Bonjour à tous! Je m'appelle Vlad et je travaille en tant que data scientist dans l'équipe Tinkoff des technologies vocales utilisées dans notre assistant vocal Oleg.
Dans cet article, je voudrais donner un bref aperçu des technologies de synthèse vocale utilisées dans l'industrie et partager l'expérience de notre équipe dans la construction de notre propre moteur de synthèse.

Synthèse vocale
La synthèse vocale est la création d'un son basé sur du texte. Ce problème est aujourd'hui résolu par deux approches:
- Sélection d'unité [1], ou approche concaténative. Il est basé sur le collage de fragments d'audio enregistrés. Depuis la fin des années 90, il a longtemps été considéré comme la norme de facto pour le développement de moteurs de synthèse vocale. Par exemple, une voix émise par la méthode de sélection d'unité peut être trouvée dans Siri [2].
- Synthèse vocale paramétrique [3], dont l'essence est de construire un modèle probabiliste qui prédit les propriétés acoustiques d'un signal audio pour un texte donné.
La parole des modèles de sélection d'unité est de haute qualité, à faible variabilité et nécessite une grande quantité de données pour la formation. Dans le même temps, pour la formation de modèles paramétriques, une quantité de données beaucoup plus faible est nécessaire, ils génèrent des intonations plus diverses, mais jusqu'à récemment, ils souffraient d'une qualité sonore globale plutôt médiocre par rapport à l'approche de sélection d'unité.
Cependant, avec le développement des technologies d'apprentissage en profondeur, les modèles de synthèse paramétrique ont connu une croissance significative dans toutes les mesures de qualité et sont capables de créer une parole qui est pratiquement impossible à distinguer de la parole humaine.
Mesures de qualité
Avant de parler des meilleurs modèles de synthèse vocale, vous devez déterminer les mesures de qualité par lesquelles les algorithmes seront comparés.
Étant donné que le même texte peut être lu d'une infinité de façons, a priori la bonne façon de prononcer une phrase spécifique n'existe pas. Par conséquent, souvent les mesures de la qualité de la synthèse vocale sont subjectives et dépendent de la perception de l'auditeur.
La métrique standard est le MOS (score d'opinion moyen), une évaluation moyenne du caractère naturel de la parole, donnée par les évaluateurs pour l'audio synthétisé sur une échelle de 1 à 5. Un signifie un son totalement invraisemblable et cinq signifie un discours qui ne peut être distingué de l'homme. Les enregistrements de personnes réelles obtiennent généralement environ 4,5, et une valeur supérieure à 4 est considérée comme assez élevée.
Fonctionnement de la synthèse vocale
La première étape de la construction d'un système de synthèse vocale consiste à collecter des données pour la formation. Il s'agit généralement d'enregistrements audio de haute qualité sur lesquels l'annonceur lit des phrases spécialement sélectionnées. La taille approximative de l'ensemble de données requis pour les modèles de sélection des unités d'apprentissage est de 10 à 20 heures de parole pure [2], tandis que pour les méthodes paramétriques de réseau neuronal, l'estimation supérieure est d'environ 25 heures [4, 5].
Nous discutons des deux technologies de synthèse.
Sélection d'unité
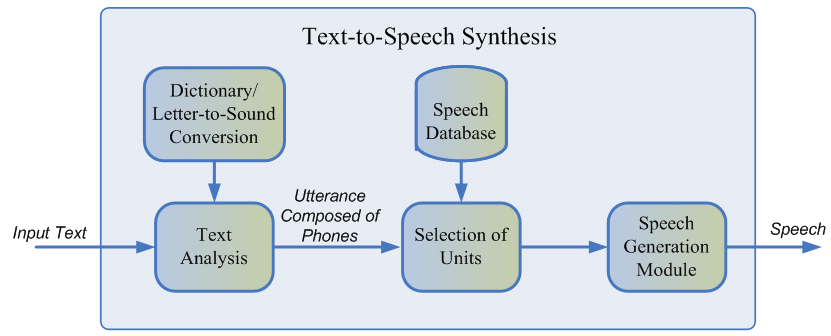
En règle générale, le discours enregistré du locuteur ne peut pas couvrir tous les cas possibles dans lesquels la synthèse sera utilisée. Par conséquent, l'essence de la méthode consiste à diviser la base audio entière en petits fragments appelés unités, qui sont ensuite collés ensemble en utilisant un post-traitement minimal. Les unités sont généralement des unités de langage acoustique minimales, telles que les demi-téléphones ou les diphons [2].
