
Bonjour, Habr! Je dirige le développement de la plateforme
Vision - il s'agit de notre plateforme publique, qui donne accès aux modèles de vision par ordinateur et vous permet de résoudre des tâches telles que la reconnaissance de visages, de nombres, d'objets et de scènes entières. Et aujourd'hui, je veux dire par l'exemple de Vision comment mettre en œuvre un service rapide et très chargé à l'aide de cartes vidéo, comment le déployer et l'exploiter.
Qu'est-ce que la vision?
Il s'agit essentiellement d'une API REST. L'utilisateur génère une requête HTTP avec une photo et l'envoie au serveur.
Supposons que vous ayez besoin de reconnaître un visage dans une image. Le système le trouve, le coupe, extrait certaines propriétés du visage, l'enregistre dans la base de données et attribue un numéro conditionnel. Par exemple, personne42. L'utilisateur télécharge ensuite la photo suivante, qui a la même personne. Le système extrait les propriétés de son visage, recherche la base de données et renvoie le numéro conditionnel qui a été attribué à la personne initialement, c'est-à-dire personne42.
Aujourd'hui, les principaux utilisateurs de Vision sont divers projets du groupe Mail.ru. La plupart des demandes proviennent de Mail et Cloud.
Dans le Cloud, les utilisateurs ont des dossiers dans lesquels les photos sont téléchargées. Le cloud exécute les fichiers via Vision et les regroupe en catégories. Après cela, l'utilisateur peut facilement parcourir ses photos. Par exemple, lorsque vous souhaitez montrer des photos à des amis ou à votre famille, vous pouvez rapidement trouver celles dont vous avez besoin.
Mail et Cloud sont des services très importants avec des millions de personnes, donc Vision traite des centaines de milliers de demandes par minute. Autrement dit, c'est un service classique à forte charge, mais avec une torsion: il a nginx, un serveur Web, une base de données et des files d'attente, mais au niveau le plus bas de ce service est l'inférence - l'exécution d'images à travers des réseaux de neurones. C'est l'ensemble des réseaux de neurones qui prend la plupart du temps et nécessite des ressources. Les réseaux informatiques consistent en une séquence d'opérations matricielles qui prennent généralement beaucoup de temps sur le CPU, mais elles sont parfaitement parallélisées sur le GPU. Pour gérer efficacement les réseaux, nous utilisons un cluster de serveurs avec des cartes vidéo.
Dans cet article, je souhaite partager un ensemble de conseils qui peuvent être utiles lors de la création d'un tel service.
Développement de services
Délai de traitement pour une demande
Pour un système à forte charge, le temps de traitement d'une demande et le débit du système sont importants. La vitesse élevée de traitement des requêtes est fournie, tout d'abord, par la sélection correcte de l'architecture du réseau neuronal. En ML, comme dans toute autre tâche de programmation, les mêmes tâches peuvent être résolues de différentes manières. Prenons la détection des visages: pour résoudre ce problème, nous avons d'abord pris des réseaux de neurones avec une architecture R-FCN. Ils montrent une qualité assez élevée, mais ont pris environ 40 ms sur une image, ce qui ne nous convenait pas. Puis nous nous sommes tournés vers l'architecture MTCNN et avons obtenu une double augmentation de la vitesse avec une légère perte de qualité.
Parfois, afin d'optimiser le temps de calcul des réseaux de neurones, il peut être avantageux de mettre en œuvre l'inférence dans un autre cadre, pas dans celui qui a été enseigné. Par exemple, il est parfois judicieux de convertir votre modèle en NVIDIA TensorRT. Il applique un certain nombre d'optimisations et est particulièrement efficace sur les modèles assez complexes. Par exemple, il peut en quelque sorte réorganiser certains calques, les fusionner et même les jeter; le résultat ne changera pas et la vitesse de calcul de l'inférence augmentera. TensorRT permet également une meilleure gestion de la mémoire et, après quelques astuces, peut se réduire au calcul des nombres avec moins de précision, ce qui augmente également la vitesse de calcul de l'inférence.
