Depuis plus de 20 ans, nous visualisons des pages Web en utilisant le protocole HTTP. La plupart des utilisateurs ne pensent pas du tout à ce que c'est et comment cela fonctionne. D'autres savent que quelque part sous HTTP il y a TLS, et en dessous il y a TCP, sous lequel IP et ainsi de suite. Et d'autres - hérétiques - croient que TCP est le siècle dernier, ils veulent quelque chose de plus rapide, de plus fiable et de plus sécurisé. Mais dans leurs tentatives d'inventer un nouveau protocole idéal, ils sont revenus aux technologies des années 80 et tentent de construire leur brave nouveau monde sur eux.

Un peu d'histoire: HTTP / 1.1
En 1997, le protocole d'échange de texte HTTP version 1.1 a obtenu son RFC. À cette époque, le protocole était utilisé par les navigateurs pendant plusieurs années, et le nouveau standard en a duré quinze autres. Le protocole ne fonctionnait que sur la base de la demande-réponse et était principalement destiné à transmettre des informations textuelles.
HTTP a été conçu pour fonctionner en plus du protocole TCP, ce qui garantit une livraison fiable des paquets vers la destination. TCP est basé sur l'établissement et le maintien d'une connexion fiable entre les points d'extrémité et la segmentation du trafic. Les segments ont leur propre numéro de séquence et leur propre somme de contrôle. Si soudainement l'un des segments ne vient pas ou vient avec la mauvaise somme de contrôle, la transmission s'arrêtera jusqu'à ce que le segment perdu soit restauré.
Dans HTTP / 1.0, la connexion TCP a été fermée après chaque demande. Cela a été extrêmement inutile car L'établissement d'une connexion TCP (3-Way-Handshake) n'est pas un processus rapide. HTTP / 1.1 a introduit le mécanisme de maintien en vie, qui vous permet de réutiliser une seule connexion pour plusieurs demandes. Cependant, comme il peut facilement devenir un goulot d'étranglement, plusieurs connexions TCP / IP au même hôte sont autorisées dans différentes implémentations HTTP / 1.1. Par exemple, dans Chrome et dans les versions récentes de Firefox, jusqu'à six connexions sont autorisées.

Le cryptage était également censé être laissé à d'autres protocoles, et pour cela, le protocole TLS a commencé à être utilisé en plus de TCP, qui protégeait de manière fiable les données, mais augmentait encore le temps nécessaire pour établir une connexion. En conséquence, le processus de prise de contact a commencé à ressembler à ceci:
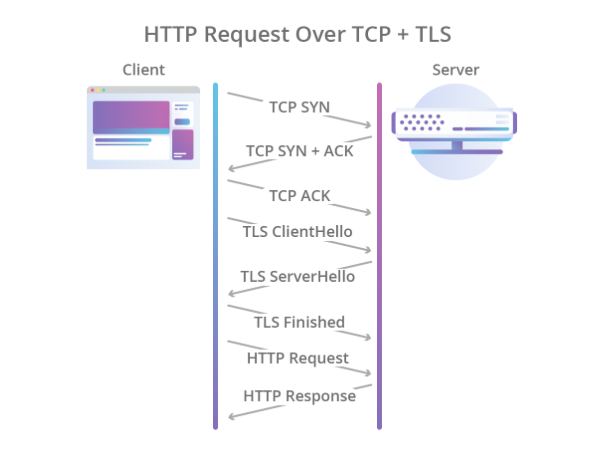 Illustration de Cloudflare
Illustration de CloudflareAinsi, HTTP / 1.1 a rencontré un certain nombre de problèmes:
- Configuration de connexion lente.
- Une connexion TCP est utilisée pour une demande, ce qui signifie que les autres demandes doivent soit trouver une autre connexion, soit attendre que la demande en cours la libère.
- Seul le modèle pull est pris en charge. Il n'y a rien dans la norme concernant la poussée du serveur.
- Les titres sont transmis en texte.
Si la poussée du serveur est implémentée d'une manière ou d'une autre en utilisant le protocole WebSocket, alors le reste des problèmes devait être traité de manière plus radicale.
Un peu de modernité: HTTP / 2
En 2012, les travaux sur le protocole SPDY (prononcé «speed») ont commencé dans les entrailles de Google. Le protocole a été conçu pour résoudre les problèmes de base de HTTP / 1.1 et devait en même temps maintenir la compatibilité descendante. En 2015, le groupe de travail IETF a introduit la spécification HTTP / 2 basée sur le protocole SPDY. Voici les différences dans HTTP / 2:
- Sérialisation binaire.
- Multiplexage de plusieurs requêtes HTTP en une seule connexion TCP.
