Il n'y a pas si longtemps, nous avons
examiné comment les expériences A / B dans la recherche étaient organisées. Le chef de l'équipe de développement de la version iOS de Yandex.Browser Andrei Sikerin
sav42 lors de la dernière réunion de CocoaHeads Russie a également parlé de l'infrastructure de test A / B, uniquement dans son projet.
- Bonjour, je m'appelle Andrey Sikerin, je développe Yandex.Browser pour iOS. Je veux vous dire ce qu'est la plate-forme d'expérimentation de navigateur pour iOS, comment nous avons appris à l'utiliser, pris en charge ses fonctionnalités plus avancées, comment diagnostiquer et déboguer les fonctionnalités déployées à l'aide du système d'expérimentation, et aussi quelle est la source d'entropie et où la pièce est stockée.
Commençons donc. Dans le navigateur pour iOS, nous ne proposons jamais la fonctionnalité aux utilisateurs à la fois. Tout d'abord, nous effectuons des tests A / B, analysons les produits et les métriques techniques afin de comprendre comment la fonctionnalité déployée affecte l'utilisateur, qu'il le veuille ou non, si elle gaspille certaines métriques techniques. Pour cela, nous utilisons des analyses. Notre analyse ressemble à ceci:
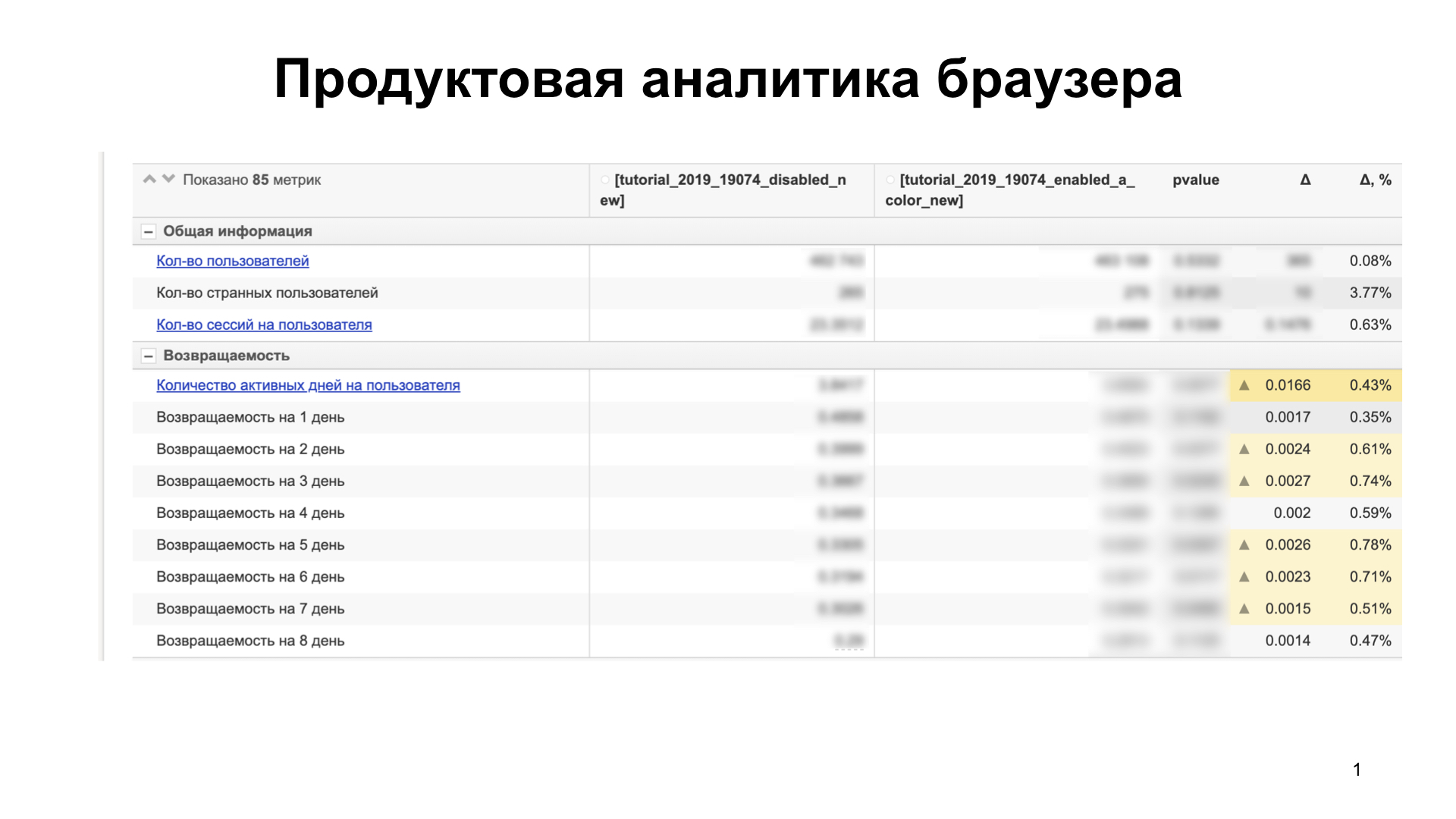
Il existe environ 85 mesures. Nous comparons plusieurs groupes d'utilisateurs. Supposons que cela augmente nos statistiques - par exemple, la capacité du produit à retenir les utilisateurs (rétention) - et n'en dilapide pas d'autres qui ne figurent pas sur la diapositive. Cela signifie que les utilisateurs aiment la fonctionnalité et peuvent être transférés à un grand groupe d'utilisateurs.
Si, néanmoins, nous gaspillons quelque chose, alors nous comprenons pourquoi. Nous construisons des hypothèses, les confirmons. Si nous dessinons des métriques techniques - c'est un bloqueur. Nous les corrigeons et réexécutons l'expérience. Et donc jusqu'à ce que nous peignions tout. Ainsi, nous déployons une fonctionnalité qui n'est pas une source de régression.
Parlons du système d'expérience original que nous avons utilisé. Elle était déjà assez développée. Ensuite, je vais vous dire ce qui ne nous convenait pas.

