Décodage du rapport «Mise en œuvre type du suivi» par Nikolay Sivko.
Je m'appelle Nikolai Sivko. Je fais aussi du monitoring. Okmeter est la surveillance que je fais. J'ai décidé que je sauverais tout le monde de l'enfer de la surveillance et nous sauverions quelqu'un de cette souffrance. J'essaie toujours de ne pas annoncer d'okmètre dans mes présentations. Naturellement, les photos seront de là. Mais l'idée de ce que je veux dire est que nous faisons de la surveillance une approche légèrement différente de ce que tout le monde fait habituellement. Nous en parlons beaucoup. Lorsque nous essayons de convaincre chaque individu en cela, il devient finalement convaincu. Je veux parler de notre approche précisément pour que si vous faites le suivi vous-même, pour éviter notre râteau.

À propos de l'Okmeter en bref. Nous faisons la même chose que vous, mais il y a toutes sortes de puces. Chips:
- détailler;
- un grand nombre de déclencheurs préconfigurés basés sur les problèmes de nos clients;
- Configuration automatique

Un client typique vient à nous. Il a deux tâches:
1) comprendre que tout est tombé en panne de surveillance, alors qu'il n'y a rien du tout.
2) le réparer rapidement.
Il vient surveiller les réponses de ce qui lui arrive.
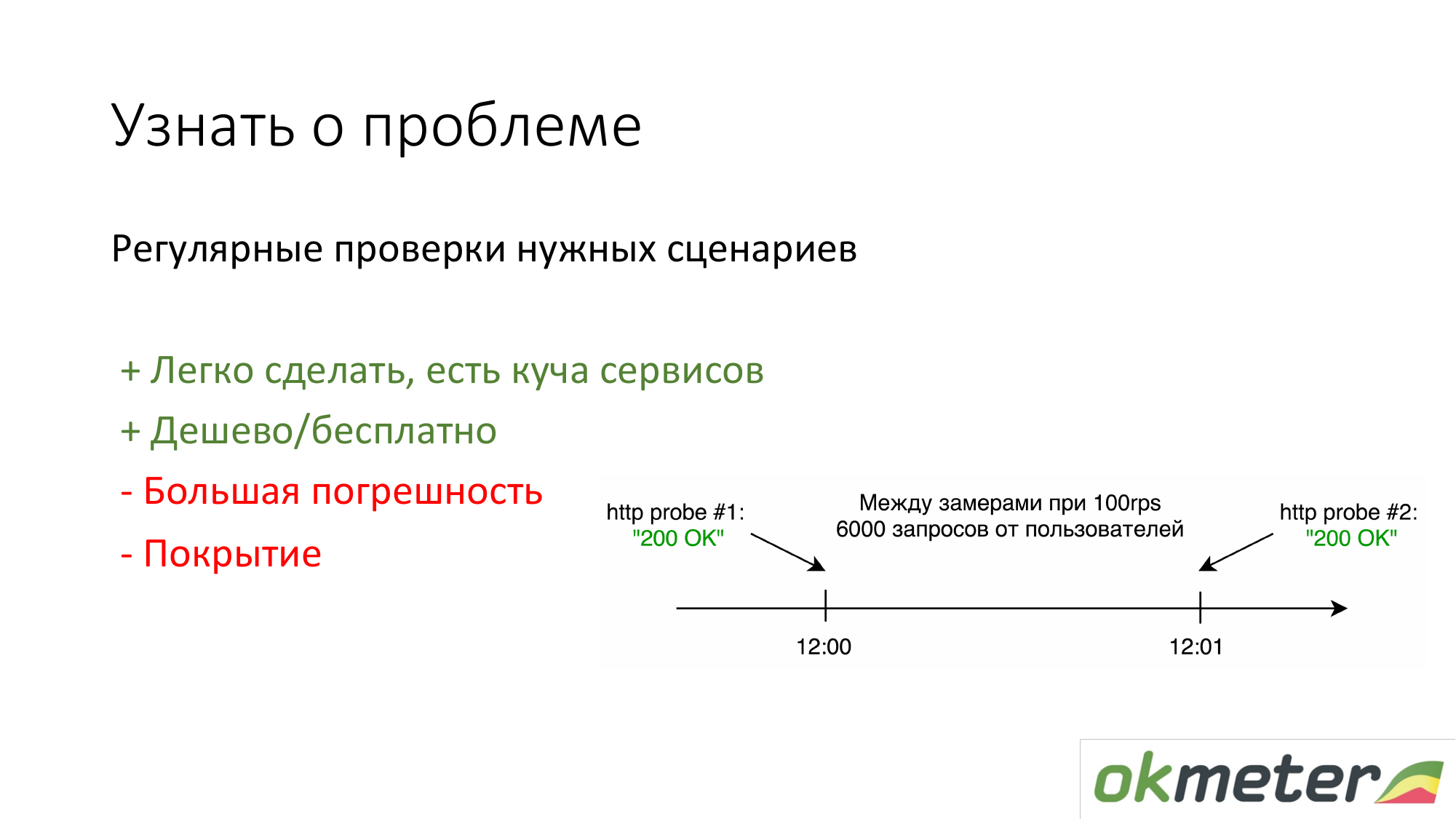
La première chose que font les gens qui n'ont rien est de mettre https://www.pingdom.com/ et d'autres services pour vérification. L'avantage de cette solution est qu'elle peut se faire en 5 minutes. Vous ne découvrirez plus le problème lors des appels des clients. Il y a des problèmes de précision pour qu'ils sautent les problèmes. Mais pour les sites simples, cela suffit.

La deuxième chose que nous préconisons est de compter par les logs selon les statistiques des utilisateurs réels. C'est combien un utilisateur particulier obtient des erreurs 5xx. Quel est le temps de réponse des utilisateurs. Il y a des inconvénients, mais en général, une telle chose fonctionne.

À propos de nginx: nous avons fait en sorte que tout client qui vient immédiatement place l'agent sur le frontend et que tout soit automatiquement capté par lui, il commence l'analyse, les erreurs commencent à apparaître, etc. Il n'a presque rien à configurer.

Mais la plupart des clients n'ont pas de temporisateur dans les journaux nginx standard. Ces 90% de clients ne souhaitent pas connaître le temps de réponse de leur site. Nous sommes constamment confrontés à cela. Il est nécessaire d'étendre le journal nginx. Ensuite, hors de la boîte, nous commençons automatiquement à afficher les histogrammes hors de la boîte. Il s'agit probablement d'un aspect important du fait que le temps doit être mesuré.

Que retirons-nous de là? Dans la pratique, nous prenons des mesures dans de telles dimensions. Ce ne sont pas des mesures plates. La métrique est appelée index.request.rate - le nombre de requêtes par seconde. Il est détaillé par:
- l'hôte duquel vous avez supprimé les journaux;
- le journal d'où ces données ont été extraites;
- http par méthode;
- statut http;
- état du cache.
Ce n'est PAS chaque URL spécifique avec tous les arguments. Nous ne voulons pas supprimer 100 000 mesures du journal.

Nous voulons prendre 1000 métriques. Par conséquent, nous essayons de normaliser l'URL, si possible. Prenez l'URL du haut. Et pour les URL significatives, nous montrons un graphique à barres séparé, séparément 5xx.

Voici un exemple de la façon dont cette métrique simple se transforme en graphiques utilisables. C'est notre DSL en haut. J'ai essayé cette DSL pour expliquer la logique approximative. Nous avons pris toutes les demandes de nginx par seconde et les avons disposées sur toutes les machines que nous avons. J'ai des connaissances sur la façon dont nous équilibrons, combien nous avons RPS total (demande par seconde, demandes par seconde).

D'un autre côté, nous pouvons filtrer cette métrique et afficher uniquement 4xx. Sur un graphique 4xx, ils peuvent être disposés en fonction de l'état réel. Je vous rappelle que c'est la même métrique.

Sur le graphique, vous pouvez afficher 4xx par URL. Il s'agit de la même mesure.

