possibles.
Nikolai : Sur Amazon, il y a CloudWatch, où tous les journaux sont diffusés, y compris avec Lambda. Intégrez la transmission des journaux et utilisez un outil distinct pour la visualisation, les alertes, etc. Dans les conteneurs que vous démarrez, vous pouvez entasser des agents.
 - Résumons.
- Résumons.
Andrew : Réfléchir aux fonctions Lambda est utile. Si vous créez un service à genoux - pas un microservice, mais un service qui écrit une demande, accède à la base de données et envoie une réponse - la fonction Lambda résout un certain nombre de problèmes: multithreading, évolutivité, etc. Si votre logique est construite de cette manière, vous pourrez à l'avenir transférer ces Lambda vers des microservices ou utiliser des services tiers comme Amazon. La technologie est utile, une idée intéressante. Combien cela est-il justifié pour les entreprises est encore une question ouverte.
Nikolai: Serverless est préférable d'utiliser pour les tâches opérationnelles que pour calculer une sorte de logique métier. Je prends toujours cela comme un traitement d'événements. Si vous l'avez sur Amazon, si vous êtes à Kubernetes - oui. Sinon, vous devrez faire beaucoup d'efforts pour augmenter Serverless vous-même. Vous devez regarder une analyse de rentabilisation spécifique. Par exemple, j'ai maintenant l'une des tâches: lorsque des fichiers apparaissent sur un disque dans un certain format, vous devez les télécharger sur Kafka. Je peux utiliser ce WatchDog ou Lambda. Logiquement, les deux conviennent, mais Serverless est plus difficile à implémenter, et je préfère la manière la plus simple, sans Lambda.
Ara : Serverless - une idée intéressante, applicable et très belle techniquement. Tôt ou tard, la technologie atteindra le point où toute fonction augmentera en moins de 100 millisecondes. Ensuite, en principe, il ne sera pas question de savoir si le temps d'attente est critique pour l'utilisateur. Dans le même temps, l'applicabilité de Serverless, comme nos collègues l'ont déjà dit, dépend complètement de la tâche métier.
Nous remercions nos sponsors qui nous ont beaucoup aidés:
- L'espace des conférences informatiques " Spring " derrière la plateforme de la conférence.
- Calendrier des événements informatiques Runet-ID et la publication " Internet en chiffres " pour le support d'informations et les actualités.
- Akronis pour les cadeaux.
- Avito pour la co-création.
- «Association of Electronic Communications» RAEC pour son implication et son expérience.
- Le sponsor principal de RUVDS - pour tout!
