Bonjour à tous! Il y a quelques mois, nous avons lancé notre nouveau projet open-source, le plugin Grafana pour surveiller les kubernetes, appelé
DevOpsProdigy KubeGraf, en production . Le code source du plugin est disponible dans le
référentiel public sur GitHub . Et dans cet article, nous voulons partager avec vous une histoire sur la façon dont nous avons créé le plug-in, quels outils nous avons utilisés et quels pièges nous avons rencontrés au cours du processus de développement. C'est parti!
Partie 0 - introduction: comment en sommes-nous arrivés là?
L'idée d'écrire notre propre plugin pour Grafan est née par hasard. Notre entreprise surveille des projets Web de différents niveaux de complexité depuis plus de 10 ans. Pendant ce temps, nous avons acquis une grande expertise, des cas intéressants et une expérience dans l'utilisation de divers systèmes de surveillance. Et à un moment donné, nous nous sommes demandé: «Existe-t-il un outil magique pour surveiller Kubernetes, de sorte que, comme on dit,« régler et oublier »»? .. Promstandart pour surveiller les k8, bien sûr, a longtemps été un groupe de Prométhée + Grafana. Et comme solutions prêtes à l'emploi pour cette pile, il existe un large éventail d'outils différents: prometheus-operator, ensemble de tableaux de bord kubernetes-mixin, grafana-kubernetes-app.
Le plugin grafana-kubernetes-app semblait être l'option la plus intéressante pour nous, mais il n'a pas été pris en charge depuis plus d'un an et, de plus, il ne sait pas comment travailler avec les nouvelles versions de node-exporter et kube-state-metrics. Et à un moment donné, nous avons décidé: "Mais ne prenons-nous pas notre propre décision?"
Quelles idées nous avons décidé de mettre en œuvre dans notre plugin:
- visualisation de la "carte des applications": présentation pratique des applications dans le cluster, regroupées par espace de noms, déploiement ...;
- visualisation des connexions de la forme "déploiement - service (+ ports)".
- visualisation de la distribution des applications de cluster par des hochements de tête de cluster.
- collecte de métriques et d'informations à partir de plusieurs sources: Prometheus et k8s api server.
- surveillance à la fois de la partie infrastructure (utilisation du temps processeur, de la mémoire, du sous-système de disque, du réseau) et de la logique d'application - modules d'état de santé, nombre de répliques disponibles, informations sur le passage des échantillons de vivacité / disponibilité.
Partie 1: Qu'est-ce que le plugin Grafana?
D'un point de vue technique, le plugin pour Grafana est un contrôleur angulaire qui est stocké dans le répertoire de données
Grafana (
/var/grafana/plugins/<votre_nom_plugin>/dist/module.js ) et peut être chargé en tant que module SystemJS. Ce fichier doit également contenir un fichier plugin.json contenant toutes les méta-informations sur votre plugin: nom, version, type de plugin, liens vers le référentiel / site / licence, dépendances, etc.
