Une fonctionnalité de tueur est apparue dans l'analyseur statique NoVerify : une façon déclarative de décrire les inspections qui ne nécessitent pas de programmation Go ni de compilation de code.
Pour vous intriguer, je vais vous montrer une description d'une inspection simple mais utile:
$x && $x;
Cette inspection trouve toutes les expressions logiques && où les opérandes gauche et droit sont identiques.
NoVerify est un analyseur statique pour PHP écrit en Go . Vous pouvez le lire dans l'article « NoVerify: Linter pour PHP de l'équipe VKontakte ». Et dans cette revue, je parlerai de la nouvelle fonctionnalité et de la façon dont nous y sommes arrivés.

Contexte
Quand même pour une simple nouvelle vérification vous avez besoin d'écrire quelques dizaines de lignes de code sur Go, vous commencez à vous demander: est-ce possible autrement?
Sur Go, nous avons écrit l'inférence de type, l'ensemble du pipeline du linter, le cache de métadonnées et de nombreux autres éléments importants sans lesquels NoVerify est impossible. Ces composants sont uniques, mais les tâches comme «interdire d'appeler une fonction X avec un ensemble d'arguments Y» ne le font pas. Juste pour ces tâches simples, le mécanisme des règles dynamiques a été ajouté.
Les règles dynamiques vous permettent de séparer les composants internes complexes de la résolution de problèmes typiques. Le fichier de définition peut être stocké et versionné séparément - il peut être édité par des personnes qui ne sont pas liées au développement de NoVerify lui-même. Chaque règle met en œuvre une inspection de code (que nous appellerons parfois vérification).
Oui, si nous avons un langage pour décrire ces règles, vous pouvez toujours écrire un modèle sémantiquement incorrect ou ignorer certaines restrictions de type - et cela conduit à des faux positifs. Néanmoins, la course aux données ou le déréférencement du pointeur nil travers le langage des règles n'est pas entré.
Langage de description du modèle
Le langage de description est syntaxiquement compatible avec PHP. Cela simplifie son étude et permet également d'éditer des fichiers de règles en utilisant le même PhpStorm.
Au tout début du fichier de règles, il est recommandé d'insérer une directive apaisant votre IDE préféré:
<?php
Ma première expérience avec la syntaxe et les filtres possibles pour les modèles a été phpgrep . Il peut être utile en soi, mais dans NoVerify, il est devenu encore plus intéressant, car il a désormais accès aux informations de type.
Certains de mes collègues ont déjà essayé phpgrep dans leur travail, et c'était un autre argument en faveur du choix d'une telle syntaxe .
Phpgrep lui-même est une adaptation gogrep pour PHP (vous pouvez également être intéressé par cgrep ). En utilisant ce programme, vous pouvez rechercher du code via des modèles de syntaxe .
Une alternative serait la syntaxe structurelle de recherche et de remplacement (SSR) de PhpStorm. Les avantages sont évidents - il s'agit d'un format existant, mais j'ai découvert cette fonctionnalité après avoir implémenté phpgrep. Vous pouvez bien sûr fournir une explication technique: il existe une syntaxe incompatible avec PHP et notre analyseur ne la maîtrisera pas, mais cette "vraie" raison convaincante a été découverte après avoir écrit le vélo.
En fait, il y avait une autre option
Il pourrait être nécessaire d'afficher un modèle avec du code PHP presque un à un - ou d'aller dans l'autre sens: inventer un nouveau langage, par exemple avec la syntaxe des expressions S.
PHP-like Lisp-like ----------------------------- $x = $y | (expr = $x $y) fn($x, 1) | (expr call fn $x 1) : (or (expr == (type string (expr)) (expr)) (expr == (expr) (type string (expr))))
Au final, j'ai pensé que la lisibilité des modèles est toujours importante, et nous pouvons ajouter des filtres via les attributs phpdoc.
clang-query est un exemple d'une idée similaire, mais il utilise une syntaxe plus traditionnelle.
Nous créons et exécutons nos propres diagnostics!
