L'ensemble de données utilisé ci-après est tiré d'un concours
de kaggle déjà passé
d'ici .
Dans l'onglet Données, vous pouvez lire la description de tous les champs.
Tout le code source
est au format ordinateur portable
ici .
Nous chargeons les données, vérifions que nous avons généralement:
import numpy as np import pandas as pd dataset = pd.read_csv('../input/ghouls-goblins-and-ghosts-boo/train.csv')
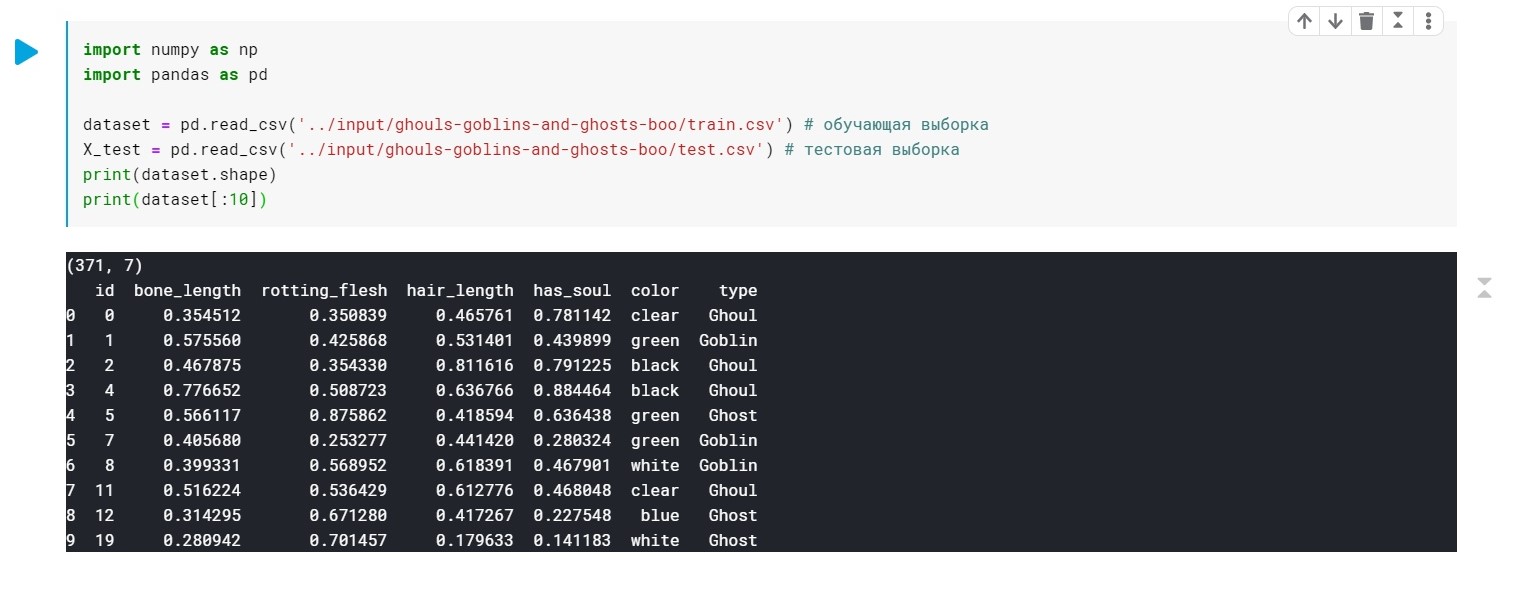
Les valeurs du champ type (Ghoul, Ghost, Goblin) sont simplement remplacées par 0, 1 et 2.
Couleur - doit également être prétraité (nous n'avons besoin que de valeurs numériques pour construire le modèle). Nous utiliserons pour cela LabelEncoder et OneHotEncoder.
Plus de détails .
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X_1 = LabelEncoder() X_train[:, 4] = labelencoder_X_1.fit_transform(X_train[:, 4]) labelencoder_X_2 = LabelEncoder() X_test[:, 4] = labelencoder_X_2.fit_transform(X_test[:, 4]) labelencoder_Y_2 = LabelEncoder() Y_train = labelencoder_Y_2.fit_transform(Y_train) one_hot_encoder = OneHotEncoder(categorical_features = [4]) X_train = one_hot_encoder.fit_transform(X_train).toarray() X_test = one_hot_encoder.fit_transform(X_test).toarray()
Eh bien, à ce stade, nos données sont prêtes. Reste à former notre modèle.
