Je vous présente la traduction d'un autre rapport de HaxeUp Sessions 2019 Linz , je crois que c'est un bon complément au précédent , car poursuit le thème des changements à Haxe survenus en 2019, ainsi qu'un petit discours sur son avenir.
Un peu sur l'auteur du rapport: Aurel Bili a rencontré Haxe , participant à divers jams de jeu, et il continue d'y participer (par exemple, voici son jeu du dernier Ludum Dare 45 ).

Aurel termine actuellement des études à l'Imperial College de Londres, ce qui implique des stages obligatoires. Le premier stage qu'il a suivi s'est déroulé dans un bureau éloigné, dont la route a pris beaucoup de temps. Il espère donc que la prochaine pratique sera possible à distance.

Il se trouve que la Fondation Haxe n'a pas trouvé pendant longtemps un employé pour le poste de développeur de compilateur. Aurel a décidé de tenter sa chance et a envoyé une lettre demandant un travail à distance. Il a eu de la chance - il a été accepté pour un stage de six mois avec la possibilité de travailler depuis Londres.
Lors de la configuration de l'appareil, la gamme de tâches qu'Aurel va gérer a été convenue (bien que tout n'ait pas finalement été réalisé).

Qu'a-t-il fait?
Tout d'abord, la documentation , qui était dans un triste état: tous les changements de syntaxe, les nouvelles fonctionnalités du langage et du compilateur ont été décrits, des sections sur les chaînes, les littéraux et les constantes ont été complétées.
Toute la documentation a été traduite de LaTeX vers Markdown !
Deuxièmement, le formatage du code de la bibliothèque standard a été amené à un seul style (puisque différentes personnes avec différents styles de conception de code y ont travaillé pendant plus de 10 ans). Ainsi, dans le référentiel du compilateur Haxe, Aurel a pris la septième place dans le nombre de lignes de code ajoutées :)
Troisièmement, Aurel a également travaillé sur la bibliothèque et le compilateur standard:
Par exemple, le conteneur Map a une nouvelle méthode clear() qui supprime toutes les valeurs stockées. Cela a été fait principalement pour la commodité de travailler avec des conteneurs créés comme variables final (c'est-à-dire qu'ils ne peuvent pas être affectés d'une nouvelle valeur, mais ils peuvent être modifiés):
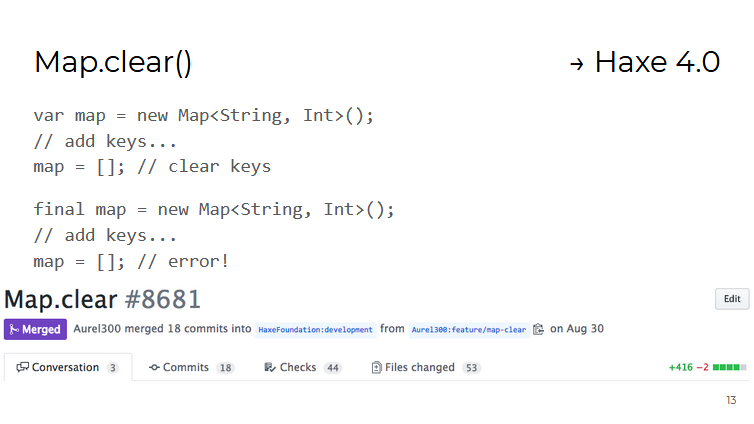
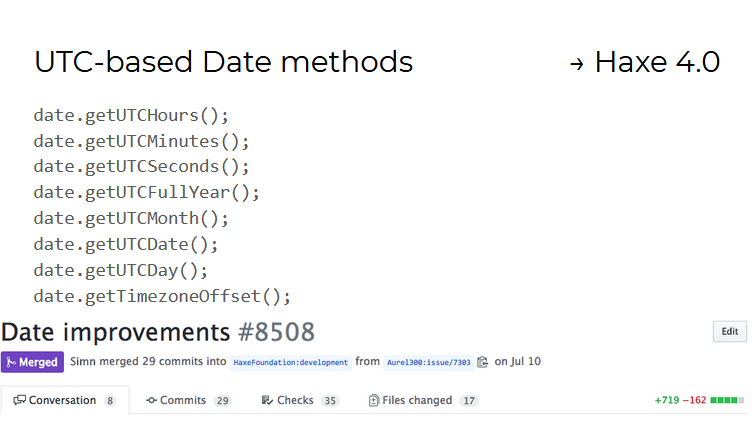
Pour les objets de type Date , des méthodes de travail avec des dates au format UTC (Universal Universal Time) sont apparues. Leur travail a montré à quel point il est difficile de mettre en œuvre une seule API qui fonctionne de manière égale sur les 11 langues / plates-formes prises en charge par Haxe.
Dans l'ancien compilateur, les définitions et les balises META étaient définies sur OCaml, mais maintenant elles sont décrites au format JSON, ce qui devrait simplifier leur analyse par des utilitaires externes (par exemple, pour générer automatiquement de la documentation):