Essayons d'implémenter nos nouveaux diagnostics pour l'analyseur.
Pour ce faire, vous devez installer NoVerify. Prenez la version binaire si vous n'avez pas de chaîne d'outils Go dans le système (si vous en avez une, vous pouvez tout compiler à partir de la source).
Énoncé du problème
PHP a de nombreuses fonctions intéressantes, dont parse_str . Sa signature:
Vous comprendrez ce qui ne va pas ici si vous regardez cet exemple dans la documentation:
$str = "first=value&arr[]=foo+bar&arr[]=baz"; parse_str($str); echo $first;
Mmm, les paramètres de la chaîne étaient dans la portée actuelle. Pour éviter cela, nous aurons besoin dans notre nouveau test d'utiliser le deuxième paramètre de la fonction, $result , pour que le résultat soit écrit dans ce tableau.
Créez vos propres diagnostics
Créez le fichier myrules.php :
<?php parse_str($_);
Le fichier de règles en général est une liste d'expressions au niveau supérieur, chacune étant interprétée comme un modèle phpgrep. Un commentaire phpdoc spécial est attendu pour chacun de ces modèles. Un seul attribut est requis - une catégorie d'erreur avec un texte d'avertissement.
Il y a maintenant quatre niveaux au total: error , warning , info et maybe - maybe . Les deux premiers sont critiques: le linter retournera un code différent de zéro après l'exécution si au moins une des règles critiques fonctionne. Après l'attribut lui-même, un texte d'avertissement sera émis par le linter en cas de déclenchement du modèle.
Le modèle que nous avons écrit utilise $_ - il s'agit d'une variable de modèle sans nom. Nous pourrions l'appeler, par exemple, $x , mais comme nous ne faisons rien avec cette variable, nous pouvons lui donner un nom «vide». La différence entre les variables de modèle et les variables PHP est que les premières coïncident avec absolument n'importe quelle expression, et pas seulement avec une variable «littérale». C'est pratique: nous devons souvent chercher des expressions inconnues plutôt que des variables spécifiques.
Démarrage d'un nouveau diagnostic
Créez un petit fichier de test pour le débogage, test.php :
<?php function f($x) { parse_str($x);
Ensuite, exécutez NoVerify avec nos règles sur ce fichier:
$ noverify -rules myrules.php test.php
Notre avertissement ressemblera à ceci:
WARNING myrules.php:4: parse_str without second argument at test.php:4 parse_str($x); ^^^^^^^^^^^^^
Le nom de la vérification par défaut est le nom du fichier de règles et la ligne qui définit cette vérification. Dans notre cas, c'est myrules.php:4 .
Vous pouvez définir votre nom à l'aide de l' @name <name> .
Exemple @Name
parse_str($_);
WARNING parseStrResult: parse_str without second argument at test.php:4 parse_str($x); ^^^^^^^^^^^^^
Les règles nommées succombent aux lois des autres diagnostics:
- Peut être désactivé via
-exclude-checks -critical niveau de -critical peut être redéfini via -critical
Travailler avec des types
L'exemple précédent est bon pour hello world - mais souvent nous devons connaître les types d'expressions afin de réduire le nombre d'opérations de diagnostic
Par exemple, pour la fonction in_array, nous demandons l'argument $strict=true lorsque le premier argument ( $needle ) est de type chaîne.
Pour cela, nous avons des filtres de résultats.
Un tel filtre est @type <type> <var> . Il vous permet de supprimer tout ce qui ne correspond pas aux types énumérés.
in_array($needle, $_);
Ici, nous avons donné le nom du premier argument à l'appel in_array pour lui in_array un filtre de type. Un avertissement ne sera émis que lorsque le type de $needle est une string .
Les jeux de filtres peuvent être combinés avec l'opérateur @or :
$x == $y;
Dans l'exemple ci-dessus, le modèle ne correspondra qu'à ces expressions == , où l'un des opérandes est de type string . On peut supposer que sans @or tous les filtres sont combinés via @and , mais cela n'a pas besoin d'être explicitement indiqué.
