Chaque jour, le Web mondial est rempli d'articles sur les algorithmes d'apprentissage automatique les plus populaires et les plus utilisés pour résoudre divers problèmes. De plus, la base de ces articles, légèrement modifiés de forme à un endroit ou à un autre, se déplace d'un chercheur de données à un autre. De plus, tous ces travaux sont unis par un postulat généralement accepté et incontestable: l'application de l'un ou l'autre algorithme d'apprentissage automatique dépend de la taille et de la nature des données disponibles et de la tâche à accomplir.
En plus de cela, en particulier les chercheurs de données insistés, partageant leur expérience, soulignent:
«Le choix d'une méthode d'évaluation devrait dépendre en partie de vos données et de ce qui, à votre avis, le modèle devrait être bon» («Data Science: informations privilégiées pour les débutants. Y compris le langage R, par Cathy O'Neill, Rachel Shutt) .
En d'autres termes, un statisticien / chercheur de données devrait avoir non seulement une expérience dans le domaine, mais également un large éventail de connaissances diverses:
«Un chercheur de données est celui qui possède des connaissances dans les domaines suivants: mathématiques, statistiques, génie informatique, apprentissage automatique, visualisation, moyens d'échanger des données ... » (du même livre). Seul un chargement approfondi des connaissances des domaines ci-dessus dans la tête permet d'approcher l'apprentissage automatique et de trouver des solutions aux problèmes indiqués.
Pour moi, ce début convient tout à fait à un livre ordinaire d'un kilo et demi sur la science des données, ou à un article d'histoire d'horreur scientifique avec des formules, des symboles et des gribouillis à deux étages «sans valeur» qui ont un impact grave et déprimant sur les débutants dans le domaine de l'apprentissage automatique et juste par hasard intéressé par cette direction lecteurs inexpérimentés, pas accablés de "connaissances nécessaires". De plus, le nombre rond 10 des mêmes articles sur les 10 algorithmes d'apprentissage automatique les plus populaires (
par exemple ) ne fait que renforcer l'effet imposé.
Chez habr, ils se sont également distingués :
«La réponse à la question:« Quel type d'algorithme d'apprentissage automatique dois-je utiliser? »Cela ressemble toujours à ceci:« Selon les circonstances ». Le choix de l'algorithme dépend du volume, de la qualité et de la nature des données. Cela dépend de la façon dont vous gérez le résultat. Cela dépend de la façon dont les instructions pour l'ordinateur qui le met en œuvre ont été créées à partir de l'algorithme, et également du temps dont vous disposez. Même les analystes de données les plus expérimentés ne vous diront pas quel algorithme est le meilleur avant de l'essayer. »Sans aucun doute, toutes ces connaissances, ainsi que la persévérance et l'intérêt sont nécessaires et utiles pour obtenir de bons résultats non seulement sur la voie de la compréhension de l'apprentissage automatique, mais aussi dans de nombreux autres domaines. En outre, ils faciliteront la compréhension du fait que les algorithmes d'apprentissage automatique (ci-après dénommés algorithmes) sont loin d'être une douzaine; mais ce n'est que plus tard, avec une étude indépendante.
Mon objectif est de présenter au lecteur les algorithmes les plus utilisés d'un point de vue pratique et accessible. (Le fait que je ne suis pas un programmeur et, en plus, pas un mathématicien (saint-saint-saint!) Devrait souligner l'intérêt pour le récit. La formation d'ingénieur plus l'expérience dans le «sujet grandissent» de 10 ans (juste une sorte de nombre magique ) - comme on dit, et toutes mes affaires, tous mes bagages avec lesquels je suis allé directement à l'apprentissage automatique. Grâce à mon expérience dans l'industrie pétrolière, des idées pour utiliser des réseaux de neurones artificiels et des algorithmes d'apprentissage automatique ont été trouvées tout de suite (lire - il fallait ensembles de données.) Il ne restait plus qu'à Scarlet - apprendre à tordre-tordre les données afin de les soumettre correctement à l'entrée du "programme" et qui, en fait, l'algorithme à choisir. Et puis dans un cercle vicieux. Je constate que mon chemin était épineux et amusant - "des balles sifflaient au-dessus de ma tête" (de m / f "Les Aventures de Funtik"), - mais j'ai quand même réussi à prendre des notes, et si l'intérêt est indiqué, alors à l'avenir je publierai d'autres messages.)
Donc, je propose l'approche de l '«usinage» d'autre part: pourquoi ne pas alimenter votre ensemble de données existant (dans les exemples, vous chargerez des ensembles de données qui peuvent être facilement formés) à beaucoup d'algorithmes à la fois, et en fonction des résultats, décidez de celui auquel vous devez prêter une attention particulière étude approfondie et sélection des paramètres optimaux qui améliorent le résultat. De plus, la principale valeur de la méthode discutée ci-dessus est que ses résultats répondront à la question de la valeur de votre ensemble de données:
"commencez par résoudre le problème et assurez-vous que vous avez quelque chose à optimiser" (également de certains puis les statistiques insistantes sont allées, "respect" pour lui, bon conseil!).
Comment est-il fait?
On sait que l'essentiel des problèmes résolus à l'aide d'algorithmes concerne les problèmes de classification (classification) et d'analyse de régression (analyse prédictive). Par
classification, on entend une différenciation constante des unités d'observation (instances) d'un ensemble de données vers une certaine catégorie (classe) en fonction des résultats de la formation.
L'analyse de régression est un ensemble de méthodes et de processus statistiques permettant d'évaluer la relation entre les variables [
Statistics: Textbook / Ed. prof. M.R. Efimova. - M.: INFRA-M, 2002 ]. Le but de l'analyse de régression est d'évaluer la valeur d'une variable de sortie continue à partir des valeurs des variables d'entrée [
lien ].
