La journalisation est une partie importante de toute application. Tout système d'enregistrement passe par trois étapes évolutives principales. Le premier est sorti sur la console, le second est la journalisation dans un fichier et l'apparition d'un cadre pour la journalisation structurée, et le troisième est la journalisation distribuée ou la collecte des journaux de divers services dans un seul centre.
Si la journalisation est bien organisée, elle vous permet de comprendre ce qui, quand et comment ça va mal, et de transmettre les informations nécessaires aux personnes qui doivent corriger ces erreurs. Pour un système dans lequel 100 000 messages sont envoyés chaque seconde dans 10 centres de données dans 190 pays et 350 ingénieurs déploient quelque chose chaque jour, le système de journalisation est particulièrement important.
 Ivan Letenko
Ivan Letenko est chef d'équipe et développeur chez Infobip. Pour résoudre le problème du traitement centralisé et du traçage des journaux dans l'architecture de microservice sous de telles charges, la société a essayé différentes combinaisons de la pile ELK, Graylog, Neo4j et MongoDB. En conséquence, après beaucoup de ratissage, ils ont écrit leur service de journalisation sur Elasticsearch, et PostgreSQL a été pris comme base de données pour des informations supplémentaires.
Sous le chat en détail, avec des exemples et des graphiques: l'architecture et l'évolution du système, les râteaux, la journalisation et le traçage, les métriques et la surveillance, la pratique de travailler avec les clusters Elasticsearch et de les administrer avec des ressources limitées.
Pour vous présenter le contexte, je vais vous parler un peu de l'entreprise. Nous aidons les clients-organisations à transmettre des messages à leurs clients: messages d'un service de taxi, SMS d'une banque au sujet de l'annulation, ou un mot de passe à usage unique lors de la saisie de VC.
350 millions de messages nous traversent chaque jour pour des clients dans 190 pays. Nous acceptons, traitons, facturons, acheminons, adaptons, envoyons aux opérateurs et traitons les rapports de livraison dans la direction opposée et formons des analyses.
Pour que tout cela fonctionne dans de tels volumes, nous avons:
- 36 centres de données dans le monde;
- Plus de 5000 machines virtuelles
- 350+ ingénieurs;
- 730+ microservices différents.
C'est un système complexe, et aucun gourou ne peut à lui seul comprendre la pleine échelle. L'un des principaux objectifs de notre société est la rapidité de livraison de nouvelles fonctionnalités et de nouvelles versions pour les entreprises. Dans ce cas, tout devrait fonctionner et ne pas tomber. Nous y travaillons: 40000 déploiements en 2017, 80000 en 2018, 300 déploiements par jour.
Nous avons 350 ingénieurs - il s'avère que
chaque ingénieur déploie quelque chose quotidiennement . Il y a quelques années à peine, une seule personne dans une entreprise avait une telle productivité - Kreshimir, notre ingénieur principal. Mais nous nous sommes assurés que chaque ingénieur se sente aussi confiant que Kresimir lorsqu'il appuie sur le bouton Déployer ou exécute un script.
Que faut-il pour cela? Tout d'abord, la
confiance que nous comprenons ce qui se passe dans le système et dans quel état il se trouve. La confiance est donnée par la possibilité de poser une question au système et de découvrir la cause du problème lors de l'incident et lors de l'élaboration du code.
Pour atteindre cette confiance, nous investissons dans l'
observabilité . Traditionnellement, ce terme combine trois composantes:
- enregistrement;
- métriques
- trace.
Nous en parlerons. Tout d'abord, examinons notre solution de journalisation, mais nous aborderons également les métriques et les traces.
Évolution
Presque toute application ou système de journalisation, y compris le nôtre, passe par plusieurs étapes d'évolution.
La première étape consiste à
sortir sur la console .
Deuxièmement - nous commençons
à écrire des journaux dans un fichier , un
cadre apparaît pour une sortie structurée dans un fichier. Nous utilisons généralement Logback car nous vivons dans la JVM. À ce stade, une journalisation structurée dans un fichier apparaît, comprenant que les différents journaux doivent avoir différents niveaux, avertissements et erreurs.
Dès
qu'il existe plusieurs instances de notre service ou différents services, la tâche d'
accès centralisé aux logs pour les développeurs et le support apparaît. Nous passons à la journalisation distribuée - nous combinons différents services en un seul service de journalisation.
Journalisation distribuée
L'option la plus connue est la pile ELK: Elasticsearch, Logstash et Kibana, mais nous avons choisi
Graylog . Il a une interface cool qui est orientée vers la journalisation. Les alarmes sortent de la boîte déjà dans la version gratuite, qui n'est pas dans Kibana, par exemple. Pour nous, c'est un excellent choix en termes de bûches, et sous le capot, c'est le même Elasticsearch.
 Dans Graylog, vous pouvez créer des alertes, des graphiques comme Kibana et même des métriques de journal.
Dans Graylog, vous pouvez créer des alertes, des graphiques comme Kibana et même des métriques de journal.Les problèmes
Notre entreprise était en pleine croissance et à un moment donné, il est devenu clair que quelque chose n'allait pas avec Graylog.
Charge excessive . Il y avait des problèmes de performances. De nombreux développeurs ont commencé à utiliser les fonctionnalités intéressantes de Graylog: ils ont construit des métriques et des tableaux de bord qui effectuent l'agrégation de données. Ce n'est pas le meilleur choix pour créer des analyses complexes sur le cluster Elasticsearch, qui est soumis à une lourde charge d'enregistrement.
Collisions Il y a beaucoup d'équipes, il n'y a pas de schéma unique. Traditionnellement, lorsqu'un identifiant touchait Graylog pour la première fois, un mappage se produisait automatiquement. Si une autre équipe décide qu'il doit être écrit l'UUID sous forme de chaîne - cela cassera le système.
Première décision
Journaux d'application et journaux de communication séparés . Différents journaux ont différents scénarios et méthodes d'application. Il existe, par exemple, des journaux d'application pour lesquels différentes équipes ont des exigences différentes pour différents paramètres: par le temps de stockage dans le système, par la vitesse de recherche.
Par conséquent, la première chose que nous avons faite a été de séparer les journaux d'application et les journaux de communication. Le deuxième type est constitué de journaux importants qui stockent des informations sur l'interaction de notre plateforme avec le monde extérieur et sur l'interaction au sein de la plateforme. Nous en parlerons davantage.
Remplacé une partie substantielle des journaux par des métriques . Dans notre entreprise, le choix standard est Prométhée et Grafana. Certaines équipes utilisent d'autres solutions. Mais il est important que nous nous soyons débarrassés d'un grand nombre de tableaux de bord avec des agrégations à l'intérieur de Graylog, que nous ayons tout transféré à Prometheus et Grafana. Cela a considérablement allégé la charge sur les serveurs.
Examinons les scénarios d'application des journaux, des métriques et des traces.
Journaux
Haute dimensionnalité, débogage et recherche . Quels sont les bons journaux?
Les journaux sont les événements que nous enregistrons.
Ils peuvent avoir une grande dimension: vous pouvez enregistrer l'ID de demande, l'ID utilisateur, les attributs de demande et d'autres données, dont la dimension n'est pas limitée. Ils sont également utiles pour le débogage et la recherche, pour poser des questions au système sur ce qui s'est passé et rechercher les causes et les effets.
Mesures
Faible dimensionnalité, agrégation, surveillance et alertes . Sous le capot de tous les systèmes de collecte métrique se trouvent les bases de données de séries chronologiques. Ces bases de données font un excellent travail d'agrégation, de sorte que les mesures conviennent pour l'agrégation, la surveillance et la création d'alertes.
