Pour des questions dans le style "pourquoi?" Il y a un article plus ancien - Natural Geektimes - rendant l'espace plus propre .
De nombreux articles, pour des raisons subjectives, certains n'aiment pas, et certains, au contraire, c'est dommage de les manquer. Je souhaite optimiser ce processus et gagner du temps.
L'article ci-dessus suggère une approche avec des scripts dans le navigateur, mais je ne l'aimais pas vraiment (même si je l'ai déjà utilisé) pour les raisons suivantes:
- Pour différents navigateurs sur votre ordinateur / téléphone, vous devez le configurer à nouveau, si possible.
- Le filtrage brutal par les auteurs n'est pas toujours pratique.
- Le problème des auteurs dont les articles ne veulent pas être manqués, même s'ils sont publiés une fois par an, n'est pas résolu.
Le filtrage par note d'article intégrée au site n'est pas toujours pratique, car les articles hautement spécialisés, pour toute leur valeur, peuvent recevoir une note plutôt modeste.
Au départ, je voulais générer du flux rss (ou même certains), ne laissant là que l'intéressant. Mais au final, il s'est avéré que la lecture de rss ne semblait pas très pratique: en tout cas, pour commenter / voter sur un article / l'ajouter aux favoris, il faut passer par le navigateur. Par conséquent, j'ai écrit un bot pour un télégramme qui me lance des articles intéressants dans PM. Le télégramme lui-même en fait de beaux aperçus, qui en combinaison avec des informations sur l'auteur / la note / les vues semblent assez informatifs.
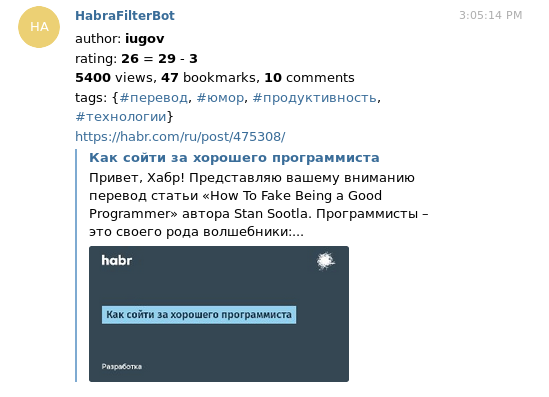
Sous la coupe, des détails comme les caractéristiques du travail, le processus d'écriture et les solutions techniques.
En bref sur le bot
Référentiel: https://github.com/Kright/habrahabr_reader
Bot télégramme: https://t.me/HabraFilterBot
L'utilisateur définit une note supplémentaire pour les balises et les auteurs. Après cela, un filtre est appliqué aux articles - la note de l'article sur Habré, la note utilisateur de l'auteur et la moyenne des notes utilisateur par tags sont ajoutées. Si le montant est supérieur à la valeur seuil définie par l'utilisateur, l'article passe le filtre.
Un objectif secondaire de l'écriture d'un bot était de s'amuser et de vivre de l'expérience. De plus, je me rappelais régulièrement que je n'étais pas Google , et donc beaucoup de choses étaient faites aussi simples et même primitives que possible. Cependant, cela n'a pas empêché le processus d'écriture du bot de s'étirer pendant trois mois.
À l'extérieur de la fenêtre était l'été
Juillet s'est terminé et j'ai décidé d'écrire un bot. Et pas seul, mais avec un ami qui maîtrise la scala et qui veut écrire quelque chose dessus. Le début semblait prometteur - le code sera scié "en équipe", la tâche semblait facile et je pensais que dans quelques semaines ou un mois le bot serait prêt.
Malgré le fait que j'écrive moi-même du code sur la roche depuis quelques années, généralement personne ne voit ou ne regarde ce code: projets pour animaux de compagnie, vérification d'idées, prétraitement des données, maîtrise de certains concepts du FP. J'étais vraiment intéressé par l'apparence du code dans l'équipe, car le code sur le rocher peut être écrit de manières très différentes.
Qu'est-ce qui aurait pu se passer ainsi ? Cependant, nous ne précipiterons pas les choses.
