
Dans un
article précédent, nous avons examiné le clustering RabbitMQ pour la tolérance aux pannes et la haute disponibilité. Maintenant, approfondissons Apache Kafka.
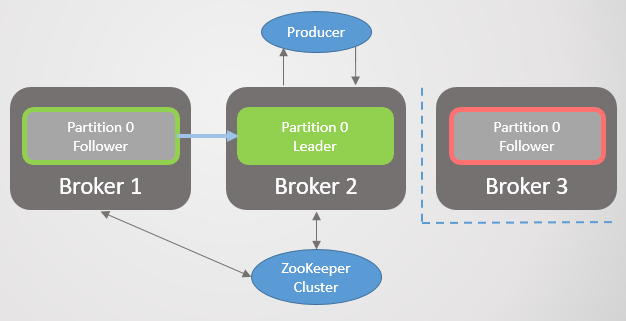
Ici, l'unité de réplication est une partition. Chaque sujet comporte une ou plusieurs sections. Chaque section a un leader avec ou sans abonnés. Lors de la création d'un sujet, le nombre de partitions et le taux de réplication sont indiqués. La valeur habituelle est 3, ce qui signifie trois remarques: un leader et deux suiveurs.
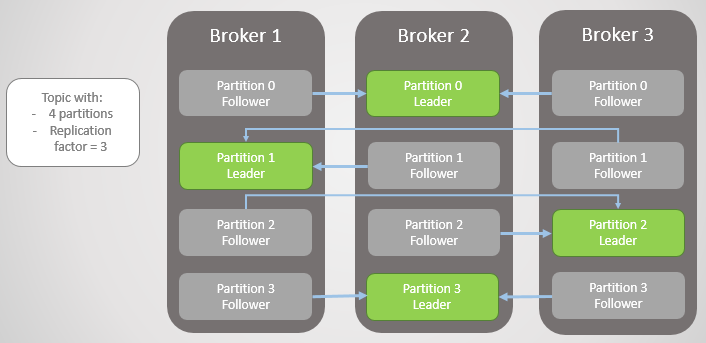 Fig. 1. Quatre sections sont réparties entre trois courtiers
Fig. 1. Quatre sections sont réparties entre trois courtiersToutes les demandes de lecture et d'écriture sont transmises au responsable. Les suiveurs envoient périodiquement des demandes au leader pour recevoir les derniers messages. Les consommateurs ne se tournent jamais vers les followers, ces derniers n'existent que pour la redondance et la tolérance aux pannes.

Échec de la section
Lorsqu'un courtier tombe, les dirigeants de plusieurs sections échouent souvent. Dans chacun d'eux, le suiveur d'un autre nœud devient le leader. En fait, ce n'est pas toujours le cas, car le facteur de synchronisation affecte également: s'il y a des suiveurs synchronisés, et sinon, la transition vers une réplique non synchronisée est-elle autorisée. Mais pour l'instant, ne compliquons pas les choses.
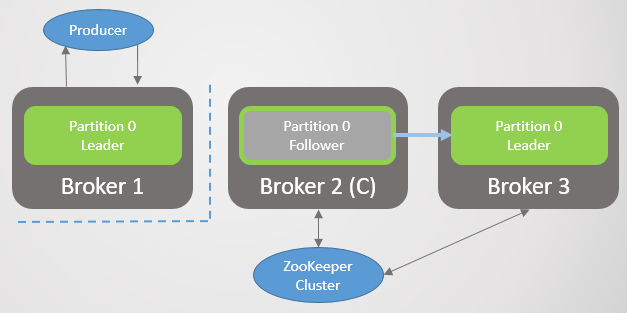
Le courtier 3 quitte le réseau - et pour la section 2, un nouveau leader sur le courtier 2 est élu.
 Fig. 2. Le courtier 3 décède et son disciple du courtier 2 est élu nouveau chef de la section 2
Fig. 2. Le courtier 3 décède et son disciple du courtier 2 est élu nouveau chef de la section 2Ensuite, le courtier 1 quitte et la section 1 perd également son chef, dont le rôle revient au courtier 2.
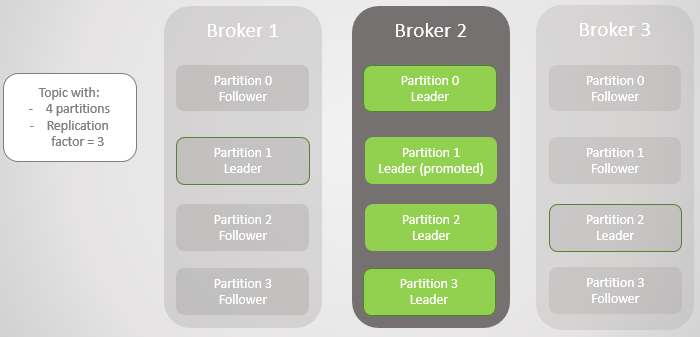 Fig. 3. Il ne reste qu'un courtier. Tous les dirigeants sont sur le même courtier à redondance zéro.
Fig. 3. Il ne reste qu'un courtier. Tous les dirigeants sont sur le même courtier à redondance zéro.Lorsque le courtier 1 revient sur le réseau, il ajoute quatre abonnés, fournissant une certaine redondance à chaque section. Mais tous les leaders sont restés sur le broker 2.