Les métriques sont très sensibles à la dimension des données.
Pour les métriques, la dimension des données ne doit pas dépasser mille. Si nous ajoutons des ID de demande, dans lesquels la taille des valeurs n'est pas limitée, nous rencontrerons rapidement de graves problèmes. Nous avons déjà marché sur ce râteau.
Corrélation et trace
Les journaux doivent être corrélés.
Les journaux structurés ne nous suffisent pas pour effectuer facilement des recherches par données. Il doit y avoir des champs avec certaines valeurs: ID de demande, ID utilisateur, autres données des services dont proviennent les journaux.
La solution traditionnelle consiste à attribuer un ID unique à la transaction (journal) à l'entrée du système. Cet ID (contexte) est ensuite transmis à travers l'ensemble du système via une chaîne d'appels au sein d'un service ou entre services.
 Corrélation et traçage.
Corrélation et traçage.Il y a des termes bien établis. La trace est divisée en étendues et illustre la pile d'appels d'un service par rapport à un autre, une méthode par rapport à une autre par rapport à la chronologie. Vous pouvez clairement tracer le chemin du message, tous les timings.
Nous avons d'abord utilisé Zipkin. Déjà en 2015, nous avions une Proof of Concept (projet pilote) de ces solutions.
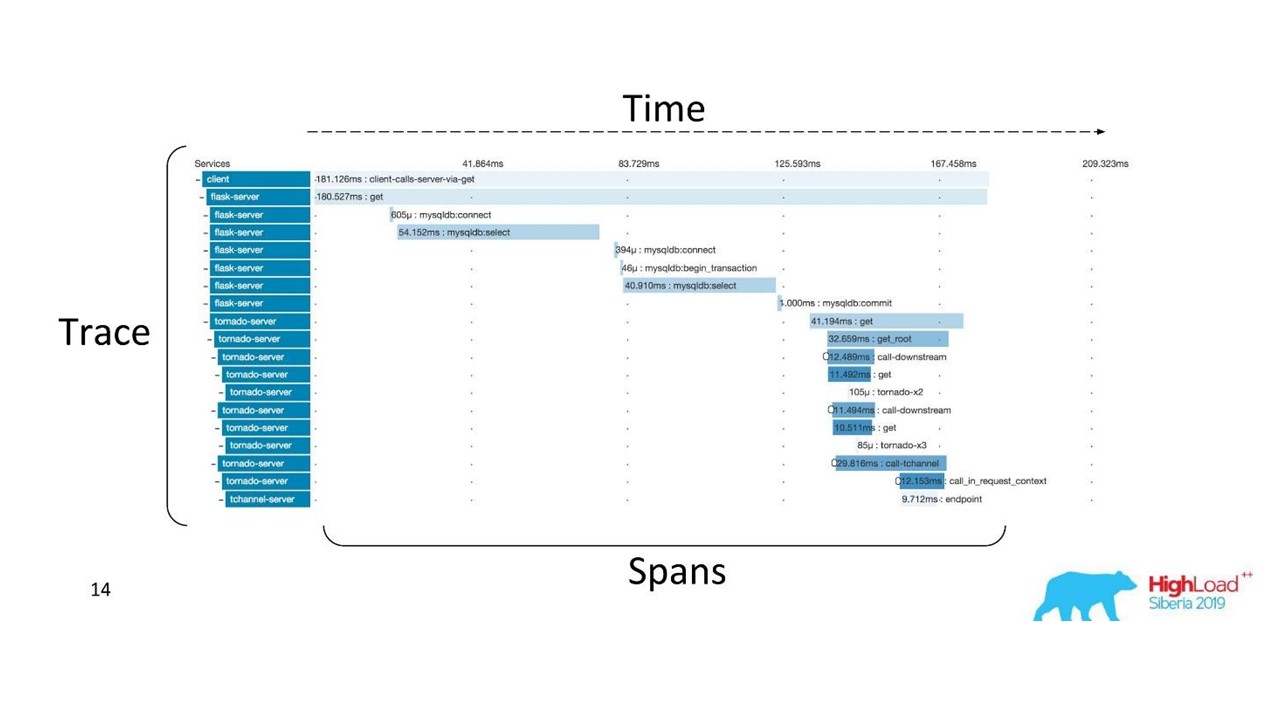 Trace distribuée
Trace distribuéePour obtenir une telle image, le
code doit être instrumenté . Si vous travaillez déjà avec une base de code qui existe, vous devez la parcourir - elle nécessite des modifications.
Pour obtenir une image complète et bénéficier des traces, vous devez
instrumenter tous les services de la chaîne , et pas seulement un service sur lequel vous travaillez actuellement.
Il s'agit d'un outil puissant, mais qui nécessite des coûts d'administration et de matériel importants, nous avons donc basculé de Zipkin vers une autre solution, qui est fournie par «as a service».
Rapports de livraison
Les journaux doivent être corrélés. Les traces doivent également être corrélées. Nous avons besoin d'un identifiant unique - un contexte commun qui peut être transmis tout au long de la chaîne d'appel. Mais souvent, cela n'est pas possible - une
corrélation se produit au sein du système en raison de son fonctionnement . Lorsque nous démarrons une ou plusieurs transactions, nous ne savons toujours pas qu'elles font partie d'un seul grand ensemble.
Prenons le premier exemple.
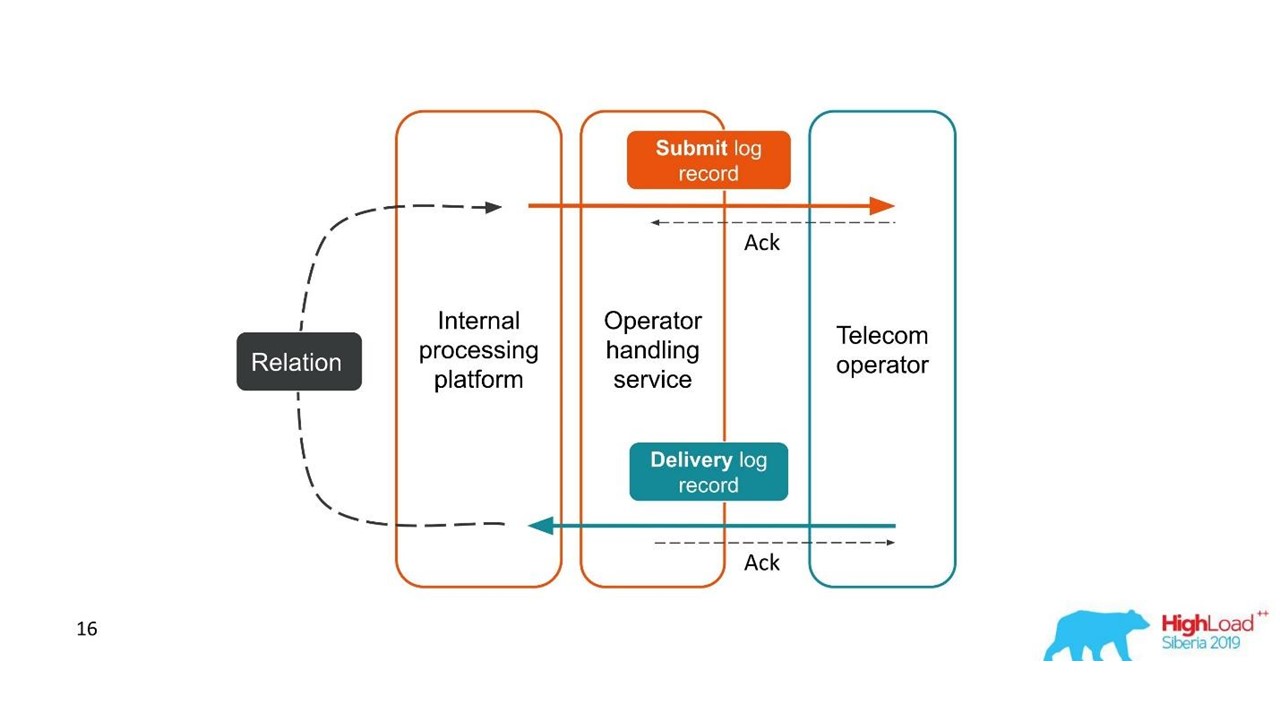 Rapports de livraison.
