
Les réseaux de neurones en vision par ordinateur se développent activement, de nombreuses tâches sont encore loin d'être résolues. Pour être tendance dans votre domaine, suivez simplement les influenceurs sur Twitter et lisez les articles pertinents sur arXiv.org. Mais nous avons eu l'occasion d'aller à la Conférence internationale sur la vision par ordinateur (ICCV) 2019. Cette année, elle se tient en Corée du Sud. Maintenant, nous voulons partager avec les lecteurs de Habr ce que nous avons vu et appris.
Nous étions nombreux à Yandex: des développeurs de véhicules sans pilote, des chercheurs et des personnes impliquées dans les tâches de CV dans les services sont arrivés. Mais maintenant, nous voulons présenter un point de vue légèrement subjectif de notre équipe - le laboratoire d'intelligence artificielle (Yandex MILAB). D'autres gars ont probablement regardé la conférence sous leur angle.
Que fait le laboratoireNous réalisons des projets expérimentaux liés à la génération d'images et de musique à des fins de divertissement. Nous sommes particulièrement intéressés par les réseaux de neurones qui vous permettent de changer le contenu de l'utilisateur (pour une photo, cette tâche est appelée manipulation d'image).
Un exemple du résultat de notre travail de la conférence YaC 2019.
Il y a beaucoup de conférences scientifiques, mais les meilleures conférences dites A * se démarquent d'elles, où des articles sur les technologies les plus intéressantes et importantes sont généralement publiés. Il n'y a pas de liste exacte des conférences A *, voici un exemple et incomplet: NeurIPS (anciennement NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Les trois derniers se spécialisent dans le sujet du CV.
ICCV en bref: affiches, tutoriels, ateliers, stands
1075 communications ont été acceptées lors de la conférence, les participants étaient 7 500. 103 personnes venaient de Russie, il y avait des articles d'employés de Yandex, Skoltech, Samsung AI Center Moscow et Samara University. Cette année, peu de grands chercheurs ont visité l'ICCV, mais ici, par exemple, Alexey (Alyosha) Efros, qui rassemble toujours beaucoup de monde:

Dans toutes ces conférences, les articles sont présentés sous forme d'affiches (
plus sur le format), et les meilleurs sont également présentés sous forme de courts rapports.
Voici une partie du travail de la Russie Sur les tutoriels, vous pouvez vous immerger dans un domaine, cela ressemble à une conférence dans une université. Il est lu par une seule personne, généralement sans parler d'œuvres spécifiques. Exemple de tutoriel sympa (
Michael Brown, Understanding Color and the In-Camera Image Processing Pipeline for Computer Vision ):

Dans les ateliers, au contraire, ils parlent d'articles. Habituellement, il s'agit de travaux sur un sujet étroit, d'histoires de chefs de laboratoire sur tous les derniers travaux d'étudiants ou d'articles qui n'ont pas été acceptés lors de la conférence principale.
Les entreprises sponsors viennent à l'ICCV avec des stands. Cette année, Google, Facebook, Amazon et de nombreuses autres sociétés internationales sont arrivées, ainsi qu'un grand nombre de startups - coréennes et chinoises. Il y avait surtout de nombreuses startups spécialisées dans le balisage de données. Il y a des représentations sur les stands, vous pouvez prendre des marchandises et poser des questions. Les sociétés de parrainage organisent des fêtes de chasse. Ils réussissent à convaincre les recruteurs que vous êtes intéressé et que vous pouvez potentiellement être interviewé. Si vous avez publié un article (ou, en outre, fait une présentation avec lui), commencé ou terminé votre doctorat - c'est un plus, mais parfois vous pouvez vous mettre d'accord sur un stand, poser des questions intéressantes aux ingénieurs de l'entreprise.
Les tendances
La conférence vous permet de parcourir toute la zone CV. Par le nombre d'affiches d'un sujet particulier, vous pouvez évaluer à quel point le sujet est chaud. Certaines conclusions demandent des mots-clés:

Zero-shot, one-shot, few-shot, auto-supervisé et semi-supervisé: de nouvelles approches pour des problèmes longtemps étudiés
Les gens apprennent à utiliser les données plus efficacement. Par exemple, dans
FUNIT, vous pouvez générer des expressions faciales d'animaux qui n'étaient pas dans le jeu d'entraînement (en appliquant plusieurs images de référence dans l'application). Les idées de Deep Image Prior ont été développées, et maintenant les réseaux
GAN peuvent être formés sur une seule image - nous en parlerons plus tard
dans les faits saillants . Vous pouvez utiliser l'autosurveillance pour la pré-formation (résoudre un problème pour lequel il est possible de synthétiser des données alignées, par exemple, pour prédire l'angle de rotation d'une image) ou pour apprendre en même temps à partir de données marquées et non étiquetées. En ce sens, la couronne de création peut être considérée comme un article
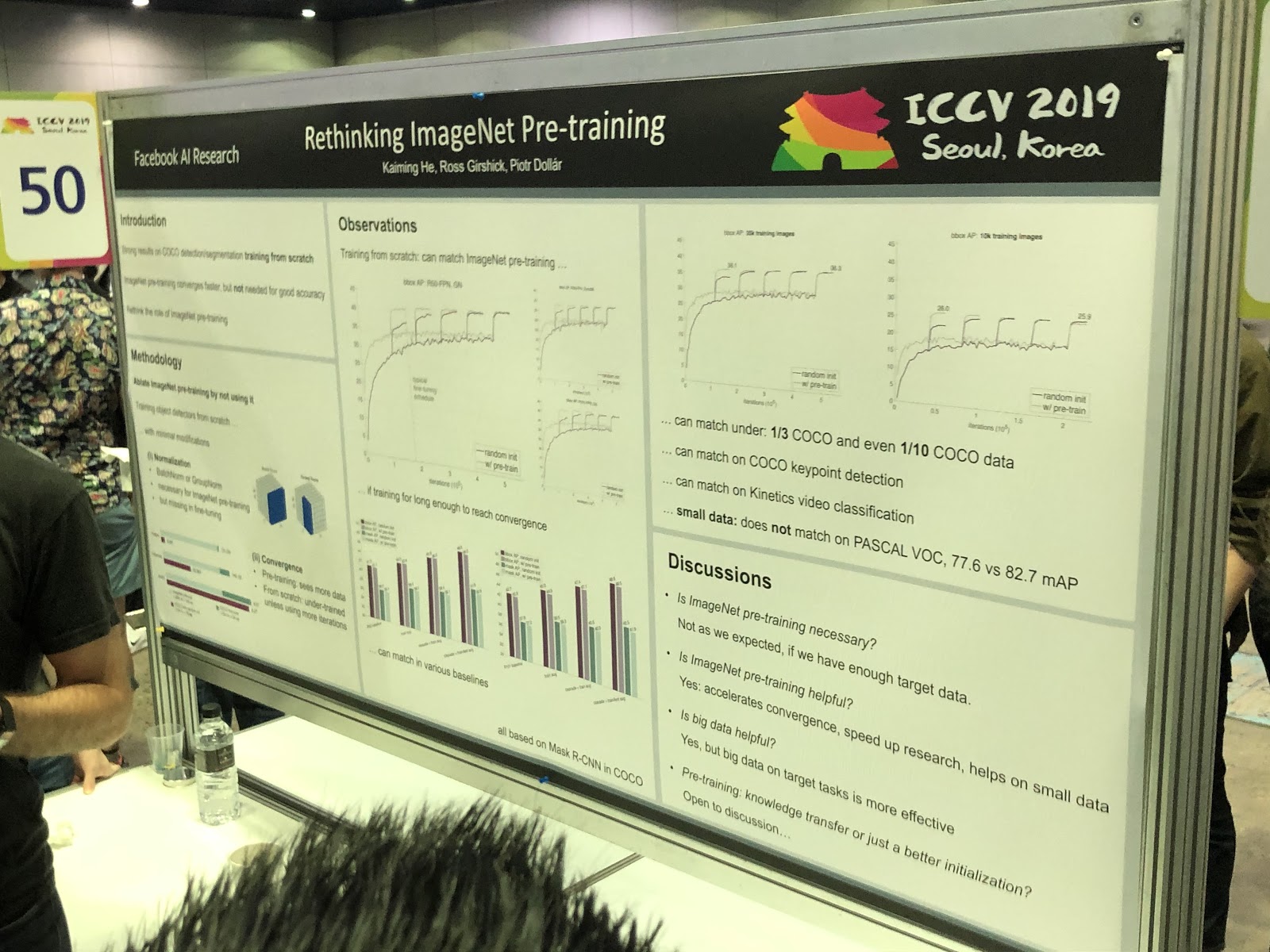
S4L: Apprentissage semi-supervisé auto-supervisé . Mais la pré-formation sur ImageNet
n'aide pas toujours .

