Photo de Dugan Arnett sur Boston Globe
Êtes-vous toujours à la recherche d'un nouvel appartement? Prêt à faire la dernière tentative? Si oui, suivez-moi et je vous montrerai comment atteindre la ligne d'arrivée.
Brève introduction et références
Il s'agit de la troisième partie du cycle visant à expliquer comment trouver l'appartement optimal sur le marché immobilier. En quelques mots, l'idée principale - trouver la meilleure offre parmi les appartements à Iekaterinbourg, où j'habitais auparavant. Mais je pense que la même idée peut être envisagée dans le contexte d'une autre ville.
Si vous n'avez pas lu les parties précédentes, ce serait une bonne idée de les lire les parties 1 et 2 .
Vous pouvez également trouver des blocs-notes Ipython là- bas .
Cette partie devait être beaucoup plus courte que les précédentes, mais le diable est dans les détails.
Conséquences
À la suite de toutes les actions, nous avons obtenu un modèle ML (Random Forest) qui fonctionne assez bien. Pas aussi bon que prévu (le score est supérieur à 87%), mais pour des données réelles, c'est assez bon. Et ... permettez-moi d'être honnête, cette réflexion sur le résultat a eu un effet étrange sur moi. Je voulais plus de score, l'écart entre le résultat attendu et la vraie prédiction était inférieur à 3%. L'optimisme mélangé à la cupidité est monté dans ma tête

Je veux plus or précision
C'est bien connu, si vous voulez améliorer quelque chose, il y aura probablement des approches opposées. Habituellement, cela ressemble à un choix entre:
- Evolution vs révolution
- Quantité vs qualité
- Extensif vs intensif
Et en raison d'un manque de volonté de changer de cheval en cours de route, j'ai décidé d'utiliser RF (Random Forest) avec l'ajout de quelques nouvelles fonctionnalités.
Cela semblait être une idée, "nous avons juste besoin de plus de fonctionnalités" pour améliorer le score. C'est du moins ce que je pensais.
Per aspera ad astra (à travers les difficultés des étoiles)
Essayons de réfléchir aux fonctionnalités connexes, qui pourraient influencer le prix d'un appartement. Il y a des caractéristiques d'appartement comme un balcon ou l'âge de la maison et des caractéristiques géo-liées comme la distance à la station de métro / bus la plus proche. Quelle pourrait être la prochaine approche pour la même approche avec RF?
Idée n ° 1. Distance au centre
Nous pourrions réutiliser la longitude et la latitude (coordonnées plates). Sur la base de ces informations, nous avons pu compter la distance au centre de la ville. La même idée a été utilisée pour les quartiers, plus nous nous situons loin du centre, moins cher cela devrait être. Et devinez quoi ... ça marche! Pas une si grosse croissance ( + 1% de score), mais c'est mieux que rien.
Un seul problème est là, la même idée n'a pas de sens pour les quartiers qui sont très loin. Si vous habitez en dehors d'une ville, vous pouvez savoir qu'il existe d'autres règles de prix.
Il ne sera pas facile d'interpréter si nous extrapolons cette approche.
Idée n ° 2. Près du métro
Le métro a une influence significative sur les prix. Surtout quand il est placé dans une zone de distance de marche. Mais la signification de "une distance de marche" n'est pas claire. Chaque personne peut interpréter ce paramètre de différentes manières. Je pourrais définir la limite manuellement, mais une augmentation du score ne dépasserait pas 0,2%
En même temps, cela ne fonctionne pas avec le plat de l'idée précédente. Il n'y a pas de métro à proximité.
Idée n ° 3. Rationalité et équilibre du marché
L'équilibre du marché est une combinaison de demande et d'offre. Adam Smith en a parlé. Bien sûr, le marché peut être exagéré. Mais en général, cette idée fonctionne bien. Au moins pour les maisons en cours de construction.
