Phoebe Wong, scientifique et directrice financière chez Equal Citizens, a parlé du conflit culturel dans les sciences cognitives. Elena Kuzmina a traduit l'article en russe.
Il y a quelques années, j'ai regardé une discussion sur le traitement du langage naturel. Le «père de la linguistique moderne»,
Noam Chomsky, et le nouveau porte-parole des gardes,
Peter Norvig , directeur de la recherche chez Google, ont pris la parole.
Chomsky a réfléchi dans quelle direction la sphère du traitement du langage naturel se déplace, et a
déclaré :
Supposons que quelqu'un s'apprête à liquider un département de physique et souhaite le faire selon les règles. Selon les règles, il s'agit de prendre un nombre infini de vidéos sur ce qui se passe dans le monde, d'alimenter ces gigaoctets de données sur l'ordinateur le plus grand et le plus rapide et de mener une analyse statistique complexe - eh bien, vous comprenez: bayésien "d'avant en arrière" * - et vous obtiendrez une certaine prévision sur ce qui va se passer en dehors de votre fenêtre. En fait, vous obtiendrez une meilleure prévision que celle donnée par la Faculté de physique. Eh bien, si le succès est déterminé par la proximité de la masse de données brutes chaotiques, alors il vaut mieux le faire que la façon dont les physiciens le font: pas d’expériences de pensée sur des surfaces idéales, etc. Mais vous n'obtiendrez pas le genre de compréhension que la science a toujours recherchée. Ce que vous obtenez n'est qu'une idée approximative de ce qui se passe dans la réalité.
* De la probabilité de Bayes - une interprétation du concept de probabilité, dans laquelle, au lieu de la fréquence ou de la tendance à un phénomène, la probabilité est interprétée comme une attente raisonnable, représentant une évaluation quantitative d'une croyance personnelle ou d'un état de connaissance. Les chercheurs en intelligence artificielle utilisent les statistiques bayésiennes dans l'apprentissage automatique pour aider les ordinateurs à reconnaître les modèles et à prendre des décisions en fonction de ceux-ci.
Chomsky a souligné à plusieurs reprises cette idée: le succès d'aujourd'hui dans le traitement du langage naturel, à savoir l'exactitude des prévisions, n'est pas une science. Selon lui, jeter une énorme partie de texte dans une «machine complexe» revient simplement à approximer des données brutes ou à collecter des insectes, cela ne mènera pas à une réelle compréhension de la langue.
Selon Chomsky, le principal objectif de la science est de découvrir des principes explicatifs du fonctionnement réel du système, et la bonne approche pour atteindre cet objectif est de permettre à la théorie de diriger les données. Il est nécessaire d'étudier la nature fondamentale du système en faisant abstraction des «inclusions non pertinentes» à l'aide d'expériences soigneusement conçues, c'est-à-dire de la même manière que celle acceptée en science à l'époque de Galilée.
Dans ses mots:
Une simple tentative de traiter des données chaotiques brutes ne vous mènera probablement nulle part, tout comme Galileo ne mènerait nulle part.
Par la suite, Norwig a répondu aux affirmations de Chomsky dans un
long essai . Norvig note que dans presque tous les domaines de l'application du traitement du langage: moteurs de recherche, reconnaissance vocale, traduction automatique et réponse aux questions, les modèles probabilistes formés prévalent car ils fonctionnent bien mieux que les anciens outils basés sur des règles théoriques ou logiques. Il dit que le critère de réussite de Chomsky en science - l'accent mis sur la question «pourquoi» et la sous-estimation de l'importance du «comment» - est faux.
Confirmant sa position, il cite Richard Feynman: "La physique peut se développer sans preuves, mais nous ne pouvons pas nous développer sans faits." Norwig rappelle que les modèles probabilistes génèrent plusieurs billions de dollars par an, tandis que les descendants de la théorie de Chomsky gagnent bien moins d'un milliard, citant les livres de Chomsky vendus sur Amazon.