Tout d'abord, il est basé sur le système d'expérience Chromium et n'était pas entièrement pris en charge sur iOS. Deuxièmement, il était à l'origine en mesure de déployer des fonctionnalités pour différents groupes d'utilisateurs et disposait d'un système de filtrage sur lequel il était possible de définir des exigences pour les appareils. Autrement dit - la version de l'application à partir de laquelle la fonctionnalité est disponible, les paramètres régionaux de l'appareil - disons que nous voulons une expérience uniquement pour les paramètres régionaux russes. Soit la version d'iOS sur laquelle cette fonctionnalité sera disponible, soit la date à laquelle cette expérience sera valide - par exemple, si nous voulons mener une expérience uniquement jusqu'à une certaine date. En général, il y avait beaucoup de balises et c'était assez pratique.
Le système d'expérimentation lui-même se compose d'un fichier qui contient des descriptions des configurations des expériences. Autrement dit, pour une expérience, il peut y avoir plusieurs configurations à la fois. Ce fichier est un fichier texte, il est compilé en protobuf et disposé sur le serveur.
Chaque configuration se compose de groupes. Il y a une expérience, elle a plusieurs configurations, et dans chacune d'elles il y a plusieurs groupes. La fonctionnalité du code est attachée au nom du groupe actif de la configuration active. Cela peut sembler assez compliqué, mais maintenant je vais expliquer en détail de quoi il s'agit.

Comment ça marche techniquement? Un fichier avec des descriptions de toutes les configurations est téléchargé sur le serveur. Au démarrage, il est téléchargé par le navigateur du serveur et enregistré sur le disque. Au prochain démarrage, nous décodons ce fichier le premier de la chaîne d'initialisation de l'application. Et pour chaque expérience unique, nous trouvons une configuration qui sera active.
La configuration adaptée aux conditions spécifiées et décrites peut devenir active. S'il existe plusieurs configurations actives répondant aux conditions spécifiées, la configuration qui sera plus élevée dans le fichier est activée.
Plus loin dans la configuration active, une pièce est lancée. La pièce est lancée localement, et selon cette pièce d'une certaine manière, dont je parlerai plus tard, le groupe actif de l'expérience est sélectionné. Et c'est précisément au nom du groupe actif de l'expérience que nous sommes attachés dans le code, vérifiant si notre fonctionnalité est disponible ou non.
Une caractéristique clé de ce système est qu'il ne stocke rien par lui-même. Autrement dit, elle n'a pas de stockage sur le disque. Chaque lancement - nous prenons le fichier, commençons à le calculer, trouvons la configuration active. À l'intérieur de la configuration, selon la pièce, nous trouvons le groupe actif, et le système d'expérience pour cette expérience dit: ce groupe est sélectionné. Autrement dit, tout est calculé, rien n'est stocké.