En d'autres termes - plus vous avez de concurrents, moins vous avez de chances d'acheter votre appartement (toutes choses étant égales par ailleurs). Et cela produit une supposition - "si autour de moi sont placés d'autres appartements, je dois diminuer le prix pour obtenir plus d'acheteurs".
Et cela ressemble à une conclusion tout à fait logique, n'est-ce pas?
J'ai donc compté des appartements SIMILAIRES près de chacun d'eux, dans la même maison et dans un rayon de 200 mètres. Les mesures ont été prises pour la date de vente. Quel résultat espérez-vous obtenir? Seulement 0,1% sur la validation croisée. Triste mais vrai.
Repenser
Quitter, c'est ... parfois faire un pas en arrière pour faire deux pas en avant.
- un sage inconnu
D'accord, une attaque frontale ne fonctionne pas. Considérons cette situation sous un autre angle.
Supposons que vous soyez une personne qui veut acheter un appartement près d'une rivière loin de la ville bruyante. Vous avez trois variantes de publicité qui se ressemblent et ont le même prix (plus ou moins). Les métriques formelles qui décrivent flat ne vous donnent rien sur l'environnement, ce ne sont que des métriques sur un écran. Mais il y a quelque chose d'important.
La description d'un appartement est une formidable opportunité.
Une description plate pourrait fournir tout ce dont vous avez besoin. Cela pourrait vous raconter une histoire d'appartement, de voisins et d'incroyables opportunités liées à ce lieu de vie spécifique. Et parfois, une description pourrait avoir plus de sens que des chiffres ennuyeux.
Mais dans la vraie vie, c'est légèrement différent de nos attentes. Permettez-moi de vous montrer ce qui fonctionnera / ne fonctionnera pas et pourquoi.
Qu'est-ce qui ne fonctionnera pas et pourquoi?
Attentes - "Whoa! Je peux essayer de classer le texte et trouver les" bons "et les" mauvais "appartements. J'utiliserai la même méthode que celle utilisée habituellement pour l'analyse des sentiments."
Réalité - "Non, vous ne le ferez pas. Les gens n'écrivent rien de mal contre leur appartement. Il peut y avoir une dissimulation sur une situation réelle ou un mensonge"
Attentes - "D'accord. Ensuite, je peux essayer de trouver des modèles et de trouver le public cible d'un appartement. Par exemple, il pourrait s'agir de personnes âgées ou d'étudiants".
Réalité - "Non, vous ne le ferez pas. Parfois, une annonce mentionne différents âges et groupes sociaux, c'est juste du marketing"
Qu'est-ce qui fonctionnerait probablement et pourquoi
Quelques mots - clés - Il y a des mots qui indiquent des choses ou des moments spécifiques liés à l'appartement. Par exemple, quand c'est un studio, le prix serait plus bas. En général, les verbes sont inutiles, mais les noms et adverbes peuvent donner plus de contexte.
La source alternative d'information - Utiliser la description pour remplir des valeurs vides ou NaN plus correctes. Parfois, la description contient plus d'informations que les caractéristiques formelles de la publicité.
Je le soupçonne basé sur la paresse humaine de remplir des champs non obligatoires comme "balcon". Tout mettre dans la description semble être une idée plus préférable
Je saute la description du processus typique de tokenisation / lemmatisation / stemming. De plus, je crois qu'il y a des auteurs capables de le décrire mieux que moi.
Bien que je pense qu'il devrait y avoir une mention de l'ensemble d'outils utilisé pour extraire les fonctionnalités. En bref, cela ressemble.

séparation-> correspondance par partie du discours
Après le prétraitement du texte publicitaire, j'ai reçu un ensemble de mots russes comme ceux-ci.