Télécharger la carte vidéo
L'inférence réseau est effectuée sur le GPU, la carte vidéo est la partie la plus chère du serveur, il est donc important de l'utiliser aussi efficacement que possible. Comment comprendre, avons-nous complètement chargé le GPU ou pouvons-nous augmenter la charge? Il est possible de répondre à cette question, par exemple, en utilisant le paramètre GPU Utilization dans l'utilitaire nvidia-smi du package de pilote vidéo standard. Cette figure, bien sûr, ne montre pas combien de cœurs CUDA sont directement chargés sur la carte vidéo, mais combien sont inactifs, mais elle vous permet d'évaluer en quelque sorte la charge du GPU. Par expérience, nous pouvons dire que le chargement à 80-90% est bon. S'il est chargé à 10-20%, c'est mauvais et il y a encore du potentiel.
Une conséquence importante de cette observation: il faut essayer d'organiser le système de manière à maximiser le chargement des cartes vidéo. De plus, si vous avez 10 cartes vidéo, chacune étant chargée à 10-20%, alors, très probablement, deux cartes vidéo à haute charge peuvent résoudre le même problème.
Débit système
Lorsque vous soumettez une image à l'entrée d'un réseau de neurones, le traitement de l'image est réduit à une variété d'opérations matricielles. La carte vidéo est un système multicœur et les images d'entrée que nous soumettons habituellement sont petites. Disons qu'il y a 1 000 cœurs sur notre carte vidéo et que nous avons 250 x 250 pixels dans l'image. Seuls, ils ne pourront pas charger tous les cœurs en raison de leur taille modeste. Et si nous soumettons ces images au modèle une à la fois, le chargement de la carte vidéo ne dépassera pas 25%.
Par conséquent, vous devez télécharger plusieurs images à déduire à la fois et en former un lot.
Dans ce cas, la charge de la carte vidéo monte à 95% et le calcul de l'inférence prendra du temps comme pour une seule image.
Mais que se passe-t-il s'il n'y a pas 10 images dans la file d'attente afin que nous puissions les combiner en un lot? Vous pouvez attendre un peu, par exemple, 50-100 ms dans l'espoir que les demandes arriveront. Cette stratégie est appelée stratégie de latence fixe. Il vous permet de combiner les demandes des clients dans un tampon interne. En conséquence, nous augmentons notre retard d'un certain montant fixe, mais augmentons considérablement le débit du système.
Lancer l'inférence
Nous formons des modèles sur des images d'un format et d'une taille fixes (par exemple, 200 x 200 pixels), mais le service doit prendre en charge la possibilité de télécharger diverses images. Par conséquent, toutes les images avant de se soumettre à l'inférence, vous devez vous préparer correctement (redimensionner, centrer, normaliser, traduire en flottant, etc.). Si toutes ces opérations sont effectuées dans un processus qui lance l'inférence, son cycle de travail ressemblera à ceci:
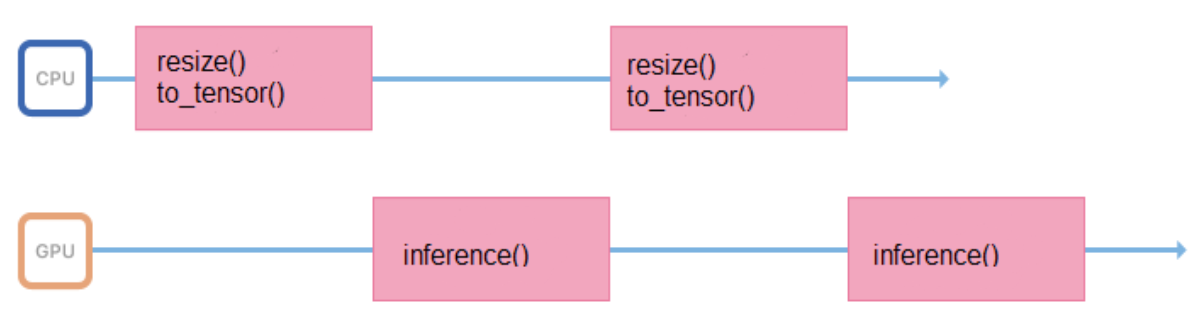
Il passe du temps dans le processeur, à préparer les données d'entrée, pendant un certain temps à attendre une réponse du GPU. Il est préférable de minimiser les intervalles entre les inférences afin que le GPU soit moins inactif.
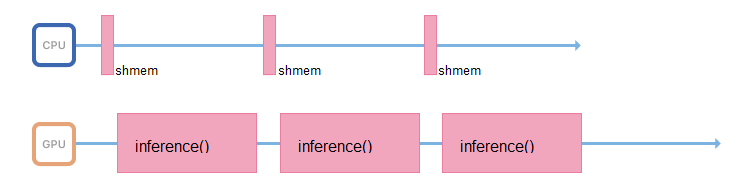
Pour ce faire, vous pouvez démarrer un autre flux, ou transférer la préparation d'images vers d'autres serveurs, sans cartes vidéo, mais avec des processeurs puissants.
Si possible, le processus responsable de l'inférence ne doit traiter que de celle-ci: accéder à la mémoire partagée, collecter les données d'entrée, les copier immédiatement dans la mémoire de la carte vidéo et exécuter l'inférence.
Turbo boost
Le lancement de réseaux de neurones est une opération qui consomme des ressources non seulement du GPU, mais aussi du processeur. Même si tout est correctement organisé en termes de bande passante et que le thread qui effectue l'inférence attend déjà de nouvelles données, sur un processeur faible, vous n'aurez tout simplement pas le temps de saturer ce flux avec de nouvelles données.
De nombreux processeurs prennent en charge la technologie Turbo Boost. Il vous permet d'augmenter la fréquence du processeur, mais il n'est pas toujours activé par défaut. Cela vaut la peine de le vérifier. Pour cela, Linux a l'utilitaire CPU Power:
$ cpupower frequency-info -m .
Les processeurs ont également un mode de consommation d'énergie qui peut être reconnu par une telle commande CPU Power:
performance .
En mode d'économie d'énergie, le processeur peut limiter sa fréquence et fonctionner plus lentement. Vous devez aller dans le BIOS et sélectionner le mode de performance. Ensuite, le processeur fonctionnera toujours à la fréquence maximale.
Déploiement d'applications
Docker est idéal pour déployer l'application, il vous permet d'exécuter des applications sur le GPU à l'intérieur du conteneur. Pour accéder aux cartes vidéo, vous devez d'abord installer les pilotes de la carte vidéo sur le système hôte - un serveur physique. Ensuite, pour démarrer le conteneur, vous devez faire beaucoup de travail manuel: jetez correctement les cartes vidéo à l'intérieur du conteneur avec les bons paramètres. Après avoir démarré le conteneur, il sera toujours nécessaire d'installer des pilotes vidéo à l'intérieur. Et seulement après cela, vous pouvez utiliser votre application.

Cette approche comporte une mise en garde. Les serveurs peuvent disparaître du cluster et être ajoutés. Il est possible que différents serveurs aient différentes versions de pilotes, et ils seront différents de la version installée à l'intérieur du conteneur. Dans ce cas, un Docker simple se cassera: l'application recevra une erreur de non-concordance de version de pilote lors de la tentative d'accès à la carte vidéo.

Comment y faire face? Il existe une version de Docker de NVIDIA, grâce à laquelle il devient plus facile et plus agréable d'utiliser le conteneur. Selon NVIDIA lui-même et selon les observations pratiques, le surcoût lié à l'utilisation de nvidia-docker est d'environ 1%.
Dans ce cas, les pilotes doivent être installés uniquement sur la machine hôte. Lorsque vous démarrez le conteneur, vous n'avez pas besoin de jeter quoi que ce soit à l'intérieur, et l'application aura immédiatement accès aux cartes vidéo.

L '"indépendance" de nvidia-docker par rapport aux pilotes vous permet d'exécuter un conteneur à partir de la même image sur différentes machines sur lesquelles différentes versions de pilotes sont installées. Comment est-ce mis en œuvre? Docker a un concept appelé docker-runtime: c'est un ensemble de normes qui décrit comment un conteneur doit communiquer avec le noyau hôte, comment il doit démarrer et s'arrêter, comment interagir avec le noyau et le pilote. À partir d'une version spécifique de Docker, il est possible de remplacer ce runtime. C'est ce que NVIDIA a fait: ils remplacent le runtime, interceptent les appels vers le pilote vidéo à l'intérieur et convertissent la bonne version en appels vers le pilote vidéo.
Orchestration
Nous avons choisi Kubernetes comme orchestre. Il prend en charge de nombreuses fonctionnalités très intéressantes qui sont utiles pour tout système lourdement chargé. Par exemple, la découverte automatique permet aux services d'accéder les uns aux autres au sein d'un cluster sans règles de routage complexes. Ou tolérance aux pannes - lorsque Kubernetes garde toujours plusieurs conteneurs prêts et si quelque chose vous arrive, Kubernetes lance immédiatement un nouveau conteneur.
