Salut
En septembre de cette année (2019), l'élection du gouverneur de Saint-Pétersbourg a eu lieu. Toutes les données de vote sont accessibles au public sur le site Web de la commission électorale, nous ne casserons rien, mais visualisons simplement les informations de ce site Web
www.st-petersburg.vybory.izbirkom.ru sous la forme dont nous avons besoin, nous effectuerons une analyse très simple et en identifierons Motifs "magiques".
Habituellement, pour ces tâches, j'utilise Google Colab. Il s'agit d'un service qui vous permet d'exécuter Jupyter Notebooks, et d'avoir accès au GPU (NVidia Tesla K80) gratuitement, il accélérera considérablement l'analyse des données et le traitement ultérieur. J'avais besoin d'un travail préparatoire avant d'importer.
%%time !apt update !apt upgrade !apt install gdal-bin python-gdal python3-gdal
Importations supplémentaires.
import requests from bs4 import BeautifulSoup import numpy as np import pandas as pd import matplotlib.pyplot as plt import geopandas as gpd import xlrd
Description des bibliothèques utilisées
- demandes - module pour une demande de connexion à un site
- BeautifulSoup - module pour analyser les documents html et xml; vous permet d'accéder directement au contenu de toutes les balises en html
- numpy - un module mathématique avec un ensemble de base et nécessaire de fonctions mathématiques
- pandas - bibliothèque d'analyse de données
- matplotlib.pyplot - ensemble de modules de méthodes de construction
- géopandas - module pour construire une carte électorale
- xlrd - module de lecture des fichiers de table
Le moment est venu de collecter les données elles-mêmes, parsim. Le comité électoral s'est occupé de notre temps et a fourni des rapports dans les tableaux, c'est pratique.
Voilà donc ce qui a été discuté. Les données de Google Colab sont collectées intelligemment, mais pas tellement.
Avant de construire différents graphiques et cartes, il est bon pour nous d'avoir une idée de ce que nous appelons un «ensemble de données».
Analyse des données de la commission électorale
Dans la ville de Saint-Pétersbourg, il y a 30 commissions territoriales; à elles, dans la 31e colonne, nous renvoyons aux bureaux de vote numériques.

Chaque commission territoriale compte plusieurs dizaines de PEC (commissions électorales de circonscription).

La principale chose qui nous intéresse est l'apparition dans chaque bureau de vote et le type de dépendances que nous pouvons observer. Je m'appuierai sur les éléments suivants:
- dépendance du taux de participation et du nombre de bureaux de vote;
- dépendance du pourcentage de voix des candidats sur la participation;
- Dépendance de la participation au nombre d'électeurs dans l'enceinte.
À partir du tableau de données, il est assez difficile de retracer le déroulement des élections et de tirer des conclusions, les graphiques sont donc notre chemin.
Construisons ce que nous avons trouvé.