L'ensemble du processus de génération se compose de deux étapes: le frontend NLP, qui est responsable de l'extraction de la représentation linguistique du texte, et le backend, qui calcule la fonction de pénalité unitaire pour les caractéristiques linguistiques données. L'interface PNL comprend:
- La tâche de normalisation du texte est la traduction de tous les caractères non alphabétiques (chiffres, signes de pourcentage, devises, etc.) dans leur représentation verbale. Par exemple, «5%» doit être converti en «cinq pour cent».
- Extraire les caractéristiques linguistiques d'un texte normalisé: représentation des phonèmes, stress, parties du discours, etc.
En règle générale, le frontend NLP est implémenté à l'aide de règles prescrites manuellement pour un langage spécifique, mais récemment, il y a eu un biais croissant vers l'utilisation de modèles d'apprentissage automatique [7].
La pénalité estimée par le sous-système backend est la somme du coût cible, ou la correspondance de la représentation acoustique de l'unité pour un phonème particulier, et du coût de concaténation, c'est-à-dire la pertinence de connecter deux unités voisines. Pour évaluer les fonctions fines, on peut utiliser les règles ou le modèle acoustique déjà formé de la synthèse paramétrique [2]. La sélection de la séquence d'unités la plus optimale du point de vue des pénalités définies ci-dessus s'effectue à l'aide de l'algorithme de Viterbi [1].
Valeurs approximatives des modèles de sélection d'unités MOS pour la langue anglaise: 3.7-4.1 [2, 4, 5].
Avantages de l'approche de sélection des unités:
- Le son naturel.
- Génération à grande vitesse.
- Petite taille des modèles - cela vous permet d'utiliser la synthèse directement sur votre appareil mobile.
Inconvénients:
- Le discours synthétisé est monotone, ne contient pas d'émotions.
- Artefacts de collage caractéristiques.
- Il nécessite une base de formation audio suffisamment large pour couvrir toutes sortes de contextes.
- En principe, il ne peut pas générer de son qui ne se trouve pas dans l'ensemble d'entraînement.
Synthèse vocale paramétrique
L'approche paramétrique est basée sur l'idée de construire un modèle probabiliste qui estime la distribution des caractéristiques acoustiques d'un texte donné.
Le processus de génération de la parole dans la synthèse paramétrique peut être divisé en quatre étapes:
- Le frontend NLP est le même stade de prétraitement des données que dans l'approche de sélection d'unité, dont le résultat est un grand nombre de fonctionnalités linguistiques contextuelles.
- Modèle de durée prédisant la durée des phonèmes.
- Un modèle acoustique qui rétablit la distribution des caractéristiques acoustiques sur les caractéristiques linguistiques. Les caractéristiques acoustiques incluent les valeurs de fréquence fondamentales, la représentation spectrale du signal, etc.
- Un vocodeur traduisant les caractéristiques acoustiques en une onde sonore.
Pour la durée de la formation et les modèles acoustiques, des modèles de Markov cachés [3], des réseaux de neurones profonds ou leurs variétés récurrentes [6] peuvent être utilisés. Un vocodeur traditionnel est un algorithme basé sur le modèle de filtre source [3], qui suppose que la parole est le résultat de l'application d'un filtre de bruit linéaire au signal d'origine.
La qualité globale de la parole des méthodes paramétriques classiques est assez faible en raison du grand nombre d'hypothèses indépendantes sur la structure du processus de génération du son.
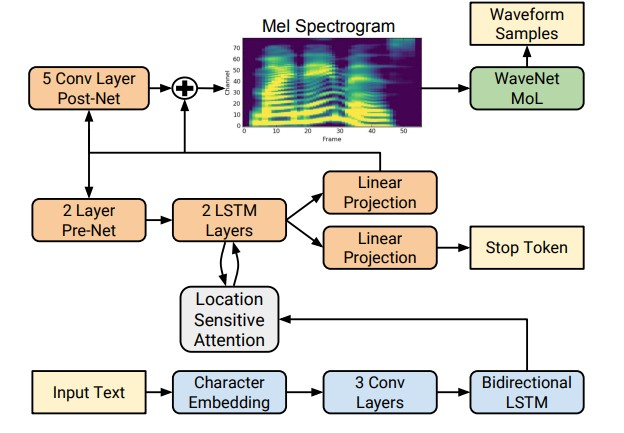
Cependant, avec l'avènement des technologies d'apprentissage en profondeur, il est devenu possible de former des modèles de bout en bout qui prédisent directement les signes acoustiques par lettre. Par exemple, les réseaux de neurones Tacotron [4] et Tacotron 2 [5] entrent une séquence de lettres et renvoient le spectrogramme de craie en utilisant l'algorithme seq2seq [8]. Ainsi, les étapes 1 à 3 de l'approche classique sont remplacées par un seul réseau neuronal. Le schéma ci-dessous montre l'architecture du réseau Tacotron 2, qui atteint une qualité sonore assez élevée.
