La puissance de JavaScript et de l'API du navigateurLe monde devient de plus en plus interconnecté - le nombre de personnes ayant accès à Internet est passé à
4,5 milliards .
Mais ces données ne reflètent pas le nombre de personnes qui ont une connexion Internet lente ou interrompue. Même aux États-Unis,
4,9 millions de foyers ne peuvent pas accéder à Internet câblé à des vitesses supérieures à 3 mégabits par seconde.
Le reste du monde - ceux qui ont un accès fiable à Internet - est toujours enclin à perdre la connectivité.
Certains facteurs peuvent affecter la qualité de votre connexion réseau:
- Mauvaise couverture du fournisseur.
- Conditions météorologiques extrêmes.
- Coupures de courant.
- Les utilisateurs qui tombent dans des zones mortes, comme les bâtiments qui bloquent leurs connexions réseau.
- Voyage en train et voyage en tunnel.
- Connexions contrôlées par un tiers et limitées dans le temps.
- Pratiques culturelles qui nécessitent un accès Internet limité ou inexistant à des heures ou des jours spécifiques.
Compte tenu de cela, il est clair que nous devons considérer l'expérience autonome lors du développement et de la création d'applications.

Cet article a été traduit avec le soutien d'EDISON Software, une société qui effectue d'excellentes commandes depuis le sud de la Chine , et développe également des applications et des sites Web .
J'ai récemment eu l'opportunité d'ajouter de l'autonomie à une application existante en utilisant des travailleurs de service, le stockage en cache et IndexedDB. Le travail technique nécessaire pour que l'application fonctionne hors ligne a été réduit à quatre tâches distinctes, dont je parlerai dans cet article.
Travailleurs des services
Les applications créées pour une utilisation hors ligne ne doivent pas dépendre fortement du réseau. Conceptuellement, cela n'est possible que si, en cas de panne, des options de sauvegarde existent.
Si l'application Web ne parvient pas à se charger, nous devons prendre les ressources du navigateur quelque part (HTML / CSS / JavaScript). D'où viennent ces ressources, sinon d'une demande de réseau? Que diriez-vous d'un cache. La plupart des gens conviendront qu'il est préférable de fournir une interface utilisateur potentiellement obsolète qu'une page vierge.
Le navigateur interroge constamment les données. Le service de mise en cache des données en tant que solution de rechange nous oblige toujours à intercepter les demandes du navigateur et à écrire des règles de mise en cache. C'est là que les travailleurs des services entrent en jeu - considérez-les comme un intermédiaire.
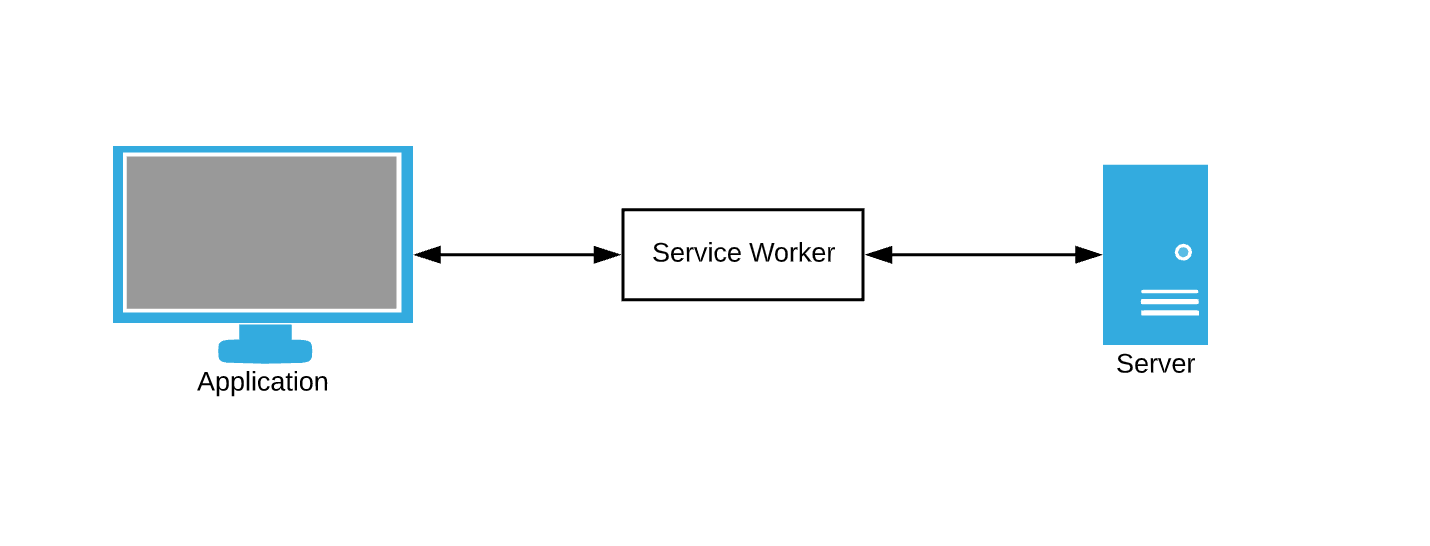
Le service worker est juste un fichier JavaScript dans lequel nous pouvons nous abonner aux événements et écrire nos propres règles pour la mise en cache et la gestion des pannes de réseau.