Appliquez d'abord
Adagrad :
En substance, il s'agit d'une modification de la descente du gradient stochastique, à propos de laquelle j'ai écrit la dernière fois:
habr.com/en/post/472300Cette méthode prend en compte l'historique de tous les gradients passés pour chaque paramètre individuel (l'idée de mise à l'échelle). Cela vous permet de réduire la taille de l'étape d'apprentissage pour les paramètres qui ont un grand gradient:
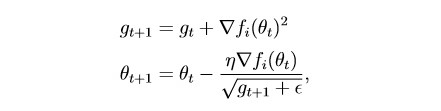
g est le paramètre de mise à l'échelle (g0 = 0)
θ - paramètre (poids)
epsilon est une petite constante introduite afin d'éviter la division par zéro
Divisez l'ensemble de données en 2 parties:
Échantillon de formation (train) et validation (val):
from sklearn.model_selection import train_test_split x_train, x_val, y_train, y_val = train_test_split(X_train, Y_train, test_size = 0.2)
Un peu de préparation à la formation de modèle:
import torch import numpy as np device = 'cuda' if torch.cuda.is_available() else 'cpu' def make_train_step(model, loss_fn, optimizer): def train_step(x, y): model.train() yhat = model(x) loss = loss_fn(yhat, y) loss.backward() optimizer.step() optimizer.zero_grad() return loss.item() return train_step
Modèle d'auto-formation:
from torch import optim, nn model = torch.nn.Sequential( nn.Linear(10, 270), nn.ReLU(), nn.Linear(270, 3)) lr = 0.01 n_epochs = 500 loss_fn = torch.nn.CrossEntropyLoss() optimizer = optim.Adagrad(model.parameters(), lr=lr) train_step = make_train_step(model, loss_fn, optimizer) from sklearn.utils import shuffle for epoch in range(n_epochs): x_train, y_train = shuffle(x_train, y_train)
Évaluation du modèle:
Ici, en plus des couches, nous n'avons que 2 paramètres configurables (pour l'instant):
taux d'apprentissage et n_époques (nombre d'époques).
Selon la façon dont nous combinons ces deux paramètres, 3 situations peuvent survenir:
1 - tout va bien, c'est-à-dire le modèle montre une faible perte sur l'échantillon d'apprentissage et une grande précision sur l'échantillon de validation.
2 - sous-ajustement - perte importante sur l'échantillon d'entraînement et faible précision sur celui de validation.
3 - sur-ajustement - faible perte sur l'échantillon d'entraînement, mais faible précision sur celui de validation.
Avec le premier, tout est clair :)
Avec le second, il semble aussi - expérimenter le taux d'apprentissage et les n_époques.
Et que faire du troisième? La réponse est simple: régularisation!
Auparavant, nous avions une fonction de perte du formulaire:
L = MSE (Y, y) sans conditions supplémentaires
L'essence de la régularisation est précisément que, en ajoutant un terme à la fonction objectif, «affinez» le gradient s'il est trop grand. En d'autres termes, nous imposons une restriction à notre fonction objective.
Il existe de nombreuses méthodes de régularisation. En savoir plus sur L1 et L2 - régularisation:
craftappmobile.com/l1-vs-l2-regularization/#_L1_L2La méthode Adagrad implémente la régularisation L2, appliquons-la!
