
Salut, Habr. Récemment, il y a eu une compétition entre Tinkoff et McKinsey. Le concours s'est déroulé en deux étapes: la première - qualificative, au format kaggle, c'est-à-dire envoyer des prédictions - obtenir une évaluation de la qualité de la prédiction; le gagnant est celui qui obtient le meilleur score. Le second est le hackathon sur place à Moscou, qui accueille les 20 meilleures équipes de la première étape. Dans cet article, je parlerai de l'étape de qualification, où j'ai réussi à prendre la première place et à gagner le MacBook. L’équipe du classement s’appelait «les enfants de Lesha».
Le concours s'est déroulé du 19 septembre au 12 octobre. J'ai commencé à résoudre exactement une semaine avant la fin et j'ai décidé presque à plein temps.
Brève description du concours:
En été, des histoires sont apparues sur l'application bancaire Tinkoff (comme sur Instagram). Sur l'histoire, vous pouvez réagir comme, ne pas aimer, sauter ou voir jusqu'à la fin. La tâche consiste à prédire la réaction de l'utilisateur à l'histoire.
Le concours est principalement tabulaire, mais les histoires elles-mêmes contiennent du texte et des images.
Plan de l'histoire

Métrique
La prévision de la réaction peut prendre une valeur de -1 à 1 inclus - plus elle est proche de 1, plus la probabilité d'obtenir un équivalent est élevée. Et avec une valeur de -1, il est préférable de retirer cette histoire aux yeux de l'utilisateur.
Pour vérifier la précision des solutions, une formule est utilisée, normalisée au résultat maximum possible:
\ begin {array} {l} {\ text {weight (event)} = \ left \ {\ begin {array} {ll} {- 10} & {\ text {dislike}} \\ {-0.1} & {\ text {skip}} \\ {0.1} & {\ text {view}} \\ {0.5} & {\ text {like}} \ end {array} \ right.} \\ [15pt] {\ text {Métrique} \ left (y _ {\ text {pred}} \ right) = \ sum_ {i = 1} ^ {n} \ left (\ text {weight} \ left (\ text {event} _ {i} \ droite) \ cdot y _ {\ text {pred,} i} \ droite)} \ end {array}
Quelles données sont là:
- Informations utilisateur de base
- Transactions utilisateur
- Informations sur l'histoire (json à partir de laquelle vous pouvez le construire)
- Historique des réactions des utilisateurs aux histoires.
Ensuite, je parlerai en détail de chaque élément de données, de la façon dont je les ai traitées et des fonctionnalités (ci-après dénommées fonctionnalités) que j'ai extraites.

ce qui est à l'origine:
- identifiant utilisateur
- produits bancaires anonymes que l'utilisateur a ouverts (OPN), utilise (UTL) ou fermés (CLS)
- sexe, âge binarisé, état matrimonial, première entrée dans l'application
- job_title - ce que les gens écrivent sur eux-mêmes
- job_position_cd - titre d'emploi d'une personne, comme l'une des 22 catégories
en tant que fonctionnalités, nous utilisons tout ce qui précède, sauf job_title, car nous supposons que job_position_cd décrit normalement la position d'une personne.
Les transactions

ce qui est à l'origine:
- identifiant utilisateur
- jour, mois de transaction
- montant de la transaction (binarisé par incréments de 250)
- merchant_id - identifiant bancaire interne de la caisse enregistreuse. De plus non utilisé.
- merchant_mcc
MCC - Code de catégorie de marchand. Il s'agit du code de service standardisé fourni par le destinataire. Cette information est ouverte, voici une transcription . Ces codes peuvent être commodément divisés en catégories, par exemple: divertissement, hôtels, etc.
Pour chaque customer_id, nous comparons les fonctionnalités suivantes:
- calculer le montant des dépenses, le chèque moyen, l'écart type
- nombre de transactions
- Nous divisons les codes mcc en 20 catégories, calculons combien de personnes ont dépensé de l'argent pour cette catégorie. Obtenez 20 fonctionnalités
- nous obtiendrons 20 autres fonctionnalités en divisant les dépenses de la catégorie par le montant des dépenses. C'est-à-dire obtenir le pourcentage d'argent dépensé sur la catégorie.
Histoires
Au total, nous avons 959 histoires.
ce qui est à l'origine:
json ressemble à ceci:

Il s'agit d'un arbre d'éléments, où chaque élément est décrit par des clés: ['guid', 'type', 'description', 'properties', 'content']. Le «contenu» contient une liste d'enfants. L'histoire se compose de pages. Le fond, le texte, les images sont projetés sur la page. Nous n'avions pas de constructeur d'histoires, et dessiner tout cela est plutôt difficile et non un fait, ce qui nous sera très utile à l'avenir.
