
Nous rencontrons régulièrement la base de données Apache Cassandra et la nécessité de l'exploiter dans le cadre de l'infrastructure basée sur Kubernetes. Dans cet article, nous partagerons notre vision des étapes nécessaires, des critères et des solutions existantes (y compris un aperçu des opérateurs) pour la migration de Cassandra vers les K8.
«Qui peut contrôler une femme fera face à l'État»
Qui est Cassandra? Il s'agit d'un système de stockage distribué conçu pour gérer de grandes quantités de données tout en offrant une haute disponibilité sans un seul point de défaillance. Le projet n'a guère besoin d'une longue introduction, donc je ne donnerai que les principales caractéristiques de Cassandra, qui seront pertinentes dans le contexte d'un article spécifique:
- Cassandra est écrite en Java.
- La topologie Cassandra comprend plusieurs niveaux:
- Node - une instance déployée de Cassandra;
- Rack - un groupe d'instances Cassandra, unies par n'importe quel attribut, situées dans un centre de données;
- Datacenter - la totalité de tous les groupes d'instances Cassandra situés dans un centre de données;
- Cluster - une collection de tous les centres de données.
- Cassandra utilise une adresse IP pour identifier l'hôte.
- Pour la vitesse des opérations de lecture et d'écriture, Cassandra stocke une partie des données dans la RAM.
Maintenant, pour le déplacement potentiel réel vers Kubernetes.
Liste de contrôle pour la migration
En parlant de la migration de Cassandra vers Kubernetes, nous espérons qu'il deviendra plus pratique de la gérer avec le déménagement. Qu'est-ce qui sera nécessaire pour cela, qu'est-ce qui vous aidera?
1. Stockage des données
Comme déjà spécifié, une partie des données que Cassanda stocke dans la RAM - dans
Memtable . Mais il existe un autre élément de données qui est enregistré sur le disque - sous la forme de
SSTable . À ces données s'ajoute le
journal de l'entité - les enregistrements de toutes les transactions qui sont également enregistrées sur le disque.
 Schéma de transaction d'écriture Cassandra
Schéma de transaction d'écriture CassandraDans Kubernetes, nous pouvons utiliser PersistentVolume pour stocker des données. Grâce à des mécanismes bien développés, l'utilisation des données dans Kubernetes devient plus facile chaque année.
 Pour chaque pod avec Cassandra, nous allouerons notre volume persistant
Pour chaque pod avec Cassandra, nous allouerons notre volume persistantIl est important de noter que Cassandra elle-même implique la réplication des données, offrant des mécanismes intégrés pour cela. Par conséquent, si vous créez un cluster Cassandra à partir d'un grand nombre de nœuds, il n'est pas nécessaire d'utiliser des systèmes distribués tels que Ceph ou GlusterFS pour stocker des données. Dans ce cas, il sera logique de stocker des données sur le disque hôte en utilisant
des disques persistants locaux ou en montant
hostPath .
Une autre question est de savoir si vous souhaitez créer un environnement de développement distinct pour chaque branche de fonctionnalité. Dans ce cas, l'approche correcte serait de soulever un nœud Cassandra et de stocker les données dans un stockage distribué, c'est-à-dire Ceph et GlusterFS mentionnés seront votre option. Le développeur sera alors sûr de ne pas perdre de données de test même si l'un des nœuds du cluster Kuberntes est perdu.
2. Suivi
Prometheus est un choix pratiquement non alternatif pour la surveillance dans Kubernetes
(nous en avons parlé en détail dans le rapport correspondant ) . Comment Cassandra s'en sort-elle avec les exportateurs de métriques pour Prometheus? Et qu'est-ce qui est encore plus important en quelque sorte, avec des tableaux de bord qui leur conviennent pour Grafana?
