Le résultat croissant (cumulatif) a longtemps été considéré comme l'un des appels SQL. Étonnamment, même après l'apparition des fonctions de la fenêtre, il continue d'être un épouvantail (en tout cas, pour les débutants). Aujourd'hui, nous examinons la mécanique des 10 solutions les plus intéressantes à ce problème - des fonctions de fenêtre aux hacks très spécifiques.
Dans des feuilles de calcul comme Excel, le total cumulé est calculé très simplement: le résultat du premier enregistrement correspond à sa valeur:
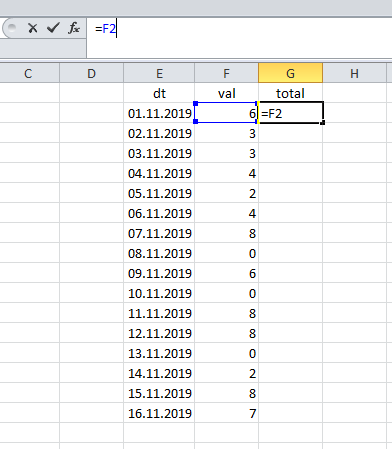
... puis nous résumons la valeur actuelle et le total précédent.

En d'autres termes
... ou:
L'apparition de deux ou plusieurs groupes dans le tableau complique quelque peu la tâche: nous comptons maintenant plusieurs résultats (pour chaque groupe séparément). Cependant, ici, la solution se trouve à la surface: à chaque fois, il est nécessaire de vérifier à quel groupe appartient l'enregistrement actuel.
Cliquez et faites glisser , et le travail est terminé:
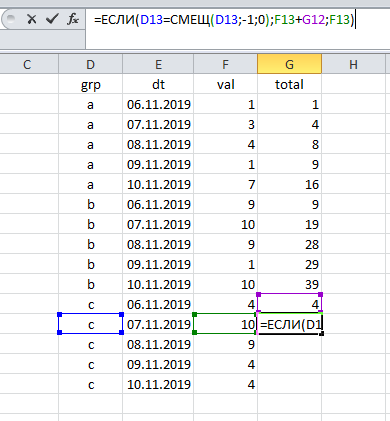
Comme vous pouvez le voir, le calcul du total cumulé est associé à deux composantes inchangées:
(a) trier les données par date et
(b) se référant à la ligne précédente.
Mais qu'est-ce que SQL? Pendant très longtemps, il n'y avait aucune fonctionnalité nécessaire. Un outil nécessaire - les fonctions de fenêtre - n'est apparu pour la première fois que dans la
norme SQL: 2003 . À ce stade, ils étaient déjà dans Oracle (version 8i). Mais l'implémentation dans d'autres SGBD a été retardée de 5 à 10 ans: SQL Server 2012, MySQL 8.0.2 (2018), MariaDB 10.2.0 (2017), PostgreSQL 8.4 (2009), DB2 9 for z / OS (2007 année), et même SQLite 3.25 (2018).
1. Fonctions de fenêtre
Les fonctions de fenêtre sont probablement le moyen le plus simple. Dans le cas de base (tableau sans groupes), nous considérons les données triées par date:
order by dt
... mais nous ne sommes intéressés que par les lignes avant la ligne actuelle:
rows between unbounded preceding and current row
En fin de compte, nous avons besoin d'une somme avec ces paramètres:
sum(val) over (order by dt rows between unbounded preceding and current row)
Une demande complète ressemblerait à ceci:
select s.*, coalesce(sum(s.val) over (order by s.dt rows between unbounded preceding and current row), 0) as total from test_simple s order by s.dt;
Dans le cas d'un total cumulé pour les groupes (champ
grp ), nous n'avons besoin que d'une petite modification. Maintenant, nous considérons les données comme divisées en «fenêtres» basées sur le groupe:

Pour tenir compte de cette séparation, vous devez utiliser la
partition by mot-clé:
partition by grp
Et, en conséquence, considérez le montant de ces fenêtres:
sum(val) over (partition by grp order by dt rows between unbounded preceding and current row)
Ensuite, la requête entière est convertie comme ceci:
select tg.*, coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt rows between unbounded preceding and current row), 0) as total from test_groups tg order by tg.grp, tg.dt;
Les performances des fonctions de fenêtre dépendront des spécificités de votre SGBD (et de sa version!), De la taille de la table et de la disponibilité des index. Mais dans la plupart des cas, cette méthode sera la plus efficace. Cependant, les fonctions de fenêtre ne sont pas disponibles dans les anciennes versions du SGBD (qui sont toujours utilisées). De plus, ils ne se trouvent pas dans des SGBD tels que Microsoft Access et SAP / Sybase ASE. Si une solution indépendante du fournisseur est nécessaire, des alternatives doivent être envisagées.