Commençons.
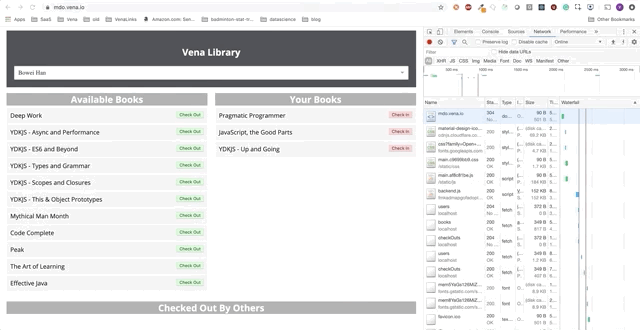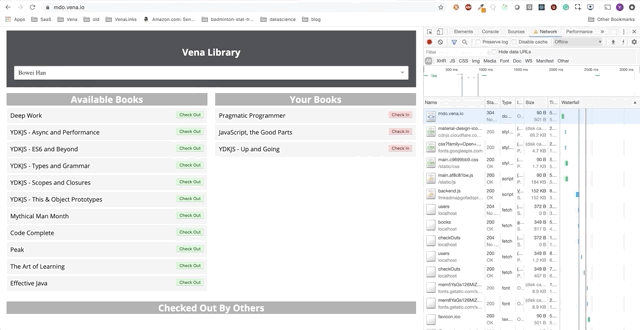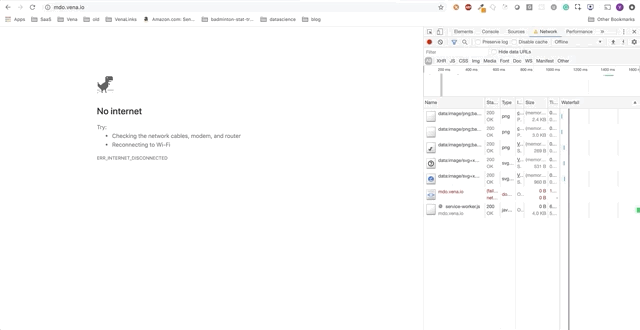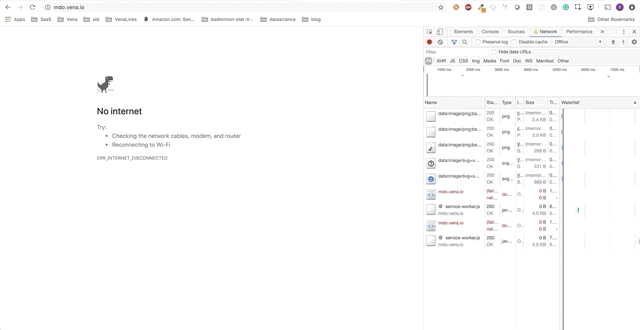
Veuillez noter: notre application de démonstrationTout au long de cet article, nous ajouterons des fonctions autonomes à l'application de démonstration. L'application de démonstration est une page simple pour prendre / louer des livres dans la bibliothèque. Les progrès seront présentés sous la forme d'une série de GIF et l'utilisation de simulations Chrome DevTools hors ligne.
