Examinons de plus près le sujet de la programmation orientée protocole. Pour plus de commodité, le matériel a été divisé en trois parties.
Ce matériel est une traduction commentée de la présentation de la WWDC 2016 . Contrairement à la croyance commune selon laquelle les choses «sous le capot» devraient rester là, il est parfois extrêmement utile de comprendre ce qui s'y passe. Cela vous aidera à utiliser l'élément correctement et à sa destination.
Cette partie abordera les problèmes clés de la programmation orientée objet et comment POP les résout. Tout sera pris en compte dans les réalités du langage Swift, les détails seront considérés comme "compartiment moteur" des protocoles.
Problèmes de POO et pourquoi avons-nous besoin de POP
Il est connu que dans la POO, il existe un certain nombre de faiblesses qui peuvent «surcharger» l'exécution du programme. Considérez le plus explicite et le plus courant:
- Allocation: pile ou tas?
- Comptage de références: plus ou moins?
- Répartition des méthodes: statique ou dynamique?
1.1 Attribution - pile
La pile est une structure de données assez simple et primitive. On peut mettre sur le dessus de la pile (push), on peut prendre du haut de la pile (pop). La simplicité est que c'est tout ce que nous pouvons faire avec.
Pour simplifier, supposons que chaque pile possède une variable (pointeur de pile). Il est utilisé pour suivre le haut de la pile et stocke un entier (Integer). Il en résulte que la vitesse des opérations avec la pile est égale à la vitesse de réécriture d'Integer dans cette variable.
Poussez - placez sur le dessus de la pile, augmentez le pointeur de la pile;
pop - réduire le pointeur de pile.
Types de valeur
Examinons les principes de l'opération de pile dans Swift en utilisant des structures (struct).
Dans Swift, les types de valeur sont des structures (struct) et des énumérations (enum), et les types de référence sont des classes (classe) et des fonctions / fermetures (func). Les types de valeur sont stockés sur la pile, les types de référence sont stockés sur le tas.
struct Point { var x, y: Double func draw() {...} } let point1 = Point(...)

- Nous plaçons la première structure sur Stack
- Copiez le contenu de la première structure
- Changer la mémoire de la seconde structure (la première reste intacte)
- Fin d'utilisation. Mémoire libre
1.2 Allocation - Tas
Le tas est une structure de données arborescente. Le sujet de l'implémentation du tas ne sera pas affecté ici, mais nous essaierons de le comparer avec la pile.
Pourquoi, si possible, vaut-il la peine d'utiliser Stack au lieu de Heap? Voici pourquoi:
- comptage de références
- administration gratuite de la mémoire et recherche d'allocation
- réécriture de la mémoire pour désallocation
Tout cela n'est qu'une petite partie de ce qui fait que Heap fonctionne et l'alourdit clairement par rapport à Stack.
Par exemple, lorsque nous avons besoin de mémoire libre sur la pile, nous prenons simplement la valeur du pointeur de pile et l'augmentons (car tout ce qui se trouve au-dessus du pointeur de pile dans la pile est de la mémoire libre) - O (1) est une opération constante dans le temps.
Lorsque nous avons besoin de mémoire libre sur Heap, nous commençons à la rechercher à l'aide de l'algorithme de recherche approprié dans la structure de l'arborescence de données - dans le meilleur des cas, nous avons une opération O (logn), qui n'est pas constante dans le temps et dépend d'implémentations spécifiques.
En fait, Heap est beaucoup plus compliqué: son travail est fourni par une multitude d'autres mécanismes qui vivent dans les entrailles des systèmes d'exploitation.
Il convient également de noter que l'utilisation de Heap en mode multithreading aggrave parfois la situation, car il est nécessaire d'assurer la synchronisation de la ressource partagée (mémoire) pour différents threads. Ceci est réalisé en utilisant des verrous (sémaphores, spinlocks, etc.).
Types de référence
Voyons comment Heap fonctionne dans Swift à l'aide de classes.
class Point { var x, y: Double func draw() {...} } let point1 = Point(...)
