En 2015, j'ai écrit sur les outils fournis par Ruby pour
détecter les fuites de mémoire gérée . La plupart du temps, l'article parlait de fuites faciles à gérer. Cette fois, je vais parler des outils et astuces que vous pouvez utiliser pour éliminer les fuites qui ne sont pas si faciles à analyser dans Ruby. En particulier, je vais parler de mwrap, heaptrack, iseq_collector et chap.
Fuites de mémoire non gérées
Ce petit programme provoque une fuite avec un appel direct à malloc. Il commence avec une consommation de 16 Mo de flux RSS et se termine avec 118 Mo. Le code place en mémoire 100 000 blocs de 1024 octets et en supprime 50 000.
require 'fiddle' require 'objspace' def usage rss = `ps -p
Bien que RSS fasse 118 Mo, notre objet Ruby ne connaît que trois mégaoctets. Dans l'analyse, nous ne voyons qu'une très petite partie de cette très grande fuite de mémoire.
Un véritable exemple d'une telle fuite est
décrit par Oleg Dashevsky , je vous recommande de lire ce merveilleux article.
Appliquer Mwrap
Mwrap est un profileur de mémoire pour Ruby qui surveille toutes les allocations de données en mémoire en interceptant malloc et d'autres fonctions de cette famille. Il intercepte les appels qui passent et libèrent de la mémoire à l'aide de
LD_PRELOAD . Il utilise
liburcu pour le comptage et peut suivre les compteurs d'allocation et de suppression pour chaque point d'appel, en code C et Ruby. Mwrap est de petite taille, environ deux fois plus grand que RSS pour un programme profilé, et environ deux fois plus lent.
Il diffère de nombreuses autres bibliothèques par sa très petite taille et son support Ruby. Il suit les emplacements dans les fichiers Ruby et n'est pas limité aux backtracks de niveau C valgrind + masif et aux profileurs similaires. Cela simplifie considérablement l'isolement des sources de problèmes.
Pour utiliser le profileur, vous devez exécuter l'application via le shell Mwrap, il implémentera l'environnement LD_PRELOAD et exécutera le binaire Ruby.
Ajoutons Mwrap à notre script:
require 'mwrap' def report_leaks results = [] Mwrap.each do |location, total, allocations, frees, age_total, max_lifespan| results << [location, ((total / allocations.to_f) * (allocations - frees)), allocations, frees] end results.sort! do |(_, growth_a), (_, growth_b)| growth_b <=> growth_a end results[0..20].each do |location, growth, allocations, frees| next if growth == 0 puts "#{location} growth: #{growth.to_i} allocs/frees (#{allocations}/#{frees})" end end GC.start Mwrap.clear leak_memory GC.start
Maintenant, exécutez le script avec le wrapper Mwrap:
% gem install mwrap % mwrap ruby leak.rb leak.rb:12 growth: 51200000 allocs/frees (100000/50000) leak.rb:51 growth: 4008 allocs/frees (1/0)
Mwrap a correctement détecté une fuite dans le script (50 000 * 1024). Et non seulement déterminé, mais aussi isolé une ligne spécifique (
i = Fiddle.malloc(1024) ), ce qui a conduit à une fuite. Le profileur l'a correctement lié aux appels à
Fiddle.free .
Il est important de noter que nous avons affaire à une évaluation. Mwrap surveille la mémoire partagée allouée par l'homologue de numérotation, puis surveille la libération de mémoire. Mais si vous avez un point d'appel qui alloue des blocs de mémoire de différentes tailles, le résultat sera inexact. Nous avons accès à l'évaluation:
((total / allocations) * (allocations - frees))De plus, pour simplifier le suivi des fuites, Mwrap suit
age_total , qui est la somme de la durée de vie de chaque objet libéré, et suit également
max_lifespan , la durée de vie de l'objet le plus ancien au point d'appel. Si
age_total / frees important, la consommation de mémoire augmente malgré de nombreuses collectes de place.
Mwrap a plusieurs aides pour réduire le bruit.
Mwrap.clear tout le stockage interne.
Mwrap.quiet {} forcera Mwrap à suivre le bloc de code.
Une autre caractéristique distinctive de Mwrap est le suivi du nombre total d'octets alloués et libérés. Supprimez
clear du script et exécutez-le:
usage puts "Tracked size: #{(Mwrap.total_bytes_allocated - Mwrap.total_bytes_freed) / 1024}"
Le résultat est très intéressant, car malgré la taille RSS de 130 Mo, Mwrap ne voit que 91 Mo. Cela suggère que nous avons gonflé notre processus. L'exécution sans Mwrap montre que dans une situation normale, le processus prend 118 Mo, et dans ce cas simple, la différence était de 12 Mo. Le modèle d'allocation / libération a conduit à la fragmentation. Cette connaissance peut être très utile, dans certains cas, les processus glocc malloc non configurés se fragmentent tellement que la très grande quantité de mémoire utilisée dans RSS est en fait libre.