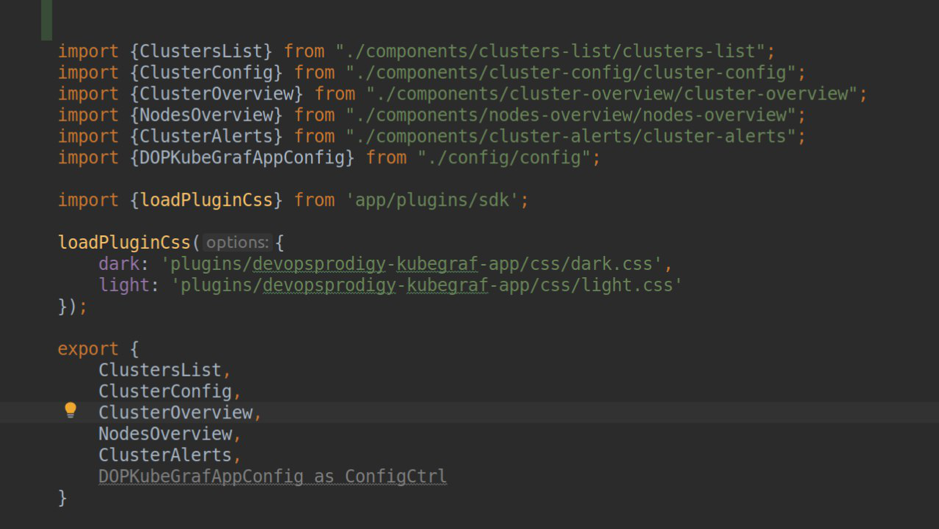 module.ts
module.ts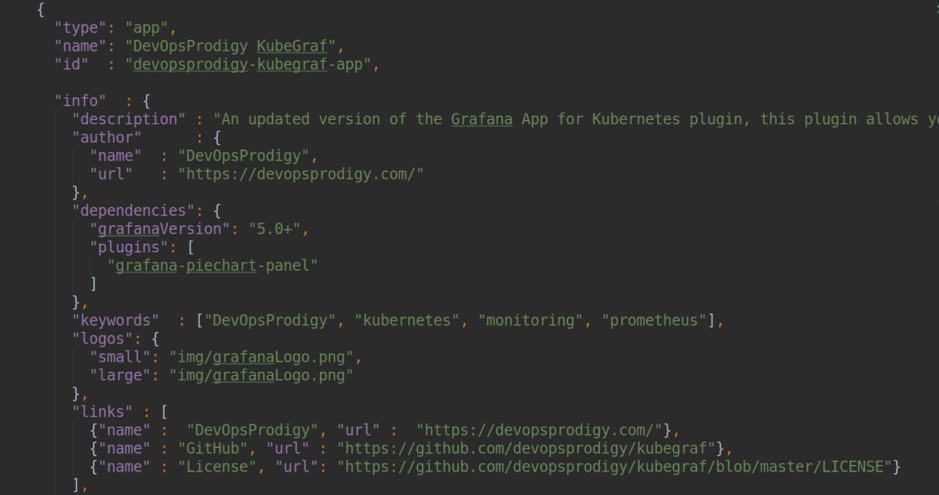 plugin.json
plugin.jsonComme vous pouvez le voir sur la capture d'écran, nous avons spécifié plugin.type = app. Les plugins pour Grafana peuvent être de trois types:
panneau : le type de plug-in le plus courant - c'est un panneau pour visualiser toutes les mesures, il est utilisé pour créer divers tableaux de bord.
source de données : connecteur enfichable vers n'importe quelle source de données (par exemple, Prometheus-datasource, ClickHouse-datasource, ElasticSearch-datasource).
app : un plugin qui vous permet de créer votre propre application frontend à l'intérieur de Grafana, de créer vos propres pages html et d'accéder manuellement à la source de données pour visualiser diverses données. De plus, des plugins d'autres types (source de données, panneau) et divers tableaux de bord peuvent être utilisés comme dépendances.
 Un exemple de dépendances de plugin avec type = app
Un exemple de dépendances de plugin avec type = app .
En tant que langage de programmation, vous pouvez utiliser à la fois JavaScript et TypeScript (nous l'avons choisi). Vous pouvez
trouver les blancs pour les plug-ins hello-world de tout type
ici : dans ce référentiel il y a un grand nombre de packs de démarrage (il y a même un exemple expérimental d'un plugin sur React) avec des constructeurs pré-installés et configurés.
Partie 2: préparer votre environnement local
Pour travailler sur le plugin, nous avons naturellement besoin d'un cluster kubernetes avec tous les outils préinstallés: prometheus, node-exporter, kube-state-metrics, grafana. L'environnement doit être configuré rapidement, facilement et naturellement, et pour fournir des données de rechargement à chaud, le répertoire Grafana doit être monté directement à partir de la machine du développeur.
À notre avis, la façon la plus pratique de travailler localement avec kubernetes est le
minikube . L'étape suivante consiste à établir le bundle Prometheus + Grafana à l'aide de l'opérateur prometheus.