 Fig. 4. Les dirigeants restent sur le courtier 2
Fig. 4. Les dirigeants restent sur le courtier 2Lorsque le courtier 3 monte, nous revenons à trois répliques par section. Mais tous les leaders sont toujours sur le broker 2.
 Fig. 5. Placement déséquilibré des dirigeants après la restauration des courtiers 1 et 3
Fig. 5. Placement déséquilibré des dirigeants après la restauration des courtiers 1 et 3Kafka a un outil pour mieux rééquilibrer les dirigeants que RabbitMQ. Là, vous avez dû utiliser un plug-in ou un script tiers qui a modifié les politiques de migration du nœud principal en réduisant la redondance lors de la migration. De plus, pour les grandes files d'attente, il fallait supporter l'inaccessibilité lors de la synchronisation.
Kafka a un concept de «repères préférés» pour le rôle de leadership. Lorsque les sections de sujet sont créées, Kafka essaie de répartir uniformément les leaders sur les nœuds et marque ces premiers leaders comme préférés. Au fil du temps, en raison des redémarrages du serveur, des échecs et des échecs de connectivité, les leaders peuvent se retrouver sur d'autres nœuds, comme dans le cas extrême décrit ci-dessus.
Pour résoudre ce problème, Kafka propose deux options:
- L'option auto.leader.rebalance.enable = true permet au nœud du contrôleur de réaffecter automatiquement les leaders aux répliques préférées et de restaurer ainsi une distribution uniforme.
- Un administrateur peut exécuter le script kafka-preferred-replica-election.sh pour réaffecter manuellement.
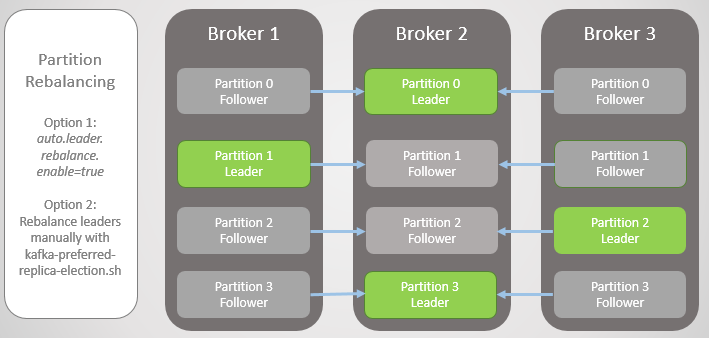 Fig. 6. Répliques après rééquilibrage
Fig. 6. Répliques après rééquilibrageC'était une version simplifiée de l'échec, mais la réalité est plus complexe, bien qu'il n'y ait rien de trop compliqué ici. Tout se résume à des répliques synchronisées (répliques In-Sync, ISR).
Répliques synchronisées (ISR)
ISR est un ensemble de répliques d'une partition qui est considérée comme «synchronisée» (en synchronisation). Il y a un leader, mais il peut ne pas y avoir de followers. Un suiveur est considéré comme synchronisé s'il a fait des copies exactes de tous les messages de leader avant l'expiration de l'intervalle
replica.lag.time.max.ms .
Le suiveur est supprimé de l'ensemble ISR s'il:
- n'a pas fait de demande d'échantillonnage pour l'intervalle replica.lag.time.max.ms (considéré comme mort)
- n'a pas eu le temps de mettre à jour pour l'intervalle replica.lag.time.max.ms (considéré comme lent)
Les suiveurs font des demandes de récupération dans l'intervalle
replica.fetch.wait.max.ms , qui par défaut est de 500 ms.
Pour expliquer clairement l'objectif de l'ISR, vous devez consulter les confirmations du producteur (producteur) et certains scénarios de défaillance. Les producteurs peuvent choisir quand un courtier envoie une confirmation:
- acks = 0, la confirmation n'est pas envoyée
- acks = 1, la confirmation est envoyée après que le leader a écrit un message dans son journal local
- acks = all, une confirmation est envoyée après que toutes les répliques du ISR ont écrit un message dans les journaux locaux
Dans la terminologie de Kafka, si l'ISR a enregistré le message, il est «engagé». Acks = all est l'option la plus sûre, mais aussi un délai supplémentaire. Examinons deux exemples d'échec et comment les différentes options «acks» interagissent avec le concept ISR.
Acks = 1 et ISR
Dans cet exemple, nous verrons que si le leader n'attend pas que chaque message de tous les abonnés soit enregistré, alors si le leader échoue, les données peuvent être perdues. Aller à un abonné non synchronisé peut être activé ou désactivé en définissant
unclean.leader.election.enable .
Dans cet exemple, le fabricant est défini sur acks = 1. La section est répartie entre les trois courtiers. Broker 3 est derrière, il s'est synchronisé avec le leader il y a huit secondes et est maintenant derrière par 7456 messages. Le courtier 1 n'a qu'une seconde de retard. Notre producteur envoie un message et reçoit rapidement un accusé de réception, sans frais généraux pour les adeptes lents ou morts auxquels le leader ne s'attend pas.