Rapports de livraison.- Le client a envoyé une demande de message et notre plateforme interne l'a traitée.
- Le service, qui est en interaction avec l'opérateur, a envoyé ce message à l'opérateur - une entrée est apparue dans le système de journalisation.
- Plus tard, l'opérateur nous envoie un rapport de livraison.
- Le service de traitement ne sait pas à quel message se rapporte ce rapport de remise. Cette relation est créée plus tard dans notre plateforme.
Deux transactions liées font partie d'une seule transaction entière. Ces informations sont très importantes pour les ingénieurs de support et les développeurs d'intégration. Mais cela est complètement impossible à voir sur la base d'une seule trace ou d'un seul ID.
Le deuxième cas est similaire - le client nous envoie un message dans un grand paquet, puis nous les démontons, ils reviennent également par lots. Le nombre de packs peut même varier, mais tous sont combinés.
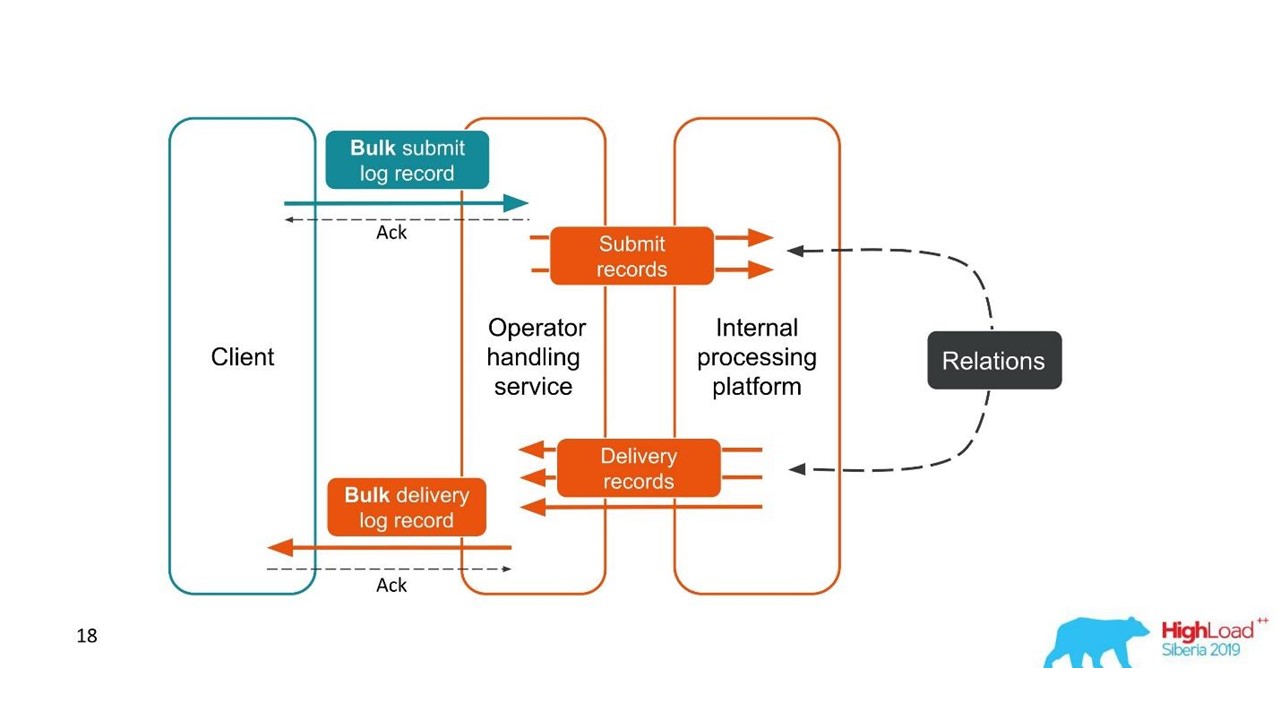
Du point de vue du client, il a envoyé un message et reçu une réponse. Mais nous avons obtenu plusieurs transactions indépendantes qui doivent être combinées. Il se révèle une relation un-à-plusieurs, et avec un rapport de livraison - un à un. Il s'agit essentiellement d'un graphique.
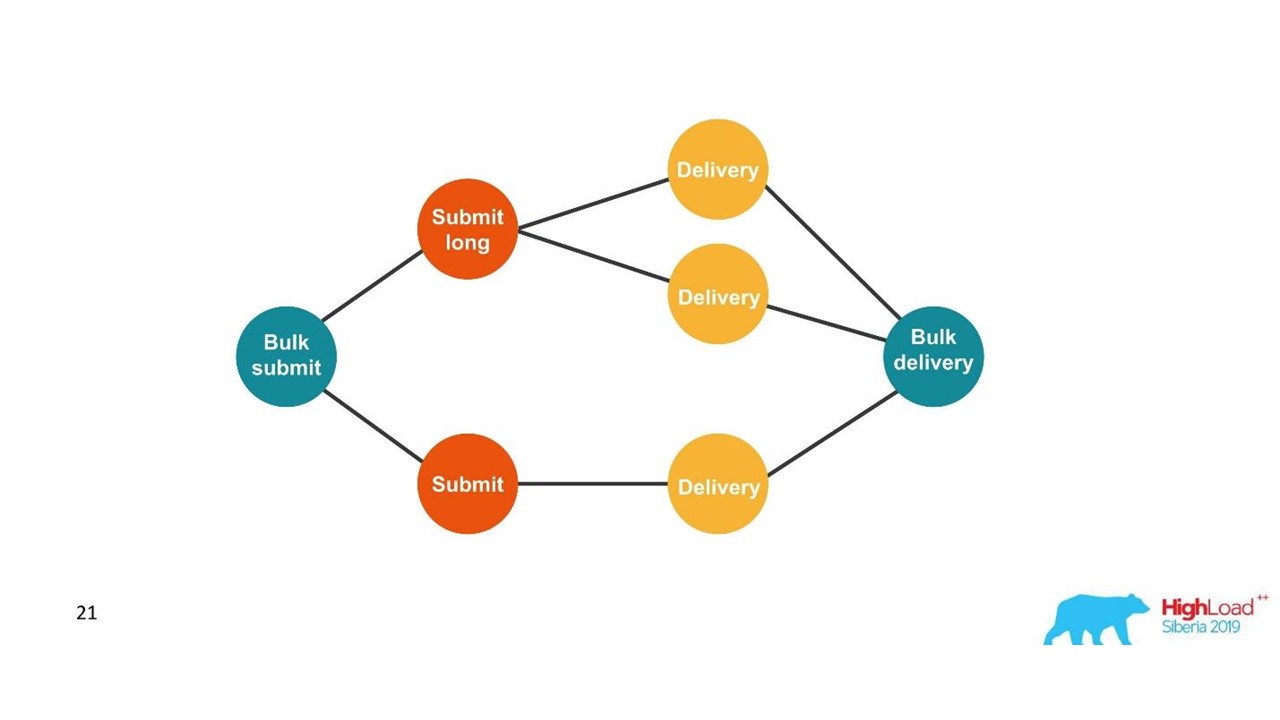 Nous construisons un graphique.