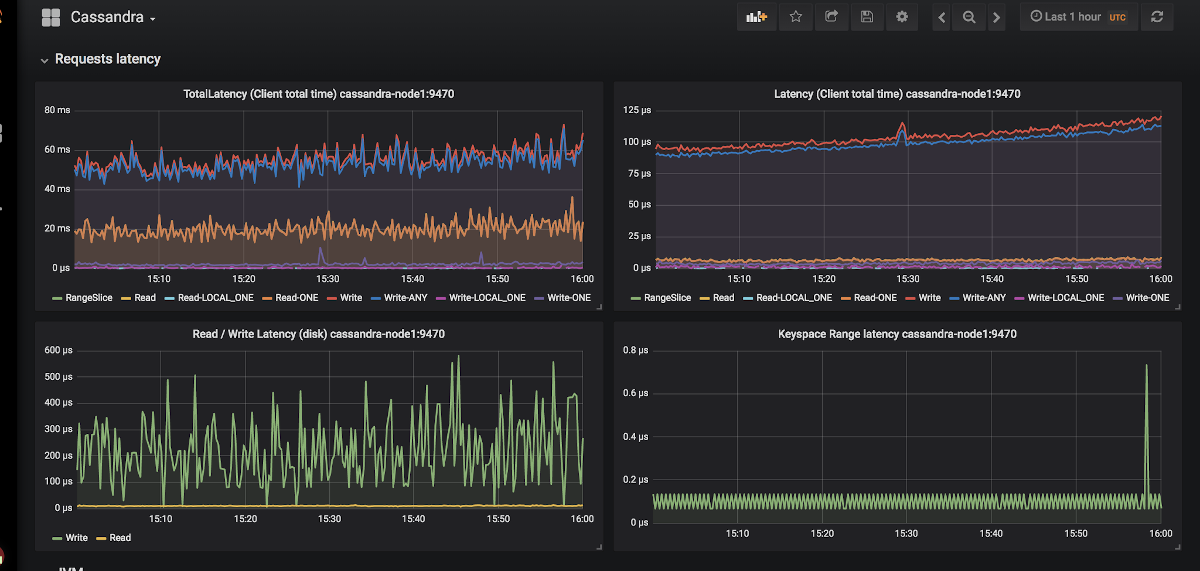 Un exemple de l'apparition de graphiques dans Grafana pour Cassandra
Un exemple de l'apparition de graphiques dans Grafana pour CassandraIl n'y a que deux exportateurs:
jmx_exporter et
cassandra_exporter .
Nous avons choisi le premier pour nous, car:
- JMX Exporter se développe et se développe, tandis que Cassandra Exporter n'a pas pu obtenir le soutien approprié de la communauté. Cassandra Exporter ne prend toujours pas en charge la plupart des versions de Cassandra.
- Vous pouvez l'exécuter en tant que javaagent en ajoutant l'indicateur
-javaagent:<plugin-dir-name>/cassandra-exporter.jar=--listen=:9180 . - Pour lui, il existe un tableau de bord adéquat qui est incompatible avec Cassandra Exporter.
3. Sélection des primitives Kubernetes
Selon la structure ci-dessus du cluster Cassandra, nous essaierons de traduire tout ce qui y est décrit dans la terminologie Kubernetes:
- Noeud Cassandra → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → pool de StatefulSets
- Cluster Cassandra → ???
Il s'avère qu'il manque une entité supplémentaire pour gérer l'ensemble du cluster Cassandra à la fois. Mais si quelque chose n'est pas là, nous pouvons le créer! Kubernetes dispose d'un moteur de définition de ressources dédié appelé
Définitions de ressources personnalisées .
 Annonce de ressources supplémentaires pour les journaux et les alertes
Annonce de ressources supplémentaires pour les journaux et les alertesMais Custom Resource seul ne veut rien dire: vous avez besoin d'un
contrôleur pour cela. Vous devrez peut-être recourir à l'aide d'un
opérateur Kubernetes ...
4. Identification des gousses
Le point ci-dessus, nous avons convenu qu'un nœud Cassandra équivaudrait à un pod dans Kubernetes. Mais les adresses IP du pod seront différentes à chaque fois. Et l'identification du nœud dans Cassandra se produit précisément sur la base de l'adresse IP ... Il s'avère qu'après chaque retrait du pod, le cluster Cassandra ajoutera un nouveau nœud.
Il existe une issue, pas même une:
- Nous pouvons conserver des enregistrements par des identifiants d'hôte (UUID qui identifient de manière unique les instances de Cassandra) ou par des adresses IP et enregistrer tout cela dans certaines structures / tableaux. La méthode présente deux inconvénients principaux:
- Le risque d'une condition de concurrence lorsque deux nœuds tombent à la fois. Après la mise à niveau, les nœuds Cassandra iront simultanément demander une adresse IP pour eux-mêmes à partir de la table et rivaliser pour la même ressource.