Nous laissons de côté le fait que l'analyse de régression dispose de deux méthodes différentes: la modélisation prédictive et la prévision. Nous notons seulement que s'il existe une série temporelle (données de séries temporelles), alors en utilisant un modèle de régression basé sur une tendance explicite, soumise à la stationnarité (constance), la prévision peut être effectuée. Si les conditions de formation des niveaux de la série temporelle changent, c'est-à-dire que le processus non stationnaire n'est pas observé, alors c'est à la modélisation prédictive. Particulièrement destiné à la maîtrise totale du ML, je vous propose de lire cet article en anglais:
lien . Si une discussion se lève à ce sujet, je serai heureux d'y participer.
Étant donné que les séries chronologiques ne seront pas utilisées dans les exemples de cet article, le terme
prévision fait référence à
l'analyse prédictive .
Pour résoudre les problèmes de classification et de prévision, toute une gamme d'algorithmes convient, dont certains seront examinés plus loin. Pour plus de commodité, le texte suivant sera divisé en deux parties: dans la première, nous considérons les algorithmes de classification les plus courants, la seconde que nous consacrons aux algorithmes d'analyse de régression. Pour chaque partie, un ensemble de données «jouet» chargé à partir de
la bibliothèque scikit-learn (v0.21.3):
ensemble de données à chiffres (classification) et
ensemble de données sur les prix des maisons à boston (régression) sera présenté, ainsi que des liens vers chaque algorithme de la bibliothèque scikit-learn pour auto-examen et, éventuellement, étude.
Tous les exemples de code sont exécutés dans la console
IDE Spyder 3.3.3 sur Python 3.7.3.
Problème de classification
Tout d'abord, nous importons les modules et fonctions nécessaires que nous utiliserons pour résoudre le problème de la classification des données:
Téléchargez le jeu de données 'digits' directement depuis
le module 'sklearn.datasets' :
IDE Spyder fournit un outil pratique "Variable Manager", qui est utile à tout moment pour étudier l'apprentissage automatique (au moins pour moi), comme d'
autres "trucs" :
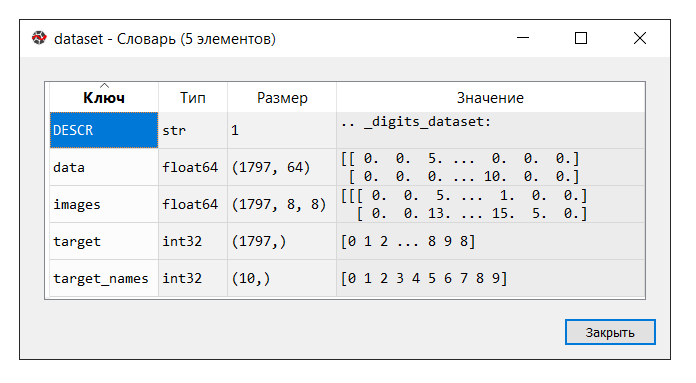
Exécutez le code. Dans la console "gestionnaire de variables", cliquez sur la variable d'
ensemble de données . Le dictionnaire suivant s'affiche:
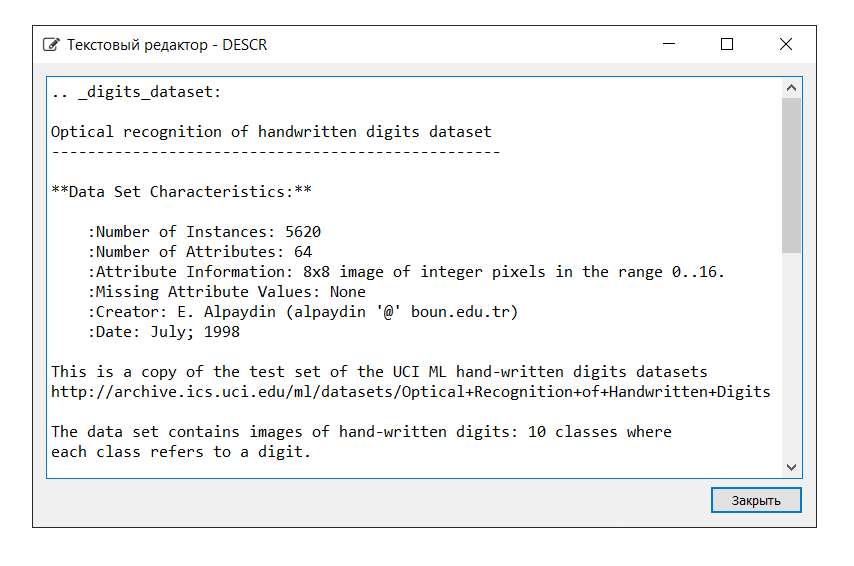
La description de l'ensemble de données est la suivante:
Dans cet exemple, nous n'avons pas besoin de la clé «images», nous affectons donc la variable «data» à
X , qui est un tableau NumPy multidimensionnel avec un ensemble d'attributs, 1797 lignes dans 64 colonnes et la variable
Y à «cible», un tableau multidimensionnel NumPy avec un marqueur pour chaque chaîne.
Ensuite, nous divisons l'ensemble de données en parties d'apprentissage et de test, configurons les paramètres pour évaluer les algorithmes (la validation croisée est utilisée [
un ,
deux ]), définissant la métrique `` précision '' dans le paramètre `` scoring '' [
lien ]. La précision est la proportion d'objets correctement classés par rapport au nombre total d'objets. Plus le résultat est proche de 1, mieux c'est [
link ]. De plus, dans l'un des livres, il a été constaté que les résultats de 0,95 (ou 95%) et plus sont considérés comme excellents.
Laissez les variables
X_train et
Y_train être utilisées à des fins de formation,
X_test et
Y_test pour le développement des valeurs de prévision. Dans ce cas, la variable
Y_test n'est pas impliquée dans le calcul de la prévision: en utilisant la méthode du `` score '', qui est la même pour chacun des algorithmes présentés ci-dessous, nous calculerons les bonnes réponses en utilisant la métrique `` précision ''. Cela nous permettra de juger comment l'algorithme fait face à la tâche. Je ne dis pas, pour notre part, il est si humainement vil de ne pas inciter la voiture avec les bonnes réponses, mais comment vérifier ses performances autrement?
