La topologie des centres de données modernes et des appareils qui s'y
trouvent ne nous permet plus de nous contenter exclusivement de la
surveillance de la boîte blanche . Au fil du temps, j'avais besoin d'un outil qui montrera les performances de périphériques spécifiques, en fonction de la situation réelle avec le transfert de trafic (dataplane) n'importe où dans le
réseau Clos . Il y a quelques semaines, lors de la conférence
Next Hop , l'ingénieur réseau Yandex Alexander Klimenko a partagé son expérience dans la résolution de ce problème.
- Je travaille dans le département d'exploitation et de développement du réseau Yandex, et parfois je suis obligé de résoudre certains problèmes, au lieu de dessiner de beaux nuages sur les feuilles ou d'inventer un avenir radieux. Les gens viennent et disent que quelque chose ne fonctionne pas pour eux. Si cette question est surveillée, si nos ingénieurs de service constatent que cela ne fonctionne pas, cela me sera plus facile. Ces 30 minutes seront donc consacrées au monitoring.

Tôt ou tard, tout le monde vient à l'idée de surveiller. Autrement dit, au début, vous pouvez collecter les appels des utilisateurs eux-mêmes, ils vont vous frapper et dire que quelque chose ne fonctionne pas pour eux. Mais il est clair qu'un tel système n'est pas très évolutif. Si vous avez plus d'un commutateur, si vous avez un réseau suffisamment grand, alors avec cette option de surveillance, vous ne pouvez pas aller loin.
Et tôt ou tard, tous parviennent à la conclusion qu'il est nécessaire de collecter certaines données de l'équipement. Ceci est la toute première étape. Il peut s'agir de journaux, de diverses données sur SNMP, de gouttes, vous pouvez créer des topologies selon LLDP, etc. Il y a un inconvénient clair - le périphérique lui-même vous fournit toutes ces informations. Cela peut ne rien dire, vous tromper, etc.
L'étape logique du développement de votre surveillance est la surveillance sur les hôtes. On peut dire qu'il y a une petite branche. Si vous avez la chance - ou pas la chance - d'avoir un réseau sur un seul fournisseur, le fournisseur peut vous proposer certaines de vos propres options de surveillance. Mais l'année dernière à Next Hop, Dima Ershov a
déclaré que notre usine avait été créée à partir de deux fournisseurs de base et que nous ne pouvions pas nous permettre un tel luxe. Ou nous pouvons, mais seulement partiellement.
Enfin, la dernière option, que tout le monde atteint en quelque sorte avec le développement du réseau. Il s'agit de la surveillance des hôtes finaux. Yandex a une telle surveillance. Cela s'appelle Netmon.

Au bas de la diapositive,
il y a un lien avec une présentation détaillée sur le fonctionnement de Netmon. Je vais dire littéralement dans une diapositive. Si quelqu'un le souhaite, veuillez lire le discours d'une autre conférence Netmon.
Netmon sont des agents installés sur presque tous les hôtes du réseau. La tâche arrive aux agents: envoyer des paquets à un nœud de réseau. Ils peuvent être complètement différents: UDP, TCP, ICMP. Il peut s'agir de différentes peintures, c'est-à-dire DSCP et destination. Les ports source et de destination peuvent également être différents.
Ces données sont agrégées, téléchargées sur un stockage séparé, et nous obtenons ici une tranche comme celle de droite sur la figure. Une tranche peut être plus agrégée ou moins agrégée, selon ce que nous voulons voir. Par exemple, ici, pour autant que je sache, nous avons une tranche de toute la connectivité des centres de données, c'est-à-dire entre tous nos centres de données. Nous pouvons tomber plus profondément dans les carrés - voir la connectivité entre le POD ou à l'intérieur du bâtiment d'un centre de données; encore plus profondément - à l'intérieur du POD entre les racks; et encore plus profond - même dans le rack.

Qu'est-ce qui pourrait mal tourner ici? Une petite parenthèse pour ceux qui n'ont pas regardé le Next Hop de l'année dernière.
Nous avons utilisé 400 gigabits par ToR, et au premier moment de la mise en œuvre de cette usine, nous n'en avions inclus que 200, car il y avait des tâches plus importantes. Peu importe pourquoi. Ils ont allumé 200, les services sont venus et ont dit: pourquoi 200? Nous en voulons 400! Commencé à l'allumer. Et il se trouve que la deuxième partie de l'usine, que nous avons incluse, a eu une sorte de mariage dans la mémoire des cartes. En conséquence, nous allumons l'usine et voyons cette image:

Ce Netmon, les carrés rouges, est en feu. Nous comprenons que tout est perdu. Nous agrippons nos têtes, comme Homère, et essayons de pousser quelque chose frénétiquement. Et sur quoi appuyer, quoi éteindre, on ne comprend pas. Autrement dit, Netmon nous montre la présence d'un problème, mais ne montre pas où, en fait, le problème se trouve sur le réseau.

Nous sommes arrivés à la tâche que nous devons accomplir. Que faut-il faire? Déterminez avec quel appareil du réseau il y a un problème et mettez-le hors service, soit automatiquement, soit par la force, par exemple, des ingénieurs en service.
De plus, les conditions initiales sont telles que nous avons une topologie assez régulière, c'est-à-dire qu'il n'y a pas de liens étranges entre les spins de second niveau ou entre les tores. Nous avons la majeure partie du trafic - TCP, il y a une place centrale, on nous en a déjà parlé, et les serveurs sont plus ou moins centralisés. Nous pouvons venir à cet endroit central et déclarer raisonnablement: les gars, nous voulons le faire, veuillez le faire.
Quelles options avons-nous envisagées?

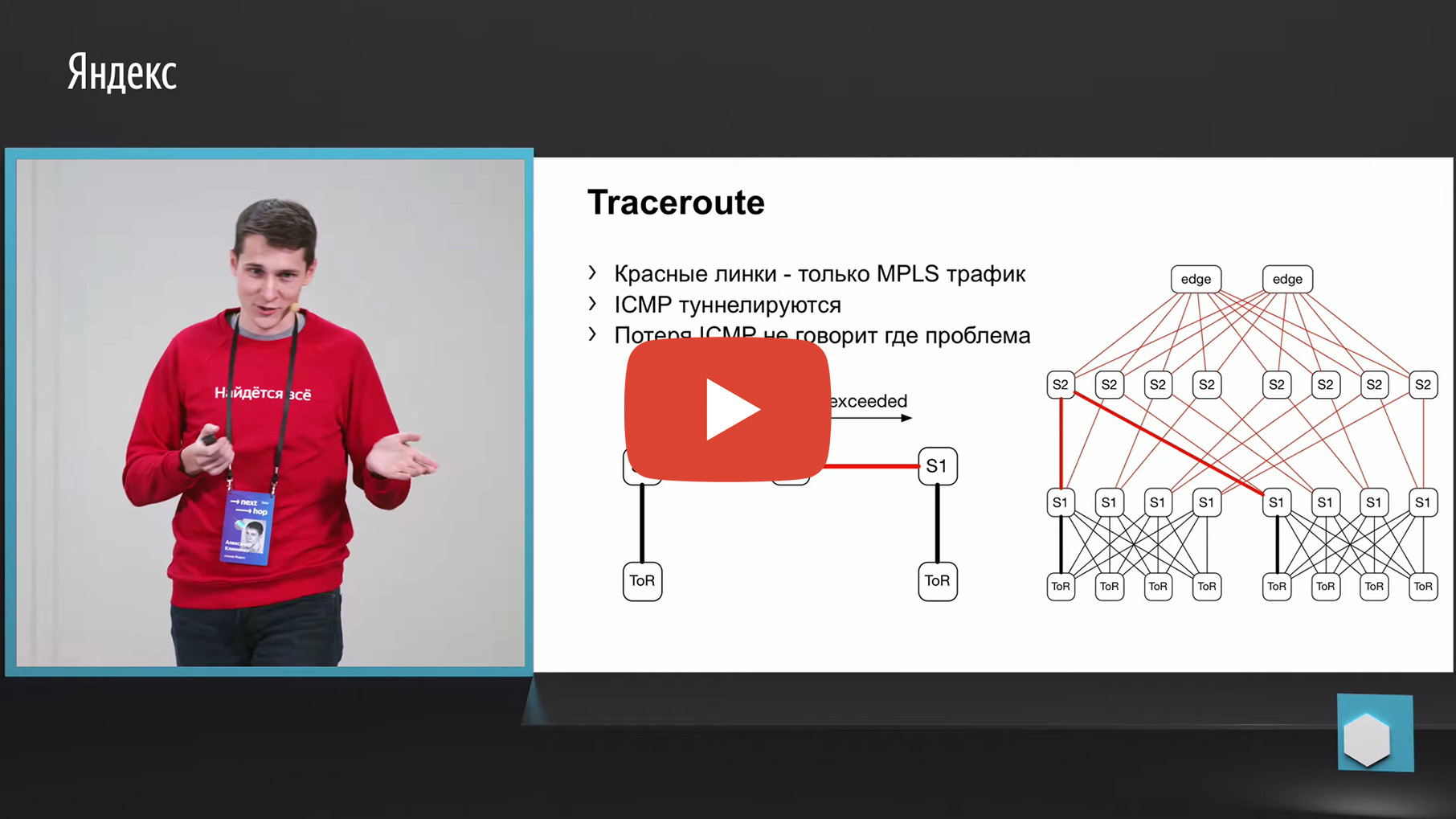
La première chose qui me vient à l'esprit est le traçage. Pourquoi? Parce que le même Netmon décharge les paires source et destination en échec dans un collecteur distinct. En conséquence, nous pouvons prendre ce 5-tuple, le regarder et faire une trace avec les mêmes paramètres. Et pour agréger les données sur quel lien ou à travers quels appareils le plus grand nombre de traces passe.