Norwig suggère que le mépris de Chomsky pour les «va-et-vient bayésiens» est dû à la division entre les
deux cultures dans la modélisation statistique décrite par Leo Breiman:
- Une culture de modélisation des données qui suppose que la nature est une boîte noire où les variables sont connectées de manière stochastique. Le travail des experts en modélisation est de déterminer le modèle qui correspond le mieux aux associations qui le sous-tendent.
- La culture de la modélisation algorithmique implique que les associations dans une boîte noire sont trop complexes pour être décrites à l'aide d'un modèle simple. Le travail des développeurs de modèles consiste à sélectionner l'algorithme qui évalue le mieux le résultat à l'aide de variables d'entrée, sans s'attendre à ce que les véritables associations de base des variables à l'intérieur de la boîte noire puissent être comprises.
Norwig suggère que Chomsky ne polémise pas tant avec des modèles probabilistes en tant que tels, mais plutôt n'accepte pas les modèles algorithmiques avec des «paramètres quadrillionnaires»: ils ne sont pas faciles à interpréter et donc ils sont inutiles pour résoudre les questions du «pourquoi».
Norwig et Breiman appartiennent à un autre camp - ils croient que les systèmes tels que les langues sont trop complexes, aléatoires et arbitraires pour être représentés par un petit ensemble de paramètres. Et l'abstraction des difficultés revient à faire un outil mystique à l'écoute d'un certain domaine permanent qui n'existe pas réellement, et donc la question de ce qu'est la langue et comment elle fonctionne est ignorée.
Norwig réaffirme sa thèse dans
un autre article , où il soutient que nous devrions cesser d'agir comme si notre objectif était de créer des théories extrêmement élégantes. Au lieu de cela, vous devez accepter la complexité et utiliser notre meilleur allié - l'efficacité déraisonnable des données. Il souligne que dans la reconnaissance vocale, la traduction automatique et presque toutes les applications d'apprentissage automatique pour les données Web, les modèles simples comme les modèles n-gram ou les classificateurs linéaires basés sur des millions de fonctions spécifiques fonctionnent mieux que les modèles complexes. qui essaient de découvrir les règles générales.
Ce qui m'attire le plus dans cette discussion n'est pas sur quoi Chomsky et Norvig ne sont pas d'accord, mais sur quoi ils sont unis. Ils conviennent que l'analyse d'énormes quantités de données à l'aide de méthodes d'apprentissage statistique sans comprendre les variables fournit de meilleures prédictions qu'une approche théorique qui tente de modéliser la façon dont les variables sont liées les unes aux autres.
Et je ne suis pas le seul à être perplexe à ce sujet: de nombreuses personnes ayant une formation mathématique avec qui j'ai parlé trouvent également cela contradictoire. L'approche la mieux adaptée à la modélisation des relations structurelles de base ne devrait-elle pas également avoir le plus grand pouvoir prédictif? Ou comment pouvons-nous prédire avec précision quelque chose sans savoir comment tout fonctionne?
Prédictions contre la causalité
Même dans les domaines universitaires, tels que l'économie et d'autres sciences sociales, les concepts de pouvoir prédictif et explicatif sont souvent combinés les uns avec les autres.
Les modèles qui montrent une grande capacité d'explication sont souvent considérés comme hautement prédictifs. Mais l'approche pour construire le meilleur modèle prédictif est complètement différente de l'approche pour construire le meilleur modèle explicatif, et les décisions de modélisation conduisent souvent à des compromis entre les deux objectifs. Les différences méthodologiques sont illustrées dans
Introduction to Statistical Learning (ISL).
Modélisation prédictive
Le principe fondamental des modèles prédictifs est relativement simple: évaluer Y en utilisant un ensemble de données d'entrée facilement disponibles X. Si l'erreur X est en moyenne nulle, Y peut être prédit en utilisant:
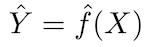
où ƒ est l'information systématique sur Y fournie par X, qui conduit à Ŷ (prédiction de Y) pour un X donné. La forme fonctionnelle exacte n'est généralement pas significative si elle prédit Y, et ƒ est considérée comme une «boîte noire».
