Performances dans .NET Core

Bonjour à tous! Cet article est un recueil de bonnes pratiques que mes collègues et moi-même utilisons depuis longtemps pour travailler sur différents projets.
Informations sur la machine sur laquelle les calculs ont été effectués:BenchmarkDotNet = v0.11.5, OS = Windows 10.0.18362
Processeur Intel Core i5-8250U 1,60 GHz (Kaby Lake R), 1 processeur, 8 cœurs logiques et 4 cœurs physiques
SDK .NET Core = 3.0.100
[Hôte]: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), RyuJIT 64 bits
Noyau: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), RyuJIT 64 bits
[Hôte]: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), RyuJIT 64 bits
Noyau: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), RyuJIT 64 bits
Job = Core Runtime = Core
ToList vs ToArray et Cycles
J'avais prévu de préparer ces informations avec la sortie de .NET Core 3.0, mais ils m'ont devancé, je ne veux pas voler la renommée de quelqu'un d'autre et copier les informations de quelqu'un d'autre, je vais donc simplement pointer
vers un bon article où la comparaison est détaillée .
De ma part, je veux juste vous présenter mes mesures et mes résultats, je leur ai ajouté des boucles inverses pour les amoureux du "style C ++" des boucles d'écriture.
Code:public class Bench { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random random = new Random(); _list = Enumerable.Repeat(0, N).Select(i => random.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForListFromEnd() { int total = 0;t for (int i = _list.Count-1; i > 0; i--) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } [Benchmark] public int ForArrayFromEnd() { int total = 0; for (int i = _array.Length-1; i > 0; i--) { total += _array[i]; } return total; } }