Limiter la portée du diagnostic
Pour chaque test, vous pouvez spécifier @scope <name> :
@scope all - la valeur par défaut, la validation fonctionne partout;@scope root - lancement uniquement au niveau supérieur;@scope local - s'exécute uniquement à l'intérieur des fonctions et méthodes.
Supposons que nous voulons signaler un return dehors du corps de la fonction. En PHP, cela a parfois du sens - par exemple, lorsqu'un fichier est connecté à partir d'une fonction ... Mais dans cet article, nous condamnons cela.
return $_;
Voyons comment cette règle va se comporter:
<?php function f() { return "OK"; } return "NOT OK";
De même, vous pouvez demander d'utiliser *_once au lieu d' require et include :
require $_; include $_;
Désormais, lors de l'appariement des motifs, les parenthèses ne sont pas prises en compte de manière assez cohérente. Le modèle (($x)) ne trouvera pas «toutes les expressions entre crochets», mais simplement toutes les expressions, en ignorant les crochets. Cependant, $x+$y*$z et ($x+$y)*$z se comportent comme ils le devraient. Cette fonctionnalité provient des difficultés de travail avec les jetons ( et ) , mais il est possible que l'ordre soit restauré dans l'une des prochaines versions.
Modèles de regroupement
Lorsque la duplication des commentaires phpdoc apparaît sur les modèles, la possibilité de combiner des modèles vient à la rescousse.
Un exemple simple pour démontrer:
Imaginez maintenant combien il serait désagréable de décrire une règle dans l'exemple suivant sans cette fonctionnalité!
{ $x > $y; $x < $y; $x >= $y; $x <= $y; $x == $y; }
Le format d'enregistrement spécifié dans l'article n'est qu'une des options proposées. Si vous souhaitez participer au choix, alors vous avez une telle opportunité: vous devez mettre +1 aux offres que vous aimez plus que les autres. Pour plus de détails, cliquez ici .
Comment les règles dynamiques sont intégrées
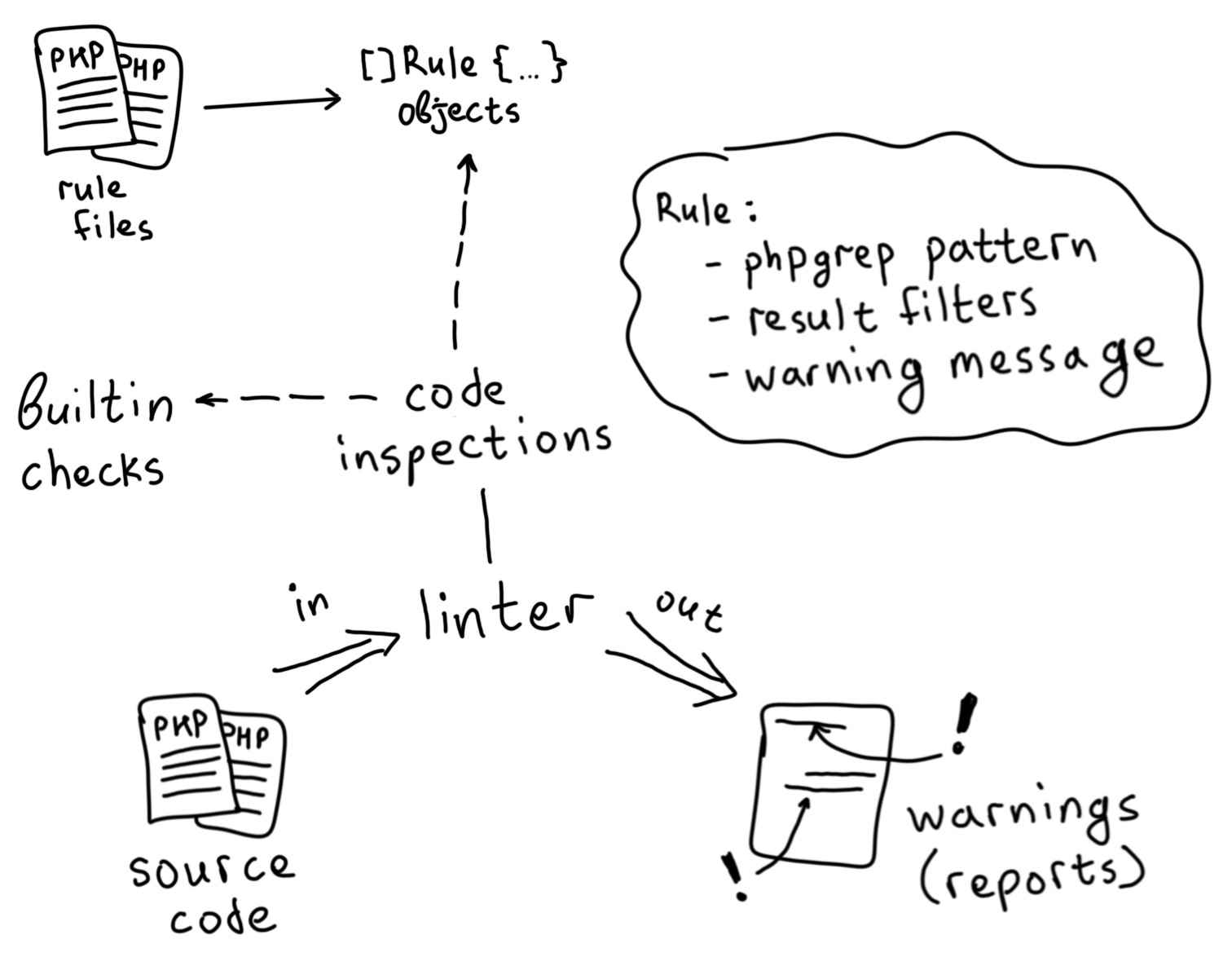
Au moment du lancement, NoVerify essaie de trouver le fichier de règles spécifié dans l'argument de rules .