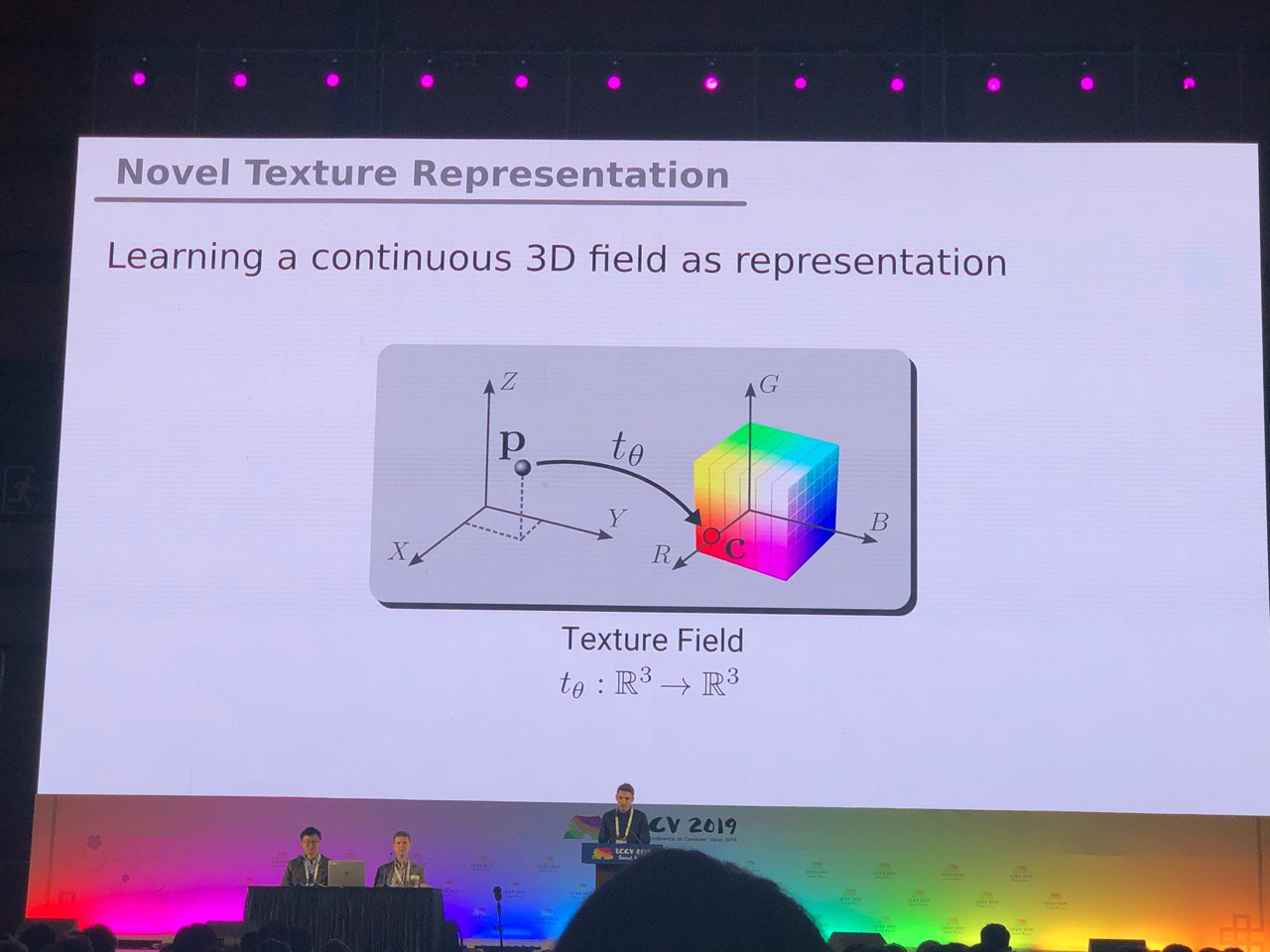
3D et 360 °
Les tâches, principalement résolues pour les photos (segmentation, détection), nécessitent des recherches supplémentaires pour les modèles 3D et les vidéos panoramiques. Nous avons vu de nombreux articles sur la conversion de RVB et
RVB-D en 3D. Certaines tâches, telles que la détermination de la pose d'une personne (estimation de la pose), sont résolues plus naturellement si nous passons à des modèles tridimensionnels. Mais jusqu'à présent, il n'y a pas de consensus sur la façon exacte de représenter les modèles 3D - sous la forme d'une grille, d'un nuage de points, de
voxels ou de
SDF . Voici une autre option:
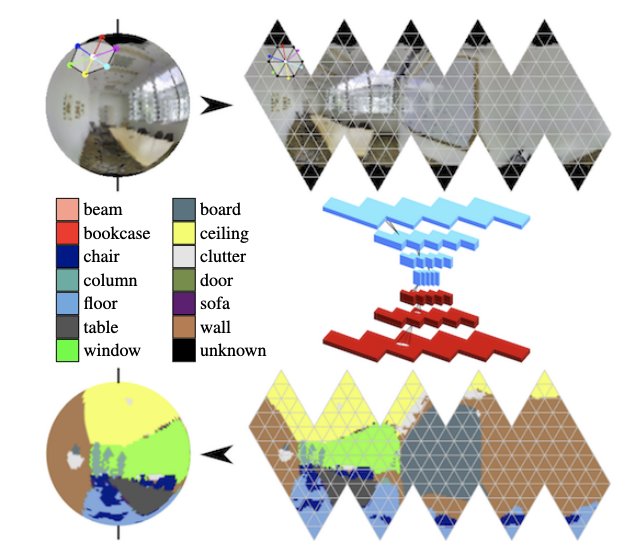
Dans les panoramas, les convolutions sur la sphère se développent activement (voir
Segmentation sémantique orientée sur les sphères d'icosaèdres ) et la recherche d'objets clés dans le cadre.
Définition de la posture et prédiction des mouvements humains
Afin de déterminer la pose en 2D, il y a déjà du succès - maintenant le focus s'est déplacé vers le travail avec plusieurs caméras et en 3D. Par exemple, vous pouvez déterminer le squelette à travers le mur, en suivant les modifications du signal Wi-Fi lors de son passage dans le corps humain.
Beaucoup de travail a été fait dans le domaine de la détection manuelle des points clés. De nouveaux ensembles de données sont apparus, y compris ceux basés sur la vidéo avec des dialogues de deux personnes - vous pouvez désormais prédire les gestes des mains par audio ou texte d'une conversation! Les mêmes progrès ont été réalisés dans les tâches d'évaluation du regard.