Dépendance du taux de participation et du nombre de bureaux de vote Dépendance du pourcentage de voix des candidats sur le taux de participation
Dépendance du pourcentage de voix des candidats sur le taux de participation- «Vert» - vote pour Amosov
 Dépendance de la participation au nombre d'électeurs dans l'enceinte
Dépendance de la participation au nombre d'électeurs dans l'enceinte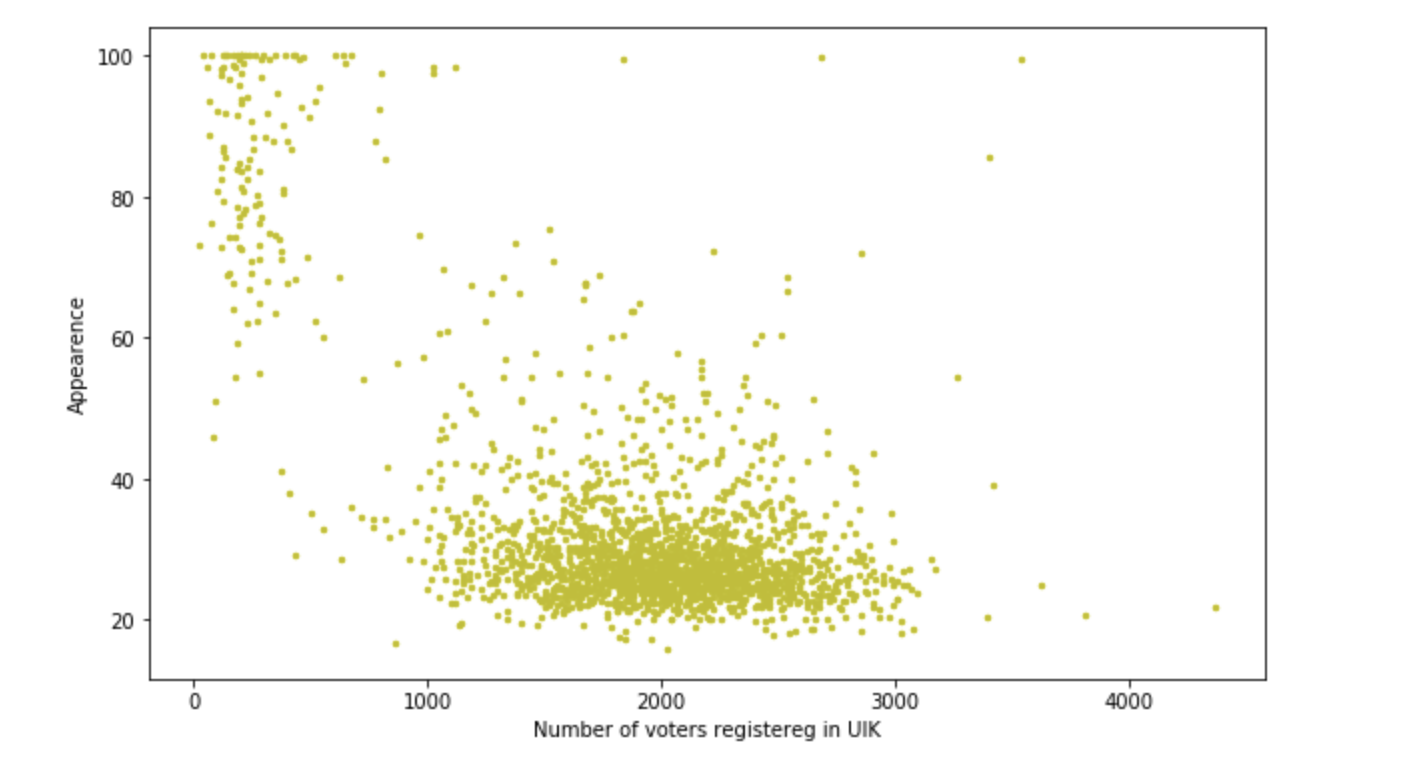
Les constructions sont assez tolérables, mais au cours des travaux, il s'est avéré qu'en moyenne 400 personnes sur le site et le pourcentage pour Beglov est de 50 à 70, mais il y a deux sites avec une participation> 1200 personnes et un pourcentage de 90 + -0,2. Il est intéressant que cela se soit produit dans ces domaines. Des agitateurs fantastiques ont-ils fonctionné? Ou simplement conduit 10 bus et forcé de voter? D'une manière ou d'une autre, nous sommes ravis, une petite enquête de ce type est en cours. Mais nous devons encore tirer des cartes. Continuons.