Les habitués retirent tout le texte et la taille de police correspondante. Nous extrayons les fonctionnalités suivantes:
- nombre de pages, liens, éléments totaux
- taille moyenne de la police du texte
- nombre d'éléments de texte
- "volume de texte" est une heuristique permettant de considérer attentivement la longueur du texte en fonction de la taille de la police.
Code de comptage de volumedef get_text_amount(all_text, font_sizes): assert len(all_text) == len(font_sizes) lengths = np.array(list(map(len, all_text))) sizes = (np.array(font_sizes) / 100)**2 return (lengths * sizes).sum()
- Prenons maintenant le texte entier, en utilisant dostoevsky, nous définissons la sémantique du texte: ['neutre', 'négatif', 'saut', 'parole', 'positif']. Et ajoutez cela comme 5 fonctionnalités
Les réactions

ce qui est à l'origine:
- ID utilisateur et historique
- le temps
- réaction
Nous traitons le temps et ajoutons des fonctionnalités en tant que fonctionnalités:
- jour de la semaine
- heure, minute
Ensuite, un groupe de fonctionnalités sera ajouté en fonction des données sur les réactions, mais pour l'instant, nous allons nous battre avec cet arsenal de fonctionnalités pour faire une ligne de base.
La meilleure approche utilisée par l'ensemble du sommet est la suivante: nous réduisons le problème à une classification multiclasse, c'est-à-dire prédire la probabilité de chaque réaction. Nous considérons l'attente d'une évaluation pour cette histoire :
Binariser :
- notre réponse pour l'objet qui peut prendre de la valeur
Modèle
Du début à la fin, j'ai utilisé CatBoost. Cela est dû au fait que CatBoost crée des statistiques utiles pour les fonctionnalités catégorielles. Et les statistiques sur l'utilisateur - à quel point il est enclin à quelles réactions, et les statistiques sur l'historique - comment ils ne réagissent pas le plus souvent, sont les fonctionnalités les plus puissantes de cette tâche.
Le fonctionnement de CatBoost avec les fonctionnalités catégorielles est bien expliqué dans la documentation .
TLDR:
- génère plusieurs permutations de données
- va dans l'ordre et construit l'encodage cible moyen (mte) sur les objets qu'il a déjà vu
brièvement sur mte dans notre exemplenous prenons la valeur du signe, par exemple, l'un de customer_id, nous considérons le pourcentage de cas où ce client a réagi comme, n'aime pas, a sauté ou vu. Nous obtenons 4 numéros. Nous remplaçons customer_id par ces 4 chiffres et les utilisons comme signes. Nous le faisons pour chaque customer_id.
Résultat actuel
Avec les fonctionnalités actuelles, avec un catbust non optimisé, dans le classement public à ce moment-là, j'ai pris la 11e place avec un résultat de 0,31209
Caractéristiques de tueur
À un moment donné, une hypothèse est apparue selon laquelle l'application peut afficher des histoires plus souvent ou moins selon la façon dont l'utilisateur y a réagi plus tôt. Ajoutons ensuite des fonctionnalités qui diront:
- combien de fois l'utilisateur a vu l'historique correspondant dans le passé / futur, au cours du mois / jour / heure / total
- temps depuis le dernier visionnement de la même histoire
- temps après lequel l'utilisateur la prochaine fois regarde la même histoire
- en fait, l'utilisateur charge plusieurs histoires à la fois en une seconde, généralement autour de 5-7. Appelez cet ensemble d'histoires un groupe . J'ai ajouté ce nombre d'histoires dans le groupe en tant que fonctionnalité, ce qui a donné une grande augmentation de la qualité.
Bien sûr, ces fonctionnalités ne peuvent pas être utilisées en production, car ils ne seront pas ringards au moment de l'application du modèle, mais en compétition tous les moyens sont bons.
Ainsi, il est dit - fait. A obtenu 0,35657 au classement.
Optimisation du modèle
J'ai parcouru les paramètres en utilisant l'optimisation bayésienne
Parmi les éléments intéressants, nous pouvons mentionner le paramètre max_ctr_complexity, qui est responsable du nombre maximal de caractéristiques catégorielles pouvant être combinées. Exemple sous le spoiler.
Extrait de la documentationSupposons que les objets de l'ensemble d'apprentissage appartiennent à deux caractéristiques catégorielles: le genre musical («rock», «indie») et le style musical («dance», «classique»). Ces fonctionnalités peuvent apparaître dans différentes combinaisons. CatBoost peut créer une nouvelle fonctionnalité qui est une combinaison de celles répertoriées («dance rock», «rock classique», «dance indie» ou «indie classique»).