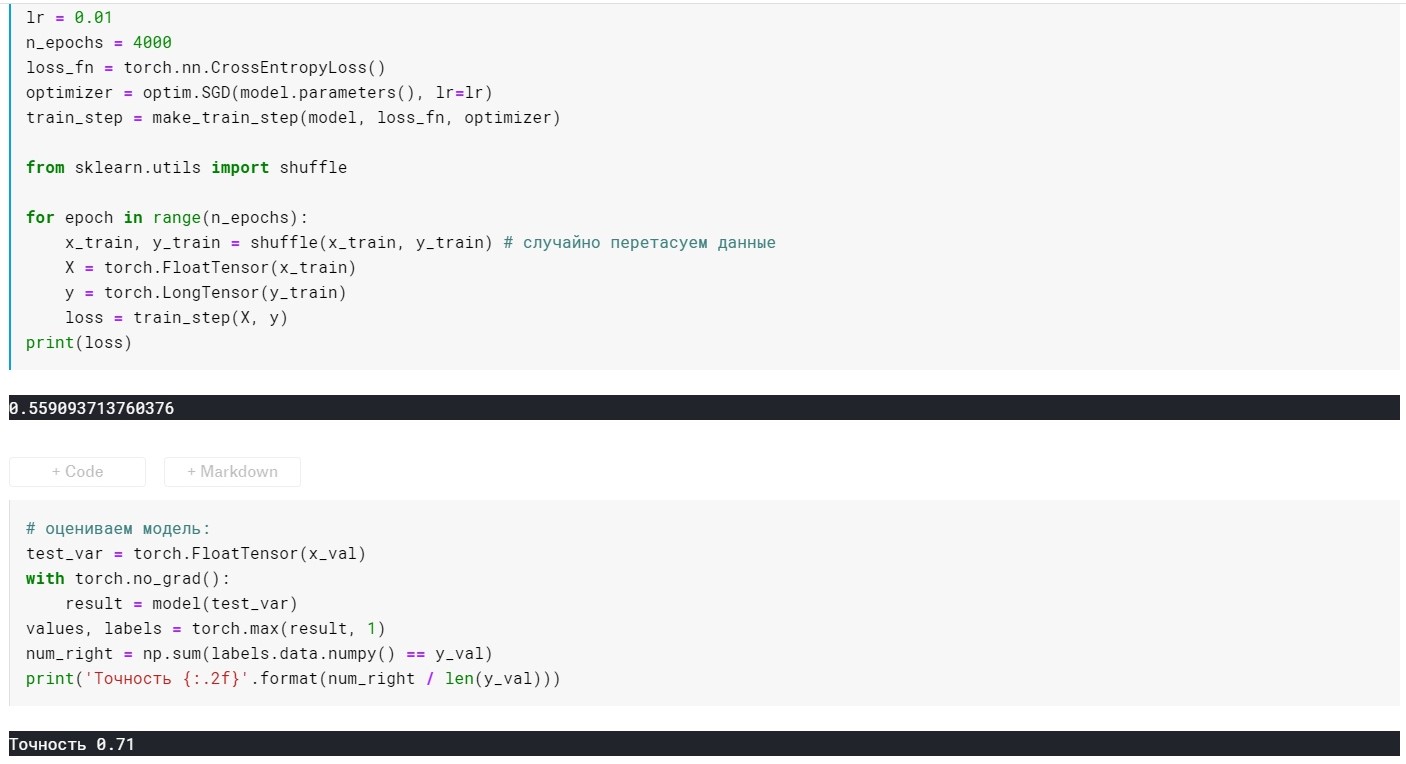
Tout d'abord, pour plus de clarté, nous regardons les indicateurs du modèle sans régularisation:
lr = 0,01, n_époques = 500:
perte = 0,44 ...
Précision: 0,71
lr = 0,01, n_époques = 1000:
perte = 0,41 ...
Précision: 0,75
lr = 0,01, n_époques = 2000:
perte = 0,39 ...
Précision: 0,75
lr = 0,01, n_époques = 3000:
perte = 0,367 ...
Précision: 0,76
lr = 0,01, n_époques = 4000:
perte = 0,355 ...
Précision: 0,72
lr = 0,01, n_époques = 10000:
perte = 0,285 ...
Précision: 0,69
Ici, vous pouvez voir qu'à 4k + époques - le modèle est déjà surajusté. Essayons maintenant d'éviter cela:
Pour ce faire, ajoutez le paramètre weight_decay pour notre méthode d'optimisation:
optimizer = optim.Adagrad(model.parameters(), lr=lr, weight_decay = 0.001)
Avec lr = 0,01, m_epochs = 10000:
perte = 0,367 ...
Précision: 0,73
À 4000 époques:
perte = 0,389 ...
Précision: 0,75
Cela s'est avéré beaucoup mieux, mais nous n'avons ajouté qu'un seul paramètre dans l'optimiseur :)
Considérons maintenant SGDm (il s'agit d'une descente de gradient stochastique avec une petite extension - heuristique, si vous le souhaitez).