Le texte original est placé https://pastebin.com/Pxh8zVe3
J'ai essayé d'utiliser l'approche de Word2Vec, mais il n'y avait pas de dictionnaire spécial pour les appartements et les publicités, donc l'image générale semblait bizarre
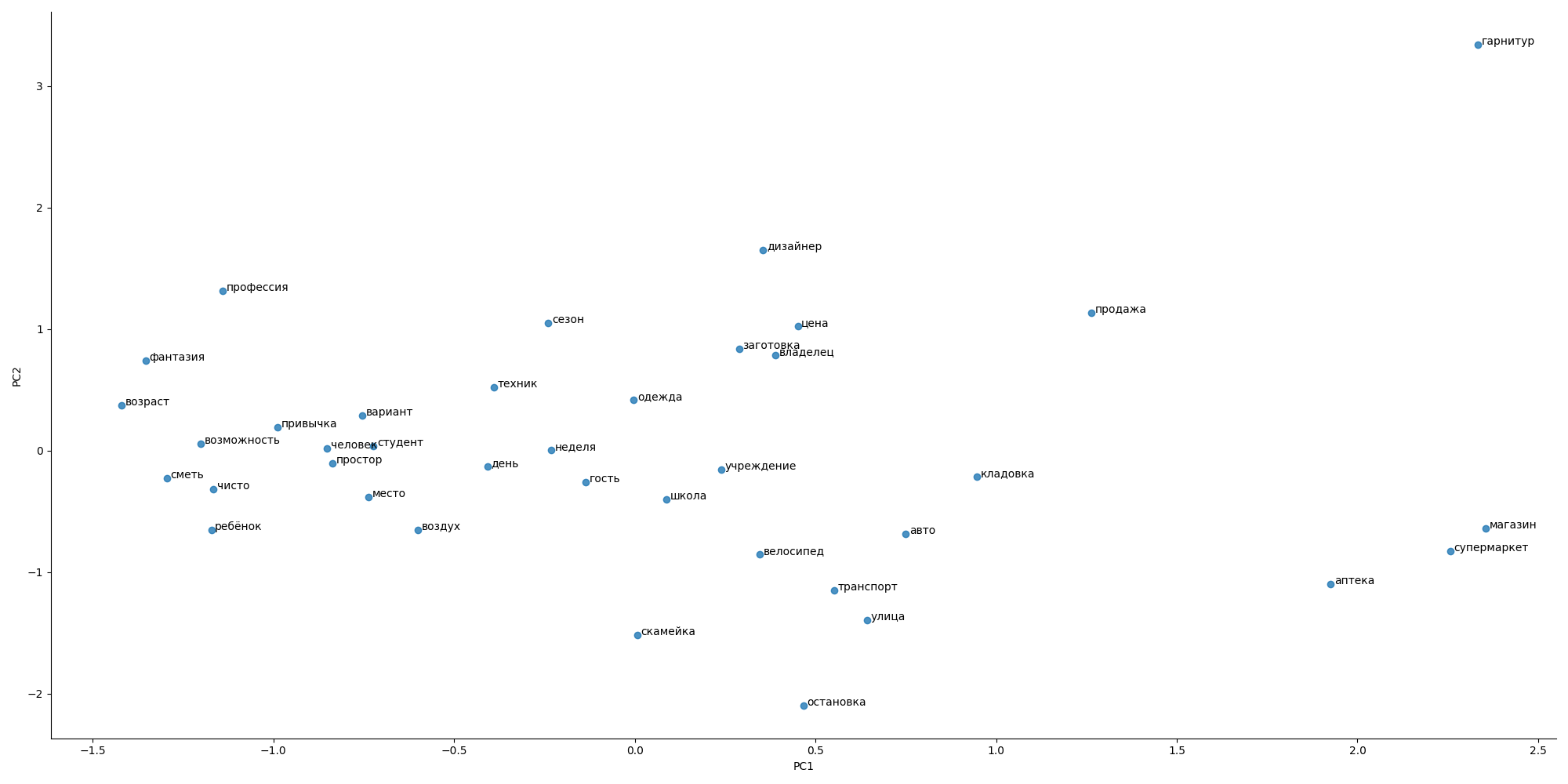
la distance entre les mots ne correspond pas aux attentes
Par conséquent, je l'ai gardé aussi simple que possible et j'ai décidé de créer plusieurs nouvelles colonnes pour l'ensemble de données
Un peu moins de conversation, un peu plus d'action
Il est temps de se salir les mains et de faire des choses pratiques. Découvrez de nouvelles fonctionnalités. Plusieurs facteurs importants ont été séparés par une influence sur les prix.