Les performances dans .NET Core 2.2 et 3.0 sont presque identiques. Voici ce que j'ai réussi à obtenir dans .NET Core 3.0:
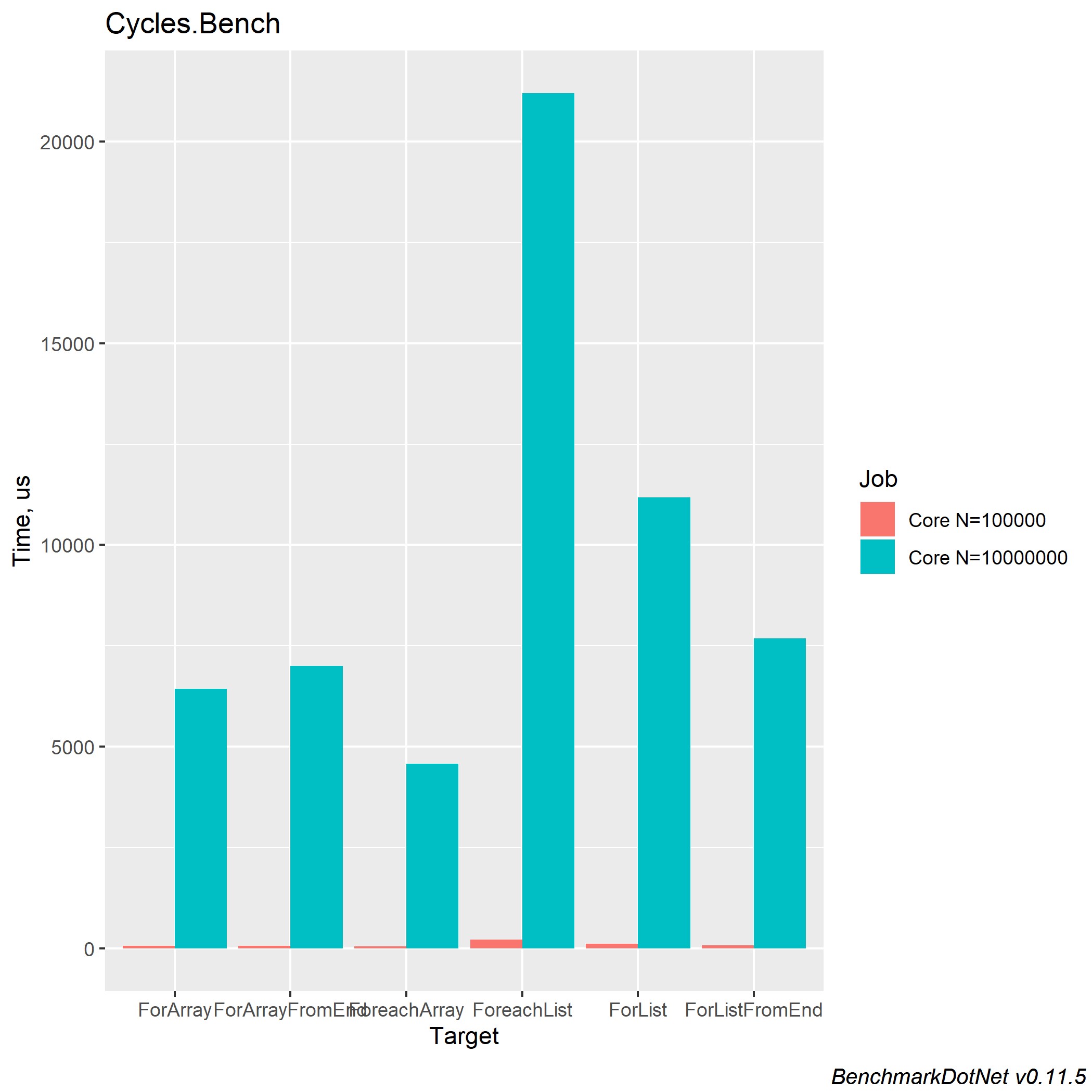
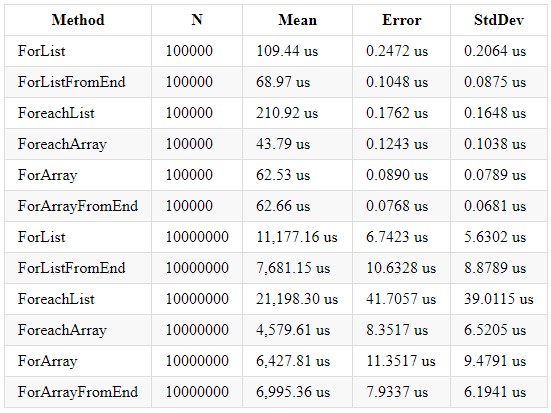
On peut conclure que le traitement en boucle d'une collection de type Array est plus rapide, du fait de ses optimisations internes et de l'allocation explicite de la taille de la collection. Il convient également de rappeler qu'une collection de type List a ses avantages et vous devez utiliser la collection souhaitée en fonction des calculs nécessaires. Même si vous écrivez la logique du travail avec des cycles, n'oubliez pas qu'il s'agit d'une boucle ordinaire et qu'elle est également soumise à une éventuelle optimisation des cycles. Un article est apparu sur habr pendant longtemps:
https://habr.com/en/post/124910/ . Il est toujours pertinent et recommandé pour la lecture.
Jeter
Il y a un an, j'ai travaillé dans une entreprise sur un projet hérité, dans ce projet, il était normal de gérer la validation sur le terrain via une construction try-catch-throw. J'ai déjà compris qu'il s'agissait d'une logique commerciale malsaine du projet, j'ai donc essayé de ne pas utiliser une telle conception si possible. Mais voyons quelle est la mauvaise approche pour gérer les erreurs avec une telle conception. J'ai écrit un petit code afin de comparer les deux approches et tiré les «bancs» pour chaque option.
