Le 26 octobre, Linz am Rhein (Allemagne) a accueilli la mini-conférence HaxeUp Sessions 2019 consacrée à Haxe et aux technologies connexes. Et son événement le plus important a été, bien sûr, la version finale de Haxe 4.0.0 (au moment de la publication, c'est-à-dire après environ une semaine, la mise à jour 4.0.1 a été publiée ). Dans cet article, je voudrais vous présenter une traduction du premier rapport de la conférence - un rapport sur le travail effectué par l'équipe Haxe pour 2019.

Un peu sur l'auteur du rapport:
Simon travaille avec Haxe depuis 2010, alors qu'il était encore étudiant et a écrit un travail sur les simulations de fluides en Flash. La mise en œuvre d'une telle simulation a nécessité un accès constant aux données décrivant l'état des particules (à chaque étape, plus de 100 requêtes ont été effectuées sur des tableaux de données sur l'état de chaque cellule de la simulation), alors que travailler avec des tableaux dans ActionScript 3 n'est pas si rapide. Par conséquent, l'implémentation initiale était tout simplement inopérante et devait trouver une solution à ce problème. Dans sa recherche, Simon est tombé sur un article de Nicolas Kannass (créateur de Haxe) sur les opcodes d'alchimie alors non documentés qui n'étaient pas disponibles en utilisant ActionScript, mais Haxe a autorisé leur utilisation. Réécrivant la simulation sur Haxe en utilisant des opcodes, Simon a obtenu une simulation de travail! Et donc, grâce aux tableaux lents en ActionScript, Simon a découvert Haxe.
Depuis 2011, Simon a rejoint le développement de Haxe, il a commencé à étudier OCaml (sur lequel le compilateur est écrit) et à apporter diverses corrections au compilateur.
Et depuis 2012, il est devenu le principal développeur de compilateurs. La même année, la Fondation Haxe a été créée (une organisation dont les principaux objectifs sont le développement et la maintenance de l'écosystème Haxe, aider la communauté à organiser des conférences, des services de conseil), et Simon est devenu l'un de ses co-fondateurs.

En 2014-2015, Simon a invité Joséphine Pertosa à la Fondation Haxe, qui au fil du temps est devenue responsable de l'organisation de conférences et des relations communautaires.
En 2016, Simon a fait sa première présentation sur Haxe , et en 2018 a organisé les premières sessions HaxeUp .

Alors, que s'est-il passé dans le monde d'Haxe au cours de la dernière année 2019?
En février et mars, 2 candidats à la libération sont sortis (4.0.0-rc1 et 4.0.0-rc2)
En avril, Aurel Bili (en tant que stagiaire) et Alexander Kuzmenko (en tant que développeur de compilateurs) ont rejoint l'équipe de la Fondation Haxe.
En mai, le sommet américain Haxe 2019 s'est tenu .
En juin, Haxe 4.0.0-rc3 est sorti. Et en septembre - Haxe 4.0.0-rc4 et Haxe 4.0.0-rc5.

Haxe n'est pas seulement un compilateur, mais aussi un ensemble complet d'outils divers, et tout au long de l'année, un travail sur eux a également été constamment effectué:
Grâce aux efforts d' Andy Lee, Haxe utilise désormais Azure Pipelines au lieu de Travis CI et AppVeyor. Cela signifie que l'assemblage et les tests automatisés sont désormais beaucoup plus rapides.
Hugh Sanderson continue de travailler sur hxcpp (une bibliothèque pour prendre en charge C ++ dans Haxe).
Soudain, les utilisateurs de Github terurou et takashiski ont rejoint le travail sur les externes pour Node.js.
Rudy Ges a travaillé sur des correctifs et des améliorations pour prendre en charge la cible C #.
George Corney continue de prendre en charge le générateur externe HTML.
Jens Fisher travaille sur vshaxe (une extension pour VS Code pour travailler avec Haxe) et sur de nombreux autres projets liés à Haxe.