Nous tirons également un histogramme à partir des journaux. Un histogramme est la métrique response_time.histrogram, qui est en fait RPS avec un paramètre de niveau supplémentaire. Il s'agit simplement d'une coupure de temps dans laquelle le compartiment obtient la demande.
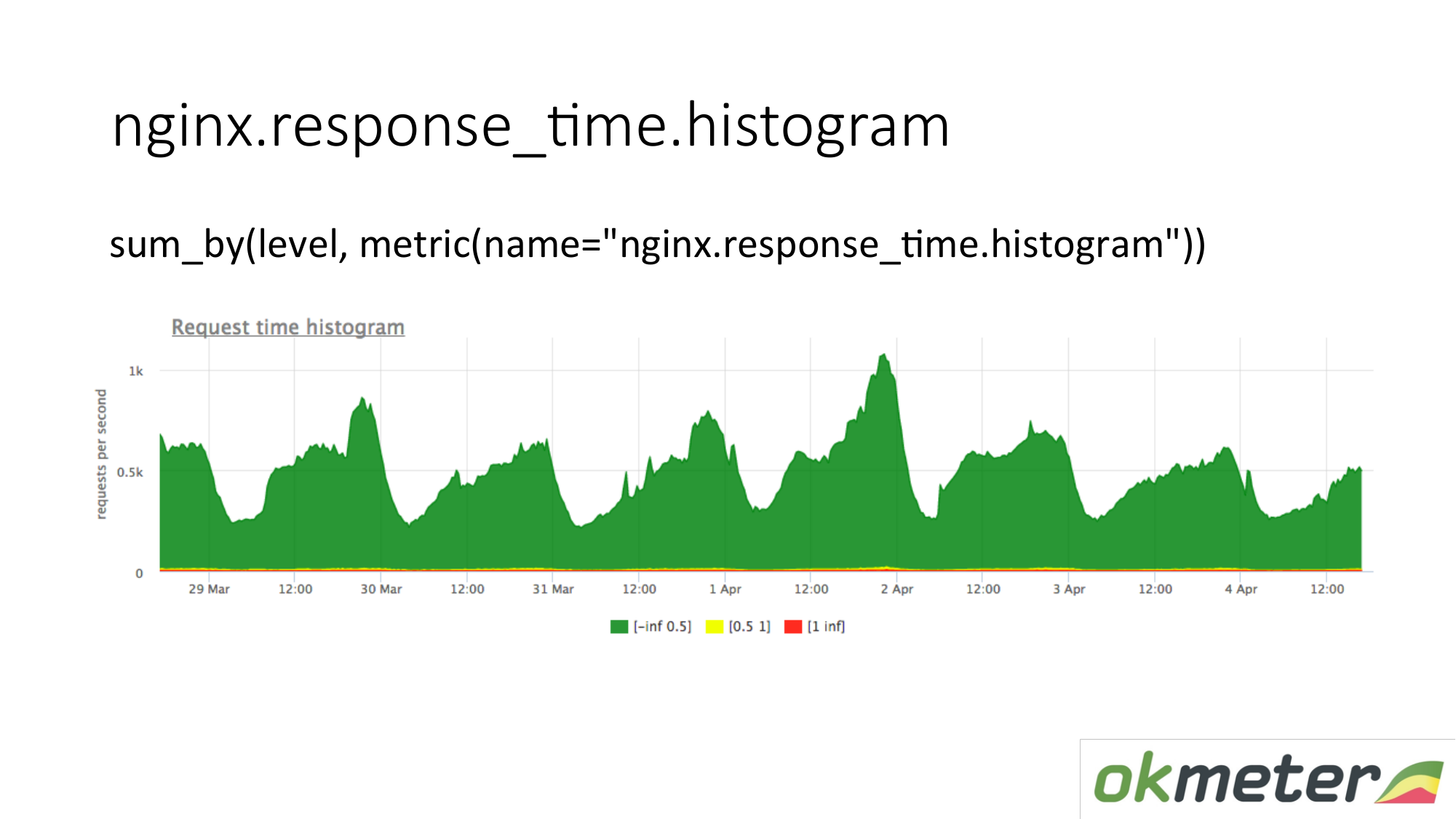
Nous dessinons une demande: résumons l'histogramme entier et le trions en niveaux:
- Demandes lentes
- demandes rapides;
- requêtes moyennes;
Nous avons une image qui a déjà été résumée par les serveurs. La métrique est la même. Sa signification physique est compréhensible. Mais nous en profitons de manières complètement différentes.
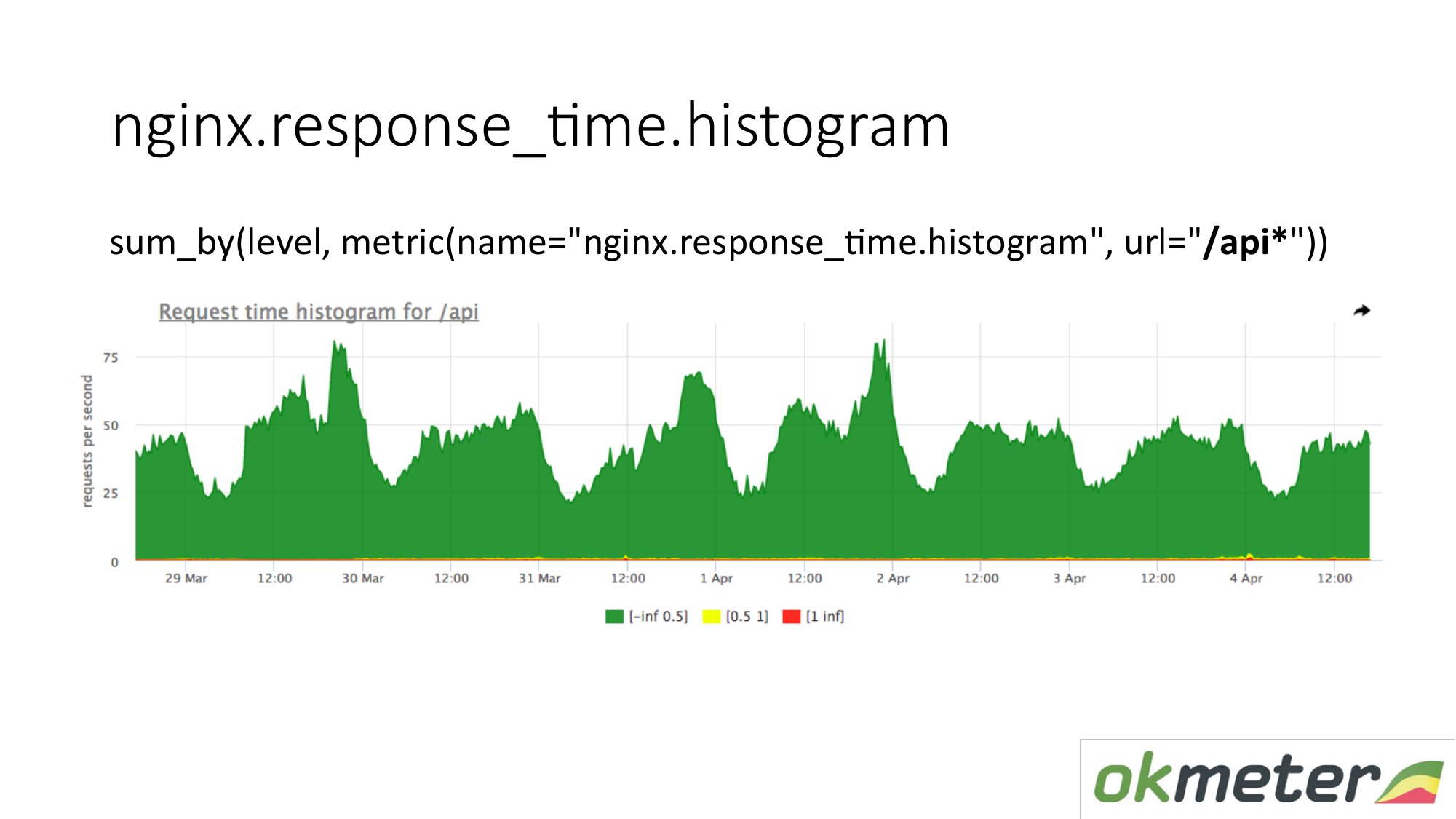
Sur le graphique, vous pouvez afficher l'histogramme uniquement par URL commençant par "/ api". Ainsi, nous regardons l'histogramme séparément. Nous regardons combien en ce moment. Nous voyons combien de RPS étaient dans l'URL "/ api". La même métrique, mais une application différente.

Quelques mots sur les timings dans nginx. Il y a request_time, qui inclut le temps entre le début de la demande et le transfert du dernier octet au socket au client. Et il y a upstream_response_time. Ils doivent être mesurés à la fois. Si nous supprimons simplement request_time, alors vous verrez des retards dus à des problèmes de connectivité client avec votre serveur, vous y verrez des retards si nous avons configuré la demande de limitation c burst et le client dans le bain. Vous ne comprendrez pas si vous devez réparer le serveur ou appeler l'hébergeur. En conséquence, nous supprimons les deux et il est à peu près clair ce qui se passe.

