Bonjour à tous!
Je m'appelle Denisov Alexander. Je travaille pour Naumen et suis responsable de la documentation et de la localisation du logiciel Naumen Contact Center (NCC).
Dans cet article, je parlerai des problèmes que nous avons rencontrés lors de la localisation de NCC en anglais et en allemand et comment nous avons résolu ces problèmes. Bien sûr, aujourd'hui, nous avons résolu loin de toutes nos tâches, et très probablement ce processus est généralement sans fin. L'article examine la vision de l'ensemble du processus dans son ensemble et les principes auxquels nous essayons d'adhérer ou que nous commençons à appliquer. Le matériel sera utile à ceux qui commencent tout juste à concevoir un logiciel, prévoient de le localiser ou sont déjà confrontés à des problèmes, mais ne savent pas encore comment les résoudre.

Présentation
Souvent, une entreprise pense à la localisation de logiciels lorsque le produit est prêt et que la documentation a été rédigée pour cela. Et il est également souvent trop tard pour faire quelque chose afin d'obtenir une bonne localisation en peu de temps et de ne pas y consacrer une énorme quantité de ressources.
Il est impossible d'écrire en détail tous les problèmes et difficultés dans un seul article, je vais donc parler un peu des principales étapes de la documentation et de la localisation et aborder plusieurs, à mon avis, les questions les plus importantes:
- Quelles étapes du cycle de vie du développement logiciel affectent la qualité de la documentation et de la localisation?
- Quoi et quand faire à chaque étape?
- Quelles approches, capacités d'outils peuvent être utilisées pour résoudre les problèmes et les problèmes de chaque étape?
- Comme une organisation. La structure affecte-t-elle la documentation et la localisation?
- Comment organiser la réception des retours des utilisateurs de la documentation?
- Comment économiser du temps et des coûts financiers à chaque étape?
Sur la base de mes nombreuses années d'expérience dans la documentation et la localisation de CNC, je vais essayer de répondre à ces questions.
Caractéristiques de NCC et processus de développement
Naumen Contact Center est un logiciel sophistiqué pour l'organisation de grands centres de contact d'entreprise ou d'externalisation.
Quelle est la difficulté de documenter et de localiser ce système:
- Le système n'est pas nuageux.
- Configuration complexe, nombreuses intégrations avec différents systèmes.
- Prise en charge de plusieurs versions.
- À la suite des paragraphes 1 à 3, nous avons des implémentations et des mises à jour complexes. Chaque client a sa propre version, sa propre configuration et son intégration avec différents systèmes.
- Le système n'est pas massif, il n'est utilisé que par les grandes entreprises. Par conséquent, le nombre de clients n'est pas très important par rapport aux produits de petite taille.
- Un grand nombre de termes spécifiques.
- Modèle multi-rôles. Et cela signifie que la documentation et l'interface doivent être adaptées aux caractéristiques de chaque rôle (niveau de connaissance et caractéristiques des tâches).
- Les interfaces système contiennent environ 30 000 lignes de texte et environ 3 000 pages de documentation technique complexe sont écrites.
- Les versions sont publiées 2 à 3 fois par an.
- Après chaque version, environ 10% du texte et de la documentation de l'interface sont mis à jour et complétés.
- 3 langues: russe (source), anglais et allemand.
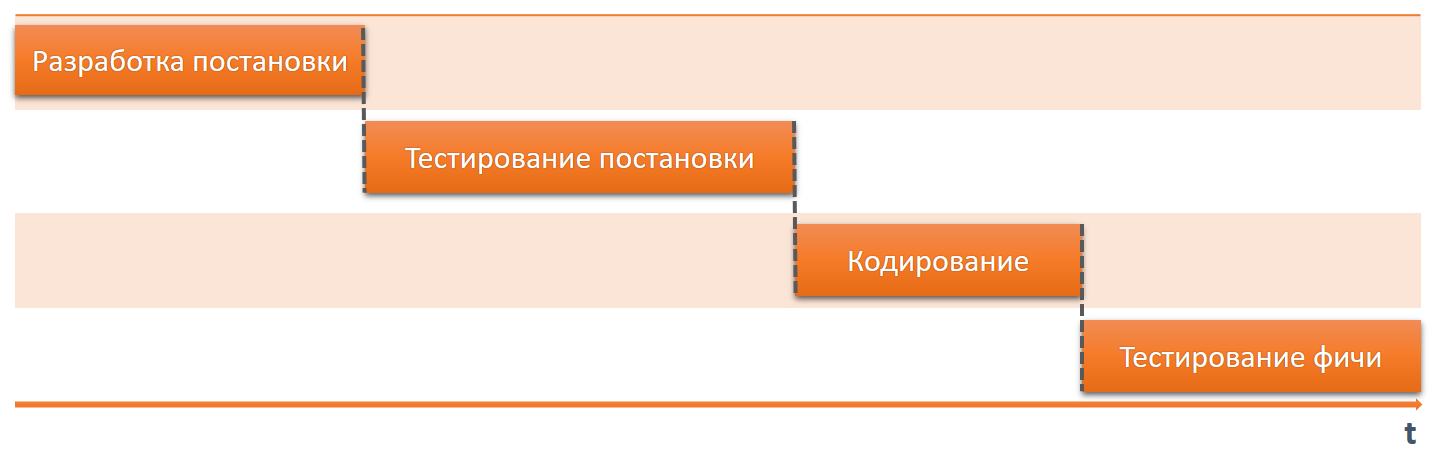
Cycle de vie du développement
Examinons le cycle de vie du développement logiciel et sélectionnons uniquement les étapes liées à la documentation et à la localisation:
- Développement de fonctionnalités. Dans le cadre de cette phase, des textes pour l'interface sont développés.
- La documentation Dans le cadre de cette phase, la documentation est développée, y compris la création de captures d'écran et d'autres images.
- Localisation de l'interface en plusieurs langues.
- Traduction de la documentation dans d'autres langues, y compris la localisation de captures d'écran et d'autres images.