Et le principal événement de l'année, bien sûr, a été la sortie tant attendue de Haxe 4.0.0 (ainsi que de neko 2.3.0), qui a accidentellement coïncidé avec le HaxeUp 2019 Linz :)

Simon a consacré l'essentiel du rapport aux nouvelles fonctionnalités de Haxe 4.0.0 (vous pouvez également en apprendre davantage à leur sujet dans le rapport d'Alexander Kuzmenko du dernier sommet américain de Haxe 2019).

Le nouvel interpréteur de macro eval est plusieurs fois plus rapide que l'ancien. Simon a parlé de lui en détail dans son discours au sommet de Haxe UE 2017 . Mais depuis lors, il a amélioré les capacités de débogage du code, corrigé de nombreux bugs, repensé l'implémentation des chaînes.
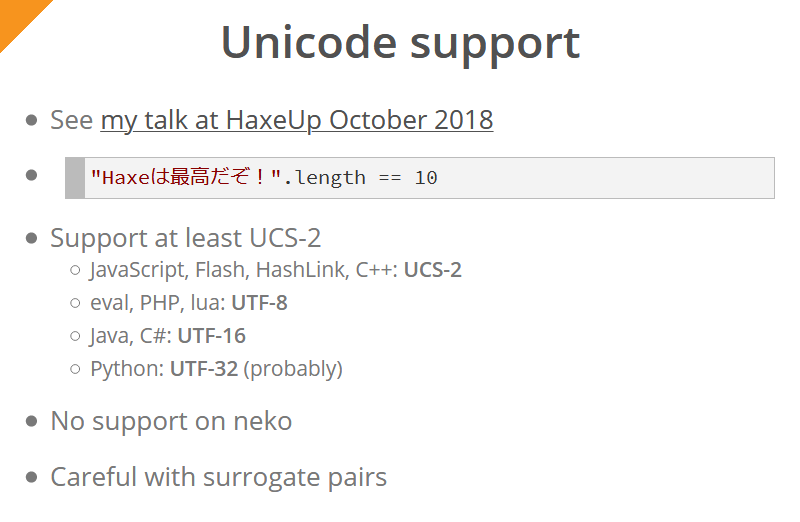
Haxe 4 introduit le support Unicode pour toutes les plateformes (sauf Neko). Simon l’a décrit en détail dans son discours de l’année dernière . Pour l'utilisateur final du compilateur, cela signifie que l'expression "Haxeは最高だぞ!".length de toutes les plates-formes renverra toujours 10 (encore une fois, sauf pour Neko).
L'encodage UCS-2 est peu pris en charge (un encodage nativement pris en charge est utilisé pour chaque plate-forme / langue; essayer de prendre en charge le même encodage partout ne serait pas pratique):
- JavaScript, Flash, HashLink et C ++ utilisent le codage UCS-2
- pour eval, PHP, lua - UTF-8
- pour Java et C # - UTF-16
- pour Python - UTF-32
Tous les caractères qui se trouvent en dehors du plan multilingue principal (y compris les emoji) sont représentés comme des «paires de substitution» - ces caractères sont représentés par deux octets. Par exemple, si en Java / C # / JavaScript (c'est-à-dire pour les chaînes dans les encodages UTF-16 et UCS-2) pour demander la longueur d'une chaîne composée d'un emoji, le résultat sera «2». Ce fait doit être pris en compte lorsque vous travaillez avec de telles chaînes sur ces plateformes.
Haxe 4 introduit un nouveau type d'itérateur - valeur-clé:

Il fonctionne avec des conteneurs de type Map (dictionnaires) et des chaînes (en utilisant la classe StringTools), la prise en charge des tableaux n'a pas encore été implémentée. Il est également possible d'implémenter un tel itérateur pour les classes personnalisées, pour cela il suffit d'implémenter la méthode keyValueIterator():KeyValueIterator<K, V> pour elles keyValueIterator():KeyValueIterator<K, V> .
La nouvelle balise meta @:using vous permet d'associer des extensions statiques à des types à l'endroit de leur déclaration.
Dans l'exemple ci-dessous, l'énumération MyOption associée à MyOptionTools , nous développons donc statiquement cette énumération (ce qui est impossible dans la situation habituelle) et obtenons l'opportunité d'appeler la méthode get() , en y faisant référence en tant que méthode objet.