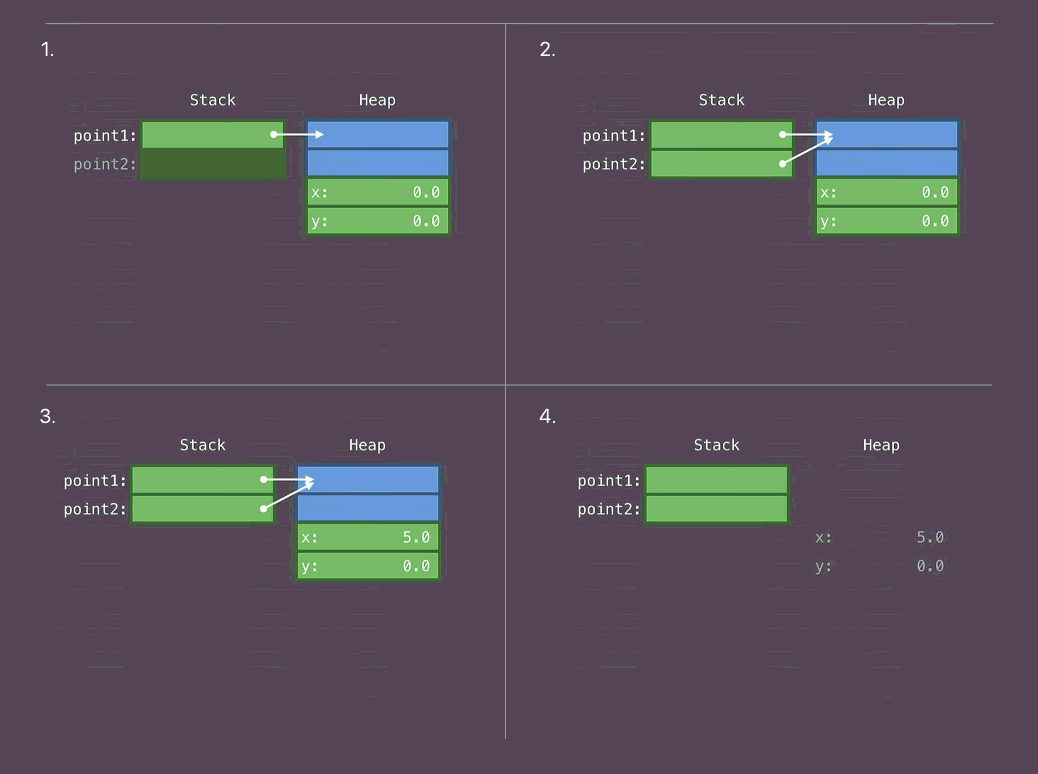
1. Placez le corps de classe sur Heap. Placez le pointeur sur ce corps sur la pile.
- Copiez le pointeur qui fait référence au corps de la classe
- On change le corps d'une classe
- Fin d'utilisation. Mémoire libre
1.3 L'allocation - un exemple petit et "réel"
Dans certaines situations, le choix de la pile simplifie non seulement la gestion de la mémoire, mais améliore également la qualité du code. Prenons un exemple:
enum Color { case red, green, blue } enum Orientation { case left, right } enum Tail { case none, tail, bubble } var cache: [String: UIImage] = [] func makeBalloon(_ color: Color, _ orientation: Orientation, _ tail: Tail) -> UIImage { let key = "\(color):\(orientation):\(tail)" if let image = cache[key] { return image } ... }
Si le dictionnaire de cache a une valeur avec la clé, la fonction retournera simplement le UIImage mis en cache.
Les problèmes de ce code sont:
Pas une bonne pratique consiste à utiliser String comme clé dans le cache, car à la fin, String "peut s'avérer être n'importe quoi".
La chaîne est une structure de copie sur écriture, pour implémenter son dynamisme, elle stocke tous ses caractères sur le tas. Ainsi, String est une structure et est stocké dans Stack, mais il stocke tout son contenu sur Heap.