Vous trouverez ci-dessous une liste d'algorithmes avec lesquels nous alimentons l'ensemble de données. Sur la base des résultats des calculs, nous conclurons quel algorithme (lequel des algorithmes) montre la plus grande efficacité. Cette méthode peut très bien être qualifiée de
«test blitz d'algorithmes d'apprentissage automatique» (ci-après - test blitz).
Pour plus de commodité, les informations seront abrégées à côté de chaque algorithme. Il convient de noter que les paramètres de chaque algorithme sont acceptés par défaut (par défaut), à l'exception de certains points, afin de fournir des conditions égales.
Algorithmes linéaires:
- Régression logistique * /
Régression logistique ('LR')
* Le mot «régression» peut prêter à confusion. Mais n'oubliez pas que la «régression logistique» est un algorithme de classification-
Analyse discriminante linéaire («LDA»)
Algorithmes non linéaires:
- Méthode des k voisins les plus proches (classification) /
K-Neighbors Classifier («KNN»)
-
Classificateur d'arbre de décision («CART»)
-
Naive Bayes Classifier («NB»)
- Méthode de
classification des vecteurs de support linéaire (Classification) /
Classification des vecteurs de support linéaire («LSVC»)
- Méthode du
vecteur de support (Classification) /
Classification du vecteur de support C («SVC»)
Algorithme de réseau de neurones artificiels:
-
Perceptron multicouches /
Perceptrons multicouches («MLP»)
Algorithmes d'ensemble:
- Bagging (classification) /
Bagging Classifier ('BG') (Bagging = Bootstrap agrégation)
-
Classification aléatoire des forêts («RF»)
-
Classificateur d'arbres supplémentaires («ET»)
- AdaBoost (classification) /
AdaBoost Classifier («AB») (AdaBoost = Adaptive Boosting)
- Amplification de gradient (classification) /
Classificateur de renforcement de gradient ('GB')
Ainsi, la liste des «modèles» contient les modèles suivants:
models = [] models.append(('LR', LogisticRegression())) models.append(('LDA', LinearDiscriminantAnalysis())) models.append(('KNN', KNeighborsClassifier())) models.append(('CART', DecisionTreeClassifier())) models.append(('NB', GaussianNB())) models.append(('LSVC', LinearSVC())) models.append(('SVC', SVC())) models.append(('MLP', MLPClassifier())) models.append(('BG', BaggingClassifier(n_estimators=n_estimators))) models.append(('RF', RandomForestClassifier(n_estimators=n_estimators))) models.append(('ET', ExtraTreesClassifier(n_estimators=n_estimators))) models.append(('AB', AdaBoostClassifier(n_estimators=n_estimators, algorithm='SAMME'))) models.append(('GB', GradientBoostingClassifier(n_estimators=n_estimators)))
Comme déjà mentionné, l'efficacité de chaque algorithme est évaluée en utilisant la validation croisée. En conséquence, un message s'affiche (msg - abréviation du message) contenant les informations suivantes: nom du modèle sous la forme d'une abréviation, score moyen de 10 fois la validation croisée des données d'entraînement (`` précision '' métrique), l'écart type est indiqué entre parenthèses , ainsi que la valeur de la métrique de «précision» sur les données de test.
Après avoir exécuté le code, nous obtenons les résultats suivants:
LR: train = 0.957 (0.014) / test = 0.948 LDA: train = 0.951 (0.014) / test = 0.946 KNN: train = 0.985 (0.013) / test = 0.981 CART: train = 0.843 (0.033) / test = 0.830 NB: train = 0.819 (0.048) / test = 0.806 LSVC: train = 0.942 (0.017) / test = 0.928 SVC: train = 0.343 (0.079) / test = 0.342 MLP: train = 0.972 (0.012) / test = 0.961 BG: train = 0.952 (0.021) / test = 0.941 RF: train = 0.968 (0.017) / test = 0.965 ET: train = 0.980 (0.010) / test = 0.975 AB: train = 0.827 (0.049) / test = 0.823 GB: train = 0.964 (0.013) / test = 0.968
Diagramme d'étendue (
«boîte avec moustache» ) (diagramme ou diagramme en boîte et moustaches, diagramme en boîte):
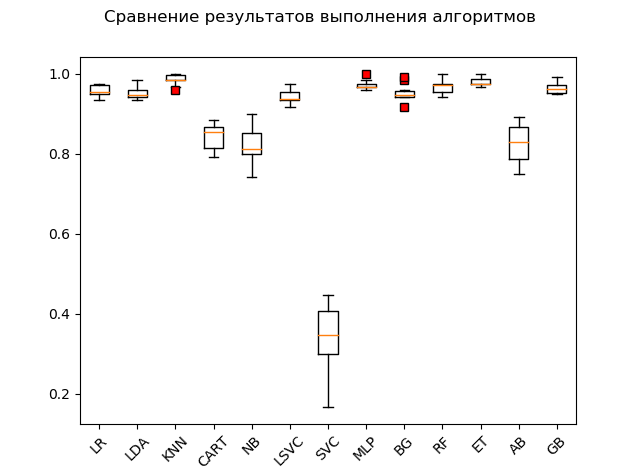
À la suite d'un test éclair sur des données brutes, on peut voir que les plus efficaces sur les données de test étaient les algorithmes «KNN» (k-voisins les plus proches), «ET» (extra-arbres), «GB» (gradient «boosting»), 'RF' (forêt aléatoire) et 'MLP' (perceptron multicouche):
KNN: train = 0.985 (0.013) / test = 0.981 ET: train = 0.980 (0.010) / test = 0.975 GB: train = 0.964 (0.013) / test = 0.968 RF: train = 0.968 (0.017) / test = 0.965 MLP: train = 0.972 (0.012) / test = 0.961 LR: train = 0.957 (0.014) / test = 0.948 LDA: train = 0.951 (0.014) / test = 0.946 BG: train = 0.952 (0.021) / test = 0.941 LSVC: train = 0.942 (0.017) / test = 0.928 CART: train = 0.843 (0.033) / test = 0.830 AB: train = 0.827 (0.049) / test = 0.823 NB: train = 0.819 (0.048) / test = 0.806 SVC: train = 0.343 (0.079) / test = 0.342
Cependant, de nombreux algorithmes sont très pointilleux sur les données qui leur sont fournies. Par conséquent, l'une des étapes nécessaires est la soi-disant préparation préliminaire des données (prétraitement des données [
lien ])
Cependant, il arrive que l'algorithme montre les meilleurs résultats sans traitement préalable. D'où la recommandation suivante: inclure dans le test Blitz plusieurs transformations de l'ensemble de données d'origine et, après avoir effectué les calculs, comparer les résultats afin de saisir l'essence du problème dans son ensemble.