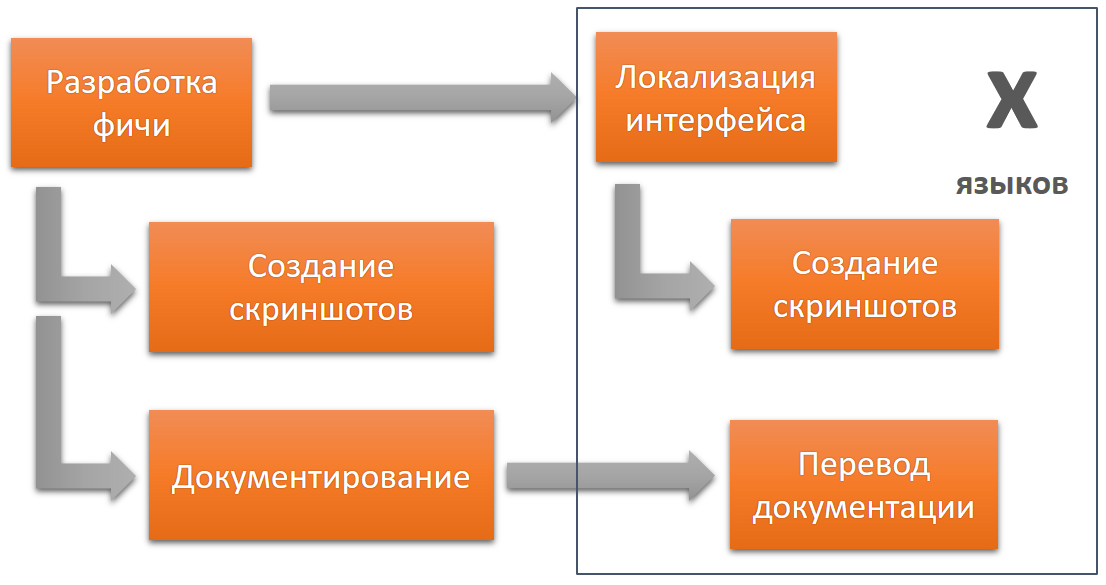
Imaginons maintenant qu'une erreur mineure ait été commise dans l'interface. Il s'applique automatiquement à chaque étape, à plusieurs versions et langues.
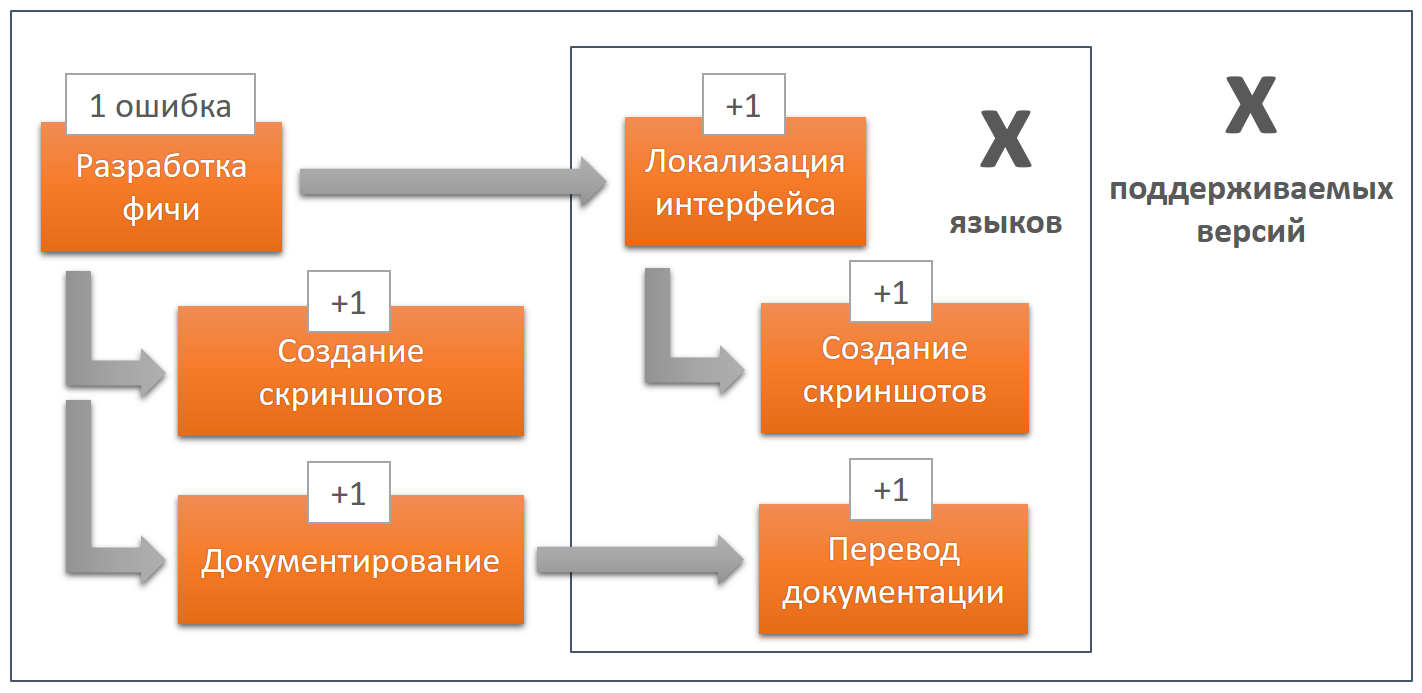
Des erreurs supplémentaires peuvent apparaître à chaque étape, c'est-à-dire que nous pouvons obtenir un grand nombre d'erreurs. Les erreurs d'interface mineures ne seront probablement jamais corrigées; il y a toujours des tâches plus importantes. Et si vous les modifiez, le coût de ces modifications sera très élevé, car vous devrez à nouveau parcourir toute la chaîne, toutes les versions et toutes les langues. Et plus il y a de versions et de langues, plus c'est cher.
Dans ce contexte, on ne peut pas parler uniquement de la qualité de localisation de l'interface ou de la qualité de la documentation traduite, puisque le résultat du travail de chaque étape est le fondement de l'étape suivante. C'est pourquoi il est très important de tout faire correctement à chaque étape. Et c'est pourquoi il vaut la peine de considérer le développement, la documentation et la localisation de logiciels comme les étapes d'un processus inextricable unique.
Organisation du texte dans l'interface
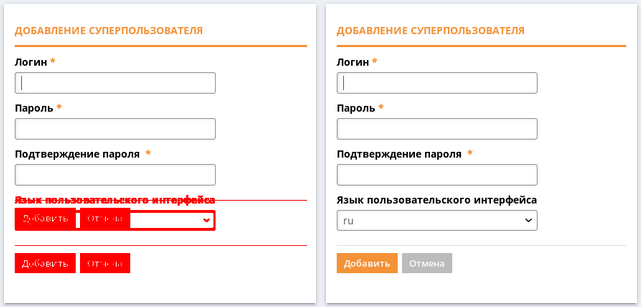
Lorsque nos programmeurs ont repris la localisation du système, il n'était absolument pas prêt pour cela. Le texte de l'interface était stocké dans le code, et le souhait de la direction était: "tout faire rapidement". Les programmeurs ont écrit un script qui a extrait tout le texte du code et l'a jeté dans les fichiers de ressources, et le lendemain, ils ont remis les fichiers de ressources au premier employé qui connaissait l'anglais, qui a rapidement tout traduit dans le bloc-notes. Ce qui est arrivé de cela peut être vu ci-dessous.