Dans cet exemple, la méthode get() est en ligne, ce qui permet également au compilateur d'optimiser davantage le code: au lieu d'appeler la MyOptionTools.get(myOption) , le compilateur remplacera la valeur stockée, c'est-à-dire 12 .
Si la méthode n'est pas déclarée intégrable, un autre outil d'optimisation à la disposition du programmeur consiste à intégrer les fonctions à l'endroit de leur appel (inlining du site d'appel). Pour ce faire, lors de l'appel de la fonction, vous devez également utiliser le inline :

Grâce au travail de Daniil Korostelev , Haxe a désormais la possibilité de générer des classes ES6 pour JavaScript. Il vous suffit d'ajouter le drapeau de compilation -D js-es=6 .
Actuellement, le compilateur génère un fichier js pour l'ensemble du projet (il peut être possible à l'avenir de générer des fichiers js distincts pour chacune des classes, mais jusqu'à présent, cela ne peut être fait qu'à l'aide d' outils supplémentaires ).

Pour les énumérations abstraites, les valeurs sont désormais générées automatiquement.
Dans Haxe 3, il était nécessaire de définir manuellement des valeurs pour chaque constructeur. Dans Haxe 4, les énumérations abstraites créées au-dessus d' Int se comportent selon les mêmes règles que dans C. Les énumérations abstraites créées au-dessus des chaînes se comportent de la même manière - pour elles, les valeurs générées coïncideront avec les noms des constructeurs.

Quelques améliorations de syntaxe méritent également d'être mentionnées:
- les énumérations abstraites et les fonctions externes sont devenues des membres à part entière de Haxe et maintenant vous n'avez plus besoin d'utiliser les balises META
@:enum et @:extern pour les déclarer - 4th Haxe utilise un nouveau type de syntaxe d'intersection qui reflète mieux l'essence des structures en expansion. De telles constructions sont plus utiles lors de la déclaration de structures de données: l'expression
typedef T = A & B signifie que la structure T a tous les champs qui sont dans les types A et B - de même, les quatre déclarent des contraintes de paramètres de type: l'entrée
<T:A & B> indique que le type de paramètre T doit être à la fois A et B - l'ancienne syntaxe fonctionnera (à l'exception de la syntaxe pour les restrictions de type, car elle entrera en conflit avec la nouvelle syntaxe pour décrire les types de fonction)

La nouvelle syntaxe pour décrire les types de fonction (syntaxe de type de fonction) est plus logique: l'utilisation de parenthèses autour des types d'arguments de fonction est visuellement plus facile à lire. De plus, la nouvelle syntaxe vous permet de définir des noms d'arguments, qui peuvent être utilisés dans le cadre de la documentation du code (bien que cela n'affecte pas le typage lui-même).

Dans ce cas, l'ancienne syntaxe continue d'être prise en charge et n'est pas déconseillée, car sinon, il faudrait trop de changements dans le code existant (Simon lui-même se retrouve constamment par habitude et continue d'utiliser l'ancienne syntaxe).
Haxe 4 a enfin des fonctions fléchées (ou expressions lambda)!