Voici l'état initial:
Tâche 1 - Mise en cache des ressources statiques
Les ressources statiques sont des ressources qui ne changent pas souvent. HTML, CSS, JavaScript et les images peuvent entrer dans cette catégorie. Le navigateur essaie de charger des ressources statiques à l'aide de requêtes pouvant être interceptées par le technicien de service.
Commençons par inscrire notre technicien.
if ('serviceWorker' in navigator) { window.addEventListener('load', function() { navigator.serviceWorker.register('/sw.js'); }); }
Les employés de service sont
des employés Web sous le capot et doivent donc être importés à partir d'un fichier JavaScript distinct. L'inscription a lieu en utilisant la méthode d'
register après le chargement du site.
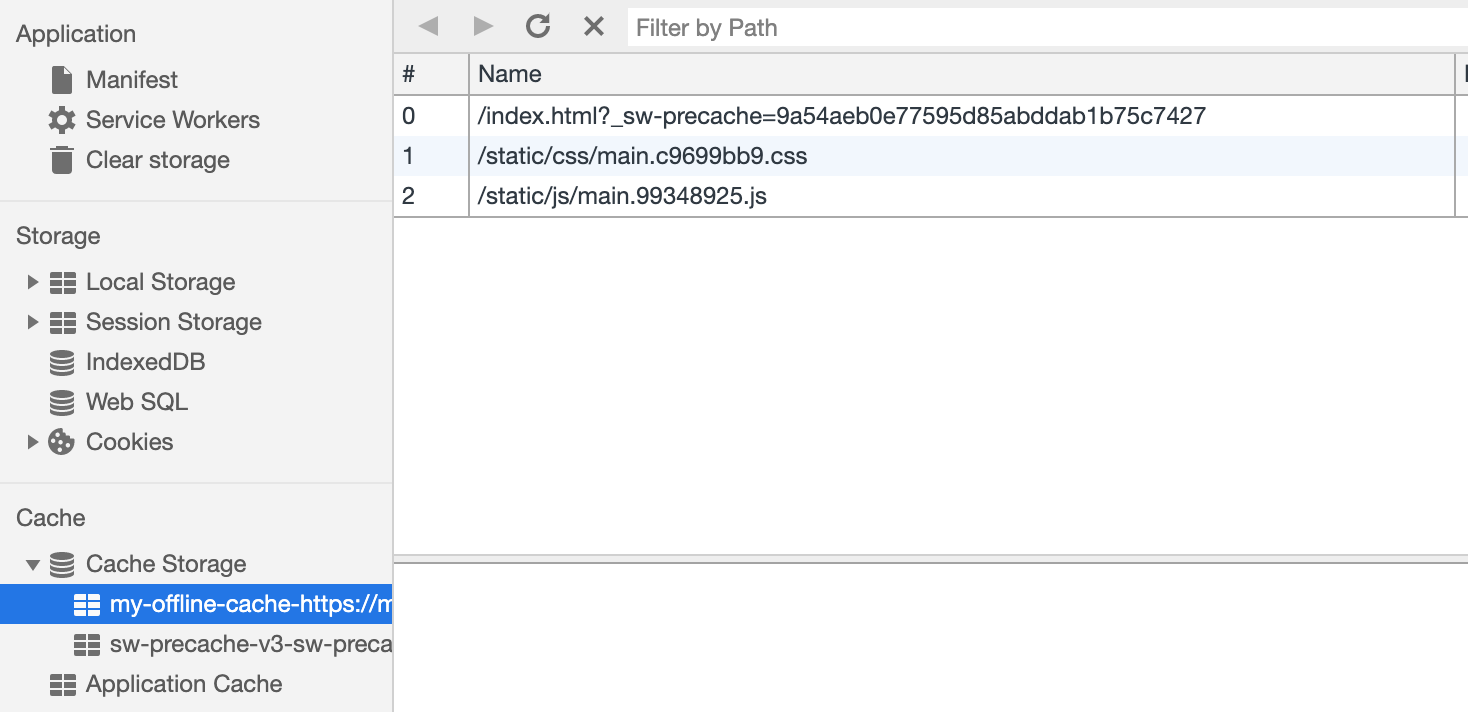
Maintenant que nous avons chargé un technicien de service, mettons en cache nos ressources statiques.
var CACHE_NAME = 'my-offline-cache'; var urlsToCache = [ '/', '/static/css/main.c9699bb9.css', '/static/js/main.99348925.js' ]; self.addEventListener('install', function(event) { event.waitUntil( caches.open(CACHE_NAME) .then(function(cache) { return cache.addAll(urlsToCache); }) ); });
Étant donné que nous contrôlons les URL des ressources statiques, nous pouvons les mettre en cache immédiatement après l'initialisation du technicien de service à l'aide du
Cache Storage .