Un autre facteur d'une augmentation significative de la qualité de la parole synthétisée a été l'utilisation de vocodeurs de réseau neuronal au lieu d'algorithmes de traitement du signal numérique.
Le premier de ces vocodeurs était le réseau neuronal WaveNet [9], qui séquentiellement, étape par étape, prédit l'amplitude de l'onde sonore.
En raison de l'utilisation d'un grand nombre de couches convolutives avec des lacunes pour capturer plus de contexte et sauter la connexion dans l'architecture de réseau, il a été possible d'obtenir une amélioration d'environ 10% du MOS par rapport aux modèles de sélection d'unité. Le schéma ci-dessous montre l'architecture du réseau WaveNet.

Le principal inconvénient de WaveNet est la faible vitesse associée à un circuit d'échantillonnage de signal série. Ce problème peut être résolu soit en utilisant l'optimisation d'ingénierie pour une architecture de fer spécifique, soit en remplaçant le schéma d'échantillonnage par un schéma plus rapide.
Les deux approches ont été mises en œuvre avec succès dans l'industrie. Le premier est sur Tinkoff.ru, et dans le cadre de la seconde approche, Google a introduit le réseau Parallel WaveNet [10] en 2017, dont les réalisations sont utilisées dans l'Assistant Google.
Valeurs approximatives de MOS pour les méthodes de réseau neuronal: 4,4–4,5 [5, 11], c'est-à-dire que la parole synthétisée n'est pratiquement pas différente de la parole humaine.
Avantages de la synthèse paramétrique:
- Son naturel et lisse lors de l'utilisation de l'approche de bout en bout.
- Plus grande variété d'intonation.
- Utilisez moins de données que les modèles de sélection d'unité.
Inconvénients:
- Faible vitesse par rapport à la sélection d'unité.
- Grande complexité de calcul.
Fonctionnement de la synthèse vocale Tinkoff
Comme il ressort de la revue, les méthodes de synthèse vocale paramétrique basées sur les réseaux de neurones sont actuellement nettement supérieures en qualité à l'approche de sélection d'unité et sont beaucoup plus simples à développer. Par conséquent, pour construire notre propre moteur de synthèse, nous les avons utilisés.
Pour les modèles de formation, environ 25 heures de discours pur d'un locuteur professionnel ont été utilisées. Les textes de lecture ont été spécialement sélectionnés pour couvrir au mieux la phonétique de la parole familière. De plus, afin d'ajouter plus de variété à la synthèse en intonation, nous avons demandé à l'annonceur de lire des textes avec une expression selon le contexte.
L'architecture de notre solution ressemble conceptuellement à ceci:
- Frontend NLP, qui inclut la normalisation du texte du réseau neuronal et un modèle pour placer les pauses et les contraintes.
- Tacotron 2 accepte les lettres en entrée.
- WaveNet autorégressif, fonctionnant en temps réel sur le CPU.
Grâce à cette architecture, notre moteur génère une parole expressive de haute qualité en temps réel, ne nécessite pas la construction d'un dictionnaire phonémique et permet de contrôler les contraintes dans les mots individuels. Des exemples d'audio synthétisés peuvent être entendus en cliquant sur le lien .
Références:
[1] AJ Hunt, AW Black. Sélection d'unité dans un système de synthèse vocale concaténative à l'aide d'une grande base de données vocales, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio , R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Système de synthèse vocale Siri On-Device Deep Learning-Guided Unit Selection, Interspeech, 2017.
[3] H. Zen, K. Tokuda, AW Black. Synthèse statistique paramétrique de la parole, Speech Communication, Vol. 51, non. 11, pp. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous . Tacotron: Vers une synthèse vocale de bout en bout.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Synthèse TTS naturelle en conditionnant WaveNet sur les prédictions du spectrogramme Mel.
[6] Heiga Zen, Andrew Senior, Mike Schuster. Synthèse statistique paramétrique de la parole à l'aide de réseaux de neurones profonds.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Xiaochang Peng, Kyle Gorman, Brian Roark. Modèles neuronaux de normalisation de texte pour les applications vocales.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Apprentissage de séquence en séquence avec les réseaux de neurones.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: un modèle génératif pour l'audio brut.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman , Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, Demis Hassabis. Parallel WaveNet: Synthèse vocale rapide haute fidélité.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: génération d'ondes parallèles dans la synthèse vocale de bout en bout.
[12] Dario Rethage, Jordi Pons, Xavier Serra. Un Wavenet pour le débruitage de la parole.