L'essentiel est que
SGD met à jour les paramètres assez fortement après chaque itération. Il serait logique de «lisser» le gradient en utilisant des gradients des itérations passées (l'idée d'inertie):
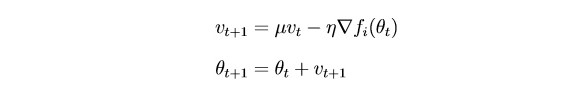
θ - paramètre (poids)
µ - hyperparamètre à inertie
SGD sans paramètre de momentum:
SGD avec paramètre de momentum:
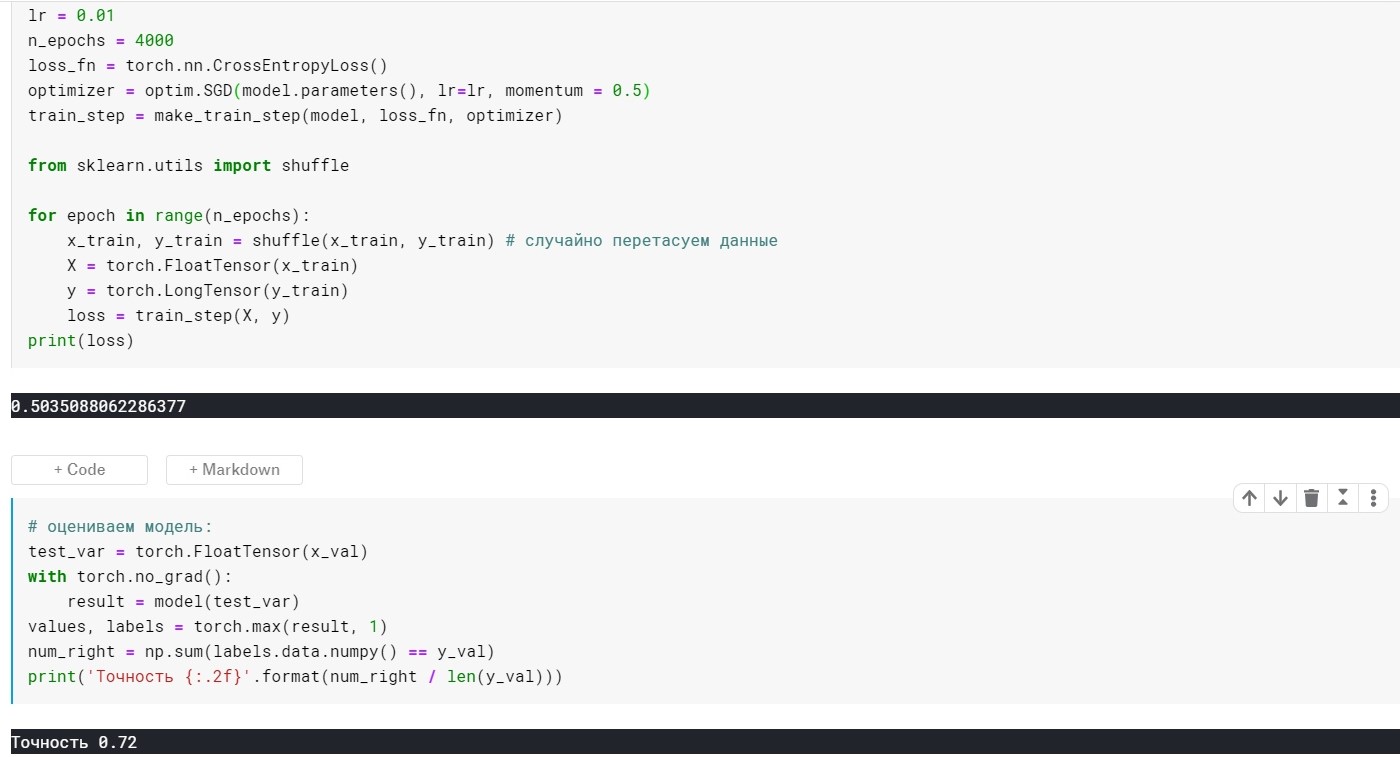
Il ne s'est pas avéré beaucoup mieux, mais le point ici est qu'il existe des méthodes qui utilisent immédiatement les idées de mise à l'échelle et d'inertie. Par exemple, Adam ou Adadelta, qui affichent désormais de bons résultats. Eh bien, pour comprendre ces méthodes, je pense qu'il est nécessaire de comprendre certaines idées de base utilisées dans des méthodes plus simples.
Merci à tous pour votre attention!