Nous construisons un graphique.Une fois que nous voyons un graphique, alors un choix adéquat est les bases de données graphiques, par exemple, Neo4j. Le choix était évident car Neo4j offre des T-shirts sympas et des livres gratuits lors de conférences.
Neo4j
Nous avons implémenté Proof of Concept: un hôte 16 cœurs pouvant traiter un graphique de 100 millions de nœuds et 150 millions de liens. Le graphique n'occupait que 15 Go de disque - alors il nous convenait.
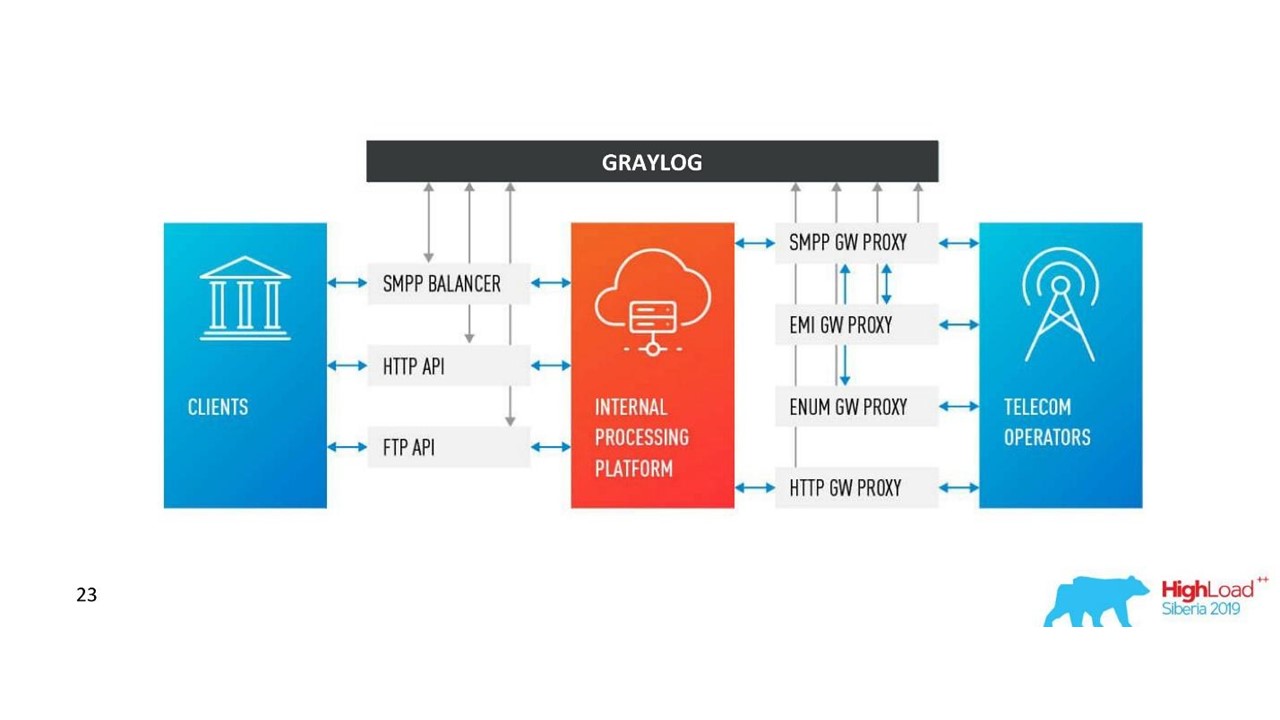 Notre décision. Architecture des journaux.
Notre décision. Architecture des journaux.En plus de Neo4j, nous avons maintenant une interface simple pour afficher les journaux associés. Avec lui, les ingénieurs voient la situation dans son ensemble.
Mais assez rapidement, nous avons été déçus par cette base de données.
Problèmes avec Neo4j
Rotation des données . Nous avons des volumes puissants et les données doivent être tournées. Mais lorsqu'un nœud est supprimé de Neo4j, les données sur le disque ne sont pas effacées. J'ai dû construire une solution complexe et reconstruire complètement les graphiques.
Performance . Toutes les bases de données graphiques sont en lecture seule. À l'enregistrement, les performances sont sensiblement inférieures. Notre cas est tout à fait le contraire: nous écrivons beaucoup et lisons relativement rarement - ce sont des unités de requêtes par seconde voire par minute.
Haute disponibilité et analyse de cluster moyennant des frais . À notre échelle, cela se traduit par des coûts décents.
Par conséquent, nous sommes allés dans l'autre sens.
Solution avec PostgreSQL
Nous avons décidé que, comme nous lisons rarement, le graphique peut être construit à la volée lors de la lecture. Ainsi, dans la base de données relationnelle PostgreSQL, nous stockons la liste d'adjacence de nos ID sous la forme d'une plaque simple avec deux colonnes et un index sur les deux. Lorsque la demande arrive, nous contournons le graphique de connectivité en utilisant l'algorithme DFS familier (traversée en profondeur) et obtenons tous les ID associés. Mais c'est nécessaire.
La rotation des données est également facile à résoudre. Pour chaque jour, nous commençons une nouvelle plaque et après quelques jours, le moment venu, nous la supprimons et libérons les données. Une solution simple.
Nous avons maintenant 850 millions de connexions dans PostgreSQL, elles occupent 100 Go de disque. Nous y écrivons à une vitesse de 30 000 par seconde, et pour cela dans la base de données, il n'y a que deux VM avec 2 CPU et 6 Go de RAM. Au besoin, PostgreSQL peut écrire des longs longs.
Il existe encore de petites machines pour le service lui-même, qui tournent et contrôlent.