Permettez-moi, en fait, de vous montrer un fichier avec des descriptions d'expériences. Le navigateur a une telle fonctionnalité - Traducteur. Elle s'est déployée dans une expérience. Le fichier commence par le bloc d'étude. La configuration de toute expérience commence par ce bloc. L'expérience s'appelle un traducteur. Il peut y avoir plusieurs blocs d'étude de ce nom. Et à l'intérieur du bloc d'étude, il existe de nombreux blocs d'expérimentation auxquels sont attribués des noms différents. Dans ce cas, nous voyons le groupe d'expériences activé. Et il y a un bloc de filtre, qui, en fait, décrit dans quelles conditions cette configuration peut devenir active, c'est-à-dire ses critères.
Il y a deux balises ici - channel et ya_min_version. Canal signifie vue d'ensemble. BETA est indiqué ici, ce qui signifie que cette configuration dans le fichier ne peut devenir active que pour les assemblys que nous envoyons à TestFlight. Pour la version App Store, cette configuration par critère de canal ne peut pas devenir active.
ya_min_version signifie qu'avec la version minimale de l'application 19.3.4.43 cette configuration peut devenir active. En fait, dans cette version de l'application, la fonctionnalité a déjà acquis un tel formulaire que vous pouvez l'activer.
Il s'agit de la description la plus simple du groupe de configuration de l'expérience du traducteur. Il peut y avoir plusieurs blocs d'étude de ce type dans un fichier. En utilisant des balises dans le bloc de filtre, nous les définissons pour différents canaux, pour les assemblages internes, pour les assemblages BETA, pour divers critères.
Voici un groupe d'expérience appelé activé, et il a une balise de poids de probabilité, le poids du groupe d'expérience. Il s'agit d'un entier non négatif utilisé pour déterminer le groupe actif au moment où la pièce sort.
Imaginons que cette configuration sur la diapositive soit devenue active. Autrement dit, nous avons vraiment installé l'application avec la version bêta publique, et nous avons vraiment la version 19.3.4.43. Comment la pièce est-elle lancée? Une pièce est un nombre aléatoire généré localement de zéro à un.
Pour que lors du prochain lancement nous tombions dans le même groupe, il est stocké sur disque. Bien que nous en tiendrons compte. Ensuite, je vais vous dire comment vous assurer qu'il n'est pas stocké. La pièce est jetée. Supposons que 0,5 soit jeté. Cette pièce est mise à l'échelle dans un segment allant de zéro à la somme des groupes d'expériences. Dans ce cas, nous avons un groupe activé, son poids est de 1000, c'est-à-dire que la somme de tous les groupes sera de 1000. «0,5» passe à 500. Par conséquent, tous les groupes d'expériences divisent l'intervalle de zéro au nombre d'expériences et de lacunes. Et le groupe devient actif dans l'intervalle duquel la valeur mise à l'échelle de la pièce indiquera.