Vous pouvez également remarquer que sur les grands projets, le serveur de compilation commence à utiliser beaucoup de mémoire.
Pour résoudre ce problème, Simon Kraevsky et Aurel ont développé le format binaire hxb, qui est utilisé pour sérialiser l'AST typé. Maintenant, le serveur de compilation peut charger le module en mémoire, travailler avec lui jusqu'à ce qu'il soit nécessaire, puis le décharger de la mémoire dans un fichier au format hxb et libérer la mémoire occupée.

La spécification du format hxb est disponible dans un référentiel séparé , et son implémentation actuelle dans le compilateur (avec sérialiseur / désérialiseur) réside dans une branche Haxe distincte . Le travail sur cette fonctionnalité n'est pas encore terminé, et peut-être apparaîtra-t-il dans Haxe 4.1.

Le quatrième et principal objectif du travail d'Aurel pendant le stage était la création d'une nouvelle API de système asynchrone - asys.

La nécessité de sa création est due au fait que l'API existante ne fournit pas de moyens simples pour effectuer des opérations système de manière asynchrone. Par exemple, pour travailler avec des fichiers de manière asynchrone, vous devrez créer un thread distinct dans lequel les opérations requises seront effectuées et contrôler manuellement son état. De plus, l'API actuelle n'a pas toutes les fonctionnalités pour travailler avec les sockets UDP, qui sont dans les bibliothèques standard dans d'autres langues, il n'y a pas de support pour les sockets IPC.

Lors de la création et de la mise en œuvre d'une nouvelle API, de nombreuses questions se posent:
Comment concevoir une API? Peut-être que cela vaut la peine de prendre un exemple existant? Après tout, nous ne voulons pas tout créer à partir de zéro, car cela prendra plus de temps et ne sera peut-être pas du goût du reste de l'équipe et provoquera beaucoup de débats.
Et, comme déjà mentionné, le problème réel pour Haxe est la mise en œuvre d'une API unique pour toutes les plateformes prises en charge.

L'API Node.js. a été choisie comme exemple. Il est bien pensé, prend en charge les fonctions système nécessaires et convient parfaitement à la création d'applications serveur.

Mais en même temps, l'API Node.js est une API Javascript sans typage fort. Par exemple, les fonctions du module fs pour travailler avec le système de fichiers peuvent prendre comme chemins des chaînes ou des objets comme Buffer et même des URL . Et ce n'est pas si bon pour Haxe.

Node.js, à son tour, utilise la bibliothèque libuv écrite en C. Travailler directement avec l'API libuv de Haxe ne serait pas aussi pratique: par exemple, pour renommer le fichier de manière asynchrone, vous devrez également créer des objets comme uv_loop_t (structure de gestion boucle d'événement dans libuv) et uv_fs_t (structure pour décrire une requête au système de fichiers):

En conséquence, les API Node.js et libuv ont été intégrées comme suit (en utilisant l'interpréteur de macros eval et la méthode de rename comme exemple):
- ils ont pris la méthode API de Node.js, l'ont convertie en Haxe, essayant de standardiser les types d'arguments et de se débarrasser des arguments redondants pour Haxe. Par exemple, les arguments de chemin (de type
FilePath ) sont des résumés sur des chaînes:

- puis créé des classeurs OCaml pour cette méthode:

- OCaml et C liés (en utilisant CFFI - C Foreign Function Interface):

- et finalement écrit des C-binders pour appeler les fonctions libuv C depuis OCaml:

De même, cela a été fait pour HashLink et Neko (pour l'instant, l'API asys n'est implémentée que pour ces trois plateformes). Comme vous pouvez le deviner, cela a demandé beaucoup de travail.
Aurel a montré quelques petites applications démontrant le fonctionnement de l'API asys.
Le premier exemple est une démonstration de lecture asynchrone du contenu d'un fichier. Jusqu'à présent, le code appelle explicitement des méthodes pour initialiser libuv ( hl.Uv.init() ) et démarrer le cycle d'application ( hl.Uv.run() ), car le travail sur l'API n'est pas terminé (mais à l'avenir ils seront ajoutés automatiquement):
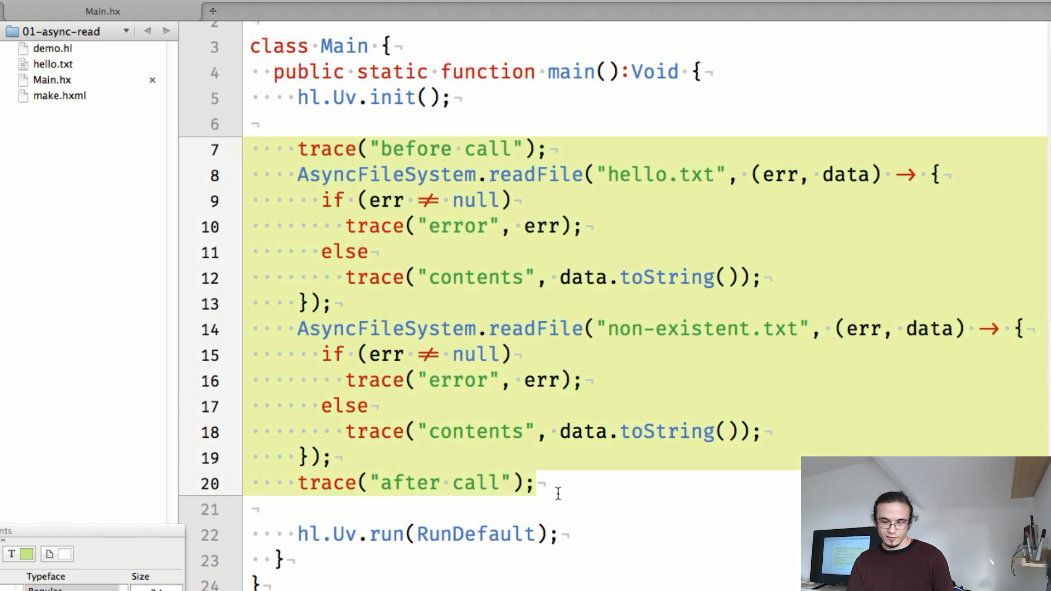
Le résultat du code affiché:
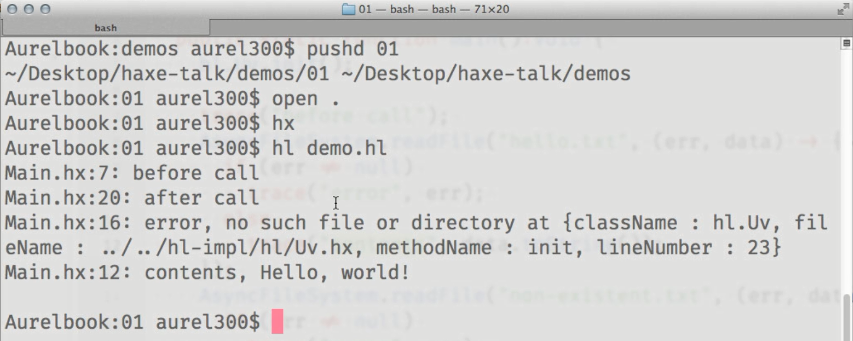
Nous voyons que les résultats des méthodes appelées AsyncFileSystem.readFile() sont affichés dans la console après la trace «après appel», qui est appelée dans le code après avoir essayé de lire le contenu des fichiers.
Le deuxième exemple est une démonstration du fonctionnement asynchrone avec les adresses DNS et IP.
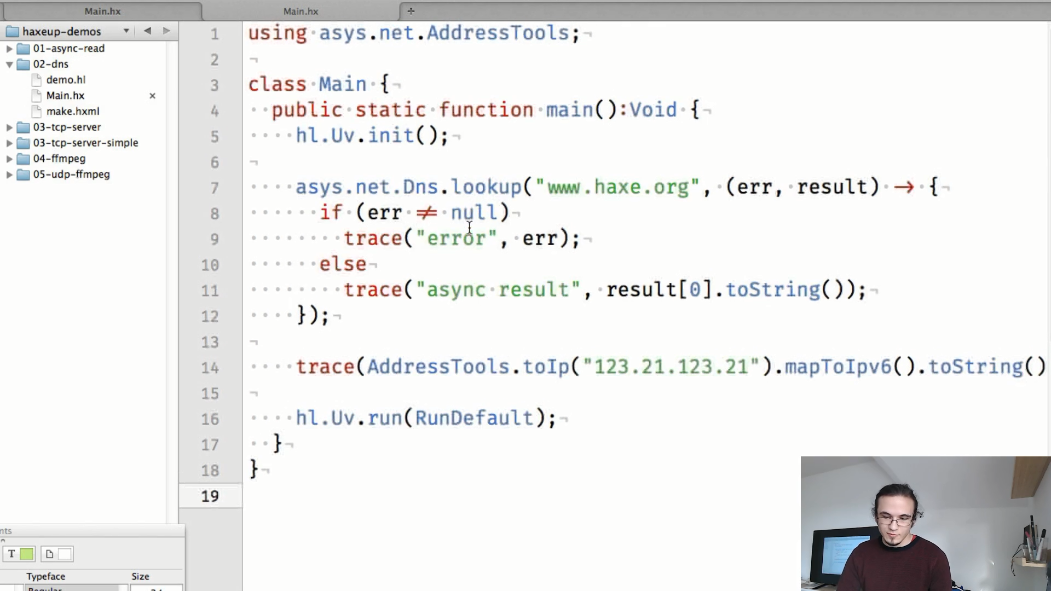
Dans la nouvelle API, il deviendra beaucoup plus facile de déterminer le nom d'hôte, ainsi que les méthodes d'assistance pour travailler avec les adresses IP.
Le troisième exemple est un simple serveur d'écho TCP, qui ne nécessite que trois lignes de code pour créer:

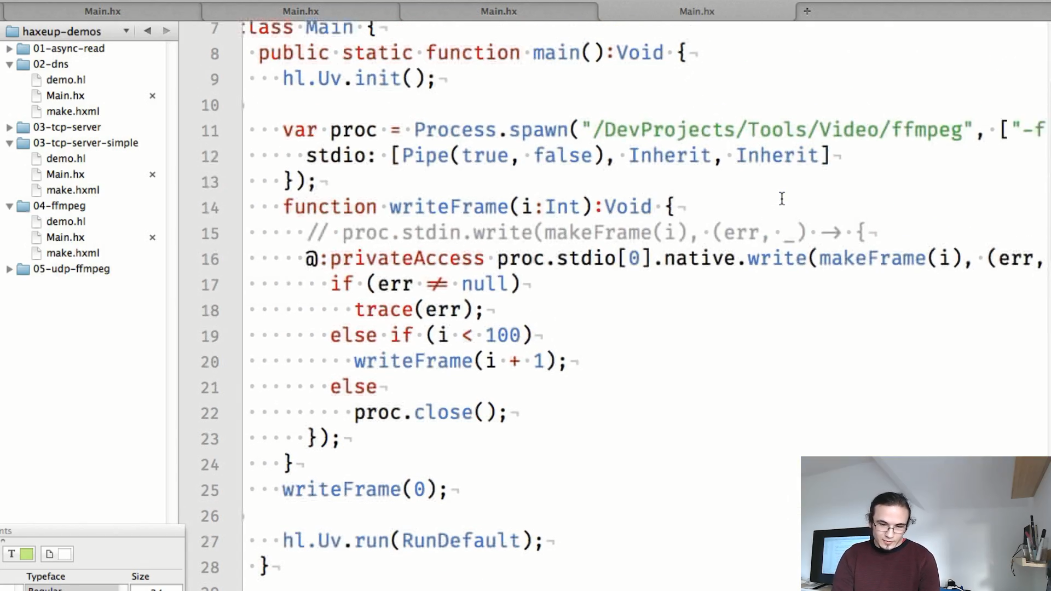
Un quatrième exemple est une démonstration de l'échange d'informations entre processus:
la makeFrame() statique makeFrame() dans cet exemple crée des images png séparées:

et dans la méthode main , nous démarrons le processus ffmpeg, dans lequel nous transférerons les images générées dans makeFrame() :
et la sortie sera un fichier vidéo:
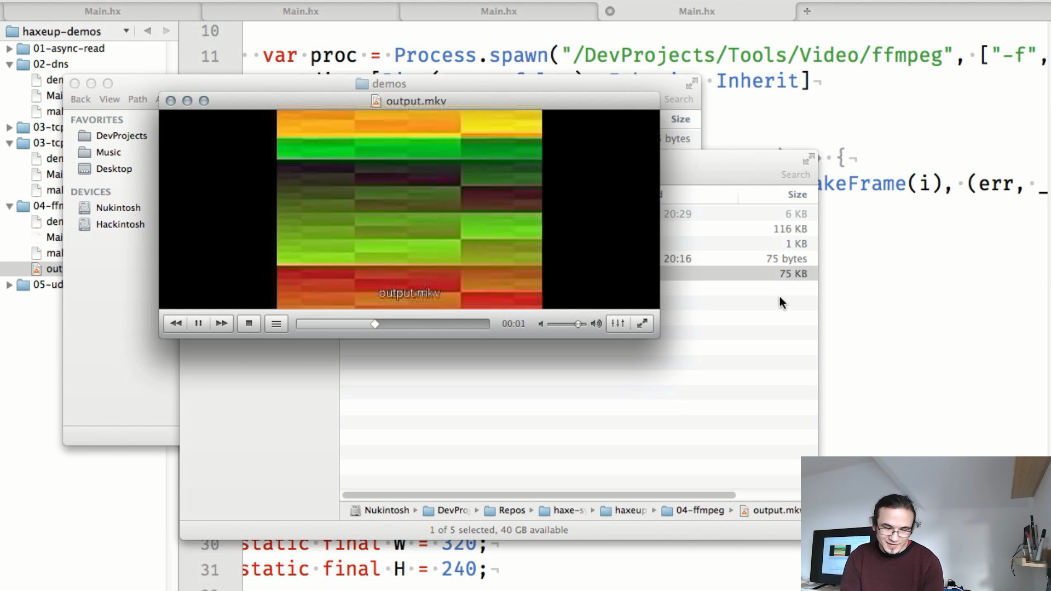
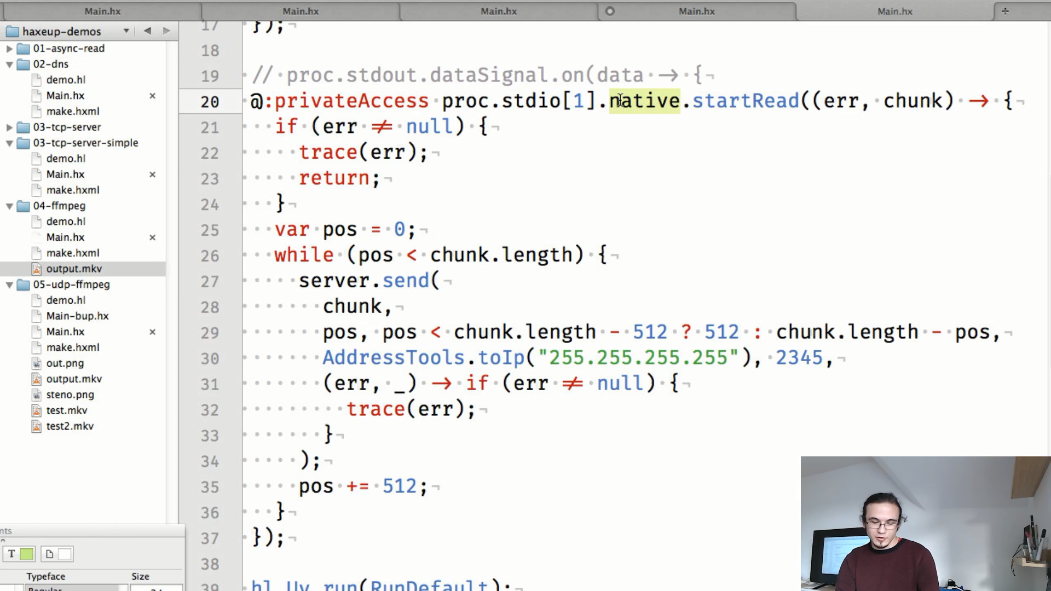
Et le cinquième exemple est le flux vidéo UDP. Ici, comme dans l'exemple précédent, le processus ffmpeg est démarré, mais cette fois, il lit la vidéo et sort ses données vers le flux de sortie standard. Un socket UDP est également créé pour traduire les données du processus ffmpeg.