Représentation visuelle et travail avec les géopandas
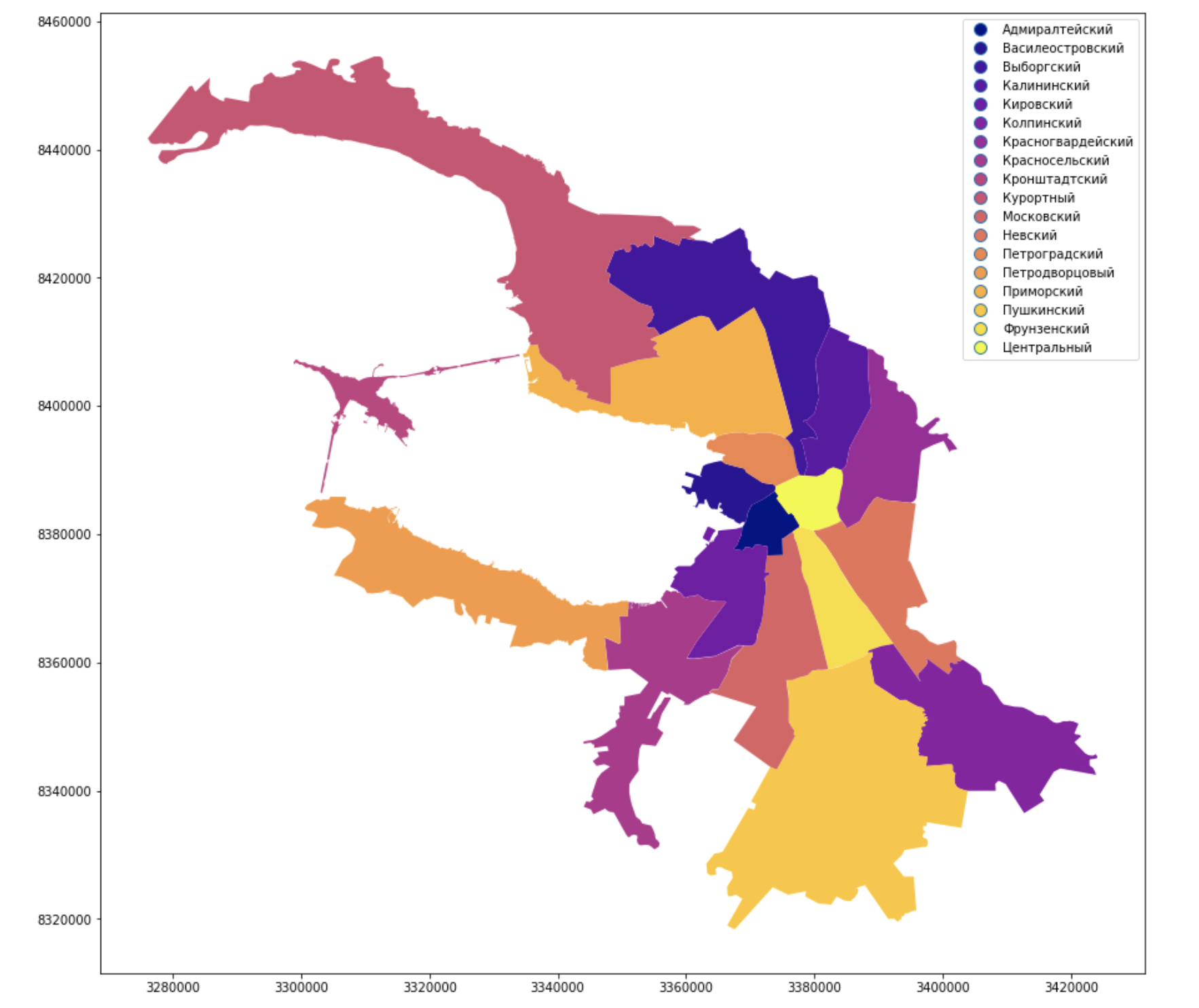
Ils ont peint les quartiers administratifs de la ville et les ont signés, ça a l'air familier, ça ressemble à Peter, mais la Neva ne suffit toujours pas.