- Serveur-pousser hors de la boîte (sans WebSocket).
Le protocole a été un grand pas en avant. Il
surpasse largement
la première version et ne nécessite pas la création de plusieurs connexions TCP: toutes les requêtes adressées à un hôte sont multiplexées en une seule. Autrement dit, dans une connexion, il existe plusieurs flux dits, chacun ayant son propre ID. Le bonus est un push serveur en boîte.
Cependant, la multiplication conduit à un autre problème fondamental. Imaginez que nous exécutons de manière asynchrone 5 demandes sur un serveur. Lorsque vous utilisez HTTP / 2, toutes ces demandes seront exécutées dans la même connexion TCP, ce qui signifie que si l'un des segments d'une demande est perdu ou arrive de manière incorrecte, la transmission de toutes les demandes et réponses s'arrêtera jusqu'à ce que le segment perdu soit restauré. Évidemment, plus la qualité de la connexion est mauvaise, plus le HTTP / 2 fonctionne lentement.
Selon Daniel Stenberg , dans une situation où les paquets perdus représentent 2% de tous, HTTP / 1.1 dans un navigateur fonctionne mieux que HTTP / 2 car il ouvre 6 connexions, et pas une.
Ce problème est appelé «blocage en tête de ligne» et, malheureusement, il n'est pas possible de le résoudre à l'aide de TCP.
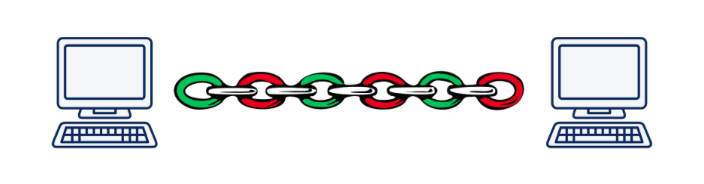 Illustration de Daniel Steinberg
Illustration de Daniel SteinbergEn conséquence, les développeurs de la norme HTTP / 2 ont fait un excellent travail et ont fait presque tout ce qui pouvait être fait au niveau de l'application du modèle OSI. Il est temps de descendre au niveau du transport et d'inventer un nouveau protocole de transport.
Nous avons besoin d'un nouveau protocole: UDP vs TCP
Assez rapidement, il est devenu clair que l'introduction d'un tout nouveau protocole de couche transport est une tâche insoluble dans les réalités d'aujourd'hui. Le fait est que les glandes ou les boîtiers intermédiaires (routeurs, pare-feu, serveurs NAT ...) connaissent le niveau de transport, et leur apprendre quelque chose de nouveau est une tâche extrêmement difficile. De plus, la prise en charge des protocoles de transport est connectée au noyau des systèmes d'exploitation, et les noyaux ne changent pas très volontiers.
Et ici, on pourrait abandonner et dire «Nous, bien sûr, inventerons un nouveau HTTP / 3 avec préférence et courtisanes, mais il sera mis en œuvre dans 10-15 ans (après environ cette période, la plupart des glandes seront remplacées)», mais il y en a une de plus, pas la plus option évidente: utilisez le protocole UDP. Oui, oui, le même protocole selon lequel nous avons lancé des fichiers sur un LAN à la fin des années 90 et au début de zéro. Presque tous les morceaux de fer d'aujourd'hui savent comment les utiliser.
Quels sont les avantages d'UDP sur TCP? Tout d'abord, nous n'avons pas de session de niveau de transport que le fer connaît. Cela nous permet de déterminer nous-mêmes la session sur les points d'extrémité et de résoudre les conflits qui s'y produisent. Autrement dit, nous ne sommes pas limités à une ou plusieurs sessions (comme dans TCP), mais nous pouvons les créer autant que nous en avons besoin. Deuxièmement, la transmission de données sur UDP est plus rapide que sur TCP. Ainsi, en théorie, nous pouvons franchir le plafond de vitesse actuel atteint dans HTTP / 2.
Cependant, UDP ne garantit pas une transmission de données fiable. En fait, nous envoyons simplement des paquets, en espérant qu'ils seront reçus à l'autre bout. N'a pas reçu? Eh bien, pas de chance ... C'était suffisant pour transmettre des vidéos pour adultes, mais pour des choses plus sérieuses, vous avez besoin de fiabilité, ce qui signifie que vous devez enrouler autre chose sur UDP.
Comme pour HTTP / 2, la création d'un nouveau protocole a commencé chez Google en 2012, c'est-à-dire à peu près en même temps que le début des travaux sur SPDY. En 2013, Jim Roskind a présenté
le protocole QUIC (Quick UDP Internet Connections) au grand public, et déjà en 2015 Internet Draft a été introduit pour normaliser l'IETF. Déjà à cette époque, le protocole développé par Roskind sur Google était très différent du protocole standard, donc la version de Google s'appelait gQUIC.