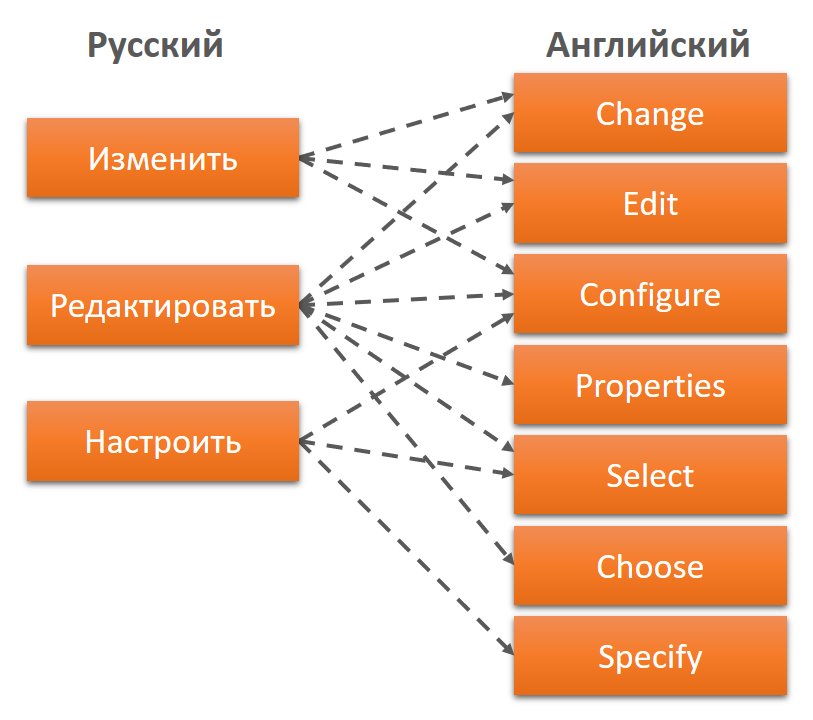
L'image montre un bouton simple, il ouvre une forme avec des paramètres, où ces paramètres peuvent être modifiés. Il existe des dizaines de ces boutons dans le système. En russe, il y avait 3 options pour un tel bouton; la localisation en anglais contenait déjà 7 options.
Dans cette situation, il y a immédiatement un grand désir de nettoyer les lignes de l'interface. Pour ce faire, je propose d'appliquer les règles suivantes:
- Division de toutes les lignes en groupes.
Toutes les lignes doivent être divisées en groupes en fonction du type d'éléments d'interface. Même si les lignes ont le même texte, des règles de traduction différentes peuvent s'appliquer pour différents groupes. Par exemple, la règle de capitalisation pour la première lettre de chaque mot en anglais. Pour certains types d'éléments d'interface, il est utilisé, pour d'autres non. - Suppression des doublons.
Dans chaque groupe, il est logique de supprimer toutes les lignes en double, c'est-à-dire les lignes avec le même texte. Ensuite, il y aura la seule option à la fois en russe et dans d'autres langues. Cela réduit les coûts de traduction. Je note que, très probablement, les lignes répétées resteront, car dans certains cas, le contexte peut être différent. De plus, ces lignes avec le même texte source peuvent être traduites de différentes manières. Par exemple, le mot Nom , dans le contexte du nom d’une personne, peut être traduit par Prénom , et dans le contexte d’un nom de fichier, simplement Nom . - Ajout de contexte aux identifiants de ligne.
L'identifiant de ligne peut être constitué de l'identifiant de la ligne elle-même et du groupe auquel appartient la ligne. Cela est nécessaire pour que le traducteur puisse utiliser l'identifiant pour sélectionner une règle de localisation. Si nous avons de tels identifiants corrects, le processus de vérification et de correction des mêmes erreurs de capitalisation peut être facilement automatisé.
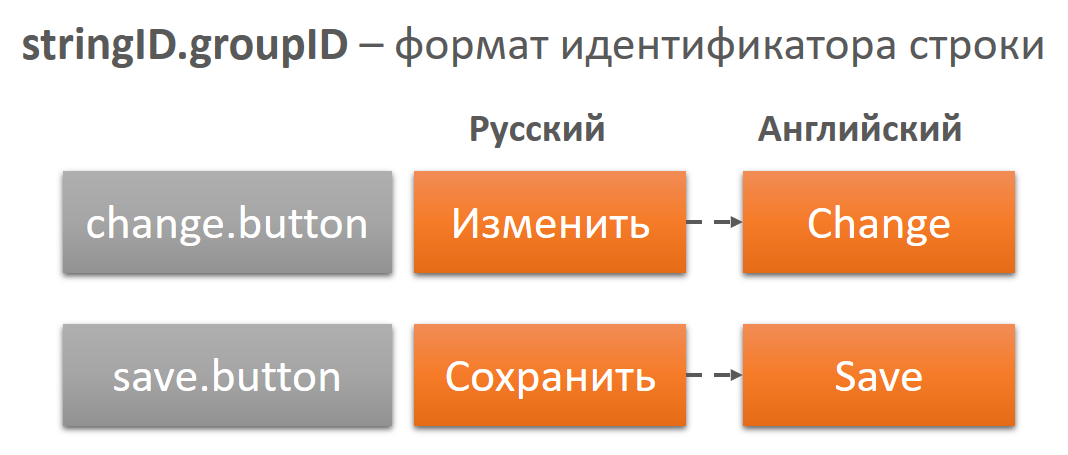
Malheureusement, l'application de ces règles à l'ensemble des 30 000 lignes existantes prend beaucoup de temps. Nous voici au stade initial et mettons progressivement en ordre les lignes les plus répétées et développons des règles pour les nouvelles lignes. Mais vous devez admettre, ce serait super si toutes les règles étaient énoncées et mises en œuvre immédiatement!
Processus de documentation et de localisation
Jetons un coup d'œil au processus de documentation et de localisation basé sur le temps. Si vous commencez à documenter et à localiser avant la fin du développement des fonctionnalités, vous devrez tout refaire (peut-être plusieurs fois).
Même chose avec la traduction de la documentation.
Et si vous remettez la documentation aux utilisateurs avant la fin de toutes les modifications, vous pouvez compter sur un tas de commentaires. Très probablement, certains de ces commentaires seront corrigés aux dernières étapes du développement, mais vous devrez consacrer plus de temps à leur traitement.
