Il existe de nombreuses façons de tester les API et les interfaces. Dans le cadre de l'ouverture d'un large accès à Acronis Cyber Platform, nous avons été obligés de chercher des moyens de tester les services «pour la durabilité» à partir de diverses positions. Dans cet article, l'architecte logiciel principal d'Acronis, Dmitry Salomatin, explique comment nous avons choisi le cadre pour les tests, quelles difficultés nous avons rencontrées et quelles améliorations nous avons dû faire nous-mêmes.

Je dois dire tout de suite que chez Acronis, nous faisons particulièrement attention aux tests des API. Le fait est que nos propres produits accèdent aux services via les mêmes API que celles utilisées pour connecter les systèmes externes. Par conséquent, des tests de performances de chaque interface sont nécessaires. Nous testons le fonctionnement de l'API et isolons le fonctionnement de l'interface utilisateur de manière isolée. Les résultats des tests vous permettront d'évaluer si l'API elle-même fonctionne bien, ainsi que les interfaces utilisateur. Confirmer le développement réussi ou formuler une tâche pour un développement ultérieur.
Mais les tests diffèrent. Parfois, un service ne montre pas immédiatement de dégradation. Même si nous exécutons un service similaire aux produits déjà publiés dans la version, pour vérification, vous pouvez le charger avec les mêmes données que celles utilisées «in prod». Dans ce cas, vous pouvez voir la régression, mais il est absolument impossible d'évaluer la perspective. Vous ne savez tout simplement pas ce qui se passera si la quantité de données augmente fortement ou si la fréquence des demandes augmente.
Ci-dessous est un graphique montrant comment le nombre d'API traitées par le backend par seconde change avec la croissance des données dans le système

Supposons que le service que nous testons soit dans un état typique du début de ce programme. Dans ce cas, même avec une petite croissance du système, la vitesse de cette API diminuera fortement.
Pour exclure de telles situations, nous augmentons la quantité de données plusieurs fois, augmentons le nombre de threads parallèles pour comprendre comment le service se comportera si la charge augmente considérablement.
Mais il y a encore une nuance. Si le travail d'un service «familier» change en fonction de l'augmentation de la quantité de données, de son développement, de l'émergence de nouvelles fonctions, de nouveaux services, la situation est encore plus compliquée. Lorsqu'un service conceptuellement nouveau apparaît dans un produit, il doit être considéré sous de nombreux angles différents. Pour cette situation, vous devez préparer des ensembles de données spéciaux, effectuer des tests de charge, suggérer des cas d'utilisation possibles.
Caractéristiques des tests de performances dans Acronis
En règle générale, nos processus de test se déroulent selon un «schéma en spirale». L'une des phases de test consiste à utiliser l'API pour augmenter le nombre d'entités (dimensionnement) et la seconde à effectuer de nouvelles opérations sur les ensembles de données existants (utilisation). Tous les tests s'exécutent dans un nombre différent de threads. Par exemple, nous avons le service Animaux et il a les API suivantes:
POST /animals PUT /animals/<id> GET /animals?filter=criteria
1 et 2 sont des API appelées dans les tests de dimensionnement - elles augmentent le nombre de nouvelles entités dans le système.