Cet article détaille le processus d'installation de prometheus-operator sur minikube. Pour activer la persistance, vous devez définir le paramètre
persistence: true dans le fichier charts / grafana / values.yaml, ajouter vos propres PV et PVC et les spécifier dans le paramètre persistence.existingClaim
Le script de lancement final du minikube ressemble à ceci:
minikube start --kubernetes-version=v1.13.4 --memory=4096 --bootstrapper=kubeadm --extra-config=scheduler.address=0.0.0.0 --extra-config=controller-manager.address=0.0.0.0 minikube mount /home/sergeisporyshev/Projects/Grafana:/var/grafana --gid=472 --uid=472 --9p-version=9p2000.L
Partie 3: le développement lui-même
Modèle d'objetEn préparation de l'implémentation du plugin, nous avons décidé de décrire toutes les entités Kubernetes de base avec lesquelles nous travaillerons en tant que classes TypeScript: pod, déploiement, daemonset, statefulset, job, cronjob, service, node, namespace. Chacune de ces classes hérite de la classe BaseModel commune, qui décrit le constructeur, le destructeur, les méthodes de mise à jour et de changement de visibilité. Chacune des classes décrit les relations imbriquées avec d'autres entités, par exemple, une liste de pods pour une entité de type déploiement.
import {Pod} from "./pod"; import {Service} from "./service"; import {BaseModel} from './traits/baseModel'; export class Deployment extends BaseModel{ pods: Array<Pod>; services: Array<Service>; constructor(data: any){ super(data); this.pods = []; this.services = []; } }
À l'aide de getters et setters, nous pouvons afficher ou définir les métriques des entités dont nous avons besoin d'une manière pratique et lisible. Par exemple, la sortie formatée des nœuds CPU allouables:
get cpuAllocatableFormatted(){ let cpu = this.data.status.allocatable.cpu; if(cpu.indexOf('m') > -1){ cpu = parseInt(cpu)/1000; } return cpu; }
PagesUne liste de toutes les pages de notre plugin est initialement décrite dans notre pluing.json dans la section des dépendances:
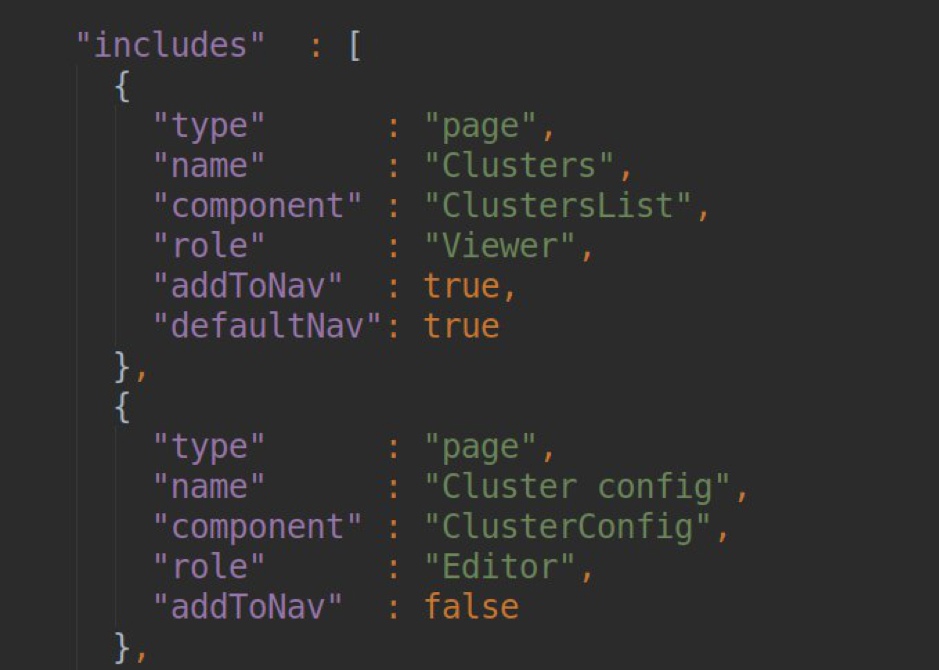
Dans le bloc de chaque page, nous devons indiquer le TITRE DE PAGE (il sera ensuite converti en slug, par lequel cette page sera disponible); nom du composant responsable du fonctionnement de cette page (la liste des composants est exportée vers module.ts); spécifiant le rôle de l'utilisateur pour lequel l'accès à cette page est disponible et les paramètres de navigation pour la barre latérale.