Vous pouvez également mettre en évidence un large éventail d'œuvres liées à la prédiction du mouvement humain (par exemple, la prévision du mouvement humain
via la peinture spatio-temporelle ou
la prévision structurée aide à la modélisation 3D du mouvement humain ). La tâche est importante et, basée sur des conversations avec les auteurs, elle est le plus souvent utilisée pour analyser le comportement des piétons en conduite autonome.
Manipulation de personnes dans des photos et des vidéos, cabines d'essayage virtuelles
La tendance principale est de changer les images faciales en termes de paramètres interprétés. Idées:
deepfake sur une image, changement d'expression par rendu de visage (
PuppetGAN ), changement anticipé des paramètres (par exemple,
âge ). Les transferts de style sont passés du titre du sujet à l'application du travail. Autre histoire - les cabines d'essayage virtuelles, elles fonctionnent presque toujours mal,
voici un exemple de démo.


Génération d'esquisse / graphique
Le développement de l'idée «Laissons la grille générer quelque chose en fonction de l'expérience précédente» est devenu différent: «Montrons à la grille quelle option nous intéresse».
SC-FEGAN vous permet de faire de la peinture guidée: l'utilisateur peut dessiner une partie du visage dans la zone effacée de l'image et obtenir l'image restaurée en fonction du rendu.

Dans l'un des 25 articles Adobe pour ICCV, deux GAN sont combinés: l'un dessine une esquisse pour l'utilisateur, l'autre génère une image photo-réaliste à partir de l'esquisse (
page du projet ).

Plus tôt dans la génération d'images, les graphiques n'étaient pas nécessaires, mais maintenant ils sont devenus un conteneur de connaissances sur la scène. Le prix ICCV Best Paper Honorable Mentions a également été décerné à l'article
Spécification des attributs et des relations des objets dans la génération de scènes interactives . En général, vous pouvez les utiliser de différentes manières: générer des graphiques à partir d'images ou des images et des textes à partir de graphiques.
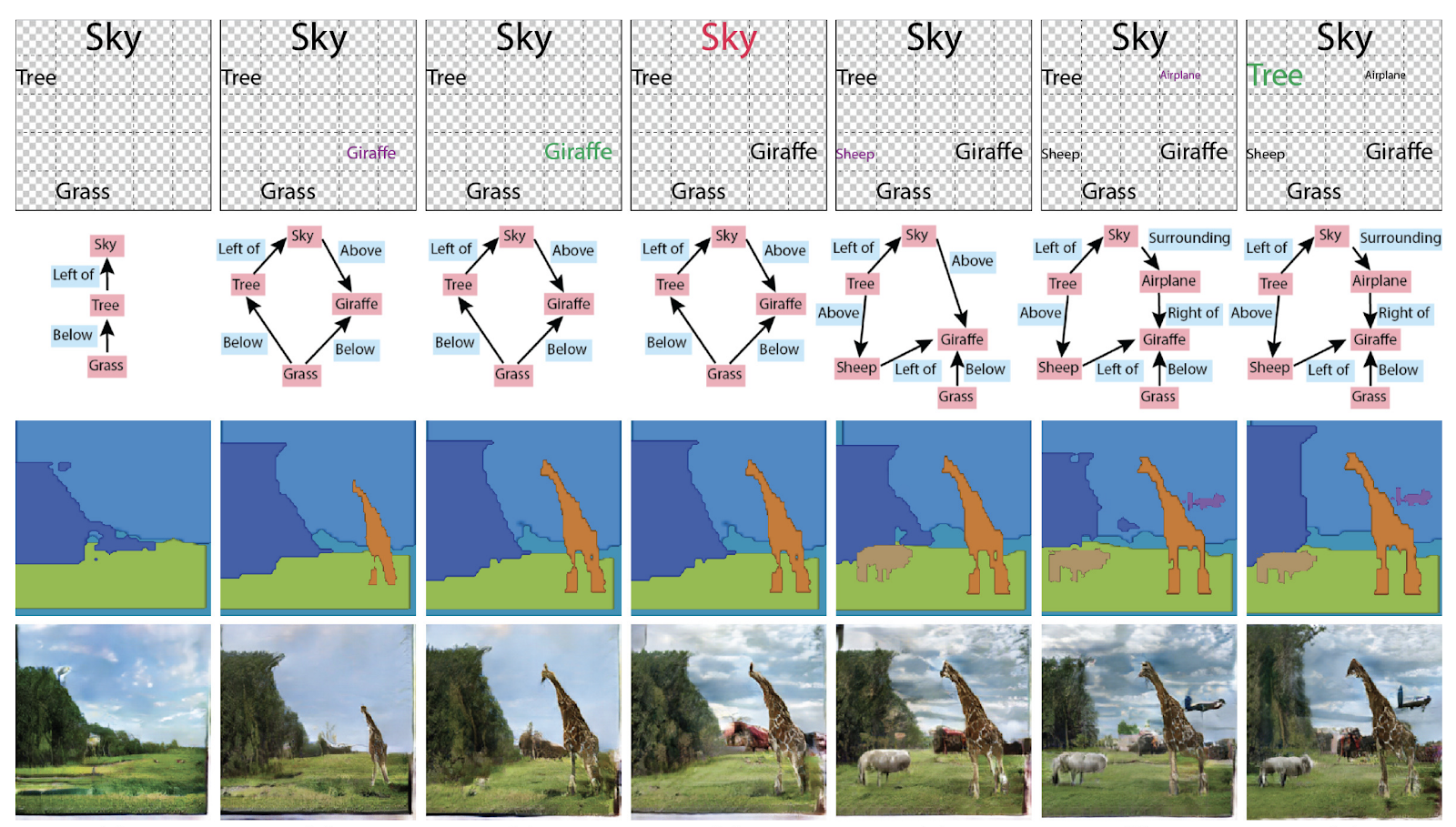
Ré-identification des personnes et des machines, en comptant le nombre de foules (!)
De nombreux articles sont consacrés au suivi des personnes et à la
réidentification des personnes et des machines. Mais ce qui nous a surpris, c'est un tas d'articles sur le comptage des gens dans une foule, et tous en provenance de Chine.
Mais Facebook, au contraire, anonymise la photo. De plus, il le fait de manière intéressante: il apprend au réseau neuronal à générer un visage sans détails uniques - similaire, mais pas tellement qu'il est correctement détecté par les systèmes de reconnaissance faciale.

Protection contre les attaques adverses
Avec le développement d'applications de vision par ordinateur dans le monde réel (dans les véhicules sans pilote, en reconnaissance faciale), la question de la fiabilité de tels systèmes se pose plus souvent. Pour utiliser pleinement le CV, vous devez vous assurer que le système résiste aux attaques contradictoires - il n'y avait donc pas moins d'articles sur la protection contre eux que sur les attaques elles-mêmes. Beaucoup de travail consistait à expliquer les prévisions du réseau (carte de saillance) et à mesurer la confiance dans le résultat.
Tâches combinées
Dans la plupart des tâches avec un seul objectif, les possibilités d'améliorer la qualité sont presque épuisées; l'un des nouveaux domaines de la croissance de la qualité consiste à enseigner aux réseaux de neurones à résoudre plusieurs problèmes similaires en même temps. Exemples:
- prédiction d'actions + prédiction de flux optique,
- présentation vidéo + représentation linguistique (
VideoBERT ),
-
super-résolution + HDR .
Et il y avait des articles sur la segmentation, la détermination de la posture et la réidentification des animaux!

Faits saillants
Presque tous les articles étaient connus à l'avance, le texte était disponible sur arXiv.org. Par conséquent, la présentation d'œuvres telles que Everybody Dance Now, FUNIT, Image2StyleGAN semble plutôt étrange - ce sont des œuvres très utiles, mais pas nouvelles du tout. Il semble que le processus classique de publication scientifique échoue ici - la science se développe trop rapidement.
Il est très difficile de déterminer les meilleures œuvres - il y en a beaucoup, les sujets sont différents. Plusieurs articles ont reçu des
prix et des références .
Nous voulons mettre en évidence des travaux intéressants en termes de manipulation d'images, car c'est notre sujet. Ils se sont avérés assez frais et intéressants pour nous (nous ne prétendons pas être objectifs).
SinGAN (prix du meilleur article) et InGAN
SinGAN:
page du projet ,
arXiv ,
code .
INGAN:
page du projet ,
arXiv ,
code .
Le développement de l'idée de Deep Image Prior par Dmitry Ulyanov, Andrea Vedaldi et Victor Lempitsky. Au lieu de former le GAN sur un ensemble de données, les réseaux apprennent à partir de fragments de la même image afin de se souvenir des statistiques qu'il contient. Le réseau formé vous permet d'éditer et d'animer des photos (SinGAN) ou de générer de nouvelles images de toute taille à partir des textures de l'image d'origine, tout en conservant la structure locale (InGAN).
SinGAN:

INGAN:

Voir ce qu'un GAN ne peut pas générer
Page du projet .
Les réseaux de neurones générateurs d'images reçoivent souvent un vecteur de bruit aléatoire en entrée. Dans un réseau formé, de nombreux vecteurs d'entrée forment un espace, de petits mouvements le long desquels entraînent de petits changements dans l'image. Grâce à l'optimisation, vous pouvez résoudre le problème inverse: trouver un vecteur d'entrée approprié pour une image du monde réel. L'auteur montre qu'il n'est presque jamais possible de trouver une image complètement correspondante dans un réseau neuronal presque jamais. Certains objets de l'image ne sont pas générés (apparemment, en raison de la grande variabilité de ces objets).
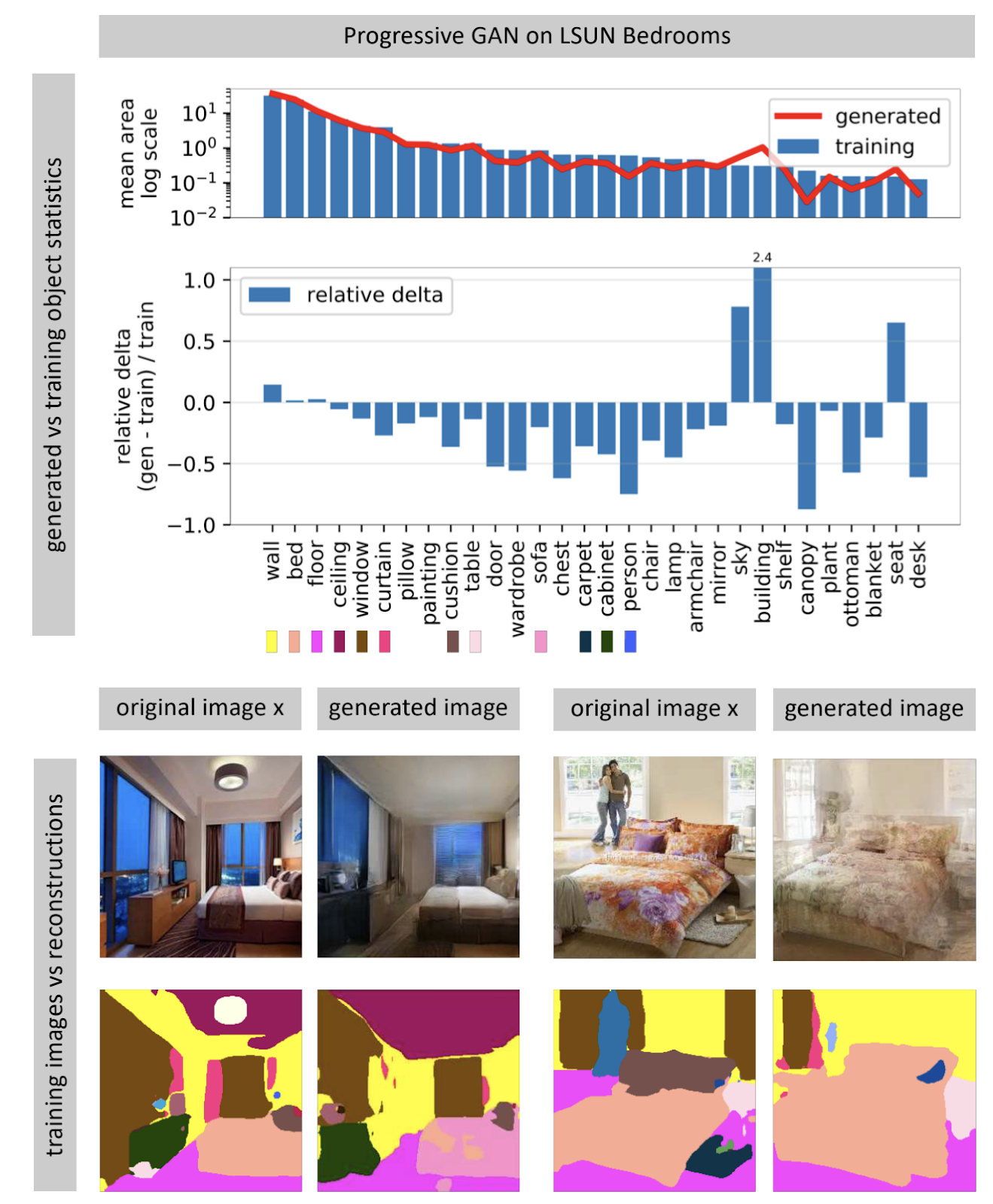
L'auteur émet l'hypothèse que le GAN ne couvre pas tout l'espace des images, mais seulement certains sous-ensembles bourrés de trous, comme du fromage. Lorsque nous essayons d'y trouver des photos du monde réel, nous échouerons toujours, car le GAN ne génère toujours pas de vraies photos. Vous pouvez surmonter les différences entre les images réelles et générées uniquement en modifiant le poids du réseau, c'est-à-dire en le recyclant pour une photo spécifique.

Lorsque le réseau est recyclé pour une photo spécifique, vous pouvez essayer d'effectuer diverses manipulations avec cette image. Dans l'exemple ci-dessous, une fenêtre a été ajoutée à la photo et le réseau a en outre généré des réflexions sur l'ensemble de cuisine. Cela signifie que le réseau après le recyclage pour la photographie n'a pas perdu la possibilité de voir la connexion entre les objets de la scène.

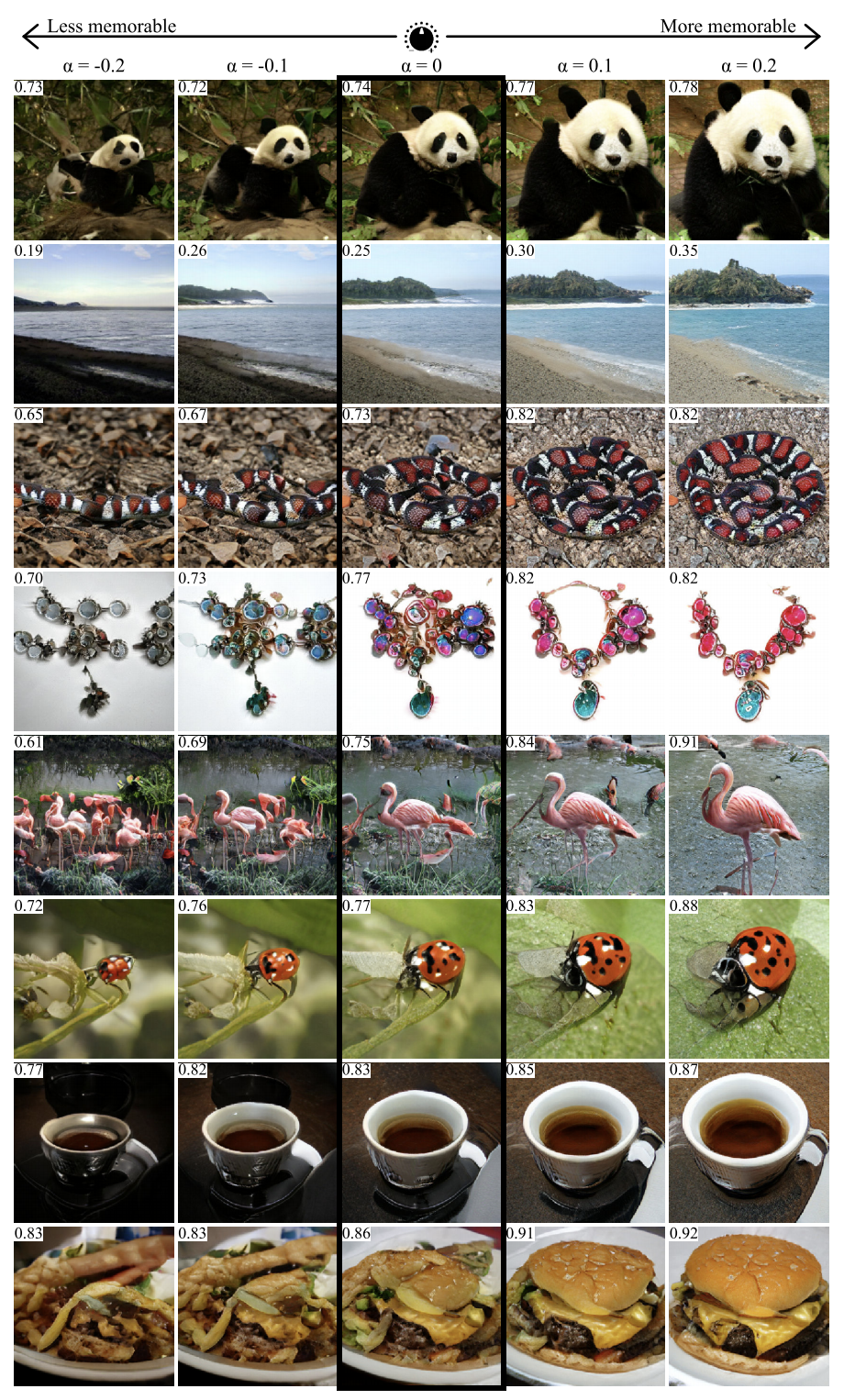
GANalyze: vers des définitions visuelles des propriétés des images cognitives
Page de projet ,
arXiv .
En utilisant l'approche de ce travail, vous pouvez visualiser et analyser ce que le réseau neuronal a appris. Les auteurs proposent de former le GAN à la création d'images pour lesquelles le réseau générera des prédictions données. Plusieurs réseaux ont été utilisés comme exemples dans l'article, y compris MemNet, qui prédit la mémorisation des photos. Il s'est avéré que pour une meilleure mémorisation, l'objet sur la photo devrait:
- être plus proche du centre
- avoir une forme ronde ou carrée et une structure simple,
- être sur un fond uniforme,
- contenir des yeux expressifs (au moins pour les photos de chiens),
- être plus lumineux, plus riche, dans certains cas - plus rouge.
Liquid Warping GAN: Un cadre unifié pour l'imitation du mouvement humain, le transfert d'apparence et la synthèse de vues innovantes
Page du projet ,
arXiv ,
code .
Pipeline pour générer des photos de personnes à partir d'une seule photo. Les auteurs montrent des exemples réussis de transfert du mouvement d'une personne à une autre, de transfert de vêtements entre les personnes et de génération de nouvelles perspectives d'une personne - le tout à partir d'une seule photographie. Contrairement aux travaux précédents, ici, pour créer des conditions, ce ne sont pas des points clés en 2D (pose) qui sont utilisés, mais un maillage 3D du corps (pose + forme). Les auteurs ont également compris comment transférer des informations de l'image d'origine vers l'image générée (Liquid Warping Block). Les résultats semblent corrects, mais la résolution de l'image résultante n'est que de 256x256. À titre de comparaison, vid2vid, qui est apparu il y a un an, est capable de générer à une résolution de 2048x1024, mais il nécessite jusqu'à 10 minutes de tournage vidéo comme un ensemble de données.

FSGAN: Sujet Agnostic Face Swapping and Recenactment
Page de projet ,
arXiv .
Au premier abord il ne semble rien d'inhabituel: du deepfake de qualité plus ou moins normale. Mais la principale réalisation de l'œuvre est la substitution de visages sur une seule image. Contrairement aux travaux antérieurs, une formation était requise sur une variété de photographies d'une personne en particulier. Le pipeline s'est avéré lourd (reconstitution et segmentation, interpolation de vue, peinture, mélange) et avec beaucoup de hacks techniques, mais le résultat en vaut la peine.