Avec la tâche de comprendre si le site fonctionne ou non, je pense que nous avons plus ou moins compris. Il y a des erreurs. Il y a des inexactitudes. Les principes généraux sont les suivants.
Maintenant sur la surveillance de l'architecture à plusieurs niveaux. Parce que même la boutique en ligne la plus simple a au moins une interface, suivie d'une bitrix et d'une base. C'est déjà beaucoup de liens. Le point général est que vous devez tirer quelques indicateurs de chaque niveau. Autrement dit, l'utilisateur pense à l'interface. Frontend pense au backend. Le backend pense au backend voisin. Et ils pensent tous à la base. Donc, par couches, par dépendances, on passe. Nous couvrons tout avec une sorte de métrique. Nous obtenons quelque chose à la sortie.

Pourquoi ne pas se limiter à une seule couche? En règle générale, entre les couches se trouve un réseau. Un grand réseau sous charge est une substance extrêmement instable. Par conséquent, tout se passe là-bas. De plus, ces mesures que vous faites sur quelle couche peut se trouver. Si vous prenez des mesures sur la couche «A» et la couche «B», et si elles interagissent entre elles via le réseau, vous pouvez comparer leurs lectures, trouver des anomalies et des incohérences.

À propos du backend. Nous voulons comprendre comment surveiller le backend. Que faire avec pour comprendre rapidement ce qui se passe. Je vous rappelle que nous sommes déjà passés à la tâche de minimiser les temps d'arrêt. Et à propos du backend, nous suggérons généralement de comprendre:
- Combien cette ressource mange-t-elle?
- Sommes-nous heurtés à une limite?