Code: public bool ContainsHash() { bool result = false; foreach (var file in _files) { var extension = Path.GetExtension(file); if (_hash.Contains(extension)) result = true; } return result; } public bool ContainsHashTryCatch() { bool result = false; try { foreach (var file in _files) { var extension = Path.GetExtension(file); if (_hash.Contains(extension)) result = true; } if(!result) throw new Exception("false"); } catch (Exception e) { result = false; } return result; }
Les résultats dans .NET Core 3.0 et Core 2.2 ont un résultat similaire (.NET Core 3.0):
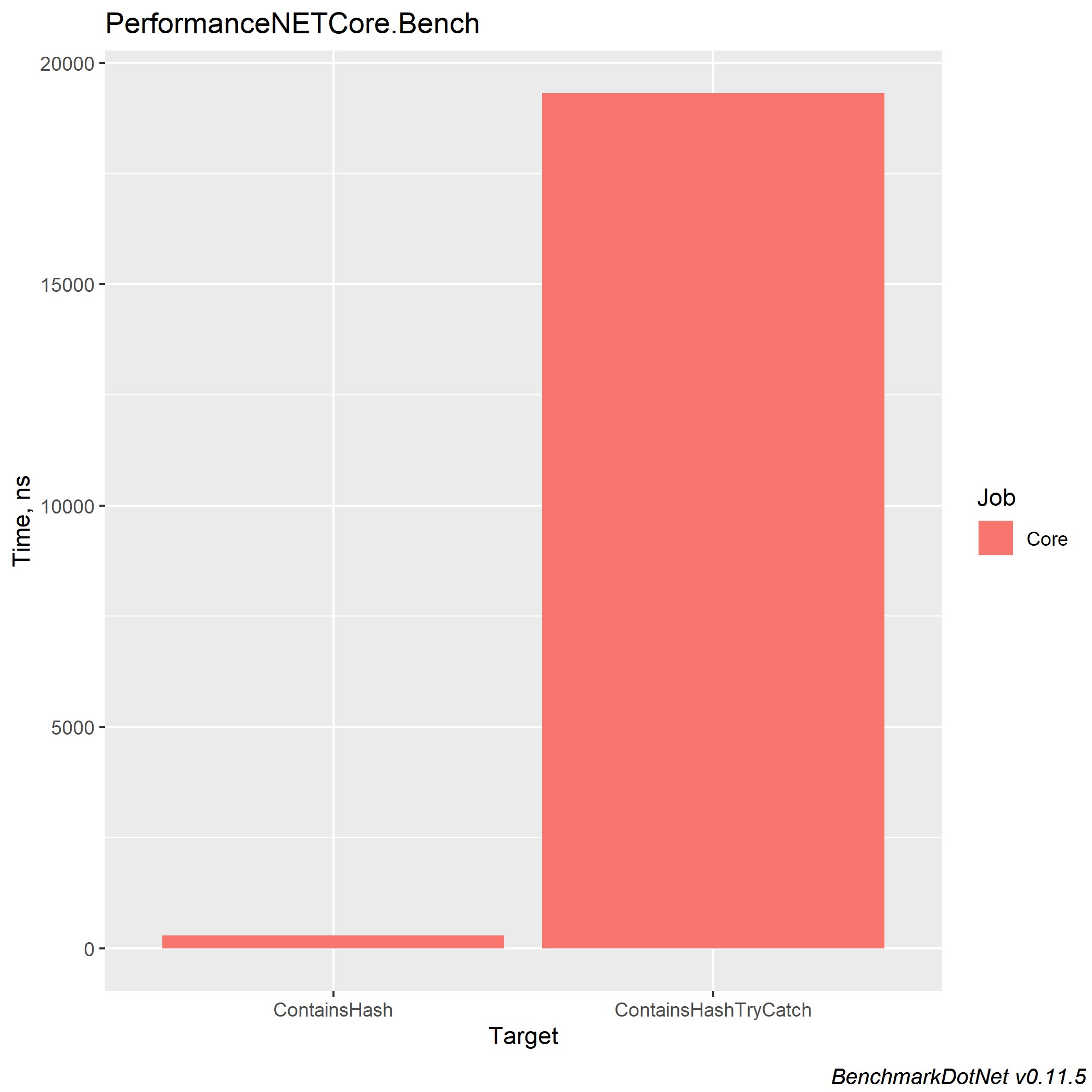
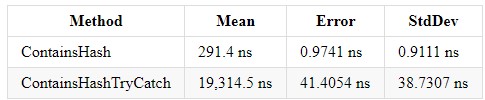
Try catch complique la compréhension du code et augmente le temps d'exécution de votre programme. Mais si vous avez besoin de cette construction, vous ne devez pas insérer les lignes de code à partir desquelles la gestion des erreurs n'est pas attendue - cela facilitera la compréhension du code. En fait, ce n'est pas tant la gestion des exceptions qui charge le système que le lancement des erreurs elles-mêmes par le biais de la nouvelle construction throw Exception.
Le lancement d'exceptions est plus lent que n'importe quelle classe qui collecte une erreur au format souhaité. Si vous traitez un formulaire ou des données et que vous savez évidemment quelle erreur devrait être, alors pourquoi ne pas la traiter?
Vous ne devez pas écrire throw new Exception () si cette situation n'est pas exceptionnelle.