Maintenant que notre cache est plein des ressources statiques les plus récemment demandées, chargeons ces ressources à partir du cache en cas d'échec d'une demande.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
L'événement
fetch est déclenché chaque fois que le navigateur fait une demande. Notre nouveau gestionnaire d'événements d'
fetch dispose désormais d'une logique supplémentaire pour renvoyer les réponses mises en cache en cas de pannes de réseau.
Démo numéro 1
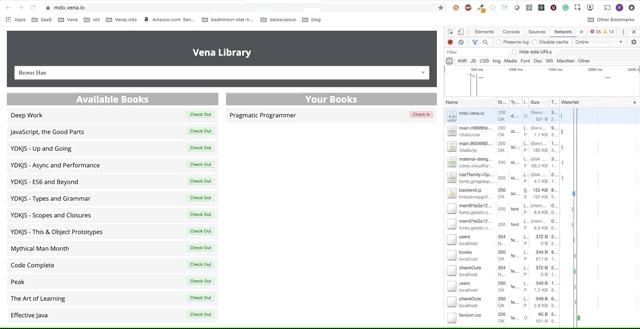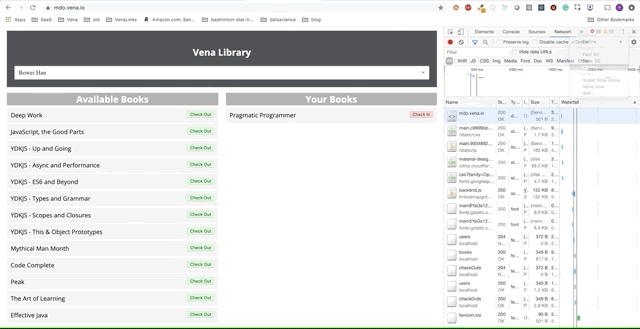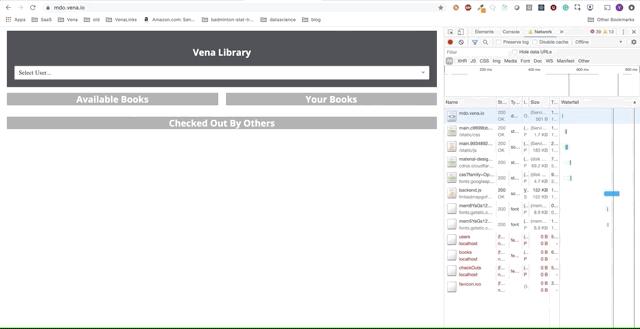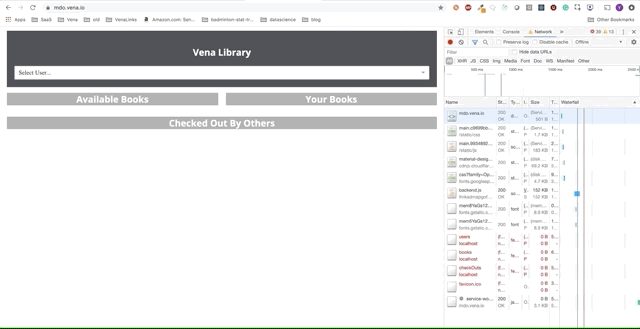
Notre application de démonstration peut désormais servir des ressources statiques hors ligne! Mais où sont nos données?
Tâche 2 - Mise en cache des ressources dynamiques
Les applications monopages (SPA) demandent généralement des données progressivement après le chargement initial de la page, et notre application de démonstration ne fait pas exception - la liste des livres n'est pas chargée immédiatement. Ces données proviennent généralement de demandes XHR qui renvoient des réponses qui changent fréquemment pour fournir un nouvel état à l'application - elles sont donc dynamiques.
