L'une des fonctionnalités les plus intéressantes de l'iPhone X est la méthode de déverrouillage: FaceID. Cet article traite du principe de fonctionnement de cette technologie.

L'image du visage de l'utilisateur est capturée à l'aide d'une caméra infrarouge, plus résistante aux changements de lumière et de couleur de l'environnement. Grâce à une formation approfondie, un smartphone est capable de reconnaître le visage de l'utilisateur dans les moindres détails, «reconnaissant» ainsi le propriétaire chaque fois qu'il décroche son téléphone. Étonnamment, Apple a déclaré que cette méthode était encore plus sûre que TouchID: le taux d'erreur est de 1: 1 000 000.
Cet article explore le principe d'un algorithme similaire à FaceID utilisant Keras. Sont également présentés certains des développements finaux créés à l'aide de Kinect.
Comprendre FaceID
"... les réseaux de neurones sur lesquels la technologie FaceID est basée n'effectuent pas seulement la classification."
La première étape consiste à analyser le fonctionnement de FaceID sur l'iPhone X. La
documentation technique peut nous y aider. Avec TouchID, l'utilisateur devait d'abord enregistrer ses empreintes digitales en appuyant plusieurs fois sur le capteur. Après 10-15 touches différentes, le smartphone termine l'enregistrement.
De même avec FaceID: l'utilisateur doit enregistrer son visage. Le processus est assez simple: l'utilisateur regarde simplement le téléphone comme il le fait quotidiennement, puis tourne lentement la tête en cercle, enregistrant ainsi son visage dans différentes poses. Cela met fin à l'enregistrement et le téléphone est prêt à être déverrouillé. Cette procédure d'enregistrement incroyablement rapide peut en dire long sur les algorithmes d'apprentissage de base. Par exemple, les réseaux de neurones sur lesquels la technologie FaceID est basée n'effectuent pas seulement une classification.
Effectuer une classification pour un réseau neuronal signifie la capacité de prédire si la personne qu'elle «voit» en ce moment est le visage de l'utilisateur. Ainsi, elle devrait utiliser certaines données de formation pour prédire «vrai» ou «faux», mais contrairement à de nombreuses autres applications d'apprentissage en profondeur, cette approche ne fonctionnera pas ici.
Tout d'abord, le réseau doit s'entraîner à partir de zéro, en utilisant de nouvelles données reçues du visage de l'utilisateur. Cela nécessiterait beaucoup de temps, d'énergie et beaucoup de données de différentes personnes (n'étant pas le visage de l'utilisateur) afin d'avoir des exemples négatifs. De plus, cette méthode ne permettra pas à Apple de former un réseau plus complexe «hors ligne», c'est-à-dire dans ses laboratoires, puis de l'envoyer déjà formé et prêt à l'emploi sur leurs téléphones. On pense que FaceID est basé sur le réseau neuronal convolutif siamois, qui est formé «hors ligne» pour afficher les visages dans un espace caché de faible dimension, formé pour maximiser la différence entre les visages de différentes personnes, en utilisant la perte de contraste. Vous obtenez une architecture qui peut effectuer une formation unique, comme mentionné dans Keynote.

Du visage aux chiffres
Le réseau neuronal siamois se compose essentiellement de deux réseaux neuronaux identiques, qui partagent également tous les poids. Cette architecture peut apprendre à distinguer les distances entre des données spécifiques, telles que des images. L'idée est que vous transmettez des paires de données via des réseaux siamois (ou transférez simplement des données en deux étapes différentes via le même réseau), le réseau les affiche dans les caractéristiques de faible dimension de l'espace, comme un tableau à n dimensions, puis vous entraînez le réseau, de faire une telle comparaison que les données des points de différentes classes étaient autant que possible, tandis que les données des points de la même classe étaient aussi proches que possible.
En fin de compte, le réseau apprendra à extraire les fonctions les plus importantes des données et à les compresser dans un tableau, créant une image. Pour comprendre cela, imaginez comment vous décririez les races de chiens à l'aide d'un petit vecteur afin que des chiens similaires aient des vecteurs presque similaires. Vous utiliseriez probablement un numéro pour coder la couleur du chien, l'autre pour indiquer la taille du chien, le troisième pour la longueur du pelage, etc. Ainsi, les chiens qui se ressemblent auront des vecteurs similaires. Un réseau de neurones siamois peut le faire pour vous, tout comme un
codeur automatique .
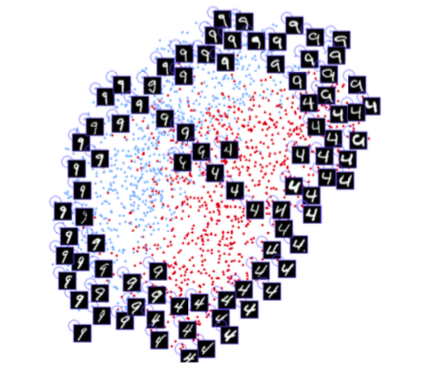
Grâce à cette technologie, un grand nombre de personnes sont nécessaires pour former une telle architecture afin de reconnaître les plus similaires. Avec le bon budget et la bonne puissance de calcul (comme le fait Apple), vous pouvez également utiliser des exemples plus complexes pour rendre le réseau résistant à des situations telles que des jumeaux, des masques, etc.
Quel est le dernier avantage de cette approche? Dans le fait que vous avez enfin un modèle plug and play qui peut reconnaître différents utilisateurs sans aucune préparation supplémentaire, mais simplement calculer l'emplacement du visage de l'utilisateur sur une carte de visage caché formée après avoir défini FaceID. De plus, FaceID est capable de s'adapter aux changements de votre apparence: à la fois soudaine (par exemple, lunettes, chapeau, maquillage) et «progressive» (croissance des cheveux). Cela se fait en ajoutant des vecteurs de support de visage calculés en fonction de votre nouveau look sur la carte.