Mais malheureusement, MPLS est utilisé dans notre usine (maintenant nous nous dirigeons dans la direction opposée à MPLS, mais nous devons également surveiller les anciennes usines d'une manière ou d'une autre, mais ne les jetez pas, en fait). Nous avons MPLS en usine, et le problème avec MPLS et le traçage est qu'il doit tunneler le message ICMP dépassé TTL, qui sous-tend le traçage. Ayant perdu un tel message de l'entrée à la sortie, nous pouvons perdre la surveillance même. Autrement dit, nous ne comprendrons pas par quels nœuds ce message est passé. Cela ne nous convenait pas pour le suivi.
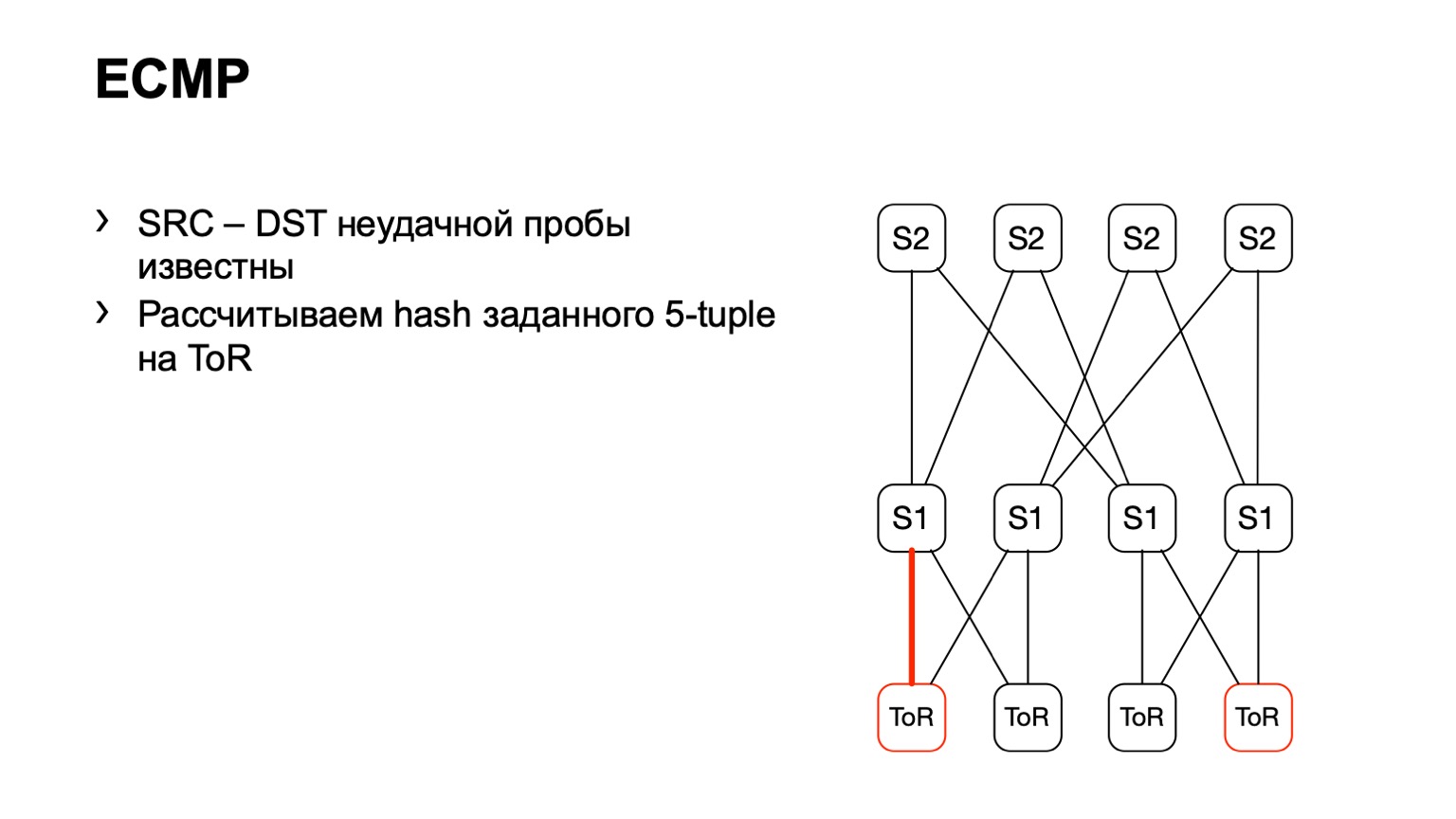
Il existe une deuxième option liée à ECMP. Nous prenons la même paire source et destination, en plus source-port destination-port. Nous arrivons à un morceau de fer, via l'API ou via la CLI, nous alimentons ce morceau de fer dans le morceau de fer et nous obtenons l'interface de sortie. De nombreux appareils prennent en charge ce type de sortie.
Nous arrivons à ToR, voyons que ToR a choisi un lien gauche ou droit. Dans ce cas, le lien gauche est vers la gauche S1.