impact positif
- meubles - parfois, les gens pouvaient laisser un lit, une machine à laver, etc.
- luxe - appartements avec des choses luxueuses comme un jacuzzi ou un intérieur exclusif
- contrôle vidéo - il permet aux gens de se sentir en sécurité, souvent il le considère comme un avantage
impact négatif
- dortoir - oui, parfois c'est un appartement dans un dortoir. Pas si populaire, mais nettement moins cher qu'un appartement moyen
- rush - lorsque les gens se précipitent pour vendre leur appartement, ils sont généralement prêts à baisser les prix.
- studio - comme je l'ai déjà dit - ils sont moins chers que leurs appartements-analogues.
Collectons-les dans quelque chose d'universel
df3 = pd.read_csv('flats3.csv') positive_impact = ['', 'luxury',''] negative_impact = ['studio', 'rush','dorm'] geo_features = ['metro','num_of_stops_1km','num_of_shops_1km','num_of_kindergarden_1km', 'num_of_medical_1km','center_distance'] flat_features=['total_area', 'repair','balcony_y', 'walls_y','district_y', 'age_y'] competitors_features = ['distance_200m', 'same_house'] cols = ['cost'] cols+=flat_features cols+=geo_features cols+=competitors_features cols+=positive_impact cols+=negative_impact df3 = df3[cols]
impact général
c'est juste une combinaison de caractéristiques négatives et positives. Initialement, pour chaque appartement, il est égal à 0. Par exemple, un studio avec contrôle vidéo aura toujours un impact général égal à 0 ( 1 [positif] –1 [négatif] = 0 )
df3['impact'] = 0 for i, row in df3.iterrows(): impact = 0 for positive in positive_impact: if row[positive]: impact+=1 for negative in negative_impact: if row[negative]: impact-=1 df3.at[i, 'impact'] = impact
D'accord, nous avons des données, de nouvelles fonctionnalités et un ancien objectif avec 10% d'erreur moyenne pour la prédiction. Faites une opération typique comme nous l'avons fait auparavant
y = df3.cost X = df3.drop(columns=['cost']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Ancienne approche (croissance extensive des fonctionnalités)
Nous allons faire un nouveau modèle basé sur de vieilles idées
data = [] max_features = int(X.shape[1]/2) for x in range(1,20): regressor = RandomForestRegressor(verbose=0, n_estimators=128, max_features=max_features, max_depth=x, random_state=42) model = regressor.fit(X_train, y_train) score = do_cross_validation(X, y, model) data.append({'max_depth':x,'score':score}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="score", data=data) max_result = data.loc[data['score'].idxmax()] ax.set_title(f'Max score - {max_result.score}\nDepth {max_result.max_depth} ')
Et le résultat était légèrement ... inattendu.
