Salut Je m'appelle Evgeny Kashin et je travaille au laboratoire d'intelligence artificielle Yandex. Nous avons récemment lancé un jeu dans lequel les utilisateurs rivalisent avec Alice dans les pays à deviner à partir de photographies.
La façon dont les gens agissent est compréhensible: ils reconnaissent les endroits qu'ils ont vus en voyage ou au cinéma, s'appuient sur l'érudition et le bon sens. Le réseau neuronal n'a rien de tout cela. Nous nous sommes demandés quels détails sur les photos lui ont donné la réponse. Nous avons mené une étude dont nous partagerons aujourd'hui les résultats avec Habr.
Ce poste sera intéressant à la fois pour les spécialistes du domaine de la vision par ordinateur, et pour tous ceux qui souhaitent regarder à l'intérieur de "l'intelligence artificielle" et comprendre la logique de son travail.

Quelques mots sur le jeu "
Devinez le pays par photo ". En bref, nous avons pris des photos de Yandex.Maps et les avons divisées en deux groupes. Le premier groupe a été montré par des réseaux de neurones, indiquant où chaque photo a été prise. Après avoir examiné des milliers de photographies, le réseau de neurones s'est fait une idée de chaque pays - c'est-à-dire qu'il a identifié indépendamment des combinaisons de signes permettant de le reconnaître. Nous utilisons le deuxième groupe d'images du jeu, Alice ne les a pas vues et ne s'en souvient pas pendant le jeu. Alice joue bien, mais les gens ont un avantage: nous n'avons pas formé le réseau neuronal à reconnaître les numéros de machine, les textes des signes et des signes, les drapeaux des états.
Pour le jeu, nous avons formé le modèle pour prédire le pays à partir d'une photo. Nous avons pris un modèle de vision par ordinateur
SE-ResNeXt-101 , pré-
formé sur de nombreuses tâches. Les signes obtenus à partir de l'image utilisant ce réseau de neurones convolutifs sont assez universels, donc pour le classificateur de pays, il n'a fallu ajouter que quelques couches supplémentaires (ce que l'on appelle la tête). Les données Yandex.Mart ont été utilisées pour la formation: environ 2,5 millions de photos. De nombreuses photos ne correspondaient pas au jeu selon le critère de la beauté et ont été filtrées. La beauté est comprise comme une combinaison de facteurs: la qualité de la photo, la présence de personnes, le texte, la forêt, la mer. Des images similaires ont été retirées du même endroit afin que le modèle ne se souvienne pas de vues spécifiques. Après tout le filtrage, il restait environ 1 million de photos. Après avoir formé le modèle sur ces données, nous avons obtenu un classificateur assez précis, qui détermine le pays uniquement par photo, sans utiliser d'informations supplémentaires.
Étant donné que la classification est effectuée à l'aide d'un réseau de neurones, nous ne pouvons pas facilement obtenir une interprétation des prédictions, contrairement aux modèles linéaires plus simples ou aux arbres de décision. Mais nous voulions savoir comment un réseau de neurones détermine à partir d'une photographie régulière d'une rue ou d'une maison de quel pays il s'agit. Et les cas les plus intéressants sont sans attraits dans le cadre.
Pour ce faire, nous avons formé le réseau neuronal à partir de zéro, en ne lui fournissant pas des images entières, mais seulement de petits morceaux de culture (de sorte que le modèle ne se souvienne pas de lieux spécifiques ou de gros objets).
Ainsi, la tâche pour le modèle est devenue sensiblement plus difficile (essayez de deviner le pays par un morceau de ciel), la précision de reconnaissance a considérablement diminué. Mais d'un autre côté, le réseau neuronal a dû prêter plus d'attention aux petits détails: maçonnerie inhabituelle, motifs spécifiques, type de toit, plantes. La taille du recadrage appliqué au modèle a changé et différents modèles ont été obtenus qui regardaient la photo à différents niveaux d'abstraction: plus le recadrage était petit, plus la tâche était difficile et plus le modèle était attentif aux détails.