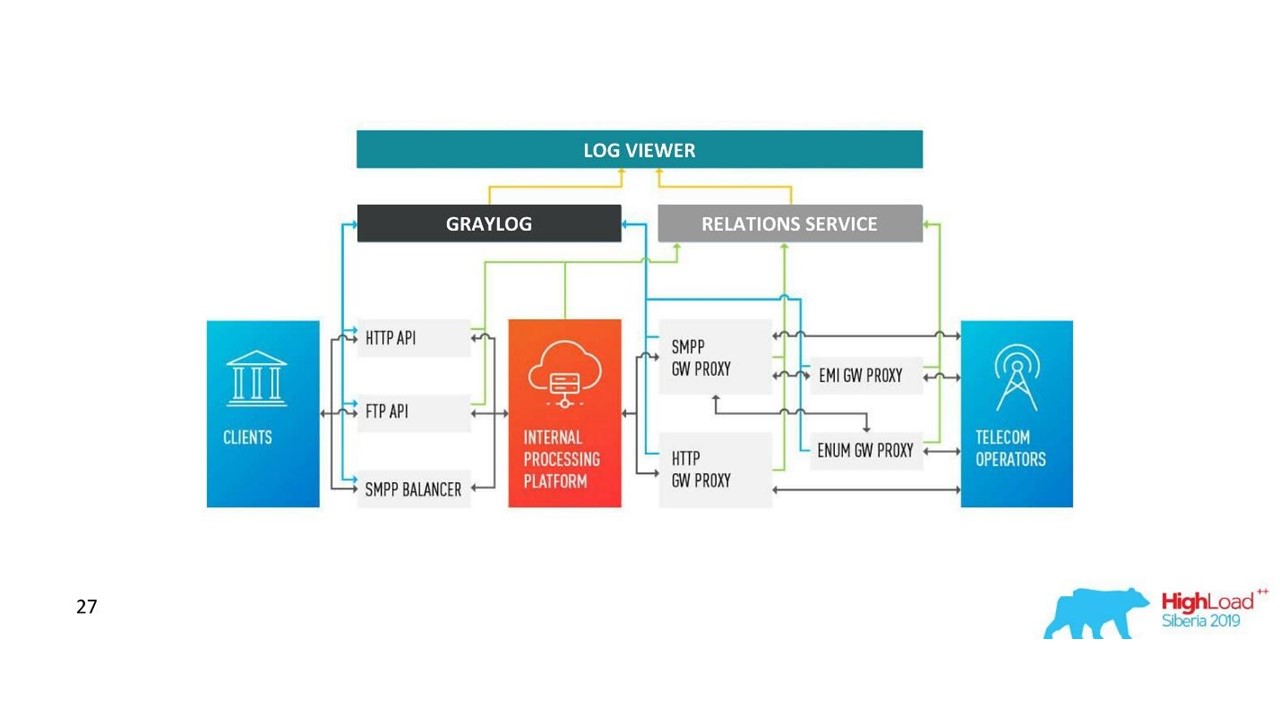 Comment notre architecture a changé.
Comment notre architecture a changé.Défis avec Graylog
La société a grandi, de nouveaux centres de données sont apparus, la charge a considérablement augmenté, même avec une solution avec des journaux de communication. Nous pensions que Graylog n'est plus parfait.
Schéma unifié et centralisation . J'aimerais avoir un outil de gestion de cluster unique dans 10 centres de données. En outre, la question s'est posée d'un schéma de cartographie des données unifié afin qu'il n'y ait pas de collisions.
API Nous utilisons notre propre interface pour afficher les connexions entre les journaux et l'API Graylog standard n'était pas toujours pratique à utiliser, par exemple, lorsque vous devez afficher des données de différents centres de données, les trier et les marquer correctement. Par conséquent, nous voulions pouvoir changer l'API à notre guise.
Les performances, il est difficile d'évaluer la perte . Notre trafic est de 3 To de journaux par jour, ce qui est décent. Par conséquent, Graylog n'a pas toujours fonctionné de manière stable, il a fallu entrer dans ses entrailles afin de comprendre les causes des pannes. Il s'est avéré que nous ne l'utilisions plus comme un outil - nous devions y faire quelque chose.
Retards de traitement (files d'attente) . Nous n'avons pas aimé l'implémentation standard de la file d'attente dans Graylog.
La nécessité de supporter MongoDB . Graylog traîne MongoDB, il fallait aussi administrer ce système.
Nous avons réalisé qu'à ce stade, nous voulons notre propre solution. Il y a peut-être moins de fonctionnalités intéressantes pour les alertes qui n'ont pas été utilisées, pour les tableaux de bord, mais les leurs sont meilleures.
Notre décision
Nous avons développé notre propre service Logs.
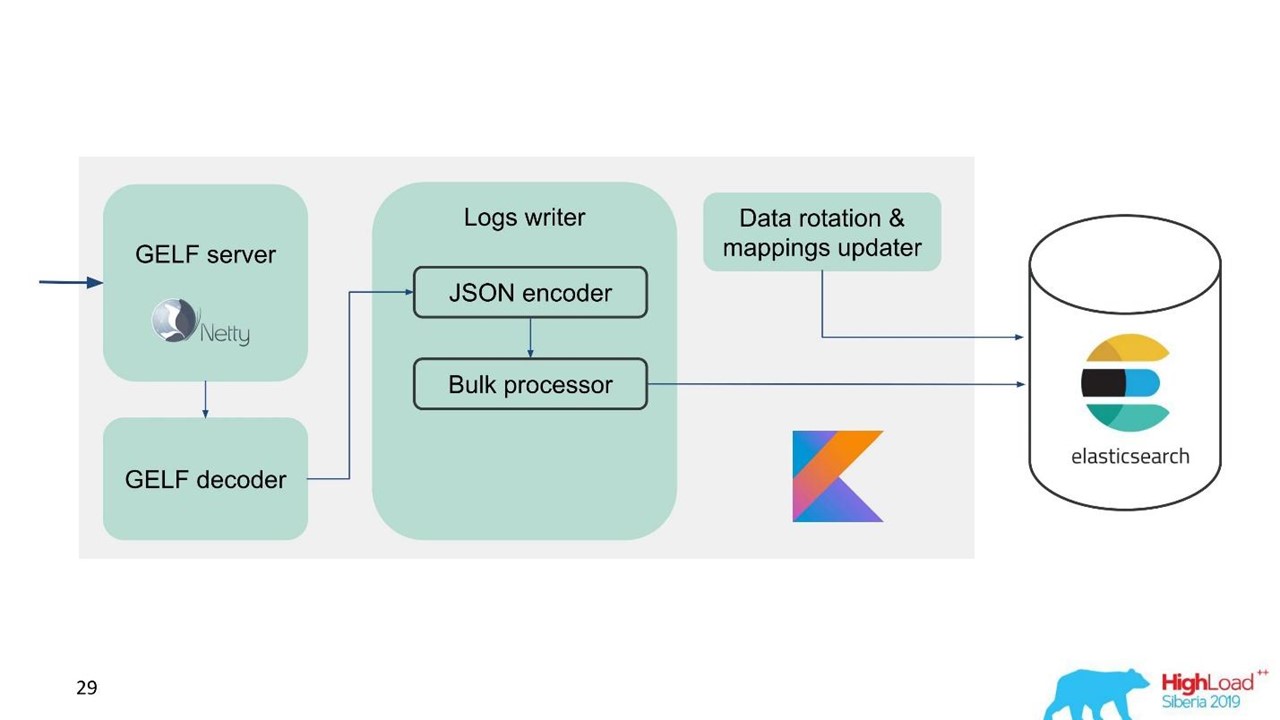 Service de journalisation.
Service de journalisation.À ce moment-là, nous avions déjà une expertise dans le service et la maintenance de grands clusters Elasticsearch, nous avons donc pris Elasticsearch comme base. La pile standard de l'entreprise est JVM, mais pour le backend, nous utilisons également Kotlin de manière célèbre, nous avons donc pris ce langage pour le service.
La première question est de savoir comment faire pivoter les données et que faire de la cartographie. Nous utilisons une cartographie fixe. Dans Elasticsearch, il est préférable d'avoir des index de même taille. Mais avec de tels indices, nous devons en quelque sorte cartographier les données, en particulier pour plusieurs centres de données, un système distribué et un état distribué. Il y avait des idées pour fixer ZooKeeper, mais c'est encore une complication de maintenance et de code.
Par conséquent, nous avons décidé simplement - écrire à temps.
Un index pendant une heure, dans d'autres centres de données 2 index pendant une heure, dans le troisième index pendant 3 heures, mais tout le temps. Les indices sont obtenus en différentes tailles, car la nuit, le trafic est inférieur à celui de la journée, mais en général cela fonctionne. L'expérience a montré qu'aucune complication n'est nécessaire.