Et enfin, nous divisons les données reçues de ffmpeg en «portions» plus petites et les traduisons vers le port spécifié:
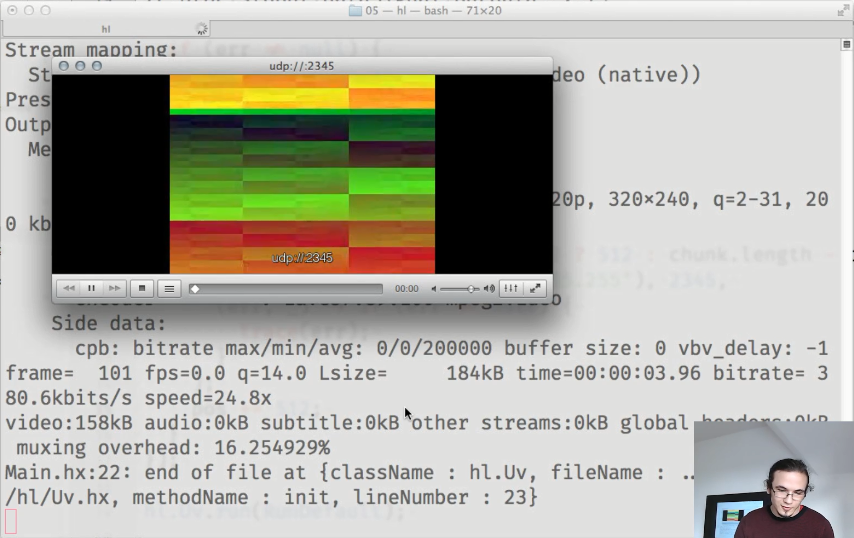
Et en conséquence, nous obtenons un flux vidéo fonctionnel:
Pour résumer ce qui précède, la nouvelle API asys comprend:
- méthodes pour travailler avec le système de fichiers, y compris les nouvelles fonctions qui n'étaient pas dans la bibliothèque standard (par exemple, pour modifier les autorisations), ainsi que les versions asynchrones de toutes les fonctions disponibles dans l'ancienne bibliothèque standard
- prise en charge du fonctionnement asynchrone avec les sockets TCP / UDP / IPC
- méthodes pour travailler avec DNS (jusqu'à présent 2 méthodes:
lookup et reverse ) - ainsi que les méthodes de travail asynchrone avec les processus.

Le travail sur l'API asys n'est pas encore terminé; il y a actuellement quelques problèmes avec le garbage collector lorsque vous travaillez avec la bibliothèque libuv. Pull Request avec les modifications correspondantes n'a pas encore été incorporé dans la branche principale de Haxe, les commentaires à ce sujet sont les bienvenus pour les opinions sur les noms des nouvelles méthodes, leurs signatures et la documentation.
Comme déjà mentionné, la prise en charge de l'API asys n'est implémentée que pour HashLink, Eval et Neko (sous la forme de trois demandes d'extraction distinctes). Aurel a déjà élaboré un plan sur la façon d'ajouter la prise en charge de la nouvelle API pour C ++ et Lua. La mise en œuvre pour d'autres plateformes nécessitera des recherches supplémentaires.

Il est possible que l'API asys devienne disponible dans Haxe 4.1 (mais uniquement sur certaines plateformes).
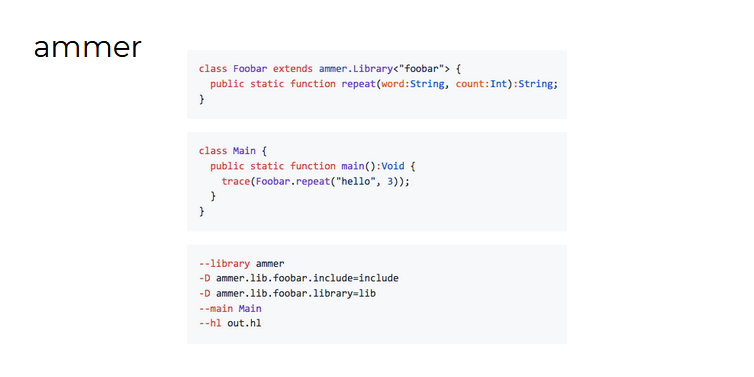
Aurel a également parlé de son projet parallèle - la bibliothèque ammer (qui est néanmoins associée à son travail à la Fondation Haxe).