Implémentation de FaceID avec Keras
Pour tous les projets d'apprentissage automatique, la première chose dont nous avons besoin, ce sont les données. La création de votre propre ensemble de données nécessitera du temps et la coopération de nombreuses personnes, cela peut donc être difficile. Il existe un site Web
avec un ensemble de données de faces RVB-D. Il se compose d'une série de photos RVB-D de personnes se tenant debout dans différentes poses et faisant différentes expressions faciales, comme ce serait le cas avec l'iPhone X. Pour voir la mise en œuvre finale, voici un lien vers
GitHub.Un réseau de convolution est créé sur la
base de l' architecture
SqueezeNet . En entrée, le réseau accepte à la fois des images RGBD de paires de visages et des images à 4 canaux, et affiche les différences entre les deux pièces jointes. Le réseau apprend avec une perte importante, ce qui minimise la différence entre les images d'une même personne et maximise la différence entre les images de visages différents.
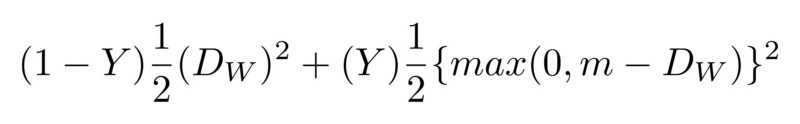
Après la formation, le réseau est capable de convertir des visages en tableaux à 128 dimensions, de sorte que les photos de la même personne soient regroupées. Cela signifie que pour déverrouiller l'appareil, le réseau de neurones calcule simplement la différence entre l'image requise lors du déverrouillage et les images stockées lors de la phase d'enregistrement. Si la différence correspond à une valeur spécifique, l'appareil est déverrouillé.
L'algorithme t-SNE est utilisé. Chaque couleur correspond à une personne: comme vous pouvez le voir, le réseau a appris à regrouper assez étroitement ces photos. Un graphique intéressant apparaît également lors de l'utilisation de l'algorithme PCA pour réduire la dimension des données.
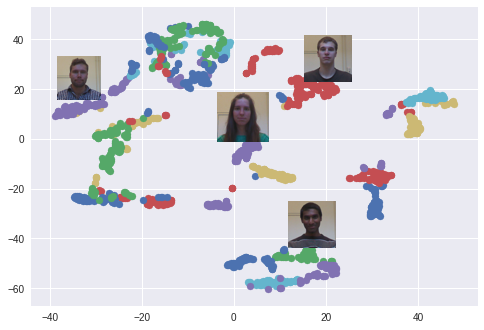

Une expérience
Essayons maintenant de voir comment ce modèle fonctionne, en simulant une boucle FaceID normale. Enregistrez d'abord la personne. Ensuite, nous le déverrouillerons au nom de l'utilisateur et d'autres personnes qui ne devraient pas déverrouiller l'appareil. Comme mentionné précédemment, la différence entre la personne qui «voit» le téléphone et la personne enregistrée a un certain seuil.
Commençons par l'inscription. Prenez une série de photographies de la même personne de l'ensemble de données et simulez la phase d'enregistrement. Maintenant, l'appareil calcule les pièces jointes pour chacune de ces poses et les enregistre localement.


Voyons ce qui se passe si le même utilisateur essaie de déverrouiller l'appareil. Différentes poses et expressions faciales d'un même utilisateur réalisent une faible différence, une moyenne d'environ 0,30.

D'un autre côté, les images de différentes personnes obtiennent une différence moyenne d'environ 1,1.

Ainsi, une valeur seuil d'environ 0,4 devrait être suffisante pour empêcher des étrangers de déverrouiller le téléphone.
Dans cet article, j'ai montré comment implémenter le concept de test de mécanique de déverrouillage FaceID basé sur l'intégration de faces et de réseaux de convolution siamois. J'espère que ces informations vous ont été utiles. Vous pouvez trouver
tout le code Python
relatif ici.
Plus d'analyse des nouvelles technologies - dans le
canal Telegram .
Toutes les connaissances!