Les méthodes de préparation des données préliminaires les plus couramment utilisées sont les suivantes:
-
normalisation;
-
mise à l'échelle (la plage par défaut est [0, 1]);
-
normalisationCes opérations avec évaluation ultérieure peuvent être automatisées et placées sur le convoyeur à l'aide de l'outil
Pipeline .
Un extrait de code avec normalisation des données source est le suivant:
Notez l'ajout de «_SS» (abréviation de StandardScaler) pour répertorier les noms. Ceci est fait afin de ne pas empiler les résultats, ainsi que de les visualiser commodément en utilisant le "gestionnaire de variables" après que les conversions soient effectuées.
L'exécution d'un extrait de code produit les résultats suivants:
SS_LR: train = 0.958 (0.015) / test = 0.949 SS_LDA: train = 0.951 (0.014) / test = 0.946 SS_KNN: train = 0.968 (0.023) / test = 0.970 SS_CART: train = 0.853 (0.036) / test = 0.835 SS_NB: train = 0.756 (0.046) / test = 0.751 SS_LSVC: train = 0.945 (0.018) / test = 0.941 SS_SVC: train = 0.976 (0.015) / test = 0.990 SS_MLP: train = 0.976 (0.012) / test = 0.973 SS_BG: train = 0.947 (0.018) / test = 0.948 SS_RF: train = 0.973 (0.016) / test = 0.970 SS_ET: train = 0.980 (0.012) / test = 0.975 SS_AB: train = 0.827 (0.049) / test = 0.823 SS_GB: train = 0.964 (0.013) / test = 0.968
Boîte à moustache (StandardScaler):
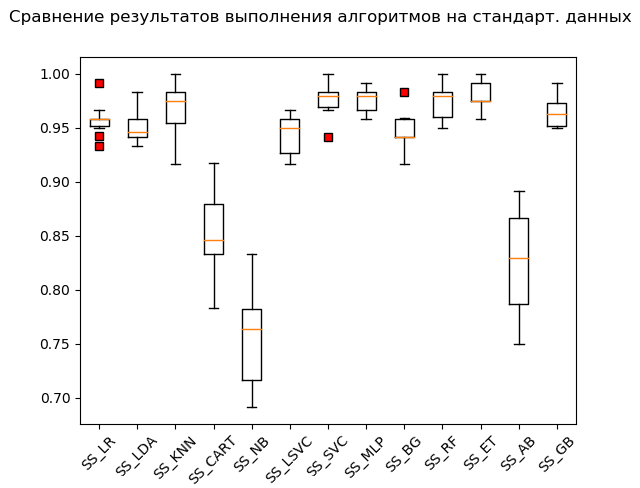
Selon les résultats du calcul sur des données standardisées, les algorithmes suivants sont devenus leaders:
SS_SVC: train = 0.976 (0.015) / test = 0.990 SS_ET: train = 0.980 (0.012) / test = 0.975 SS_MLP: train = 0.976 (0.012) / test = 0.973 SS_KNN: train = 0.968 (0.023) / test = 0.970 SS_RF: train = 0.973 (0.016) / test = 0.970 SS_GB: train = 0.964 (0.013) / test = 0.968 SS_LR: train = 0.958 (0.015) / test = 0.949 SS_BG: train = 0.947 (0.018) / test = 0.948 SS_LDA: train = 0.951 (0.014) / test = 0.946 SS_LSVC: train = 0.945 (0.018) / test = 0.941 SS_CART: train = 0.853 (0.036) / test = 0.835 SS_AB: train = 0.827 (0.049) / test = 0.823 SS_NB: train = 0.756 (0.046) / test = 0.751
Comme on dit, des chiffons aux richesses: la méthode des vecteurs supports («SVC»), alimentée par des données standardisées, a fait le reste, montrant un excellent résultat. Lors de la vérification «manuelle», en comparant les valeurs des variables
Y_test et
predictions_SS [6] , l'algorithme n'a pas mâché seulement quelques valeurs.
Ensuite, le même code est exécuté pour les fonctions MinMaxScaler (mise à l'échelle) et Normalizer (normalisation). Je ne donnerai pas le code complet dans l'article. Vous pouvez le télécharger depuis mon référentiel sur GitHub:
lien .
