Redash a récemment commencé à passer d'un système d'exécution de tâches à un autre. À savoir, ils ont commencé la transition de Céleri à RQ. À la première étape, seules les tâches qui n'exécutent pas directement les demandes ont été transférées vers la nouvelle plateforme. Parmi ces tâches figurent l'envoi d'e-mails, la détermination des demandes à mettre à jour, l'enregistrement des événements utilisateur et d'autres tâches de support.

Après avoir déployé tout cela, il a été remarqué que les employés de RQ ont besoin de beaucoup plus de ressources informatiques pour résoudre le même volume de tâches que Celery avait l'habitude de résoudre.
Le matériel, dont nous publions la traduction aujourd'hui, est consacré à l'histoire de la façon dont Redash a découvert la cause du problème et l'a résolu.
Quelques mots sur les différences entre le céleri et le RQ
Le céleri et RQ ont le concept de travailleurs de processus. Là et là pour l'organisation de l'exécution parallèle des tâches grâce à la création de fourches. Lorsque le travailleur Celery démarre, plusieurs processus fork sont créés, chacun traitant de manière autonome les tâches. Dans le cas de RQ, l'instance de l'ouvrier contient un seul sous-processus (appelé "cheval de bataille"), qui effectue une tâche, puis est détruit. Lorsque le travailleur télécharge la tâche suivante de la file d'attente, il crée un nouveau «cheval de bataille».
Lorsque vous travaillez avec RQ, vous pouvez obtenir le même niveau de parallélisme que lorsque vous travaillez avec Celery, simplement en exécutant plus de processus de travail. Cependant, il existe une différence subtile entre le céleri et le RQ. Dans Celery, un travailleur crée de nombreuses instances de sous-processus au démarrage, puis les utilise à plusieurs reprises pour effectuer de nombreuses tâches. Et dans le cas de RQ, pour chaque travail, vous devez créer une nouvelle fourche. Les deux approches ont leurs avantages et leurs inconvénients, mais ici, nous n'en parlerons pas.
Mesure du rendement
Avant de commencer le profilage, j'ai décidé de mesurer les performances du système en découvrant combien de temps le conteneur de travail a besoin pour traiter 1000 travaux. J'ai décidé de me concentrer sur la tâche
record_event , car il s'agit d'une opération légère courante. Pour mesurer les performances, j'ai utilisé la commande
time . Cela a nécessité quelques modifications au code du projet:
- Pour mesurer les performances de l'exécution de 1000 tâches, j'ai décidé d'utiliser le mode batch RQ, dans lequel, après le traitement des tâches, le processus est quitté.
- Je voulais éviter d'influencer mes mesures avec d'autres tâches qui auraient pu être planifiées à l'époque où je mesurais les performances du système. J'ai donc déplacé
record_event vers une file d'attente distincte appelée benchmark , en remplaçant @job('default') par @job('benchmark') . Cela a été fait juste avant la record_event dans tasks/general.py .
Il était maintenant possible de commencer les mesures. Pour commencer, je voulais savoir combien de temps il faut pour démarrer et arrêter un travailleur sans charge. Ce temps pourrait être soustrait des résultats finaux obtenus ultérieurement.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m14.728s user 0m6.810s sys 0m2.750s
Il a fallu 14,7 secondes pour initialiser le travailleur sur mon ordinateur. Je m'en souviens.
Ensuite, j'ai mis 1000
record_event test
record_event dans la file d'attente de
benchmark :
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"
Après cela, j'ai démarré le système de la même manière qu'auparavant et j'ai découvert combien de temps il faut pour traiter 1000 tâches.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 1m57.332s user 1m11.320s sys 0m27.540s
En soustrayant 14,7 secondes de ce qui s'est passé, j'ai découvert que 4 travailleurs traitent 1000 tâches en 102 secondes. Essayons maintenant de savoir pourquoi il en est ainsi. Pour ce faire, nous, pendant que les travailleurs sont occupés, les rechercherons à l'aide de
py-spy .
Profilage
Nous ajoutons 1 000 tâches supplémentaires à la file d'attente (cela doit être fait car, lors des mesures précédentes, toutes les tâches ont été traitées), exécutons les travailleurs et les espions.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]" $ docker-compose exec worker bash -c 'nohup ./manage.py rq workers 4 benchmark & sleep 15 && pip install py-spy && rq info -u "redis://redis:6379/0" | grep busy | awk "{print $3}" | grep -o -P "\s\d+" | head -n 1 | xargs py-spy record -d 10 --subprocesses -o profile.svg -p' $ open -a "Google Chrome" profile.svg
Je sais que l'équipe précédente était très longue. Idéalement, pour améliorer sa lisibilité, il vaudrait la peine de le diviser en fragments séparés, de le diviser aux endroits où se trouvent des séquences de
&& caractères. Mais les commandes doivent être exécutées séquentiellement dans la même session
docker-compose exec worker bash , donc tout ressemble à ça. Voici une description de ce que fait cette commande:
- Lance 4 batch batch en arrière-plan.
- Il attend 15 secondes (il en faut environ beaucoup pour terminer leur téléchargement).
- Installe
py-spy . - Exécute
rq-info et découvre le PID de l'un des employés. - Enregistre des informations sur le travail du travailleur avec le PID précédemment reçu pendant 10 secondes et enregistre les données dans le fichier
profile.svg
En conséquence, le «calendrier ardent» suivant a été obtenu.