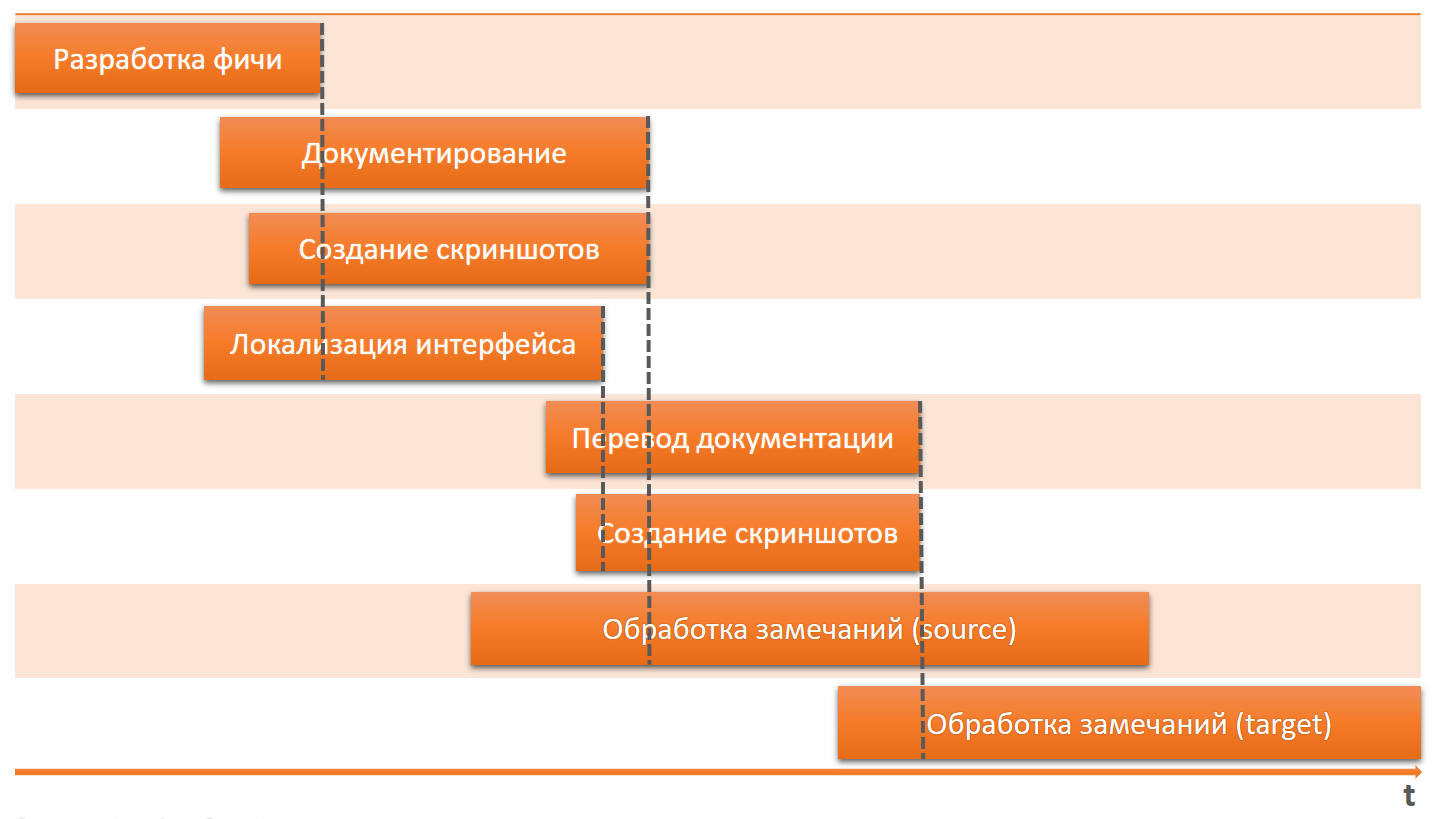
Si les processus ne sont pas coordonnés et que nous ne suivons pas tous les changements à temps, alors «rien-rien-n'importe où» ne correspondra pas.
La documentation ne correspondra pas à l'interface. Les captures d'écran ne correspondront pas à l'interface et au texte de la documentation.
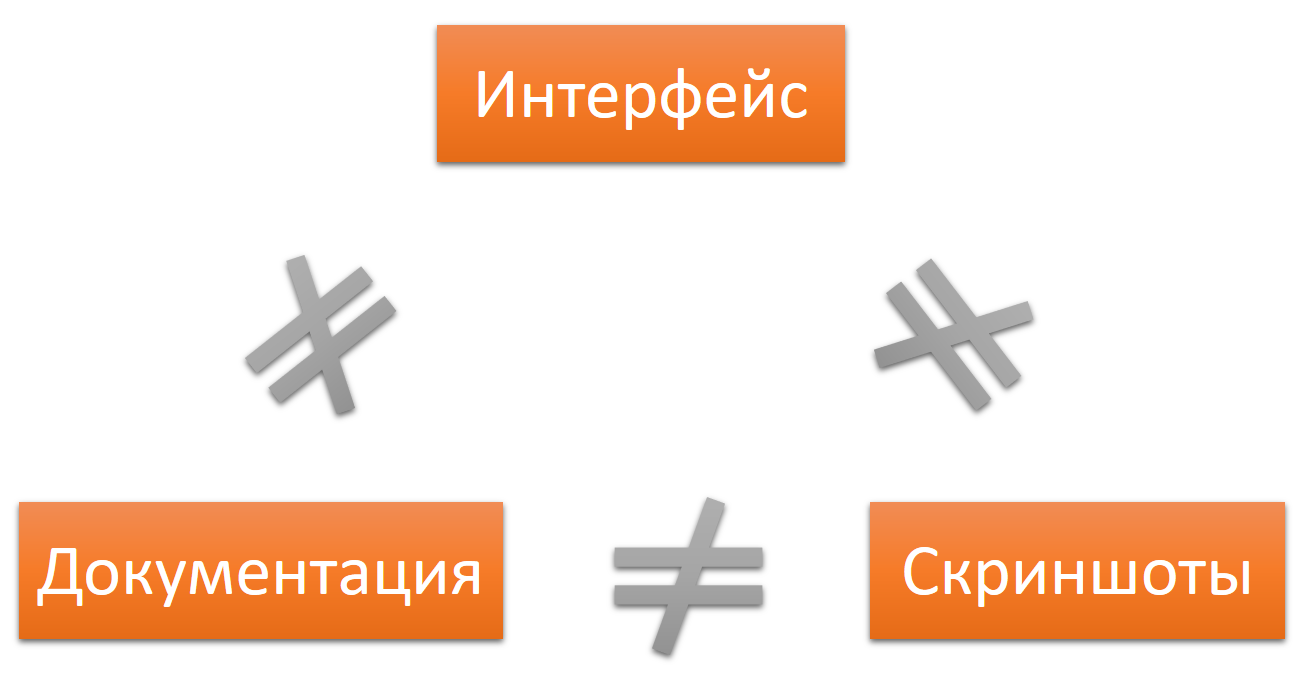
La même chose avec la localisation. Le texte de l'interface et de la documentation dans la langue source ne correspondra pas au texte de l'interface et de la documentation dans d'autres langues.