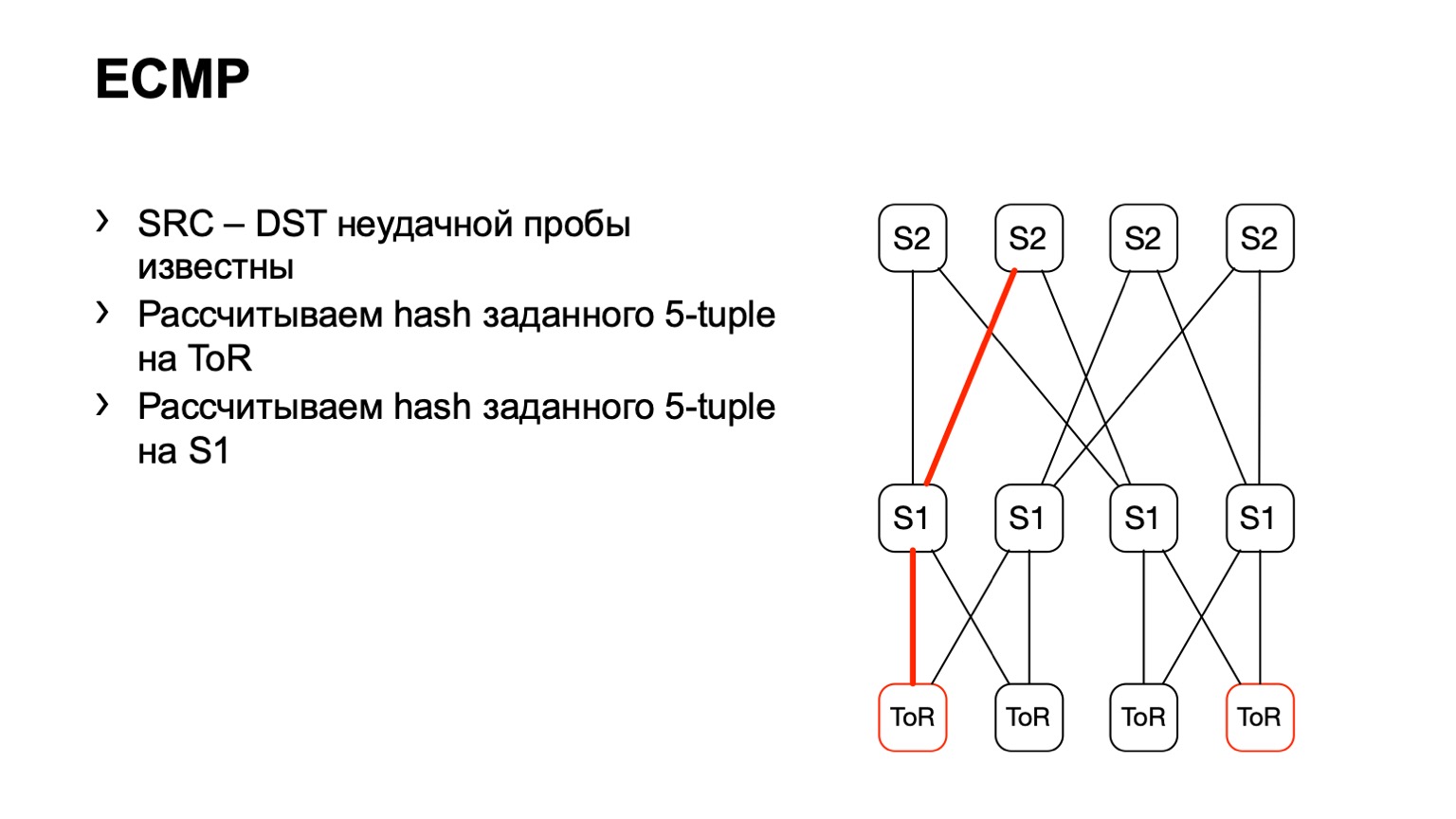
Nous sommes arrivés à ce S1, avons regardé, à droite S2, et de cette façon un chemin prêt s'est formé.
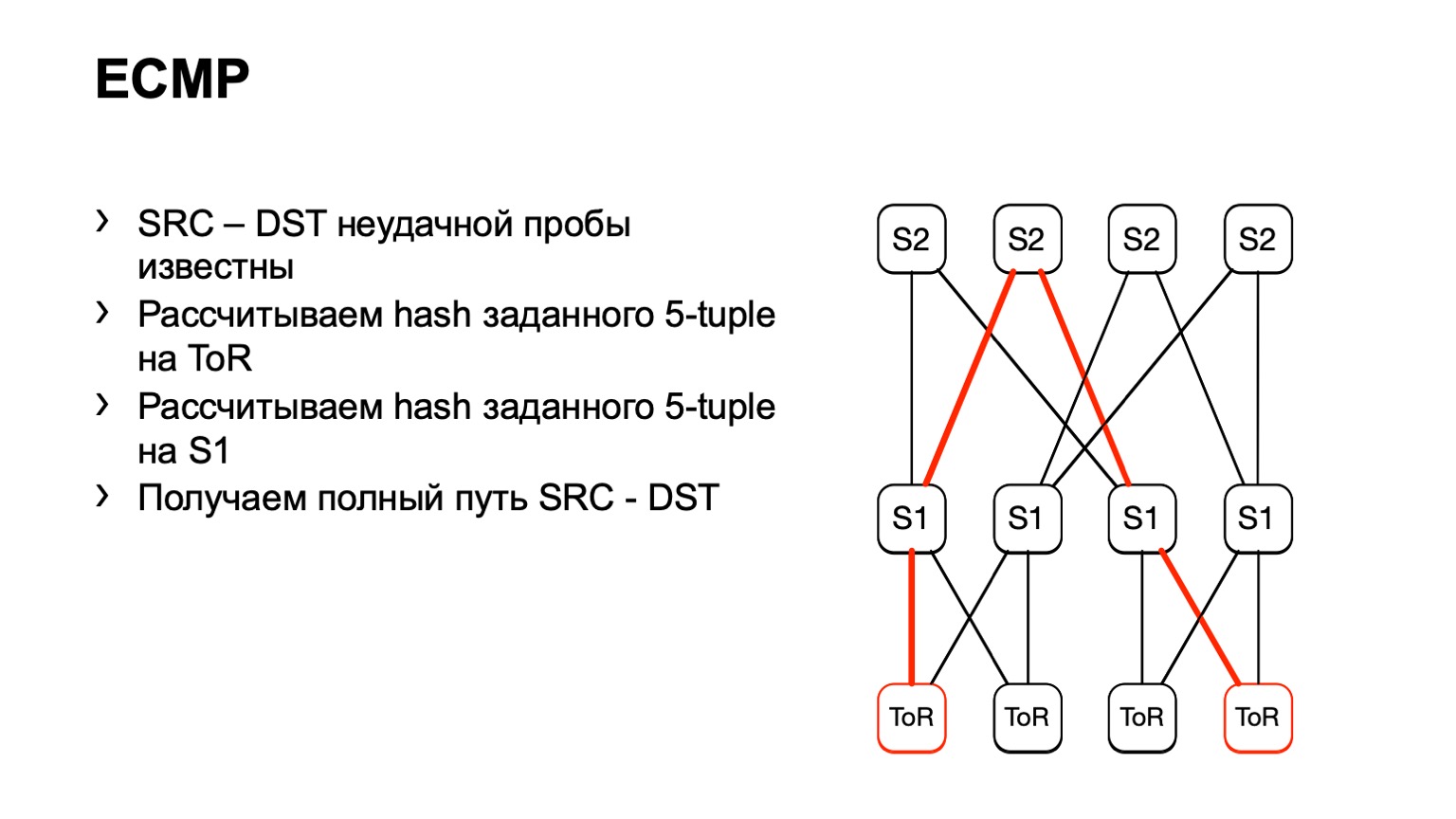
Il y a quelques inconvénients. Premièrement, tous les appareils ne peuvent normalement pas accepter ces données d'entrée que nous leur donnons. Cela est dû au fait que nous avons IPv6 et MPLS, ainsi qu'au fait que certains fournisseurs ne l'ont tout simplement pas implémenté. Le deuxième inconvénient de cette solution: nous comptons sur ce que le morceau de fer nous dira à nouveau, au lieu de regarder ce qui se passe sur les hôtes. Et enfin, le troisième inconvénient - pendant le temps que vous allez voir ce qui s'y passe, quelque chose peut déjà changer sur le réseau et vos données ne seront pas pertinentes.

Ensuite, nous sommes tombés sur une présentation intéressante faite par Facebook. Nous avons aimé l'idée proposée par Facebook, nous avons décidé d'essayer de faire quelque chose de similaire.
Quelle était l'idée principale? Utilisez un programme eBPF sur l'hôte pour colorer la retransmission TCP, puis calculez le nombre de ces paquets. Malheureusement, nous ne pouvions pas le faire comme sur Facebook, nous avons dû inventer notre propre vélo. Je vais essayer de vous parler du chemin de la douleur et de la souffrance que nous avons traversé.