Nombre d'électeurs
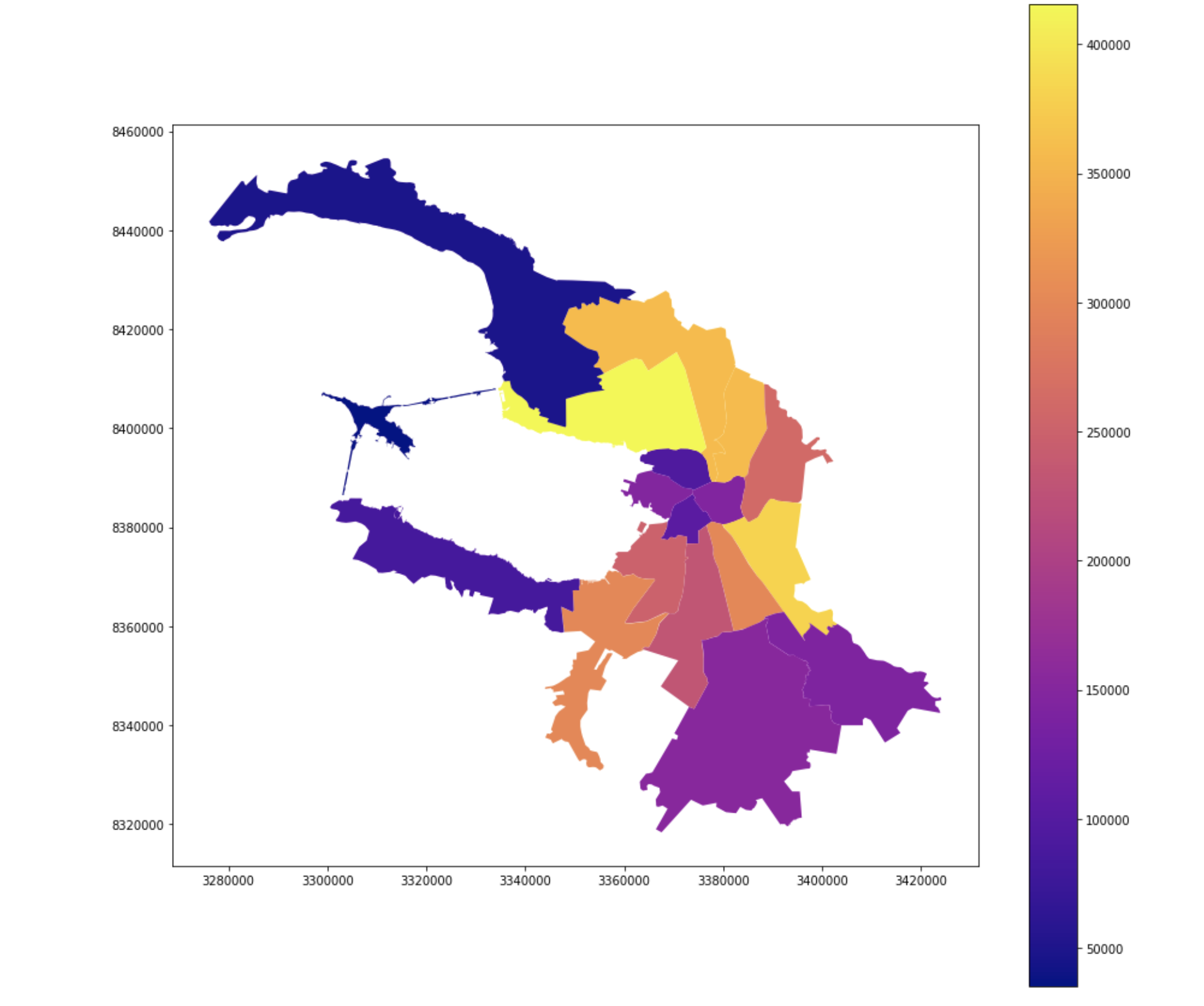 Participation
Participation

Conclusion
Vous pouvez vous amuser avec les données pendant longtemps, les utiliser dans différents domaines et, bien sûr, en retirer des avantages, car elles existent. Des outils de visualisation de géolocalisation simples et sophistiqués peuvent faire de grandes choses. Écrivez sur votre succès dans les commentaires!