Ensuite, ce fichier est analysé comme un script PHP normal, et à partir de l' AST résultant, un ensemble d'objets de règle avec des modèles phpgrep liés à eux est collecté.
Ensuite, l'analyseur démarre le travail selon le schéma habituel - la seule différence est que pour certaines sections de code vérifiées, il démarre un ensemble de règles liées. Si la règle est déclenchée, un avertissement s'affiche.
Le succès est considéré comme la mise en correspondance du modèle phpgrep et le passage d'au moins un des ensembles de filtres (ils sont séparés par @or ).
À ce stade, le mécanisme de règles ne ralentit pas de manière significative le fonctionnement du linter, même s'il y a beaucoup de règles dynamiques.
Algorithme de correspondance
Avec l'approche naïve, pour chaque nœud AST, nous devons appliquer toutes les règles dynamiques. Il s'agit d'une implémentation très inefficace, car la plupart du travail sera fait en vain: de nombreux modèles ont un préfixe spécifique par lequel nous pouvons regrouper les règles.
Ceci est similaire à l'idée de l' appariement parallèle , mais au lieu de construire honnêtement le NFA, nous ne «parallélisons» que la première étape des calculs.
Considérez ceci avec un exemple avec trois règles:
$_ ? $x : $x; explode("", ${"*"}); if ($_);
Si nous avons N éléments et M règles, avec une approche naïve nous avons N * M opérations à effectuer. En théorie, cette complexité peut être réduite à linéaire et obtenir O(N) - si vous combinez tous les modèles en un seul et effectuez la correspondance comme elle le fait, par exemple, le package regexp de Go.
Cependant, dans la pratique, je me suis jusqu'à présent concentré sur la mise en œuvre partielle de cette approche. Il permettra de répartir les règles du fichier ci-dessus en trois catégories, et aux éléments AST auxquels aucune règle ne correspond, d'attribuer une quatrième catégorie vide. Pour cette raison, pas plus d'une règle n'est exécutée pour chaque élément.
Si nous avons des milliers de règles et que nous ressentons un ralentissement significatif, l'algorithme sera finalisé. En attendant, la simplicité de la solution et l'accélération qui en résulte me conviennent.