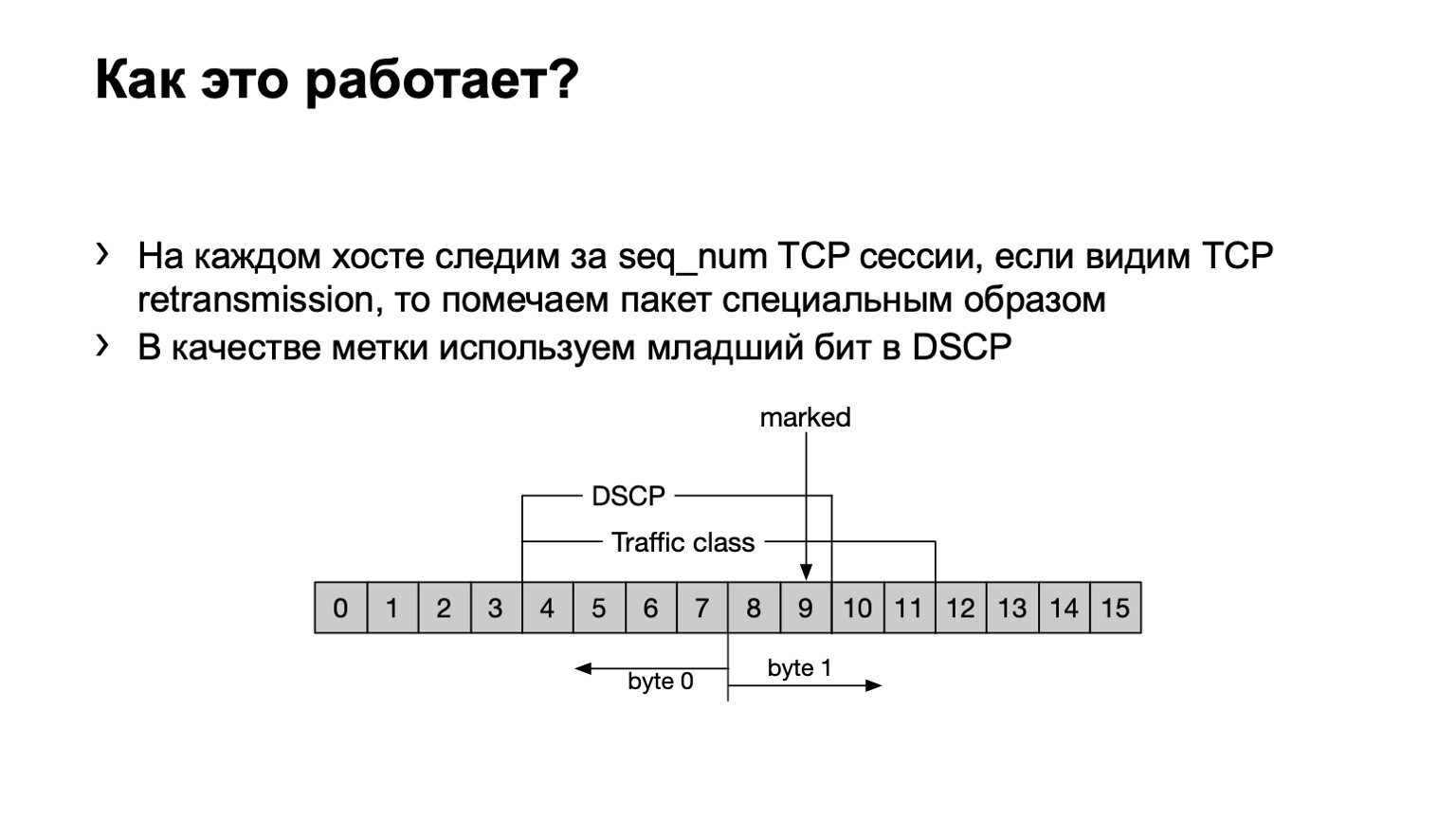
Qu'avons-nous fait? Juste au cas où, je soulignerai que la retransmission TCP sont des messages TCP qui sont répétés plusieurs fois car leur réception n'a pas été confirmée. Nous avons un programme eBPF installé sur l'hôte et regarde si ce message TCP est retransmis ou non retransmis. Il le fait ringard - par numéro de séquence. Si le même numéro de séquence est transmis dans une session TCP, il s'agit alors d'une retransmission.
Que faisons-nous avec de tels packages? Nous avons mis le dernier bit du champ DSCP à un pour calculer davantage le tout.
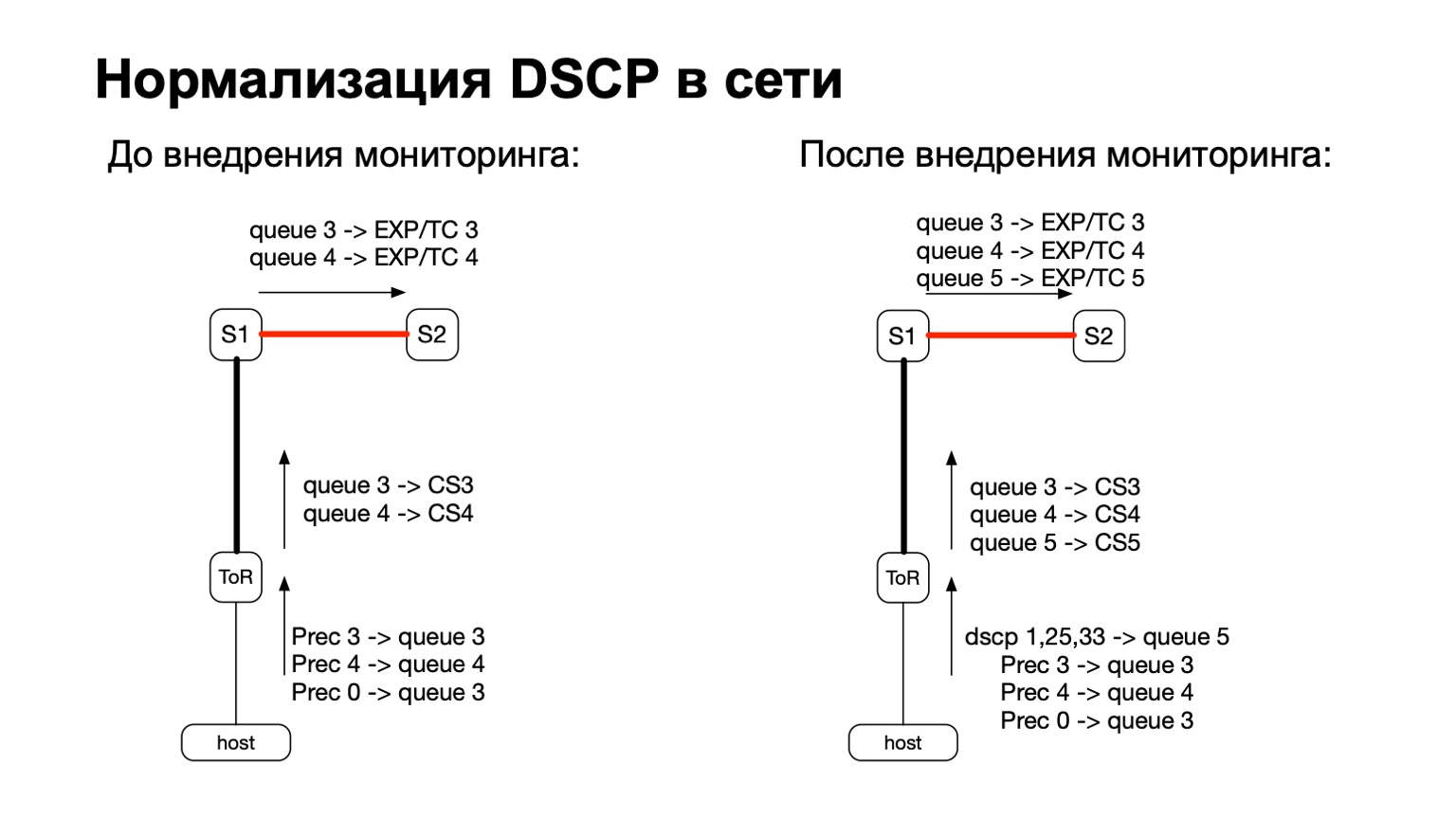
De manière générale, DSCP est en quelque sorte lié à la QoS, non? Et avec la QoS, l'histoire de notre réseau est assez compliquée et ancienne. Nous avons certaines politiques qui sont surveillées sur les commutateurs ToR. À ces politiques, nous venons d'ajouter la nécessité de compter plus et ces paquets colorés.
Ainsi, pour les paquets colorés (lire: pour les paquets TCP retransmis depuis l'hôte), nous avons simplement ajouté une autre file d'attente QoS. C'était assez facile à faire, car nous avions encore des lignes libres. De plus, cela est pratique, car au stade de la transition entre IPv6 et MPLS en usine, c'est-à-dire au stade où le paquet vole S1 et quitte notre partie MPLS de l'usine, il est pratique de prendre et de repeindre EXP / TC dans l'en-tête du paquet MPLS pour chaque file d'attente spécifique .