2. Sous-requête
Comme mentionné ci-dessus, les fonctions de fenêtre ont été introduites très tard dans le SGBD principal. Ce retard n'est pas surprenant: en théorie relationnelle, les données ne sont pas ordonnées. Beaucoup plus à l'esprit de la théorie relationnelle correspond à une solution à travers une sous-requête.
Une telle sous-requête doit considérer la somme des valeurs avec une date antérieure à l'actuelle (et y compris l'actuelle):
.
À quoi ressemble le code:
select s.*, (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt <= s.dt) as total from test_simple s order by s.dt;
Une solution légèrement plus efficace sera dans laquelle la sous-requête considère le total jusqu'à la date actuelle (mais ne l'inclut pas), puis le résume avec la valeur de la ligne:
select s.*, s.val + (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt < s.dt) as total from test_simple s order by s.dt;
Dans le cas d'un résultat cumulatif pour plusieurs groupes, nous devons utiliser une sous-requête corrélée:
select g.*, (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt) as total from test_groups g order by g.grp, g.dt;
La condition
g.grp = t2.grp vérifie les lignes à inclure dans le groupe (ce qui, en principe, est similaire au travail de
partition by grp dans les fonctions de fenêtre).
3. Connexion interne
Étant donné que les sous-requêtes et les jointures sont interchangeables, nous pouvons facilement les remplacer les unes par les autres. Pour ce faire, vous devez utiliser Self Join, en connectant deux instances de la même table:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s inner join test_simple t2 on t2.dt <= s.dt group by s.dt, s.val order by s.dt;
Comme vous pouvez le voir, la condition de filtrage dans la sous-requête
t2.dt <= s.dt est devenue une condition de jointure. De plus, pour utiliser la fonction d'agrégation
sum() nous devons regrouper par date et valeur par
group by s.dt, s.val .
De même, vous pouvez faire pour le cas avec différents groupes
grp :
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g inner join test_groups t2 on g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
4. Produit cartésien
Puisque nous avons remplacé la sous-requête par join, pourquoi ne pas essayer le produit cartésien? Cette solution ne nécessitera que des modifications minimales:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s, test_simple t2 where t2.dt <= s.dt group by s.dt, s.val order by s.dt;
Ou pour les groupes:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g, test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
Les solutions listées (sous-requête, jointure interne, jointure cartésienne) correspondent à
SQL-92 et
SQL: 1999 , et seront donc disponibles dans presque tous les SGBD. Le principal problème avec toutes ces solutions est une mauvaise performance. Ce n'est pas un gros problème si nous matérialisons un tableau avec le résultat (mais vous voulez quand même plus de vitesse!). D'autres méthodes sont beaucoup plus efficaces (ajustées pour les spécificités de SGBD spécifiques et leurs versions déjà spécifiées, la taille de la table, les index).
5. Demande récursive
L'une des approches les plus spécifiques est une requête récursive dans une expression de table commune. Pour ce faire, nous avons besoin d'une «ancre» - une requête qui renvoie la toute première ligne:
select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple)
Ensuite, avec l'aide de
union all , les résultats d'une requête récursive sont ajoutés à "l'ancre". Pour ce faire, vous pouvez compter sur le champ date
dt , en y ajoutant un jour:
select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
La partie du code qui ajoute un jour n'est pas universelle. Par exemple, il s'agit de
r.dt = dateadd(day, 1, cte.dt) pour SQL Server,
r.dt = cte.dt + 1 pour Oracle, etc.
En combinant «l'ancre» et la demande principale, nous obtenons le résultat final:
with cte (dt, val, total) as (select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple) union all select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
La solution pour le cas avec des groupes ne sera pas beaucoup plus compliquée:
with cte (dt, grp, val, total) as (select g.dt, g.grp, g.val, g.val as total from test_groups g where g.dt = (select min(dt) from test_groups where grp = g.grp) union all select r.dt, r.grp, r.val, cte.total + r.val from cte inner join test_groups r on r.dt = dateadd(day, 1, cte.dt)
6. row_number() récursive avec la fonction row_number()
La décision précédente était basée sur la continuité du champ de date
dt avec une augmentation séquentielle de 1 jour. Nous évitons cela en utilisant la fonction de fenêtre
row_number() , qui numérote les lignes. Bien sûr, cela est injuste - car nous allons envisager des alternatives aux fonctions de fenêtre. Cependant, cette solution peut être une sorte de
preuve de concept : en pratique, il peut y avoir un champ qui remplace les numéros de ligne (id d'enregistrement). De plus, dans SQL Server, la fonction
row_number() est apparue avant la prise en charge complète des fonctions de fenêtre (y compris
sum() ).