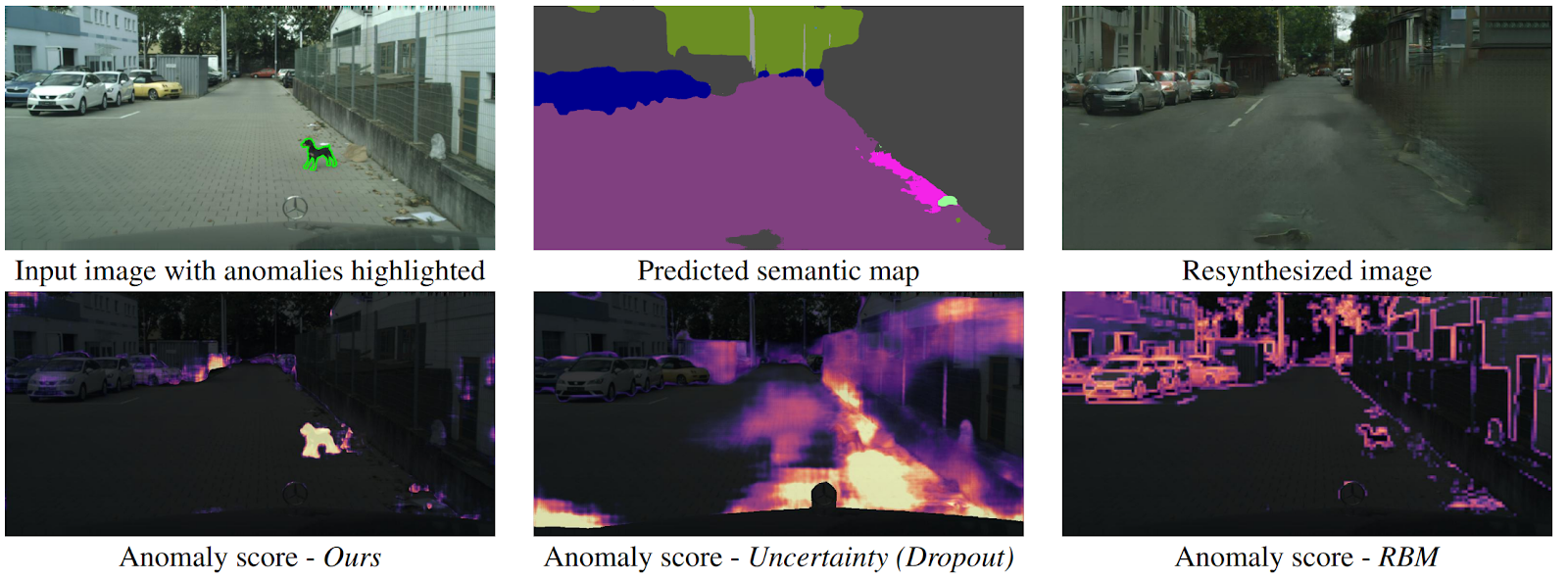
Détecter l'inattendu via la resynthèse d'images
arXiv .
Comment un drone peut-il comprendre qu'un objet est soudainement apparu devant lui et ne tombe dans aucune classe de segmentation sémantique? Il existe plusieurs méthodes, mais les auteurs proposent un nouvel algorithme intuitif qui fonctionne mieux que ses prédécesseurs. La segmentation sémantique est prédite à partir de l'image d'entrée de la route. Il est introduit dans le GAN (pix2pixHD), qui essaie de restaurer l'image d'origine uniquement à partir de la carte sémantique. Les anomalies qui ne tombent dans aucun des segments différeront considérablement dans la source et l'image générée. Ensuite, trois images (initiale, segmentation et reconstruite) sont soumises à un autre réseau, qui prédit des anomalies. L'ensemble de données pour cela a été généré à partir de l'ensemble de données bien connu Cityscapes, changeant accidentellement des classes sur la segmentation sémantique. Fait intéressant, dans ce cadre, un chien debout au milieu de la route, mais correctement segmenté (ce qui signifie qu'il y a une classe pour lui), n'est pas une anomalie, car le système a pu le reconnaître.
Conclusion
Avant la conférence, il est important de savoir quels sont vos intérêts scientifiques, quels sont les discours que j'aimerais aborder, avec qui parler. Ensuite, tout sera beaucoup plus productif.
ICCV est principalement un réseau. Vous comprenez qu'il y a des institutions et des scientifiques de haut niveau, vous commencez à comprendre cela, à connaître des gens. Et vous pouvez lire des articles sur arXiv - et en passant, c'est très cool que vous ne puissiez aller nulle part pour des connaissances.
De plus, lors de la conférence, vous pouvez plonger profondément dans des sujets qui ne sont pas proches de vous, voir les tendances. Eh bien, écrivez une liste d'articles à lire. Si vous êtes étudiant, c'est l'occasion pour vous de vous familiariser avec un scientifique potentiel, si vous êtes de l'industrie, puis avec un nouvel employeur, et si l'entreprise, alors montrez-vous.
Abonnez-vous à
@loss_function_porn ! C'est un projet personnel: nous sommes avec
karfly . Tout le travail que nous avons aimé pendant la conférence, nous avons posté ici:
@loss_function_live .