Algorithme de recherche floue TextRadar - Approches de base
Contrairement aux comparaisons de chaînes floues, lorsque les deux chaînes comparées sont équivalentes, la chaîne de recherche et la chaîne de données sont mises en évidence dans la tâche de recherche floue, et il est nécessaire de déterminer non pas le degré de similitude des deux chaînes, mais le degré de présence de la chaîne de recherche dans la chaîne de données.
Énoncé du problème
Une chaîne de données et une chaîne de recherche sont données sous forme de jeux de caractères arbitraires constitués de mots - groupes de caractères séparés par des espaces.
Il est nécessaire de trouver dans la ligne de données l'ensemble des fragments les plus proches de la ligne de recherche par la composition et la position relative des caractères.
Pour évaluer la qualité du résultat de la recherche, calculez le coefficient de pertinence, dont la valeur doit être comprise entre 0 et 1, où 0 doit correspondre à l'absence totale de caractères de la chaîne de recherche dans la chaîne de données et 1 doit correspondre à la présence de la chaîne de recherche dans la chaîne de données sous la forme non déformée.
La recherche doit être effectuée par analyse caractère par caractère des lignes sources, en tenant compte de la disposition mutuelle des caractères et des mots dans les lignes, mais sans tenir compte de la syntaxe et de la morphologie de la langue.
Description de l'algorithme
La recherche s'effectue en plusieurs étapes.
Construction d'une matrice de coïncidences
La matrice de correspondance (M) est une matrice bidimensionnelle dont le nombre de colonnes correspond à la longueur de la chaîne de données et le nombre de lignes à la longueur de la chaîne de recherche. Les éléments de la matrice de coïncidence prennent les valeurs 0 ou 1 selon que les caractères correspondants des lignes coïncident ou non, à l'exception des espaces (délimiteurs de mots).
La matrice de correspondance pour la chaîne de données "ABCD EF" et la chaîne de recherche "ABC" a la forme:
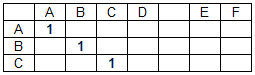
Élément de matrice de correspondance m (i, j) = 1 si d (i) = s (j), où D est un tableau de caractères de chaîne de données, S est un tableau de caractères de chaîne de recherche, i est un numéro de colonne de la matrice de correspondance M (numéro de caractère d'une chaîne de données ), j est le numéro de ligne de la matrice de correspondance (le numéro du caractère dans la chaîne de recherche). Dans les autres cas, m (i, j) = 0. Les correspondances de séparateurs de mots (dans notre cas, les espaces) ne sont pas prises en compte, soit: m (i, j) = 0 si d (i) = s (j) = '' .
Match Matrix Diagonals
Les éléments de la matrice de coïncidence M forment des diagonales. Les éléments de la matrice sont sur la même diagonale si leurs indices i et j diffèrent simultanément de +1 ou de - 1.

Les diagonales correspondent aux positions de la chaîne de recherche dans la séquence de décalages le long de la chaîne de données.

Les éléments de l'une des diagonales et le décalage correspondant dans la figure ci-dessus sont surlignés en bleu.
L'idée d'utiliser une séquence de décalages de ligne les uns par rapport aux autres dans un problème de recherche floue remonte à la technique bien connue de détection de signaux radar sur fond d'interférence, qui implique le calcul de la fonction de corrélation mutuelle des signaux radio. La fonction de corrélation croisée détermine le degré de similitude des copies de deux signaux différents v (t) et u (t), décalés de temps τ l'un par rapport à l'autre et est définie comme l'intégrale: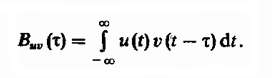
Le nombre total de diagonales est calculé par la formule:

Les longueurs des diagonales sont égales à la longueur de la chaîne de recherche.
Groupes de matchs
Les unités qui se succèdent dans les diagonales de la matrice de coïncidence forment des groupes de correspondances. Vous trouverez ci-dessous les groupes correspondants pour la chaîne de données «ABCD DEF JH» et la chaîne de recherche «ABC DE J» - 4 groupes situés sur différentes diagonales.

