L'article abordera la classification de la tonalité des messages texte en russe (et essentiellement toute classification des textes utilisant les mêmes technologies). Prenons
cet article comme base, dans laquelle la classification de la tonalité sur l'architecture CNN en utilisant le modèle Word2vec a été considérée. Dans notre exemple, nous allons résoudre le même problème de séparation des tweets en positifs et négatifs sur le même ensemble de données en utilisant le modèle
ULMFit . Le résultat de l'article (score F1 moyen = 0,78142) sera accepté comme référence.
Présentation
Le modèle ULMFIT a été introduit par les développeurs de fast.ai (Jeremy Howard, Sebastian Ruder) en 2018. L'essence de l'approche est d'utiliser l'apprentissage par transfert dans les tâches PNL lorsque vous utilisez des modèles pré-formés, ce qui réduit le temps de formation de vos modèles et les exigences de taille de l'échantillon de test étiqueté.
Le programme de formation dans notre cas ressemblera à ceci:

La signification du modèle de langage est de pouvoir prédire le mot suivant en séquence. Il est problématique d'obtenir de longs textes connectés de cette manière, mais néanmoins, les modèles de langage sont capables de capturer les propriétés de la langue, de comprendre le contexte de l'utilisation des mots, c'est donc le modèle de langage (et non, par exemple, l'affichage vectoriel des mots) qui est la base de la technologie. Pour la tâche de modélisation du langage, ULMFit utilise l'architecture
AWD-LSTM , qui implique l'utilisation active du décrochage dans la mesure du possible et est logique. Le type de formation sur le modèle linguistique est parfois appelé apprentissage semi-supervisé, car l'étiquette est le mot suivant et rien ne doit être marqué avec vos mains.
En tant que modèle de langue pré-formé, nous utiliserons presque le seul
disponible publiquement.
Passons en revue l'algorithme d'apprentissage dès le début.
Nous chargeons les bibliothèques (nous vérifions la version de Fast.ai en cas d'incompatibilités):
%load_ext autoreload %autoreload 2 import pandas as pd import numpy as np import re import statistics import fastai print('fast.ai version is:', fastai.__version__) from fastai import * from fastai.text import * from sklearn.model_selection import train_test_split path = ''
Out: fast.ai version is: 1.0.58
Nous préparons des données pour la formation
Par analogie, nous organiserons une formation sur le
corps des courts textes RuTweetCorp de Yulia Rubtsova , formés sur la base de messages en russe de Twitter. Le corps contient 114 991 tweets positifs et 111 923 tweets négatifs au format CSV. De plus, il existe une base de données de tweets non alloués avec un volume de 17 639 674 enregistrements au format SQL. La tâche de notre classificateur sera de déterminer si le tweet est positif ou négatif.
Étant donné
qu'il a fallu longtemps pour recycler le modèle de langage sur 17 millions de tweets et que la tâche de montrer l'apprentissage par transfert était la
paresse , nous allons recycler le modèle de langage sur un morceau de texte de l'ensemble de données de formation, ignorant complètement la base des tweets non alloués. Probablement, en utilisant cette base pour «affiner» le modèle de langage, vous pouvez améliorer le résultat global.
Nous formons des ensembles de données pour la formation et les tests avec un traitement de texte préliminaire. Nous reprenons le code de l'article d'
origine :
def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
df_train=pd.DataFrame(columns=['Text', 'Label']) df_test=pd.DataFrame(columns=['Text', 'Label']) df_train['Text'], df_test['Text'], df_train['Label'], df_test['Label'] = train_test_split(data, labels, test_size=0.2, random_state=1)
df_val=pd.DataFrame(columns=['Text', 'Label']) df_train, df_val = train_test_split(df_train, test_size=0.2, random_state=1)
Nous regardons ce qui s'est passé:
df_train.groupby('Label').count()
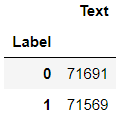
df_val.groupby('Label').count()
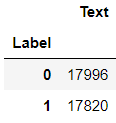
df_test.groupby('Label').count()

Apprendre un modèle de langue
Chargement des données:
tokenizer=Tokenizer(lang='xx') data_lm = TextLMDataBunch.from_df(path, tokenizer=tokenizer, bs=16, train_df=df_train, valid_df=df_val, text_cols=0)
Nous regardons le contenu:
data_lm.show_batch()

Nous fournissons des liens vers les poids stockés du modèle
pré -
formé et un dictionnaire:
weights_pretrained = 'ULMFit/lm_5_ep_lr2-3_5_stlr' itos_pretrained = 'ULMFit/itos' pretained_data = (weights_pretrained, itos_pretrained)
Nous créons l'apprenant, mais avant cela - une béquille pour fast.ai. Le modèle pré-formé a été formé sur une ancienne version de la bibliothèque, vous devez donc ajuster le nombre de nœuds dans la couche cachée du réseau neuronal.
config = awd_lstm_lm_config.copy() config['n_hid'] = 1150 learn_lm = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=pretained_data, drop_mult=0.3) learn_lm.freeze()
Nous recherchons le taux d'apprentissage optimal:
learn_lm.lr_find() learn_lm.recorder.plot()