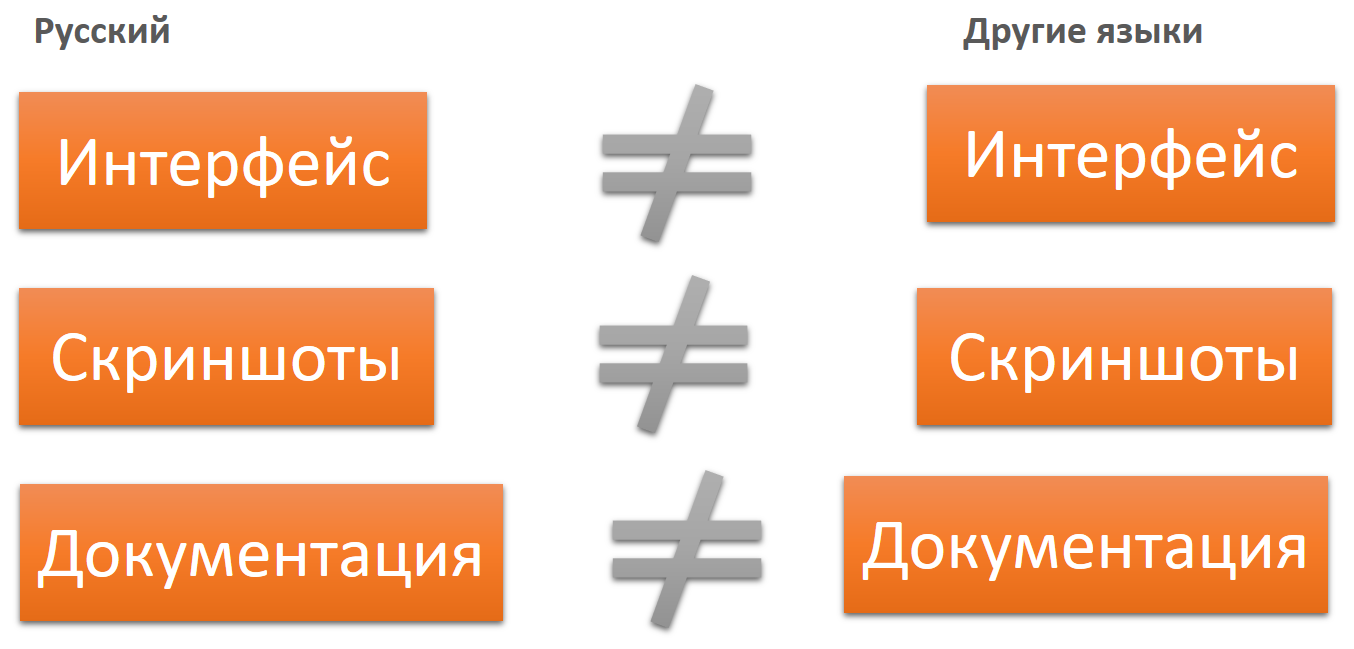
Nous avons décidé que pour le moment nous ne pouvons nous permettre de commencer chaque nouvelle étape qu'après avoir terminé la précédente.
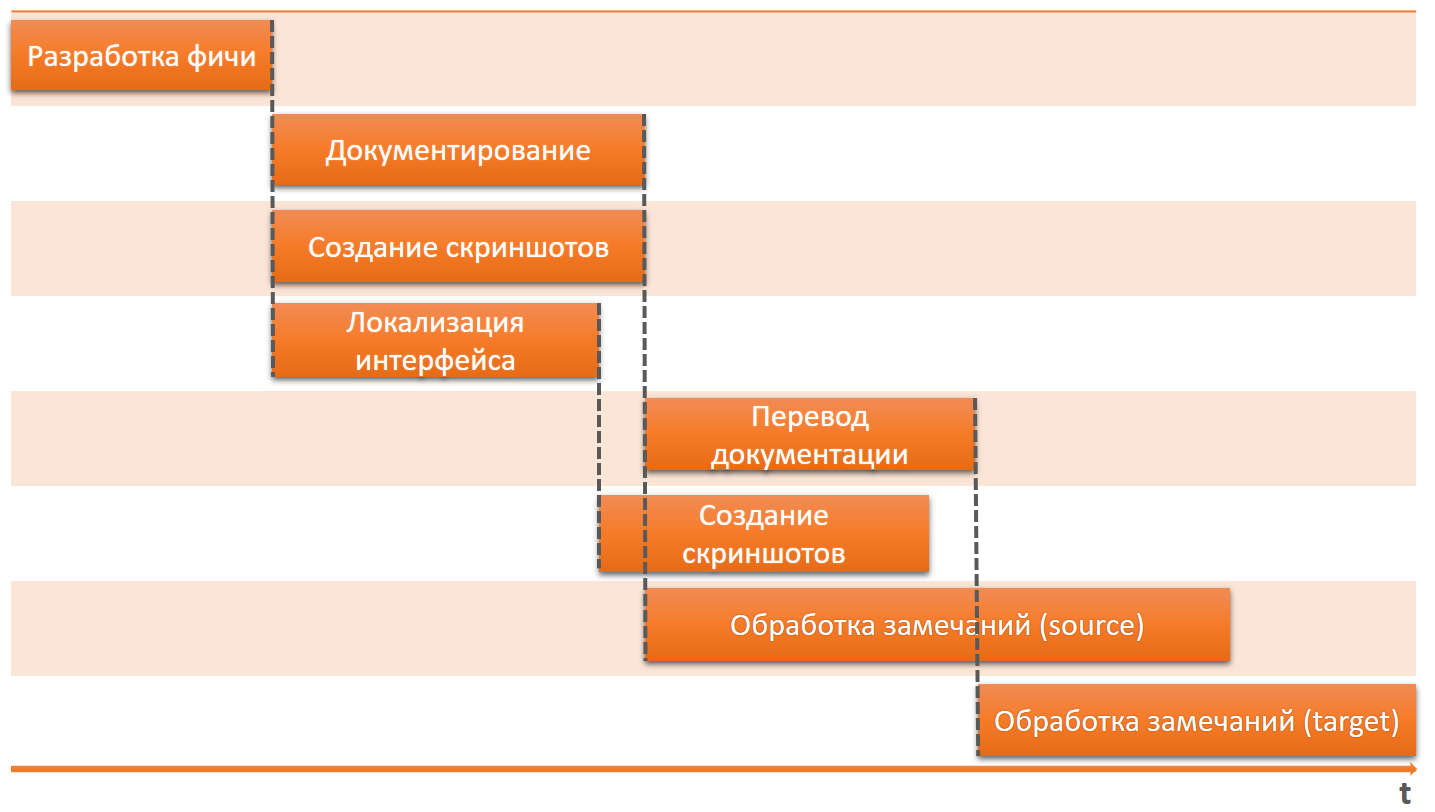
Oui, notre documentation et notre localisation sortent tard après la sortie. Et en parlant de localisation, nous avons déjà sécurisé la possibilité d'une localisation continue, mais nous n'utilisons pas cette opportunité et faisons toute la localisation en une seule étape à la fin de la version. Un couple de jours dans le cadre d'une version semestrielle est une très petite étape.