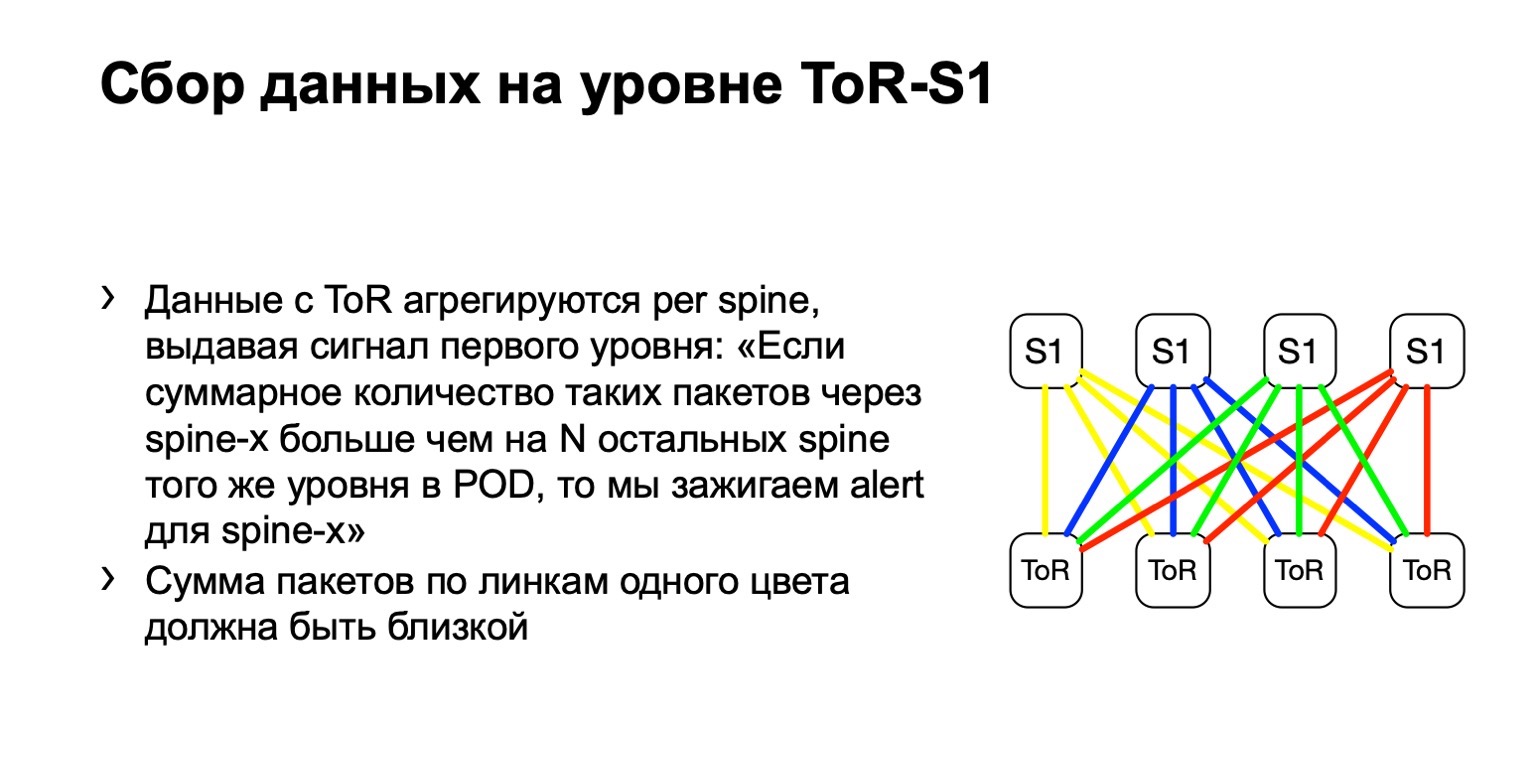
Que faisons-nous de ces données? Nous les collectons avec des filtres ACL standard, classe de trafic. Autrement dit, cela fonctionne, en principe, sur n'importe quel fournisseur. Nous pouvons collecter et calculer le nombre de ces colis partout.
Ensuite, nous examinons la distribution inégale de ces paquets sur le POD. Dans celui-ci, par exemple, quatre épines, comme sur la photo. Si le nombre de paquets sur les liens jaunes, sur bleu, sur vert et sur rouge est le même, alors nous pensons que tout est plus ou moins bon. Si à un moment donné, nous voyons une augmentation, disons, sur la colonne vertébrale la plus à droite du premier niveau, nous comprenons que cet appareil attire la retransmission, quelque chose ne va pas. Ensuite, nous essayons soit de le mettre hors service, soit du moins de le louer. Au moins, lorsque nous verrons des problèmes sur Netmon, nous saurons avec quel appareil ils peuvent survenir.
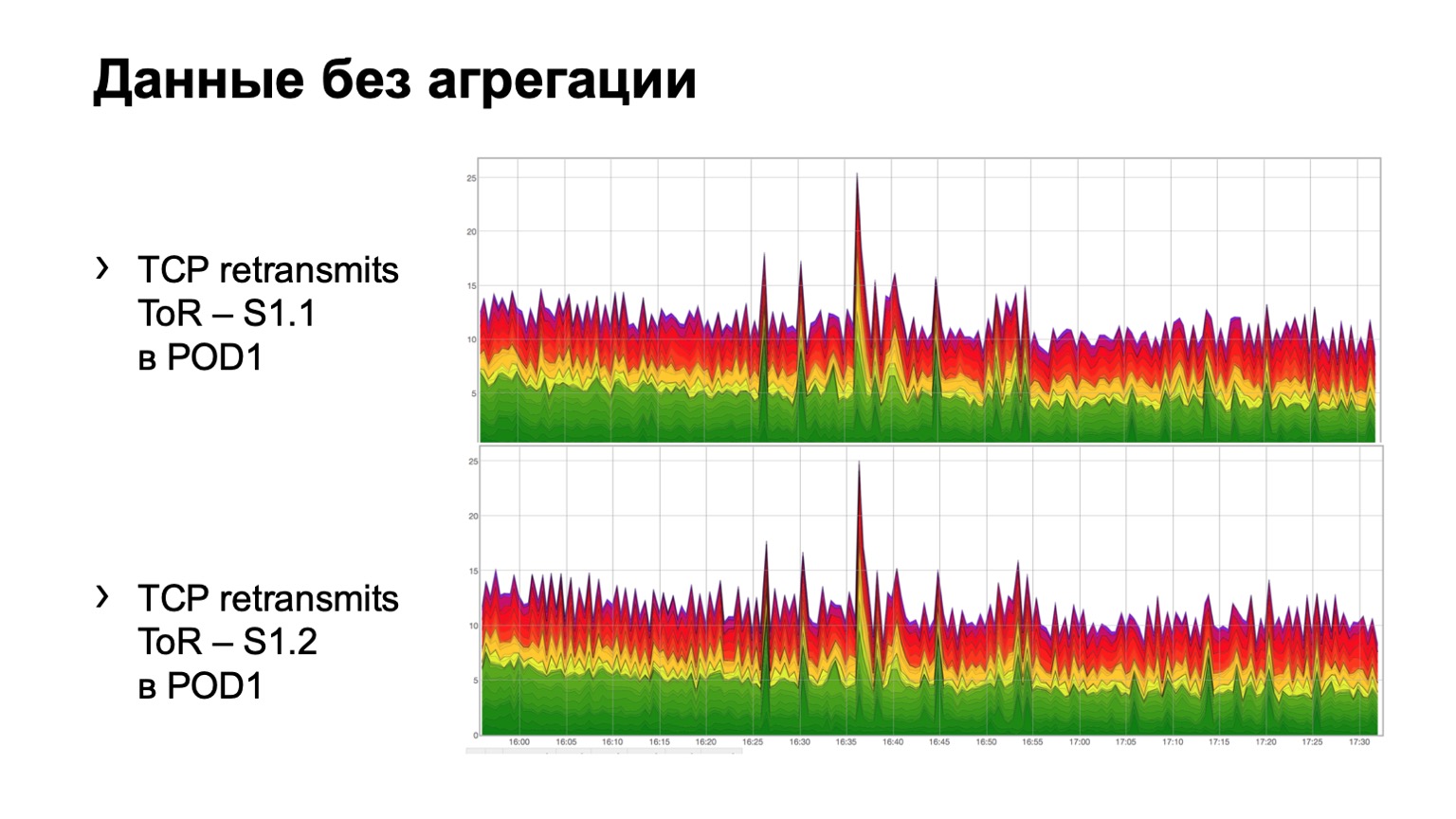
À quoi cela ressemble-t-il sur des données brutes simples? Voici deux graphiques. En fait, ce sont des graphiques retransmis avec ToR vers la colonne vertébrale de premier niveau. Dans l'exemple, deux dos dans le module. Le graphique supérieur est l'agrégation de la première colonne vertébrale, le graphique inférieur est la deuxième colonne vertébrale. Regarder cela dans ce formulaire n'est pas très pratique, nous avons donc ajouté l'agrégation de ces informations.