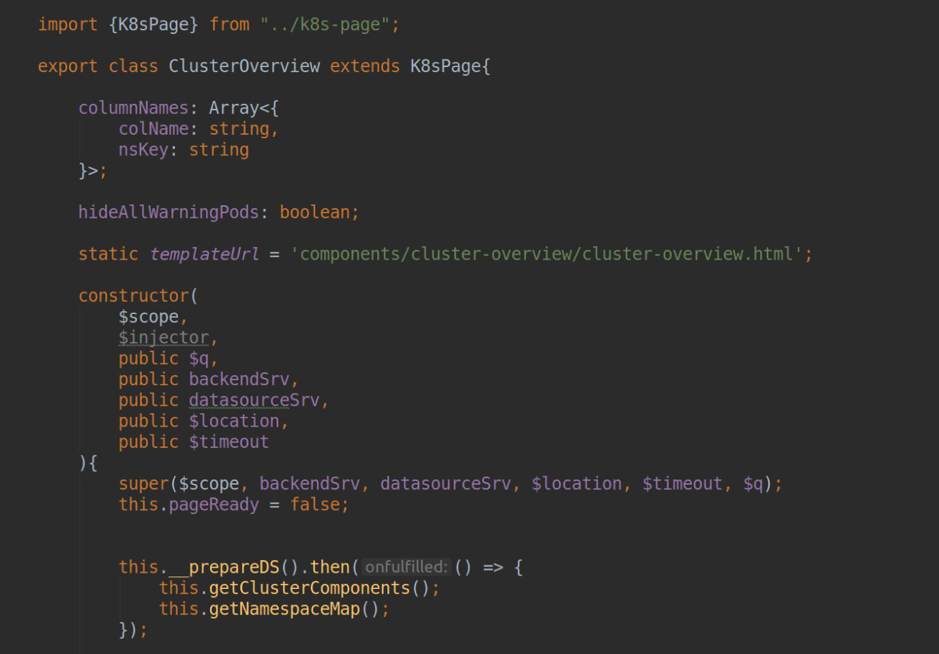
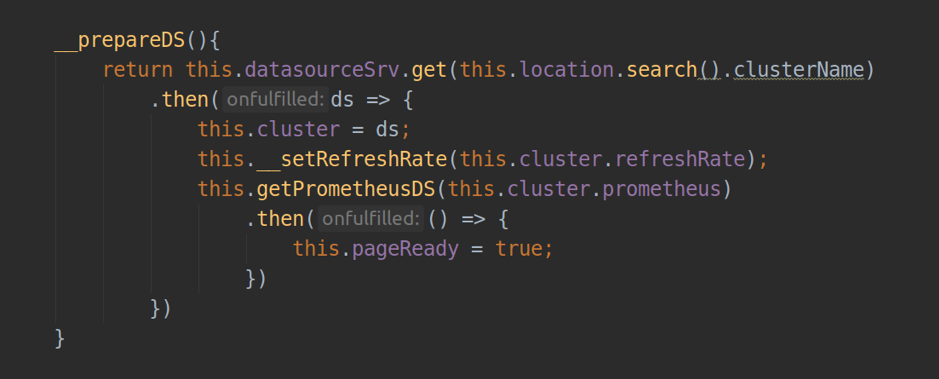
Dans le composant responsable du fonctionnement de la page, nous devons installer templateUrl, en y passant le chemin du fichier html avec balisage. À l'intérieur du contrôleur, grâce à l'injection de dépendances, nous pouvons accéder à jusqu'à 2 services angulaires importants:
- backendSrv - un service qui fournit une interaction avec le serveur api grafana;
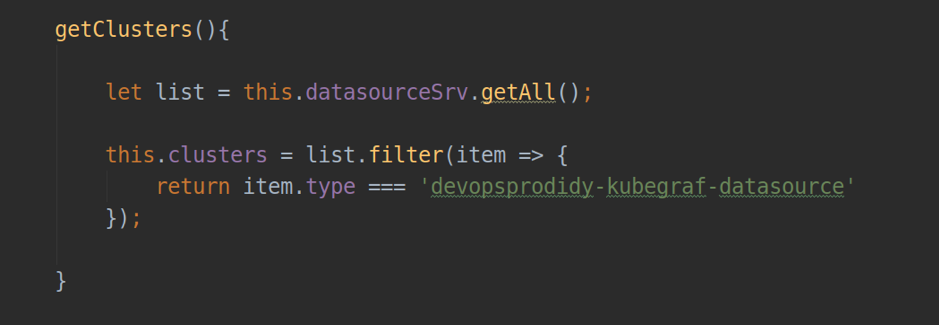
- datasourceSrv - un service qui fournit une interaction locale avec toutes les sources de données installées dans votre Grafana (par exemple, la méthode .getAll () - renvoie une liste de toutes les sources de données installées'ov; .get (<nom>) - renvoie un objet instance d'une source de données particulière.