La syntaxe actuelle duplique @var et @var , mais nous pouvons avoir besoin de nouveaux opérateurs, par exemple, "le type n'est pas égal". Imaginez à quoi cela pourrait ressembler.
Nous avons au moins deux priorités importantes:
- La syntaxe lisible et concise des annotations.
- Le soutien le plus élevé possible de l'IDE sans effort supplémentaire.
Pour PhpStorm, il existe un plugin php-annotations qui ajoute l'auto-complétion, la transition vers les classes d'annotation et d'autres utilités pour travailler avec des commentaires phpdoc.
La priorité (2) signifie en pratique que vous prenez des décisions qui ne contredisent pas les attentes de l'IDE et des plugins. Par exemple, vous pouvez faire des annotations dans un format que le plugin php-annotations peut reconnaître:
class Filter { public $value; public $type; public $text; }
Ensuite, appliquer un filtre aux types ressemblerait à ceci:
@Type($needle, eq=string) @Type($x, not_eq=Foo)
Les utilisateurs pourraient aller à la définition du Filter , une liste des paramètres possibles (type / texte / etc) serait demandée.
Méthodes d'enregistrement alternatives, dont certaines ont été suggérées par des collègues:
@type string $needle @type !Foo $x @type $needle == string @type $x != Foo @type(==) string $needle @type(!=) Foo $x @type($needle) == string @type($x) != Foo @filter type($needle) == string @filter type($x) != Foo
Ensuite, nous avons été un peu distraits et avons oublié que tout était à l'intérieur de phpdoc, et cela est apparu:
(eq string (typeof $needle)) (neq Foo (typeof $x))
Bien que l'option avec enregistrement postfix pour le plaisir ait également été émise. Un langage pour décrire les contraintes de type et de valeur pourrait être appelé sixième:
@eval string $needle typeof = @eval Foo $x typeof <>
La recherche de la meilleure option n'est pas encore terminée ...
Comparaison d'extensibilité avec Phan
Comme l'un des avantages de Phan , l'article " Analyse statique du code PHP en utilisant l'exemple de PHPStan, Phan et Psalm " indique l'extensibilité.
Voici ce qui a été implémenté dans l'exemple de plugin:
Nous voulions évaluer dans quelle mesure notre code est prêt pour PHP 7.3 (en particulier, pour savoir s'il a des constantes insensibles à la casse). Nous étions presque sûrs qu'il n'y avait pas de telles constantes, mais tout pouvait arriver en 12 ans - cela devrait être vérifié. Et nous avons écrit un plugin pour Phan qui jurerait si le troisième paramètre était utilisé dans define ().
Voici à quoi ressemble le code du plugin (le formatage est optimisé pour la largeur):
<?php use Phan\AST\ContextNode; use Phan\CodeBase; use Phan\Language\Context; use Phan\Language\Element\Func; use Phan\PluginV2; use Phan\PluginV2\AnalyzeFunctionCallCapability; use ast\Node; class DefineThirdParamTrue extends PluginV2 implements AnalyzeFunctionCallCapability { public function getAnalyzeFunctionCallClosures(CodeBase $code_base) { $def = function(CodeBase $cb, Context $ctx, Func $fn, $args) { if (count($args) < 3) { return; } $this->emitIssue( $cb, $ctx, 'PhanDefineCaseInsensitiv', 'define with 3 arguments', [] ); }; return ['define' => $def]; } } return new DefineThirdParamTrue();
Et voici comment cela pourrait être fait dans NoVerify:
<?php define($_, $_, $_);
Nous voulions obtenir à peu près le même résultat - afin que les choses triviales puissent être faites aussi simplement que possible.
Conclusion
Liens, documents utiles
Des liens importants sont rassemblés ici, dont certains ont peut-être déjà été mentionnés dans l'article, mais pour plus de clarté et de commodité, je les ai rassemblés en un seul endroit.
Si vous avez besoin de plus d'exemples de règles pouvant être implémentées, vous pouvez jeter un œil aux tests NoVerify .