N'oubliez pas de vous arrêter un moment et de vous moquer de vous à des fins éducatives uniquement! :)
Par conséquent, après avoir parcouru tout le code, nous obtenons les résultats suivants:
LR: train = 0.957 (0.014) / test = 0.948 LDA: train = 0.951 (0.014) / test = 0.946 KNN: train = 0.985 (0.013) / test = 0.981 CART: train = 0.843 (0.033) / test = 0.830 NB: train = 0.819 (0.048) / test = 0.806 LSVC: train = 0.942 (0.017) / test = 0.928 SVC: train = 0.343 (0.079) / test = 0.342 MLP: train = 0.972 (0.012) / test = 0.961 BG: train = 0.952 (0.021) / test = 0.941 RF: train = 0.968 (0.017) / test = 0.965 ET: train = 0.980 (0.010) / test = 0.975 AB: train = 0.827 (0.049) / test = 0.823 GB: train = 0.964 (0.013) / test = 0.968 SS_LR: train = 0.958 (0.015) / test = 0.949 SS_LDA: train = 0.951 (0.014) / test = 0.946 SS_KNN: train = 0.968 (0.023) / test = 0.970 SS_CART: train = 0.853 (0.036) / test = 0.835 SS_NB: train = 0.756 (0.046) / test = 0.751 SS_LSVC: train = 0.945 (0.018) / test = 0.941 SS_SVC: train = 0.976 (0.015) / test = 0.990 SS_MLP: train = 0.976 (0.012) / test = 0.973 SS_BG: train = 0.947 (0.018) / test = 0.948 SS_RF: train = 0.973 (0.016) / test = 0.970 SS_ET: train = 0.980 (0.012) / test = 0.975 SS_AB: train = 0.827 (0.049) / test = 0.823 SS_GB: train = 0.964 (0.013) / test = 0.968 MMS_LR: train = 0.961 (0.013) / test = 0.953 MMS_LDA: train = 0.951 (0.014) / test = 0.946 MMS_KNN: train = 0.985 (0.013) / test = 0.981 MMS_CART: train = 0.850 (0.027) / test = 0.840 MMS_NB: train = 0.796 (0.045) / test = 0.786 MMS_LSVC: train = 0.964 (0.012) / test = 0.958 MMS_SVC: train = 0.963 (0.016) / test = 0.956 MMS_MLP: train = 0.972 (0.011) / test = 0.963 MMS_BG: train = 0.948 (0.024) / test = 0.946 MMS_RF: train = 0.973 (0.014) / test = 0.968 MMS_ET: train = 0.983 (0.010) / test = 0.981 MMS_AB: train = 0.827 (0.049) / test = 0.823 MMS_GB: train = 0.963 (0.013) / test = 0.968 N_LR: train = 0.938 (0.020) / test = 0.919 N_LDA: train = 0.952 (0.013) / test = 0.949 N_KNN: train = 0.981 (0.012) / test = 0.985 N_CART: train = 0.834 (0.028) / test = 0.825 N_NB: train = 0.825 (0.043) / test = 0.805 N_LSVC: train = 0.960 (0.014) / test = 0.953 N_SVC: train = 0.551 (0.053) / test = 0.586 N_MLP: train = 0.963 (0.018) / test = 0.946 N_BG: train = 0.949 (0.016) / test = 0.938 N_RF: train = 0.973 (0.015) / test = 0.970 N_ET: train = 0.982 (0.012) / test = 0.980 N_AB: train = 0.825 (0.040) / test = 0.820 N_GB: train = 0.953 (0.022) / test = 0.956
Résultats du «Top 5»:
SS_SVC: train = 0.976 (0.015) / test = 0.990 N_KNN: train = 0.981 (0.012) / test = 0.985 KNN: train = 0.985 (0.013) / test = 0.981 MMS_KNN: train = 0.985 (0.013) / test = 0.981 MMS_ET: train = 0.983 (0.010) / test = 0.981
Ainsi, selon les résultats d'un test éclair d'algorithmes d'apprentissage automatique pour résoudre le problème de classification de l'ensemble de données `` chiffres '', les algorithmes d'apprentissage automatique les plus appropriés sont: la méthode k-voisins les plus proches ('KNN'), la méthode des vecteurs de support ('SVC') et les arbres supplémentaires («ET»). Ces algorithmes devraient faire l'objet d'une plus grande attention au développement ultérieur des résultats visant à accroître l'efficacité des calculs. Tout, comme on dit, est résoluble.
Et sur cette note soulevée, passez en douceur à la 2ème partie.
Problème de prévision
On bouge sur le pouce:
Exécutez le code et traitez le dictionnaire. La description et les clés sont les suivantes:


Nous attribuons la clé `` données '' à la variable
X , qui est un tableau NumPy multidimensionnel avec un ensemble d'attributs, dimensionnez 506 lignes par 13 colonnes, et la variable
Y - `` cible '', un tableau NumPy multidimensionnel avec un marqueur pour chaque ligne.
Nous divisons l'ensemble de données en parties de formation et de test, configurons les paramètres d'évaluation des algorithmes. Dans le paramètre «scoring», nous définissons l'une des
métriques «r2» traditionnelles pour l'analyse de régression:
R2 - coefficient de détermination - c'est la proportion de la variance de la variable dépendante, expliquée par le modèle en question (
lien ).
«Le coefficient de détermination pour un modèle avec une constante prend des valeurs de 0 à 1. Plus le coefficient est proche de 1, plus la dépendance est forte. Lors de l'évaluation des modèles de régression, cela est interprété comme faisant correspondre le modèle aux données. Pour les modèles acceptables, on suppose que le coefficient de détermination doit être d'au moins 50% (dans ce cas, le coefficient de corrélation multiple dépasse 70% modulo). Les modèles avec un coefficient de détermination supérieur à 80% peuvent être considérés comme assez bons (le coefficient de corrélation dépasse 90%). L'égalité du coefficient de détermination à l'unité signifie que la variable expliquée est exactement décrite par le modèle considéré » (ibid.).