- Si le nœud Cassandra a perdu ses données, nous ne pourrons plus l'identifier.
- La deuxième solution semble être un petit hack, mais néanmoins: nous pouvons créer un service avec ClusterIP pour chaque nœud Cassandra. Problèmes avec cette implémentation:
- S'il y a beaucoup de nœuds dans un cluster Cassandra, nous devrons créer beaucoup de services.
- La fonctionnalité ClusterIP est implémentée via iptables. Cela peut être un problème si le cluster Cassandra a plusieurs (1000 ... ou même 100?) Nœuds. Bien que l' équilibrage basé sur IPVS puisse résoudre ce problème.
- La troisième solution consiste à utiliser un réseau de nœuds pour les nœuds Cassandra au lieu d'un réseau de pod dédié en activant le
hostNetwork: true . Cette méthode impose certaines restrictions:
- Pour remplacer les nœuds. Il est nécessaire que le nouvel hôte doit avoir la même adresse IP que le précédent (dans les nuages comme AWS, GCP, c'est presque impossible à faire);
- En utilisant le réseau de nœuds de cluster, nous commençons à rivaliser pour les ressources réseau. Par conséquent, mettre sur un nœud de cluster plus d'un pod avec Cassandra sera problématique.
5. Sauvegardes
Nous voulons garder la version complète des données pour un nœud Cassandra sur un calendrier. Kubernetes offre une opportunité pratique en utilisant
CronJob , mais ici Cassandra insère les bâtons dans les roues.
Permettez-moi de vous rappeler qu'une partie des données que Cassandra stocke en mémoire. Pour effectuer une sauvegarde complète, vous devez transférer les données de la mémoire (
Memtables ) vers le disque (
SSTables ). À ce stade, le nœud Cassandra cesse d'accepter les connexions, s'arrêtant complètement à partir du cluster.
Après cela, une sauvegarde (
instantané ) est supprimée et le schéma (
espace de clés ) est
enregistré . Et puis il s'avère que juste une sauvegarde ne nous donne rien: vous devez enregistrer les identifiants de données dont le nœud Cassandra était responsable - ce sont des jetons spéciaux.
 Distribution de jetons pour identifier les données responsables des nœuds Cassandra
Distribution de jetons pour identifier les données responsables des nœuds CassandraUn exemple de script pour supprimer Cassandra de Google dans Kubernetes peut être trouvé sur
ce lien . Le seul point que le script ne prend pas en compte est le vidage des données sur le nœud avant de supprimer l'instantané. Autrement dit, la sauvegarde n'est pas effectuée pour l'état actuel, mais pour l'état un peu plus tôt. Mais cela aide à ne pas mettre le nœud hors de travail, ce qui semble très logique.
set -eu if [[ -z "$1" ]]; then info "Please provide a keyspace" exit 1 fi KEYSPACE="$1" result=$(nodetool snapshot "${KEYSPACE}") if [[ $? -ne 0 ]]; then echo "Error while making snapshot" exit 1 fi timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }') mkdir -p /tmp/backup for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do table=$(echo "${path}" | awk -F "[/-]" '{print $7}') mkdir /tmp/backup/$table mv $path /tmp/backup/$table done tar -zcf /tmp/backup.tar.gz -C /tmp/backup . nodetool clearsnapshot "${KEYSPACE}"
Exemple de script bash pour supprimer la sauvegarde d'un seul nœud CassandraSolutions prêtes à l'emploi pour Cassandra à Kubernetes
Que utilisent-ils actuellement pour déployer Cassandra dans Kubernetes, et lequel est le plus adapté aux exigences données?
1. Solutions StatefulSet ou Helm Chart
L'utilisation des StatefulSets de base pour démarrer un cluster Cassandra est une bonne option. En utilisant le modèle Helm chart et Go, vous pouvez fournir à l'utilisateur une interface flexible pour déployer Cassandra.
Habituellement, cela fonctionne bien ... jusqu'à ce que quelque chose d'inattendu se produise - par exemple, un nœud tombe en panne. Les outils Kubernetes standard ne peuvent tout simplement pas prendre en compte toutes les fonctionnalités ci-dessus. De plus, cette approche est très limitée dans la façon dont elle peut être étendue pour une utilisation plus complexe: remplacement de nœud, sauvegarde, restauration, surveillance, etc.
Représentants:
Les deux graphiques sont également bons, mais sont sujets aux problèmes décrits ci-dessus.