La précision de ce type de modèle peut être décomposée en deux parties: une erreur réductible et une erreur fatale:
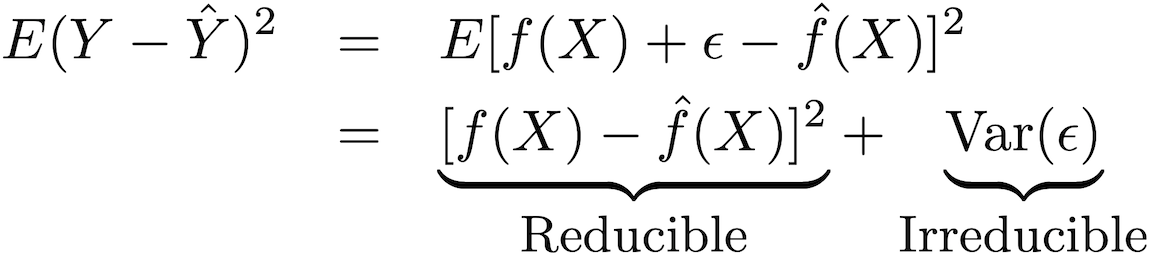
Afin d'augmenter la précision de la prévision du modèle, il est nécessaire de minimiser l'erreur réductible, en utilisant les méthodes les plus appropriées de formation statistique pour l'estimation afin d'évaluer ƒ.
Modélisation de sortie
ƒ ne peut pas être considéré comme une «boîte noire» si l'objectif est de comprendre la relation entre X et Y (comment Y change en fonction de X). Parce que nous ne pouvons pas déterminer l'effet de X sur Y sans connaître la forme fonctionnelle ƒ.
Presque toujours lors de la modélisation des conclusions, des méthodes paramétriques sont utilisées pour estimer ƒ. Le critère paramétrique fait référence à la façon dont cette approche simplifie l'estimation de ƒ en prenant la forme paramétrique ƒ et en évaluant ƒ à travers les paramètres proposés. Cette approche comporte deux étapes principales:
1. Faites une hypothèse sur la forme fonctionnelle ƒ. L'hypothèse la plus courante est que ƒ est linéaire dans X:
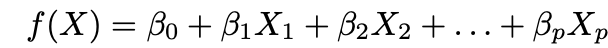
2. Utilisez les données pour ajuster le modèle, c'est-à-dire trouvez les valeurs des paramètres β₀, β₁, ..., βp telles que:
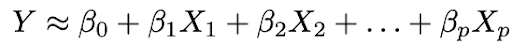
L'approche d'ajustement de modèle la plus courante est la méthode des moindres carrés (OLS).
Le compromis entre flexibilité et interprétabilité
Vous vous demandez peut-être déjà: comment savons-nous que ƒ est linéaire? En fait, nous ne le saurons pas, car la vraie forme ƒ est inconnue. Et si le modèle sélectionné est trop éloigné du réel ƒ, nos estimations seront biaisées. Alors, pourquoi voulons-nous faire une telle hypothèse en premier lieu? Parce qu'il existe un compromis inhérent entre la flexibilité et l'interprétabilité des modèles.
La flexibilité fait référence à la gamme de formes qu'un modèle peut créer pour s'adapter aux nombreuses formes fonctionnelles possibles ƒ. Par conséquent, plus le modèle est flexible, plus il peut être adapté, ce qui augmente la précision des prévisions. Mais un modèle plus flexible est plus complexe et nécessite plus de paramètres pour s'adapter, et les estimations de deviennent souvent trop complexes pour que les associations de tous les prédicteurs individuels et des facteurs pronostiques soient interprétées.