3 sont des API appelées dans la phase d'utilisation. Cette API a une tonne d'options de filtrage. En conséquence, il y aura plus d'un test
Ainsi, en exécutant des tests de dimensionnement et d'utilisation itératifs, nous obtenons une image de l'évolution des performances du système avec sa croissance
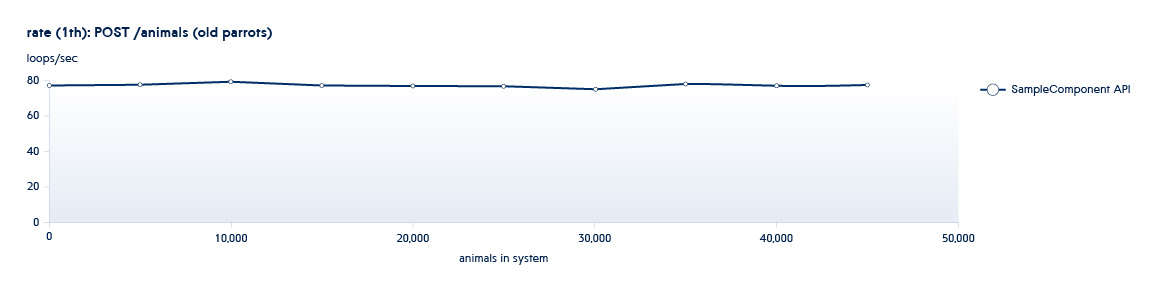
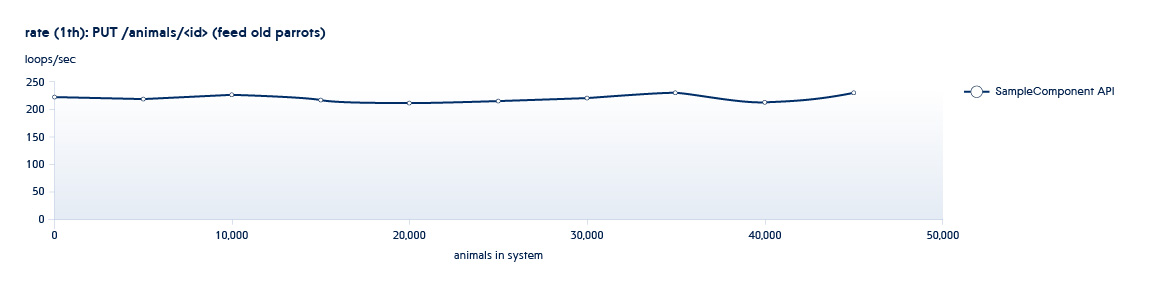
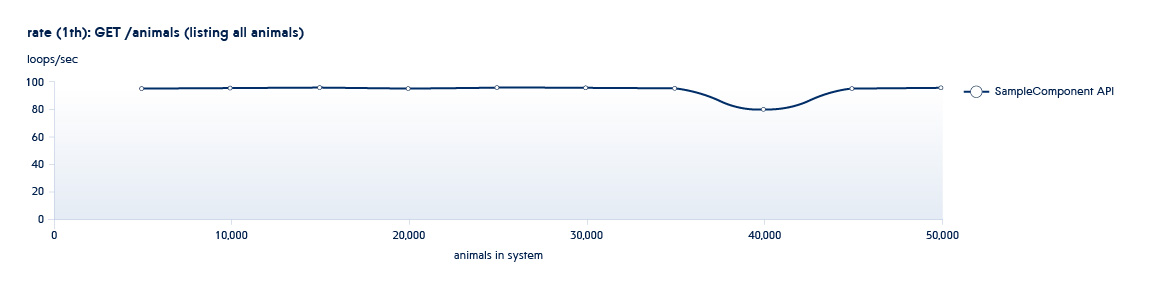

Cadre nécessaire ...
Afin de mener des tests à grande échelle sur un grand nombre de services nouveaux et mis à jour, nous avions besoin d'un cadre flexible qui nous permettrait d'exécuter différents scripts. Et l'essentiel est de vraiment tester l'API, et pas seulement de créer une charge sur les services avec des opérations répétitives.
Les tests de performance peuvent avoir lieu à la fois sur une charge synthétique et en utilisant un modèle de charge enregistré à partir de la production. Les deux approches ont leurs avantages et leurs inconvénients. La méthode avec une charge réelle peut être davantage caractérisée comme un test de stress - nous obtenons une image réelle des performances du système sous une telle charge, mais nous ne pouvons pas facilement identifier les zones problématiques, mesurer le débit des composants séparément, nous n'obtenons pas les nombres exacts que la charge que les composants individuels peuvent supporter. Dans le cas de l'approche synthétique, nous obtenons des nombres exacts, nous avons une grande flexibilité, et nous pouvons facilement résoudre les problèmes, et en exécutant plusieurs scripts de test en parallèle, nous pouvons reproduire la charge de stress. Les principaux inconvénients de la deuxième approche sont les coûts de main-d'œuvre élevés pour l'écriture de scripts de test, ainsi que le risque croissant de manquer un script important. Par conséquent, nous avons décidé de suivre la voie la plus difficile.
Ainsi, le choix d'un cadre a été déterminé par la tâche. Et notre tâche est de:
- Trouver les goulots d'étranglement de l'API
- Vérifier la résistance aux charges élevées
- Évaluer l'efficacité du service avec la croissance des volumes de données
- Identifier les erreurs cumulatives qui se produisent au fil du temps
Il existe de nombreux frameworks de performance sur le marché qui peuvent déclencher un grand nombre de demandes identiques. Beaucoup d'entre eux ne permettent rien de changer à l'intérieur (par exemple, Apache Benchmark) ou avec des capacités limitées pour décrire des scripts (par exemple, JMeter).