- Que se passe-t-il avec le runtime? Par exemple, la plate-forme d'exécution JVM, l'environnement d'exécution Golang et d'autres environnements d'exécution.
- Lorsque nous avons déjà couvert tout cela, il est intéressant pour nous déjà plus proche de notre code. Nous pouvons soit utiliser l'intrumétrie automatique (statsd, * -metric), qui nous montrera tout cela. Ou informez-vous en réglant des minuteries, des compteurs, etc.
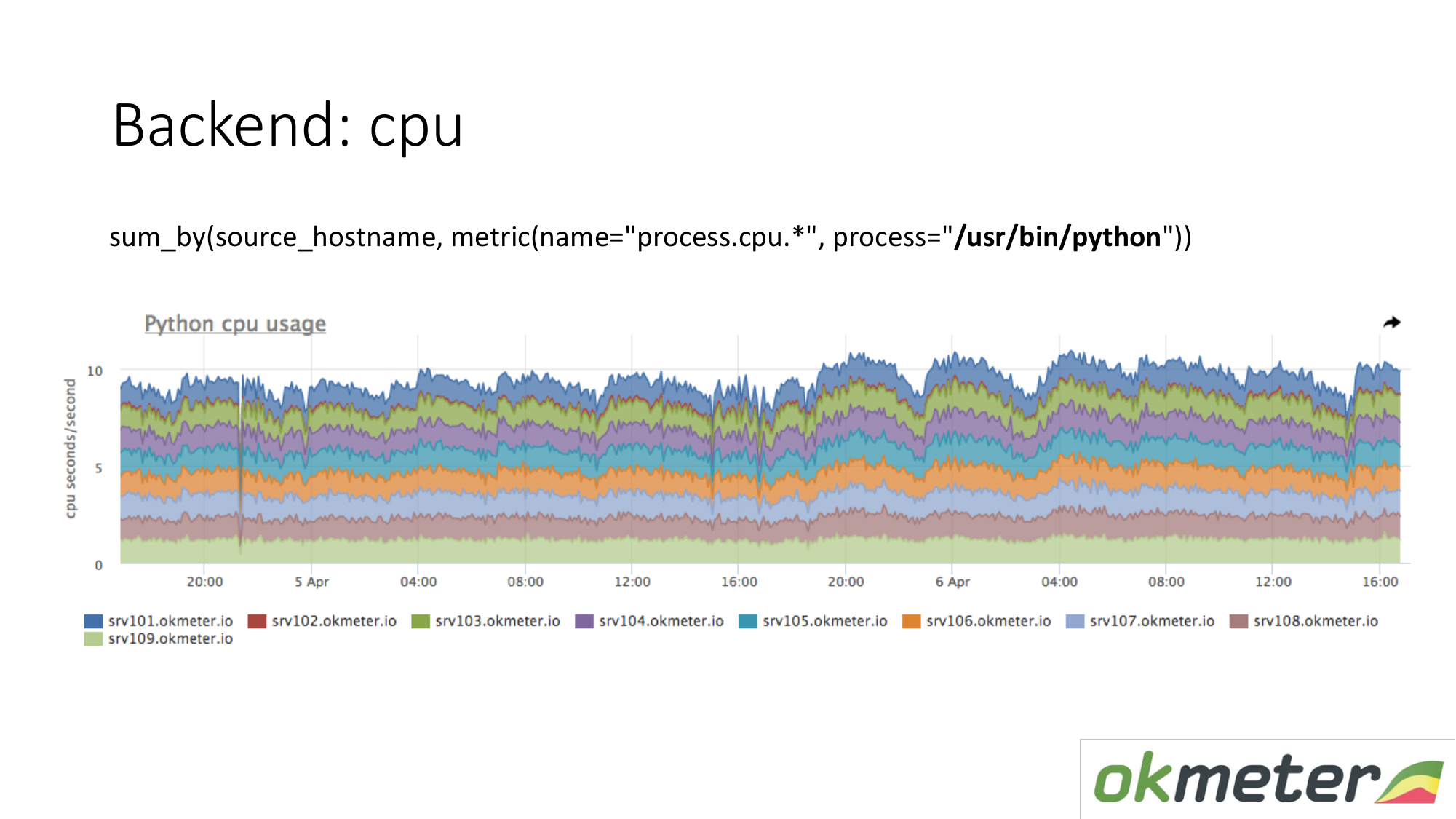
À propos des ressources. Notre agent standard supprime la consommation de ressources par tous les processus. Par conséquent, pour le backend, nous n'avons pas besoin de capturer séparément les données. Nous prenons et voyons combien le CPU consomme le processus, par exemple Python sur les serveurs masqués. Nous montrons tous les serveurs du cluster sur le même graphique, car nous voulons comprendre si nous avons des déséquilibres et si quelque chose a explosé sur la même machine. Nous voyons la consommation totale d'hier à aujourd'hui.
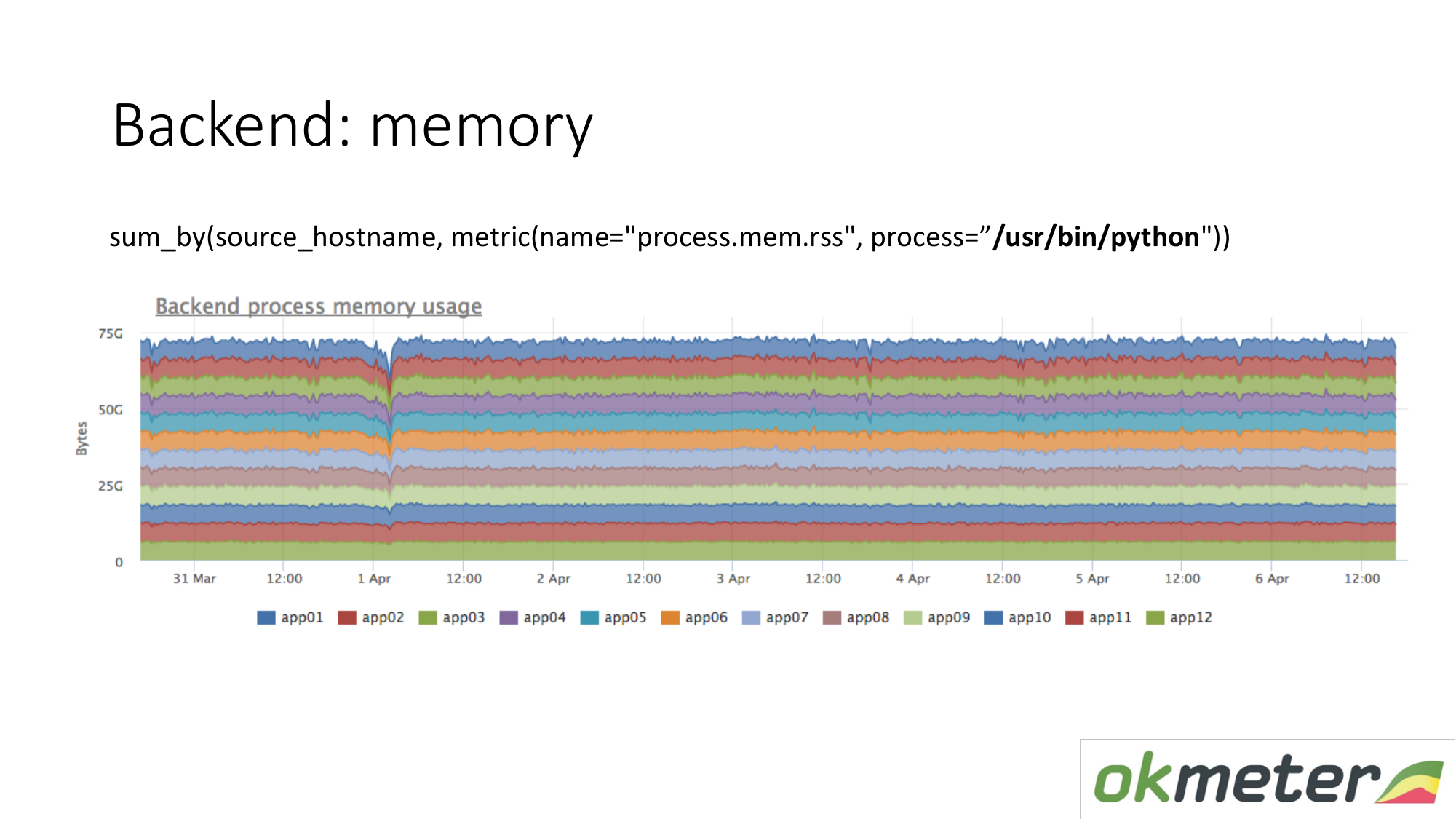
Il en va de même pour la mémoire. Quand on le dessine comme ça. Nous sélectionnons Python RSS (RSS est la taille des pages mémoire allouées au processus par le système d'exploitation et actuellement situées dans la RAM). Somme par hôte. Nous ne regardons nulle part où la mémoire coule. Partout la mémoire est répartie uniformément. En principe, nous avons reçu une réponse à nos questions.
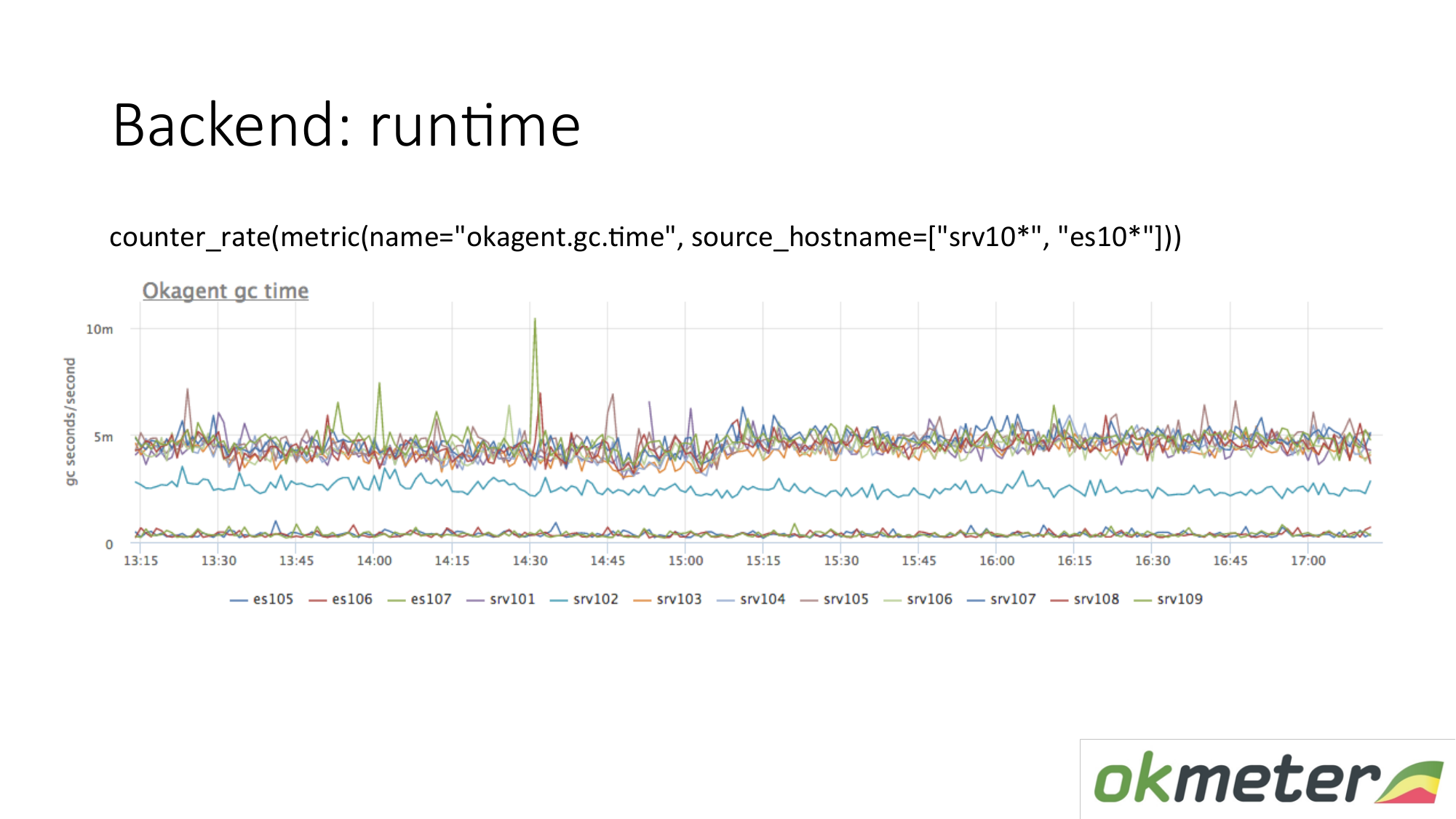
Exemple d'exécution. Notre agent est écrit à Golang. L'agent Golang s'envoie des métriques de son runtime. Il s'agit en particulier du nombre de secondes passées par le ramasse-miettes de Golang sur la collecte des ordures par seconde. Nous voyons ici que certains serveurs ont des métriques différentes des autres serveurs. Nous avons vu une anomalie. Nous essayons d'expliquer cela.