Tant que notre produit n'est pas massif, nous n'avons pas un besoin urgent de documentation et de localisation pour apparaître le même jour. Nous avons de longues versions, de grandes entreprises clientes, dont il n'y a pas beaucoup par rapport à des produits petits et plus massifs, et ils ne commencent pas immédiatement à installer une nouvelle version du produit ou à la mettre à niveau. Les coûts d'un remodelage constant sont sensiblement réduits.
Problèmes de terminologie
Au stade de la documentation et de la localisation, nous avons constamment rencontré des problèmes de terminologie:
- Les mêmes entités étaient appelées différemment et différentes entités étaient nommées de la même manière.
- Les mêmes termes ont été traduits de différentes manières et différents termes ont été traduits de la même manière.
- Une entité peut être assimilée à ses entités enfants dont elle est constituée, ou entités parent.
- Des termes infructueux ou incorrects ont été choisis pour désigner une entité.
Le processus de développement pour nous pendant un certain temps ressemblait à ceci:
- Les analystes écrivent une production.
- Les testeurs testent la production.
- Code des développeurs.
- Les testeurs testent le résultat.
Et en essayant de se faufiler dans ce processus avec la terminologie, nous avons reçu de telles excuses:
- Vous ralentirez tout le processus.
- Ce n'est généralement pas si important.
- Vous avez les outils, vous pouvez tout réparer plus tard.
Mais "plus tard", il s'est avéré que nous ne pouvons pas tout réparer. Par exemple, il y avait des situations où, en raison d'une terminologie mal comprise, les objets système étaient placés aux mauvais niveaux de hiérarchie ou étaient combinés en groupes incorrects.
Nous vérifions maintenant les termes et le texte de l'interface en parallèle avec la définition des tests. Autrement dit, pendant que les testeurs écrivent leurs commentaires, nous écrivons les nôtres.

Ce que nous faisons lors des tests de production:
- Nous révélons de nouveaux termes.
- Vérifiez le texte de l'interface: pour l'utilisation correcte des termes, la conformité avec le guide de style et la conformité avec les rôles.
- Nous identifions les lignes existantes afin de ne pas faire de doublons.
- Nous convenons de la nécessité de la localisation, car certaines parties de l'interface ne peuvent être utilisées que dans un seul pays.
Lorsque nous révélons de nouveaux termes, nous les ajoutons au glossaire, tout en:
- Ajoutez une définition ou un contexte.
- Nous indiquons la relation avec d'autres termes (indiquer les termes parent et enfant).
- Nous essayons d'indiquer immédiatement le sens anglais, car après avoir choisi le nom anglais, il devient parfois clair que le russe n'est pas choisi très correctement.
On peut dire qu'en raison de la coordination de la terminologie et des textes d'interface au stade de l'approbation de la mise en place, nous avons commencé à gagner beaucoup de temps sur de multiples corrections dans les étapes suivantes.
La documentation
Les principes auxquels nous adhérons lors de la documentation:
- Utilisation d'un système à source unique.
- Utilisation du glossaire.
- Utilisez le guide de style.
- Division de la documentation en petits documents facilement aliénables.
Cela vaut la peine, même si le format principal est le Web. Si nécessaire, vous ne pouvez pas traduire toute la documentation, mais uniquement les documents les plus importants, ou le faire par étapes.
Je vais maintenant parler de certains des aspects les plus importants du processus de documentation.
Réutiliser le texte
Dans la plupart des systèmes à source unique, des variables peuvent être utilisées. Par conséquent, nous avons développé des scripts qui convertissent automatiquement les fichiers de ressources d'interface en fichiers variables. Dans le processus de développement de la documentation, nous ne saisissons pas les textes des éléments d'interface, mais insérons des variables dans le texte. Ainsi, dans la version russe, les lignes russes sont automatiquement tirées, dans la version anglaise, anglais, en allemand allemand.

Quels sont les avantages:
- Les erreurs dans le texte des éléments d'interface sont exclues si elles sont mentionnées dans la documentation. Les textes des éléments d'interface dans la documentation sont toujours identiques aux textes de l'interface.
- Si des lignes de texte ont changé dans l'interface, elles changent automatiquement dans la documentation.
- Les erreurs sont exclues lors de la traduction des textes des éléments d'interface dans la documentation.
- Un traducteur passe moins de temps à travailler.
Il existe de nombreuses phrases en double dans la documentation. Par exemple, une phrase comme - «Cliquez sur le bouton
Enregistrer ». Dans les systèmes à source unique, une telle proposition peut être placée dans un extrait. Un extrait est un si petit fichier qui peut être inséré dans d'autres pages de la documentation.

Comme vous pouvez le voir, le texte du bouton
Enregistrer dans l'extrait est également remplacé par la variable.
Cela offre les avantages suivants:
- Les phrases de sens identiques sont partout identiques, ce qui signifie que l'uniformité du texte augmente.
- Le coût de développement de la documentation par réutilisation est réduit.
- Ces phrases ne sont traduites qu'une seule fois. Cela réduit le coût du traducteur.
Captures d'écran et autres images
Dans notre documentation, nous utilisons souvent des captures d'écran et d'autres images pouvant contenir du texte.
Pour prendre des captures d'écran dans différentes langues par nos propres moyens, sous chaque capture d'écran, nous écrivons le texte qui y est utilisé. Ce texte est balisé et n'apparaît pas dans la documentation terminée. Avant de traduire la documentation, nous traduisons les textes pour les captures d'écran. Et pendant la traduction de la documentation, nous prenons des captures d'écran par des rédacteurs techniques sans connaissance de la langue.
En utilisant des captures d'écran, il y a d'autres difficultés. Par exemple, comment suivre toutes les modifications si l'interface modifie une ligne de texte, qui est utilisée à 50 endroits?