Tout ce qui se passe peut être suivi par l'historique des commits.
Un ami a créé le référentiel le 27 juillet, mais n'a rien fait d'autre, alors j'ai commencé à écrire du code.
30 juillet
En bref: j'ai écrit l'analyse des flux rss de Habr.
com.github.pureconfig pour lire les fichiers de configuration typesafe directement dans les classes de cas (cela s'est avéré très pratique)scala-xml pour lire le xml: comme je voulais à l'origine écrire mon implémentation pour la bande rss et la bande rss au format xml, j'ai utilisé cette bibliothèque pour l'analyse. En fait, l'analyse rss est également apparue.scalatest pour les tests. Même pour les petits projets, l'écriture de tests permet de gagner du temps - par exemple, lors du débogage de l'analyse XML, il est beaucoup plus facile de le télécharger dans un fichier, d'écrire des tests et de corriger les erreurs. Lorsqu'un bogue est apparu plus tard avec l'analyse d'un étrange code html avec des caractères utf-8 invalides, il s'est avéré encore plus pratique de le mettre dans un fichier et d'ajouter un test.- acteurs d'Akka. Objectivement, ils n'étaient pas du tout nécessaires, mais le projet a été écrit pour le plaisir, je voulais les essayer. En conséquence, je suis prêt à dire que j’ai aimé. On peut regarder l'idée de la POO de l'autre côté - il y a des acteurs qui échangent des messages. Ce qui est plus intéressant - il est possible (et nécessaire) d'écrire du code de manière à ce que le message ne parvienne pas ou ne puisse pas être traité (généralement, lorsque le compte s'exécute sur un seul ordinateur, les messages ne doivent pas être perdus). Au début, je me creusais la tête et il y avait une poubelle dans le code avec des acteurs qui s'abonnaient les uns aux autres, mais à la fin j'ai réussi à trouver une architecture plutôt simple et élégante. Le code à l'intérieur de chaque acteur peut être considéré comme un seul thread, lorsque l'acteur se bloque, l'Akka le redémarre - un système plutôt tolérant aux pannes est obtenu.
9 août
J'ai ajouté le projet scala-scrapper pour analyser les pages html du Habr (pour extraire des informations telles que la note de l'article, le nombre de signets, etc.).
Et les chats. Ceux qui sont dans la roche.
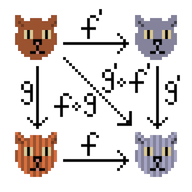
J'ai ensuite lu un livre sur les bases de données distribuées, j'ai aimé l'idée de CRDT (Conflict-free replicated data type, https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type , habr ), alors j'ai filmé la classe de type du semi-groupe commutatif pour informations sur l'article sur Habré.
En fait, l'idée est très simple - nous avons des compteurs qui changent de façon monotone. Le nombre de promoteurs augmente régulièrement, le nombre d'avantages aussi (cependant, ainsi que le nombre d'inconvénients). Si j'ai deux versions d'informations sur un article, vous pouvez «les fusionner en une seule» - considérez l'état du compteur qui est le plus pertinent.
Un semi-groupe signifie que deux objets contenant des informations sur un article peuvent être fusionnés en un seul. Commutative signifie que vous pouvez fusionner A + B et B + A, le résultat ne dépend pas de l'ordre, par conséquent, la version la plus récente reste. Soit dit en passant, l'associativité est également là.
Par exemple, par conception, rss après l'analyse a donné des informations légèrement atténuées sur l'article - sans métriques telles que le nombre de vues. Un acteur spécial a ensuite pris des informations sur les articles et a couru vers les pages html pour le mettre à jour et fusionner avec l'ancienne version.
D'une manière générale, comme akka, cela n'était pas nécessaire, il était possible de simplement stocker la date de mise à jour de l'article et d'en prendre une plus récente sans aucune fusion, mais le chemin de l'aventure m'a conduit.