Pour résoudre le problème de prévision, nous utilisons les algorithmes suivants:
Algorithmes linéaires:
-
Régression linéaire («LR»)
- Régression de crête (régression de crête) /
Régression de crête («R»)
- Régression Lasso (de l'anglais LASSO - Opérateur de retrait et de sélection le moins absolu) /
Régression Lasso ('L')
- Méthode de régression
Elastic Net Regression («ELN»)
- Méthode de
régression du moindre angle (LARS) («LARS»)
- Régression de
la crête bayésienne / régression de
la crête bayésienne («BR»)
Algorithmes non linéaires:
-
Méthode du régresseur k-voisins les plus proches («KNR»)
-
Régresseur d'arbre de décision («DTR»)
-
Machine à vecteur de support linéaire (régression) /
Machine à vecteur de support linéaire - Régression / ('LSVR')
- Méthode de
vecteur de support (régression) /
Régression de vecteur de support Epsilon ('SVR')
Algorithmes d'ensemble:
- AdaBoost (régression) /
AdaBoost Regressor ('ABR') (AdaBoost = Adaptive Boosting)
- Ensachage (régression) /
Régresseur d'ensachage ('BR') (Ensachage = agrégation Bootstrap)
-
Régresseur d'arbres supplémentaires («ETR»)
- Augmentation du gradient (régression) / Régression de l'augmentation du
gradient ('GBR')
-
Classification aléatoire des forêts (régression) /
Random Forest Classifier («RFR»)
Ainsi, la liste des «modèles» contient les modèles suivants:
models = [] models.append(('LR', LinearRegression())) models.append(('R', Ridge())) models.append(('L', Lasso())) models.append(('ELN', ElasticNet())) models.append(('LARS', Lars())) models.append(('BR', BayesianRidge(n_iter=n_iter))) models.append(('KNR', KNeighborsRegressor())) models.append(('DTR', DecisionTreeRegressor())) models.append(('LSVR', LinearSVR())) models.append(('SVR', SVR())) models.append(('ABR', AdaBoostRegressor(n_estimators=n_estimators))) models.append(('BR', BaggingRegressor(n_estimators=n_estimators))) models.append(('ETR', ExtraTreesRegressor(n_estimators=n_estimators))) models.append(('GBR', GradientBoostingRegressor(n_estimators=n_estimators))) models.append(('RFR', RandomForestRegressor(n_estimators=n_estimators)))
Comme pour la classification, l'évaluation de l'efficacité de chaque algorithme se fait par validation croisée. Le message affiché contient les informations suivantes: le nom du modèle sous la forme d'une abréviation, le score moyen d'une validation croisée 10 fois sur les données d'entraînement (métrique `` r2 ''), l'écart type et le coefficient de détermination r2 sur les données de test sont indiqués entre parenthèses.
Après avoir exécuté le code, nous obtenons les résultats suivants:
LR: train = 0.746 (0.068) / test = 0.579 R: train = 0.744 (0.067) / test = 0.570 L: train = 0.689 (0.070) / test = 0.641 ELN: train = 0.677 (0.074) / test = 0.662 LARS: train = 0.744 (0.069) / test = 0.579 BR: train = 0.739 (0.069) / test = 0.571 KNR: train = 0.434 (0.288) / test = 0.538 DTR: train = 0.671 (0.145) / test = 0.637 LSVR: train = 0.550 (0.144) / test = 0.459 SVR: train = -0.012 (0.048) / test = -0.003 ABR: train = 0.810 (0.078) / test = 0.763 BR: train = 0.854 (0.064) / test = 0.805 ETR: train = 0.889 (0.047) / test = 0.836 GBR: train = 0.878 (0.042) / test = 0.863 RFR: train = 0.852 (0.068) / test = 0.819
Tableau de portée:
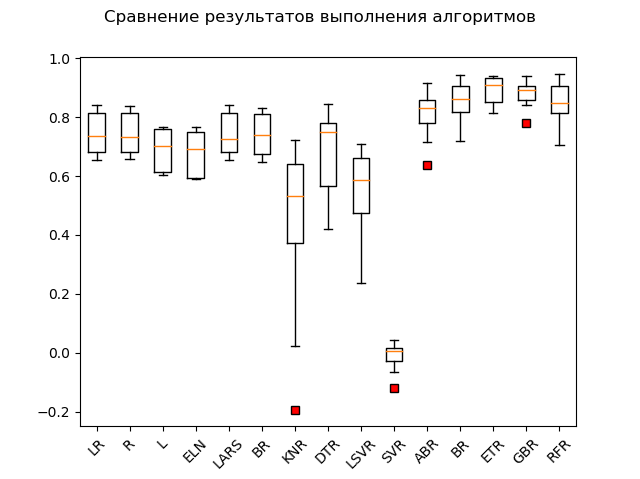
Les leaders évidents sont les méthodes d'ensemble 'GBR' (gradient 'boosting'), 'ETR' (extra-trees), 'RFR' (random forest) et 'BR' ('bagging'):
GBR: train = 0.878 (0.042) / test = 0.863 ETR: train = 0.889 (0.047) / test = 0.836 RFR: train = 0.852 (0.068) / test = 0.819 BR: train = 0.854 (0.064) / test = 0.805 ABR: train = 0.810 (0.078) / test = 0.763 ELN: train = 0.677 (0.074) / test = 0.662 L: train = 0.689 (0.070) / test = 0.641 DTR: train = 0.671 (0.145) / test = 0.637 LR: train = 0.746 (0.068) / test = 0.579 LARS: train = 0.744 (0.069) / test = 0.579 BR: train = 0.739 (0.069) / test = 0.571 R: train = 0.744 (0.067) / test = 0.570 KNR: train = 0.434 (0.288) / test = 0.538 LSVR: train = 0.550 (0.144) / test = 0.459 SVR: train = -0.012 (0.048) / test = -0.003
Un "adabust", une sorte de "loshara", est en retard.
Peut-être que les trois dirigeants peignent la normalisation et la normalisation. Découvrons-le en exécutant le reste du code.