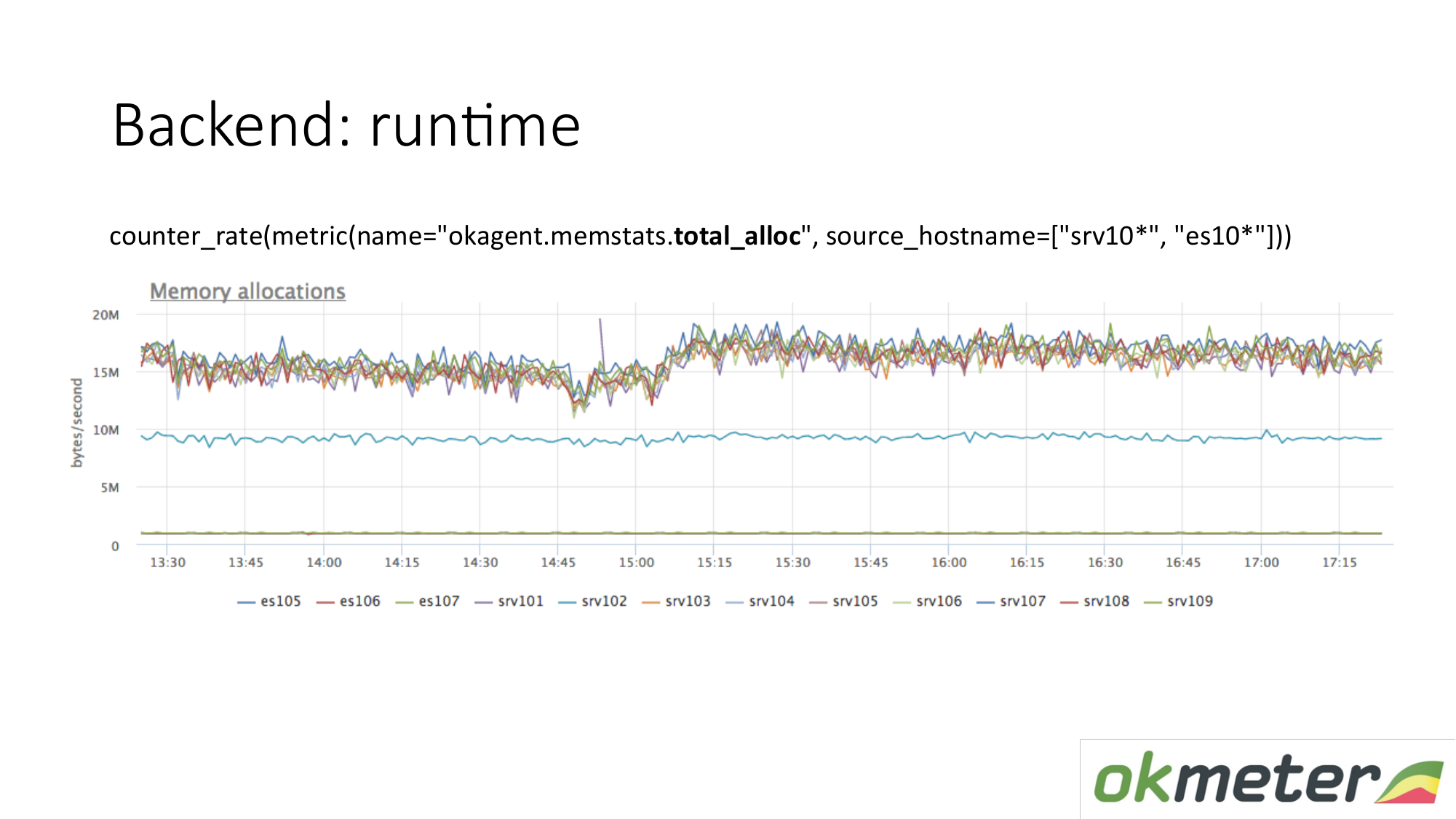
Il existe une autre mesure d'exécution. La quantité de mémoire allouée par unité de temps. Nous voyons que les agents de type supérieur allouent plus de mémoire que les agents inférieurs. Vous trouverez ci-dessous des agents avec un garbage collector moins agressif. C'est logique. Plus la mémoire qui vous traverse est allouée, libérée, plus la charge sur le garbage collector est importante. De plus, selon nos métriques internes, nous comprenons pourquoi nous voulons autant de mémoire sur ces machines et moins sur ces machines.
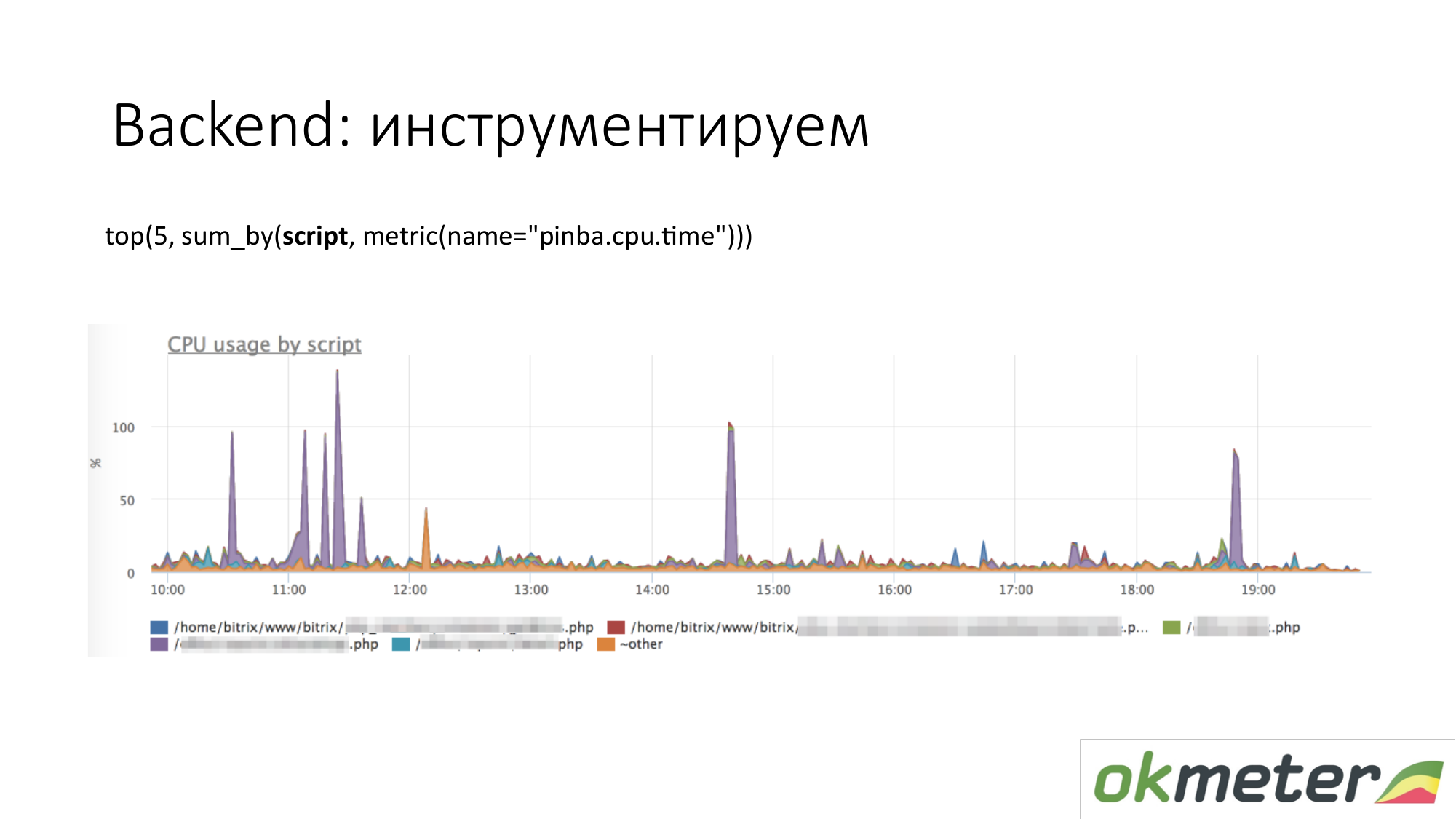
Quand on parle d'instrumentation, toutes sortes d'outils comme http://pinba.org/ pour php arrivent. Pinba est une extension pour php de Badoo, que vous installez et connectez-vous à php. Il vous permet de supprimer et d'envoyer immédiatement le protobuf via UDP. Ils ont un serveur pinba. Mais nous avons créé un serveur Pinba intégré dans l'agent. PHP s'envoie combien il a dépensé de CPU et de mémoire pour de tels scripts, combien de trafic est donné par ces scripts, etc. Voici un exemple avec Pinba. Nous montrons les 5 meilleurs scripts sur la consommation du processeur. Nous voyons une valeur violette aberrante qui est un point barbouillé de PHP. Nous allons réparer le point souillé de PHP ou comprendre pourquoi il mange le CPU. Nous avons déjà réduit la portée du problème afin de comprendre les étapes suivantes. Nous allons regarder le code et le réparer.