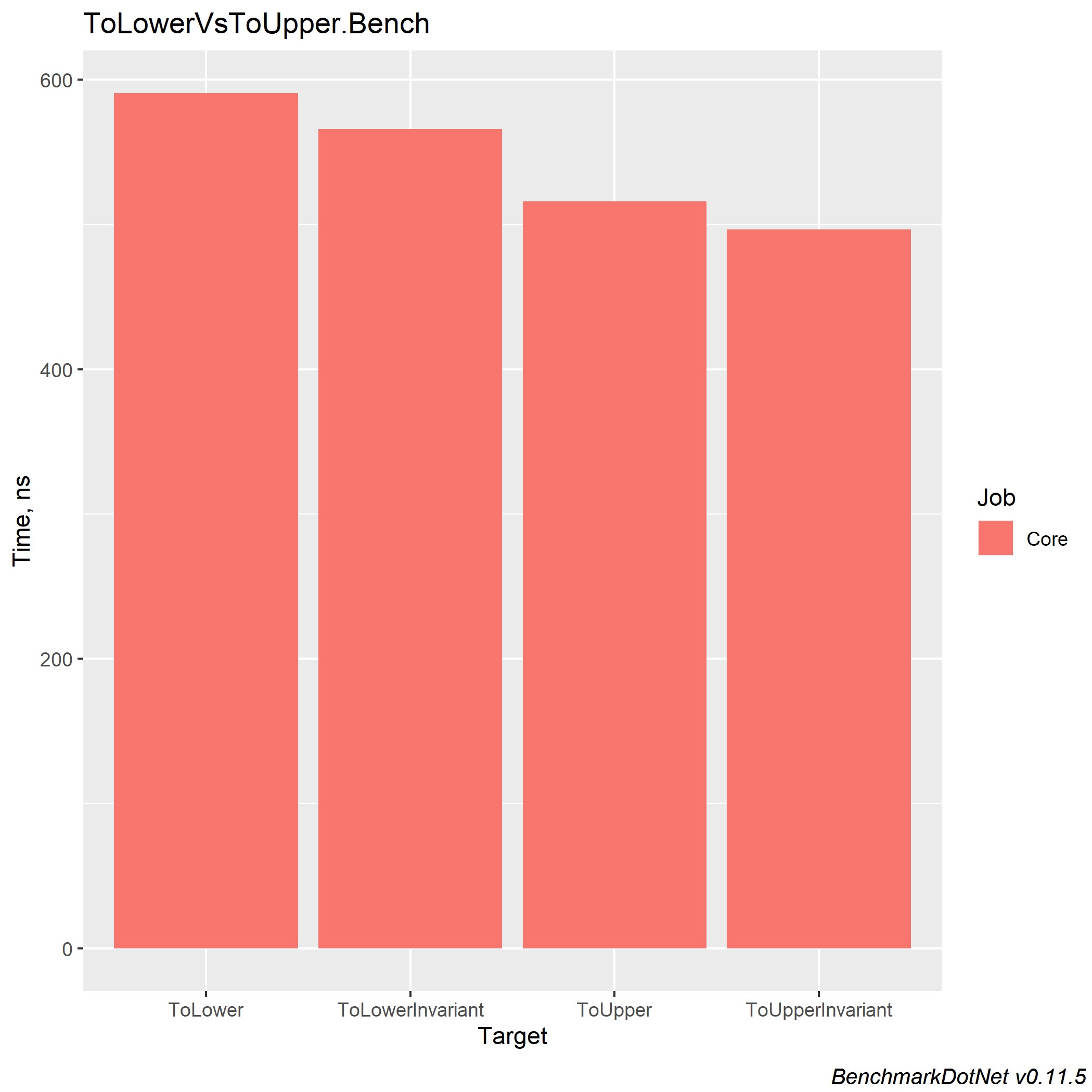
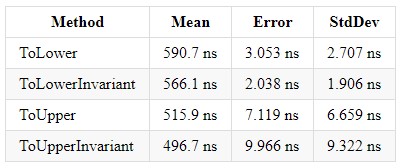
Gérer et lever une exception coûte très cher !!!ToLower, ToLowerInvariant, ToUpper, ToUpperInvariant
Au cours de ses 5 années d'expérience sur la plate-forme .NET, il a rencontré de nombreux projets utilisant la correspondance de chaînes. J'ai également vu l'image suivante: il y avait une solution d'entreprise avec de nombreux projets, chacun effectuant des comparaisons de chaînes de différentes manières. Mais qu'est-ce qui vaut la peine d'être utilisé et comment l'unifier? Dans le CLR de Richter via C #, j'ai lu que ToUpperInvariant () est plus rapide que ToLowerInvariant ().