Mwrap peut-il isoler une ancienne fuite de tapis rouge?
Dans
son article, Oleg discute d'une manière très approfondie d'isoler une fuite très mince dans le tapis rouge. Il y a beaucoup de détails. Il est très important de prendre des mesures. Si vous ne créez pas de chronologie pour le processus RSS, il est peu probable que vous puissiez vous débarrasser de toute fuite.
Entrons dans une machine à remonter le temps et montrons à quel point il est plus facile d'utiliser Mwrap pour de telles fuites.
def red_carpet_leak 100_000.times do markdown = Redcarpet::Markdown.new(Redcarpet::Render::HTML, extensions = {}) markdown.render("hi") end end GC.start Mwrap.clear red_carpet_leak GC.start
Redcarpet 3.3.2:
redcarpet.rb:51 growth: 22724224 allocs/frees (500048/400028) redcarpet.rb:62 growth: 4008 allocs/frees (1/0) redcarpet.rb:52 growth: 634 allocs/frees (600007/600000)
Redcarpet 3.5.0:
redcarpet.rb:51 growth: 4433 allocs/frees (600045/600022) redcarpet.rb:52 growth: 453 allocs/frees (600005/600000)
Si vous pouvez vous permettre d'exécuter le processus à la moitié de la vitesse en le redémarrant simplement dans la prod Mwrap avec la journalisation du résultat dans un fichier, vous pouvez identifier un large éventail de fuites de mémoire.
Fuite mystérieuse
Récemment, Rails a été mis à jour vers la version 6. En général, l'expérience a été très positive, les performances sont restées à peu près les mêmes. Rails 6 a de très bonnes fonctionnalités que nous utiliserons (par exemple
Zeitwerk ). Rails a changé la façon dont les modèles ont été rendus, ce qui a nécessité quelques modifications pour la compatibilité. Quelques jours après la mise à jour, nous avons remarqué une augmentation du flux RSS pour la tâche Sidekiq.
Mwrap a signalé une forte augmentation de la consommation de mémoire en raison de son allocation (
lien ):
source.encode!
Au début, nous étions très perplexes. Nous essayions de comprendre pourquoi mécontent de Mwrap? Peut-être qu'il s'est cassé? Alors que la consommation de mémoire augmentait, les tas de rubis sont restés inchangés.
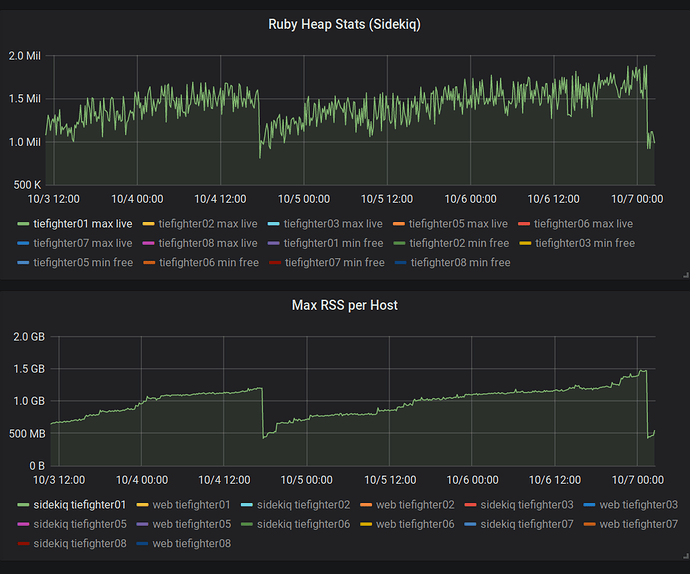
Deux millions d'emplacements dans le tas ne consommaient que 78 Mo (40 octets par emplacement). Les lignes et les tableaux peuvent prendre plus de place, mais cela n'explique toujours pas la consommation de mémoire anormale que nous avons observée. Cela a été confirmé lorsque j'ai
rbtrace -p SIDEKIQ_PID -e ObjectSpace.memsize_of_all .
Où est passé le souvenir?
Heaptrack
Heaptrack est un profileur de mémoire de tas pour Linux.
Milian Wolff a parfaitement
expliqué le fonctionnement du profileur et en a parlé dans plusieurs discours (
1 ,
2 ,
3 ). En fait, il s'agit d'un profileur de tas natif très efficace qui, avec l'aide de
libunwind, recueille les
traces des applications profilées. Il fonctionne nettement plus rapidement que
Valgrind / Massif et a la capacité de le rendre beaucoup plus pratique pour le profilage temporaire dans la prod. Il peut être attaché à un processus déjà en cours!