Il en va de même pour le trafic. Nous regardons les 5 meilleurs scripts de trafic. Si c'est important pour nous, alors nous allons comprendre.

Il s'agit d'un tableau sur nos outils internes. Lorsque nous avons réglé le minuteur via statsd et mesuré les métriques. Nous avons fait en sorte que le temps total passé dans le CPU ou en prévision d'une ressource soit défini selon le gestionnaire que nous traitons actuellement, et selon les étapes importantes de votre code: ils ont attendu la cassander, attendu elasticsearch. Le graphique présente les 5 premières étapes du gestionnaire / metric / query. Sur le graphique, vous pouvez afficher les 5 meilleurs gestionnaires pour la consommation du processeur, donc ce qui se passe à l'intérieur. Il est clair que corriger.
À propos du backend, vous pouvez aller plus loin. Il y a des choses qui font le traçage. Autrement dit, vous pouvez voir cette demande d'utilisateur particulière avec un cookie tel ou tel et une telle ou telle adresse IP générée tant de demandes à la base de données, ils ont attendu tellement de temps. Nous ne sommes pas en mesure de retracer. Nous ne traçons pas. Nous pouvons toujours croire que nous ne faisons pas d'applications ni de surveillance des performances.

À propos de la base de données. La même chose. Les bases de données sont le même processus. Il consomme des ressources. Si la base est très sensible à la latence, il existe des fonctionnalités légèrement différentes. Nous suggérons de vérifier qu'il n'y a pas moins de ressources, pas de dégradation des ressources. Il est idéal de comprendre que si la base commence à consommer plus qu'elle n'en consomme, alors comprenez exactement ce qui a changé dans votre code.
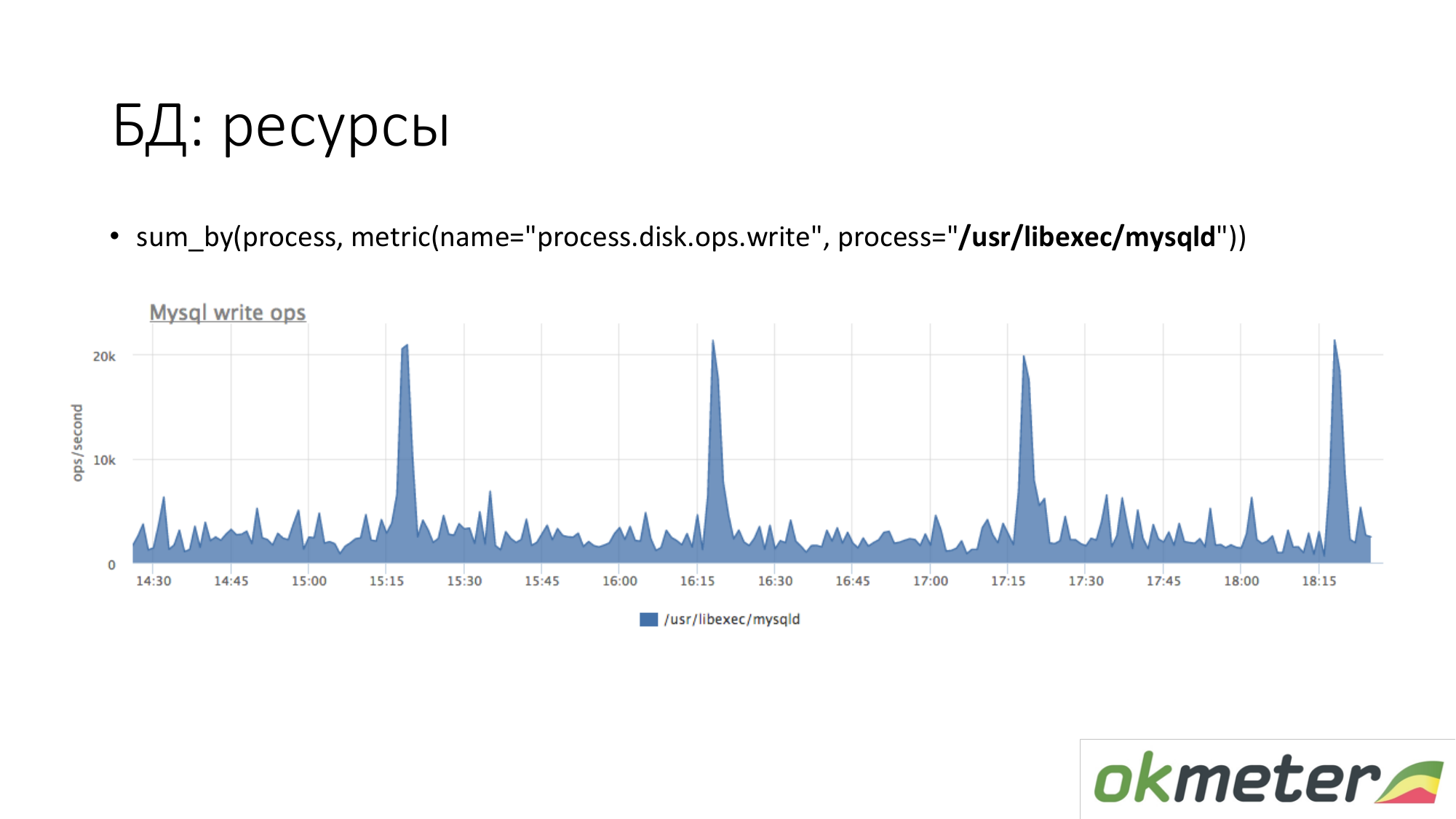
À propos des ressources. De la même manière, nous regardons combien le processus MySQL génère sur notre disque. On voit qu'en moyenne il y en a tellement, mais certains pics se produisent. Par exemple, beaucoup d'insert arrive et il commence à écrire sur le disque à 15h15, 16h15, 17h15.
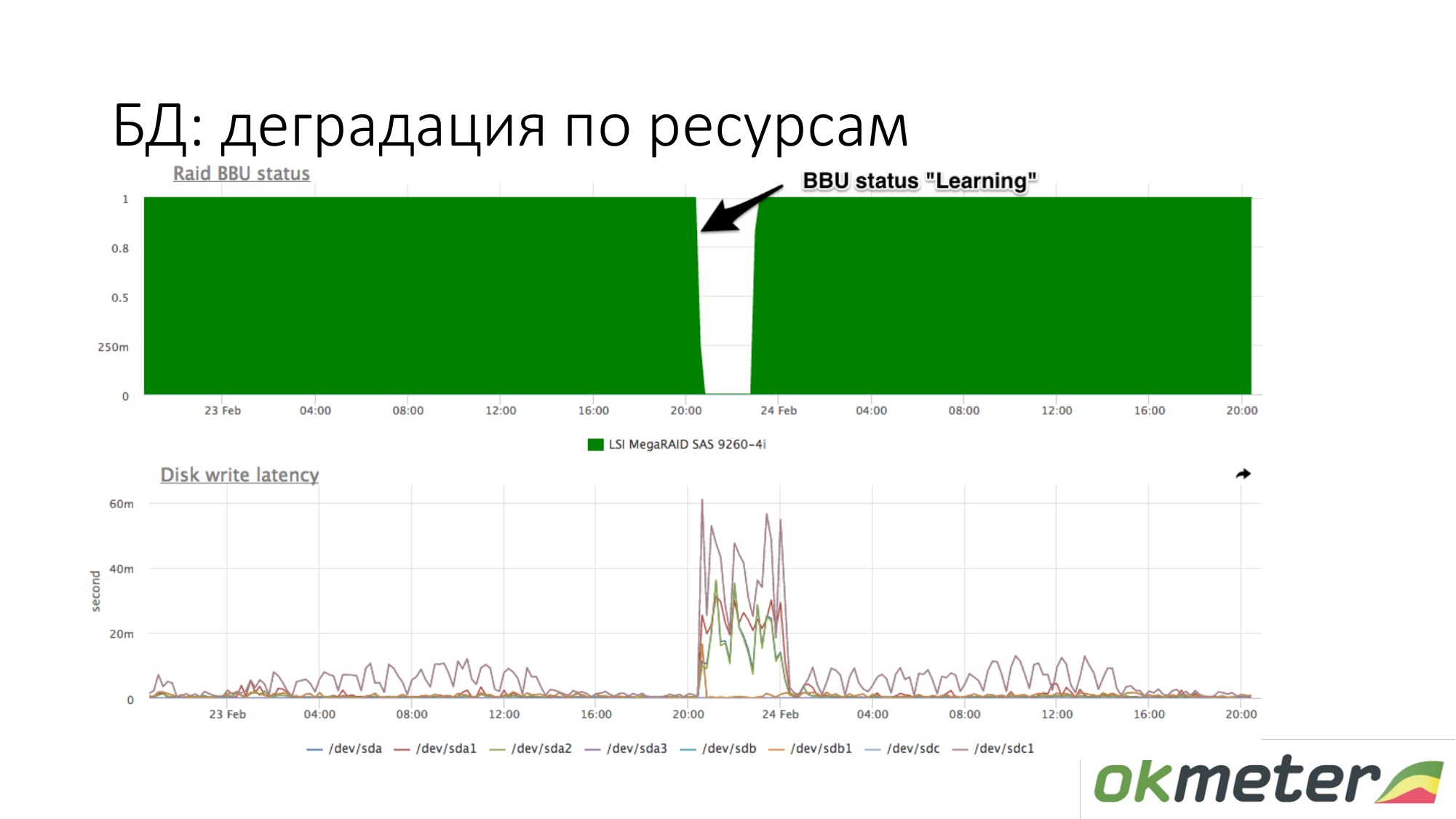
A propos de la dégradation des ressources. Par exemple, une batterie RAID est passée en mode maintenance. Elle a cessé d'être un contrôleur comme une batterie sous tension. À ce stade, le cache d'écriture est déconnecté, la latence des disques d'écriture augmente. À ce stade, si la base de données a commencé à s'émousser en attendant le disque et que vous savez approximativement qu'avec la même charge sur votre écriture, la latence du disque était différente, vérifiez la batterie en RAID.