 Fig. 7. ISR avec trois répliques
Fig. 7. ISR avec trois répliquesLe courtier 2 échoue et le fabricant reçoit une erreur de connexion. Après la transition du leadership vers le courtier 1, nous perdons 123 messages. Le suiveur du courtier 1 faisait partie de l'ISR, mais ne s'est pas complètement synchronisé avec le leader lors de sa chute.
 Fig. 8. En cas d'échec, les messages sont perdus
Fig. 8. En cas d'échec, les messages sont perdusDans la configuration
bootstrap.servers , le fabricant répertorie plusieurs courtiers, et il peut demander à un autre courtier qui est devenu le nouveau leader de la section. Il établit ensuite une connexion avec le courtier 1 et continue d'envoyer des messages.
 Fig. 9. L'envoi de messages reprend après une courte pause
Fig. 9. L'envoi de messages reprend après une courte pauseLe courtier 3 traîne encore plus loin. Il effectue des requêtes de récupération, mais ne peut pas se synchroniser. Cela peut être dû à une connexion réseau lente entre les courtiers, un problème de stockage, etc. Il est supprimé de l'ISR. Désormais, l'ISR se compose d'une seule réplique - le leader! Le fabricant continue d'envoyer des messages et de recevoir une confirmation.
 Fig. 10. Le suiveur du courtier 3 est supprimé de l'ISR
Fig. 10. Le suiveur du courtier 3 est supprimé de l'ISRLe courtier 1 tombe et le rôle du leader revient au courtier 3 avec la perte de 15286 messages! Le fabricant reçoit un message d'erreur de connexion. Aller au leader en dehors de l'ISR n'était possible qu'en raison du paramètre
unclean.leader.election.enable = true . S'il est défini sur
false , la transition ne se serait pas produite et toutes les demandes de lecture et d'écriture seraient rejetées. Dans ce cas, nous attendons le retour du courtier 1 avec ses données intactes dans la réplique, qui reprendra la tête.
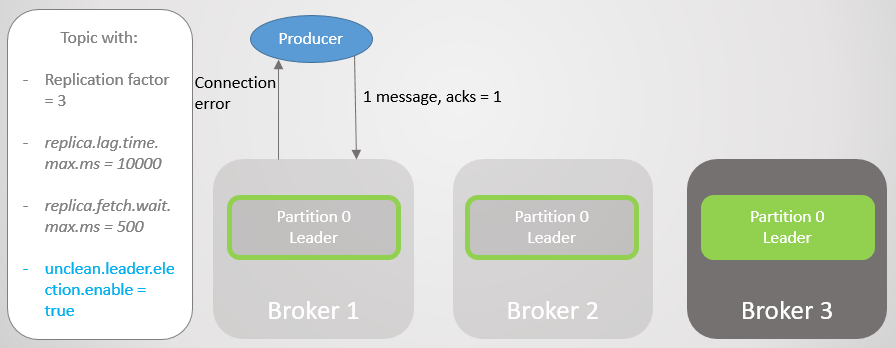 Fig. 11. Le courtier 1 tombe. En cas d'échec, un grand nombre de messages sont perdus
Fig. 11. Le courtier 1 tombe. En cas d'échec, un grand nombre de messages sont perdusLe constructeur établit une connexion avec le dernier courtier et constate qu'il est désormais le leader de la section. Il commence à envoyer des messages au courtier 3.
 Fig. 12. Après une courte pause, les messages sont à nouveau envoyés à la section 0
Fig. 12. Après une courte pause, les messages sont à nouveau envoyés à la section 0Nous avons vu qu'en plus de brèves interruptions pour établir de nouvelles connexions et rechercher un nouveau leader, le fabricant envoyait constamment des messages. Cette configuration assure l'accessibilité grâce à la cohérence (sécurité des données). Kafka a perdu des milliers de messages, mais a continué d'accepter de nouvelles entrées.
Acks = all et ISR
Répétons à nouveau ce scénario, mais avec
acks = all . Retarder le courtier 3 en moyenne quatre secondes. Le fabricant envoie un message avec
acks = all et ne reçoit plus de réponse rapide. Le leader attend que tous les messages de l'ISR stockent le message.
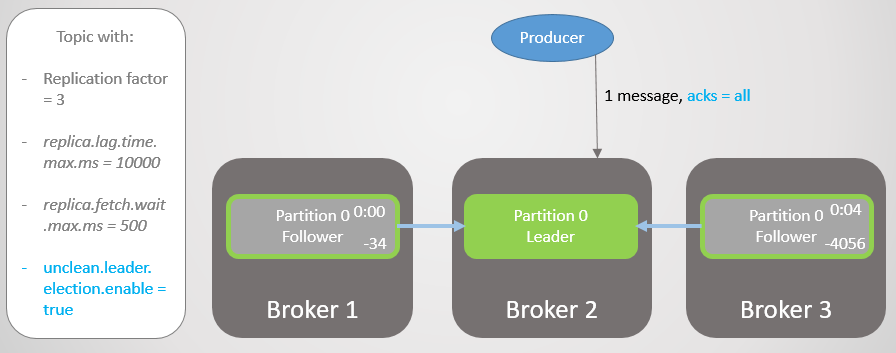 Fig. 13. ISR avec trois répliques. L'un est lent, entraînant un retard d'enregistrement
Fig. 13. ISR avec trois répliques. L'un est lent, entraînant un retard d'enregistrementAprès quatre secondes de délai supplémentaire, le courtier 2 envoie un accusé de réception. Toutes les répliques sont désormais entièrement mises à jour.