Si vous avez déjà configuré un cluster Kubernetes, vous n'avez pas besoin de tant de choses pour commencer à utiliser des cartes vidéo à l'intérieur du cluster:
- pilotes relativement frais
- installé nvidia-docker version 2
- runtime de docker défini par défaut sur `nvidia` dans /etc/docker/daemon.json:
"default-runtime": "nvidia"
- Plugin installé
kubectl create -f https://githubusercontent.com/k8s-device-plugin/v1.12/plugin.yml
Après avoir configuré votre cluster et installé le plug-in de périphérique, vous pouvez spécifier une carte vidéo comme ressource.
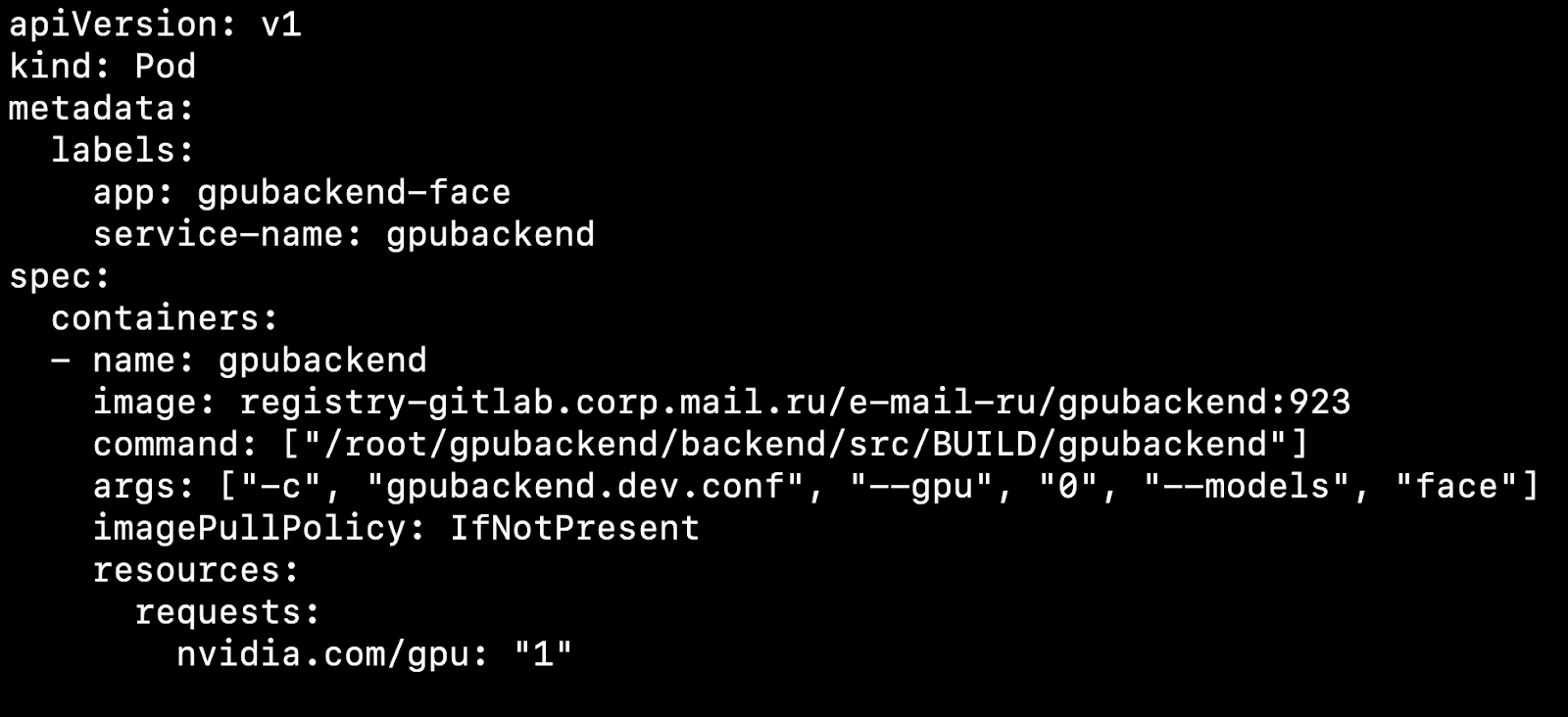
Qu'est-ce que cela affecte? Disons que nous avons deux nœuds, des machines physiques. Sur l'un il y a une carte vidéo, sur l'autre non. Kubernetes détectera une machine avec une carte vidéo et récupérera notre pod dessus.