Extrait du livre:

Bien sûr, je n'y croyais pas et j'ai décidé de faire des tests à l'époque sur le .NET Framework et le résultat m'a choqué - augmentation de plus de 15% des performances. Plus loin à mon arrivée au travail le lendemain matin, j'ai montré ces mesures à mes supérieurs et leur ai donné accès à la source. Après cela, 2 projets sur 14 ont été modifiés pour de nouvelles mesures, et étant donné que ces deux projets existaient pour traiter d'énormes tableaux Excel, le résultat était plus que significatif pour le produit.
Je vous présente également des mesures pour différentes versions de .NET Core, afin que chacun de vous puisse faire un choix dans la direction de la solution la plus optimale. Et je veux juste ajouter que dans l'entreprise où je travaille, nous utilisons ToUpper () pour comparer les chaînes.
Code: public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3"; [Benchmark] public bool ToLower() { return defaultString.ToLower() == defaultString.ToLower(); } [Benchmark] public bool ToLowerInvariant() { return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant(); } [Benchmark] public bool ToUpper() { return defaultString.ToUpper() == defaultString.ToUpper(); } [Benchmark] public bool ToUpperInvariant() { return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant(); } ; public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3"; [Benchmark] public bool ToLower() { return defaultString.ToLower() == defaultString.ToLower(); } [Benchmark] public bool ToLowerInvariant() { return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant(); } [Benchmark] public bool ToUpper() { return defaultString.ToUpper() == defaultString.ToUpper(); } [Benchmark] public bool ToUpperInvariant() { return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant(); }
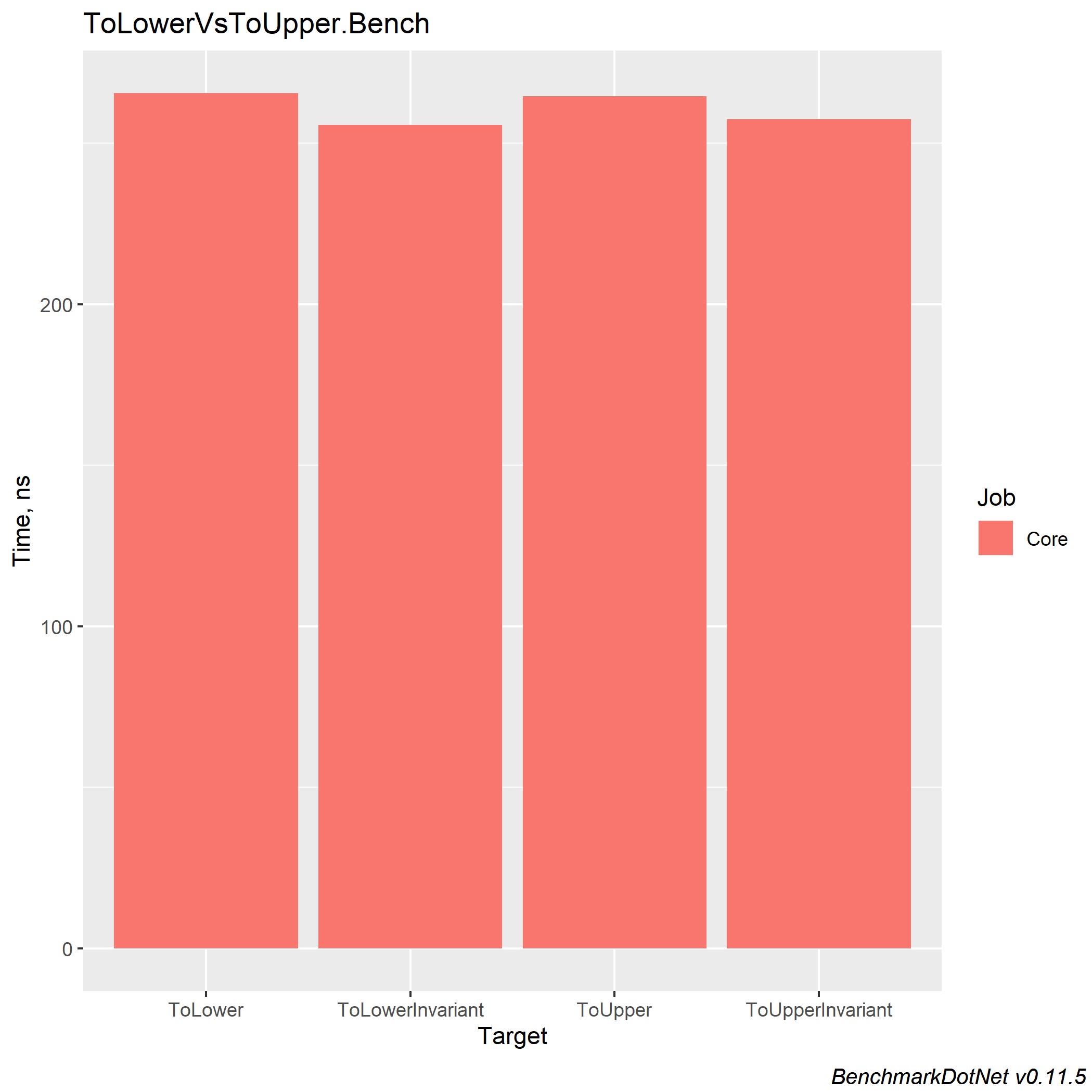
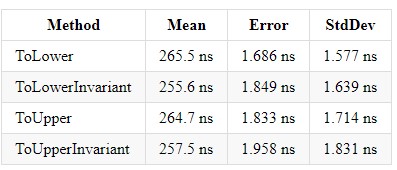
Dans .NET Core 3.0, le gain pour chacune de ces méthodes est ~ x2 et équilibre les implémentations entre elles.
Compilation de niveaux