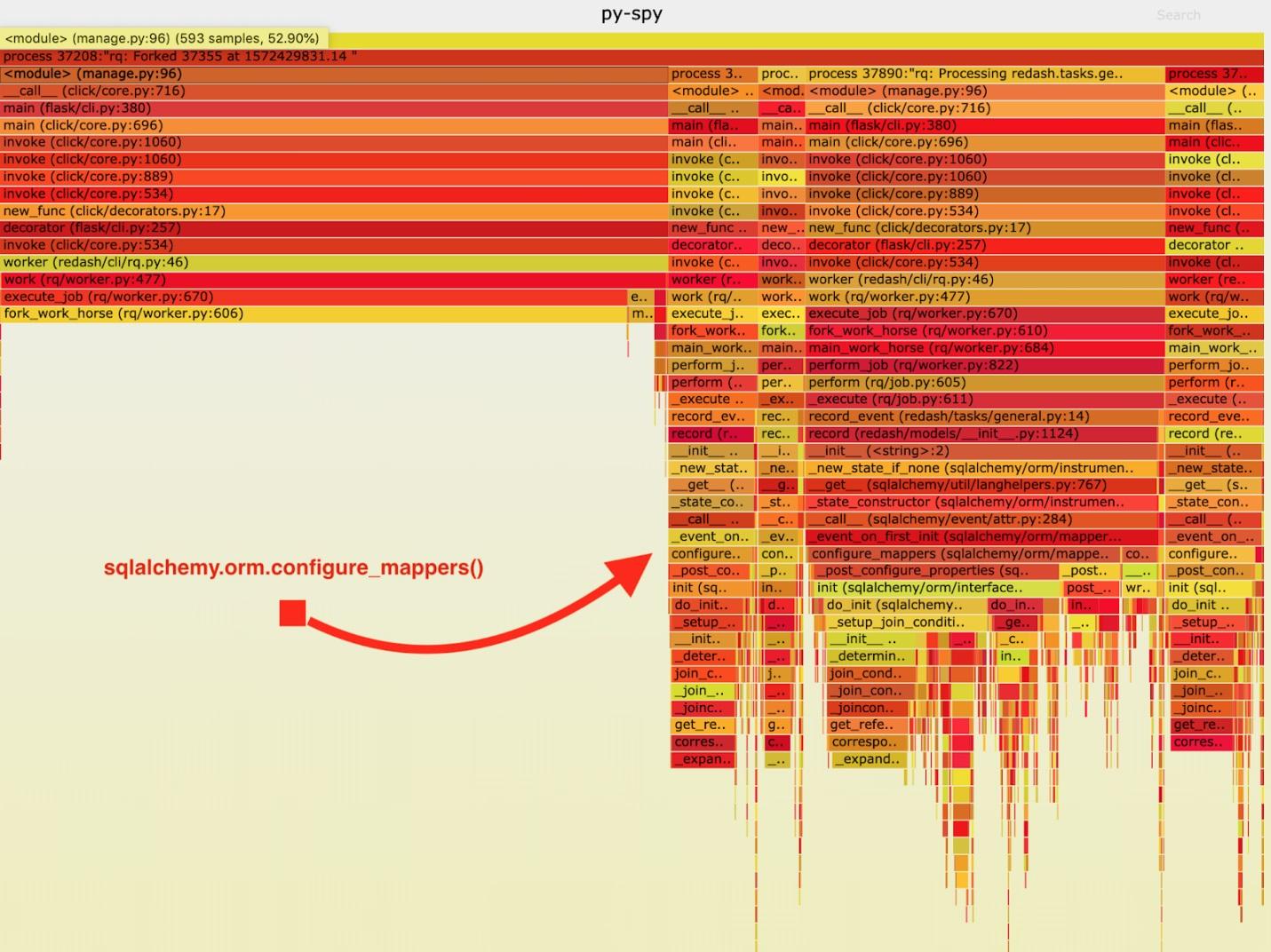 Visualisation des données collectées par py-spy
Visualisation des données collectées par py-spyAprès avoir analysé ces données, j'ai remarqué que la tâche
record_event passe beaucoup de temps à l'exécuter dans
sqlalchemy.orm.configure_mappers . Cela se produit lors de chaque tâche. De la documentation, j'ai appris qu'au moment qui m'intéresse, les relations de tous les mappeurs créés précédemment sont initialisées.
De telles choses ne doivent absolument pas se produire avec chaque fourche. Nous pouvons initialiser la relation une fois chez le parent travailleur et éviter de répéter cette tâche dans les «chevaux de trait».
Par conséquent, j'ai ajouté un appel à
sqlalchemy.org.configure_mappers() au code avant de démarrer le «cheval de bataille» et j'ai pris de nouveau des mesures.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)] $ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m39.348s user 0m15.190s sys 0m10.330s
Si vous soustrayez 14,7 secondes de ces résultats, il s'avère que nous avons amélioré le temps nécessaire à 4 travailleurs pour traiter 1000 tâches de 102 secondes à 24,6 secondes. Il s'agit d'une quadruple amélioration des performances! Grâce à ce correctif, nous avons pu quadrupler les ressources de production RQ et conserver la même bande passante système.
Résumé
De tout cela, j'ai tiré la conclusion suivante: il convient de rappeler que l'application se comporte différemment s'il s'agit du seul processus et s'il s'agit de fourches. Si au cours de chaque tâche, il est nécessaire de résoudre certaines tâches officielles difficiles, il est préférable de les résoudre à l'avance, après l'avoir fait une fois avant que la fourche ne soit terminée. De telles choses ne sont pas détectées lors des tests et du développement.Par conséquent, après avoir senti que quelque chose ne va pas avec le projet, mesurez sa vitesse et arrivez à la fin tout en recherchant les causes des problèmes de performances.
Chers lecteurs! Avez-vous rencontré des problèmes de performances dans les projets Python que vous pourriez résoudre en analysant soigneusement un système qui fonctionne?