Matrices de projection
Les diagonales de la matrice de correspondance et les groupes de correspondance qu'elle contient sont mappés sur les sections correspondantes de la ligne de recherche et de la ligne de données, formant deux matrices de projection - la ligne de recherche et la ligne de données, respectivement. Pour notre exemple, les matrices de projection ressembleront à ceci:
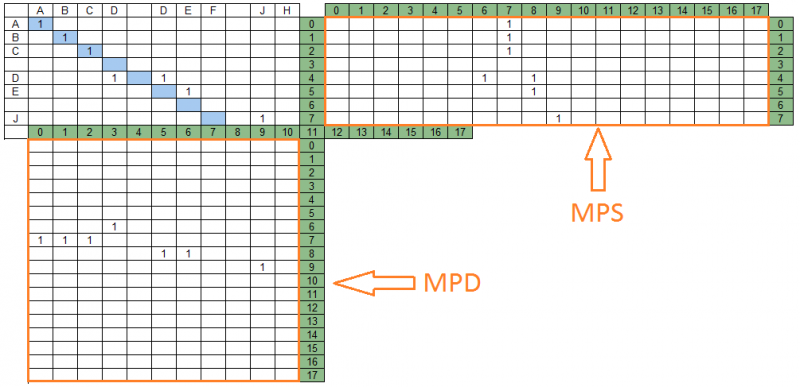
Dans la figure ci-dessus, à droite de la matrice de correspondance se trouve la matrice de projections sur la chaîne de recherche - MPS, en dessous - la matrice de projections sur la chaîne de données MPD. Le nombre de colonnes MPS est égal au nombre de lignes MPD et égal au nombre de diagonales de la matrice de correspondance - dans notre exemple, il y en a 18.
Rechercher un ensemble de résultats de groupes
Pour résoudre le problème, il est nécessaire de trouver un tel ensemble de groupes qui «recouvre» le plus la chaîne de recherche, avec le moins de fragmentation (aussi grande que possible), sans intersections mutuelles dans les matrices de projection, et dont le mappage sur la chaîne de données sera le plus proche de la chaîne de recherche «originale». .
Intersection de groupes dans la matrice de projectionDans notre exemple, il y a des groupes qui se croisent dans la matrice MPS - dans la figure ci-dessous, ils sont surlignés en rouge. De plus, dans la matrice MPD, ces mêmes groupes ne se coupent pas, sur la figure ils sont surlignés en vert.
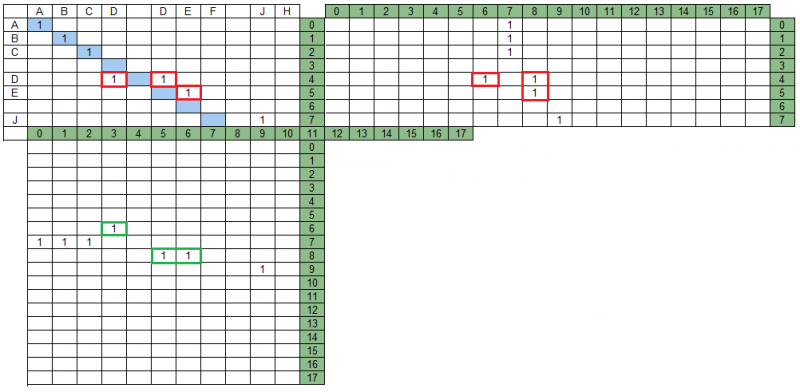
La recherche de l'ensemble de groupes résultant implique que tous les groupes n'y seront pas inclus et que certains des groupes restants peuvent être modifiés (tronqués) lors de l'analyse des intersections mutuelles de groupes dans les projections.
La recherche de l'ensemble de résultats peut être effectuée en passant par le cycle «infini» (le nombre d'itérations du cycle ne dépasse pas le nombre de groupes) du
tableau de tous les groupes , dans lequel les groupes de la matrice de correspondances sont initialement placés, à chaque itération dont les actions suivantes seront effectuées:
- Choisir le meilleur en fonction de certains paramètres (selon le contexte du problème résolu) - dans le cas le plus simple, cela peut être le choix du premier groupe de la plus grande taille qui se présente;
- Placement du meilleur groupe dans le tableau des groupes de résultats et son retrait du tableau de tous les groupes (dont les lignes sont explorées);
- Supprimer (ou tronquer) de la table des groupes se croisant avec le meilleur groupe sélectionné dans les matrices de projection des groupes.
L'ensemble optimal de groupes pour notre exemple est présenté dans la figure ci-dessous - les groupes d'ensemble sont surlignés en orange.

Le groupe supprimé lors du traitement d'intersection (intersection dans la matrice MPS avec le meilleur groupe de la deuxième itération) est surligné en rouge.
Le résultat de la recherche dans la ligne de données ressemblera à ceci:

Calcul du coefficient de pertinence
Pour une évaluation quantitative des résultats de la recherche, la longueur des groupes trouvés est comparée à la longueur des mots de la chaîne de recherche (évaluation de la composition du groupe), ainsi que la longueur totale de la chaîne de recherche avec la longueur des groupes trouvés dans la chaîne de données. On suppose que l'importance d'évaluer la composition des groupes trouvés est supérieure à l'importance de l'estimation de l'étendue dans la ligne de données, qui est prise en compte dans les coefficients de pondération de la formule de calcul du coefficient de pertinence:

Où le coefficient de composition de groupe est calculé comme le rapport de la somme des longueurs au carré des groupes trouvés sur la somme des longueurs au carré des mots de la chaîne de recherche:

Le facteur de longueur est le rapport entre la longueur de la chaîne de recherche et la longueur totale des groupes trouvés sur la chaîne de données. Si la valeur ainsi obtenue est supérieure à 1, sa valeur inverse est prise:

Pour notre exemple:

Portée estimée
Les opérations les plus gourmandes en ressources sont les suivantes:
- détermination de la matrice de correspondance M - le nombre d'éléments de matrice est défini comme le produit de la longueur de la chaîne de recherche par la longueur de la chaîne de données: L * L;
- définition des matrices de projection sur les données et les chaînes de recherche - le nombre d'éléments de matrice sera pour MPS: (L + L - 1) * L, pour MPD: (L + L - 1) * ;
- la formation de la table de tous les groupes - le nombre de groupes ne dépassera pas la valeur L * L / 2;
- rechercher l'ensemble de groupes résultant - le nombre d'itérations du cycle ne dépasse pas le nombre initial de groupes, c'est-à-dire L * L / 2.
Ainsi, le montant total des calculs sera un multiple du produit de la longueur de la chaîne de recherche par la longueur de la chaîne de données:

La linéarité de la quantité de calcul par rapport à la taille des données source est un argument important en faveur de l'application pratique de l'algorithme.
Non linéarité
Il convient de noter que la linéarité est due à une procédure simplifiée pour trouver l'ensemble de groupes résultant. Dans le cas général, si nous considérons toutes les options possibles pour placer des groupes sur une ligne de données, en tenant compte des options de traitement d'intersection possibles et en sélectionnant le meilleur
ensemble de groupes parmi l'ensemble des possibles, plutôt que de choisir
un groupe à chaque itération du cycle, le montant des calculs cessera d'être linéaire par rapport à la taille les données source. La dépendance non linéaire de la quantité de calcul de la taille des données source limite considérablement les possibilités d'application pratique.
Trouvez l'équilibre
Pour assurer l'équilibre optimal entre la qualité de la recherche et le besoin de ressources, il est important de choisir la méthodologie de recherche correcte pour l'ensemble de groupes résultant, qui, en règle générale, peut être effectuée en utilisant les caractéristiques contextuelles du problème résolu.
Un stand de démonstration a
été déployé sur le site web
textradar.ru où vous pouvez tester le fonctionnement de l'algorithme.
Comparaison avec des analogues:
Comparaison de l'algorithme de recherche floue TextRadar avec des analogues: Lucene, Sphinx, Yandex, 1C