Ressources à la demande. Ce n'est pas si simple ici. Dépend de la base. La base doit pouvoir parler d'elle-même: quelles demandes elle dépense en ressources, etc. Le leader dans ce domaine est PostgreSQL. Il a pg_stat_statements. Vous pouvez comprendre le type de demande que vous avez en utilisant beaucoup de CPU, de disque de lecture et d'écriture et de trafic.
Dans MySQL, pour être honnête, tout est bien pire. Il a performance_schema. Cela fonctionne en quelque sorte à partir de la version 5.7. Contrairement à une seule vue dans PostgreSQL, performance_schema est une table de vue système 27 ou 23 dans MySQL. Parfois, si vous faites des requêtes sur les mauvaises tables (sur la mauvaise vue), vous pouvez dilapider MySQL.
Redis a des statistiques sur l'équipe. Vous voyez qu'une certaine commande utilise beaucoup de CPU, etc.
Cassandra dispose de temps pour interroger des tables spécifiques. Mais comme la cassandra est conçue pour qu'un seul type de requête soit fait sur la table, cela suffit pour la surveillance.
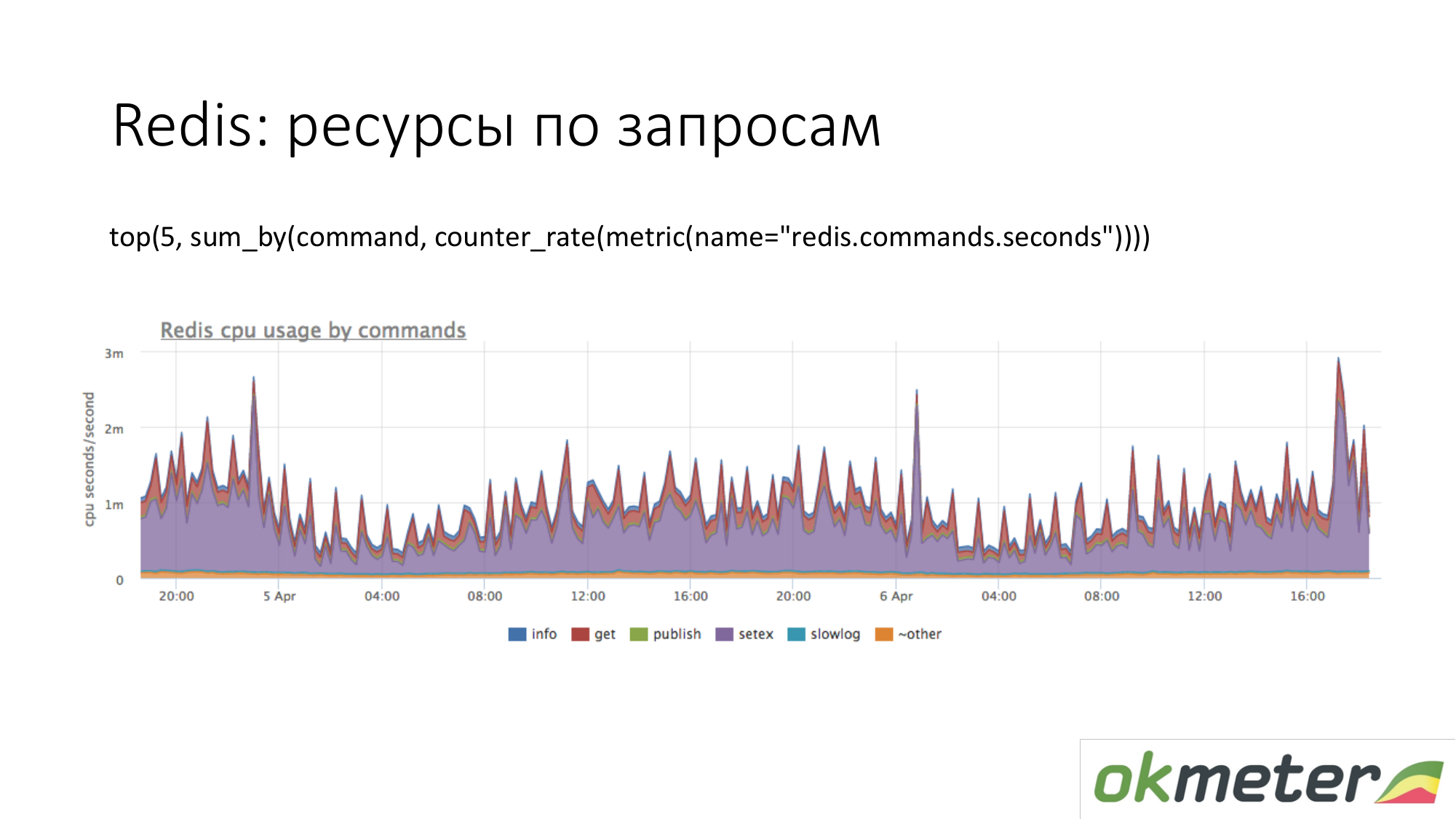
Voici Redis. Nous voyons que le violet utilise beaucoup de CPU. Le violet est un setex. Setex - enregistrement clé avec installation TTL. Si c'est important pour nous, allons-y. Si cela n'est pas important pour nous, nous savons simplement où vont toutes les ressources.
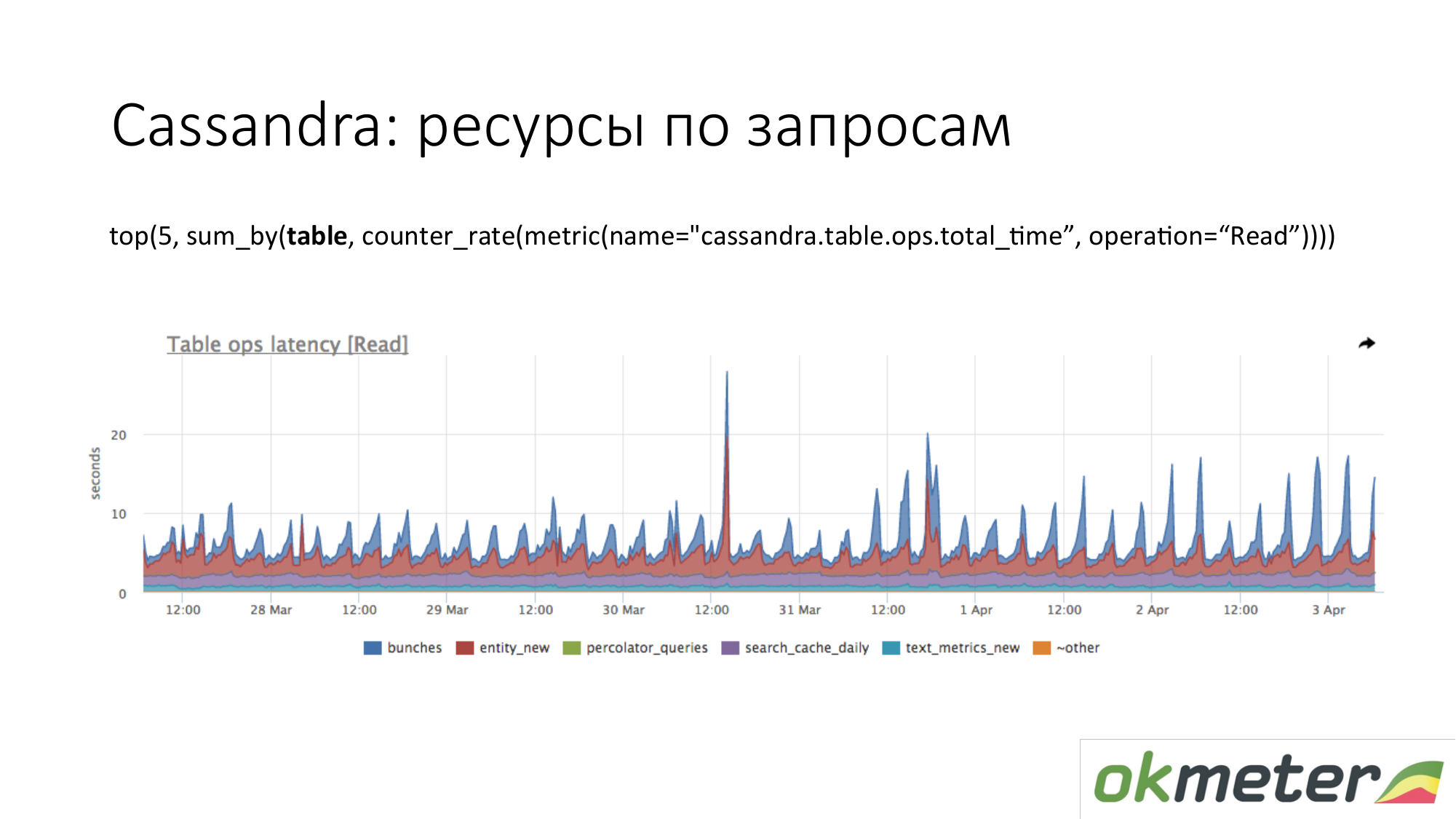
Cassandra. Nous voyons les 5 premiers tableaux pour les demandes de lecture par le temps de réponse total. Nous voyons cette montée subite. Ce sont des requêtes à la table, et nous comprenons à peu près qu'une requête à cette table fait un morceau de code. Cassandra n'est pas une base de données SQL dans laquelle nous pouvons effectuer différentes requêtes sur des tables. Cassandra est de plus en plus misérable.