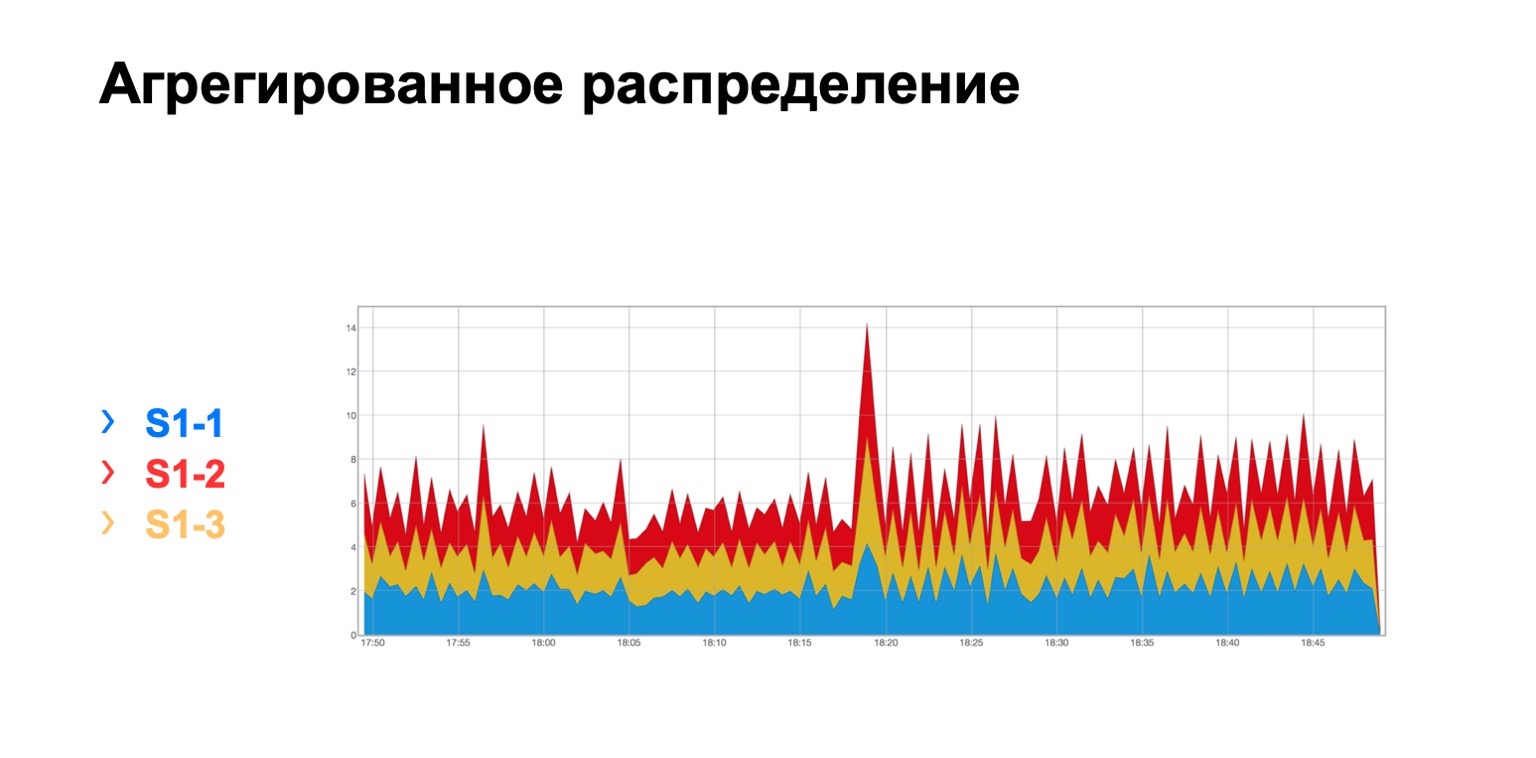
Cela ressemble à ceci. Il y a un module dans lequel trois épines, pour une raison quelconque, peu importe laquelle, et nous voyons ici une telle distribution totale des retransmissions à trois épines. Il est, en principe, assez uniforme.
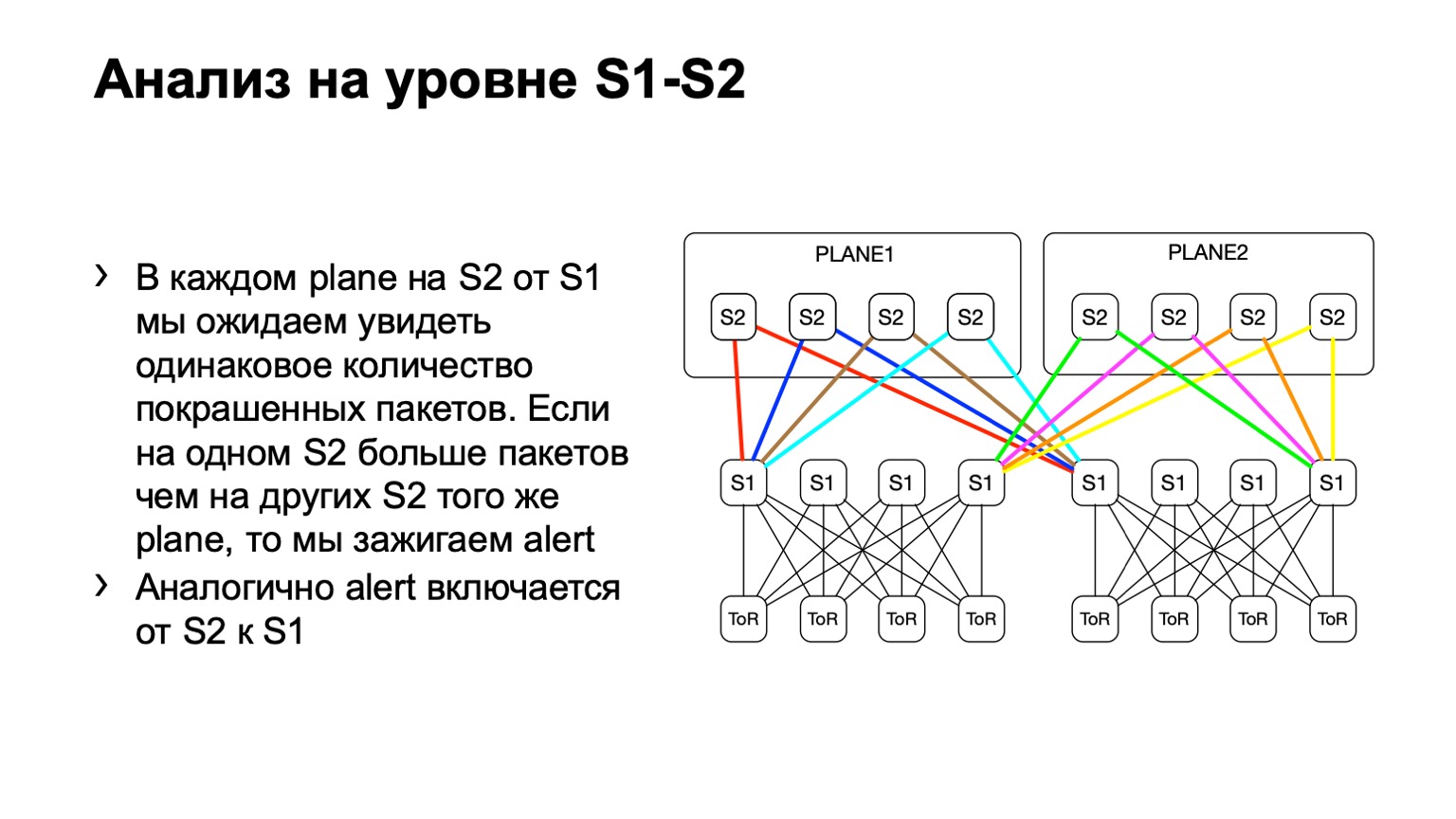
Pour la colonne vertébrale de deuxième niveau, nous pouvons avoir divers écarts, appelons-les ainsi. La topologie reste toujours régulière, mais selon le centre de données, nous pouvons ou non utiliser une architecture de type plaque. Le point ici est exactement le même. À un niveau, nous devrions avoir approximativement la même distribution de paquets colorés.