12 août
J'ai commencé à me sentir plus libre et, par intérêt, j'ai fait de chaque conversation un acteur distinct. Théoriquement, un acteur à lui seul pèse environ 300 octets et peut être créé au moins par millions, c'est donc une approche tout à fait normale. Il s'est avéré, il me semble, une solution assez intéressante:
Un acteur était le pont entre le serveur de télégramme et le système de messagerie à Akka. Il a simplement reçu des messages et les a envoyés à l'acteur de chat souhaité. Le chat d'acteur en réponse pourrait renvoyer quelque chose - et il a été renvoyé aux télégrammes. Ce qui était très pratique - cet acteur s'est avéré être aussi simple que possible et ne contenait que la logique de la réponse aux messages. Soit dit en passant, des informations sur les nouveaux articles sont venues à chaque discussion, mais encore une fois, je ne vois aucun problème.
En général, le bot fonctionnait déjà, répondait aux messages, gardait une liste d'articles envoyés à l'utilisateur, et je pensais déjà que le bot était presque prêt. J'ai lentement fini de petites puces comme normaliser les noms des auteurs et des balises (en remplaçant "sd f" par "s_d_f").
Il n'y avait qu'une petite mais - l'État n'a persisté nulle part.
Tout s'est mal passé
Vous avez peut-être remarqué que j'ai écrit le bot principalement seul. Ainsi, le deuxième participant s'est joint au développement et les modifications suivantes sont apparues dans le code:
- Pour stocker l'état est apparu mongoDB. Dans le même temps, les journaux se sont cassés dans le projet, car pour une raison quelconque, la monga a commencé à les spammer et certaines personnes les ont simplement désactivés à l'échelle mondiale.
- Le pont des acteurs dans le télégramme a été transformé au-delà de la reconnaissance et a commencé à analyser les messages lui-même.
- Les acteurs pour les chats étaient ivres sans pitié, au lieu d'eux apparaissait un acteur qui cachait en lui toutes les informations sur tous les chats à la fois. Pour chaque éternuement, cet acteur montait en mongu. Eh bien, oui, il est difficile de l'envoyer à tous les acteurs du chat lors de la mise à jour des informations sur un article (nous sommes comme Google, des millions d'utilisateurs attendent un million d'articles dans un chat pour tout le monde), mais il est normal d'entrer dans un monga chaque fois que vous mettez à jour un chat. Comme je l'ai compris beaucoup plus tard, la logique de travail des chats a également été complètement coupée et quelque chose d'inopérant est apparu.
- Il ne reste aucune trace des classes.
- Une logique malsaine est apparue chez les acteurs avec leurs abonnements les uns aux autres, conduisant à une condition de race.
- Structures de données avec des champs de type
Option[Int] transformées en Int avec des valeurs magiques par défaut de type -1. Plus tard, j'ai réalisé que mongoDB stocke json et qu'il n'y a rien de mal à y stocker Option ou au moins à analyser -1 comme None, mais à ce moment-là, je ne le savais pas et j'ai cru le mot "c'est nécessaire". Ce code n'a pas été écrit par moi et je n'ai pas pris la peine de le changer pour le moment. - J'ai découvert que mon adresse IP publique a la propriété de changer, et chaque fois que je devais l'ajouter à la langue de la liste blanche. J'ai démarré le bot localement, la monga était quelque part sur les serveurs monga en tant qu'entreprise.
- Soudain, la normalisation des balises et le formatage des messages pour un télégramme ont disparu. (Hmm, pourquoi ça?)
- J'ai aimé que l'état du bot soit stocké dans une base de données externe, et au redémarrage, il continue de fonctionner comme si de rien n'était. Cependant, c'était le seul avantage.
La deuxième personne n'était pas pressée, et tous ces changements sont apparus en un seul gros tas déjà début septembre. Je n'ai pas immédiatement apprécié l'ampleur des dégâts et j'ai commencé à comprendre le travail de la base de données, car n'avait jamais traité avec eux auparavant. Ce n'est qu'alors que j'ai réalisé combien de code de travail a été coupé et combien de bogues ont été ajoutés en retour.