Observations intéressantes
CatBoost peut être formé sur le GPU, ce qui accélère considérablement l'apprentissage, mais introduit également de nombreuses restrictions, en particulier en ce qui concerne les fonctionnalités catégorielles. Dans cette tâche, la formation sur le GPU a donné un résultat bien pire que sur le CPU.
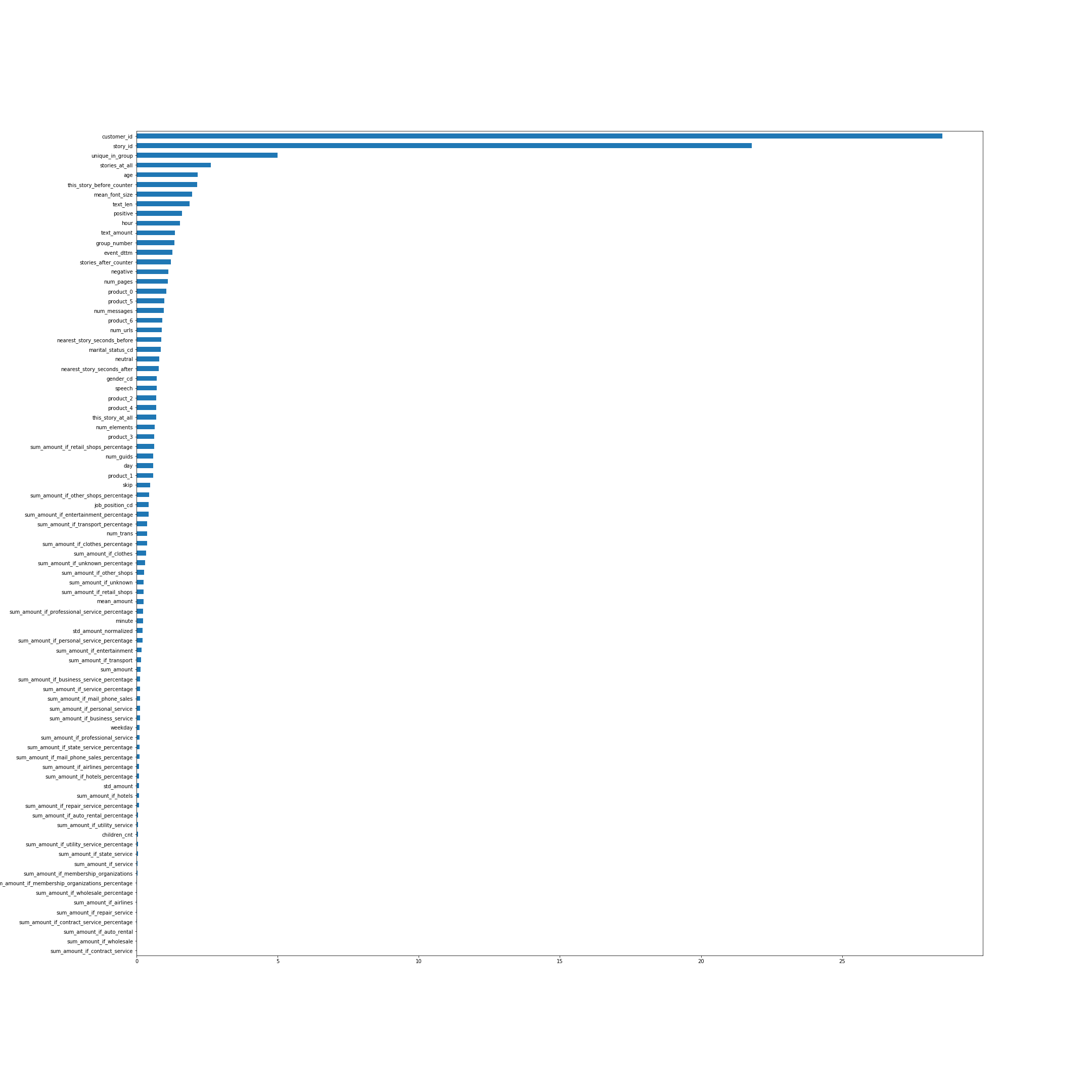
L'importance des fonctionnalités selon CatBoost. À bien des égards, les noms des fonctionnalités parlent d'eux-mêmes, mais certains, pas les plus évidents d'en haut, je vais expliquer:
- unique_in_group - le nombre d'histoires dans le groupe. (Dans le groupe, ils sont toujours uniques, juste au moment où la fonctionnalité a été créée, je ne le savais pas)
- stories_at_all - le nombre d'histoires qu'une personne a vues dans le futur et dans le passé.
- this_story_before_counter - combien de fois les gens ont déjà regardé cette histoire.
- text_amount - cette heuristique avec le volume de texte.
- group_number - numéro de série du groupe.
- Near_story_seconds_before / After - c'est essentiellement le temps jusqu'à ce que le prochain groupe soit affiché.