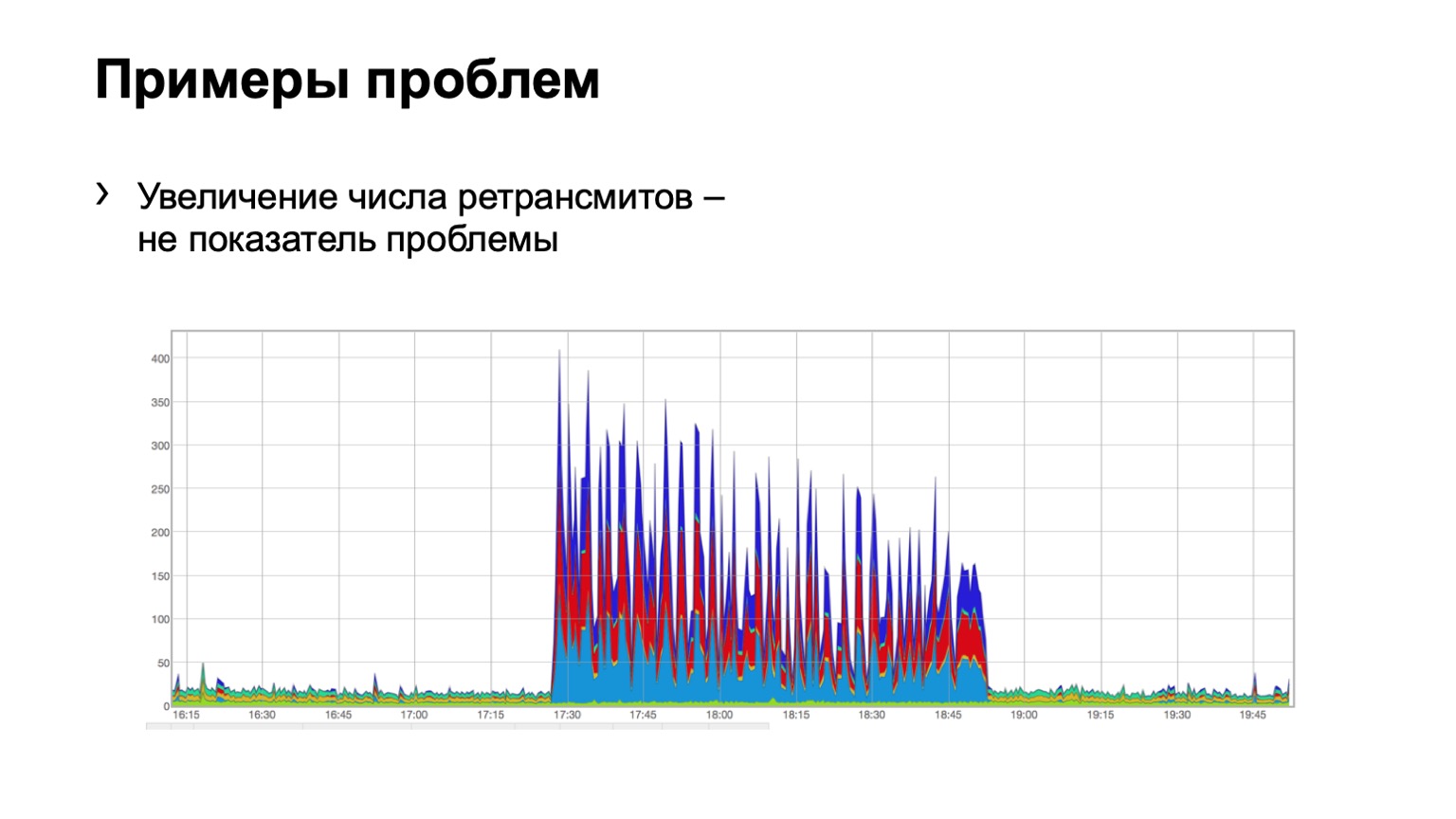
Regardons quelques exemples. Quelqu'un voit-il un problème sur un tel graphique? Il y a un problème ici, mais ce n'est pas en même temps. Oui, c'est le problème de Schrödinger. Pourquoi est-elle là et pas? Parce que nous voyons une augmentation du nombre de retransmissions, il est évident que quelque chose s'est produit pour nous. Mais en même temps, nous voyons que cette croissance est assez uniforme. Autrement dit, trois bleus de colonne vertébrale, rouges, bleus, même la distribution sur eux. Qu'est-ce que cela signifie? Qu'il y avait une sorte de problème dans le réseau, mais ce n'est pas lié à ce niveau d'agrégation de données. Elle est ailleurs.
Peut-être que quelqu'un a fermé le port sur les pare-feu, déconnecté un cluster, c'est-à-dire que quelque chose s'est produit. Mais nous ne sommes pas du tout intéressés par ce qui était là et pourquoi. Autrement dit, nous ne considérons même pas un tel problème.
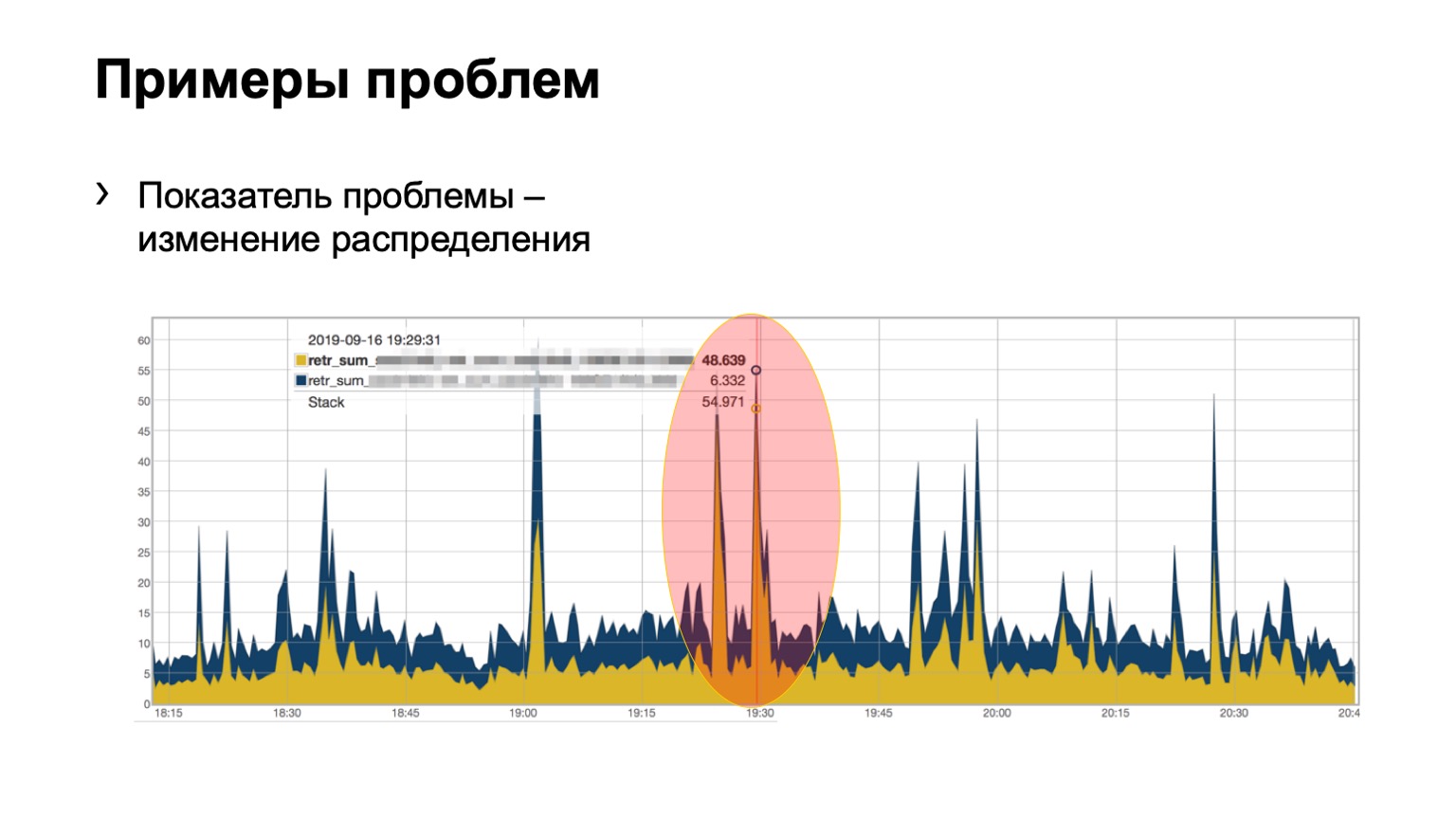
Et ici, peut-être, pas si clairement, mais le problème est visible. Deux épines dans le module, 46 paquets peints ont volé sur l'un et un peu sur le second. Nous comprenons que nous avons un problème avec une sorte de colonne vertébrale sur le réseau, nous devons y faire quelque chose.