Comme avec la plupart des profileurs de tas, lors de l'appel de toutes les fonctions de la famille malloc, Heaptrack doit compter. Cette procédure ralentit définitivement un peu le processus.
À mon avis, l'architecture ici est la meilleure de toutes. L'interception est effectuée à l'aide de
LD_PRELOAD ou
GDB pour charger le profileur. À l'aide d'un
fichier FIFO spécial, il transfère les données du processus profilé le plus rapidement possible. Le wrapper
heaptrack est un simple script shell qui facilite la recherche d'un problème. Le deuxième processus lit les informations du FIFO et compresse à la volée les données de suivi. Étant donné que Heaptrack fonctionne avec des «morceaux», vous pouvez analyser le profil en quelques secondes après le début du profilage, en plein milieu de la session. Copiez simplement le fichier de profil vers un autre emplacement et lancez l'interface graphique Heaptrack.
Ce
ticket GitLab m'a parlé de la possibilité même de lancer Heaptrack. S'ils pouvaient l'exécuter, alors je le peux.
Notre application s'exécute dans un conteneur, et je dois le redémarrer avec
--cap-add=SYS_PTRACE , cela permet à GDB d'utiliser
ptrace , qui est nécessaire pour que Heaptrack s'injecte lui-même. J'ai également besoin d'un
petit hack pour que le fichier shell applique
root au profil du processus non
root (nous avons lancé notre application Discourse dans le conteneur sous un compte limité).
Une fois que tout a été fait, il ne reste plus qu'à exécuter
heaptrack -p PID et attendre que les résultats apparaissent. Heaptrack s'est avéré être un excellent outil, il était très facile de suivre tout ce qui se passe avec des fuites de mémoire.
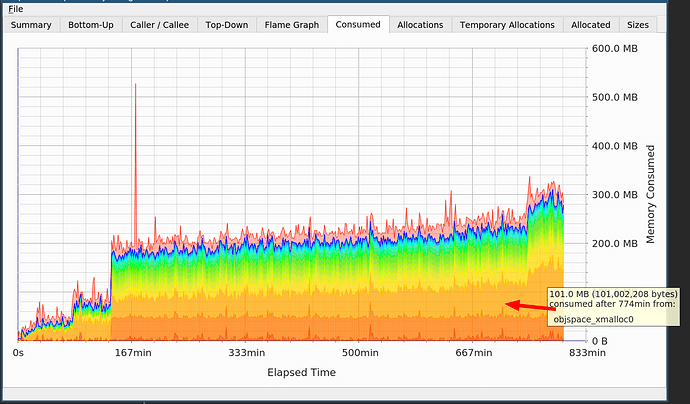
Sur le graphique, vous voyez deux sauts, l'un dû à
cppjieba , l'autre à
objspace_xmalloc0 dans Ruby.
Je connaissais
cppjieba . La segmentation de la langue chinoise coûte cher, vous avez besoin de gros dictionnaires, donc ce n'est pas une fuite. Mais qu'en est-il de l'allocation de mémoire dans Ruby, qui ne me dit toujours pas cela?
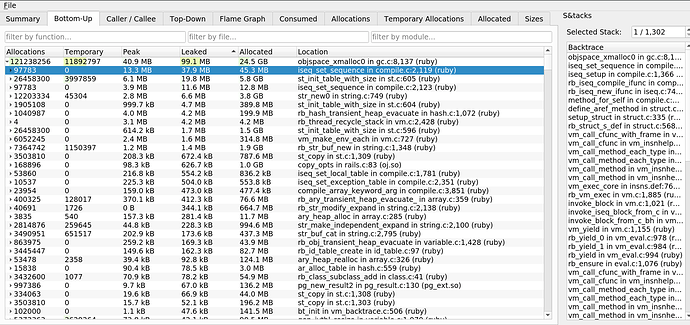
Le gain principal est lié à
iseq_set_sequence dans
compile.c . Il s'avère que la fuite est due à des séquences d'instructions. Cela a effacé la fuite découverte par Mwrap. Sa cause était
mod.module_eval(source, identifier, 0) , qui a créé des séquences d'instructions qui n'ont pas été supprimées de la mémoire.
Si, dans une analyse rétrospective, j'avais soigneusement considéré un vidage de tas de Ruby, alors j'aurais remarqué tous ces IMEMO, car ils sont inclus dans ce vidage. Ils sont simplement invisibles lors des diagnostics en cours.