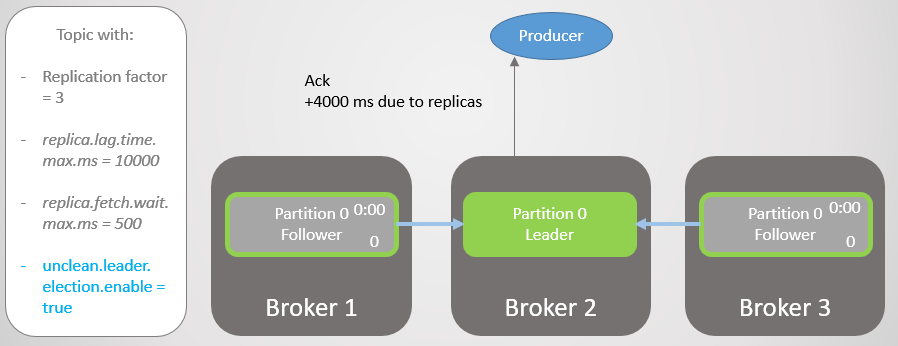 Fig. 14. Toutes les répliques enregistrent les messages et un accusé de réception est envoyé
Fig. 14. Toutes les répliques enregistrent les messages et un accusé de réception est envoyéLe courtier 3 est maintenant encore plus en retard et est en cours de retrait de l'ISR. Le délai est considérablement réduit car il n'y a plus de répliques lentes dans l'ISR. Le courtier 2 n'attend plus que le courtier 1 et il a un décalage moyen de 500 ms.
 Fig. 15. La réplique sur le courtier 3 est supprimée de l'ISR
Fig. 15. La réplique sur le courtier 3 est supprimée de l'ISREnsuite, le courtier 2 tombe et le leadership passe au courtier 1 sans perdre de messages.
 Fig. 16. Le courtier 2 tombe
Fig. 16. Le courtier 2 tombeLe constructeur trouve un nouveau leader et commence à lui envoyer des messages. Le délai est toujours réduit, car maintenant l'ISR se compose d'une seule réplique! Par conséquent, l'option
acks = all n'ajoute pas de redondance.
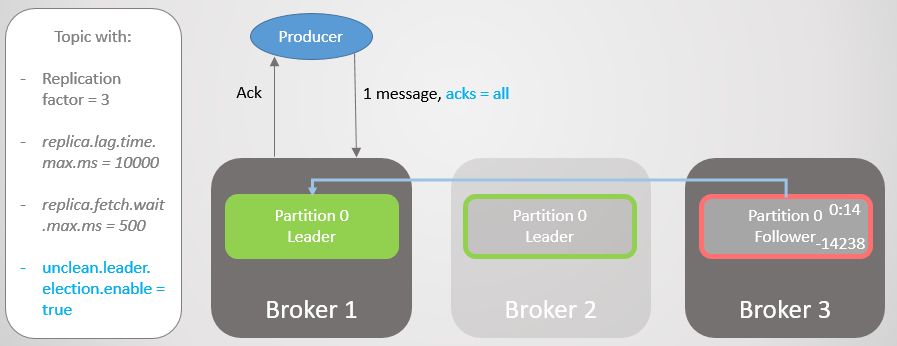 Fig. 17. La réplique sur le courtier 1 prend les devants sans perdre les messages
Fig. 17. La réplique sur le courtier 1 prend les devants sans perdre les messagesEnsuite, le courtier 1 tombe et le leadership passe au courtier 3 avec la perte de 14 238 messages!
 Fig. 18. Le courtier 1 meurt et la transition du leadership avec une configuration impure entraîne une perte de données importante
Fig. 18. Le courtier 1 meurt et la transition du leadership avec une configuration impure entraîne une perte de données importanteNous n'avons pas pu définir l'option
unclean.leader.election.enable sur
true . Par défaut, c'est
faux . La définition de
acks = all avec
unclean.leader.election.enable = true offre une accessibilité avec une sécurité supplémentaire des données. Mais, comme vous pouvez le voir, nous pouvons encore perdre des messages.
Mais que faire si nous voulons augmenter la sécurité des données? Vous pouvez définir
unclean.leader.election.enable = false , mais cela ne nous protège pas nécessairement contre la perte de données. Si le chef est tombé fort et a pris les données avec lui, les messages sont toujours perdus, et l'accessibilité est perdue jusqu'à ce que l'administrateur récupère la situation.
Il vaut mieux garantir la redondance de tous les messages, et sinon refuser d'enregistrer. Ensuite, du moins du point de vue du courtier, la perte de données n'est possible qu'avec deux ou plusieurs défaillances simultanées.
Acks = all, min.insync.replicas et ISR
Avec la
configuration de rubrique
min.insync.replicas, nous
augmentons la sécurité des données. Reprenons la dernière partie du dernier scénario, mais cette fois avec
min.insync.replicas = 2 .
Ainsi, le courtier 2 a une réplique leader et le suiveur du courtier 3 est supprimé de l'ISR.
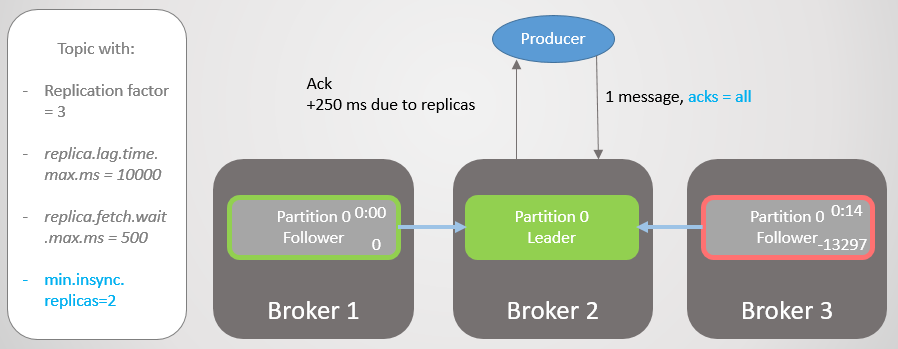 Fig. 19. ISR de deux répliques
Fig. 19. ISR de deux répliquesLe courtier 2 tombe et le leadership passe au courtier 1 sans perdre de messages. Mais maintenant ISR se compose d'une seule réplique. Cela ne correspond pas au nombre minimum pour recevoir des enregistrements, et par conséquent le courtier répond à la tentative d'enregistrement avec l'erreur
NotEnoughReplicas .
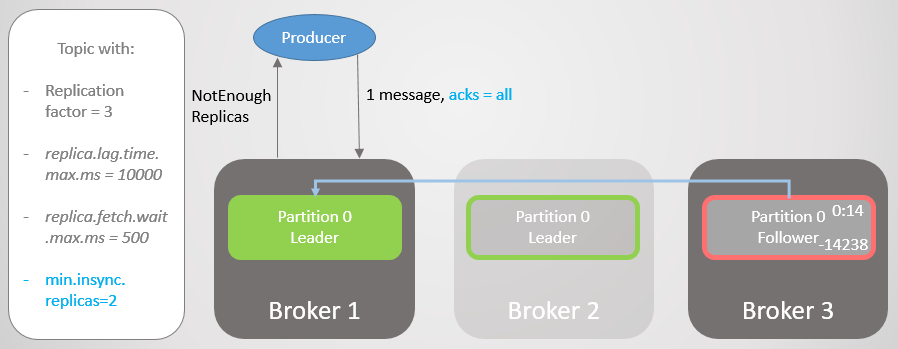 Fig. 20. Le nombre d'ISR est inférieur de un à celui spécifié dans min.insync.replicas
Fig. 20. Le nombre d'ISR est inférieur de un à celui spécifié dans min.insync.replicasCette configuration sacrifie la disponibilité pour la cohérence. Avant de confirmer un message, nous garantissons qu'il est enregistré sur au moins deux répliques. Cela donne au fabricant beaucoup plus de confiance. Ici, la perte de message n'est possible que si deux répliques échouent simultanément dans un court intervalle, jusqu'à ce que le message soit répliqué sur un suiveur supplémentaire, ce qui est peu probable. Mais si vous êtes un superparanoïde, vous pouvez définir le taux de réplication à 5, et
min.insync.replicas à 3. Ensuite, trois courtiers à la fois doivent tomber en même temps afin de perdre le record! Bien sûr, pour une telle fiabilité, vous paierez un délai supplémentaire.
Lorsque l'accessibilité est nécessaire pour la sécurité des données
Comme
avec RabbitMQ , parfois l'accessibilité est nécessaire pour la sécurité des données. Vous devez y penser:
- Un éditeur peut-il simplement renvoyer une erreur et un service ou un utilisateur supérieur peut-il réessayer plus tard?
- Un éditeur peut-il enregistrer un message localement ou dans une base de données pour réessayer plus tard?
Si la réponse est non, l'optimisation de l'accessibilité améliore la sécurité des données. Vous perdrez moins de données si vous choisissez la disponibilité au lieu de supprimer l'enregistrement. Ainsi, tout se résume à trouver un équilibre, et la décision dépend de la situation spécifique.
La signification de l'ISR
La suite ISR vous permet de choisir l'équilibre optimal entre la sécurité des données et la latence. Par exemple, pour garantir que la plupart des répliques sont accessibles en cas de panne, en minimisant l'impact des répliques mortes ou lentes en termes de retard.
Nous choisissons nous-mêmes la valeur de
replica.lag.time.max.ms en fonction de nos besoins. En substance, ce paramètre signifie quel retard nous sommes prêts à accepter avec
acks = all . La valeur par défaut est de dix secondes. Si c'est trop long pour vous, vous pouvez le réduire. Ensuite, la fréquence des changements dans l'ISR augmentera, car les abonnés seront plus souvent supprimés et ajoutés.