L'image est cliquable.
Regardons la répartition des réactions dans le temps:

C'est-à-dire à un moment donné, la distribution des réactions varie considérablement.
Ensuite, je veux obtenir une confirmation que la distribution sur le test est la même qu'à la fin de l'échantillon de formation. Envoyons comme prédiction tous ceux-là, on obtient le résultat 0,00237. Nous prédisons tous ceux de la dernière partie du train - nous obtenons environ 0,009, sur la première partie - environ -0,22. La distribution sur le test est donc probablement la même qu'à la fin du train et ne ressemble certainement pas à la partie principale. Cela donne lieu à l'hypothèse que si la distribution est corrigée dans nos prévisions, le résultat dans le classement s'améliorera considérablement, car les distributions sur le train et sur le test sont différentes.
Prédictions Threshhold
À la dernière étape de l'obtention des prédictions finales, ajoutez un thrashhold:
Dans le dernier modèle, j'avais environ 66% d'unités, si binarisé avec une poubelle égale à 0. Il s'est avéré qu'en effet, une diminution du nombre de +1 a donné une forte augmentation de la qualité. Seuls les 3 derniers locaux ont été évalués, j'ai donc envoyé les prédictions du meilleur modèle avec différentes poubelles afin que le pourcentage plus un soit d'environ 62, 58 et 54.
Par conséquent, dans un classement public, mon meilleur résultat était de 0,37970 .
Résultats du concours
à propos du classement public / privéComme d'habitude dans les compétitions d'apprentissage automatique, lorsque vous envoyez des prédictions au système, le résultat n'est évalué que pour une partie de l'échantillon de test entier. Habituellement, environ 30%. Les résultats de cette partie sont reflétés dans le classement public. Pour le reste du test, le résultat final est évalué, qui est affiché après la fin de la compétition sur un classement privé.
A l'issue du concours au classement public, la situation était la suivante:
- 0.382 - HereCould BeYourAdvertising
- 0,379 - Les enfants de Lesha
- 0,372 - Jardiniers
- 0,35 - paresseux et akulov
Sur un classement privé, selon lequel les résultats finaux ont été pris en compte, j'ai eu de la chance et les gars, pour une raison quelconque, sont passés de la quatrième à la quatrième place. Voici la position finale.
- 0,45807 enfants de Lesha
- 0.45264 Jardiniers
- 0.44136 Zhuk
- 0.43704 HereCould BeYourAdvertising
- 0,43474 paresseux et akulov
Ce qui n'a pas fonctionné
- J'ai essayé de traduire tout le texte de l'histoire en un vecteur à l'aide de texte rapide, puis j'ai regroupé les vecteurs et j'ai utilisé le numéro de cluster comme caractéristique catégorielle. Cette fonctionnalité figurait dans le top 3 (après story_id et customer_id) pour l'importance des fonctionnalités de CatBoost, mais pour une raison quelconque, elle était stable et aggravait considérablement le résultat de la validation.
- Grâce aux clusters, on a pu trouver des histoires liées à la Coupe du Monde et qui n'étaient présentes que dans le set d'entraînement.
Cependant, l'éjection de ces objets du jeu de données n'a pas amélioré le résultat. - par défaut, CatBoost génère des permutations aléatoires d'objets et prend en compte les signes des caractéristiques catégorielles en fonction de ceux-ci. Mais nous pouvons dire au katbust que nous avons du temps dans les données - has_time = True. Ensuite, il se déroulera dans l'ordre, sans mélanger l'ensemble de données. Dans ce problème, malgré le fait que nous ayons du temps, le résultat avec has_time était de façon stable pire.
Dans le cas général, s'il reste du temps, mais que cela ne doit pas être pris en compte lors de la construction du codage cible moyen, le modèle utilisera des informations sur les bonnes réponses du futur et pourra se recycler. Dans ce problème, apparemment, cela n'a pas eu beaucoup d'effet et il était plus important de répéter plusieurs fois dans différentes permutations. - Il y avait une idée pour attribuer plus de poids aux objets à la fin du train, c'est-à-dire de prendre en compte plus d'objets avec la bonne répartition des réactions. Mais à la fois sur la validation et sur le classement public, cela a donné un résultat pire.
- Vous pouvez prendre en compte différentes réactions avec différents poids pendant l'entraînement. Même si cela ne s'est pas amélioré pour moi, cela a aidé certaines équipes.
Conclusions
Le concours s'est avéré intéressant, car il rassemblait de nombreux éléments, tels que des données tabulaires, des textes et des images. Il y avait beaucoup d'espace pour la recherche, beaucoup de choses qui pouvaient encore être expérimentées. En général, je n'avais pas à m'ennuyer.
Merci aux organisateurs du concours!
Tout le code est affiché sur le github .