Il est important de noter que Kubernetes ne sait pas comment tâtonner avec compétence une carte vidéo entre des modules. Si vous avez 4 cartes vidéo et que vous avez besoin d'un GPU pour démarrer le conteneur, vous ne pouvez pas soulever plus de 4 pods sur votre cluster.
Nous prenons en règle générale 1 Pod = 1 Model = 1 GPU.
Il existe une option pour exécuter plus d'instances sur 4 cartes vidéo, mais nous ne l'examinerons pas dans cet article, car cette option ne sort pas de la boîte.
Si plusieurs modèles doivent tourner simultanément, il est pratique de créer un déploiement dans Kubernetes pour chaque modèle. Dans son fichier de configuration, vous pouvez spécifier le nombre de foyers pour chaque modèle, en tenant compte de la popularité du modèle. Si un grand nombre de requêtes arrivent sur le modèle, vous devez alors spécifier un grand nombre de pods, s'il y a peu de requêtes, il y a peu de pods. Au total, le nombre de foyers doit être égal au nombre de cartes vidéo du cluster.
Considérez un point intéressant. Disons que nous avons 4 cartes vidéo et 3 modèles.
Sur les deux premières cartes vidéo, laissez l'inférence du modèle de reconnaissance faciale augmenter, sur une autre reconnaissance d'objets et sur une autre reconnaissance de numéros de voiture.
Vous travaillez, les clients vont et viennent, et une fois, par exemple la nuit, une situation se produit lorsqu'une carte vidéo avec des objets d'inférence n'est tout simplement pas chargée, qu'une petite quantité de demandes lui parvient et que les cartes vidéo avec reconnaissance faciale sont surchargées. Je voudrais sortir un modèle avec des objets en ce moment et lancer des visages à sa place pour décharger les lignes.
Pour la mise à l'échelle automatique des modèles sur les cartes vidéo, il existe des outils à l'intérieur de Kubernetes - mise à l'échelle automatique du foyer horizontal (HPA, autoscaler horizontal pod).
Prêt à l'emploi, Kubernetes prend en charge la mise à l'échelle automatique sur l'utilisation du processeur. Mais dans une tâche avec des cartes vidéo, il sera beaucoup plus raisonnable d'utiliser des informations sur le nombre de tâches pour chaque modèle pour la mise à l'échelle.
Nous faisons cela: mettre les demandes pour chaque modèle dans une file d'attente. Une fois les demandes terminées, nous les supprimons de cette file d'attente. Si nous parvenons à traiter rapidement les demandes de modèles populaires, la file d'attente ne s'allonge pas. Si le nombre de demandes pour un modèle particulier augmente soudainement, la file d'attente commence à s'allonger. Il devient clair que vous devez ajouter des cartes vidéo qui vous aideront à ratisser la ligne.