Comment alors retrouver toutes les captures d'écran de ces 50 lieux pour les remplacer dans la documentation?
Pour résoudre ce problème, nous utilisons l'outil QVisual que nous avons développé chez Tinkoff. Le processus de travail avec cela ressemble à ceci:
- Pendant le développement de la documentation, sous chaque capture d'écran, nous faisons un lien vers le stand où cette capture d'écran est prise.
- À un certain moment, nous préparons une liste de tous les liens.
- Nous chargeons la liste reçue dans QVisual.
- QVisual parcourt une version du produit et prend un ensemble de captures d'écran.
- Ensuite, nous prenons la nouvelle version du produit et QVisual l'exécute en utilisant les mêmes liens.
- QVisual compare ensuite 2 jeux de captures d'écran et génère un rapport. Dans le rapport, graphiquement, vous pouvez voir les différences entre les deux versions. Un exemple est ci-dessous. Vous pouvez immédiatement voir que dans la nouvelle version de la capture d'écran, un champ supplémentaire Langue d'interface utilisateur est apparu.
- Ensuite, nous répétons la procédure de comparaison (p. 1-6) pour chaque langue.
- Nous prenons les rapports et parcourons les captures d'écran de la documentation.
Ainsi, nous réduisons le coût de nombreuses vérifications manuelles de captures d'écran. De plus, manuellement, il n'est pas toujours possible d'identifier toutes les erreurs, vous pouvez simplement ignorer quelque chose.
Certes, toutes les fenêtres ne peuvent pas être ouvertes à l'aide de liens et cela ne fonctionne que pour l'interface Web, mais cela supprime toujours certains des problèmes de mise à jour des captures d'écran.
Localisation d'interface
Avant de localiser l'interface, si cela n'est pas déjà fait, vous devez traduire tous les termes du glossaire.
Lorsque le glossaire est traduit, la localisation peut commencer. Dans ce processus, nous adhérons aux principes suivants:
- Utilisez le glossaire.
- Nous utilisons la mémoire de traduction.
- Nous utilisons le guide de style.
- Nous utilisons un contexte.
- Nous utilisons l'assurance qualité automatique (QA).
Je note que le contexte peut avoir une priorité plus élevée pour prendre une décision de traduction que d'avoir la même ligne déjà traduite dans la mémoire de traduction. En outre, en fonction du contexte, certaines règles de traduction spécifiées dans le guide de style peuvent s'appliquer.
Il peut y avoir plusieurs façons de fournir un contexte:
- Comme je l'ai écrit ci-dessus, le contexte peut être défini dans l'identificateur de chaîne lui-même ou dans des champs supplémentaires de fichiers de ressources (si le format le permet).
- Des captures d'écran peuvent être ajoutées. À l'heure actuelle, nous sommes en mesure d'ajouter manuellement des captures d'écran à des lignes particulièrement complexes.
- Fourniture de stands et de documentation dans la langue source. Comme le montre la pratique, cette méthode ne fonctionne pas. Les traducteurs n'utilisent généralement pas le matériel et les supports qui leur sont fournis. Peut-être parce que le temps de traduction d'une ligne augmente plusieurs fois.
Traduction de documentation
Les principes que nous essayons d'adhérer lors de la traduction de la documentation:
- Tout d'abord, nous traduisons des textes pour des captures d'écran et d'autres images. Comme je l'ai écrit ci-dessus, les captures d'écran sont prises en parallèle avec la traduction de la documentation. Cela se fait sur le stand en utilisant des textes traduits pour les captures d'écran.
- Nous traduisons uniquement les lignes modifiées et nouvelles. Les lignes précédemment traduites avec une correspondance à 100% ne semblent tout simplement pas. Oui, vous pouvez relire toute la documentation à chaque version, mais en tenant compte du fait que chaque version est mise à jour à environ 10% du texte, la soustraction des 90% restants du texte est un coût injustifié.
- Utilisez le glossaire. Le glossaire doit être traduit plus tôt, au stade de la localisation de l'interface.
- Nous utilisons la documentation de traduction de la mémoire.
- Nous utilisons l'interface de traduction de mémoire.
- Nous utilisons le guide de style.
- Nous utilisons un contrôle qualité automatique (QA).
Structure organisationnelle et rétroaction
Je vais dire quelques mots sur la structure organisationnelle de l'entreprise. C'est différent pour tout le monde, mais imaginez un cas où chaque département a son propre département.
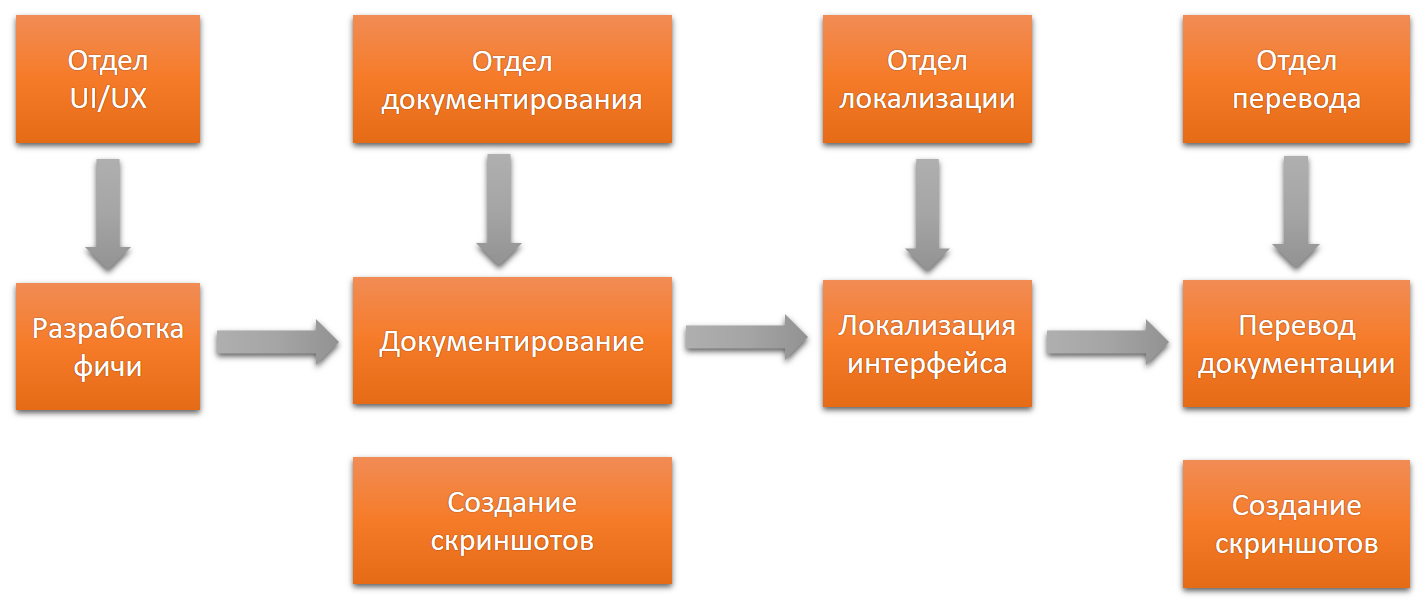
La rétroaction d'un département au précédent dans cette version sera difficile, l'interaction entre les employés de différents départements est difficile. La solution de tous les problèmes à travers la tête est également un "cou étroit". Chaque leader a sa propre vision, ses objectifs et ses priorités. Beaucoup de temps peut être consacré à des approbations supplémentaires.