Dans mon dernier article, j'ai brièvement décrit cette fonctionnalité, je voudrais corriger et compléter mes mots. La compilation à plusieurs niveaux accélère le temps de lancement de votre solution, mais vous sacrifiez des parties de votre code pour les compiler en une version plus optimisée en arrière-plan, ce qui peut entraîner une légère surcharge. Avec l'avènement de NET Core 3.0, le temps de construction des projets avec la compilation des niveaux a permis de réduire et de corriger les bogues liés à cette technologie. Auparavant, cette technologie entraînait des erreurs dans les premières requêtes dans ASP.NET Core et des blocages lors de la première génération en mode de compilation à plusieurs niveaux. Actuellement, il est activé par défaut dans .NET Core 3.0, mais vous pouvez le désactiver comme vous le souhaitez. Si vous êtes chef d'équipe, senior, intermédiaire ou que vous êtes le chef du département, vous devez comprendre que le développement rapide du projet augmente la valeur de l'équipe et cette technologie vous permettra d'économiser à la fois le temps des développeurs et le temps de travail du projet.
Niveau supérieur .NET
Mettez à niveau votre .NET Framework / .NET Core. Souvent, chaque nouvelle version améliore les performances et ajoute de nouvelles fonctionnalités.
Mais quels sont exactement les avantages? Regardons certains d'entre eux:
- Dans .NET Core 3.0, des images R2R ont été introduites afin de réduire le temps de démarrage des applications .NET Core.
- La version 2.2 a introduit la compilation de niveaux, grâce à laquelle les programmeurs passeront moins de temps à lancer un projet.
- Prise en charge de la nouvelle norme .NET.
- Prise en charge de la nouvelle version du langage de programmation.
- Optimisation, avec chaque nouvelle version, l'optimisation est améliorée par les bibliothèques de base Collection / Struct / Stream / String / Regex et bien plus encore. Si vous effectuez une mise à niveau du .NET Framework vers le .NET Core, vous obtiendrez une amélioration considérable des performances dès le départ. Par exemple, j'attache un lien vers une partie des optimisations qui ont été ajoutées dans .NET Core 3.0: https://devblogs.microsoft.com/dotnet/performance-improvements-in-net-core-3-0/

Conclusion
Lors de l'écriture de code, vous devez prêter attention aux différents aspects de votre projet et utiliser les fonctions de votre langage de programmation et de votre plateforme pour obtenir le meilleur résultat. Je serai heureux si vous partagez vos connaissances liées à l'optimisation dans .NET.
Lien Github