RabbitMQ n'est qu'une collection de miroirs qui doivent être répliqués. Les miroirs lents introduisent un délai supplémentaire, et la réponse des miroirs morts peut être attendue avant l'expiration des paquets qui vérifient la disponibilité de chaque nœud (net tick). Les ISR sont un moyen intéressant d'éviter ces problèmes avec une latence accrue. Mais nous risquons de perdre la redondance, car l'ISR ne peut être réduit qu'à un leader. Pour éviter ce risque, utilisez le paramètre
min.insync.replicas .
Garantie de connectivité client
Dans les paramètres
bootstrap.servers du fabricant et du consommateur, vous pouvez spécifier plusieurs courtiers pour connecter les clients. L'idée est que lorsque vous déconnectez un nœud, il existe plusieurs nœuds de rechange avec lesquels le client peut ouvrir une connexion. Ce ne sont pas nécessairement des chefs de section, mais simplement un tremplin pour le bootstrap. Le client peut leur demander sur quel nœud se trouve le leader de la section lecture / écriture.
Dans RabbitMQ, les clients peuvent se connecter à n'importe quel hôte et le routage interne envoie une demande si nécessaire. Cela signifie que vous pouvez installer un équilibreur de charge devant RabbitMQ. Kafka exige que les clients se connectent à l'hôte hébergeant le leader de la partition correspondante. Dans cette situation, l'équilibreur de charge ne livre pas. La liste
bootstrap.servers est critique pour que les clients puissent accéder aux noeuds appropriés et les trouver après un plantage.
Architecture de consensus de Kafka
Jusqu'à présent, nous n'avons pas examiné comment le cluster apprend la chute du courtier et comment un nouveau leader est choisi. Pour comprendre comment Kafka fonctionne avec les partitions réseau, vous devez d'abord comprendre l'architecture de consensus.
Chaque cluster Kafka est déployé avec le cluster Zookeeper - c'est un service de consensus distribué qui permet au système de parvenir à un consensus sur un état donné avec la priorité sur la cohérence par rapport à la disponibilité. L'approbation des opérations de lecture et d'écriture nécessite le consentement de la plupart des nœuds Zookeeper.
Zookeeper stocke le statut du cluster:
- Liste des sujets, des sections, de la configuration, des répliques actuelles des leaders, des répliques préférées.
- Membres du cluster. Chaque courtier envoie un ping dans un cluster Zookeeper. S'il ne reçoit pas de ping pendant une période donnée, alors Zookeeper écrit le courtier inaccessible.
- Le choix des nœuds primaires et secondaires pour le contrôleur.
Le nœud du contrôleur est l'un des courtiers Kafka qui est responsable de l'élection des chefs de réplique. Zookeeper envoie au contrôleur des notifications d'appartenance à un cluster et de modifications de sujet, et le contrôleur doit agir conformément à ces changements.
Par exemple, prenez un nouveau sujet avec dix sections et un coefficient de réplication de 3. Le contrôleur doit sélectionner le leader de chaque section, en essayant de répartir de manière optimale les leaders entre les courtiers.
Pour chaque section, le contrôleur:
- met à jour les informations dans Zookeeper sur ISR et le leader;
- envoie une commande LeaderAndISRCommand à chaque courtier qui publie une réplique de cette section, informant les courtiers de l'ISR et du leader.
Lorsqu'un courtier avec un chef tombe, Zookeeper envoie une notification au contrôleur, et il sélectionne un nouveau chef. Encore une fois, le contrôleur met d'abord à jour Zookeeper, puis envoie une commande à chaque courtier, les informant d'un changement de leadership.
Chaque leader est responsable du recrutement des ISR. Le
paramètre replica.lag.time.max.ms détermine qui y ira. Lorsque l'ISR change, le leader transmet les nouvelles informations à Zookeeper.
Zookeeper est toujours informé de tout changement, de sorte qu'en cas d'échec, la direction se déplace en douceur vers le nouveau leader.
 Fig. 21. Consensus Kafka
Fig. 21. Consensus KafkaProtocole de réplication
La compréhension des détails de la réplication vous aide à mieux comprendre les scénarios de perte de données potentiels.
Exemples de demandes, décalage de fin de journal (LEO) et Highwater Mark (HW)
Nous avons considéré que les abonnés envoient périodiquement des demandes de récupération au leader. L'intervalle par défaut est de 500 ms. Cela diffère de RabbitMQ en ce que dans RabbitMQ, la réplication est lancée non pas par le miroir de file d'attente, mais par l'assistant. Le maître pousse les modifications aux miroirs.
Le leader et tous les suiveurs conservent le label Log End Offset (LEO) et Highwater (HW). La marque LEO stocke le décalage du dernier message dans la réplique locale et HW stocke le décalage du dernier commit. N'oubliez pas que pour le statut de validation, le message doit être enregistré dans toutes les répliques ISR. Cela signifie que LEO est généralement légèrement en avance sur HW.