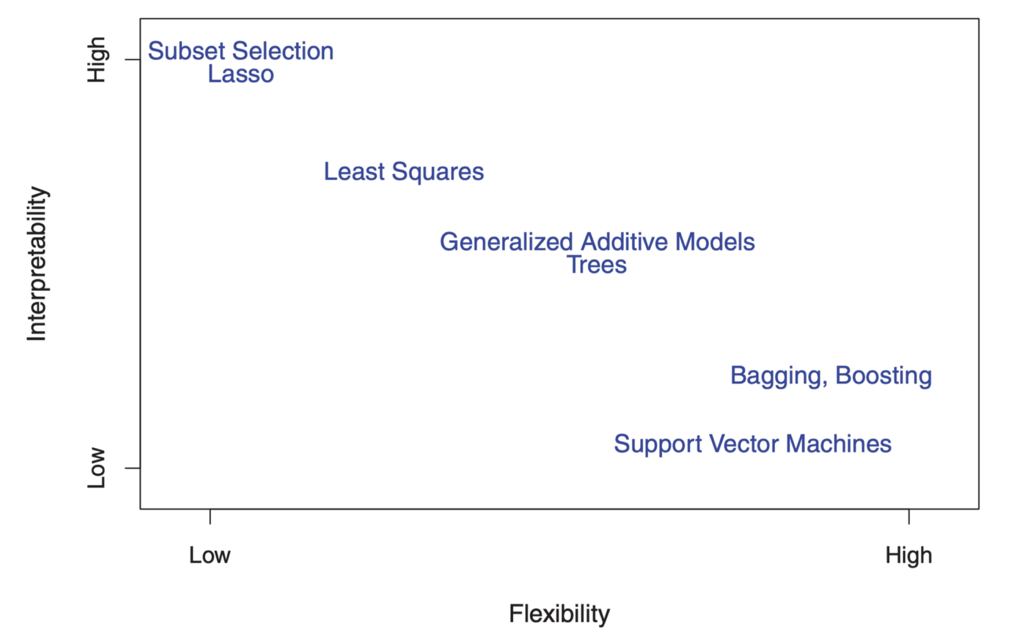
En revanche, les paramètres du modèle linéaire sont relativement simples et interprétables, même s'il n'effectue pas très bien une prévision précise. Voici un excellent diagramme dans ISL qui illustre ce compromis dans divers modèles de formation statistique:
"
"
Comme vous pouvez le voir, les modèles d'apprentissage automatique plus flexibles avec une meilleure précision de prévision, tels que la méthode du vecteur de support et les méthodes d'amélioration, ont en même temps une faible interprétabilité. La modélisation par inférence refuse également la précision des prévisions du modèle interprété, faisant une hypothèse confiante sur la forme fonctionnelle f.
Identification causale et raisonnement contrefactuel
Mais attendez un instant! Même si vous utilisez un modèle bien interprété avec un bon ajustement, vous ne pouvez toujours pas utiliser ces statistiques comme preuve distincte de causalité. C'est à cause du vieux cliché las «la corrélation n'est pas la causalité».
Voici un
bon exemple : supposons que vous ayez des données sur la longueur d'une centaine de mâts, la longueur de leurs ombres et la position du soleil. Vous savez que la longueur de l'ombre est déterminée par la longueur du pôle et la position du soleil, mais même si vous définissez la longueur du pôle comme variable dépendante et la longueur de l'ombre comme variable indépendante, votre modèle s'adaptera toujours à des coefficients statistiquement significatifs et ainsi de suite.
C'est pourquoi les relations causales ne peuvent pas être établies uniquement par des modèles statistiques et nécessitent des connaissances de base - la prétendue causalité devrait être justifiée par une compréhension théorique préliminaire de la relation. Par conséquent, l'analyse des données et la modélisation statistique des relations de cause à effet sont souvent largement basées sur des modèles théoriques.
Et même si vous avez une bonne justification théorique pour dire que X cause Y, l'identification d'un effet causal est encore souvent très difficile. En effet, l'évaluation d'une relation causale implique d'identifier ce qui se passerait dans un monde contre-actif dans lequel X n'a pas eu lieu, ce qui par définition n'est pas observable.
Voici
un autre bon exemple : supposons que vous vouliez déterminer les effets sur la santé de la vitamine C. Avez-vous des données indiquant si quelqu'un prend des vitamines (X = 1 s'il prend; 0 - ne prend pas) et certains résultats binaires pour la santé (Y = 1 s'il est en bonne santé; 0 - pas en bonne santé) qui ressemble à ceci:
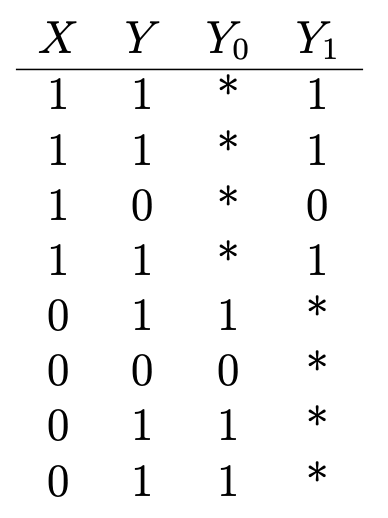
Y₁ est le résultat pour la santé de ceux qui prennent de la vitamine C, et Y₀ est le résultat pour la santé de ceux qui n'en prennent pas. Pour déterminer l'effet de la vitamine C sur la santé, nous évaluons l'effet moyen du traitement:
Mais pour ce faire, il est important de savoir quelles seraient les conséquences sur la santé de ceux qui prennent de la vitamine C s'ils ne prenaient pas de vitamine C, et vice versa (ou E (Y₀ | X = 1) et E (Y₁ | X = 0)), qui sont indiqués par des astérisques dans le tableau et représentent des résultats contrefactuels non observés. L'effet de traitement moyen ne peut pas être évalué séquentiellement sans cette entrée.
Imaginez maintenant que les personnes déjà en bonne santé, en règle générale, essaient de prendre de la vitamine C, mais pas les personnes déjà en mauvaise santé. Dans ce scénario, les évaluations montreraient un fort effet curatif, même si la vitamine C n'affectait pas du tout la santé. Ici, l'état de santé précédent est appelé facteur mixte, qui affecte à la fois l'apport en vitamine C et la santé (X et Y), ce qui conduit à des estimations déformées. Le moyen le plus sûr d'obtenir un score θ cohérent est de randomiser le traitement par l'expérience afin que X ne dépende pas de Y.
Lorsque le traitement est prescrit au hasard, le résultat du groupe ne recevant pas le médicament, en moyenne, devient un indicateur objectif des résultats contrefactuels du groupe recevant le traitement et garantit qu'il n'y a pas de facteur de distorsion. Les tests A / B sont guidés par cette compréhension.
Mais les expériences randomisées ne sont pas toujours possibles (ou éthiques, si nous voulons étudier les effets sur la santé du tabagisme ou de manger trop de biscuits aux pépites de chocolat), et dans ces cas, les effets causaux doivent être estimés à partir d'observations avec un traitement souvent non randomisé.
Il existe de
nombreuses méthodes statistiques qui identifient les effets causaux dans des conditions non expérimentales. Ils le font en construisant des résultats contrefactuels ou en modélisant des prescriptions aléatoires de traitement dans des données d'observation.
Il est facile d'imaginer que les résultats de ces types d'analyses sont souvent peu fiables ou reproductibles. Et encore plus important: ces niveaux d'obstacles méthodologiques ne visent pas à améliorer la précision de la prévision du modèle, mais à présenter des preuves de causalité à travers une combinaison de conclusions logiques et statistiques.
Il est beaucoup plus facile de mesurer le succès d'un pronostic qu'un modèle causal. Bien qu'il existe des indicateurs de performance standard pour les modèles pronostiques, il est beaucoup plus difficile d'évaluer le succès relatif des modèles causaux. Mais s'il est difficile de retracer les causes et les effets, cela ne signifie pas que nous devons arrêter d'essayer.