Informations sur les files d'attente que nous mandatons via HPA via Prometheus:
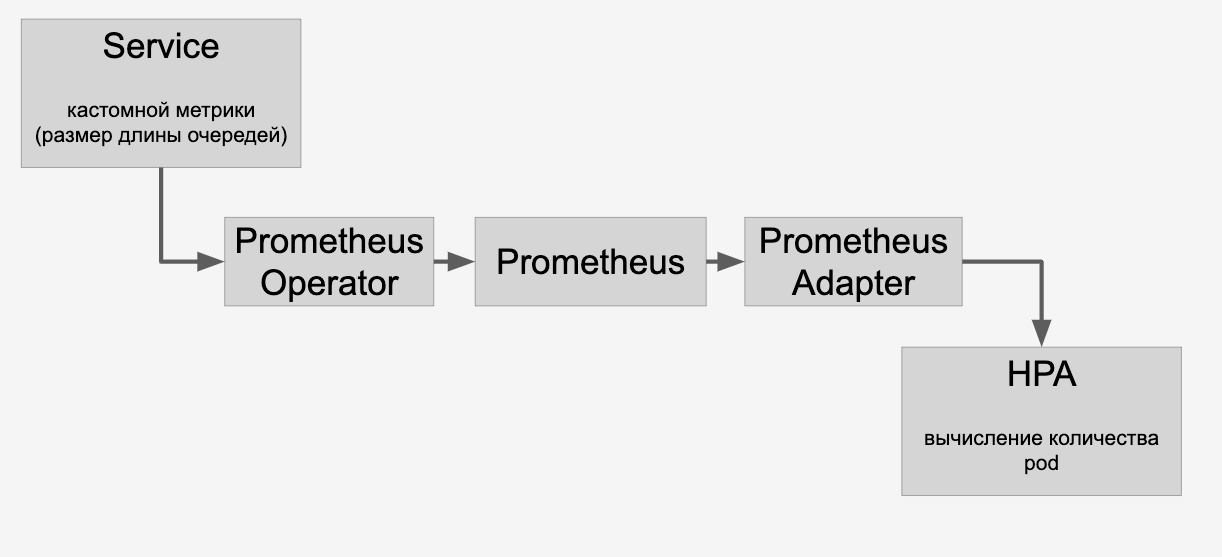
Et puis nous effectuons la mise à l'échelle automatique des modèles sur les cartes vidéo du cluster en fonction du nombre de requêtes qui leur sont adressées.
CI / CD
Une fois que vous avez inclus l'application et l'avez enveloppée dans Kubernetes, il vous reste littéralement une étape vers le haut du projet. Vous pouvez ajouter CI / CD, voici un exemple de notre pipeline:
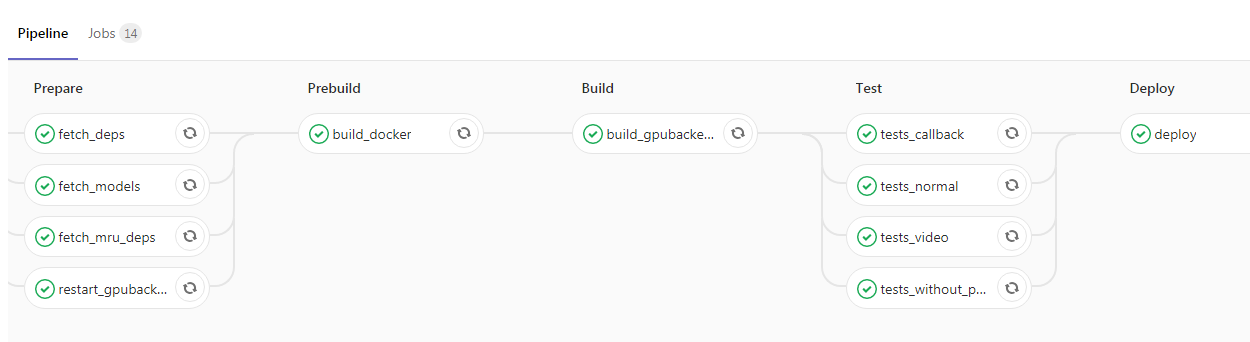
Ici, le programmeur a lancé le nouveau code dans la branche principale, après quoi l'image Docker avec nos démons backend est automatiquement collectée et les tests sont exécutés. Si toutes les cases sont vertes, l'application est versée dans l'environnement de test. S'il n'y a aucun problème, vous pouvez envoyer l'image en fonctionnement sans aucune difficulté.
Conclusion
Dans mon article, j'ai abordé certains aspects du travail d'un service très chargé utilisant un GPU. Nous avons parlé des moyens de réduire le temps de réponse d'un service, tels que:
- sélection de l'architecture optimale du réseau neuronal pour réduire la latence;
- Applications d'optimisation de frameworks comme TensorRT.
A soulevé les questions de l'augmentation du débit:
- l'utilisation du lot d'images;
- appliquer une stratégie de latence fixe de façon à réduire le nombre de cycles d'inférence, mais chaque inférence traiterait un plus grand nombre d'images;
- optimisation du pipeline d'entrée de données pour minimiser les temps d'arrêt du GPU;
- "Combattez" avec le trot du processeur, la suppression des opérations liées au processeur vers d'autres serveurs.
Nous avons examiné le processus de déploiement d'une application avec un GPU:
- Utiliser nvidia-docker dans Kubernetes
- mise à l'échelle basée sur le nombre de demandes et HPA (horizontal pod autoscaler).