Nous utilisons généralement des scripts plus complexes pour les tests. Souvent, les appels d'API doivent être effectués de manière séquentielle - l'un après l'autre, ou pour modifier les paramètres de demande conformément à une sorte de logique. L'exemple le plus simple lorsque nous voulons tester une API REST du formulaire
PUT /endpoint/resource/<id>
Dans ce cas, vous devez connaître à l'avance le <id> de la ressource que nous voulons modifier afin de mesurer le temps net d'exécution de la requête.
Par conséquent, nous devons pouvoir créer des scripts pour exécuter des requêtes de test complexes.
Plus rapide
Étant donné que les produits Acronis sont conçus pour une charge élevée, nous testons les API dans des dizaines de milliers de demandes par seconde. Il s'est avéré que tous les cadres ne peuvent pas permettre cela. Par exemple, Python n'est pas toujours et pas toujours possible à utiliser pour les tests, car en raison des particularités du langage, la possibilité de créer une grande charge multi-thread est limitée
Un autre problème est l'utilisation des ressources. Par exemple, nous avons d'abord examiné le framework Locust, qui peut être exécuté à partir de plusieurs nœuds matériels à la fois et obtenir de bonnes performances. Mais en même temps, beaucoup de ressources sont consacrées au travail du système de test et son fonctionnement est coûteux.
En conséquence, nous avons choisi le framework K6, qui nous permet de décrire les scripts en Javascript à part entière, et offre des performances supérieures à la moyenne. Ce cadre est écrit en Go et gagne rapidement en popularité. Par exemple, sur Github, le projet a déjà reçu près de 5,5 mille étoiles! K6 se développe activement, et la communauté a déjà proposé près de 3 000 commits, et le projet compte 50 contributeurs qui ont créé 36 branches de code. Bien sûr, K6 est encore loin d'être idéal, mais progressivement le cadre s'améliore, et vous pouvez lire sa comparaison avec Jmeter
ici .
Difficultés et leurs solutions
Étant donné la «jeunesse» de K6, même après un choix équilibré du cadre, nous avons été confrontés à un certain nombre de problèmes. Par exemple, avant de tester une API comme / endpoint /, vous devez d'abord trouver ces points de terminaison d'une manière ou d'une autre. Nous ne pouvons pas utiliser les mêmes valeurs, car en raison de la mise en cache, les résultats seront incorrects.
Vous pouvez obtenir les données dont vous avez besoin de différentes manières:
- Vous pouvez les demander via l'API
- Vous pouvez utiliser un accès direct à la base de données
La deuxième méthode fonctionne plus rapidement et, lors de l'utilisation de bases de données relationnelles, elle s'avère souvent beaucoup plus pratique, car elle vous permet de gagner beaucoup de temps lors de longs tests. Le seul «mais» est que vous ne pouvez l'utiliser que si le code de service et les tests sont écrits par les mêmes personnes. Parce que pour parcourir la base de données, les tests doivent toujours être à jour. Cependant, dans le cas de K6, le cadre n'a pas de mécanismes d'accès aux bases de données. Par conséquent, j'ai dû écrire le module approprié moi-même.
Un autre problème se pose lors du test des API non idempotentes. Dans ce cas, il est important qu'ils ne soient appelés qu'une seule fois avec les mêmes paramètres (par exemple, l'API DELETE). Lors de nos tests, nous préparons les données de test à l'avance, lors de la phase de configuration, lorsque le système est configuré et préparé. Et pendant le test, les mesures sont effectuées à partir d'appels API purs, car le temps et les ressources nécessaires à la préparation des données ne sont plus nécessaires. Cependant, cela pose le problème de la distribution de données pré-préparées sur les flux non synchronisés du test principal. Ce problème a été résolu avec succès en écrivant une file d'attente de données interne. Mais c'est un tout grand sujet, dont nous discuterons dans les prochains articles.
Cadre prêt
Pour résumer, je voudrais noter qu'il n'a pas été facile de trouver un cadre complètement prêt à l'emploi et que je devais encore terminer certaines choses avec mes mains. Néanmoins, nous avons aujourd'hui un outil qui nous convient, qui, compte tenu des améliorations, nous permet d'effectuer des tests complexes, créant une simulation de charges élevées afin de garantir la fonctionnalité de l'API et de l'interface graphique dans différentes conditions.
Dans le prochain article, je parlerai de la façon dont nous avons résolu le problème de tester un service qui prend en charge la connexion simultanée de centaines de milliers de connexions en utilisant des ressources minimales.