Le point principal ici est que les modèles pronostiques et causaux servent à des fins complètement différentes et nécessitent des données et des processus de modélisation statistique complètement différents, et souvent nous devons faire les deux.
Un exemple de l'industrie cinématographique illustre: les studios utilisent des modèles de prévision pour prévoir les recettes au box-office, pour prédire les résultats financiers de la distribution de films, pour évaluer les risques financiers et la rentabilité de leur portefeuille de films, etc. Mais les modèles de prévision ne nous rapprocheront pas de la compréhension de la structure et de la dynamique du marché du film et n'aideront pas les décisions d'investissement, car aux premiers stades du processus de production du film (généralement des années avant la date de sortie), lorsque les décisions d'investissement sont prises, la variance des possibles Les résultats sont élevés.
Par conséquent, la précision des modèles de prévision basés sur les données initiales dans les premiers stades est considérablement réduite. Les modèles prédictifs se rapprochent de la date de début de la distribution du film, lorsque la plupart des décisions de production ont déjà été prises et que les prévisions ne sont plus particulièrement réalisables et pertinentes. D'autre part, la modélisation des relations de cause à effet permet aux studios de découvrir comment diverses caractéristiques de production peuvent influencer les revenus potentiels aux premiers stades de la production cinématographique et sont donc cruciales pour informer sur leurs stratégies de production.
Attention accrue aux prédictions: Chomsky avait-il raison?
Il est facile de comprendre pourquoi Chomsky est contrarié: les modèles pronostiques dominent la communauté scientifique et l'industrie.
Une analyse textuelle des prépublications académiques montre que les domaines de recherche quantitative qui connaissent la croissance la plus rapide accordent de plus en plus d'attention aux prévisions. Par exemple, le nombre d'articles dans le domaine de l'intelligence artificielle qui mentionnent la «prédiction» a plus que doublé, tandis que les articles sur les conclusions ont diminué de moitié depuis 2013.
Les programmes de sciences des données ignorent largement les relations de cause à effet. Et la science des données dans les entreprises se concentre principalement sur les modèles prédictifs. Des compétitions de terrain prestigieuses telles que le prix Kaggle et Netflix sont basées sur l'amélioration des indicateurs de performance prédictifs.
D'autre part, il existe encore de nombreux domaines dans lesquels une attention insuffisante est accordée à la prévision empirique, et ils peuvent bénéficier des acquis obtenus dans le domaine de l'apprentissage automatique et de la modélisation prédictive. Mais présenter l'état actuel des choses comme une guerre culturelle entre «l'équipe Chomsky» et «l'équipe Norvig» est inexact: il n'y a pas de raison de ne choisir qu'une seule option, car il existe de nombreuses opportunités d'enrichissement mutuel entre les deux cultures. Beaucoup de travail a été fait pour rendre les modèles d'apprentissage automatique plus compréhensibles. Par exemple,
Susan Ati de Stanford utilise des méthodes d'apprentissage automatique dans une méthodologie de relation causale.
Pour terminer sur une note positive, rappelons les
oeuvres de Jude Pearl . Pearl a dirigé un projet de recherche sur l'intelligence artificielle dans les années 1980, qui a permis aux machines de raisonner de manière probabiliste à l'aide de réseaux bayésiens. Cependant, depuis lors, il est devenu le plus grand critique de la façon dont l'attention de l'intelligence artificielle exclusivement aux associations et corrélations probabilistes est devenue un obstacle aux réalisations.
Partageant l'opinion de Chomsky,
Pearl soutient que toutes les réalisations impressionnantes du deep learning se résument à adapter la courbe aux données. , ( ), 30 . , — « ».
, - , , — , , .
, - , , .
dans l'un de ses articles, il affirme:La plupart des connaissances humaines sont organisées autour de relations causales plutôt que probabilistes, et la grammaire de calcul des probabilités ne suffit pas pour comprendre ces relations ... C'est pour cette raison que je ne me considère qu'à moitié bayésien.
Il semble que la science des données ne gagnera que si nous avons plus de grignotages.