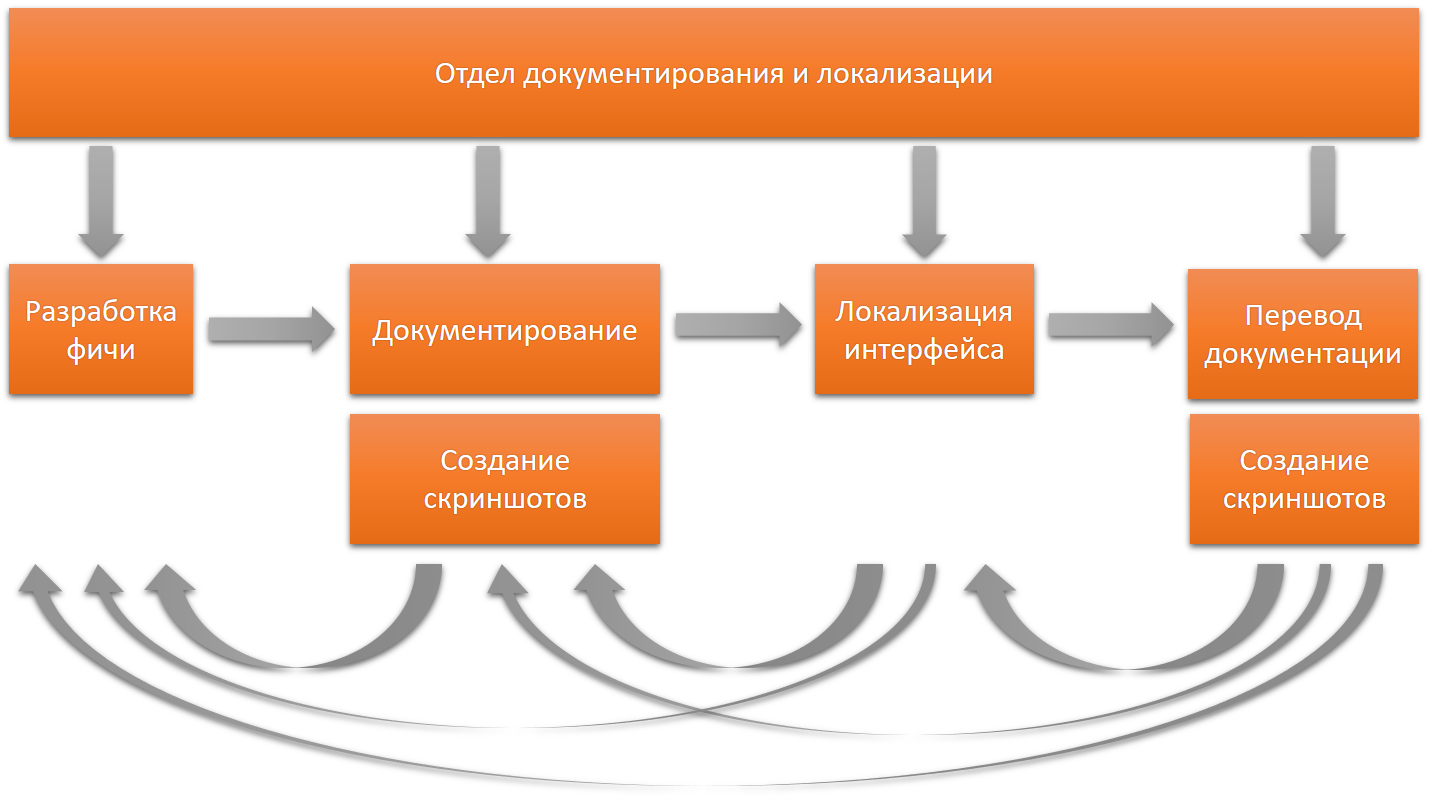
À mon avis, un département devrait être responsable de tous les textes dans toutes les langues.
Avec cette répartition des responsabilités, chaque version du produit est un projet distinct de plusieurs étapes, et la qualité de la mise en œuvre de ce projet doit être répondue dans son ensemble. Il est plus facile d'établir une rétroaction, de comprendre rapidement tout problème, de faire une rétrospective et de trouver la cause profonde du problème.
Je vais vous donner un exemple.
Étant donné que nos rédacteurs techniques vérifient eux-mêmes les traductions à l'aide de l'assurance qualité, nous avons constaté des dizaines, voire des centaines, d'erreurs d'incohérence.
Il s'est avéré que le traducteur voit les phrases qui sont identiques dans leur sens, mais de différentes manières, et fait la même traduction pour elles. Nous avons lancé la tâche et le rédacteur technique a remplacé toutes les différentes versions du même texte au sens d'un extrait. Maintenant, il n'y aura plus de telles erreurs répétées. Les professionnels n'auront pas à passer du temps à les analyser, et la traduction dans de nouvelles langues sera plus facile à l'avenir.
Dans le cas général, si le traducteur a des questions pendant la traduction, alors pour nous, c'est déjà une «cloche» que quelque chose ne va pas dans les premiers stades et nous devons faire la tâche de correction.
Quelle documentation de qualité est nécessaire
Avant d'essayer de créer une documentation parfaite dans toutes les langues, il convient de considérer la qualité requise? Des questions supplémentaires aideront à répondre à cette question:
- Qui sont les utilisateurs de la documentation?
Si la documentation est du domaine public et que les clients qui en décident prennent la décision d'acheter le produit, la qualité doit être proche de l'idéal. ( ), . , . , : , , . . - ?
, , . . ? , , .
:
- .
, , -50 , . - 1-2 , . - .
CAT-. , (, ), . - , , , .
- , .
Web- . , , .
. , .
. . , .
:
- .
- , . . , Ctrl+Enter . . . - .
, . , , . - .
, , . , ( ), . , . .
, , , . , , .
Conclusions
, -, .
, , .
. .
, ! !
, !