La mise en cache des ressources dynamiques est en fait très similaire à la mise en cache des ressources statiques - la principale différence est que nous devons mettre à jour le cache plus souvent. Il est également assez difficile de générer une liste complète de toutes les demandes XHR dynamiques possibles, nous allons donc les mettre en cache à leur arrivée, et nous n'aurons pas de liste prédéfinie, comme nous l'avons fait pour les ressources statiques.
Jetez un œil à notre gestionnaire d'
fetch :
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
Nous pouvons personnaliser cette implémentation en ajoutant du code qui met en cache les demandes et réponses réussies. Cela garantit que nous ajoutons constamment de nouvelles demandes à notre cache et mettons constamment à jour les données mises en cache.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request) .then(function(response) { caches.open(CACHE_NAME).then(function(cache) { cache.put(event.request, response); }); }) .catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
Notre
Cache Storage actuellement plusieurs entrées.

Démo numéro 2
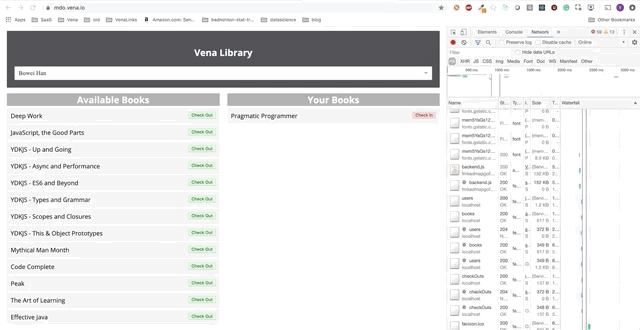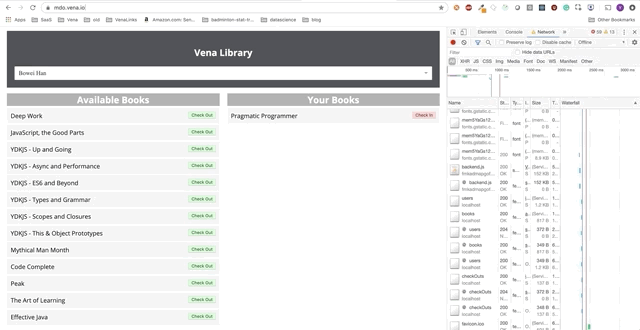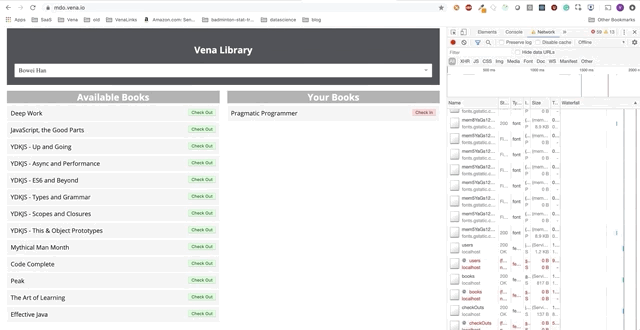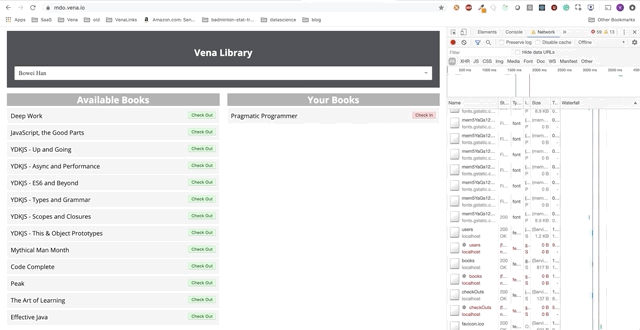
Notre démo est maintenant la même au démarrage, quel que soit l'état de notre réseau!
Super. Essayons maintenant d'utiliser notre application.