2. Solutions basées sur Kubernetes Operator
Ces options sont plus intéressantes car elles offrent des capacités de gestion de cluster étendues. Pour concevoir une instruction Cassandra, comme toute autre base de données, un bon modèle ressemble à Sidecar <-> Controller <-> CRD:
 Diagramme de gestion des nœuds dans une instruction Cassandra correctement conçue
Diagramme de gestion des nœuds dans une instruction Cassandra correctement conçueConsidérez les opérateurs existants.
1. Cassandra-operator par instaclustr
- Github
- Volonté: Alpha
- Licence: Apache 2.0
- Implémenté en: Java
Il s'agit en effet d'un projet très prometteur et en développement rapide d'une entreprise qui propose des déploiements gérés par Cassandra. Il, comme décrit ci-dessus, utilise un conteneur sidecar qui accepte les commandes via HTTP. Il est écrit en Java, donc il lui manque parfois la fonctionnalité de bibliothèque client-go plus avancée. En outre, l'opérateur ne prend pas en charge différents racks pour un centre de données.
Mais l'opérateur a des avantages tels que la prise en charge de la surveillance, la gestion de cluster de haut niveau à l'aide de CRD et même la documentation sur la suppression des sauvegardes.
2. Navigator par Jetstack
- Github
- Volonté: Alpha
- Licence: Apache 2.0
- Mis en œuvre en: Golang
Une déclaration pour le déploiement de DB-as-a-Service. Prend actuellement en charge deux bases de données: Elasticsearch et Cassandra. Il a des solutions intéressantes comme le contrôle d'accès à la base de données via RBAC (pour cela, son propre navigateur-apiserver distinct est levé). Un projet intéressant, qui mériterait un examen plus approfondi, mais le dernier engagement a été pris il y a un an et demi, ce qui réduit clairement son potentiel.
3. Cassandra-opérateur de vgkowski
- Github
- Volonté: Alpha
- Licence: Apache 2.0
- Mis en œuvre en: Golang
Ils ne l'ont pas considéré «sérieusement», car le dernier commit sur le référentiel remonte à plus d'un an. Le développement des opérateurs est abandonné: la dernière version de Kubernetes, déclarée prise en charge, est la 1.9.
4. Cassandra-opérateur de Rook
- Github
- Volonté: Alpha
- Licence: Apache 2.0
- Mis en œuvre en: Golang
Un opérateur dont le développement ne va pas aussi vite que nous le souhaiterions. Il a une structure CRD bien pensée pour gérer le cluster, résout le problème de l'identification des nœuds en utilisant Service avec ClusterIP (le même "hack") ... mais pour l'instant c'est tout. Il n'y a pas de surveillance et de sauvegardes prêtes à l'emploi pour l'instant (au fait, nous avons
commencé à nous surveiller). Un point intéressant est qu'en utilisant cet opérateur, vous pouvez également déployer ScyllaDB.
NB: Nous avons utilisé cet opérateur avec des modifications mineures dans l'un de nos projets. Il n'y a eu aucun problème dans le travail de l'opérateur pendant toute l'opération (~ 4 mois de fonctionnement).5. CassKop par Orange
- Github
- Volonté: Alpha
- Licence: Apache 2.0
- Mis en œuvre en: Golang
Le plus jeune opérateur de la liste: le premier commit a été effectué le 23 mai 2019. Déjà, il a dans son arsenal un grand nombre de fonctionnalités de notre liste, dont plus de détails peuvent être trouvés dans le référentiel du projet. L'opérateur est basé sur le populaire operator-sdk. Prend en charge la surveillance prête à l'emploi. La principale différence avec les autres opérateurs est l'utilisation du
plugin CassKop , implémenté en Python et utilisé pour la communication entre les nœuds Cassandra.
Conclusions
Le nombre d'approches et d'options possibles pour porter Cassandra vers Kubernetes parle de lui-même: le sujet est en demande.
À ce stade, vous pouvez essayer l'une des solutions ci-dessus à vos risques et périls: aucun des développeurs ne garantit le travail à 100% de leur solution dans l'environnement de production. Mais maintenant, de nombreux produits semblent prometteurs d'essayer de les utiliser dans les stands de développement.
Je pense qu'à l'avenir, cette femme sur le navire devra partir!
PS
Lisez aussi dans notre blog: