
Bonjour, Khabrovchans! Nous continuons à vous familiariser avec le système hyperconvergé russe AERODISK vAIR. Cet article se concentrera sur l'architecture de ce système. Dans le dernier article, nous avons analysé notre système de fichiers ARDFS, et dans cet article, nous allons passer en revue tous les principaux composants logiciels qui composent vAIR et leurs tâches.
Nous commençons la description de l'architecture de bas en haut - du stockage à la gestion.
ARDFS + Raft Cluster Driver File System
La base de vAIR est le système de fichiers distribué ARDFS, qui combine les disques locaux de tous les nœuds de cluster en un seul pool logique, sur la base duquel les disques virtuels avec l'un ou l'autre schéma de tolérance aux pannes (facteur de réplication ou codage d'effacement) sont formés à partir de blocs virtuels de 4 Mo. Une description plus détaillée du travail de l'ARDFS est donnée dans l' article précédent.
Raft Cluster Driver est un service ARDFS interne qui résout le problème du stockage distribué et fiable des métadonnées du système de fichiers.
Les métadonnées ARDFS sont classiquement divisées en deux classes.
- notifications - informations sur les opérations avec les objets de stockage et informations sur les objets eux-mêmes;
- informations de service - définition des verrous et informations de configuration pour les nœuds de stockage.
Le service RCD est utilisé pour diffuser ces données. Il attribue automatiquement à un nœud le rôle d'un leader dont la tâche est d'obtenir et de diffuser des métadonnées sur les nœuds. Un leader est la seule véritable source de ces informations. De plus, le leader organise un battement de cœur, c'est-à-dire vérifie la disponibilité de tous les nœuds de stockage (cela n'a aucun rapport avec la disponibilité des machines virtuelles, RCD est juste un service de stockage).
Si, pour une raison quelconque, le leader est devenu indisponible pour l'un des nœuds ordinaires pendant plus d'une seconde, ce nœud ordinaire organise une réélection du leader, demandant la disponibilité du leader à partir d'autres nœuds ordinaires. S'il y a quorum, le chef est réélu. Après que l'ancien chef se soit "réveillé", il devient automatiquement un nœud ordinaire, car le nouveau chef lui envoie l'équipe appropriée.
La logique du RCD lui-même n'est pas nouvelle. De nombreuses solutions tierces et commerciales et gratuites sont également guidées par cette logique, mais ces solutions ne nous convenaient pas (comme les FS open source existantes), car elles sont assez lourdes et il est très difficile de les optimiser pour nos tâches simples, nous avons donc simplement écrit notre propre Service RCD.
Il peut sembler que le leader est un «col étroit» qui peut ralentir le travail dans les grands clusters par des centaines de nœuds, mais ce n'est pas le cas. Le processus décrit se produit presque instantanément et «pèse» très peu puisque nous l'avons écrit nous-mêmes et que nous n'avons inclus que les fonctions les plus nécessaires. De plus, cela se produit de manière complètement automatique, ne laissant que des messages dans les journaux.
MasterIO - Service de gestion d'E / S multithread
Une fois qu'un pool ARDFS avec des disques virtuels est organisé, il peut être utilisé pour les E / S. À ce stade, la question se pose spécifiquement pour les systèmes hyperconvergés, à savoir: combien de ressources système (CPU / RAM) pouvons-nous donner pour les E / S?
Dans les systèmes de stockage classiques, ce problème n'est pas si aigu, car la tâche de stockage consiste uniquement à stocker des données (et la plupart des ressources de stockage système peuvent être fournies en toute sécurité sous IO), et les tâches d'hyperconvergence incluent, en plus du stockage, l'exécution de machines virtuelles. Par conséquent, le GCS nécessite l'utilisation de ressources CPU et RAM principalement pour les machines virtuelles. Et les E / S?
Pour résoudre ce problème, vAIR utilise le service de gestion des E / S: MasterIO. La tâche du service est simple - "Prenez tout et partagez" il est garanti de récupérer le nième nombre de ressources système pour les entrées et les sorties et, à partir de celles-ci, de démarrer le nième nombre de flux d'entrée / sortie.
Au départ, nous voulions fournir un mécanisme «très intelligent» pour l'allocation des ressources aux IO. Par exemple, s'il n'y a pas de charge sur le stockage, les ressources système peuvent être utilisées pour les machines virtuelles et si la charge apparaît, ces ressources sont supprimées «en douceur» des machines virtuelles dans des limites prédéterminées. Mais cette tentative s'est soldée par un échec partiel. Les tests ont montré que si la charge augmente progressivement, alors tout va bien, les ressources (marquées pour une éventuelle suppression) sont progressivement retirées de la VM au profit des E / S. Mais de brusques rafales de charges de stockage provoquent un retrait pas si «doux» des ressources des machines virtuelles, et par conséquent, les files d'attente s'accumulent sur les processeurs et, par conséquent, et les loups ont faim et les moutons sont morts et virtualka se bloquent, et il n'y a aucun IOPS.
Peut-être qu'à l'avenir, nous reviendrons sur ce problème, mais pour l'instant, nous avons mis en œuvre la délivrance de ressources pour les OI à la manière du bon vieux grand-père.
Sur la base des données de dimensionnement, l'administrateur pré-alloue le nième nombre de cœurs de CPU et de RAM pour le service MasterIO. Ces ressources se voient attribuer un monopole, c'est-à-dire ils ne peuvent en aucun cas être utilisés pour les besoins de la machine virtuelle tant que l'administrateur ne le permet pas. Les ressources sont réparties de manière égale, c'est-à-dire la même quantité de ressources système est prélevée sur chaque nœud du cluster. Tout d'abord, les ressources processeur intéressent MasterIO (la RAM est moins importante), surtout si nous utilisons le codage Erasure.
Si une erreur s'est produite avec le dimensionnement et que nous avons donné trop de ressources à MasterIO, la situation est facilement résolue en supprimant ces ressources dans le pool de ressources de la machine virtuelle. Si les ressources sont inactives, elles retourneront presque immédiatement au pool de ressources de la machine virtuelle, mais si ces ressources sont éliminées, vous devrez attendre un certain temps pour que MasterIO les libère en douceur.
La situation inverse est plus compliquée. Si nous avions besoin d'augmenter le nombre de cœurs pour MasterIO, et qu'ils sont occupés avec des virtuels, alors nous devons «négocier» avec les virtuels, c'est-à-dire les sélectionner avec des poignées, car en mode automatique dans une situation de forte augmentation de la charge, cette opération est lourde de gels de VM et d'autres comportements capricieux.
En conséquence, une grande attention doit être accordée au dimensionnement des performances des systèmes hyperconvergés IO (pas seulement les nôtres). Un peu plus tard, dans l'un des articles, nous promettons d'examiner cette question plus en détail.
Hyperviseur
Hypervisor Aist est responsable de l'exécution des machines virtuelles dans vAIR. Cet hyperviseur est basé sur l'hyperviseur KVM éprouvé. En principe, beaucoup de choses ont été écrites sur le travail de KVM, il n'y a donc pas besoin de le peindre, il suffit d'indiquer que toutes les fonctions standard de KVM sont stockées dans Stork et fonctionnent correctement.
Par conséquent, nous décrirons ici les principales différences par rapport au KVM standard, que nous avons implémenté dans Stork. La cigogne fait partie du système (hyperviseur préinstallé) et elle est contrôlée à partir de la console commune vAIR via le Web-GUI (versions russe et anglaise) et SSH (évidemment, uniquement en anglais).
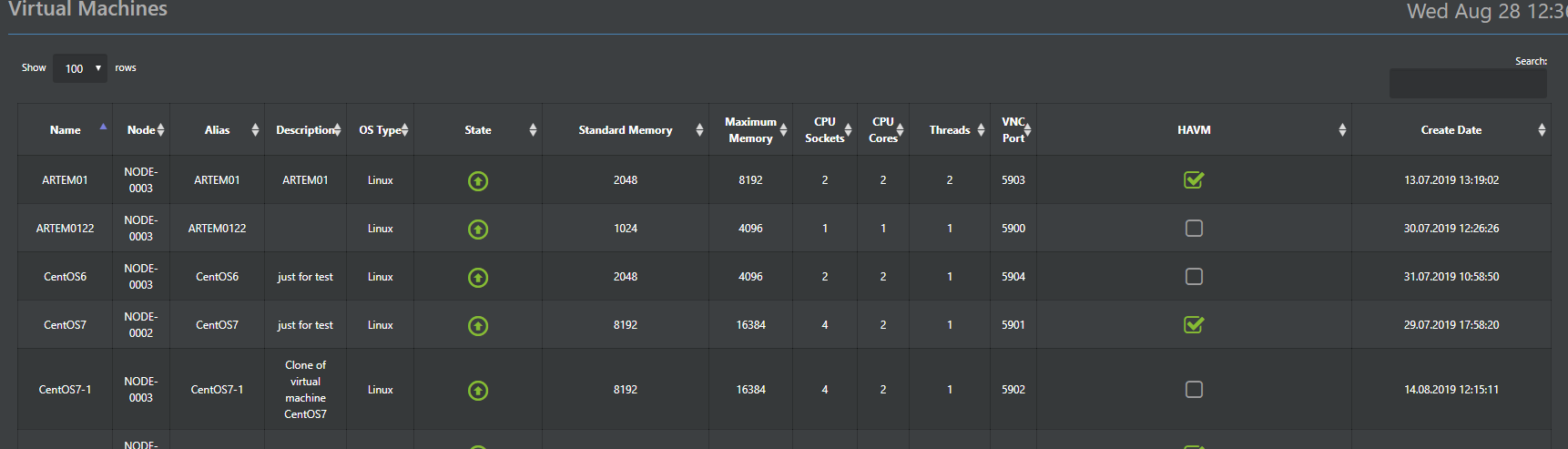
De plus, les configurations d'hyperviseur sont stockées dans la base de données ConfigDB distribuée (à ce sujet un peu plus tard), qui est également un point de contrôle unique. Autrement dit, vous pouvez vous connecter à n'importe quel nœud du cluster et tout gérer sans avoir besoin d'un serveur de gestion distinct.
Le module HA que nous avons développé constitue un ajout important à la fonctionnalité KVM standard. Il s'agit de l'implémentation la plus simple d'un cluster de machines virtuelles haute disponibilité, qui vous permet de redémarrer automatiquement la machine virtuelle sur un autre nœud de cluster en cas de défaillance d'un nœud.
Une autre fonctionnalité utile est le déploiement en masse de machines virtuelles (pertinent pour les environnements VDI), qui automatisera le déploiement des machines virtuelles avec leur distribution automatique entre les nœuds en fonction de la charge sur eux.
La distribution de VM entre les nœuds est la base de l'équilibrage de charge automatique (ala DRS). Cette fonction n'est pas encore disponible dans la version actuelle, mais nous y travaillons activement et elle apparaîtra certainement dans l'une des prochaines mises à jour.
L'hyperviseur VMware ESXi est pris en charge en option, il est actuellement implémenté à l'aide du protocole iSCSI et la prise en charge NFS est également prévue à l'avenir.
Commutateurs virtuels
Pour la mise en œuvre logicielle des commutateurs, un composant distinct est fourni - Fractal. Comme dans nos autres composants, nous passons du simple au complexe, donc dans la première version, une commutation simple est implémentée, tandis que le routage et le pare-feu sont accordés à des appareils tiers. Le principe de fonctionnement est standard. L'interface physique du serveur est connectée par un pont à l'objet Fractal - un groupe de ports. Un groupe de ports, à son tour, avec les machines virtuelles souhaitées dans le cluster. L'organisation des VLAN est prise en charge et dans l'une des prochaines versions, la prise en charge du VxLAN sera ajoutée. Tous les commutateurs créés sont distribués par défaut, c'est-à-dire distribués sur tous les nœuds du cluster, de sorte que les machines virtuelles vers lesquelles basculer pour se connecter à la machine virtuelle ne dépendent pas du nœud d'emplacement, cela dépend uniquement de la décision de l'administrateur.
Suivi et statistiques
Le composant responsable du suivi et des statistiques (titre de travail Monica) est en fait un clone repensé du système de stockage ENGINE. À un moment donné, il s'est bien recommandé et nous avons décidé de l'utiliser avec vAIR avec un réglage facile. Comme tous les autres composants, Monica est exécuté et stocké sur tous les nœuds du cluster en même temps.
Les responsabilités difficiles de Monica peuvent être décrites comme suit:
Collecte de données:
- des capteurs matériels (ce qui peut donner du fer sur IPMI);
- à partir d'objets logiques vAIR (ARDFS, Stork, Fractal, MasterIO et autres objets).
Collecte de données dans une base de données distribuée;
Interprétation des données sous forme de:
- journaux;
- Alertes
- horaires.
Interaction externe avec des systèmes tiers via les protocoles SMTP (envoi d'alertes par e-mail) et SNMP (interaction avec des systèmes de surveillance tiers).
Base de configuration distribuée
Dans les paragraphes précédents, il a été mentionné que de nombreuses données sont stockées sur tous les nœuds du cluster en même temps. Pour organiser cette méthode de stockage, une base de données ConfigDB distribuée spéciale est fournie. Comme son nom l'indique, la base de données stocke les configurations de tous les objets du cluster: hyperviseur, machines virtuelles, module HA, commutateurs, système de fichiers (à ne pas confondre avec la base de données de métadonnées FS, il s'agit d'une autre base de données), ainsi que des statistiques. Ces données sont stockées de manière synchrone sur tous les nœuds et la cohérence de ces données est une condition préalable au fonctionnement stable de vAIR.
Un point important: bien que le fonctionnement de ConfigDB soit vital pour le fonctionnement de vAIR, son échec, bien qu'il arrête le cluster, n'affecte pas la cohérence des données stockées dans ARDFS, ce qui à notre avis est un plus pour la fiabilité de la solution dans son ensemble.
ConfigDB est également un point de gestion unique, vous pouvez donc accéder à n'importe quel nœud du cluster par adresse IP et gérer entièrement tous les nœuds du cluster, ce qui est assez pratique.
De plus, pour accéder aux systèmes externes, ConfigDB fournit une API Restful à travers laquelle vous pouvez configurer l'intégration avec des systèmes tiers. Par exemple, nous avons récemment réalisé une intégration pilote avec plusieurs solutions russes dans les domaines du VDI et de la sécurité de l'information. Lorsque les projets seront terminés, nous serons heureux d'écrire les détails techniques ici.
L'image entière
En conséquence, nous avons deux versions de l'architecture du système.
Dans le premier cas principal, notre hyperviseur Aist basé sur KVM et nos commutateurs logiciels Fractal sont utilisés.
Scénario 1. Vrai
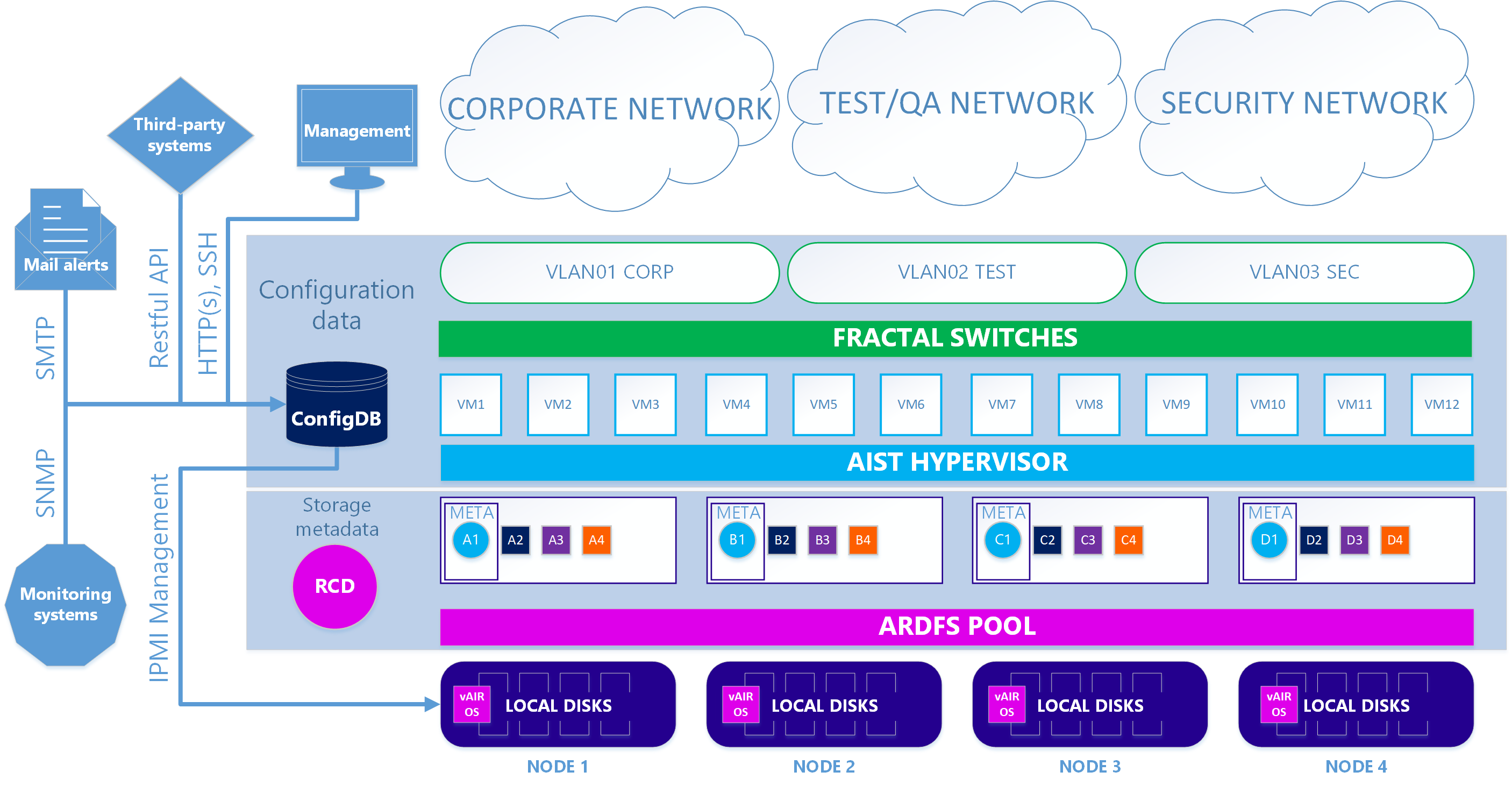
Dans la seconde - option facultative - lorsque vous souhaitez utiliser l'hyperviseur ESXi, le schéma est quelque peu compliqué. Pour utiliser ESXi, il doit être installé de manière standard sur les lecteurs locaux du cluster. Ensuite, sur chaque nœud ESXi, la machine virtuelle vAIR MasterVM est installée, qui contient une distribution spéciale vAIR à exécuter en tant que machine virtuelle VMware.
ESXi offre tous les disques locaux gratuits par transfert direct à MasterVM. À l'intérieur de MasterVM, ces disques sont déjà formatés en ARDFS et livrés à l'extérieur (ou plutôt, à ESXi) en utilisant le protocole iSCSI (et à l'avenir il y aura également NFS) via les interfaces dédiées dans ESXi. En conséquence, les machines virtuelles et le réseau de logiciels dans ce cas sont fournis par ESXi.