Quelques mots sur le workflow avec les incidents. Comme je le vois.
À propos de l'alerte. Notre vision du flux de travail des incidents est différente de ce qui est généralement accepté.

Severy Critical. Nous vous informons par SMS et tous les canaux de communication en temps réel.
Severy Info est une ampoule qui peut vous aider avec quelque chose lorsque vous travaillez avec des incidents. L'information n'est notifiée nulle part. Info se bloque simplement et vous indique que quelque chose se passe.
Severy Warning est quelque chose qui peut être notifié, peut-être pas.

Exemples critiques.
Le site ne fonctionne pas du tout. Par exemple, 5xx 100% ou le temps de réponse a augmenté et les utilisateurs ont commencé à partir.
Erreurs de logique métier. Ce qui est critique. Il faut mesurer l'argent par seconde. L'argent par seconde est une bonne source de données pour Critical. Par exemple, le nombre de commandes, la promotion d'annonces et autres.

Workflow avec Critical de sorte que cet incident ne puisse pas être reporté. Vous ne pouvez pas cliquer sur OK et rentrer chez vous. Si Critical est venu vers vous et que vous prenez le métro, vous devez sortir du métro, sortir, prendre un banc et commencer à réparer. Sinon, ce n'est pas critique. À partir de ces considérations, nous construisons la gravité restante pour l'attribut résiduel.

Attention. Exemples d'avertissement.
- L'espace disque est épuisé.
- Le service interne fonctionne depuis longtemps, mais si vous n'avez pas Critical, cela signifie que vous êtes quand même conditionnel.
- Beaucoup d'erreurs sur l'interface réseau.
- Le plus controversé est que le serveur n'est pas disponible. En fait, si vous avez plusieurs serveurs et que le serveur n'est pas disponible, il s'agit d'un avertissement. Si vous n'avez pas 1 backend sur 100, alors c'est stupide de se réveiller des SMS et vous obtiendrez des administrateurs nerveux.
Tous les autres Severy sont conçus pour vous aider à gérer les critiques.

Attention. Nous préconisons cette approche pour travailler avec Warning. De préférence avertissement fermé pendant la journée. La plupart de nos clients ont désactivé la notification d'avertissement. Ainsi, ils ne disposent pas de la soi-disant surveillance de la cécité. Cela signifie plier des lettres dans le courrier sans lire un répertoire séparé. Les clients ont désactivé l'alerte d'avertissement.
(Si je comprends bien, la surveillance pure est des alertes et des déclencheurs inutiles ajoutés aux exceptions - note de l'auteur de l'article)
Si vous utilisez la technique de surveillance pure, si vous avez 5 nouveaux avertissements, vous pouvez les réparer en mode silencieux. Ils n’ont pas eu le temps de le réparer aujourd’hui, mais ils l’ont reporté à demain, sinon de manière critique. Si l'avertissement s'allume et s'éteint, cela doit être tordu dans la surveillance afin que vous ne vous dérangiez pas à nouveau. Ensuite, vous serez plus tolérant envers eux et, en conséquence, la vie s'améliorera.

Exemples d'informations. Il est discutable que l'utilisation élevée du processeur de nombreux Critical. En fait, si rien n'affecte, vous pouvez ignorer cette notification.

Attention (peut-être que je vois Info - une note de l'auteur du post) ce sont les lumières qui s'allument lorsque vous venez réparer le Critical. Vous voyez deux panneaux d'avertissement côte à côte (il y a peut-être un lien Info - note de l'auteur du message). Ils peuvent vous aider à résoudre l'incident avec Critical. Pourquoi il n'est pas clair sur l'utilisation élevée du processeur séparément dans SMS ou dans une lettre.
L'information inutile est également mauvaise. Si vous les configurez comme exception, vous allez trop aimer Info.

Principes généraux de conception des alertes. L'alerte doit indiquer la raison. C'est parfait. Mais cela est difficile à réaliser. Ici, nous travaillons à plein temps sur une tâche et elle se révèle avec un certain succès.
Tout le monde parle du besoin de dépendance, d'auto-magie. En fait, si vous ne recevez pas de notifications pour quelque chose qui ne vous intéresse pas, il n'y en aura pas trop. Dans ma pratique, les statistiques montrent qu'une personne regardera au moment d'un incident critique avec ses yeux une centaine d'ampoules en diagonale. Il trouvera la bonne là-bas et ne pensera pas que la dépendance a caché des ampoules qui pourraient m'aider maintenant. En pratique, cela fonctionne. Il vous suffit de nettoyer les alertes inutiles.

(Ici la vidéo sautée - note de l'auteur de l'article)

Ce serait bien de classer ces temps d'arrêt afin de pouvoir travailler avec eux plus tard. Par exemple, tirez des conclusions organisationnelles. Vous devez comprendre pourquoi vous mentiez. Nous proposons de classer / diviser dans les classes suivantes:
- créé par l'homme
- mise en place d'hébergeur
- est venu des bots
Si vous les classifiez, alors tout le monde sera content.

Le SMS est arrivé. On fait quoi? Nous courons d'abord pour tout réparer. Jusqu'à présent, rien n'est important pour nous, à l'exception du temps d'arrêt. Parce que nous sommes motivés à mentir moins. Ensuite, lorsque l'incident est clos, il doit être fermé au système de surveillance. Nous pensons que l'incident doit être contrôlé par surveillance. Si votre surveillance n'est pas configurée, il suffit de vous assurer que le problème est résolu. Cela doit être tordu. Une fois l'incident clos, il n'est pas réellement clos. Il attend pendant que vous arrivez au fond de la raison. En fait, tout dirigeant doit d’abord s’assurer que les problèmes ne se reproduisent pas. Pour que les problèmes ne se reproduisent pas, il faut aller au fond de la raison. Une fois que nous sommes arrivés au fond de la raison, nous avons des données pour les classer. Nous analysons les raisons. Ensuite, alors que nous arrivons au fond de la raison, nous devons le faire à l'avenir pour que l'incident ne se reproduise pas:
- il faut deux personnes par quart pour écrire telle ou telle logique dans le backend.
- besoin de mettre plus de répliques.
Il est nécessaire de s'assurer que le même incident ne se produit pas exactement. Lorsque vous travaillez dans un tel flux de travail à travers N itérations, le bonheur vous attend, une bonne disponibilité.
Pourquoi les avons-nous classés? Nous pouvons prendre les statistiques du trimestre et comprendre quel temps d'arrêt vous a le plus apporté. Travaillez ensuite dans cette direction. Vous pouvez travailler sur tous les fronts ne sera pas très efficace, surtout si vous avez peu de ressources là-bas.

Nous avons calculé que nous restions là pendant tellement de temps, par exemple 90% à cause de l'hébergeur. Nous facturons nous changeons cet hébergeur. Si les gens jouent avec nous, nous les envoyons aux cours. , - — . . , . , .

. :
, , . , , .

: , . : , , . False Positive ( ), , . ?
: . 10- frontend , . 9 frontend nginx, 10- , warning alert . . , . . .
: . , , load avarage 4 , - load avarage 20 .
: load avarage. 100 . CPU usage Hadoop . . . . , , . PostgreSQL autovacuum, worker autovacuum . 99 . Warning . Critical . Critical 10 5 , Critical.
Question: À quel moment et comment le seuil est-il déterminé? Qui fait ça?
Réponse: Vous venez chez nous et dites: nous voulons demander à certains critiques de notre projet. Si vous mettez 10 5xx par seconde maintenant, alors combien de notifications vous recevriez il y a une semaine.
Question: Quel est le poids de tout ce bon suivi?
Réponse: En moyenne, il est généralement invisible. Mais si vous analysez 50 000 RPS, ce sera de 1% à 10% d'un processeur. Comme nous ne faisons que du suivi, nous avons optimisé notre agent. Nous mesurons les performances des agents. Si vous n'avez pas les ressources à surveiller sur le serveur, vous faites quelque chose de mal. Il devrait toujours y avoir des ressources à surveiller. Si vous ne le faites pas, vous serez aussi aveugle au toucher pour administrer votre projet.