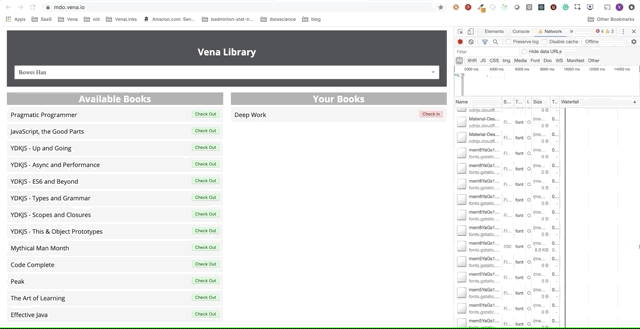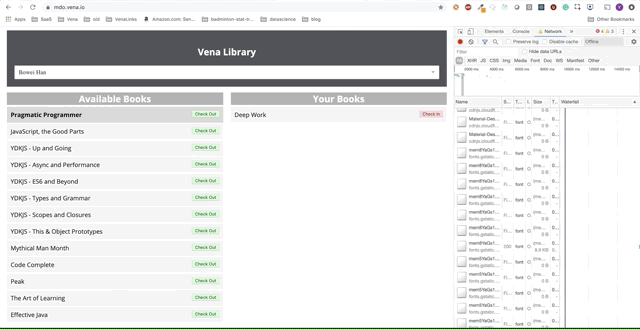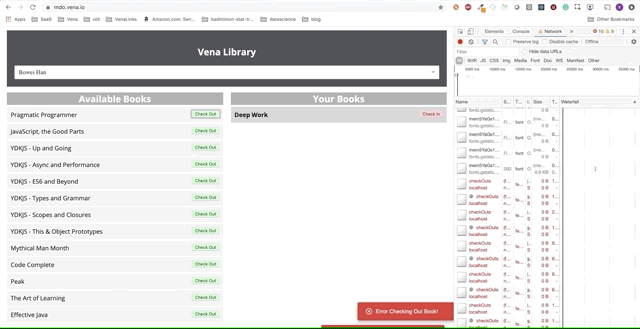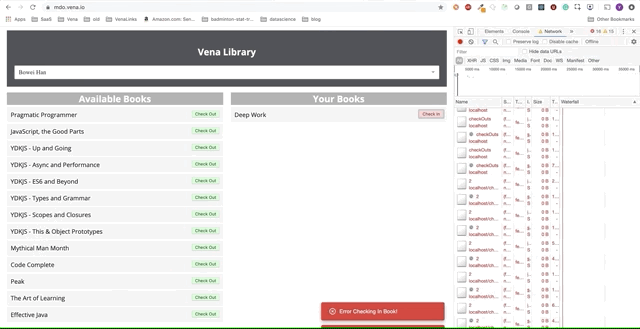
Malheureusement, les messages d'erreur sont partout. Il semble que toutes nos interactions avec l'interface ne fonctionnent pas. Je ne peux pas choisir ou remettre le livre! Que faut-il corriger?
Tâche 3 - Créer une interface utilisateur optimiste
À l'heure actuelle, le problème de notre application est que notre logique de collecte de données dépend toujours fortement des réponses du réseau. L'action d'archivage ou d'extraction envoie une demande au serveur et attend une réponse réussie. C'est idéal pour la cohérence des données, mais mauvais pour notre expérience autonome.
Pour que ces interactions fonctionnent hors ligne, nous devons rendre notre application plus
optimiste . Les interactions optimistes ne nécessitent pas de réponse du serveur et affichent volontiers une vue mise à jour des données. L'opération optimiste habituelle dans la plupart des applications Web est la
delete - pourquoi ne pas donner à l'utilisateur une rétroaction instantanée si nous avons déjà toutes les informations nécessaires?
Déconnecter notre application du réseau en utilisant une approche optimiste est relativement facile à mettre en œuvre.
case CHECK_OUT_SUCCESS: case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, }; case CHECK_IN_SUCCESS: case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
La clé est de gérer les actions des utilisateurs de la même manière, que la requête réseau aboutisse ou non. L'extrait de code ci-dessus est tiré du réducteur redux de notre application,
SUCCESS et
FAILURE lancés en fonction de la disponibilité du réseau. Quelle que soit la manière dont la demande de réseau est traitée, nous allons mettre à jour notre liste de livres.