Pourquoi ai-je d'abord parlé du chemin de la douleur et de la souffrance? Parce qu'il y a beaucoup de problèmes avec une telle solution. Le problème principal est, bien sûr, le problème de toute surveillance, c'est un faux positif. Les faux positifs, c'était beaucoup. Principalement dû au fait que nous utilisons DSCP et sommes généralement liés à la QoS.

Nous avons constaté que les colis d'autres personnes volent dans notre peinture et nous alertent de notre surveillance. Autrement dit, nous pensons que c'est une retransmission, et quelqu'un d'autre met leurs paquets là-bas et, en général, gâche l'image pour nous. Naturellement, nous avons commencé à comprendre, trouvé beaucoup d'endroits où nous pensions que cela fonctionnait, mais cela ne fonctionne pas comme nous le pensons. Par exemple, le trafic entrant dans le réseau doit apparemment être repeint, le trafic avec les classes CS6 et CS7 sur les frontières ne doit pas entrer dans notre réseau. Mais à certains endroits, il y avait, disons, des défauts, et nous les avons traités avec succès.
Certains fabricants ont présenté des surprises sous la forme de compteurs sur la direction sortante de ces paquets, et la puce fonctionne de telle sorte qu'en fait, pour traiter la liste d'accès sortante, elle enveloppe à nouveau le trafic, en mordant la moitié de la bande passante de la puce . C'était 900 gigabits par puce, c'est devenu la moitié.
Et nous avons fait quelques améliorations car les paramètres de l'hôte peuvent être différents. Autrement dit, certains hôtes peuvent envoyer des retransmissions plus souvent, certains hôtes peuvent être moins probables, deux ou cinq, et tout cela alerte notre surveillance, tout cela est faux positif.
Tout d'abord, nous avons abandonné l'idée de peindre chaque retransmission TCP. Nous avons réalisé qu'en principe, nous n'avons pas besoin de chaque retransmission pour comprendre où se situe le problème. Nous avons commencé à peindre uniquement SYN-retransmettre. SYN est le premier paquet de la session, cela nous suffit pour recevoir un signal. Nous peignons également SYN-ACL.
Cela a quand même donné de faux positifs. Nous sommes allés un peu plus loin. Nous avons commencé à peindre uniquement la première retransmission TCP SYN de la session. Autrement dit, il y en a plusieurs envoyés, nous les avons peints chacun - un seul a commencé à être peint. Nous en sommes donc arrivés à ce que nous avons maintenant.
Au total, il y a Netmon, il y a des agents sur les hôtes qui colorent le premier SYN-retransmit dans la session, et nous comptons ces retransmissions sur chaque appareil, sur presque chaque lien de notre réseau.

Mais regarder avec les yeux l'image que je montrais n'est pas très pratique. Autrement dit, vous ne pouvez pas le vendre à un officier de garde, car dans chaque section, vous devez tout évaluer avec vos yeux. Et nous sommes arrivés au fait que je veux avoir une alerte. Je veux qu'une lumière s'allume: un appareil tel ou tel est un problème; un autre appareil pose problème.
Rappelons quelques statistiques mathématiques. L'idée avec alerte est que chaque appareil est essentiellement un panier. Nous avons une probabilité de succès et une probabilité d'échec pour quatre appareils. La probabilité de retransmission dans le panier, c'est-à-dire le succès, est de ¼. Il s'avère une distribution binomiale.
Quelle est la difficulté de faire une alerte ici? Le fait qu'on ne puisse pas rendre les seuils statiques, on ne peut pas dire: si dix retransmissions arrivent sur un appareil et neuf sur l'autre, alors il n'y a pas de problème. Et si dix et cinq, alors il y a un problème. Parce que si nous l'adaptons à mille PPS, ces données ne seront plus pertinentes. 1000 PPS et 800 PPS entre différents appareils est définitivement un problème.
Nous ne pouvons pas définir de seuils statiques en PPS ou en octets, nous ne pouvons pas les définir en pourcentage - le même problème avec eux. Par conséquent, nous avons besoin d'une solution qui rend ce seuil plus ou moins dynamique, en fonction du nombre de paquets.
Et le charme de la distribution binomiale est qu'à l'augmentation du PPS, elle tend à la normale, et pour une distribution normale, nous pouvons déjà calculer l'attente, la variance et calculer l'intervalle de confiance, ce que nous avons fait. L'intervalle de confiance pour nous est 3NPQ, c'est-à-dire qu'il dépend du nombre de paquets à travers l'appareil. En conséquence, nous avons un seuil de décalage dynamique.
Voici à quoi ressemble notre signal dans l'image. Si un appareil est éliminé de la distribution, nous levons un drapeau dessus - quelque chose ne va pas.

Où voulons-nous nous développer davantage, que voulons-nous améliorer ici, en plus, bien sûr, de la lutte contre les faux positifs? Tout d'abord, nous serions intéressés de voir ce qu'il y avait au moment du problème? Pour ce faire, nous avons une telle option dans l'agent - Debug. Nous pouvons télécharger exactement ce qui a été retransmis, c'est-à-dire un paquet de 5 tuples, par exemple, dans un collecteur séparé, puis le regarder. Mais cela donne une certaine charge aux hôtes, il nous est donc parfois interdit de le faire. Nous voulons fixer ERSPAN et décharger ces packages sur le collecteur depuis le matériel lui-même, car personne ne nous interdit de le faire sur le matériel.
Dima Afanasyev a
expliqué comment nous allons développer nos usines, et l'un des points était la transition de l'usine MPLS à IPv6 uniquement. Qu'est-ce que cela nous donne? MPLS a trois bits pour le marquage QoS. En IPv6, au moins six. Actuellement, seuls trois bits sont utilisés dans notre réseau. Autrement dit, nous avons encore trois bits de plus dans lesquels nous pouvons mettre, en fait, toutes les informations de l'hôte.
Par exemple, nous ne peignons maintenant que le premier SYN-retransmis de la session. Et nous pouvons colorer le deuxième bit, par exemple, si le paquet va vers un réseau externe. Et nous pouvons retransmettre, c'est-à-dire mettre en évidence un autre signal, que nous examinerons ensuite séparément.
De plus, la transition vers la conception avec le pod de bord, lorsque nous avons effectué le DCI à un endroit particulier, nous menace du fait qu'à cet endroit, nous pouvons contrôler plus précisément notre domaine diffserv. Autrement dit, repeindre et faire quelque chose avec des peintures pour couper les faux positifs.
En conséquence, faire tout ce qui précède s'est avéré plutôt douloureux, mais intéressant. Il n'y avait rien à craindre. En fait, nous avons développé une solution que tout le monde peut utiliser. Il est testé sur pratiquement tous les fournisseurs, cela fonctionne, ce n'est pas difficile. Et cela montre vraiment quel appareil sur le réseau il y a un problème. Par conséquent, mon message est - n'ayez pas peur de faire de même et laissez votre surveillance rester verte. Merci d'avoir écouté.