Scénario 2. ESXi
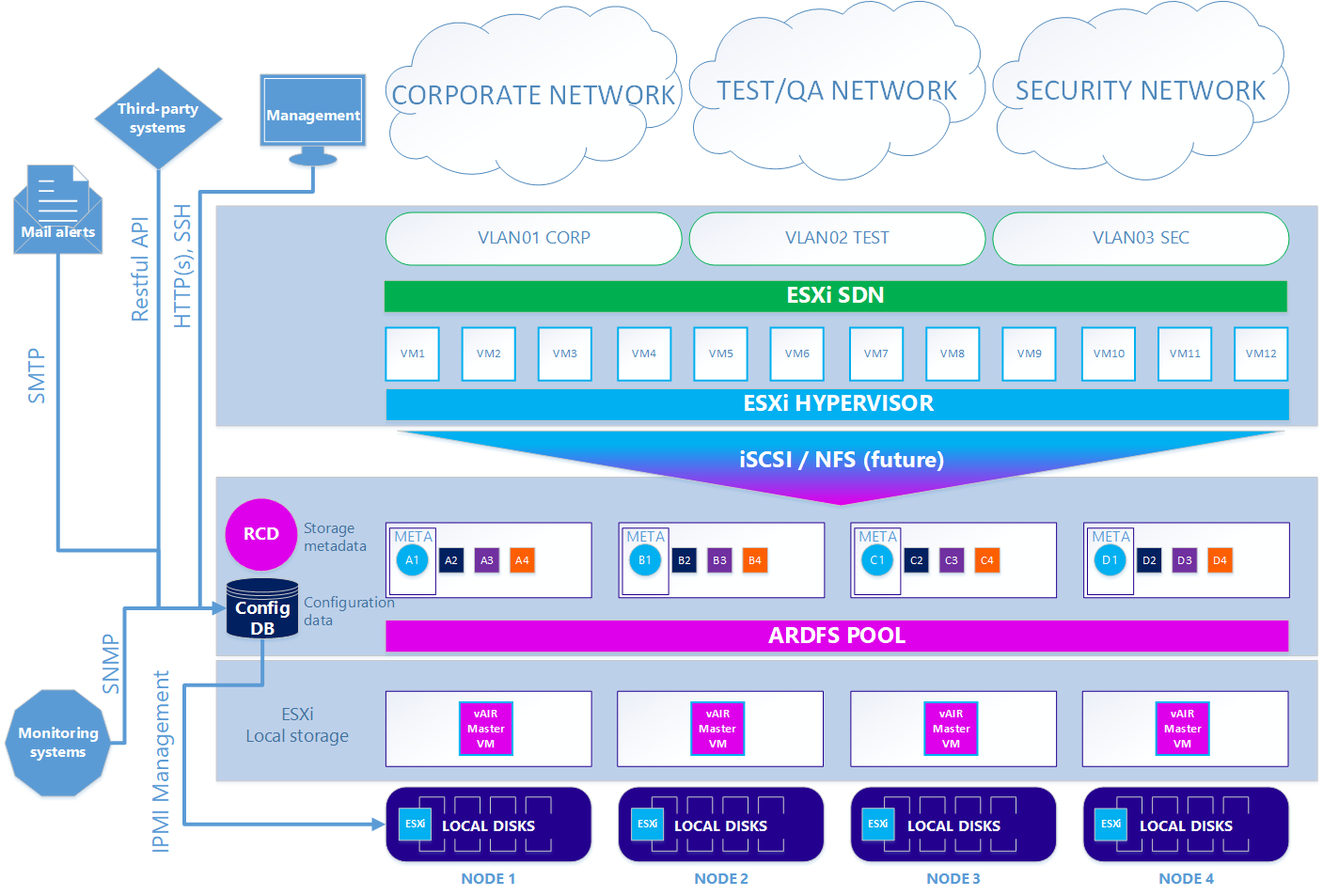
Nous avons donc démonté tous les principaux composants de l'architecture vAIR et leurs tâches. Dans le prochain article, nous parlerons des fonctionnalités déjà mises en œuvre et des plans pour un avenir proche.
Nous attendons vos commentaires et suggestions.