Donc, pour une requête récursive avec
row_number() nous avons besoin de deux STE. Dans le premier, nous ne numérotons que les lignes:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple)
... et si le numéro de ligne est déjà dans le tableau, vous pouvez vous en passer. Dans la requête suivante, nous faisons déjà
cte1 à
cte1 :
cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 )
Et toute la demande ressemble à ceci:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple), cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 ) select dt, val, total from cte2 order by dt;
... ou pour les groupes:
with cte1 (dt, grp, val, rn) as (select dt, grp, val, row_number() over (partition by grp order by dt) as rn from test_groups), cte2 (dt, grp, val, rn, total) as (select dt, grp, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.grp, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.grp = cte2.grp and cte1.rn = cte2.rn + 1 ) select dt, grp, val, total from cte2 order by grp, dt;
7. CROSS APPLY / LATERAL
L'un des moyens les plus exotiques de calculer un total cumulé consiste à utiliser l'instruction
CROSS APPLY (SQL Server, Oracle) ou son équivalent
LATERAL (MySQL, PostgreSQL). Ces opérateurs sont apparus assez tard (par exemple, dans Oracle uniquement à partir de la version 12c). Et dans certains SGBD (par exemple,
MariaDB ), ils ne le sont pas du tout. Par conséquent, cette décision est d'un intérêt purement esthétique.
Fonctionnellement, l'utilisation de
CROSS APPLY ou
LATERAL identique à la sous-requête: nous attachons le résultat du calcul à la requête principale:
cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2
... qui ressemble à ceci:
select s.*, t2.total from test_simple s cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2 order by s.dt;
La solution pour le cas avec des groupes sera similaire:
select g.*, t2.total from test_groups g cross apply (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt ) t2 order by g.grp, g.dt;
Total: nous avons examiné les principales solutions indépendantes de la plateforme. Mais il existe des solutions spécifiques à des SGBD spécifiques! Puisqu'il y a beaucoup d'options ici, nous allons nous attarder sur quelques-unes des plus intéressantes.
8. MODEL (Oracle)
L'instruction
MODEL dans Oracle fournit l'une des solutions les plus élégantes. Au début de l'article, nous avons examiné la formule générale du total cumulé:
MODEL vous permet de mettre en œuvre cette formule littéralement un à un! Pour ce faire, nous remplissons d'abord le champ
total avec les valeurs de la ligne courante
select dt, val, val as total from test_simple
... puis nous calculons le numéro de ligne comme
row_number() over (order by dt) as rn (ou utilisez le champ fini avec le numéro, le cas échéant). Et enfin, nous introduisons une règle pour toutes les lignes sauf la première:
total[rn >= 2] = total[cv() - 1] + val[cv()] .
La fonction
cv() est ici responsable de la valeur de la ligne courante. Et toute la demande ressemblera à ceci:
select dt, val, total from (select dt, val, val as total from test_simple) t model dimension by (row_number() over (order by dt) as rn) measures (dt, val, total) rules (total[rn >= 2] = total[cv() - 1] + val[cv()]) order by dt;
9. Curseur (SQL Server)
Un total cumulé est l'un des rares cas où le curseur dans SQL Server est non seulement utile, mais également préférable à d'autres solutions (au moins jusqu'à la version 2012, où les fonctions de fenêtre sont apparues).
L'implémentation via le curseur est assez banale. Vous devez d'abord créer un tableau temporaire et le remplir avec les dates et les valeurs du principal:
create table
Ensuite, nous définissons les variables locales à travers lesquelles la mise à jour aura lieu:
declare @VarTotal int, @VarDT date, @VarVal int; set @VarTotal = 0;
Après cela, nous mettons à jour la table temporaire via le curseur:
declare cur cursor local static read_only forward_only for select dt, val from
Et enfin, nous obtenons le résultat souhaité:
select dt, val, total from
10. Mettre à jour via une variable locale (SQL Server)
La mise à jour via une variable locale dans SQL Server est basée sur un comportement non documenté, elle ne peut donc pas être considérée comme fiable. Néanmoins, c'est peut-être la solution la plus rapide, et c'est intéressant.
Créons deux variables: une pour les totaux cumulatifs et une variable de table:
declare @VarTotal int = 0; declare @tv table (dt date null, val int null, total int null );
Tout d'abord, remplissez
@tv données de la table principale
insert @tv (dt, val, total) select dt, val, 0 as total from test_simple order by dt;
Ensuite,
@tv jour la variable de table
@tv utilisant
@VarTotal :
update @tv set @VarTotal = total = @VarTotal + val from @tv;
... après quoi nous obtenons le résultat final:
select * from @tv order by dt;
Résumé: Nous avons examiné les 10 meilleures façons de calculer les totaux cumulatifs en SQL. Comme vous pouvez le voir, même sans fonctions de fenêtre, ce problème est complètement résoluble et la mécanique de la solution ne peut pas être qualifiée de compliquée.