Lorsqu'un leader reçoit un message, il l'enregistre localement. Le suiveur fait une demande de récupération, passant son LEO. Le leader envoie ensuite un paquet de messages commençant par ce LEO, et transmet également le matériel actuel. Lorsque le leader reçoit des informations indiquant que toutes les répliques ont enregistré le message à un décalage donné, il déplace la marque HW. Seul le leader peut déplacer le matériel, et ainsi tous les suiveurs connaîtront la valeur actuelle dans les réponses à leur demande. Cela signifie que les suiveurs peuvent être à la traîne du leader en matière de reporting et de connaissance des matériels. Les consommateurs ne reçoivent des messages que jusqu'au HW actuel.
Notez que «persistant» signifie écrit dans la mémoire, pas sur le disque. Pour des performances, Kafka se synchronise sur le disque à un intervalle spécifié. RabbitMQ a également un tel intervalle, mais il n'enverra la confirmation à l'éditeur qu'après que le maître et tous les miroirs auront écrit le message sur le disque. Pour des raisons de performances, les développeurs de Kafka ont décidé d'envoyer un accusé de réception dès que le message est écrit en mémoire. Kafka s'appuie sur le fait que la redondance compense le risque de stockage à court terme des messages confirmés uniquement en mémoire.
Échec du leader
Lorsqu'un chef tombe, Zookeeper avertit le contrôleur et il sélectionne une nouvelle réplique de chef. Le nouveau leader établit une nouvelle marque HW en ligne avec son LEO. Ensuite, les abonnés reçoivent des informations sur le nouveau leader. Selon la version de Kafka, le suiveur choisira l'un des deux scénarios:
- Tronque le journal local au célèbre HW et envoie un message au nouveau leader après cette marque.
- Il enverra une demande au chef pour connaître HW au moment de son élection en tant que chef, puis tronquer le journal à ce décalage. Ensuite, il commencera à faire des demandes d'échantillonnage périodiques, à partir de ce décalage.
Le suiveur peut avoir besoin de couper le journal pour les raisons suivantes:- , ISR, Zookeeper, . ISR, «», . , . Kafka , . , , HW . , acks=all .
- . , . , , , , , .
c
, : HW ( ). , RabbitMQ . . , « ». . .
Kafka — , , RabbitMQ, . . Kafka — , . . Kafka HW ( ) , . , , , LEO.
ISR . , , , ISR. .
Kafka , RabbitMQ, , . Kafka , .
:
- 1. , Zookeeper.
- 2. , Zookeeper.
- 3. , Zookeeper.
- 4. , Zookeeper.
- 5. Kafka, Zookeeper.
- 6. Kafka, Zookeeper.
- 7. Kafka Kafka.
- 8. Kafka Zookeeper.
.
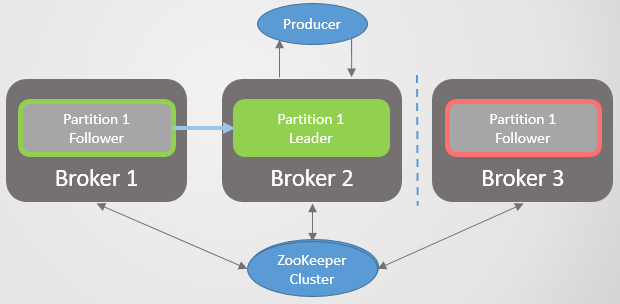
1. , Zookeeper
 . 22. 1. ISR
. 22. 1. ISR3 1 2, Zookeeper. 3 .
replica.lag.time.max.ms ISR . , ISR, . Zookeeper , .
 . 23. 1. ISR, replica.lag.time.max.ms
. 23. 1. ISR, replica.lag.time.max.ms(split-brain) , RabbitMQ. .
2. , Zookeeper
 . 24. 2.
. 24. 2., Zookeeper. , ISR , , . , . , . Zookeeper , .
 . 25. 2. ISR
. 25. 2. ISR3. , Zookeeper
Zookeeper, . ISR. Zookeeper , , .
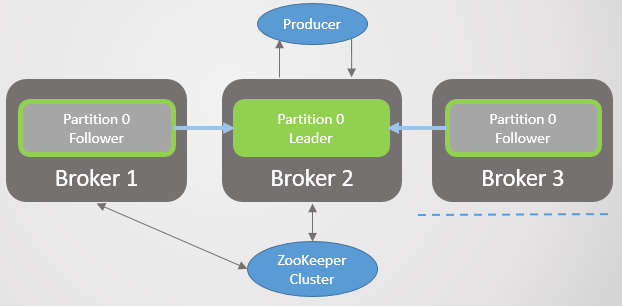 . 26. 3.
. 26. 3.4. , Zookeeper
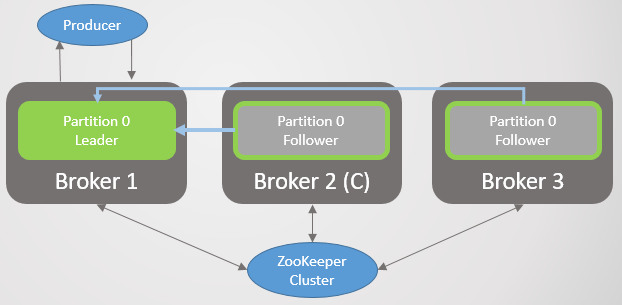 . 27. 4.
. 27. 4.Zookeeper, .