Nous pouvons demander le nom du groupe d'expériences actif dans le code et ainsi déterminer l'accessibilité - devons-nous activer la fonctionnalité ou non.
De plus, nous examinerons des configurations expérimentales plus complexes que nous utilisons en production. Tout d'abord, il est clair qu'il est stupide de déployer une fonctionnalité à 100%, nous ne l'utilisons que pour la version bêta ou pour l'assemblage interne. Pour la production, nous utilisons les mécanismes suivants.
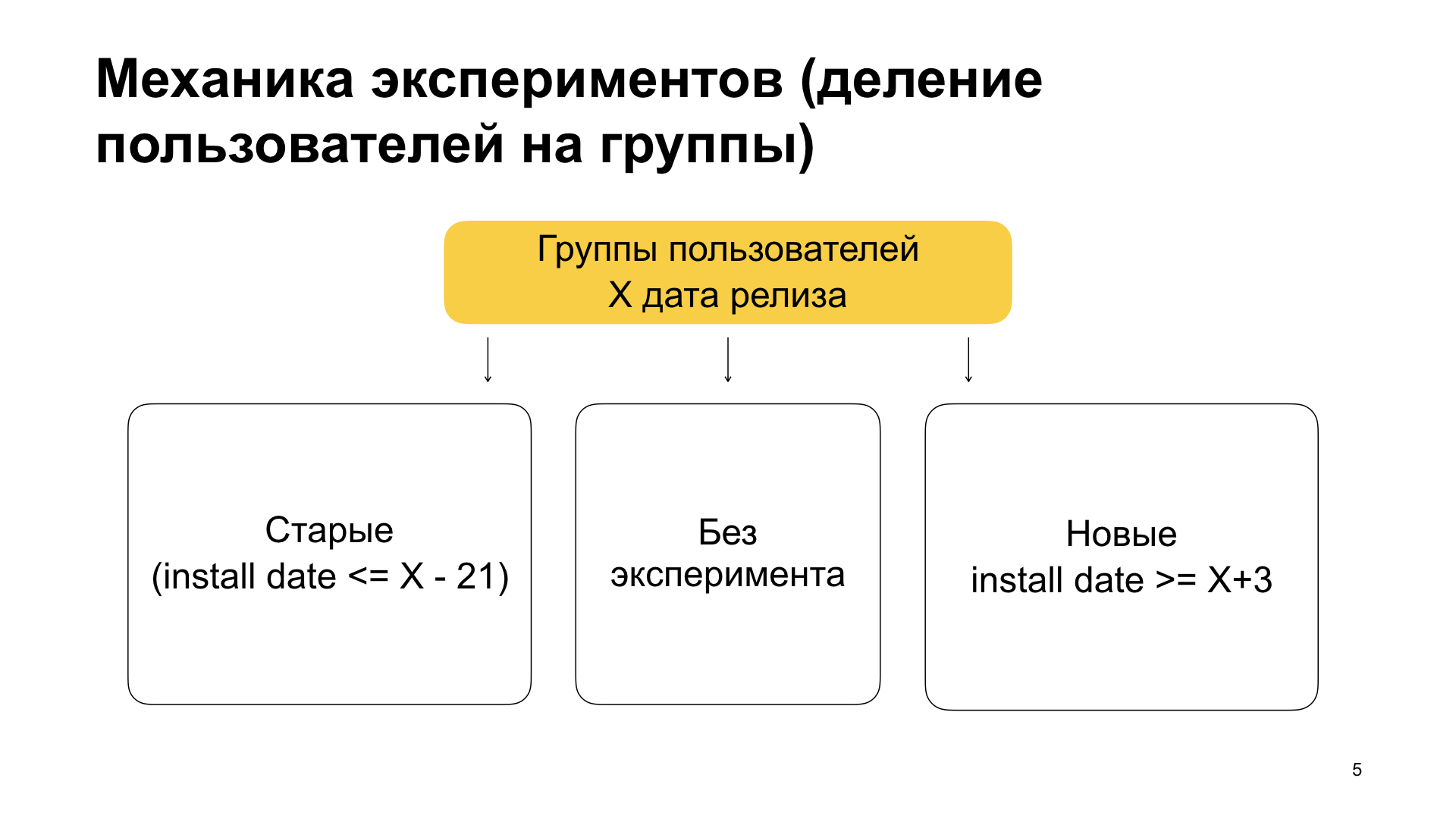
Nous divisons les utilisateurs en trois groupes: les anciens utilisateurs, les utilisateurs sans expérience et les nouveaux utilisateurs. En termes, cela signifie ce qui suit. Les anciens utilisateurs sont ceux qui ont déjà utilisé notre application et installé l'application avec des fonctionnalités en plus de l'ancienne version. Autrement dit, ils l'ont déjà utilisé, ils n'avaient pas de fonctionnalités, ils se sont habitués à tout et mettent soudainement à jour l'application, dans laquelle il y a une sorte d'expérience, de nouvelles fonctionnalités. Ensuite - utilisateurs sans expérience et nouveaux utilisateurs. Les nouveaux sont ceux qui nettoient l'application. Autrement dit, ils n'ont jamais utilisé Yandex.Browser, ils ont soudainement décidé de l'utiliser et ont installé l'application.
Comment réaliser cette partition? Dans le bloc de filtrage, nous définissons les conditions pour les balises min_install_date et max_install_date. Supposons que X soit le 14 mars 2019 - il s'agit de la date de sortie de la création de fonctionnalités. La date max_install_date pour les anciens utilisateurs sera alors de X moins 21 jours, avant la publication de l'assembly avec fonctionnalités. Si l'application a une telle date d'installation, il est fort probable que son premier lancement ait eu lieu avant sa sortie. Et avant la sortie, il y avait une version sans fonctionnalités. Et si maintenant il a, conditionnellement, une version avec des fonctionnalités, cela signifie qu'il a reçu l'application à l'aide d'une mise à jour.
Et pour les nouveaux utilisateurs, nous définissons min_install_date. Nous l'exposons comme X plus quelques jours. Cela signifie: s'il a une telle date d'installation, c'est-à-dire qu'il a effectué le premier lancement après la date de sortie de la version avec des fonctionnalités, alors il a eu une installation propre. Il a maintenant une version avec des fonctionnalités, mais la date d'installation était postérieure à cette version avec des fonctionnalités.
Ainsi, nous divisons les utilisateurs en anciens, sans expérience ni nouveaux. Nous le faisons parce que nous voyons: le comportement des anciens utilisateurs est différent du comportement des nouveaux utilisateurs. En conséquence, nous pouvons, par exemple, ne pas peindre dans un groupe avec d'anciens utilisateurs, mais peindre dans un groupe avec de nouveaux utilisateurs, ou vice versa. Si nous faisons une expérience sur toute la masse, nous ne le verrons peut-être pas.

Regardons cette expérience. Nous voyons la configuration d'expérience suivante - Traducteur pour l'App Store, nouveaux utilisateurs. Étude de bloc, traducteur de noms, groupe enabled_new. Le préfixe new signifie que nous décrivons la configuration pour de nombreux utilisateurs nouveaux. Poids 500 (si la somme de tous les poids est de 1000, alors la puissance de cet ensemble est de 50%). Control_new, poids 500, c'est le deuxième groupe. Et le plus intéressant, ce sont les filtres pour le canal STABLE, c'est-à-dire pour les assemblages qui sont assemblés pour la production. Version dans laquelle la fonctionnalité est apparue: 19.4.1. Et voici la balise min_install_date. Ici, au format horaire Unix, il est chiffré le 18 avril 2019. C'est quelques jours après la sortie de la version 19.4.1.
Il y a une autre partie ici en plus du nouveau préfixe, il est activé et contrôlé. Voici le préfixe de contrôle, ce n'est pas accidentel. Et en plus du fait que nous divisons les utilisateurs en nouveaux et anciens, nous les divisons en groupes au sein de l'expérience en plusieurs parties.
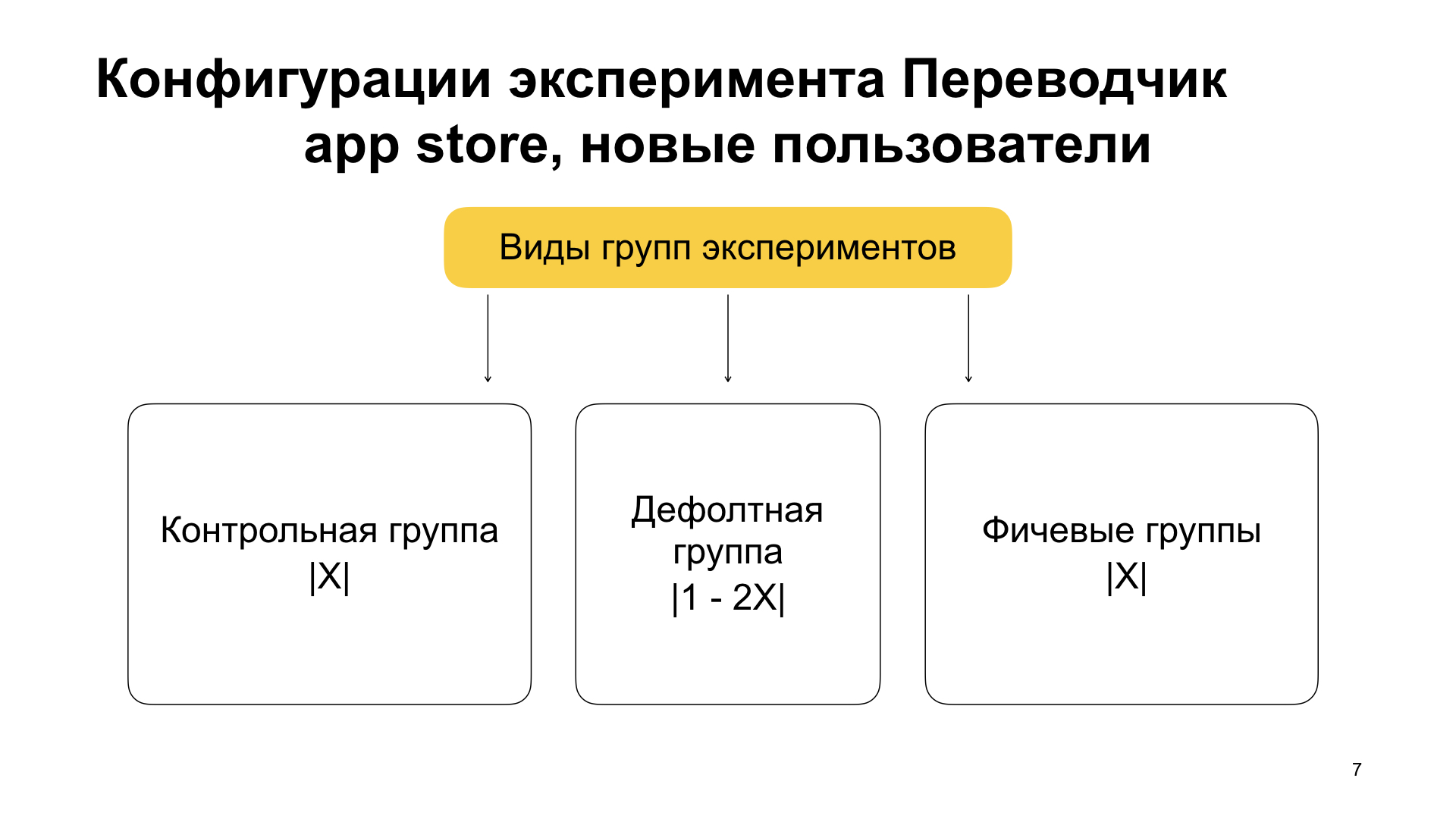
La première partie des utilisateurs est un groupe de contrôle, celui qui a le préfixe de contrôle. Il n'y a aucune fonctionnalité. Elle a un poids X. Elle possède également un groupe de fonctions, généralement appelé activé. Il a également un poids X, ce qui est important: là, la fonction doit être activée. Et il y a un groupe par défaut qui a un poids de 1 moins 2X (1000 moins 2X, car 1000 est la valeur du poids total de tous les groupes dans la même configuration, qui est acceptée par défaut). Le groupe par défaut ne comprend également aucune fonctionnalité. Il stocke simplement les utilisateurs qui sont restés après leur séparation en utilisateurs de contrôle et de fonctionnalité. Vous pouvez également réexécuter l'expérience à partir de celle-ci, si nécessaire.

Voyons, disons, la configuration pour les anciens utilisateurs. Nous verrons un groupe de fonctionnalités et de contrôle ici. enabled_old - en vedette. control_old, - contrôle, 10%. default_old - défaut, 80%.
Filtre de notes, ya_min_version 19.4.1, max_install_date 28 mars 2019. Il s'agit d'une date antérieure à la date de sortie. En conséquence, il s'agit d'une configuration avec une liste d'utilisateurs qui ont reçu la version 19.4.1 après la mise à jour. Ils ont utilisé l'application et utilisent maintenant la nouvelle version.
Pourquoi des groupes de fonctionnalités et de contrôle sont-ils nécessaires? Dans l'analyse que j'ai montrée sur la première diapositive, nous comparons le groupe de contrôle et le groupe d'entités. Ils doivent être de même puissance pour pouvoir comparer les métriques de leurs produits.
Ainsi, nous comparons le contrôle et les groupes de fonctionnalités dans l'analyse pour différents groupes d'utilisateurs, anciens et nouveaux. Si nous peignons tout, nous roulons la fonctionnalité de 100%.

Comment un développeur de code fonctionne-t-il avec ce système? Il connaît les noms des groupes d'entités, la date à laquelle la fonctionnalité doit être activée et écrit une couche d'accès, c'est un pseudocode, demandant un groupe actif par le nom de l'expérience. Ce n'est peut-être pas le cas. En fait, toutes les configurations peuvent ne pas correspondre aux conditions de l'appareil. Ensuite, la chaîne vide reviendra.
Après cela, si le nom du groupe actif apparaît, vous devez activer la fonction, sinon désactivez-la. De plus, cette fonction est déjà utilisée dans le code, qui inclut des fonctionnalités dans le code du navigateur.

Nous avons donc vécu avec ce système d'expériences pendant plusieurs années. Tout allait bien, mais a révélé un certain nombre de lacunes. Le premier inconvénient de cette approche est qu'il est impossible d'ajouter de nouveaux groupes d'expériences sans corriger le code. Autrement dit, s'il est peu probable que le nom de l'expérience change pour une fonctionnalité, puis en ajoutant quelques groupes supplémentaires, cela peut facilement l'être. Mais votre code d'accessibilité aux fonctionnalités ne connaît pas de tels groupes, car vous ne l'aviez pas prévu à l'avance. Par conséquent, vous devez rouler la version, expérimenter avec cette version, ce qui est un problème. Autrement dit, il est nécessaire, en changeant le code, de reconstruire et de publier dans l'App Store.
Deuxièmement, vous ne pouvez pas déployer des parties d'une fonction ou diviser une fonction en parties après avoir commencé l'expérience. Autrement dit, si vous décidez soudainement que certaines fonctionnalités peuvent être déployées et que certaines restent dans l'expérience, vous ne pouvez pas le faire, vous devez réfléchir à l'avance et diviser cette fonctionnalité en deux et les accepter indépendamment dans l'expérience.
Troisièmement, vous ne pouvez pas configurer une fonctionnalité ou comparer des configurations. Dans Translator, par exemple, il existe un paramètre - timeout time to the Translator API. Autrement dit, si nous n'avons pas réussi à traduire en quelques millisecondes, alors nous disons que, essayez à nouveau, une erreur, pas de chance.
Il est impossible de définir ce délai dans l'expérience, car nous devons soit fixer les groupes et immédiatement à l'avance, nous allons avoir les groupes suivants à l'avance - enabled_with_300_ms, enabled_with_600_ms au nom desquels la valeur du paramètre est codée. Mais il est impossible de définir le paramètre numériquement d'une manière ou d'une autre. Si nous n'y avons pas pensé auparavant, nous ne pouvons plus comparer plusieurs configurations.
Quatrièmement, les analystes et les développeurs sont obligés de s'entendre à l'avance sur les noms des groupes. Autrement dit, pour qu'un développeur commence à développer une fonctionnalité, il commence généralement, en fait, par la politique de disponibilité de cette fonctionnalité. Et il a besoin de connaître les noms des groupes de fonctionnalités. Et pour cela, l'analyste doit expliquer la mécanique de l'expérience - si nous diviserons les utilisateurs en nouveaux et anciens ou si tous les utilisateurs seront dans le même groupe sans division.
Ou cela pourrait être une expérience inverse. Par exemple, nous pouvons immédiatement considérer que la fonctionnalité est activée, mais pouvoir la désactiver. Ce n'est pas très intéressant pour l'analyste, car la fonctionnalité n'est pas prête. Il déterminera la mécanique de l'expérience lorsqu'elle sera prête. Et le développeur a besoin à l'avance des noms des groupes et des mécanismes de l'expérience, sinon il devra constamment apporter des modifications au code.
Nous avons consulté et décidé que c'était suffisant pour durer. Le projet Make Experiments Great Again est donc né.

L'idée clé de ce projet est la suivante. Si auparavant nous étions attachés à un code, un code aux noms des groupes actifs que l'analyste nous a transmis, nous avons maintenant ajouté deux entités supplémentaires. Cette fonctionnalité (Feature) et paramètre de fonctionnalité (FeatureParam). Et ainsi, le programmeur invente les fonctionnalités et les paramètres de fonctionnalité indépendamment, en choisissant des identificateurs pour eux, en choisissant des valeurs par défaut pour eux et en programmant la disponibilité des fonctionnalités pour eux.
Après cela, il transmet ces identifiants à l'analyste, et l'analyste, en réfléchissant à la mécanique des expériences, les spécifie d'une manière spéciale dans les groupes d'expériences en utilisant la balise feature_association. Si ce groupe devient actif, n'oubliez pas d'activer ou de désactiver la fonctionnalité avec l'identifiant tel ou tel, et de définir les paramètres avec de tels identifiants.

À quoi ressemble-t-il dans le fichier de configuration de l'expérience? Ici, nous regardons le groupe d'expérience. Nom activé, une balise facultative feature_association est ajoutée, dans cette balise de commande enable_feature ou disable_feature, et des identificateurs sont ajoutés.
Il y a aussi un bloc param, dont il peut y en avoir plusieurs. Ici aussi, il y a un nom - timeout, et la valeur qui doit être définie est ajoutée.

À quoi cela ressemble-t-il à partir du code? Le programmeur déclare les entités des classes Feature et FeatureParam. Et il écrit les valeurs de ces primitives dans la couche d'accès aux entités. Ensuite, il transmet cet identifiant à l'analyste, et il déjà dans le fichier de configuration définit les identifiants dans le bloc du groupe d'expérience en utilisant la balise feature_association. Dès que le groupe d'expériences devient actif, les valeurs des caractéristiques et des paramètres avec ces identifiants dans le code sont définies à partir du fichier. S'il n'y a pas de paramètres et de fonctionnalités dans le groupe, les valeurs par défaut sont utilisées, qui sont indiquées dans le code.
Il semblerait que cela nous a donné? Tout d'abord, lors de l'ajout d'un nouveau groupe, l'analyste n'a pas besoin de demander au programmeur d'ajouter un nouveau groupe d'entités au code, car la couche d'accès aux données fonctionne avec des identifiants qui ne changent pas lorsqu'un nouveau groupe est ajouté au système d'expérimentation.
-, , , , . , , , , .
. , , translator, , , . TranslateServiceAPITimeout, , timeout API . , , , , : 300 600.
. . (FeatureParam).
, , , . , , . , , . . ?

, : Feature FeatureParam. Feature FeatureParam . , Feature FeatureParam, , . . - , , .
-, Feature&FeatureParam. , «», , , . FeatureParam , , API — 300 600 ?
. . - , . public beta, . , .
, : .

? , , .
: . URL, , .
: browser://version — show-variations-cmd. : cheat-, . : .
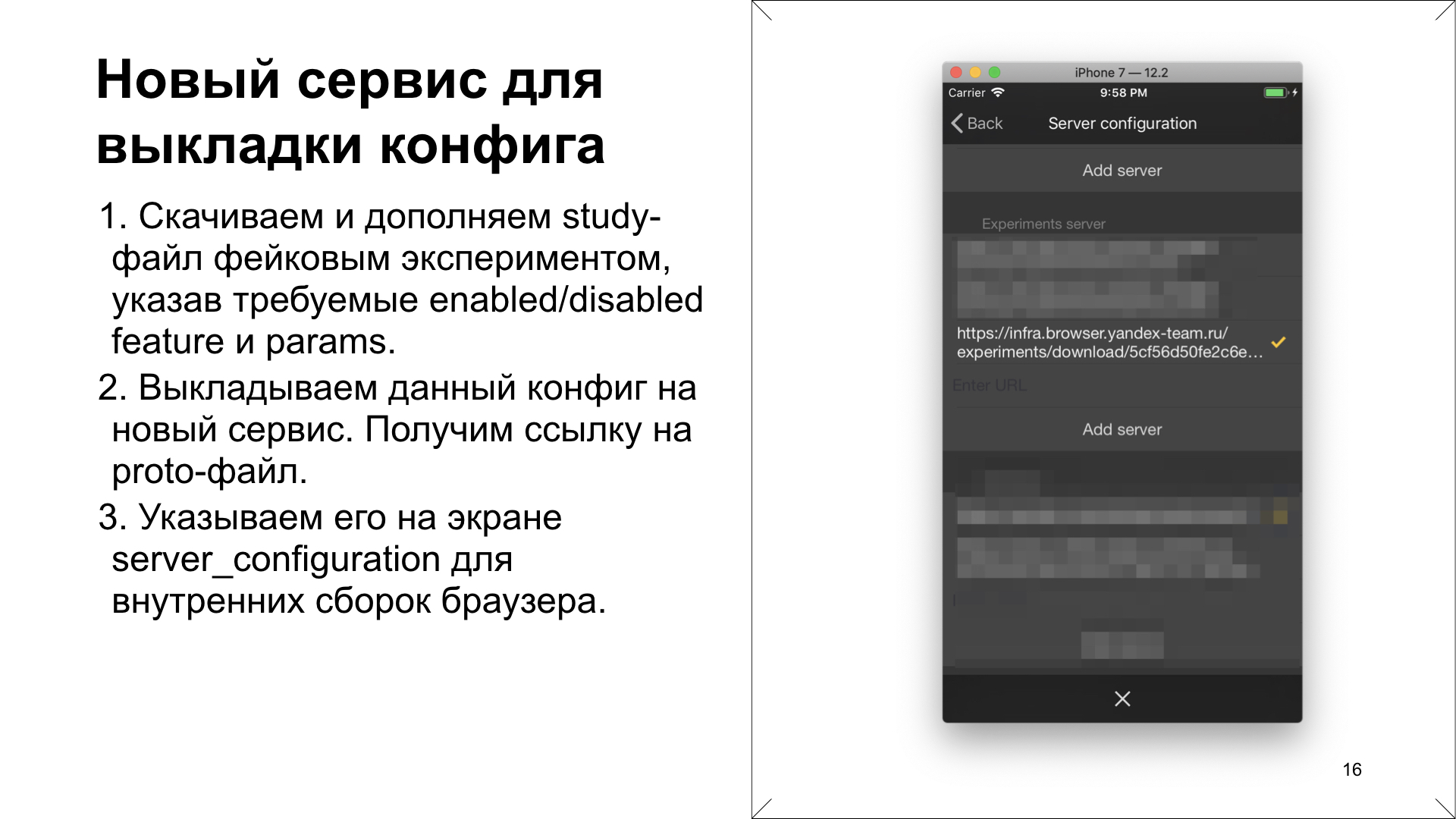
. , . proto- - , study-, . , . Feature&FeatureParam, . , , . , , Feature&FeatureParam .
. proto- . . , . , , .

Le deuxième. Feature&FeatureParam? Chromium, . Chromium browser://version, show-variations-cmd.
: enabled-features, force-fieldtrials force-fieldtrials-params, . , . ? , . , Feature1 trial1. Feature2 trial2. Feature3 .
trial1 group1. trial2 group2. force-fieldtrials-params, , trial1 group1, p1 v1, p2 v2. trial2 group2, p3 v3, p4 v4.
, . Chromium, iOS. , .
. --force-fieldtrials=translator/enabled_new/ enabled_new translator.
--force-fieldtrial-params==translator.enablew_new:timeout/5000, translator enabled_new, , , translator, enabled_new timeout, 5 000 .
--enabled-features=TranslateServiceAPITimeout<translator , - translator translator , , , TranslateServiceAPITimeout. , , , , .

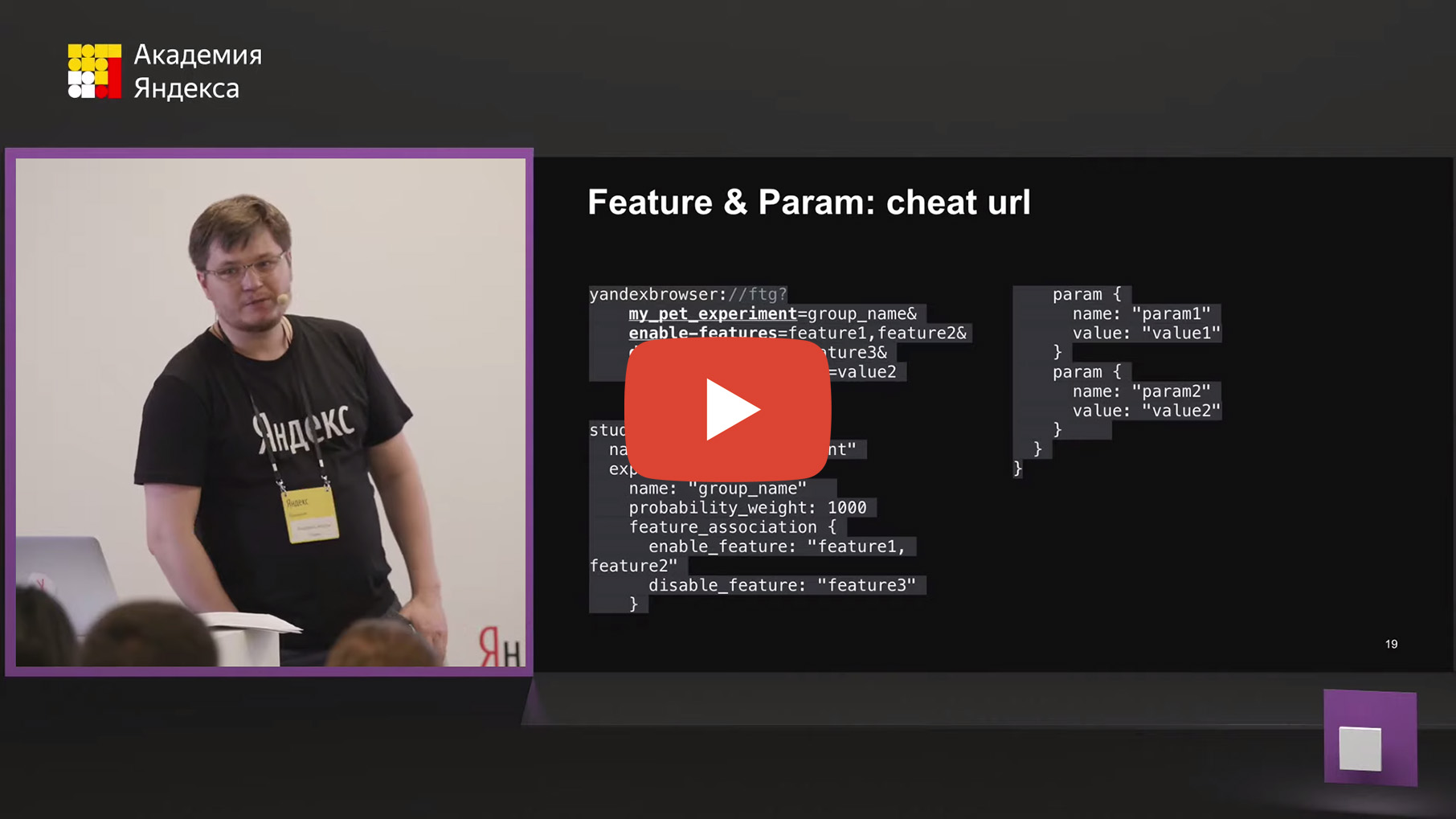
(cheat urls). , , , , , , . . . .
yandexbrowser:// (.), , . . my_pet_experiment=group_name. , enable-features=, , disable-features=, . , &.
(cheat url), . , , , . , , . filter, my_pet_experiment , . 1000, feature_association, , .
, . , , . , — my_pet_experiment — , , . , , study .
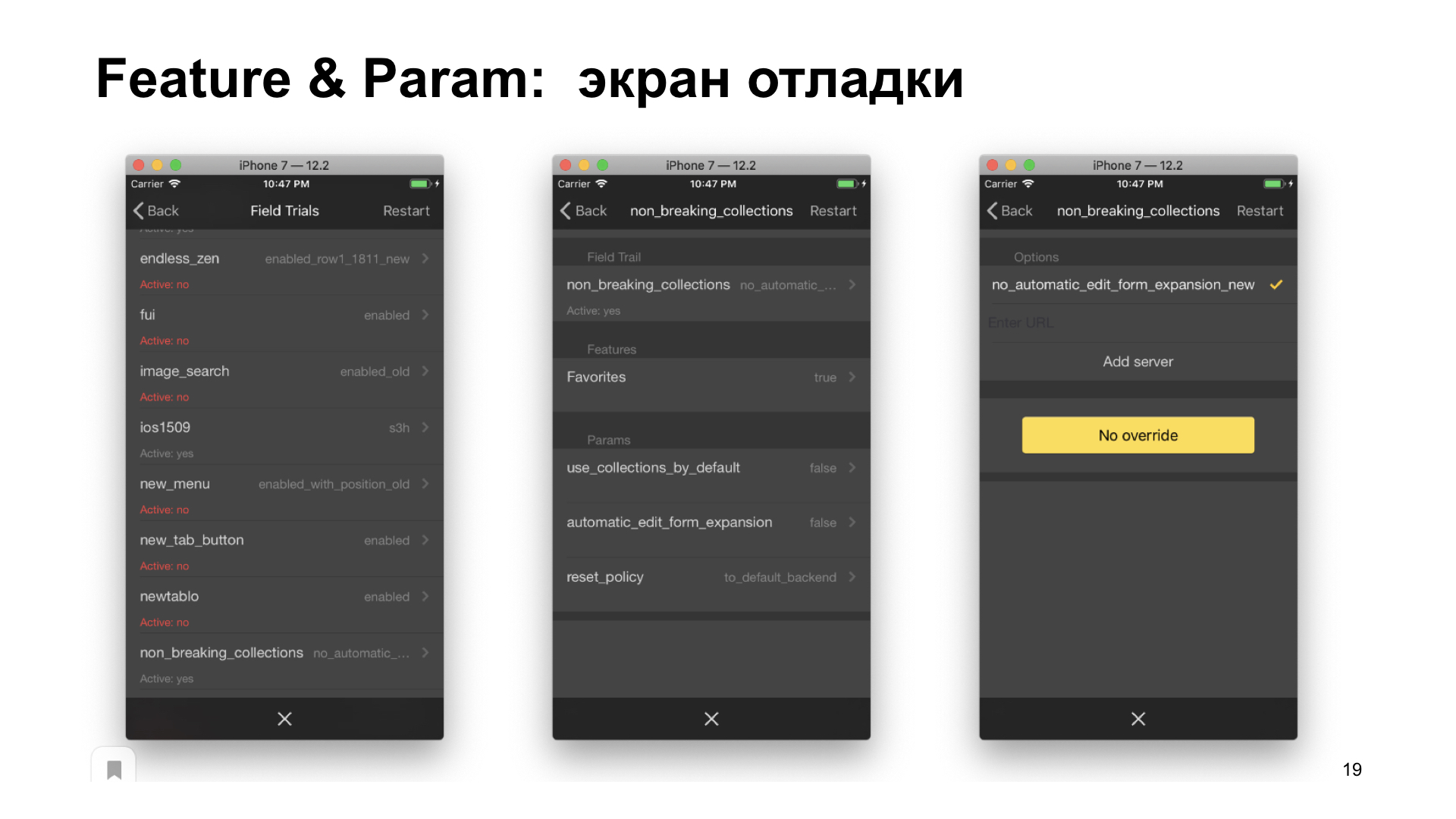
, . — , . . , .
, .

, , , , . , . , .
. . , , ? , . , ?
. .

, . , , UUID, application Identifier, . . hash .
? ? , , UUID, . ? , , . . ? hash hash , . ,
Google, An Efficient Low-Entropy Provider.
, — UUID, , , . , , Chromium.
, , ? ? :
- : , -. .
- . , , , .
- . , , , .
- , .
- . , , (. hromium variation service ).
Chromium, . iOS, . , . Je vous remercie