Les fonctions des flèches dans Haxe sont les suivantes:
return implicite. Si le corps de la fonction se compose d'une expression, cette fonction renvoie implicitement la valeur de cette expression- il est possible de définir les types d'arguments de fonction, car le compilateur ne peut pas toujours déterminer le type requis (par exemple
Float ou Int ) - si le corps de la fonction se compose de plusieurs expressions, vous devez l'entourer d'accolades
- mais il n'y a aucun moyen de définir explicitement le type de retour de la fonction
En général, la syntaxe des fonctions fléchées est très similaire à celle utilisée dans Java 8 (bien qu'elle fonctionne quelque peu différemment).
Et puisque nous avons mentionné Java, il faut dire que dans Haxe 4, il est devenu possible de générer directement du bytecode JVM. Pour ce faire, lors de la compilation d'un projet sous Java, ajoutez simplement l'indicateur -D jvm .
La génération d'un bytecode JVM signifie qu'il n'est pas nécessaire d'utiliser un compilateur Java et que le processus de compilation est beaucoup plus rapide.

Jusqu'à présent, la cible JVM a un statut expérimental pour les raisons suivantes:
- dans certains cas, le bytecode est légèrement plus lent que le résultat de la traduction de Haxe en Java puis de la compilation avec javac. Mais l'équipe du compilateur est consciente du problème et sait comment le résoudre, cela nécessite juste un travail supplémentaire.
- il y a des problèmes avec MethodHandle sur Android, qui nécessite également un travail supplémentaire (Simon sera heureux s'il est aidé à résoudre ces problèmes).

Une comparaison générale de la génération directe de bytecode (genjvm) et de la compilation de Haxe en code Java, qui est ensuite compilé en bytecode (genjava):
- comme déjà mentionné, en termes de vitesse de compilation, genjvm est plus rapide que genjava
en termes de vitesse d'exécution, le bytecode genjvm est toujours inférieur à genjava - il y a des problèmes lors de l'utilisation des paramètres de type et de genjava
- genJvm utilise MethodHandle pour faire référence aux fonctions, et genjava utilise les soi-disant «fonctions Waneck» (en l'honneur de Kaui Vanek , grâce auxquelles Java et le support C # sont apparus dans Haxe). Bien que le code obtenu à l'aide des fonctions Waneck ne soit pas beau, il fonctionne et fonctionne assez rapidement.
Conseils généraux pour travailler avec Java dans Haxe:
- En raison du fait que le garbage collector en Java est rapide, les problèmes qui lui sont associés sont rares. Bien sûr, la création constante de nouveaux objets n'est pas une bonne idée, mais Java gère bien la gestion de la mémoire et la nécessité de prendre constamment en charge les allocations n'est pas aussi aiguë que sur certaines autres plates-formes prises en charge par Haxe (par exemple, dans HashLink)
- accéder aux champs d'une classe dans une cible jvm peut fonctionner très lentement dans le cas où cela se fait via une structure (
typedef ) - alors que le compilateur ne peut pas optimiser un tel code - une utilisation excessive du mot clé en
inline doit être évitée - le compilateur JIT fait un très bon travail - Évitez d'utiliser
Null<T> , en particulier lorsque vous traitez des calculs mathématiques complexes. Sinon, de nombreuses instructions conditionnelles apparaîtront dans le code généré, ce qui affectera négativement la vitesse de votre code.
La nouvelle fonctionnalité Haxe 4, la sécurité Null, peut aider à éviter d'utiliser Null<T> . Alexander Kuzmenko a parlé d'elle en détail lors du HaxeUp de l'année dernière .