Septembre
Au début, je pensais qu'il serait utile de maîtriser Mongu et de bien faire tout. Puis j'ai lentement commencé à comprendre que l'organisation de la communication avec la base de données est aussi un art dans lequel on peut faire des courses et juste des erreurs. Par exemple, si deux messages de type /subscribe arrivent de l'utilisateur, et en réponse à chacun, nous créerons une entrée dans la plaque, car au moment du traitement de ces messages, l'utilisateur n'est pas signé. Je soupçonnais que la communication avec la monga sous la forme existante n'était pas écrite de la meilleure façon. Par exemple, les paramètres utilisateur ont été créés au moment de son inscription. S'il essayait de les changer avant le fait de l'abonnement ... le bot n'a pas répondu, car le code de l'acteur est monté dans la base de données pour les paramètres, n'a pas pu trouver et s'est écrasé. À la question - pourquoi ne pas créer les paramètres selon les besoins, j'ai découvert qu'il n'y avait rien pour les changer si l'utilisateur n'était pas abonné ... Le système de filtrage des messages a été en quelque sorte rendu évident, et même après un examen attentif du code, je ne pouvais pas comprendre s'il avait été conçu à l'origine ou il y a une erreur.
Aucune liste d'articles n'a été envoyée pour chatter, mais il a été suggéré de les écrire moi-même. Cela m'a surpris - en général, je n'étais pas opposé à faire glisser toutes sortes de pièces dans le projet, mais il serait logique de tirer ces choses et de les visser. Mais non, le deuxième participant semble avoir tout oublié, mais a déclaré que la liste à l'intérieur du chat était censée être une mauvaise décision, et vous devez faire une plaque avec des événements comme "l'article x a été envoyé à l'utilisateur x". Ensuite, si l'utilisateur demandait d'envoyer de nouveaux articles, il était nécessaire d'envoyer une demande à la base de données, lequel des événements sélectionnerait les événements liés à l'utilisateur, obtiendrait toujours une liste de nouveaux articles, les filtrerait, les enverrait à l'utilisateur et renverrait des événements à ce sujet dans la base de données.
Le deuxième participant a quelque part souffert dans le sens des abstractions, lorsque le bot ne recevra pas seulement des articles de Habr et n'enverra pas seulement aux télégrammes.
J'ai en quelque sorte mis en œuvre les événements sous la forme d'une tablette séparée d'ici la seconde moitié de septembre. Pas optimal, mais le bot a au moins fonctionné et a recommencé à m'envoyer des articles, et j'ai lentement compris ce qui se passait dans le code.
Maintenant, vous pouvez d'abord revenir en arrière et vous rappeler que le référentiel n'a pas été créé par moi à l'origine. Qu'est-ce qui aurait pu se passer ainsi? Ma demande de pool a été rejetée. Il s'est avéré que j'avais un shortcode, que je ne savais pas comment travailler en équipe et que je devais éditer des bugs dans la courbe d'implémentation actuelle, et ne pas le modifier dans un état utilisable.
J'étais bouleversé, j'ai regardé l'historique des commits, la quantité de code écrit. J'ai regardé les moments qui étaient bien écrits à l'origine, puis je me suis cassé ...
F * rk it
Je me suis souvenu de l'article You Are Not Google .
Je pensais que personne n'avait vraiment besoin d'une idée sans mise en œuvre. Je pensais que je voulais avoir un bot qui fonctionnerait en une seule copie sur un seul ordinateur comme un simple programme java. Je sais que mon bot fonctionnera pendant des mois sans redémarrage, car dans le passé, j'écrivais de tels bots. S'il tombe soudainement et n'envoie pas le prochain article à l'utilisateur, le ciel ne tombera pas sur la terre et rien de catastrophique ne se produira.
Pourquoi ai-je besoin d'un docker, d'un mongoDB et d'un autre logiciel cargo "sérieux", si le code ne fonctionne pas bêtement ou fonctionne de manière tordue?
J'ai bifurqué le projet et fait tout ce que je voulais.