Le but d'Ammer est d'automatiser la création de classeurs pour les bibliothèques C afin qu'ils puissent être utilisés à la fois dans HashLink et HXCPP (en octobre 2018, Lars Duse a fixé des frais pour résoudre ce problème).
Pourquoi cette tâche était-elle pertinente? Le fait est que bien que le processus de création de classeurs pour HashLink et HXCPP soit similaire, pour chaque plate-forme, vous devrez écrire votre propre code de collage.
Aurel a fait à peu près la même chose lorsqu'il a intégré la bibliothèque libuv dans Haxe - pour Eval, Neko et HashLink, il a dû écrire le même code qui ne différait que dans les détails (appels de fonction, différences dans le travail de FFI, etc.):

Un travail similaire devait être fait du côté de Haxe afin que les fonctions natives puissent être appelées à partir de celui-ci:

Et l'idée d'ammer est de prendre la version Haxe de l'API, non encombrée d'informations redondantes, et de faire fonctionner ce code pour toutes les plateformes:

Quel ammer est maintenant requis pour utiliser les bibliothèques C externes:
- créer la spécification Haxe pour la bibliothèque, qui est essentiellement externe à la bibliothèque utilisée
- écrire le code d'application
- compiler le projet en spécifiant les chemins d'accès aux fichiers d'en-tête et aux fichiers de la bibliothèque C
- ...
- profit
Sous le capot, ammer fait ce qui suit:
- correspond aux types en fonction de la plate-forme cible
- génère automatiquement du code C pour appeler des fonctions natives
- génère un makefile utilisé pour créer des fichiers hdll, ndll

Ammer prend actuellement en charge:
- fonctions simples
- définir les fichiers d'en-tête (dans le code Hax, ils sont accessibles sous forme de constantes)
- pointeurs
Support prévu:
- rappels (ils sont encore rares)
- et structures (très nécessaires pour travailler avec l'API C)

Maintenant, ammer fonctionne avec C ++, HashLink et Eval. Et Aurel est sûr qu'il peut ajouter la prise en charge d'autres plates-formes système.

Pour démontrer les capacités d'ammer, Aurel a montré une petite application qui exécute l'interpréteur Lua:
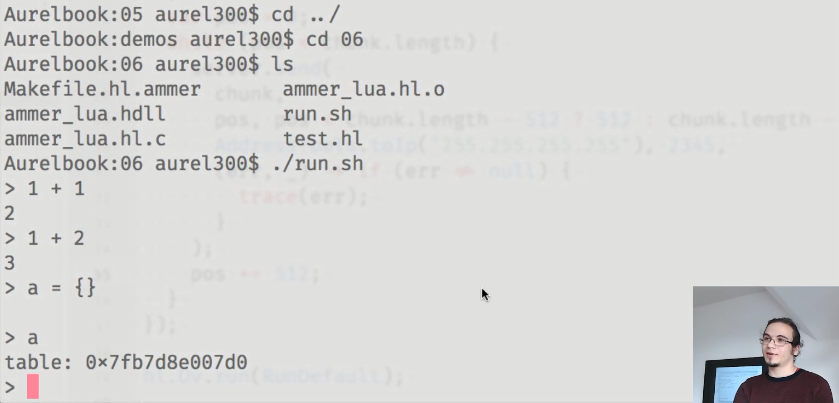
Les liants utilisés sont les suivants:
Comme vous pouvez le voir, certaines méthodes sont commentées, car ils utilisent des rappels, dont le support n'a pas encore été réalisé, mais Aurel espère qu'il pourra bientôt résoudre ce problème.

Alors, quel ammer peut être utilisé pour:
- incorporer une machine virtuelle Lua
- création d'applications sur SDL
- l'automatisation du travail avec libuv est possible (comme indiqué précédemment, maintenant il faut beaucoup de code manuscrit pour travailler avec libuv)
- et, bien sûr, cela simplifiera considérablement l'utilisation de nombreuses autres bibliothèques C utiles (comme OpenAL, Dear-imgui, etc.)

Bien que le stage d'Aurel à la Fondation Haxe soit terminé, il prévoit de continuer à travailler avec Haxe, ses études collégiales ne sont pas encore terminées et il doit encore rédiger son dernier travail. Aurel sait déjà à quoi il sera dédié - améliorer le travail du garbage collector dans HashLink. Eh bien, ce sera intéressant!