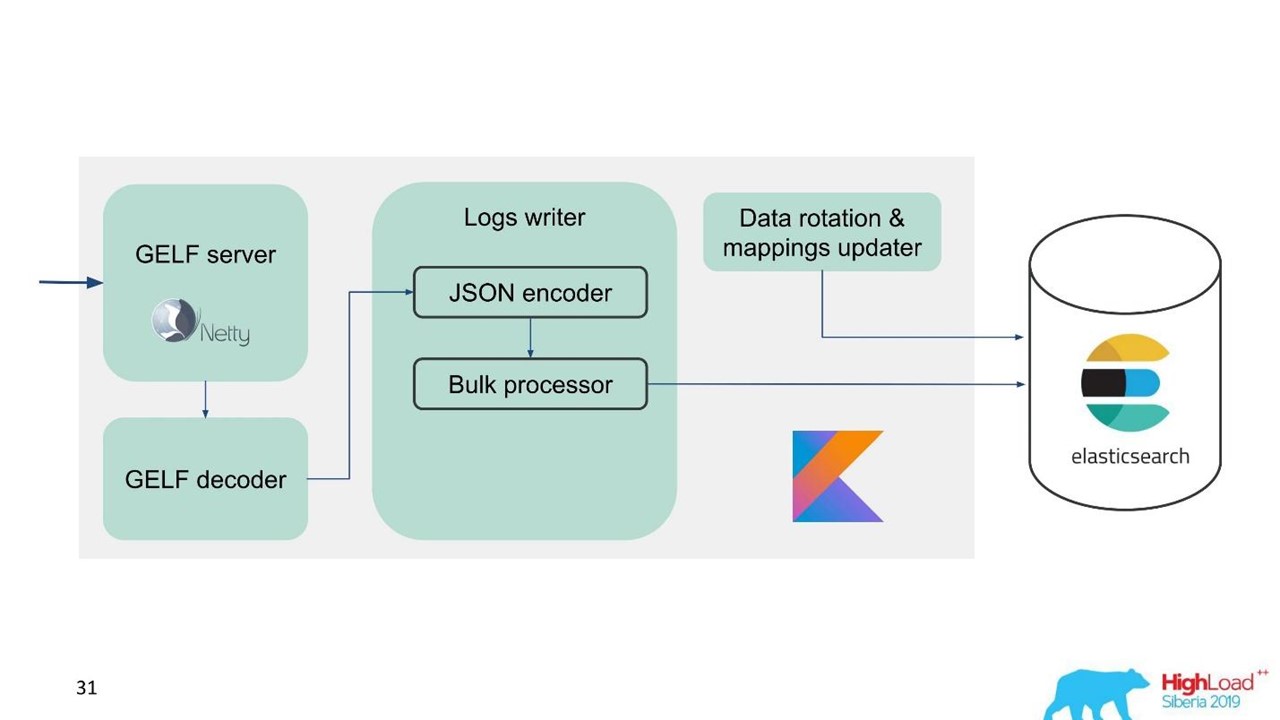
Pour faciliter la migration et compte tenu de la grande quantité de données, nous avons choisi le protocole GELF, un protocole Graylog simple basé sur TCP. Nous avons donc obtenu un serveur GELF pour Netty et un décodeur GELF.
Ensuite, JSON est codé pour écrire dans Elasticsearch. Nous utilisons l'API Java officielle d'Elasticsearch et écrivons en vrac.
Pour une vitesse d'enregistrement élevée, vous devez écrire Bulk'ami.
Il s'agit d'une optimisation importante. L'API fournit un processeur en bloc qui accumule automatiquement les demandes, puis les envoie pour enregistrement dans un ensemble ou au fil du temps.
Problème avec le processeur en vrac
Tout semble aller bien. Mais nous avons commencé et réalisé que nous nous reposions sur le processeur Bulk - c'était inattendu. Nous ne pouvons pas atteindre les valeurs sur lesquelles nous comptions - le problème est venu de nulle part.
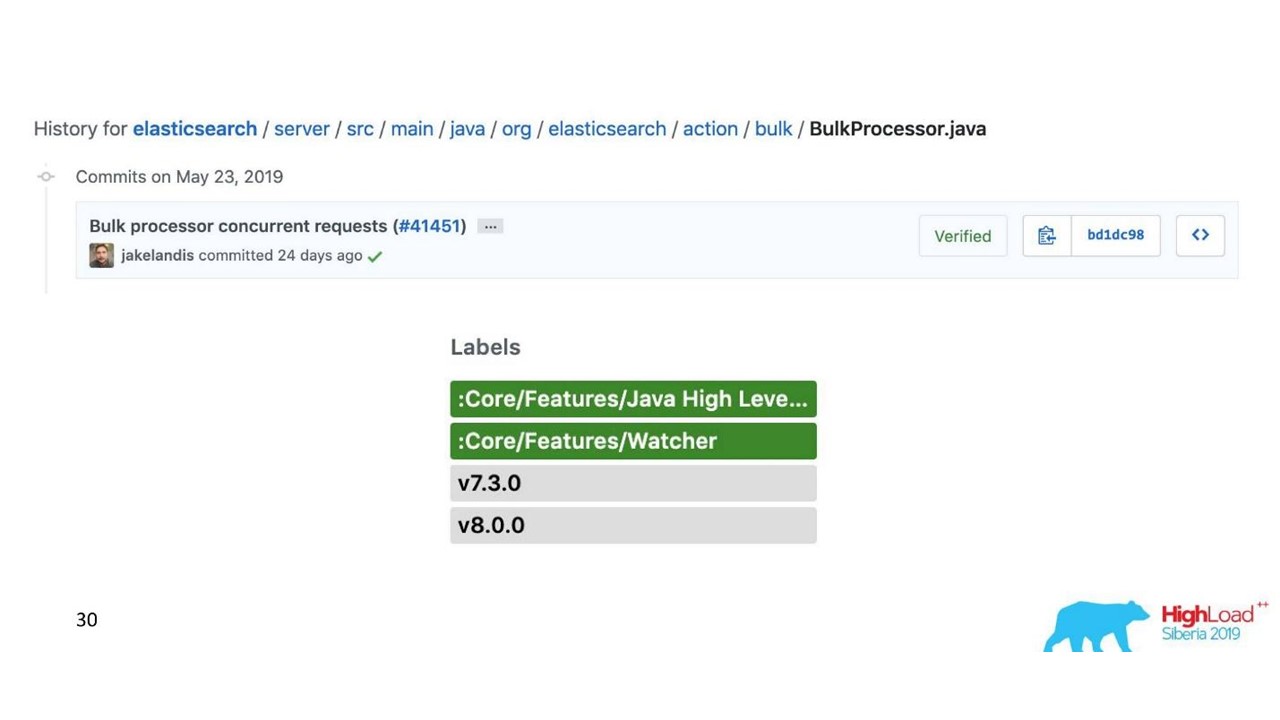
Dans l'implémentation standard, le processeur Bulk est un thread unique, synchrone, malgré le fait qu'il existe un paramètre de parallélisme. C'était ça le problème.
Nous avons fouillé et il s'est avéré qu'il s'agit d'un bogue connu mais non résolu. Nous avons un peu changé le processeur Bulk - nous avons fait un verrou explicite via ReentrantLock. Ce n'est qu'en mai que des modifications similaires ont été apportées au référentiel officiel d'Elasticsearch et ne seront disponibles qu'à partir de la version 7.3. La version actuelle est 7.1, et nous utilisons la version 6.3.
Si vous travaillez également avec un processeur en bloc et que vous souhaitez overclocker une entrée dans Elasticsearch - regardez ces
changements sur GitHub et
portez à votre version. Les modifications affectent uniquement le processeur Bulk. Il n'y aura aucune difficulté si vous devez porter sur la version ci-dessous.