 . 28. 4. Zookeeper
. 28. 4. ZookeeperZookeeper . . ,
acks=1 . , ISR . Zookeeper, , .
acks=all , ISR , . ISR, - .
. , , , HW, , . . , . , , .
 . 29. 4. 1
. 29. 4. 15. Kafka, Zookeeper
Kafka, Zookeeper. ISR, , .
 . 30. 5. ISR
. 30. 5. ISR6. Kafka, Zookeeper
 . 31. 6.
. 31. 6., Zookeeper.
acks=1 .
 . 32. 6. Kafka Zookeeperreplica.lag.time.max.ms
. 32. 6. Kafka Zookeeperreplica.lag.time.max.ms , ISR , , Zookeeper, .
, Zookeeper , .
 . 33. 6.
. 33. 6., . 60 . .
 . 34. 6.
. 34. 6., . , Zookeeper , . HW .
 . 35. 6.
. 35. 6.,
acks=1 min.insync.replicas 1. , , , , — , . ,
acks=1 .
, , ISR . - . , ,
acks=all , ISR . . —
min.insync.replicas = 2 .
7. Kafka Kafka
, Kafka . , 6. .
8. Kafka Zookeeper
Zookeeper Kafka. , Zookeeper, . , , , Kafka.
, , , . , , , .
- Zookeeper,
acks=1 . Zookeeper .
acks=all .
min.insync.replicas , , 6.
, Kafka:
- , acks=1
- (unclean) , ISR, acks=all
- Zookeeper, acks=1
- , ISR . , acks=all . , min.insync.replicas=1 .
- . , . .
, , . —
acks=all min.insync.replicas 1.
RabbitMQ Kafka
. RabbitMQ . , . RabbitMQ. , . . , ( ) .
Kafka . . . , . , , . , - , . , .
RabbitMQ Kafka . , RabbitMQ . :
- fsync toutes les quelques centaines de millisecondes
- Les miroirs ne peuvent être détectés qu'après la durée de vie des paquets qui vérifient la disponibilité de chaque nœud (net tick). Si le miroir ralentit ou tombe, cela ajoute un délai.
Kafka s'appuie sur le fait que si le message est stocké sur plusieurs nœuds, vous pouvez confirmer les messages dès qu'ils sont en mémoire. De ce fait, il y a un risque de perdre des messages de tout type (même
acks = all ,
min.insync.replies = 2 ) en cas de panne simultanée.
Dans l'ensemble, Kafka présente de meilleures performances et a été initialement conçu pour les clusters. Le nombre d'adeptes peut être porté à 11, si nécessaire pour des raisons de fiabilité. Un facteur de réplication de 5 et un nombre minimum de répliques dans un état synchronisé de
min.insync.replicas = 3 feront de la perte de message un événement très rare. Si votre infrastructure est capable de fournir un tel taux de réplication et un niveau de redondance, vous pouvez choisir cette option.
Le clustering RabbitMQ est bon pour les petites files d'attente. Mais même les petites files d'attente peuvent augmenter rapidement avec un trafic élevé. Une fois les files d'attente devenues volumineuses, vous devrez faire un choix difficile entre disponibilité et fiabilité. Le clustering RabbitMQ est le mieux adapté aux situations non typiques où les avantages de la flexibilité de RabbitMQ l'emportent sur les inconvénients du clustering.
L'un des antidotes à la grande vulnérabilité de file d'attente de RabbitMQ est de les décomposer en de nombreux plus petits. Si vous n'avez pas besoin d'un ordre complet de toute la file d'attente, mais uniquement des messages pertinents (par exemple, les messages d'un client spécifique), ou rien du tout, alors cette option est acceptable: regardez mon projet
Rebalanser pour fractionner la file d'attente (le projet est encore à un stade précoce).
Enfin, n'oubliez pas un certain nombre de bogues dans les mécanismes de clustering et de réplication de RabbitMQ et de Kafka. Au fil du temps, les systèmes sont devenus plus matures et stables, mais aucun message ne sera jamais protégé à 100% contre les pertes! De plus, des accidents à grande échelle se produisent dans les centres de données!
Si j'ai raté quelque chose, fait une erreur ou si vous n'êtes d'accord avec aucun des points, n'hésitez pas à écrire un commentaire ou à me contacter.
Les gens me demandent souvent: «Que choisir, Kafka ou RabbitMQ?», «Quelle plateforme est la meilleure?». La vérité est que cela dépend vraiment de votre situation, de votre expérience actuelle, etc. Je n'ose pas exprimer mon opinion, car ce sera trop de simplification de recommander une plate-forme unique pour tous les cas d'utilisation et les limitations possibles. J'ai écrit cette série d'articles pour que vous puissiez vous faire votre propre opinion.
Je tiens à dire que les deux systèmes sont des chefs de file dans ce domaine. Je suis peut-être un peu biaisé, car à partir de l'expérience de mes projets, je suis plus enclin à apprécier des choses comme la garantie de l'ordre des messages et la fiabilité.
Je vois d'autres technologies qui manquent de fiabilité et de commande garantie, puis je regarde RabbitMQ et Kafka - et je comprends la valeur incroyable de ces deux systèmes.