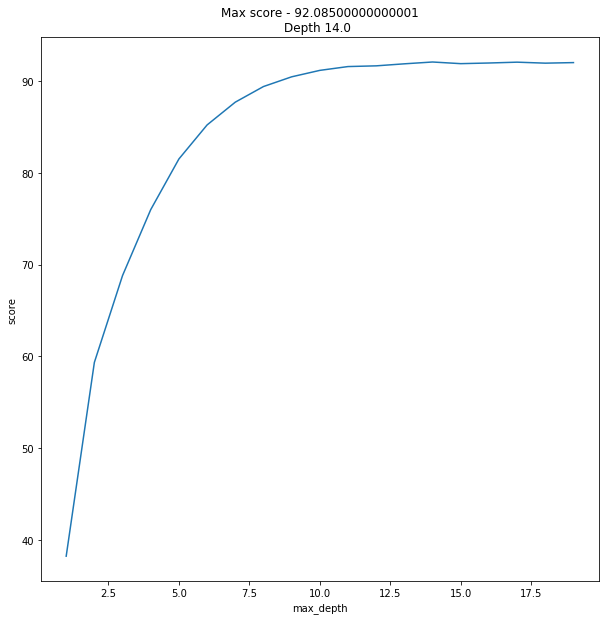
92% est un résultat accablant. Je veux dire, dire que j'ai été choqué serait un euphémisme.
Mais pourquoi ça a si bien fonctionné? Jetons un œil aux nouvelles fonctionnalités.
regressor = RandomForestRegressor(random_state=42, max_depth=max_result.max_depth, n_estimators=128, max_features=max_features) rf3 = regressor.fit(X_train, y_train) feat_importances = pd.Series(rf3.feature_importances_, index=X.columns) feat_importances.nlargest(X.shape[1]).plot(kind='barh')
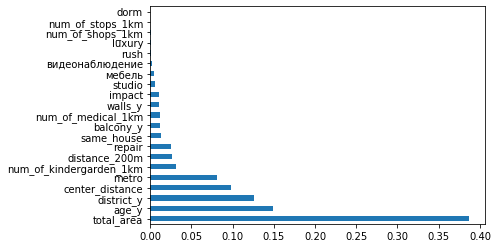
Importance de toutes les fonctionnalités de notre modèle
L'importance ne donne pas d'informations sur la contribution des fonctionnalités (c'est une autre histoire), elle montre seulement comment le modèle actif utilise l'une ou l'autre fonctionnalité. Mais pour la situation actuelle, cela semble instructif. Certaines des nouvelles fonctionnalités sont plus importantes que les précédentes, d'autres presque inutiles.
Nouvelle approche (travail intensif avec les données)
Et bien ... la ligne d'arrivée est franchie, le résultat est atteint. Cela pourrait-il être mieux?
Réponse courte - "Oui, c'est possible"
- Tout d'abord, nous pourrions réduire la profondeur d'un arbre. Cela réduira également le temps de formation et de prévision.
- Deuxièmement, nous pourrions augmenter un peu le score de prédiction.
Pour les deux moments, nous utiliserons XGBoost . Parfois, les gens préfèrent utiliser d'autres boosters comme LightGBM ou CatBoost , mais mon humble avis - le premier est assez bon lorsque vous avez beaucoup de données, un second est meilleur si vous travaillez avec des variables catégorielles. Et en bonus - XGBoost semble juste plus rapide
from xgboost import XGBRegressor,plot_importance data = [] for x in range(3,10): regressor = XGBRegressor(verbose=0, reg_lambda=10, n_estimators=1000, objective='reg:squarederror', max_depth=x, random_state=42) model = regressor.fit(X_train, y_train) score = do_cross_validation(X, y, model) data.append({'max_depth':x,'score':score}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="score", data=data) max_result = data.loc[data['score'].idxmax()] ax.set_title(f'Max score-{max_result.score}\nDepth {max_result.max_depth} ')

Le résultat est meilleur que le précédent.
Bien sûr, c'est la petite différence entre Random Forest et XGBoost. Et chacun d'eux pourrait être utilisé comme un bon outil pour résoudre notre problème de prédiction. Cela dépend de vous.
Conclusion
Le résultat est-il atteint? Certainement oui.
La solution est disponible sur place et peut être utilisée gratuitement par n'importe qui. Si vous êtes intéressé par l'évaluation d'un appartement en utilisant cette approche, n'hésitez pas et contactez-moi.
Comme prototype, il y est placé
Merci d'avoir lu! .