
Salut Je m'appelle Askhat Nuryev, je suis l'un des principaux ingénieurs en automatisation de DINS.
Je travaille chez Dino Systems depuis 7 ans. Pendant ce temps, j'ai dû faire face à différentes tâches: de l'écriture de tests fonctionnels automatisés aux tests de performances et de haute disponibilité. Petit à petit, je suis devenu plus impliqué dans l'organisation des tests et l'optimisation des processus en général.
Dans cet article, je dirai:
- Que se passe-t-il si des bogues ont déjà fui en production?
- Comment rivaliser pour la qualité du système, si vous ne pouvez pas compter les erreurs avec vos mains et ne révisez pas vos yeux?
- Quels sont les pièges de la gestion automatique des erreurs?
- Quels bonus puis-je obtenir en analysant les statistiques des requêtes?
DINS est le centre de développement de RingCentral, un leader du marché parmi les fournisseurs de cloud pour les communications unifiées. Ringentral fournit tout pour les communications d'entreprise de la téléphonie classique, SMS, réunions aux fonctionnalités des centres de contact et des produits pour un travail d'équipe complexe (à la Slack). Cette solution cloud est située dans ses propres centres de données, et le client n'a besoin que de s'abonner au site.
Le système, au développement duquel nous participons, dessert 2 millions d'utilisateurs actifs et traite plus de 275 millions de demandes par jour. L'équipe sur laquelle je travaille développe l'API.
Le système possède une API assez compliquée. Avec lui, vous pouvez envoyer des SMS, passer des appels, collecter des vidéoconférences, configurer des comptes et même envoyer des fax (bonjour, 2019). Sous une forme simplifiée, le schéma d'interaction des services ressemble à ceci. Je ne plaisante pas.

Il est clair qu'un système aussi complexe et très chargé crée un grand nombre d'erreurs. Par exemple, il y a un an, nous recevions des dizaines de milliers d'erreurs par semaine. Ce sont des millièmes de pour cent par rapport au nombre total de demandes, mais toujours autant d'erreurs sont un gâchis. Nous les avons rattrapés grâce au service de support développé, cependant, ces erreurs affectent les utilisateurs. De plus, le système évolue constamment, le nombre de clients augmente. Et le nombre d'erreurs aussi.
Tout d'abord, nous avons essayé de résoudre le problème de manière classique.
Nous avons rassemblé, demandé des journaux de production, corrigé quelque chose, oublié quelque chose, créé des tableaux de bord dans Kibana et Sumologic. Mais dans l'ensemble, cela n'a pas aidé. Les bugs ont quand même fui, se sont plaints les utilisateurs. Il est devenu clair que quelque chose n'allait pas.
Automatisation
Bien sûr, nous avons commencé à comprendre et à constater que 90% du temps consacré à la correction de l'erreur est consacré à la collecte d'informations à ce sujet. Voici quoi exactement:
- Obtenez les informations manquantes des autres services.
- Examinez les journaux du serveur.
- Enquêter sur le comportement de notre système.
- Comprenez si tel ou tel comportement du système est erroné.
Et seuls les 10% restants ont été dépensés directement pour le développement.
Nous avons pensé - mais que se passe-t-il si nous créons un système qui trouve lui-même des erreurs, leur donne une priorité et affiche toutes les données nécessaires pour y remédier?
Je dois dire que l'idée même d'un tel service a suscité quelques inquiétudes.
Quelqu'un a dit: "Si nous trouvons nous-mêmes tous les bogues, alors pourquoi avons-nous besoin de l'assurance qualité?"
D'autres ont dit le contraire: "Vous allez vous noyer dans ce tas de punaises!".
En un mot, cela valait la peine de rendre un service, ne serait-ce que pour comprendre lequel d'entre eux a raison.
spoiler(les deux groupes de sceptiques se sont trompés)
Solutions prêtes à l'emploi
Tout d'abord, nous avons décidé de voir lesquels des systèmes similaires sont déjà sur le marché. Il s'est avéré qu'il y en avait beaucoup. Vous pouvez mettre en évidence Raygun, Sentry, Airbrake, il existe d'autres services.
Mais aucun d'eux ne nous convenait, et voici pourquoi:
- Certains services nous ont obligés à apporter des modifications trop importantes à l'infrastructure existante, y compris des modifications sur le serveur. Airbrake.io devrait affiner des dizaines, des centaines de composants du système.
- D'autres ont collecté des données sur nos propres erreurs et les ont envoyées quelque part sur le côté. Notre politique de sécurité ne le permet pas - les données des utilisateurs et des erreurs doivent rester avec nous.
- Eh bien, ils sont également assez chers.
Nous faisons notre
Il est devenu évident que nous devions rendre notre service, d'autant plus que nous avions déjà construit une très bonne infrastructure pour cela:
- Tous les services ont déjà écrit des journaux dans un référentiel unique - Elastic. Dans les journaux, des identifiants uniformes des demandes de tous les services ont été jetés.
- Des statistiques de performances ont également été enregistrées dans Hadoop. Nous avons travaillé avec des journaux en utilisant Impala et Metabase.
De toutes les erreurs de serveur (
selon la classification des codes d'état HTTP ), le code 500 est le plus prometteur en termes d'analyse d'erreurs. En réponse aux erreurs 502, 503 et 504, dans certains cas, vous pouvez simplement répéter la demande après un certain temps sans même montrer la réponse à l'utilisateur. Et selon les recommandations de l'API RC Platform, les utilisateurs doivent contacter le support s'ils reçoivent le code d'état 500 en réponse à un appel.
La première version du système a collecté les journaux d'exécution des requêtes, toutes les traces de pile qui se sont produites, les données utilisateur et ont placé le bogue dans le tracker, dans notre cas c'était JIRA.
Juste après le test, nous avons remarqué que le système crée un nombre important d'erreurs en double. Cependant, parmi ces doublons, beaucoup avaient presque les mêmes traces de pile.
Il a fallu changer la méthode d'identification des mêmes erreurs. De l'analyse de données purement statistiques, passez à la recherche de la cause première de l'erreur. Les traces de pile caractérisent bien le problème, mais elles sont assez difficiles à comparer les unes aux autres - les numéros de ligne changent d'une version à l'autre, les données utilisateur et d'autres parasites y pénètrent. De plus, ils n'entrent pas toujours dans le journal - pour certaines demandes abandonnées, ils n'existent tout simplement pas.
Dans sa forme la plus pure, les traces de pile sont peu pratiques à utiliser pour le suivi des erreurs.
Il était nécessaire de sélectionner des modèles, des modèles de traces de pile et de les effacer des informations qui changeaient souvent. Après une série d'expériences, nous avons décidé d'utiliser des expressions régulières pour effacer les données.
En conséquence, nous avons publié une nouvelle version, dans laquelle les erreurs ont été identifiées par ces modèles uniques, si des traces de pile étaient disponibles. Et s'ils n'étaient pas disponibles, alors à l'ancienne, par la méthode http et le groupe d'API.
Et après cela, il n'y avait pratiquement plus de doublons. Cependant, de nombreuses erreurs uniques ont été trouvées.
L'étape suivante consiste à comprendre comment hiérarchiser les erreurs, lesquelles doivent être corrigées plus tôt. Nous avons priorisé par:
- La fréquence de l'erreur.
- Le nombre d'utilisateurs qu'elle est concernée.
Sur la base des statistiques collectées, nous avons commencé à publier des rapports hebdomadaires. Ils ressemblent à ceci:
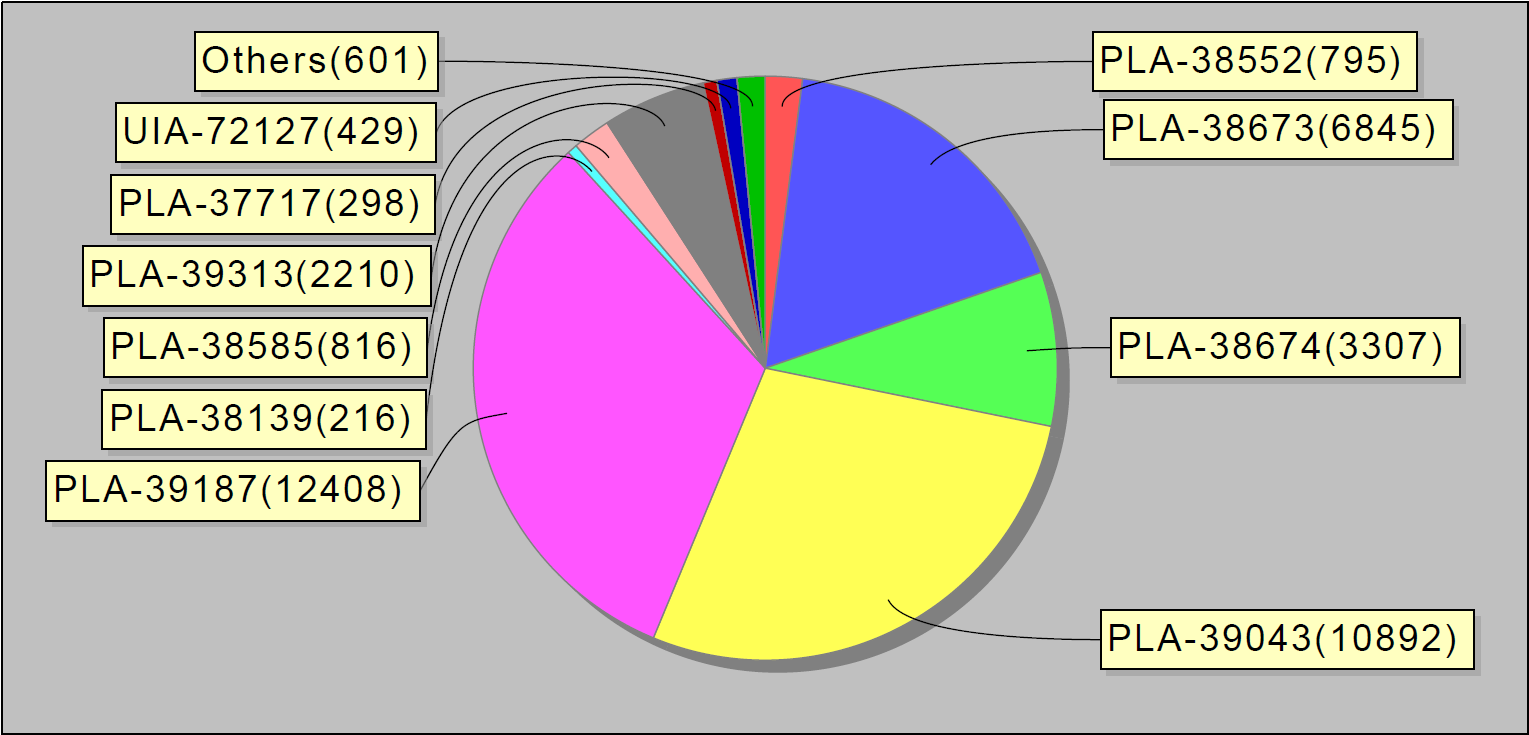
Ou, par exemple, les 10 principales erreurs par semaine. Fait intéressant, ces 10 bogues dans jira ont représenté 90% des erreurs de service:
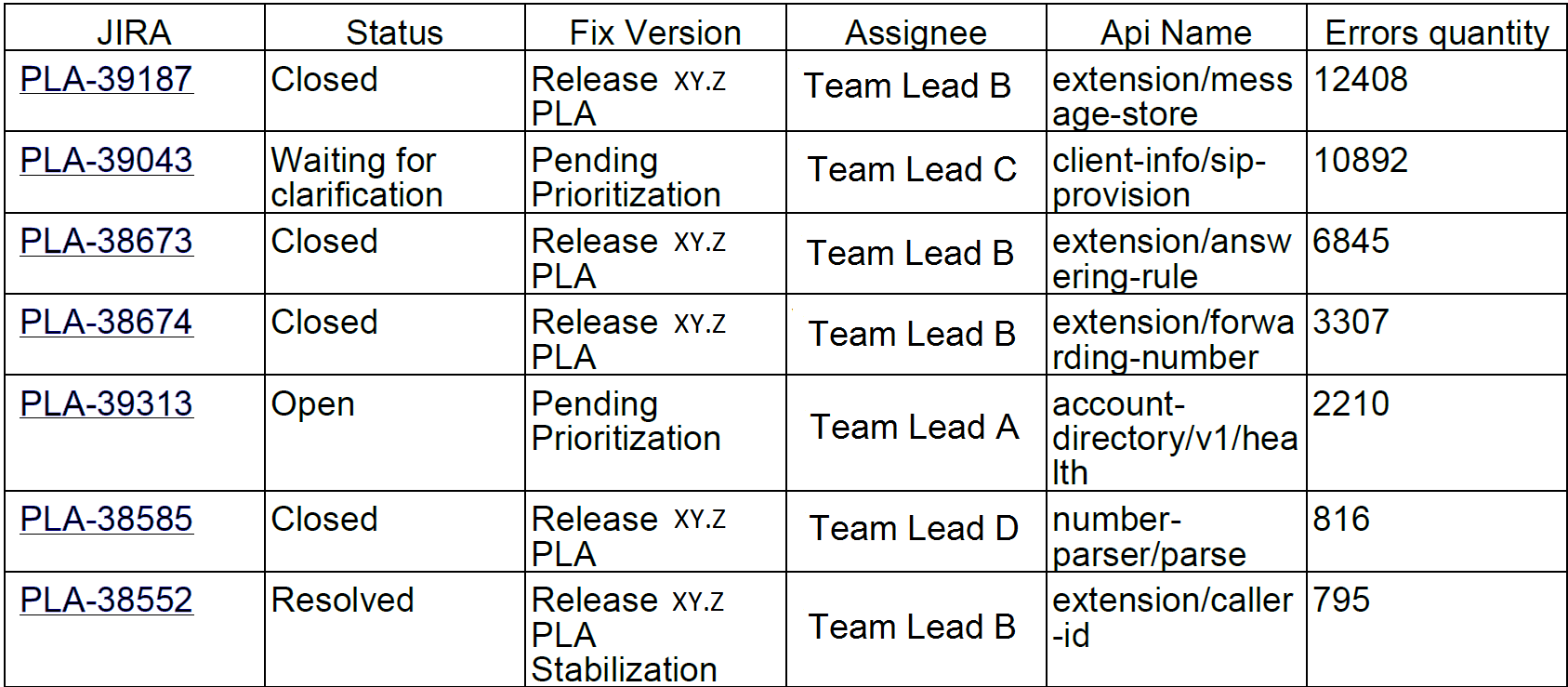
Nous avons envoyé ces rapports aux développeurs et aux chefs d'équipe.
Quelques mois après le lancement du système, le nombre de problèmes est devenu nettement moins important. Même notre petit MVP (produit minimalement viable) a aidé à mieux trier les erreurs.
Le problème
Peut-être que nous nous arrêterions ici, sinon pour un accident.
Une fois que je suis arrivé au travail, j'ai remarqué que le système rivetait les bogues comme des petits pains: un par un. Après une courte enquête, il est devenu clair que des dizaines de ces erreurs provenaient d'un seul service. Pour savoir quel est le problème, je suis allé dans la salle de discussion de l'équipe de déploiement. Il y avait des gars qui étaient impliqués dans l'installation de nouvelles versions de services en production et s'assuraient qu'ils fonctionnaient comme prévu.
J'ai demandé: "Les gars, que s'est-il passé avec ce service?".
Et ils répondent: "Il y a une heure, nous y avons installé une nouvelle version."
Étape par étape, nous avons identifié le problème et trouvé une solution temporaire, en d'autres termes, redémarré le serveur.
Il est devenu clair que le système "erroné" est nécessaire non seulement aux développeurs et ingénieurs responsables de la qualité. Les ingénieurs qui sont responsables de l'état des serveurs en production, ainsi que les gars qui installent de nouvelles versions sur les serveurs, s'y intéressent également. Le service que nous développons montrera exactement quelles erreurs se produisent dans la production lors des modifications du système, telles que l'installation de serveurs, l'application d'une nouvelle configuration, etc.
Et nous avons décidé de faire une autre itération de développement.
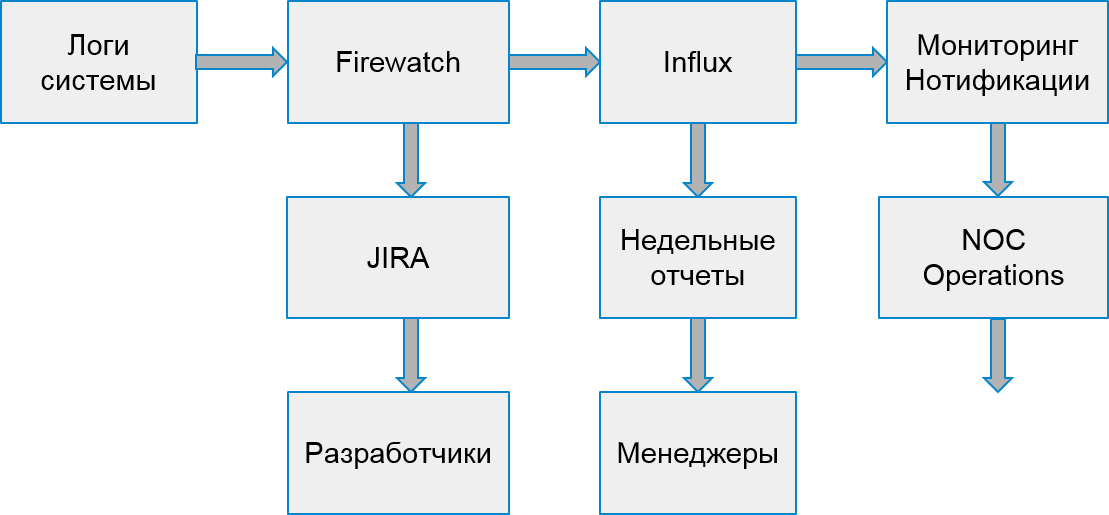
Dans le processus de gestion des erreurs, nous avons ajouté un enregistrement des statistiques de lecture des problèmes à la base de données et aux tableaux de bord dans Grafana. Voici à quoi ressemble la distribution graphique des erreurs par jour dans tout le système:

Et donc - des erreurs dans les services individuels.

Nous avons également vissé les déclencheurs avec escalades aux équipes d'ingénierie responsables - au cas où il y aurait beaucoup d'erreurs. Nous avons également mis en place une collecte de données toutes les 30 minutes (au lieu d'une fois par jour, comme auparavant).
Le processus de notre système a commencé à ressembler à ceci:
Erreurs client
Cependant, les utilisateurs n'ont pas seulement souffert d'erreurs de serveur. Il est également arrivé que l'erreur se soit produite en raison de la mise en œuvre des applications clientes.
Pour gérer les erreurs des clients, nous avons décidé de construire un autre processus de recherche et d'analyse. Pour ce faire, nous avons choisi 2 types d'erreurs qui affectent les entreprises: les erreurs d'autorisation et les erreurs de limitation.
La limitation est un moyen de protéger le système contre les surcharges. Si l'application ou l'utilisateur dépasse leur quota de demandes, le système renvoie un code d'erreur 429 et un en-tête Retry-After, la valeur de l'en-tête indique le délai après lequel la demande doit être répétée pour une exécution réussie.
Les applications peuvent rester limitées indéfiniment si elles cessent d'envoyer de nouvelles demandes. Les utilisateurs finaux ne peuvent pas distinguer ces erreurs des autres. En conséquence, cela provoque des plaintes auprès du service d'assistance.
Heureusement, l'infrastructure et le système de statistiques permettent de suivre même les erreurs des clients. Nous pouvons le faire car les développeurs d'applications qui utilisent notre API doivent se pré-enregistrer et recevoir leur clé unique. Chaque demande du client doit contenir un jeton d'autorisation, sinon le client recevra une erreur. À l'aide de ce jeton, nous calculons l'application.
Voici à quoi ressemble la surveillance des erreurs de limitation. Les pics d'erreurs correspondent aux jours de la semaine et le week-end - au contraire, il n'y a pas d'erreurs:

De la même manière que dans le cas d'erreurs internes, sur la base des statistiques de Hadoop, nous avons trouvé des applications suspectes. Premièrement, par rapport au nombre de demandes réussies par rapport au nombre de demandes qui se sont terminées avec le code 429. Si nous avons reçu plus de la moitié de ces demandes, nous pensions que l'application ne fonctionnait pas correctement.
Plus tard, nous avons commencé à analyser le comportement des applications individuelles avec des utilisateurs spécifiques. Parmi les applications suspectes, nous avons trouvé le périphérique spécifique sur lequel l'application s'exécute et regardé la fréquence à laquelle elle exécute les demandes après avoir reçu la première erreur de limitation. Si la fréquence des demandes n'a pas diminué, l'application n'a pas traité l'erreur comme prévu.
Une partie des applications a été développée dans notre entreprise. Par conséquent, nous avons pu trouver immédiatement des ingénieurs responsables et corriger rapidement les erreurs. Et nous avons décidé d'envoyer les erreurs restantes à une équipe qui a contacté des développeurs externes et les a aidés à corriger leur application.
Pour chacune de ces applications, nous:
- Nous créons une tâche dans JIRA.
- Nous enregistrons des statistiques dans Influx.
- Nous préparons des déclencheurs d'intervention chirurgicale en cas de forte augmentation du nombre d'erreurs.
Le système de gestion des erreurs client ressemble à ceci:
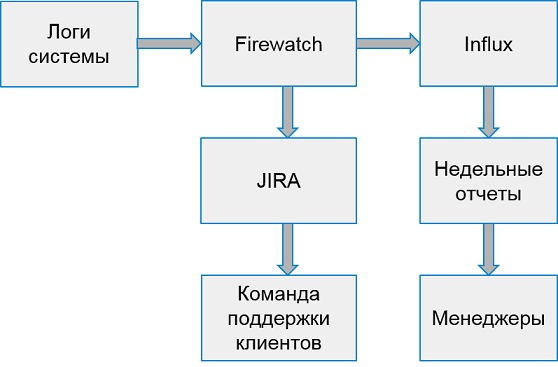
Une fois par semaine, nous collectons des rapports sur les 10 pires applications en fonction du nombre d'erreurs.
Ne pas attraper, mais avertir
Ainsi, nous avons appris à trouver des erreurs dans le système de production, appris à travailler avec les erreurs de serveur et les erreurs de client. Tout semble aller bien, mais ...
Mais en fait, nous répondons trop tard - les bogues affectent déjà les utilisateurs!
Pourquoi ne pas essayer de trouver des erreurs plus tôt?
Bien sûr, il serait cool de tout trouver dans des environnements de test. Mais les environnements de test sont des espaces de bruit blanc. Ils sont en développement actif, chaque jour plusieurs versions de serveurs fonctionnent. Il est trop tôt pour détecter les erreurs de manière centralisée. Il y a trop d'erreurs, trop souvent tout change.
Cependant, la société dispose d'environnements spéciaux dans lesquels tous les assemblages stables sont intégrés pour vérifier les performances, la régression manuelle centralisée et les tests de haute disponibilité. En règle générale, ces environnements ne sont pas encore suffisamment stables. Cependant, certaines équipes sont intéressées à analyser les problèmes avec ces environnements.
Mais il y a un obstacle de plus - Hadoop ne collecte pas de données de ces environnements! Nous ne pouvons pas utiliser la même méthode pour détecter les erreurs; nous devons rechercher une source de données différente.
Après une courte recherche, nous avons décidé de traiter le streaming des statistiques, en lisant les données de la file d'attente dans laquelle nos services écrivent pour le transfert vers Hadoop. Il suffisait d'accumuler des erreurs uniques et de les traiter par lots, par exemple une fois toutes les 30 minutes. Il est facile de mettre en place un système de mise en file d'attente qui délivre des données - il ne restait plus qu'à affiner la réception et le traitement.
Nous avons commencé à observer le comportement des erreurs trouvées après détection. Il s'est avéré que la plupart des erreurs trouvées et non corrigées apparaissent plus tard en production. Donc, nous les trouvons correctement.
Ainsi, nous avons construit un prototype du système, des institutions et des erreurs de suivi. Déjà sous sa forme actuelle, il vous permet d'améliorer la qualité du système, de constater et de corriger les erreurs avant que les utilisateurs ne les connaissent. Si, auparavant, nous traitions des dizaines de milliers de demandes erronées par semaine, ce nombre n'est plus que de 2 à 3 000. Et nous les corrigeons beaucoup plus rapidement.
Et ensuite
Bien sûr, nous ne nous arrêterons pas là et continuerons d'améliorer le système de recherche et de suivi des erreurs. Nous avons des plans:
- Analyse de plus d'erreurs API.
- Intégration avec des tests fonctionnels.
- Fonctionnalités supplémentaires pour enquêter sur les incidents dans notre système.
Mais plus à ce sujet la prochaine fois.