Les résultats sont les suivants:
SS_LR: train = 0.746 (0.068) / test = 0.579 SS_R: train = 0.746 (0.068) / test = 0.578 SS_L: train = 0.678 (0.054) / test = 0.510 SS_ELN: train = 0.665 (0.060) / test = 0.513 SS_LARS: train = 0.744 (0.069) / test = 0.579 SS_BR: train = 0.746 (0.066) / test = 0.576 SS_KNR: train = 0.763 (0.098) / test = 0.739 SS_DTR: train = 0.610 (0.242) / test = 0.629 SS_LSVR: train = 0.727 (0.091) / test = 0.482 SS_SVR: train = 0.653 (0.126) / test = 0.610 SS_ABR: train = 0.811 (0.076) / test = 0.819 SS_BR: train = 0.853 (0.074) / test = 0.813 SS_ETR: train = 0.887 (0.048) / test = 0.846 SS_GBR: train = 0.878 (0.038) / test = 0.860 SS_RFR: train = 0.851 (0.071) / test = 0.818 N_LR: train = 0.751 (0.099) / test = 0.576 N_R: train = 0.287 (0.126) / test = 0.271 N_L: train = -0.030 (0.032) / test = -0.000 N_ELN: train = -0.007 (0.030) / test = 0.023 N_LARS: train = 0.751 (0.099) / test = 0.576 N_BR: train = 0.744 (0.100) / test = 0.589 N_KNR: train = 0.485 (0.192) / test = 0.504 N_DTR: train = 0.729 (0.080) / test = 0.765 N_LSVR: train = 0.182 (0.108) / test = 0.136 N_SVR: train = 0.086 (0.076) / test = 0.084 N_ABR: train = 0.795 (0.053) / test = 0.752 N_BR: train = 0.854 (0.054) / test = 0.827 N_ETR: train = 0.877 (0.048) / test = 0.850 N_GBR: train = 0.852 (0.063) / test = 0.872 N_RFR: train = 0.852 (0.051) / test = 0.801
Comme vous pouvez le voir, les méthodes d'ensemble sont toujours en avance sur tout le monde.«Top 5» contient les résultats suivants: N_GBR: train = 0.852 (0.063) / test = 0.872 GBR: train = 0.878 (0.042) / test = 0.863 SS_GBR: train = 0.878 (0.038) / test = 0.860 N_ETR: train = 0.877 (0.048) / test = 0.850 SS_ETR: train = 0.887 (0.048) / test = 0.846
Nous afficherons un tableau comparant les résultats: le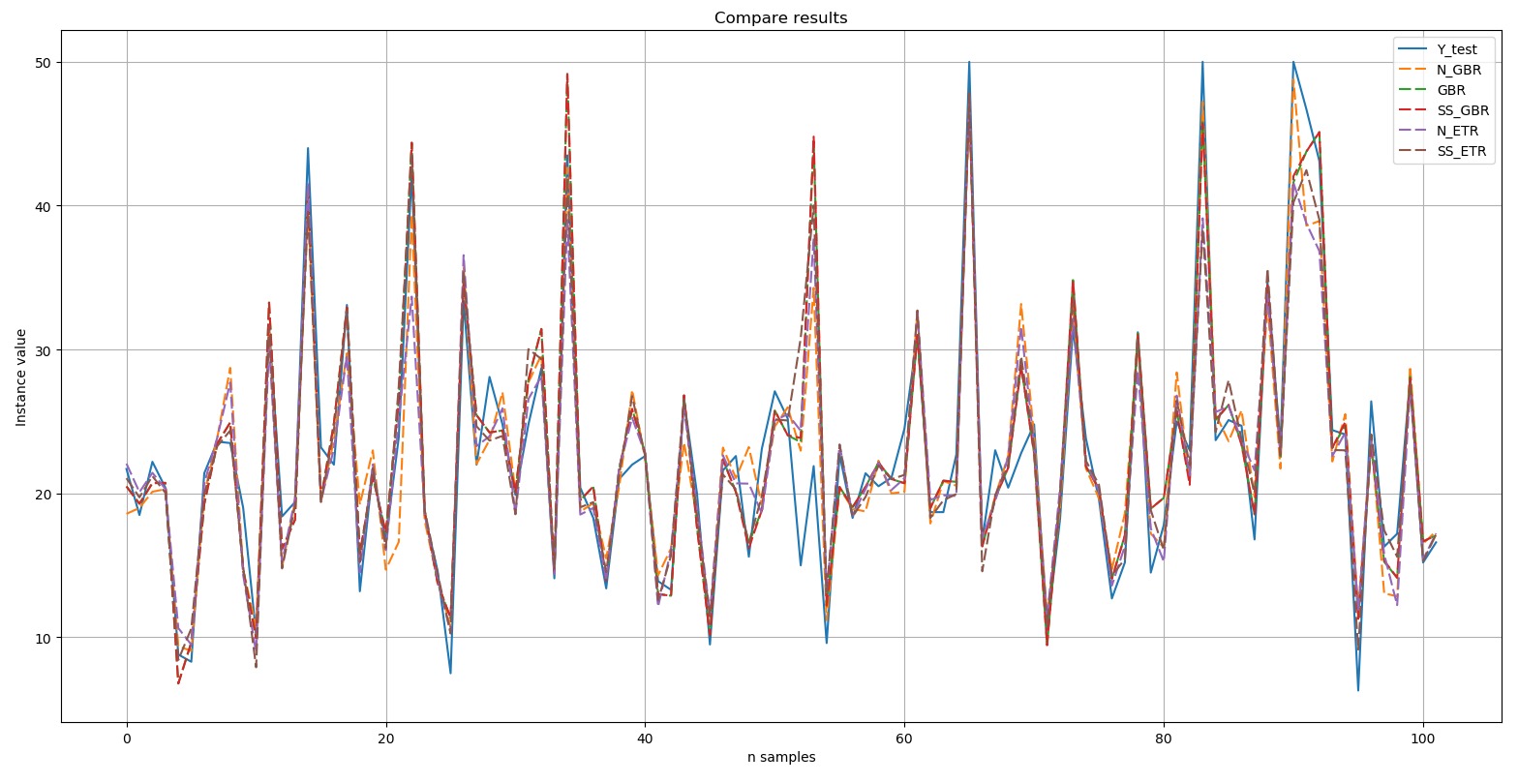 test Y est la norme. Les cinq résultats sélectionnés montrés dans le diagramme sont indiqués par une ligne pointillée. On peut voir que tous les pics ont été reproduits soit avec répétition exacte, soit à un degré ou à un autre.Bref extrait de comparaison manuelle des valeurs de référence et des valeurs prévisionnelles de l'algorithme inclus dans le Top 5:
test Y est la norme. Les cinq résultats sélectionnés montrés dans le diagramme sont indiqués par une ligne pointillée. On peut voir que tous les pics ont été reproduits soit avec répétition exacte, soit à un degré ou à un autre.Bref extrait de comparaison manuelle des valeurs de référence et des valeurs prévisionnelles de l'algorithme inclus dans le Top 5: Ainsi, selon les résultats d'un test de blitz d'algorithmes d'apprentissage automatique pour résoudre le problème de la prévision de l'ensemble de données «Boston House-Price», les algorithmes les plus appropriés sont le «boosting» de gradient («GBR ») et d'arbres supplémentaires (« ETR »). Ces algorithmes doivent faire l'objet d'une attention accrue afin de développer davantage les résultats et d'améliorer l'efficacité des prévisions.