Tout va bien, le processeur Bulk est parti, la vitesse s'est accélérée.
Les performances d'écriture d'Elasticsearch sont instables dans le temps, car diverses opérations s'y déroulent: fusion d'index, vidage. En outre, les performances ralentissent pendant un certain temps lors de la maintenance, lorsqu'une partie des nœuds est supprimée du cluster, par exemple.
À cet égard, nous avons réalisé que nous devons implémenter non seulement le tampon en mémoire, mais également la file d'attente. Nous avons décidé que nous n'enverrions que des messages rejetés à la file d'attente - uniquement ceux que le processeur de masse ne pouvait pas écrire dans Elasticsearch.
Réessayer le repli
Il s'agit d'une implémentation simple.
- Nous enregistrons les messages rejetés dans le fichier -
RejectedExecutionHandler .
- Soumettez à nouveau à l'intervalle spécifié dans un exécuteur distinct.
- Cependant, nous ne retardons pas le nouveau trafic.
Pour les ingénieurs de support et les développeurs, le nouveau trafic dans le système est nettement plus important que celui qui, pour une raison quelconque, a été retardé lors de la montée en puissance ou du ralentissement d'Elasticsearch. Il s'attarda, mais il reviendrait plus tard - ce n'était pas grave. Le nouveau trafic est priorisé.
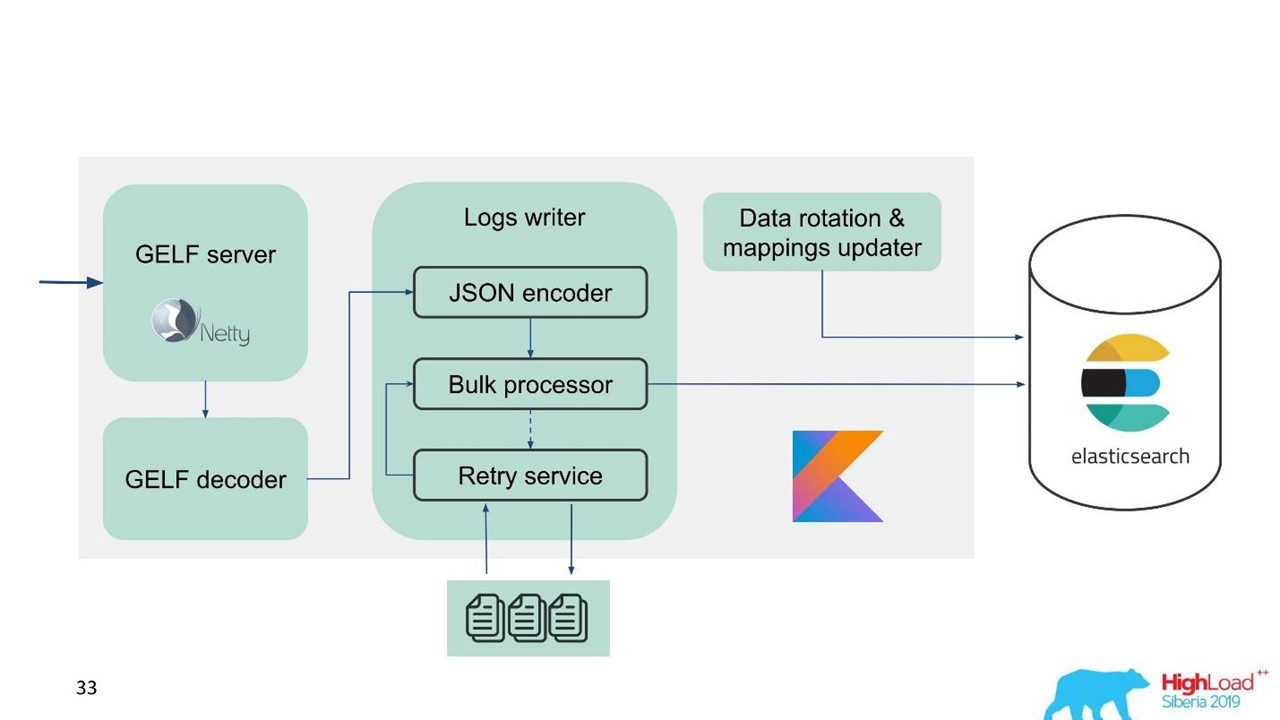 Notre schéma a commencé à ressembler à ceci.
Notre schéma a commencé à ressembler à ceci.Parlons maintenant de la façon dont nous préparons Elasticsearch, des paramètres que nous avons utilisés et de la configuration.
Configuration d'Elasticsearch
Le problème auquel nous sommes confrontés est la nécessité d'overclocker Elasticsearch et de l'optimiser pour l'écriture, car le nombre de lectures est sensiblement plus petit.
Nous avons utilisé plusieurs paramètres.
"ignore_malformed": true -
supprime les champs avec le mauvais type, et non le document entier . Nous voulons toujours stocker les données, même si, pour une raison quelconque, des champs avec un mappage incorrect y ont été divulgués. Cette option n'est pas entièrement liée aux performances.
Pour le fer, Elasticsearch a une nuance. Lorsque nous avons commencé à demander de gros clusters, on nous a dit que les matrices RAID à partir de disques SSD pour vos volumes coûtent terriblement cher. Mais les tableaux ne sont pas nécessaires car la tolérance aux pannes et le partitionnement sont déjà intégrés dans Elasticsearch. Même sur le site officiel, il est recommandé de prendre plus de fer bon marché que moins cher et bon. Cela s'applique à la fois aux disques et au nombre de cœurs de processeur, car l'ensemble Elasticsearch est très bien parallèle.
"index.merge.scheduler.max_thread_count": 1 -
recommandé pour le disque dur .
Si vous n'avez pas obtenu de SSD, mais des disques durs ordinaires, définissez ce paramètre sur un. Les index sont écrits en morceaux, puis ces morceaux sont figés. Cela économise un peu de disque, mais surtout accélère la recherche. En outre, lorsque vous arrêtez d'écrire dans l'index, vous pouvez
force merge . Lorsque la charge sur le cluster est moindre, il se bloque automatiquement.
"index.unassigned.node_left.delayed_timeout": "5m" -
retard de déploiement lorsqu'un nœud disparaît . C'est le temps après lequel Elasticsearch commencera à implémenter les index et les données si un nœud est redémarré, déployé ou retiré pour maintenance. Mais si vous avez une lourde charge sur le disque et le réseau, le déploiement est une opération difficile. Afin de ne pas les surcharger, cette temporisation est préférable pour contrôler et comprendre les retards nécessaires.
"index.refresh_interval": -1 -
ne met pas à jour les index s'il n'y a pas de requêtes de recherche . Ensuite, l'index sera mis à jour lorsqu'une requête de recherche apparaît. Cet index peut être défini en secondes et minutes.
"index.translogDurability": "async" - à quelle fréquence exécuter fsync: à chaque demande ou par heure. Donne des gains de performances pour les disques lents.
Nous avons également une manière intéressante de l'utiliser. Le support et les développeurs souhaitent pouvoir effectuer des recherches en texte intégral et utiliser regexp'ov dans tout le corps du message. Mais dans Elasticsearch, cela n'est pas possible - il ne peut rechercher que par jetons qui existent déjà dans son système. RegExp et le caractère générique peuvent être utilisés, mais le jeton ne peut pas démarrer avec certains RegExp. Par conséquent, nous avons ajouté
word_delimiter au filtre:
"tokenizer": "standard" "filter" : [ "word_delimiter" ]
Il divise automatiquement les mots en jetons:
- «Wi-Fi» → «Wi», «Fi»;
- "PowerShot" → "Power", "Shot";
- "SD500" → "SD", "500".