Vers la même époque, j'ai changé d'emploi et le temps libre manquait cruellement. Le matin, je me suis réveillé exactement dans le train, je suis rentré tard dans la soirée et je ne voulais plus rien faire. Je n'ai rien fait pendant un moment, puis j'ai surmonté le désir de terminer le bot, et j'ai commencé à réécrire lentement le code en conduisant au travail le matin. Je ne peux pas dire que c'était productif: s'asseoir dans un train tremblant avec un ordinateur portable sur vos genoux et jeter un œil au débordement de la pile de votre téléphone n'est pas très pratique. Cependant, le temps passé à écrire le code est passé complètement inaperçu et le projet a commencé à passer lentement à un état de fonctionnement.
Quelque part au fond, il y avait un ver de doute que mongoDB voulait utiliser, mais je pensais qu'il y avait des inconvénients notables en plus des avantages du stockage d'état «fiable»:
- La base de données devient un autre point de défaillance.
- Le code devient plus difficile et je l'écrirai plus longtemps.
- Le code devient lent et inefficace; au lieu de changer l'objet en mémoire, les modifications sont envoyées à la base de données et retirées si nécessaire.
- Il existe des restrictions sur le type de stockage des événements dans une plaque distincte, qui sont associés aux fonctionnalités de la base de données.
- Dans la version d'essai de monga, il existe certaines restrictions, et si vous les rencontrez, vous devrez démarrer et configurer le mongu pour quelque chose.
J'ai bu Mongu, maintenant l'état du bot est simplement stocké dans la mémoire du programme et de temps en temps il est enregistré dans un fichier sous forme de json. Peut-être que dans les commentaires, ils écriront que je me trompe, car c'est là que vous devriez l'utiliser, etc. Mais c'est mon projet, l'approche avec le fichier est aussi simple que possible et cela fonctionne de manière transparente.
J'ai jeté des valeurs magiques comme -1 et suis revenu à l' Option normale, j'ai ajouté le stockage d'une plaque de hachage avec les articles envoyés à l'objet avec des informations de chat. Ajout de la suppression des informations sur les articles de plus de cinq jours, afin de ne pas tout stocker de suite. Il a mis la journalisation en état de fonctionnement - des journaux en quantités raisonnables sont écrits à la fois dans le fichier et dans la console. Ajout de plusieurs commandes d'administration telles que l'enregistrement de l'état ou l'obtention de statistiques comme le nombre d'utilisateurs et d'articles.
J'ai corrigé un tas de petites choses: par exemple, les articles indiquent maintenant le nombre de vues, de goûts, d'aversions et de commentaires au moment où le filtre utilisateur a été passé. En général, il est étonnant de voir combien de petites choses ont dû être réparées. J'en ai gardé une liste, y ai noté toutes les «rugosités» et les ai corrigées autant que possible.
Par exemple, j'ai ajouté la possibilité de définir tous les paramètres directement dans un message:
/subscribe /rating +20 /author a -30 /author s -20 /author p +9000 /tag scala 20 /tag akka 50
Et la commande /settings affiche sous cette forme, vous pouvez en prendre du texte et envoyer tous les paramètres à un ami.
Cela semble être une bagatelle, mais il existe des dizaines de nuances similaires.
Filtrage des articles mis en œuvre sous la forme d'un modèle linéaire simple - l'utilisateur peut définir une note supplémentaire pour les auteurs et les balises, ainsi qu'une valeur de seuil. Si la somme de la note de l'auteur, de la note moyenne des tags et de la note réelle de l'article est supérieure à la valeur seuil, l'article est présenté à l'utilisateur. Vous pouvez soit demander au bot des articles avec la commande / new, soit vous abonner au bot et il lancera des articles dans PM à tout moment de la journée.
De manière générale, j'ai eu une idée pour chaque article de dessiner plus de signes (hubs, le nombre de commentaires, les signets, la dynamique des changements de notation, la quantité de texte, les images et le code dans l'article, les mots-clés), et l'utilisateur de montrer le vote ok / not ok sous chacun article et pour chaque utilisateur de former le modèle, mais je suis devenu trop paresseux.
De plus, la logique du travail ne sera pas aussi évidente. Maintenant, je peux mettre manuellement une note de +9000 pour patientZero et avec une note seuil de +20, je serai assuré de recevoir tous ses articles (sauf, bien sûr, je mets -100500 pour toutes les balises).