Ainsi, selon les résultats d'un test de blitz d'algorithmes d'apprentissage automatique pour résoudre le problème de la prévision de l'ensemble de données «Boston House-Price», les algorithmes les plus appropriés sont le «boosting» de gradient («GBR ») et d'arbres supplémentaires (« ETR »). Ces algorithmes doivent faire l'objet d'une attention accrue afin de développer davantage les résultats et d'améliorer l'efficacité des prévisions.Postface
Une vérification rapide des algorithmes d'apprentissage automatique permet, en première approximation, d'identifier les algorithmes les plus efficaces pour résoudre les problèmes de classification et d'analyse de régression (prévision). Nous en avons été convaincus en traitant l'ensemble de données «digits», en triant brillamment les instances en 10 classes, ainsi que l'ensemble de données «boston house-price», en triant «étonnamment» la recherche de dépendances et en faisant une prévision «fluctuante» de la variable dépendante.Vous êtes invité à essayer cette méthode sur vos propres ensembles de données ou sur ceux que vous pouvez creuser dans différents référentiels, y compris GitHub. Par exemple: lien .Obtenez un ensemble de données approprié pour la cible - et définissez un troupeau d'algorithmes dessus dans l'équipe du test de blitz. Et là, il devient clair dont la prise: un sur le terrain n'est pas un guerrier. :)
Et en conclusion. Je serai reconnaissant pour vos commentaires, questions et suggestions, car la base de cet article est l'information que je partage avec de nouveaux collègues sur chaque nouveau projet dans le domaine de l'apprentissage automatique. Chacun d'eux a sa propre spécialisation, à propos de l'apprentissage automatique et des réseaux de neurones artificiels, beaucoup d'entre eux ne sont «entendus que quelque part», il est donc important pour moi de parler de complexes, de multiples facettes et, enfin, imprenables (il s'agit de l'ANN et de l'apprentissage automatique en général) :), dans un langage simple et compréhensible; montrez que ce ne sont pas les dieux qui brûlent des pots; et que s'il y a un intérêt, alors plus d'une douzaine d'algorithmes peuvent être "exploités". :)
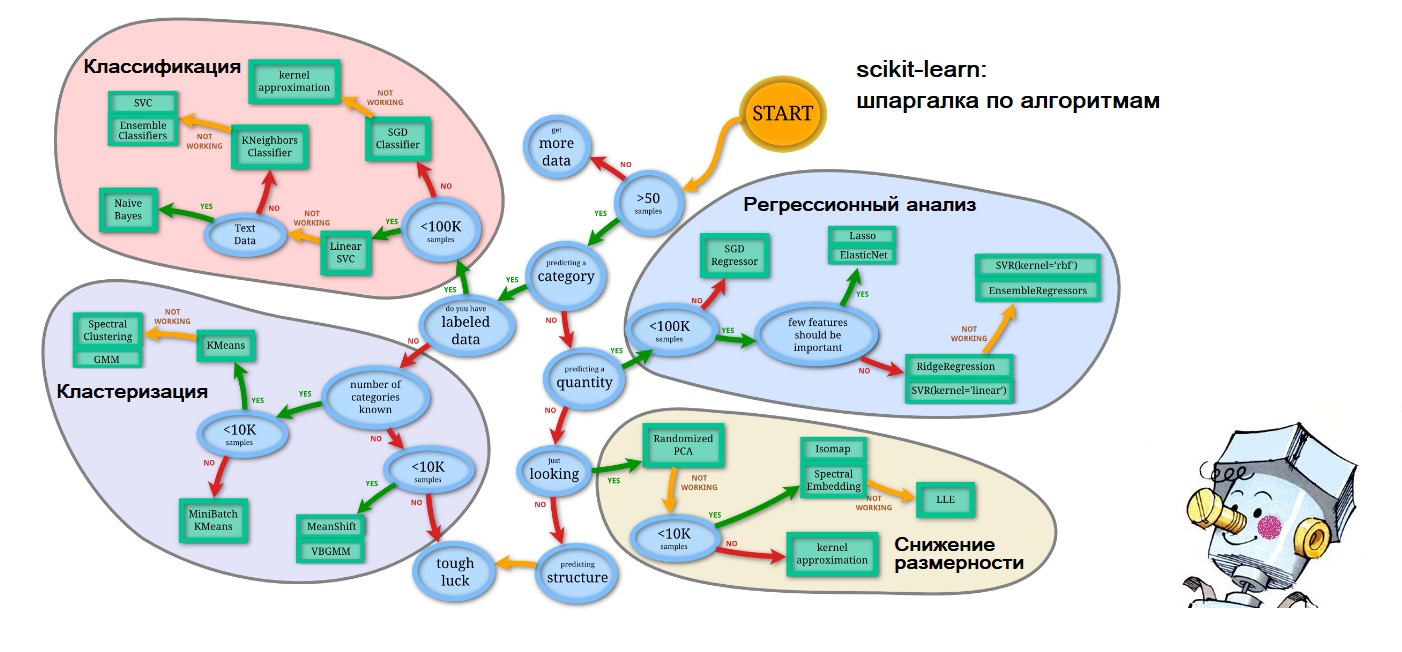
PS À la fin de l'article, j'ai déjà commencé à me prédire, donc aux questions à venir sur où j'ai obtenu la feuille de triche dans le premier chiffre que je donne: tout sur le même site scikit-learn.org ( `` Choisir le bon estimateur '' ): lien . Et la personnification de l'intelligence artificielle sous la forme d'un Samodelkin rougi est ainsi des vagues de la mémoire de mon enfance heureuse.