Dans l'exemple de la diapositive ci-dessus, la méthode static safe() a le mode Strict pour vérifier la sécurité Null activé, et cette méthode a un paramètre optionnel arg , qui peut avoir une valeur nulle. Pour que cette fonction soit compilée avec succès, le programmeur devra ajouter une vérification de la valeur de l'argument arg (sinon, le compilateur affichera un message sur l'impossibilité d'appeler la charAt() sur un objet potentiellement nul).
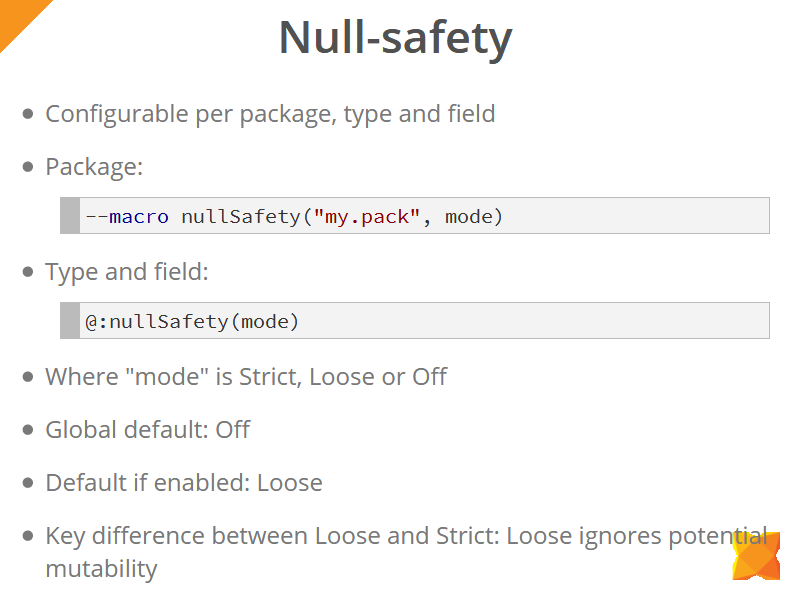
La sécurité nulle peut être configurée à la fois au niveau du package (à l'aide d'une macro) et des types et champs individuels d'objets (à l'aide de la balise @:nullSafety ).
Les modes dans lesquels les contrôles de sécurité Null fonctionnent sont: Strict, Loose et Off. Globalement, ces vérifications sont désactivées (hors mode). Lorsqu'ils sont activés, le mode Loose est utilisé par défaut (sauf si vous spécifiez explicitement le mode). La principale différence entre les modes Loose et Strict est que le mode Loose ignore la possibilité de modifier les valeurs entre les opérations d'accès à ces valeurs. Dans l'exemple de la diapositive ci-dessous, nous voyons qu'une vérification null a été ajoutée pour la variable x . Cependant, en mode Strict, ce code ne compile pas, car avant de travailler directement avec la variable x , la méthode sideEffect() est sideEffect() , ce qui peut potentiellement annuler la valeur de cette variable, vous devrez donc ajouter une autre vérification ou copier la valeur de la variable dans une variable locale, avec laquelle nous continuerons de travailler.

Haxe 4 introduit un nouveau mot-clé final , qui a une signification différente selon le contexte:
- si vous l'utilisez à la place du mot clé
var , le champ déclaré de cette manière ne peut pas recevoir de nouvelle valeur. Vous ne pouvez le définir directement que lors de la déclaration (pour les champs statiques) ou dans le constructeur (pour les champs non statiques) - si vous l'utilisez lors de la déclaration d'une classe, cela en interdira l'héritage
- si vous l'utilisez comme modificateur pour accéder à la propriété d'un objet, cela interdit la redéfinition de getter / setter dans les classes héritières.

Théoriquement, le compilateur, après avoir rencontré le mot-clé final , peut essayer d'optimiser le code, en supposant que la valeur de ce champ ne change pas. Mais pour l'instant, cette possibilité est uniquement envisagée et n'est pas implémentée dans le compilateur.

Et un peu sur l'avenir d'Haxe:
- travaille actuellement sur l'API d'E / S asynchrone
Le soutien de Coroutine est prévu, mais jusqu'à présent, le travail sur ceux-ci est bloqué au stade de la planification. Peut-être qu'ils apparaîtront dans Haxe 4.1, et peut-être plus tard. - l'optimisation des appels de queue apparaîtra dans le compilateur
- et éventuellement les fonctions disponibles au niveau du module . Bien que la priorité de cette fonctionnalité change constamment