De manière similaire, le nom de la classe est écrit, diverses informations de débogage. Avec cela, nous avons résolu certains des problèmes liés à la recherche en texte intégral. Je vous conseille d'ajouter de tels paramètres lorsque vous travaillez avec la connexion.
À propos du cluster
Le nombre de fragments doit être égal au nombre de nœuds de données pour l'équilibrage de charge . Le nombre minimum de répliques est 1, puis chaque nœud aura un fragment principal et une réplique. Mais si vous avez des données précieuses, par exemple, des transactions financières, il vaut mieux en faire 2 ou plus.
La taille du fragment est de quelques Go à plusieurs dizaines de Go . Le nombre de fragments sur un nœud n'est pas supérieur à 20 pour 1 Go de hanche Elasticsearch, bien sûr. Elasticsearch ralentit davantage - nous l'avons également attaqué. Dans les centres de données où le trafic est faible, les données n'ont pas tourné en volume, des milliers d'index sont apparus et le système s'est écrasé.
Utilisez la allocation awareness , par exemple, par le nom d'un hyperviseur en cas de service. Aide à disperser les index et les fragments sur différents hyperviseurs afin qu'ils ne se chevauchent pas lorsqu'un hyperviseur tombe.
Créez des index au préalable . Bonne pratique, surtout lorsque vous écrivez à temps. L'index est immédiatement chaud, prêt et il n'y a aucun retard.
Limitez le nombre de fragments d'un index par nœud .
"index.routing.allocation.total_shards_per_node": 4 est le nombre maximal de fragments d'un index par nœud. Dans le cas idéal, il y en a 2, nous en mettons 4 juste au cas où, si nous avons encore moins de voitures.
Quel est le problème ici? Nous utilisons la
allocation awareness - Elasticsearch sait comment répartir correctement les index entre les hyperviseurs. Mais nous avons découvert qu'après avoir éteint le nœud pendant une longue période, puis revenir au cluster, Elasticsearch constate qu'il y a formellement moins d'index dessus et qu'ils sont restaurés. Tant que les données ne sont pas synchronisées, il existe officiellement peu d'index sur le nœud. Si nécessaire, allouez un nouvel index, Elasticsearch essaie de marteler cette machine aussi densément que possible avec de nouveaux index. Ainsi, un nœud reçoit une charge non seulement du fait que les données y sont répliquées, mais également avec du trafic frais, des index et de nouvelles données qui tombent sur ce nœud. Contrôlez et limitez-le.
Recommandations de maintenance Elasticsearch
Ceux qui travaillent avec Elasticsearch connaissent ces recommandations.
Pendant la maintenance planifiée, appliquez les recommandations de mise à niveau progressive: désactivez l'allocation des partitions, vidage synchronisé.
Désactivez l'allocation des fragments . Désactivez l'allocation des fragments de répliques, laissez la capacité d'allouer uniquement le primaire. Cela aide sensiblement Elasticsearch - il ne réaffectera pas les données dont vous n'avez pas besoin. Par exemple, vous savez que dans une demi-heure, le nœud augmentera - pourquoi transférer tous les fragments d'un nœud à un autre? Rien de terrible ne se produira si vous vivez avec le cluster jaune pendant une demi-heure, lorsque seuls les fragments primaires sont disponibles.
Rinçage synchronisé . Dans ce cas, le nœud se synchronise beaucoup plus rapidement lorsqu'il revient dans le cluster.
Avec une lourde charge d'écriture dans l'index ou de récupération, vous pouvez réduire le nombre de répliques.
Si vous téléchargez une grande quantité de données, par exemple la charge de pointe, vous pouvez désactiver les fragments et donner ensuite une commande à Elasticsearch pour les créer lorsque la charge est déjà moindre.
Voici quelques commandes que j'aime utiliser:
GET _cat/thread_pool?v - vous permet de voir thread_pool sur chaque nœud: ce qui est chaud maintenant, quelles sont les files d'attente d'écriture et de lecture.
GET _cat/recovery/?active_only=true - quels index sont déployés où, où la récupération a lieu.
GET _cluster/allocation/explain - sous une forme humaine pratique pourquoi et quels index ou répliques n'ont pas été alloués.
Pour la surveillance, nous utilisons Grafana.
 Vincent van Hollebeke
Vincent van Hollebeke offre un excellent
exportateur et un esprit d'équipe Grafana, qui vous permet de voir visuellement l'état du cluster et tous ses principaux paramètres. Nous l'avons ajouté à notre image Docker et à toutes les métriques lors du déploiement à partir de notre box.
Conclusions de journalisation
Les journaux doivent être:
- centralisé - un point d'entrée unique pour les développeurs;
- disponible - la possibilité de rechercher rapidement;
- structuré - pour l'extraction rapide et pratique d'informations précieuses;
- en corrélation - non seulement entre eux, mais aussi avec d'autres mesures et systèmes que vous utilisez.
Le concours suédois
Melodifestivalen a récemment eu lieu. Ceci est une sélection de représentants de la Suède pour l'Eurovision. Avant la compétition, notre service d'assistance nous a contactés: «Maintenant, en Suède, il y aura une grosse charge. Le trafic est assez sensible et nous voulons corréler certaines données. Vous avez des données dans les journaux qui manquent sur le tableau de bord Grafana. Nous avons des mesures qui peuvent être extraites de Prometheus, mais nous avons besoin de données sur des demandes d'identification spécifiques. »
Ils ont ajouté Elasticsearch comme source de Grafana et ont pu corréler ces données, résoudre le problème et obtenir de bons résultats assez rapidement.
Il est beaucoup plus facile d'exploiter vos propres solutions.
Maintenant, au lieu des 10 clusters Graylog qui ont fonctionné pour cette solution, nous avons plusieurs services. Ce sont 10 centres de données, mais nous n'avons même pas une équipe dédiée et des personnes qui les servent. Plusieurs personnes y ont travaillé et ont changé quelque chose au besoin. Cette petite équipe est parfaitement intégrée à notre infrastructure - le déploiement et l'entretien sont plus faciles et moins chers.
Séparez les cas et utilisez les outils appropriés.
Ce sont des outils distincts pour la journalisation, le suivi et la surveillance. Il n'y a pas d '«instrument d'or» qui couvrira tous vos besoins.
Pour comprendre quel outil est nécessaire, ce qu'il faut surveiller, quels journaux utiliser, quelles exigences de journal, vous devez absolument vous référer à
SLI / SLO - Indicateur de niveau de service / objectif de niveau de service. Vous devez savoir ce qui est important pour vos clients et votre entreprise, quels indicateurs ils examinent.
Une semaine plus tard, SKOLKOVO hébergera HighLoad ++ 2019 . Dans la soirée du 7 novembre, Ivan Letenko vous racontera comment il vit avec Redis sur la prod, et au total il y a 150 reportages au programme sur une variété de sujets.
Si vous rencontrez des problèmes pour visiter HighLoad ++ 2019 en direct, nous avons de bonnes nouvelles. Cette année, la conférence se tiendra dans trois villes à la fois - à Moscou, Novossibirsk et Saint-Pétersbourg. En même temps. Comment cela se fera et comment s'y rendre - découvrez-le sur une page promotionnelle distincte de l' événement.