Qu'est-ce que QUIC
Tout d'abord, comme déjà mentionné, il s'agit d'un wrapper sur UDP. La connexion QUIC dépasse UDP, dans laquelle, par analogie avec HTTP / 2, plusieurs flux peuvent exister. Ces flux n'existent qu'aux points de terminaison et sont servis indépendamment. Si la perte de paquets s'est produite dans un flux, cela n'affectera en rien les autres.
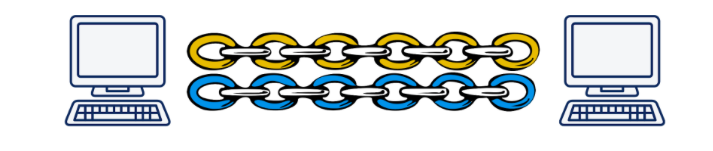 Illustration de Daniel Steinberg
Illustration de Daniel SteinbergDeuxièmement, le chiffrement est désormais mis en œuvre non pas à un niveau distinct, mais inclus dans le protocole. Cela vous permet d'établir une connexion et d'échanger des clés publiques en une seule poignée de main, et vous permet également d'utiliser le mécanisme de négociation délicat 0-RTT et d'éviter généralement les retards dans la poignée de main. De plus, les paquets de données individuels peuvent désormais être chiffrés. Cela vous permet de ne pas attendre la fin de la réception des données du flux, mais de décrypter les paquets reçus indépendamment. Ce mode de fonctionnement n'était pas du tout possible dans TCP, car TLS et TCP fonctionnaient indépendamment l'un de l'autre, et TLS ne pouvait pas savoir dans quels morceaux les données TCP seraient coupées. Et par conséquent, je ne pouvais pas préparer mes segments afin qu'ils s'insèrent dans les segments TCP un à un et puissent être déchiffrés indépendamment. Toutes ces améliorations permettent à QUIC de réduire la latence par rapport à TCP.

Troisièmement, le concept de flux faciles vous permet de délier la connexion de l'adresse IP du client. Ceci est important, par exemple, lorsqu'un client passe d'un point d'accès Wi-Fi à un autre, changeant son IP. Dans ce cas, lors de l'utilisation de TCP, un long processus se produit pendant lequel les connexions TCP existantes tombent en timeout et de nouvelles connexions sont créées à partir de la nouvelle IP. Dans le cas de QUIC, le client continue simplement d'envoyer des paquets de la nouvelle IP au serveur avec l'ancien ID de flux. Parce que L'ID de flux est désormais unique et non réutilisé, le serveur comprend que le client a changé d'IP, envoie les paquets perdus et continue la communication vers la nouvelle adresse.
Quatrièmement, QUIC est implémenté au niveau de l'application et non du système d'exploitation. Cela, d'une part, permet des modifications plus rapides du protocole, comme Pour obtenir une mise à jour, il suffit de mettre à jour la bibliothèque, plutôt que d'attendre une nouvelle version du système d'exploitation. En revanche, cela conduit à une forte augmentation de la consommation du processeur.
Et enfin, les gros titres. La compression d'en-tête se réfère uniquement aux points qui diffèrent en QUIC et gQUIC. Je ne vois aucune raison de consacrer beaucoup de temps à cela, je peux seulement dire que dans la version soumise pour standardisation, la compression d'en-tête a été rendue aussi similaire que possible à la compression d'en-tête dans HTTP / 2. Plus de détails peuvent être lus
ici .
C'est beaucoup plus rapide?
C'est une question délicate. Le fait est que même si nous n'avons pas de norme, il n'y a rien de spécial à mesurer. Les seules statistiques dont nous disposons sont peut-être les statistiques de Google, qui utilise gQUIC depuis 2013 et, en 2016, ont
rapporté à l'IETF qu'environ 90% du trafic allant vers leurs serveurs à partir du navigateur Chrome utilise désormais QUIC. Dans la même présentation, ils signalent que grâce à gQUIC, les pages se chargent environ 5% plus rapidement et la vidéo en streaming a 30% de gel en moins par rapport à TCP.
En 2017, un groupe de chercheurs dirigé par Arash Molavi Kakhki a publié un
important travail sur l'étude des performances de gQUIC par rapport au TCP.