Partie 4: source de données
Du point de vue de Grafana, la source de données est exactement le même plug-in que tout le monde: elle a son propre point d'entrée module.js, il y a un fichier avec meta-information plugin.json. Lors du développement d'un plugin avec type = app, nous pouvons interagir avec la source de données existante (par exemple, prometheus-datasource), ainsi que la nôtre, que nous pouvons stocker directement dans le répertoire du plugin (dist / datasource / *) ou définir comme une dépendance. Dans notre cas, la source de données est livrée avec le code du plugin. Il est également obligatoire que vous ayez le modèle config.html et le contrôleur ConfigCtrl qui seront utilisés pour la page de configuration de l'instance de source de données et le contrôleur de source de données, qui implémente la logique de votre source de données.
Dans le plugin KubeGraf, du point de vue de l'interface utilisateur, la source de données est une instance du cluster kubernetes dans lequel les fonctionnalités suivantes sont implémentées (le code source est disponible
par référence ):
- collecte de données depuis le serveur api k8s (obtention d'une liste de namespace'ov, deployment'ov ...)
- les demandes de proxy dans prometheus-datasource (qui est sélectionné dans les paramètres du plug-in pour chaque cluster spécifique) et les réponses de formatage pour l'utilisation des données dans les pages statiques et les tableaux de bord.
- mise à jour des données sur les pages statiques du plugin (avec le taux de rafraîchissement défini).
- traitement des demandes de génération d'une liste de modèles dans les tableaux de bord grafana (méthode .metriFindQuery ())
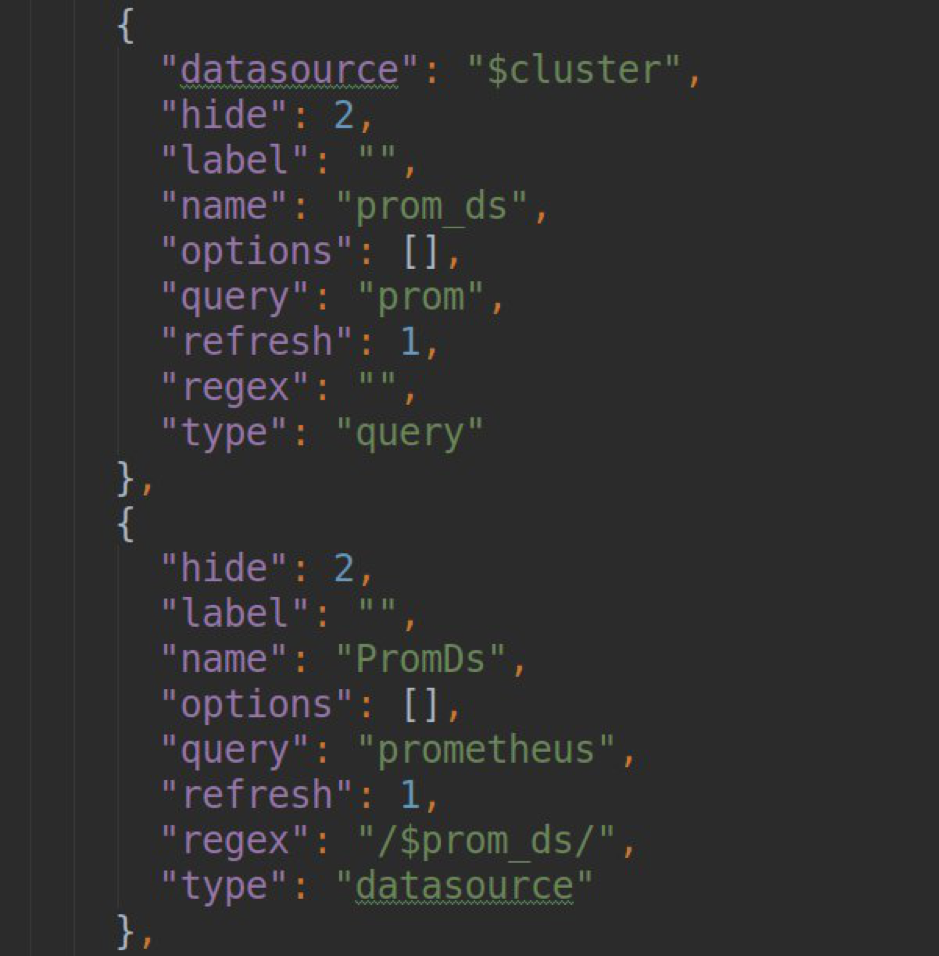
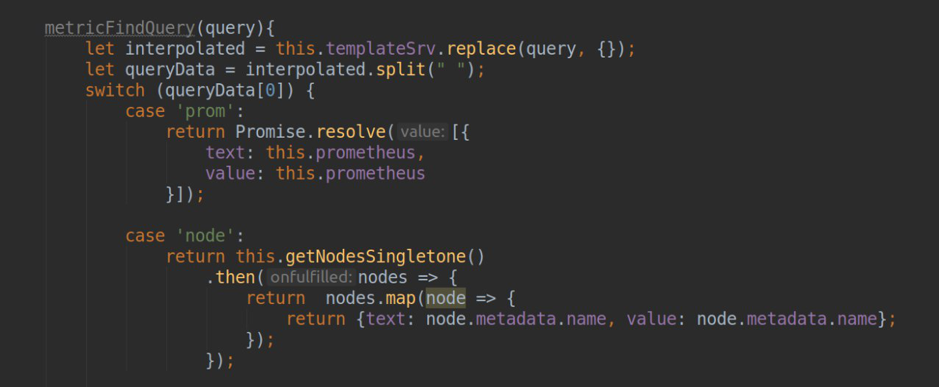
- tester la connexion avec le cluster final k8s.