Démo numéro 3
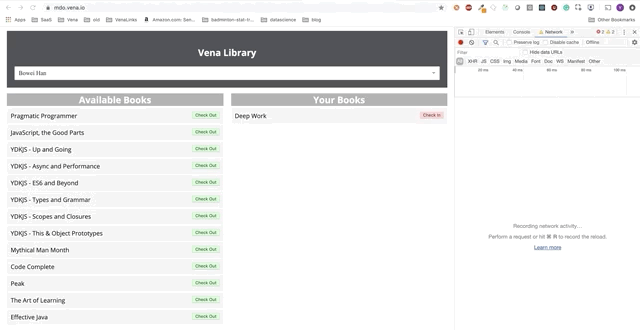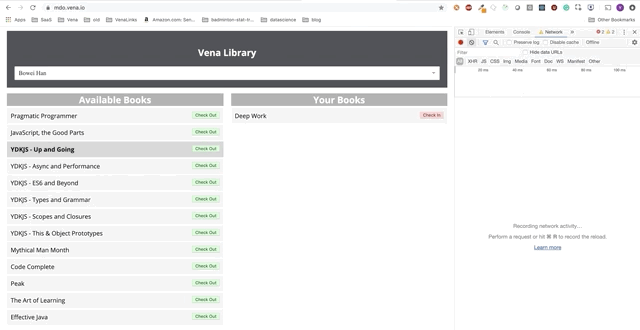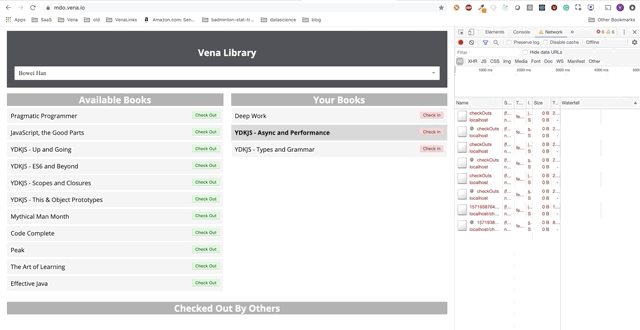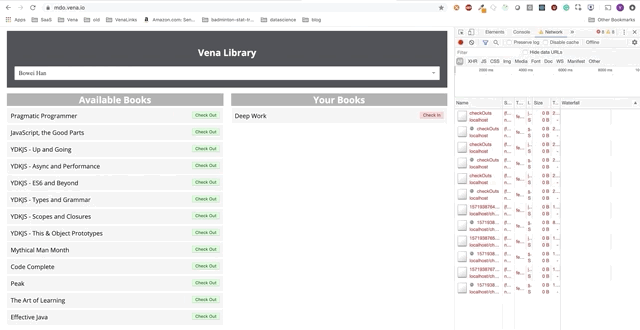
L'interaction des utilisateurs se produit désormais en ligne (pas littéralement). Les boutons «check-in» et «check-out» mettent à jour l'interface en conséquence, bien que les messages rouges de la console indiquent que les requêtes réseau ne sont pas exécutées.
Bon! Il n'y a qu'un petit problème avec le rendu hors ligne optimiste ...
Ne perdons-nous pas notre monnaie!?

Tâche 4 - Mettre en file d'attente les actions des utilisateurs pour la synchronisation
Nous devons suivre les actions effectuées par l'utilisateur lorsqu'il était hors ligne, afin de pouvoir les synchroniser avec notre serveur lorsque l'utilisateur revient sur le réseau. Il existe plusieurs mécanismes de stockage dans le navigateur qui peuvent agir comme une file d'attente d'actions, et nous allons utiliser IndexedDB. IndexedDB fournit quelques éléments que vous n'obtiendrez pas de LocalStorage:
- Opérations non bloquantes asynchrones
- Limites de stockage considérablement plus élevées
- Gestion des transactions
Regardez notre ancien code de réduction:
case CHECK_OUT_SUCCESS: case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, }; case CHECK_IN_SUCCESS: case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
Modifions-le pour stocker les événements d'archivage et d'extraction dans IndexedDB pendant l'événement
FAILURE .
case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); addToDB(action);
Voici l'implémentation de la création d'IndexedDB avec l'
addToDB addToDB.
let db = indexedDB.open('actions', 1); db.onupgradeneeded = function(event) { let db = event.target.result; db.createObjectStore('requests', { autoIncrement: true }); }; const addToDB = action => { var db = indexedDB.open('actions', 1); db.onsuccess = function(event) { var db = event.target.result; var objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.add(action); }; };
Maintenant que toutes nos actions utilisateur hors ligne sont stockées dans la mémoire du navigateur, nous pouvons utiliser l'écouteur d'événements du navigateur en
online pour synchroniser les données lorsque la connexion est rétablie.
window.addEventListener('online', () => { const db = indexedDB.open('actions', 1); db.onsuccess = function(event) { let db = event.target.result; let objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.getAll().onsuccess = function(event) { let requests = event.target.result; for (let request of requests) { send(request);
À ce stade, nous pouvons effacer la file d'attente de toutes les demandes que nous avons envoyées avec succès au serveur.