Nous formons le modèle de la 3e ère (dans le modèle, seul le dernier groupe de couches est dégelé).
learn_lm.fit_one_cycle(3, 1e-2, moms=(0.8, 0.7))
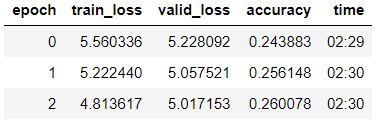
Décongélation du modèle, enseignement de 5 ères supplémentaires avec un taux d'apprentissage plus faible:
learn_lm.unfreeze() learn_lm.fit_one_cycle(5, 1e-3, moms=(0.8, 0.7))

learn_lm.save('lm_ft')
Nous essayons de générer du texte sur un modèle formé.
learn_lm.predict(" ", n_words=5)
Out: ' '
learn_lm.predict(", ", n_words=4)
Out: ', '
Nous voyons - quelque chose que le modèle fait. Mais notre tâche principale est la classification, et pour sa solution, nous prendrons un encodeur du modèle.
learn_lm.save_encoder('ft_enc')
Nous formons le classificateur
Télécharger les données pour la formation
data_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_val, text_cols=0, label_cols=1, tokenizer=tokenizer)
Regardons les données, nous voyons que les étiquettes ont été comptées avec succès (0 signifie négatif et 1 signifie un commentaire positif):
data_clas.show_batch()

Créez un apprenant avec une béquille similaire:
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn = text_classifier_learner(data_clas, AWD_LSTM, config=config, drop_mult=0.5)
Nous chargeons l'encodeur formé à l'étape précédente et gelons le modèle, sauf pour le dernier groupe de poids:
learn.load_encoder('ft_enc') learn.freeze()
Nous recherchons le taux d'apprentissage optimal:
learn.lr_find() learn.recorder.plot(skip_start=0)

Nous formons le modèle avec la décongélation progressive des couches.
learn.fit_one_cycle(2, 2e-2, moms=(0.8,0.7))
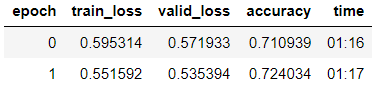
learn.freeze_to(-2) learn.fit_one_cycle(3, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))

learn.freeze_to(-3) learn.fit_one_cycle(2, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))

learn.unfreeze() learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))

learn.save('tweet-0801')
Nous voyons que sur l'échantillon de validation, ils ont atteint une précision = 80,1%.
Nous allons tester le modèle sur le commentaire
ZlodeiBaal de mon précédent article:
learn.predict(' — ?')
Out: (Category 0, tensor(0), tensor([0.6283, 0.3717]))
On voit que le modèle attribue ce commentaire à négatif :-)
Vérification du modèle sur un échantillon de test
À ce stade, la tâche principale consiste à tester la capacité de généralisation du modèle. Pour ce faire, nous validons le modèle sur l'ensemble de données stocké dans le DataFrame df_test, qui jusque-là n'était pas disponible pour le modèle de langage ou pour le classifieur.
data_test_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_test, text_cols=0, label_cols=1, tokenizer=tokenizer)
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn_test = text_classifier_learner(data_test_clas, AWD_LSTM, config=config, drop_mult=0.5)
learn_test.load_encoder('ft_enc') learn_test.load('tweet-0801')
learn_test.validate()
Out: [0.4391682, tensor(0.7973)]
Nous constatons que la précision sur l'échantillon testé s'est avérée être de 79,7%.
Jetez un œil à Confusion Matrix:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
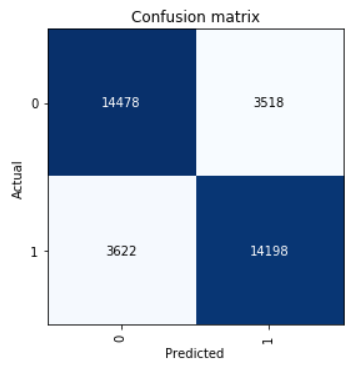
Nous calculons les paramètres de précision, de rappel et de score f1.
neg_precision = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[1][0]) neg_recall = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[0][1]) pos_precision = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[0][1]) pos_recall = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[1][0]) neg_f1score = 2 * (neg_precision * neg_recall) / (neg_precision + neg_recall) pos_f1score = 2 * (pos_precision * pos_recall) / (pos_precision + pos_recall)
print(' F1-score') print(' Negative {0:1.5f} {1:1.5f} {2:1.5f}'.format(neg_precision, neg_recall, neg_f1score)) print(' Positive {0:1.5f} {1:1.5f} {2:1.5f}'.format(pos_precision, pos_recall, pos_f1score)) print(' Average {0:1.5f} {1:1.5f} {2:1.5f}'.format(statistics.mean([neg_precision, pos_precision]), statistics.mean([neg_recall, pos_recall]), statistics.mean([neg_f1score, pos_f1score])))
Out: F1-score Negative 0.79989 0.80451 0.80219 Positive 0.80142 0.79675 0.79908 Average 0.80066 0.80063 0.80064
Le résultat indiqué dans l'échantillon test F1-score moyen = 0,80064.
Les poids des modèles enregistrés peuvent être pris
ici .