À partir de ce moment, le débogage était assez simple. J'ai suivi tous les appels vers le module eval et jeté ce qu'il a évalué. J'ai constaté que nous ajoutons encore et encore des méthodes à une grande classe. Voici une vue simplifiée du bug rencontré:
require 'securerandom' module BigModule; end def leak_methods 10_000.times do method = "def _#{SecureRandom.hex}; #{"sleep;" * 100}; end" BigModule.module_eval(method) end end usage # RSS: 16164 ObjectSpace size 2869 leak_methods usage
Ruby a une classe pour stocker les séquences d'instructions
RubyVM::InstructionSequence :
RubyVM::InstructionSequence . Cependant, Ruby est trop paresseux pour créer ces objets wrapper, car les stocker inutilement est inefficace. Koichi
Sasada a créé la dépendance
iseq_collector . Si nous ajoutons ce code, nous pouvons trouver notre mémoire cachée:
require 'iseq_collector' puts "#{ObjectSpace.memsize_of_all_iseq / 1024}"
matérialise chaque séquence d'instructions, ce qui peut augmenter légèrement la consommation de mémoire du processus et donner au garbage collector un peu plus de travail.
Si, par exemple, nous calculons le nombre d'ISEQ avant et après le démarrage du collecteur, nous verrons qu'après le démarrage d'
ObjectSpace.memsize_of_all_iseq notre compteur de la classe
RubyVM::InstructionSequence de 0 à 11128 (dans cet exemple):
def count_iseqs ObjectSpace.each_object(RubyVM::InstructionSequence).count end
Ces emballages resteront pendant toute la durée de vie de la méthode, ils devront être visités avec une exécution complète du ramasse-miettes. Notre problème a été résolu en réutilisant la classe responsable du rendu des modèles de courrier électronique (
correctif 1 ,
correctif 2 ).
chap
Lors du débogage, j'ai utilisé un outil très intéressant. Il y a quelques années, Tim Boddy a sorti un outil interne utilisé par VMWare pour analyser les fuites de mémoire et a ouvert son code. Voici la seule vidéo à ce sujet que j'ai réussi à trouver:
https://www.youtube.com/watch?v=EZ2n3kGtVDk . Contrairement à la plupart des outils similaires, celui-ci n'a aucun effet sur le processus exécutable. Il peut simplement être appliqué aux fichiers du vidage principal, tandis que glibc est utilisé comme un allocateur (il n'y a pas de support pour jemalloc / tcmalloc, etc.).
Avec chap, il est très facile de détecter la fuite que j'avais. Peu de distributions ont un binaire chap, mais vous pouvez facilement le
compiler à partir du code source . Il est très activement soutenu.
# 444098 is the `Process.pid` of the leaking process I had sudo gcore -p 444098 chap core.444098 chap> summarize leaked Unsigned allocations have 49974 instances taking 0x312f1b0(51,573,168) bytes. Unsigned allocations of size 0x408 have 49974 instances taking 0x312f1b0(51,573,168) bytes. 49974 allocations use 0x312f1b0 (51,573,168) bytes. chap> list leaked ... Used allocation at 562ca267cdb0 of size 408 Used allocation at 562ca267d1c0 of size 408 Used allocation at 562ca267d5d0 of size 408 ... chap> summarize anchored .... Signature 7fbe5caa0500 has 1 instances taking 0xc8(200) bytes. 23916 allocations use 0x2ad7500 (44,922,112) bytes.
Chap peut utiliser des signatures pour rechercher des emplacements de mémoire différente, et il peut compléter GDB. Lors du débogage dans Ruby, il peut être très utile pour déterminer la mémoire utilisée par le processus. Il montre la mémoire totale utilisée, parfois la glibc malloc peut se fragmenter tellement que le volume utilisé peut être très différent du RSS réel. Vous pouvez lire la discussion:
Feature # 14759: [PATCH] set M_ARENA_MAX for glibc malloc - Ruby master - Ruby Issue Tracking System . Chap est capable de compter correctement toute la mémoire utilisée et de fournir une analyse approfondie de son allocation.
De plus, chap peut être intégré dans les workflows pour détecter automatiquement les fuites et signaler de tels assemblages.
Travaux de suivi
Ce tour de débogage m'a fait poser quelques questions liées à nos boîtes à outils d'aide:
Résumé
Notre boîte à outils d'aujourd'hui pour le débogage de fuites de mémoire très complexes est bien meilleure qu'elle ne l'était il y a 4 ans! Mwrap, Heaptrack et chap sont des outils très puissants pour résoudre les problèmes de mémoire qui surviennent pendant le développement et l'exploitation.
Si vous recherchez une simple fuite de mémoire dans Ruby, je vous recommande de lire
mon article de 2015 , pour la plupart, il est pertinent.
J'espère que vous trouverez cela plus facile la prochaine fois que vous commencerez à déboguer une fuite de mémoire native complexe.