Démo numéro 4
La démo finale semble un peu plus compliquée. À droite, dans la fenêtre sombre du terminal, toute l'activité de l'API est enregistrée. La démo implique de se déconnecter, de sélectionner plusieurs livres et de revenir en ligne.
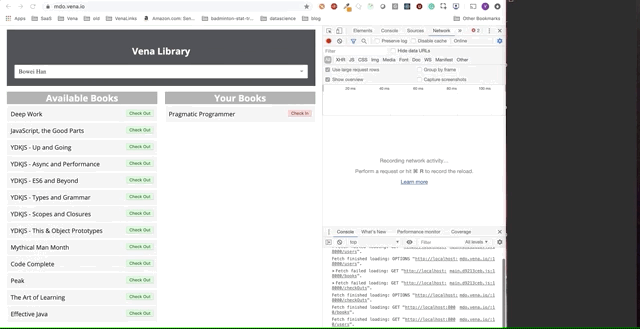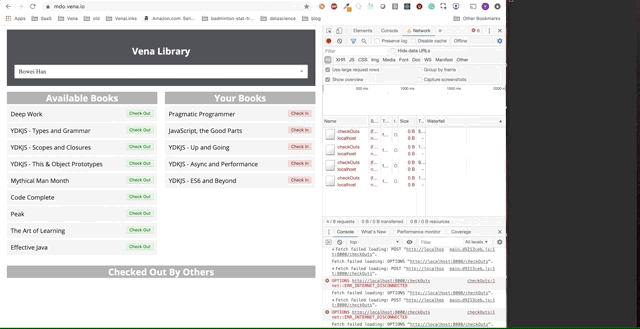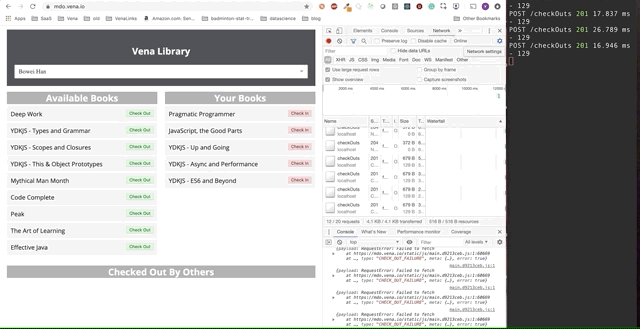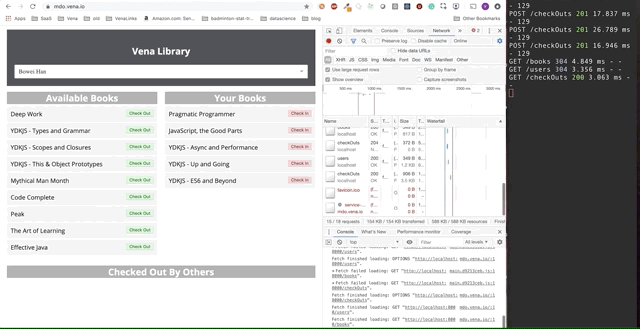
Il est clair que les demandes effectuées hors ligne ont été mises en file d'attente et envoyées immédiatement lorsque l'utilisateur revient en ligne.
Cette approche de «jeu» est un peu naïve - par exemple, nous n’aurons probablement pas besoin de faire deux demandes si nous prenons et retournons le même livre. Cela ne fonctionnera pas non plus si plusieurs personnes utilisent la même application.
C'est tout
Sortez et mettez vos applications Web hors ligne! Cet article montre certaines des nombreuses choses que vous pouvez faire pour ajouter des fonctionnalités autonomes à vos applications et n'est certainement pas exhaustif.
Pour en savoir plus, consultez
les principes de base de Google Web . Pour voir une autre implémentation hors ligne, consultez
cette présentation .

Lisez aussi le blog
Société EDISON:
20 bibliothèques pour
application iOS spectaculaire