L'architecture résultante était assez simple:
- Un acteur qui stocke l'état de tous les chats et articles. Il charge son état à partir d'un fichier sur le disque et le sauvegarde de temps en temps, à chaque fois dans un nouveau fichier.
- Un acteur qui rencontre occasionnellement le flux rss apprend les nouveaux articles, examine les liens, analyse et envoie ces articles au premier acteur. De plus, il demande parfois au premier acteur une liste d'articles, sélectionne ceux d'entre eux qui n'ont pas plus de trois jours, mais qui n'ont pas été mis à jour depuis longtemps, et les met à jour.
- Un acteur qui communique avec un télégramme. J'ai toujours pris l'analyse des messages ici. Dans le bon sens, je veux le diviser en deux - afin que l'un analyse les messages entrants et que le second traite des problèmes de transport tels que le transfert des messages non envoyés. Maintenant, il n'y a pas de ré-envoi, et le message qui n'a pas atteint en raison d'une erreur sera simplement perdu (sauf qu'il sera marqué dans les journaux), mais jusqu'à présent, cela ne pose aucun problème. Peut-être que des problèmes surviendront si un groupe de personnes s'abonne au bot et que j'atteins la limite d'envoi de messages).
Ce que j'ai aimé - grâce à akka, la chute des acteurs 2 et 3 en général n'affecte pas les performances du bot. Peut-être que certains articles ne sont pas mis à jour à temps ou que certains messages n'atteignent pas le télégramme, mais Akka redémarre l'acteur et tout continue de fonctionner. J'enregistre les informations selon lesquelles l'article est montré à l'utilisateur uniquement lorsque l'acteur de télégramme répond qu'il a bien livré le message. La pire chose qui me menace est d'envoyer un message plusieurs fois (s'il est délivré, mais la confirmation est perdue d'une manière inconnue). En principe, si le premier acteur ne gardait pas l'État en lui-même, mais communiquait avec une sorte de base de données, il pouvait également tomber tranquillement et reprendre vie. Je pourrais aussi essayer akka persistance pour restaurer l'état des acteurs, mais l'implémentation actuelle me convient par sa simplicité. Non pas que mon code se bloque souvent - au contraire, j'ai mis beaucoup d'efforts pour rendre cela impossible. Mais la merde arrive, et la possibilité de diviser le programme en morceaux isolés-acteurs me semblait vraiment pratique et pratique.
Circle-ci ajouté afin de le savoir immédiatement lorsque le code casse. Au moins que le code a cessé de compiler. Au départ, je voulais ajouter des travis, mais cela ne montrait que mes projets sans ceux fourchus. En général, ces deux éléments peuvent être librement utilisés sur des référentiels ouverts.
Résumé
C'est déjà novembre. Le bot est écrit, je l'ai utilisé depuis deux semaines et j'ai bien aimé. Si vous avez des idées d'amélioration - écrivez. Je ne vois pas l'intérêt de le monétiser - laissez-le fonctionner et envoyez des articles intéressants.
Lien vers le bot: https://t.me/HabraFilterBot
Github: https://github.com/Kright/habrahabr_reader
Petites conclusions:
- Même un petit projet peut prendre beaucoup de temps.
- Vous n'êtes pas Google. Cela n'a aucun sens de tirer un moineau avec un canon. Une solution simple peut tout aussi bien fonctionner.
- Les projets pour animaux de compagnie sont très bien adaptés pour expérimenter de nouvelles technologies.
- Les robots télégrammes sont écrits tout simplement. Sans le «travail d'équipe» et les expériences avec les technologies, le bot aurait été écrit en une semaine ou deux.
- Le modèle d'acteur est une chose intéressante qui va bien avec le multithread et la résilience du code.
- Il me semble que la communauté open source aime les fourches.
- Les bases de données sont bonnes en ce que l'état de l'application ne dépend plus des pannes / redémarrages de l'application, mais travailler avec la base de données complique le code et impose des restrictions sur la structure des données.