Cela est nécessaire pour permettre de modifier la ligne (supprimer une partie de la ligne, ajouter une nouvelle ligne à cette ligne). Si tous les caractères de la chaîne étaient stockés sur la pile, de telles manipulations seraient impossibles. Par exemple, en C, les chaînes sont statiques, ce qui signifie que la taille d'une chaîne ne peut pas être augmentée lors de l'exécution car tout le contenu est stocké sur la pile. Pour une copie sur écriture et une analyse plus détaillée des lignes dans Swift, veuillez cliquer ici .
Solution:
Utilisez la structure assez évidente ici au lieu de la chaîne:
struct Attributes: Hashable { var color: Color var orientation: Orientation var tail: Tail }
Changez le dictionnaire en:
var cache: [Attributes: UIImage] = []
Débarrassez-vous de String
let key = Attributes(color: color, orientation: orientation, tail: tail)
Dans la structure Attributes, toutes les propriétés sont stockées sur la pile, car l'énumération est stockée sur la pile. Cela signifie qu'il n'y a pas d'utilisation implicite de Heap ici, et maintenant les clés du dictionnaire de cache sont définies très précisément, ce qui a augmenté la sécurité et la clarté de ce code. Nous nous sommes également débarrassés de l'utilisation implicite de Heap.
Verdict: Stack est beaucoup plus facile et plus rapide que Heap - le choix pour la plupart des situations est évident.
2. Comptage des références
Pour quoi?
Swift doit savoir quand il est possible de libérer un morceau de mémoire sur Heap, occupé, par exemple, par une instance d'une classe ou d'une fonction. Ceci est implémenté via un mécanisme de comptage de liens - chaque instance (classe ou fonction) hébergée sur Heap a une variable qui stocke le nombre de liens vers elle. Lorsqu'il n'y a pas de lien vers une instance, Swift décide de libérer un morceau de mémoire qui lui est alloué.
Il convient de noter que pour une mise en œuvre «de haute qualité» de ce mécanisme, il faut beaucoup plus de ressources que pour augmenter et diminuer le pointeur de pile. Cela est dû au fait que la valeur du nombre de liens peut augmenter à partir de différents threads (car vous pouvez faire référence à une classe ou une fonction à partir de différents threads). N'oubliez pas non plus la nécessité d'assurer la synchronisation d'une ressource partagée (nombre variable de liens) pour différents threads (spinlocks, sémaphores, etc.).
Pile: recherche de mémoire libre et libération de mémoire utilisée - opération de pointeur de pile
Heap: recherche de mémoire libre et libération de mémoire utilisée - algorithme de recherche d'arbre et comptage de références.
Dans la structure Attributes, toutes les propriétés sont stockées sur la pile, car l'énumération est stockée sur la pile. Cela signifie qu'il n'y a pas d'utilisation implicite de Heap ici, et maintenant les clés du dictionnaire de cache sont définies très précisément, ce qui a augmenté la sécurité et la clarté de ce code. Nous nous sommes également débarrassés de l'utilisation implicite de Heap.
Pseudo code
Considérez un petit morceau de pseudocode pour montrer comment fonctionne le comptage de liens:
class Point { var refCount: Int var x, y: Double func draw() {...} init(...) { ... self.refCount = 1 } } let point1 = Point(x: 0, y: 0) let point2 = point1 retain(point2)
Struct
Lorsque vous travaillez avec des structures, un mécanisme tel que le comptage de références n'est tout simplement pas nécessaire:
- structure non stockée sur le tas
- struct - copié lors de l'affectation, donc pas de références
Copier les liens
Encore une fois, la structure et tout autre type de valeur dans Swift sont copiés lors de l'affectation. Si la structure stocke des liens en elle-même, ils seront également copiés:
struct Label { let text: String let font: UIFont ... init() { ... text.refCount = 1 font.refCount = 1 } } let label = Label(text: "Hi", font: font) let label2 = label retain(label2.text._storage)
label et label2 partagent des instances communes hébergées sur le tas:
Ainsi, si la structure stocke des liens en elle-même, alors lors de la copie de cette structure, le nombre de liens double, ce qui, si ce n'est pas nécessaire, affecte négativement la "facilité" du programme.