testDatasource(){ let url = '/api/v1/namespaces'; let _url = this.url; if(this.accessViaToken) _url += '/__proxy'; _url += url; return this.backendSrv.datasourceRequest({ url: _url, method: "GET", headers: {"Content-Type": 'application/json'} }) .then(response => { if (response.status === 200) { return {status: "success", message: "Data source is OK", title: "Success"}; }else{ return {status: "error", message: "Data source is not OK", title: "Error"}; } }, error => { return {status: "error", message: "Data source is not OK", title: "Error"}; }) }
Un point intéressant distinct, à notre avis, est la mise en œuvre du mécanisme d'authentification et d'autorisation pour la source de données. En règle générale, dès la configuration de l'accès à la source de données finale, nous pouvons utiliser le composant Grafana intégré - datasourceHttpSettings. À l'aide de ce composant, nous pouvons configurer l'accès à la source de données http en spécifiant l'url et les paramètres d'authentification / autorisation de base: login-password ou client-cert / client-key. Afin de réaliser la possibilité de configurer l'accès à l'aide d'un jeton au porteur (de facto la norme pour les k8), j'ai dû faire un peu de "chimie".
Pour résoudre ce problème, vous pouvez utiliser le mécanisme intégré de «Plugin Routes» de Grafana (plus sur la
page de documentation officielle ). Dans les paramètres de notre source de données, nous pouvons déclarer un ensemble de règles de routage qui seront traitées par le serveur proxy grafana. Par exemple, pour chaque point de terminaison individuel, il est possible d'apposer des en-têtes ou des URL avec la possibilité de créer un modèle, dont les données peuvent être extraites des champs jsonData et secureJsonData (pour stocker des mots de passe ou des jetons sous forme cryptée). Dans notre exemple, les requêtes du formulaire
/ __ proxy / api / v1 / namespaces seront transmises par proxy à l'url du formulaire
<your_k8s_api_url> / api / v1 / namespaces avec l'en-tête Authorization: Bearer.
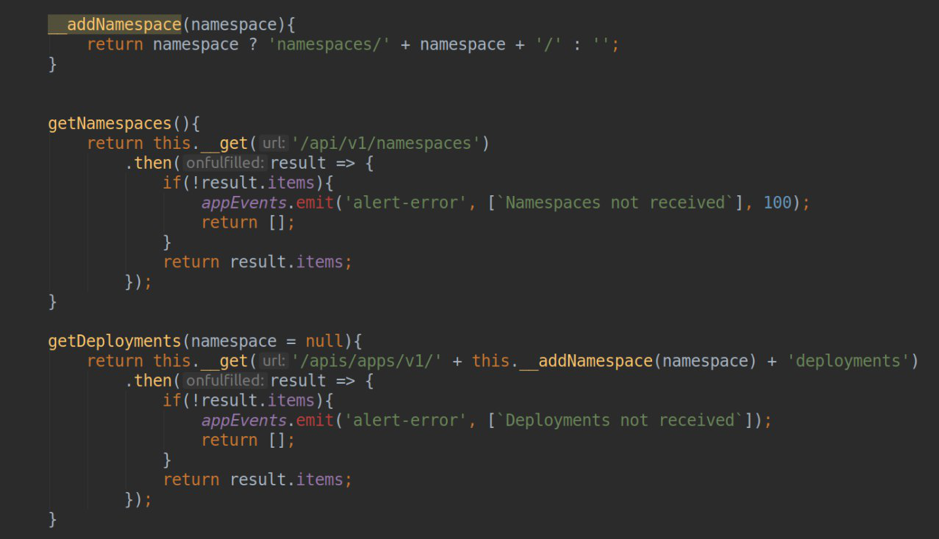
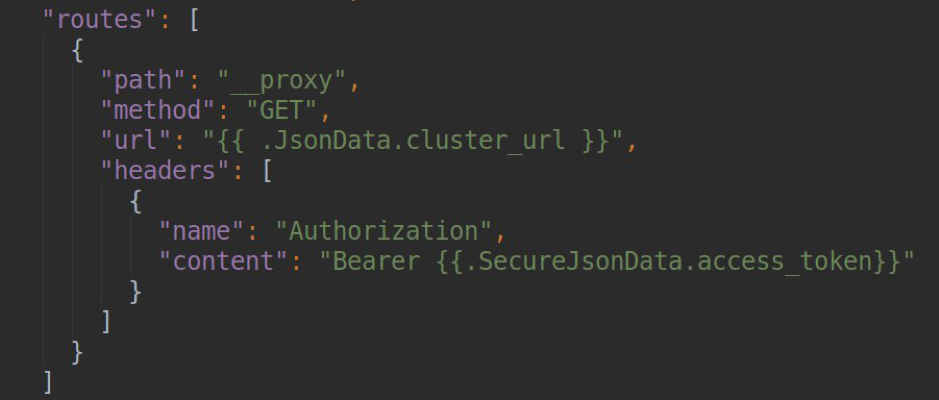
Naturellement, pour travailler avec le serveur api k8s, nous avons besoin d'un utilisateur avec des accès en lecture seule, le manifeste de création que vous pouvez également trouver dans le
code source du plugin .
Partie 5: libération

Après avoir écrit votre propre plugin pour Grafana, vous voudrez naturellement le mettre dans le domaine public. Grafana est une bibliothèque de plugins disponible sur
grafana.com/grafana/pluginsPour que votre plugin soit disponible dans la boutique officielle, vous devez faire des relations publiques dans
ce référentiel en ajoutant le contenu suivant au fichier repo.json:
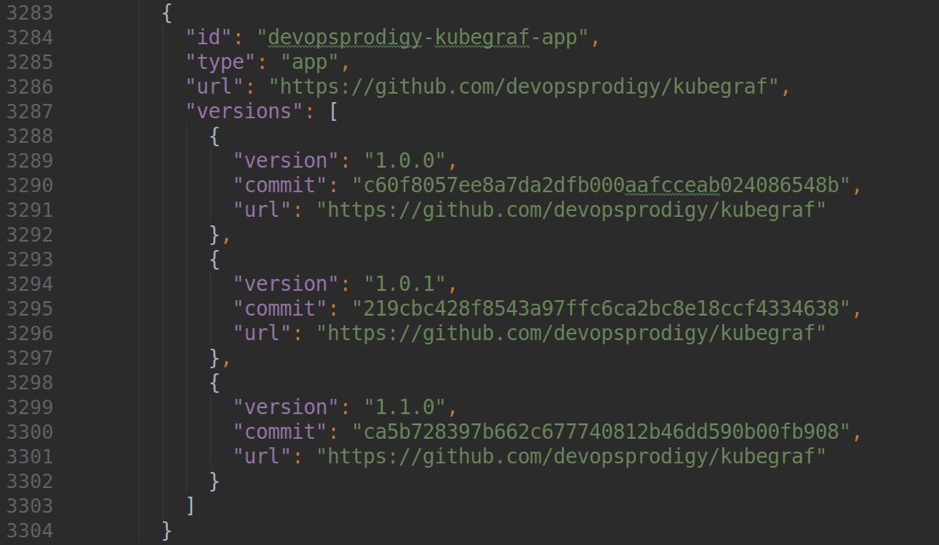
où version est la version de votre plugin, url est un lien vers le référentiel, et commit est un hachage du commit, par lequel une version spécifique du plugin sera disponible.
Et à la sortie, vous verrez une merveilleuse image du formulaire:
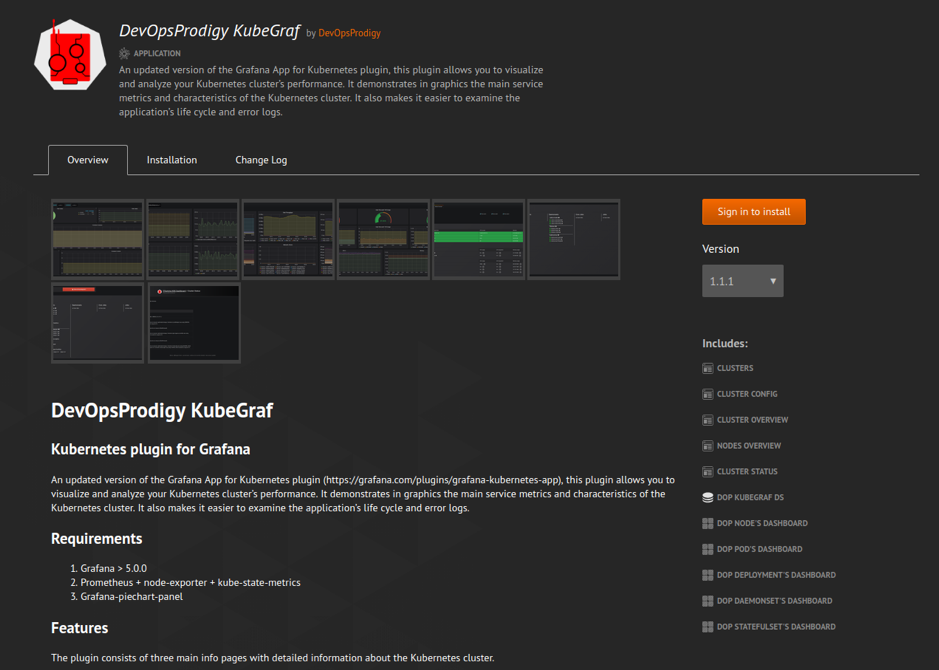
Les données seront automatiquement extraites de votre fichier Lisezmoi.md, Changelog.md et du fichier plugin.json avec la description du plugin.
Partie 6: au lieu de conclusions
Nous n'avons pas arrêté de développer notre plugin après la sortie. Et maintenant, nous travaillons sur la surveillance correcte de l'utilisation des ressources des nœuds de cluster, l'introduction de nouvelles fonctionnalités pour augmenter l'UX, et nous récoltons également une grande quantité de commentaires reçus après l'installation du plugin à la fois par nos clients et depuis l'ishui sur le github (si vous laissez votre problème ou tirez une demande, je Je serai très content :-)).
Nous espérons que cet article vous aidera à comprendre un outil aussi génial que Grafana et, éventuellement, à écrire votre propre plugin.
Merci!)