L'étude a révélé plusieurs faiblesses gQUIC, telles que l'instabilité du mélange de paquets réseau, l'injustice de la capacité des canaux et le transfert plus lent de petits objets (jusqu'à 10 ko). Ce dernier, cependant, peut être compensé pour l'utilisation du 0-RTT. Dans tous les autres cas étudiés, gQUIC a montré une augmentation de la vitesse par rapport à TCP. Il est difficile de parler de chiffres spécifiques. Il est préférable de lire
l'étude elle -
même ou un
court article .
Ici, il faut dire que ces données concernent spécifiquement gQUIC et qu'elles ne sont pas pertinentes pour la norme en cours d'élaboration. Que se passera-t-il pour QUIC: jusqu'à présent, le mystère est derrière sept sceaux, mais il y a de l'espoir que les faiblesses identifiées par gQUIC seront prises en compte et corrigées.
Un petit avenir: qu'en est-il de HTTP / 3?
Et ici, tout est clair: l'API ne changera en rien. Tout restera exactement le même que dans HTTP / 2. Eh bien, si l'API reste la même, la transition vers HTTP / 3 devra être décidée en utilisant la dernière version de la bibliothèque prenant en charge le transport via QUIC sur le backend. Certes, pendant longtemps, vous devez toujours vous replier sur les anciennes versions de HTTP, car Internet n'est désormais pas prêt pour un passage complet à UDP.
Qui soutient déjà
Voici une
liste des implémentations QUIC existantes. Malgré l'absence de standard, la liste n'est pas mauvaise.
Aucun navigateur ne prend actuellement en charge QUIC dans la version. Récemment, il y avait des informations selon lesquelles Chrome incluait la prise en charge HTTP / 3, mais jusqu'à présent uniquement aux Canaries.
Parmi les backends, HTTP / 3 ne prend en charge que
Caddy et
Cloudflare , mais jusqu'à présent expérimentalement. NGINX a
annoncé à la fin du printemps 2019 qu'il avait commencé à travailler sur le support HTTP / 3, mais ne l'avait pas encore terminé.
Quels sont les problèmes
Nous vivons dans le monde réel, où aucune grande technologie ne peut aller dans les masses sans rencontrer de résistance, et QUIC ne fait pas exception.
Plus important encore, vous devez expliquer en quelque sorte au navigateur que «https: //» n'est plus un fait qui mène au 443e port TCP. Il n'y a peut-être pas du tout de TCP. Pour ce faire, utilisez l'en-tête Alt-Svc. Il permet au navigateur d'être informé que ce site est également disponible sur tel ou tel protocole à telle ou telle adresse. En théorie, cela devrait fonctionner comme une horloge, mais en pratique, nous tombons sur le fait qu'UDP peut être, par exemple, désactivé sur un pare-feu afin d'éviter les attaques DDoS.
Mais même si UDP n'est pas interdit, le client peut se trouver derrière un routeur NAT configuré pour contenir une session TCP par adresse IP, comme nous utilisons UDP, dans lequel il n'y a pas de session matérielle, NAT ne tiendra pas la connexion et la session QUIC
sera toujours terminée .
Tous ces problèmes sont liés au fait que l'UDP n'était pas utilisé auparavant pour transmettre du contenu Internet, et les fabricants de matériel ne pouvaient pas prévoir que cela arriverait un jour. De la même manière, les administrateurs ne comprennent pas encore comment configurer correctement leurs réseaux pour QUIC. Cette situation changera lentement et, en tout cas, ces changements prendront moins de temps que l'introduction d'un nouveau protocole de couche transport.
De plus, comme déjà décrit, QUIC augmente considérablement l'utilisation du processeur. Daniel Stenberg a
évalué la croissance du processeur jusqu'à trois fois.
Quand HTTP / 3 arrive
Ils
veulent adopter la norme d'ici mai 2020, mais étant donné que les documents prévus pour juillet 2019 restent inachevés, nous pouvons dire que la date est très probablement reportée.
Eh bien, Google utilise son implémentation de gQUIC depuis 2013. Si vous regardez la requête HTTP envoyée au moteur de recherche Google, vous pouvez voir ceci:

Conclusions
QUIC ressemble maintenant à une technologie plutôt brute, mais très prometteuse. Sachant qu'au cours des 20 dernières années, toutes les optimisations des protocoles de la couche transport liées principalement à TCP, QUIC, qui dans la plupart des cas gagne en performances, semblent désormais extrêmement bonnes.
Cependant, des problèmes non résolus doivent encore être résolus au cours des prochaines années. Le processus peut être retardé en raison du fait que le matériel est impliqué, que personne n'aime mettre à jour, mais néanmoins tous les problèmes semblent assez résolubles, et tôt ou tard nous aurons tous HTTP / 3.
L'avenir n'est pas loin!