Et encore le "vrai" exemple:
struct Attachment { let fileUrl: URL
Les problèmes de cette structure sont qu'elle a:
- 3 Allocation de tas
- La chaîne pouvant être n'importe quelle chaîne, la sécurité et la clarté du code sont affectées.
En même temps, uuid et mimeType sont des choses strictement définies:
uuid est une chaîne de format xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
mimeType est une chaîne de format de type / extension.
Solution
let uuid: UUID
Dans le cas de mimeType, l'énumération fonctionne correctement:
enum MimeType { init?(rawValue: String) { switch rawValue { case "image/jpeg": self = .jpeg case "image/png": self = .png case "image/gif": self = .gif default: return nil } } case jpeg, png, gif }
Ou mieux et plus facilement:
enum MimeType: String { case jpeg = "image/jpeg" case png = "image/png" case gif = "image/gif" }
Et n'oubliez pas de changer:
let mimeType: MimeType
3.1 Envoi de la méthode
- ceci est un algorithme qui recherche le code de méthode qui a été appelé
Avant de parler de la mise en œuvre de ce mécanisme, il convient de déterminer ce qu'est un «message» et une «méthode» dans ce contexte:
- un message est le nom que nous envoyons à l'objet. Les arguments peuvent toujours être envoyés avec le nom.
circle.draw(in: origin)
Le message est draw - le nom de la méthode. L'objet récepteur est un cercle. L'origine est également un argument passé.
- est le code qui sera renvoyé en réponse au message.
Ensuite, Method Dispatch est un algorithme qui décide de la méthode à attribuer à un message particulier.
Plus précisément sur la répartition des méthodes dans Swift
Comme nous pouvons hériter de la classe parente et remplacer ses méthodes, Swift doit savoir exactement quelle implémentation de cette méthode doit être appelée dans une situation spécifique.
class Parent { func me() { print("parent") } } class Child: Parent { override func me() { print("child") } }
Créez quelques instances et appelez la méthode me:
let parent = Parent() let child = Child() parent.me()
Un exemple assez évident et simple. Et si:
let array: [Parent] = [Child(), Child(), Parent(), Child()] array.forEach { $0.me()
Ce n'est pas si évident et nécessite des ressources et un certain mécanisme pour déterminer la mise en œuvre correcte de la méthode me. Les ressources sont le processeur et la RAM. Un mécanisme est une méthode de répartition.
En d'autres termes, Method Dispatch est la façon dont le programme détermine quelle implémentation de méthode appeler.
Lorsqu'une méthode est appelée dans le code, son implémentation doit être connue. Si elle est connue pour
Au moment de la compilation, il s'agit de Static Dispatch. Si l'implémentation est déterminée immédiatement avant l'appel (lors de l'exécution, au moment de l'exécution du code), il s'agit de Dynamic Dispatch.
3.2 Répartition des méthodes - Répartition statique
Le plus optimal, car:
- Le compilateur sait quel bloc de code (implémentation de méthode) sera appelé. Grâce à cela, il peut optimiser autant que possible ce code et recourir à un tel mécanisme comme l'inline.
- De plus, au moment de l'exécution du code, le programme exécutera simplement ce bloc de code connu du compilateur. Aucune ressource et aucun temps ne seront consacrés à la détermination de la mise en œuvre correcte de la méthode, ce qui accélérera l'exécution du programme.
3.3 Répartition des méthodes - Répartition dynamique
Pas le plus optimal, car:
- La mise en œuvre correcte de la méthode sera déterminée au moment de l'exécution du programme, ce qui nécessite des ressources et du temps
- Aucune optimisation du compilateur n'est hors de question
3.4 Répartition des méthodes - Inline
Un mécanisme tel que l'inline a été mentionné, mais quel est-il? Prenons un exemple:
struct Point { var x, y: Double func draw() {
- La méthode point.draw () et la fonction drawAPoint seront traitées via Static Dispatch, car il n'y a aucune difficulté à déterminer l'implémentation correcte du compilateur (car il n'y a pas d'héritage et la redéfinition est impossible)
- puisque le compilateur sait ce qui sera fait, il peut l'optimiser. Optimise d'abord drawAPoint, en remplaçant simplement l'appel de fonction par son code:
let point = Point(x: 0, y: 0) point.draw()
- optimise ensuite point.draw, car l'implémentation de cette méthode est également connue:
let point = Point(x: 0, y: 0)
Nous avons créé un point, exécuté le code de la méthode draw - le compilateur a simplement substitué le code nécessaire à ces fonctions au lieu de les appeler. Dans Dynamic Dispatch, ce sera un peu plus compliqué.