Des algorithmes pour interpréter les prédictions peuvent être appliqués à des modèles qui ont été formés sur des tailles de cultures de différentes tailles. Je voudrais interpréter les prédictions dans les photographies sources. La plupart des réseaux de convolution modernes utilisent le
Global Average Pooling (GAP) avant la dernière couche - cela permet de former le réseau sur une taille et de l'appliquer sur une autre. Cela est dû au fait qu'avant la dernière couche, les entités spatiales, réparties en largeur et en hauteur, sont moyennées en un numéro pour chaque canal (carte des entités). Par conséquent, des modèles formés sur le recadrage (par exemple, 160 × 160 pixels) peuvent être utilisés sur les grandes images originales (800 × 800).
En fait, la couche GAP est nécessaire non seulement pour utiliser le modèle à différentes résolutions ou pour la régularisation. Il aide également le réseau neuronal à stocker des informations sur la position des objets jusqu'à la toute dernière couche (juste ce dont nous avons besoin).
La première méthode que nous avons essayée est la
cartographie d'activation de classe (CAM).
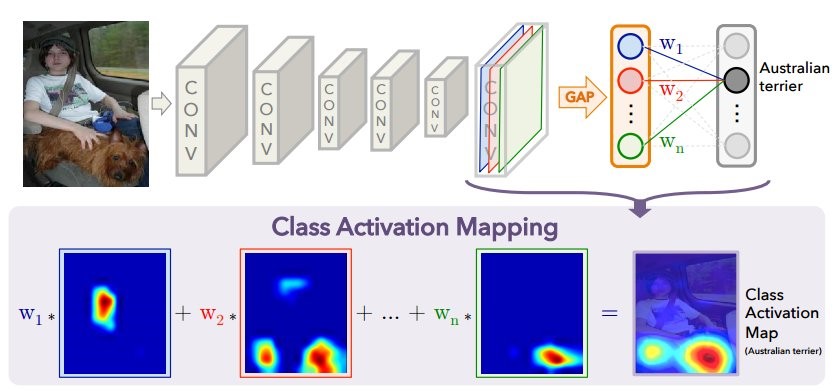
Lorsque l'image est envoyée à l'entrée du réseau neuronal, puis sur l'avant-dernière couche, une «image» réduite (en fait le tenseur d'activation) est obtenue avec les signes les plus importants pour chaque classe prédite. En utilisant la méthode CAM, vous pouvez modifier les dernières couches afin que la sortie soit la probabilité de chaque classe dans chaque région. Par exemple, si vous voulez prédire 60 classes (pays), pour une image d'entrée de 800 × 800, l'image finale sera composée de 60 cartes d'activation de taille 25 × 25. Ceci est bien illustré dans la publication
originale .
Le diagramme ci-dessus montre le modèle habituel avec GAP: les entités spatiales sont compressées en un numéro pour chaque canal (carte des entités), après quoi il y a une couche entièrement connectée qui prédit les classes qui trouvent les poids optimaux pour chaque canal. Ce qui suit montre comment modifier l'architecture pour obtenir la méthode CAM: la couche GAP est supprimée et les poids de la dernière couche entièrement connectée obtenue lors de la formation avec GAP (ci-dessus dans le diagramme) sont utilisés pour chaque canal à chaque point. Pour chaque image, N cartes d'activation sont obtenues pour toutes les classes prédites. Pour chaque pays, plus la zone de la «carte» est lumineuse, plus la contribution de cette section de l'image à la décision de choisir un pays est importante. Ce qui est intéressant: si après cette opération, nous faisons la moyenne de chaque carte d'activation (en gros, appliquons GAP), alors nous obtenons juste la prédiction initiale pour chaque classe.

Dans l'image, vous voyez une carte d'activation pour la classe la plus probable (selon le modèle). Il a été obtenu en étirant la carte d'activation de 25 × 25 à la taille de l'image originale 800 × 800.
Après avoir reçu une telle carte pour chaque image, nous pouvons agréger le recadrage le plus important pour les pays à partir d'images différentes. Cela vous permet de regarder la collection de cultures, décrivant le pays de la meilleure façon.
La seconde méthode, avec laquelle nous avons décidé de comparer la première, est une simple recherche exhaustive. Que se passe-t-il si nous prenons un modèle formé sur de petites cultures (par exemple, 160 × 160 pixels) et prédisons chaque pièce sur une grande image 800 × 800 avec? En passant une fenêtre coulissante recouvrant chaque zone de l'image, nous obtenons une autre version de la carte d'activation, montrant la probabilité que chaque morceau de l'image appartient à la classe du pays prédit.

L'image est découpée en petits récipients avec un chevauchement de 160 × 160. Pour chaque recadrage, le réseau neuronal fait des prédictions, le nombre au dessus du recadrage est la probabilité d'appartenir à la classe que le modèle a finalement prédit.
Comme dans la première méthode, nous pouvons à nouveau choisir les pièces les plus probables pour chaque pays. Mais les images obtenues par les deux méthodes pour le pays peuvent être uniformes (par exemple, un bâtiment sous différents angles ou une version de la texture). Par conséquent, la meilleure récolte pour le pays est en outre regroupée - alors la plupart des images similaires seront rassemblées en un seul cluster. Après cela, il suffira de prendre une photo de chaque cluster avec la probabilité maximale - pour chaque pays, il y aura autant d'images que de clusters spécifiés. Nous avons effectué un regroupement basé sur les caractéristiques obtenues à partir de la dernière couche de classificateur. Le regroupement agglomératif dans notre cas s'est avéré être le meilleur.

Après avoir reçu un pipeline assez similaire pour les deux méthodes, vous pouvez parcourir les paramètres des algorithmes pour trouver la combinaison optimale. Par exemple, nous avons sélectionné la taille du recadrage et opté pour deux options: 160 et 256 pixels. Les cultures inférieures à 160 ont donné des signes trop petits, selon lesquels une personne ne comprend souvent pas ce qui est représenté. Et recadrer plus de 256 contenait parfois plusieurs objets à la fois. Différents paramètres doivent être sélectionnés au stade du clustering: le choix de l'algorithme principal, ainsi que les caractéristiques par lesquelles le clustering est effectué. Pour de nombreuses combinaisons de paramètres, il était immédiatement clair qu'ils donnaient une récolte insuffisamment «intéressante». Mais pour sélectionner l'algorithme final, nous avons mené des expériences côte à côte sur Tolok pour comprendre quelle option, selon les gens, décrit le pays spécifique de manière «plus appropriée».
Il s'est avéré peu intuitif qu'une méthode plus simple de recherche de recadrage dans l'image (recherche normale) trouve des objets plus «intéressants». Cela peut être dû au fait que dans la deuxième méthode (énumération), le réseau neuronal ne voit pas la partie voisine de l'image, et dans la méthode CAM, l'environnement du point affecte le résultat. En conséquence, nous avons reçu une visualisation des caractéristiques de chaque pays en mode automatique.
Alors maintenant, nous savons quelles parties du cadre sont d'une importance décisive pour le réseau neuronal, et nous pouvons voir ce qui est tombé dessus. Par exemple, les Pays-Bas reconnaissent un réseau de neurones par la combinaison de murs de briques sombres et de contours de fenêtres blanches, les Émirats arabes unis - par des gratte-ciel spécifiques sur le fond des palmiers et l'Iran - par les arcs et les ornements caractéristiques des façades.