3.5 Répartition des méthodes - Polymorphisme basé sur l'hérédité
Pourquoi ai-je besoin de Dynamic Dispatch? Sans cela, il est impossible de définir des méthodes remplacées par des classes enfants. Le polymorphisme ne serait pas possible. Prenons un exemple:
class Drawable { func draw() {} } class Point: Drawable { var x, y: Double override func draw() { ... } } class Line: Drawable { var x1, y1, x2, y2: Double override func draw() { ... } } var drawables: [Drawable] for d in drawables { d.draw() }
- le tableau drawables peut contenir des points et des lignes
- intuitivement, Static Dispatch n'est pas possible ici. d dans la boucle for peut être Line, ou peut-être Point. Le compilateur ne peut pas déterminer cela, et chaque type a sa propre implémentation de draw
Comment fonctionne Dynamic Dispatch? Chaque objet a un champ type. Donc Point (...). Type sera égal à Point, et Line (...). Type sera égal à Line. Quelque part dans la mémoire (statique) du programme se trouve une table (table virtuelle), où pour chaque type il y a une liste avec ses implémentations de méthode.
Dans Objective-C, le champ type est appelé champ isa. Il est présent sur chaque objet Objective-C (NSObject).
La méthode de classe est stockée dans virtual-table et n'a aucune idée de soi. Pour pouvoir utiliser self dans cette méthode, il doit y être transmis (self).
Ainsi, le compilateur changera ce code en:
class Point: Drawable { ... override func draw(_ self: Point) { ... } } class Line: Drawable { ... override func draw(_ self: Line) { ... } } var drawables: [Drawable] for d in drawables { vtable[d.type].draw(d) }
Au moment de l'exécution du code, vous devez regarder dans la table virtuelle, y trouver la classe d, prendre la méthode draw dans la liste résultante et lui passer un objet de type d comme self. C'est un travail décent pour une invocation de méthode simple, mais il est nécessaire de s'assurer que le polymorphisme fonctionne. Des mécanismes similaires sont utilisés dans n'importe quel langage de POO.
Répartition des méthodes - Résumé
- les méthodes de classe sont traitées par défaut via Dynamic Dispatch. Mais toutes les méthodes de classe ne doivent pas être gérées via Dynamic Dispatch. Si la méthode n'est pas remplacée, vous pouvez l'intituler avec le mot-clé final, puis le compilateur saura que cette méthode ne peut pas être remplacée et il la traitera via Static Dispatch
- les méthodes non-classe ne peuvent pas être remplacées (puisque struct et enum ne prennent pas en charge l'héritage) et sont traitées via Static Dispatch
Problèmes de POO - Résumé
Il est nécessaire de prêter attention aux bagatelles telles que:
- Lors de la création d'une instance: où sera-t-elle située?
- Lorsque vous travaillez avec cette instance: comment fonctionnera le comptage de liens?
- Lors de l'appel d'une méthode: comment sera-t-elle traitée?
Si nous payons pour le dynamisme sans le réaliser et sans en avoir besoin, cela affectera négativement le programme mis en œuvre.
Le polymorphisme est une chose très importante et utile. Pour le moment, tout ce que l'on sait, c'est que le polymorphisme dans Swift est directement lié aux classes et aux types de référence. À notre tour, nous disons que les classes sont lentes et lourdes, et que la structure est simple et facile. Le polymorphisme est-il réalisé à travers des structures? La programmation orientée protocole peut apporter une réponse à cette question.